【微服务的数据一致性分发问题】究极解决方案
文章目录
- 一、微服务数据分发
- 1、简介
- 2、典型场景
- (1)跨服务业务流程协同
- (2)数据副本同步(读写分离)
- (3)实时状态通知
- (4)数据聚合与统计分析
- (5)多端数据一致性
- 3、什么是数据一致性分发
- (1)核心挑战
- (2)典型问题
- (3)设计原则
- 二、解决方案
- 1、双写(容易产生问题)
- 2、事务性发件箱模式(类似本地消息表)
- (1)简介
- (2)设计发件箱表
- (3)本地事务记录消息
- (4)消息发送器:发送并确认
- (5)处理异常与重试
- (6)关键要点
- 3、变更数据捕获(Change Data Capture,CDC)
- (1)简介
- (2)与发件箱模式的对比
- 参考资料
一、微服务数据分发
1、简介
在微服务架构中,“数据分发”指的是当一个服务(源服务)的数据发生变更时,通过特定机制将变更信息传递给其他依赖该数据的服务(目标服务),以保证各服务间数据协同的过程。它是解决微服务“数据隔离”与“业务协同”矛盾的核心手段。
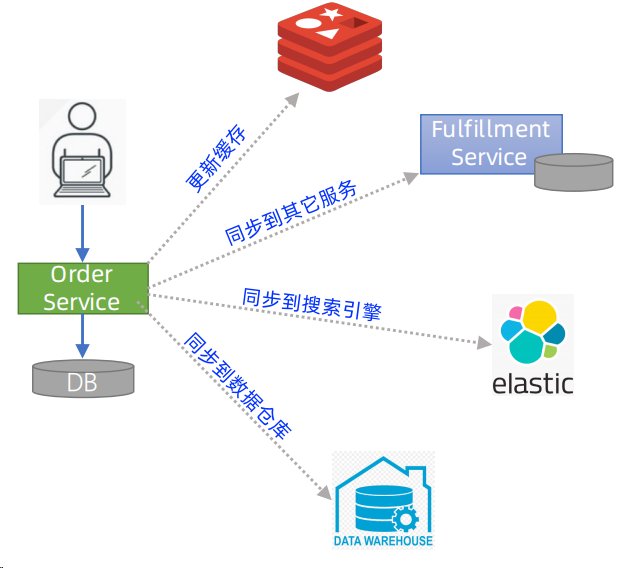
2、典型场景
微服务的数据分发场景本质上是“服务间数据依赖”的具体体现,以下是最常见的几类场景:
(1)跨服务业务流程协同
场景描述:一个完整业务流程需要多个服务协作完成,源服务的数据变更会触发其他服务的业务操作。
典型案例:
电商“下单流程”:订单服务创建订单后,需将“订单创建”信息分发给库存服务(扣减库存)、支付服务(发起支付)、物流服务(预约配送);
金融“转账流程”:账户服务扣减转出方金额后,需将“转账成功”信息分发给交易记录服务(记录流水)、通知服务(发送短信给用户)。
核心特点:数据分发是业务流程的“串联者”,若分发失败,整个流程会中断或出现数据不一致(如订单创建了但库存未扣减,导致超卖)。
(2)数据副本同步(读写分离)
场景描述:目标服务为了避免频繁调用源服务查询数据(减少网络开销、提高响应速度),会在本地存储源服务数据的“副本”,需通过数据分发同步副本更新。
典型案例:
用户中心服务存储用户基础信息(姓名、手机号),商品评价服务为了快速展示“评价者昵称”,会在本地存储用户信息副本,当用户中心的昵称更新时,需将变更分发给评价服务;
商品服务存储商品详情(名称、价格),搜索服务为了加速商品搜索,会在本地索引库存储商品信息副本,当商品价格调整时,需将变更分发给搜索服务。
核心特点:数据副本是“只读”的,分发目的是保证副本与源数据的最终一致,避免目标服务使用过期数据(如用户改了昵称但评价区仍显示旧昵称)。
(3)实时状态通知
场景描述:源服务的关键状态变更需要实时通知给关注该状态的目标服务,以触发即时响应。
典型案例:
订单服务的订单状态从“待支付”变为“已支付”时,需实时通知库存服务(锁定库存→确认扣减)、客服服务(生成待处理工单);
物联网设备服务监测到设备“离线”时,需实时通知运维服务(触发告警)、用户服务(推送设备离线通知)。
核心特点:对实时性要求高(通常毫秒级或秒级),若分发延迟会导致业务响应滞后(如用户已支付但库存未确认扣减,可能被其他订单占用)。
(4)数据聚合与统计分析
场景描述:数据平台或分析服务需要汇总多个源服务的数据,进行统计、报表生成或业务分析,需通过数据分发获取各服务的原始数据变更。
典型案例:
电商平台的“销售报表服务”需要聚合订单服务(订单金额)、支付服务(支付成功金额)、退款服务(退款金额)的数据,生成每日销售额报表,需各服务将数据变更分发给报表服务;
风控服务需要实时获取用户服务(用户行为)、订单服务(下单频率)、支付服务(支付渠道)的变更数据,构建风控模型。
核心特点:数据分发的频率和时效性取决于分析需求(如实时风控需秒级,日报表可T+1),但需保证数据完整性(不能遗漏关键变更)。
(5)多端数据一致性
场景描述:同一业务数据需在多个终端(Web、APP、小程序)或多地域服务节点间保持一致,需通过数据分发同步变更。
典型案例:
社交平台的“用户动态”:用户在APP发布动态后,需将动态数据分发给Web服务、小程序服务,确保多端展示一致;
跨国电商的“商品库存”:美国仓库的库存变更需分发给欧洲、亚洲的区域服务,确保全球用户看到的库存状态一致。
核心特点:数据分发需覆盖所有依赖端,避免“信息孤岛”(如用户在APP删了动态,Web端仍显示)。
3、什么是数据一致性分发
在微服务架构中,数据一致性分发是指当一个服务的数据发生变更时,如何将这一变更可靠、准确地同步到依赖该数据的其他服务,确保各服务间数据最终一致的问题。由于微服务的分布式特性(独立数据库、网络不可靠、服务自治),数据一致性分发面临诸多挑战,是微服务设计中的核心难题之一。
(1)核心挑战
微服务架构下,每个服务通常维护独立的数据库(“数据私有”原则),服务间通过API或消息队列通信。当某个服务的数据变更需要同步到其他服务时,会面临以下核心挑战:
1.分布式环境的不可靠性
网络延迟、中断、服务宕机等问题可能导致:
- 数据变更通知丢失(如服务A更新数据后,通知服务B时网络中断,B未收到通知);
- 通知重复(如服务A重试机制导致服务B收到多条相同通知);
- 通知乱序(如服务A的两次更新通知,服务B先收到后发的通知)。
2.本地事务与跨服务同步的原子性冲突
服务A的本地数据变更(如创建订单)与“通知服务B”这两个操作无法天然保证原子性:
- 若先更新本地数据,再通知B:本地更新成功但通知失败→B数据不一致;
- 若先通知B,再更新本地数据:通知成功但本地更新失败→B数据冗余。
3.数据语义的一致性
不同服务对同一业务概念可能有不同的数据模型(如服务A的“订单状态”与服务B的“订单状态”定义差异),导致同步的数据语义不一致。
4.性能与一致性的平衡
强一致性方案(如分布式事务)会牺牲性能和可用性(需服务间频繁协调);而追求高性能的方案可能导致数据长期不一致。
(2)典型问题
1.双写不一致
服务A和服务B需同时更新关联数据(如A创建订单,B扣减库存),若未通过可靠机制同步,可能出现:
- A订单创建成功,但B库存扣减失败→超卖;
- B库存扣减成功,但A订单创建失败→库存无故减少。
2.数据孤岛与同步延迟
服务C依赖服务D的用户信息,若D的用户信息更新后未及时同步到C,C会使用旧数据处理业务(如用户手机号变更后,C仍发送短信到旧号码)。
3.重复数据与数据污染
因网络重试,服务B多次收到服务A的同一数据变更通知,若B未做幂等处理,可能重复执行操作(如重复扣减库存)。
4.因果关系破坏
服务A先执行“订单创建”,再执行“订单取消”,但两个通知因网络原因倒序到达服务B,B先处理“取消”再处理“创建”,导致数据逻辑错误。
(3)设计原则
1.优先追求最终一致性
微服务中强一致性代价过高(可用性低、性能差),多数场景下“最终一致”即可满足需求(如订单状态最终同步到物流系统)。
2.设计幂等接口
接收端必须支持幂等操作(即多次执行同一操作结果相同),通过唯一标识(如消息ID、业务单号)避免重复处理。
3.异步优先,同步兜底
优先用异步消息(如Kafka、RabbitMQ)分发数据,减少服务间耦合;同步调用仅用于必须实时响应的场景(如查询当前库存)。
4.明确数据所有权
一个数据实体(如订单)应有唯一的“owner服务”(如订单服务),其他服务仅存储副本或视图,避免多服务同时修改同一数据。
5.监控与可观测性
对数据分发链路(消息发送、消费、补偿)进行监控,记录关键指标(如消息延迟、失败率),及时发现不一致问题。
二、解决方案
1、双写(容易产生问题)
以下伪代码:
@Transactional
public void updateDbAndSendMsg() {try {// 1、先修改数据库boolean result = dao.update(model);if (result) {// 2、数据库修改 mq.send(model);}}}
通过编码的方式,确实可以一定程度上规避数据不一致的问题。
但是极端场景下,没有重试机制、网络延迟等原因,还是有可能出问题的。
2、事务性发件箱模式(类似本地消息表)
中小规模的企业应用,用基于DB的事务性发件箱来实现异步可靠消息,比较简单。
(1)简介
其核心思想是,将 “消息发送” 与 “本地业务事务” 绑定为一个原子操作:
1、先将消息暂存到本地数据库的 “发件箱表” 中,这一步与本地业务操作在同一个事务内完成(要么都成功,要么都失败);
2、再通过独立的 “消息发送器”(或者定时任务) 从发件箱表中读取消息,发送到消息队列;
3、发送成功后,标记或删除发件箱中的消息,确保消息仅被发送一次。
通过这种方式,保证 “业务操作成功” 与 “消息被记录” 的强一致性,再通过可靠的发送器确保消息最终能到达消息队列。
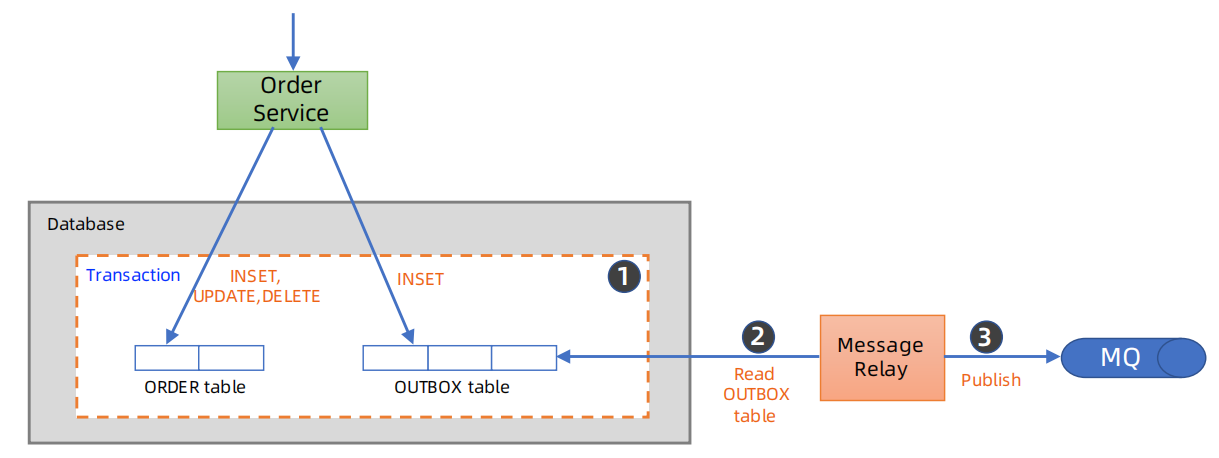
(2)设计发件箱表
在本地数据库中创建专门的发件箱表(如outbox_messages),存储待发送的消息,典型字段包括:
| 字段名 | 作用 | 示例值 |
|---|---|---|
id | 唯一标识(主键) | 123e4567-e89b-12d3-a456-426614174000 |
aggregate_type | 业务聚合根类型(如订单) | “order” |
aggregate_id | 业务聚合根ID(如订单ID) | “ORD-20240822-001” |
event_type | 事件类型(如订单创建) | “order_created” |
payload | 消息内容(JSON格式) | {"orderId":"ORD-xxx", "amount":100} |
status | 消息状态(未发送/已发送/失败) | “PENDING”(未发送) |
created_at | 创建时间 | 2024-08-22 10:00:00 |
sent_at | 发送成功时间 | NULL(未发送时) |
(3)本地事务记录消息
在业务逻辑的本地事务中,完成业务操作后,同步将消息插入发件箱表。例如:
// 伪代码:订单创建事务
@Transactional
public void createOrder(Order order) {// 1. 执行本地业务操作(如保存订单到数据库)orderRepository.save(order);// 2. 生成消息并插入发件箱表(与订单保存同属一个事务)OutboxMessage message = new OutboxMessage(UUID.randomUUID(), "order", order.getId(), "order_created", JSON.toJSONString(order), "PENDING", LocalDateTime.now());outboxRepository.save(message);
}
若订单保存失败(如数据库异常),事务回滚,消息不会被插入发件箱;
若订单保存成功,消息必然被插入发件箱,确保“业务成功→消息记录成功”的原子性。
(4)消息发送器:发送并确认
启动独立的“消息发送器”(可通过定时任务、后台线程或数据库触发器实现),定期从发件箱表读取“未发送”(status = PENDING)的消息,发送到消息队列(如Kafka、RabbitMQ)。
发送流程:
1.读取消息:按created_at升序读取未发送消息(避免消息乱序);
2.发送消息:调用消息队列的发送API,将payload发送到指定主题/队列;
3.确认发送:若发送成功,更新消息状态为“已发送”(status = SENT)并记录sent_at;若失败,可标记为“失败”(status = FAILED),等待重试。
示例伪代码:
// 消息发送器定时任务(每10秒执行一次)
@Scheduled(fixedRate = 10000)
public void sendOutboxMessages() {// 1. 读取未发送的消息List<OutboxMessage> pendingMessages = outboxRepository.findByStatus("PENDING");for (OutboxMessage msg : pendingMessages) {try {// 2. 发送到消息队列messageQueue.send("order-events", msg.getPayload());// 3. 标记为已发送msg.setStatus("SENT");msg.setSentAt(LocalDateTime.now());outboxRepository.save(msg);} catch (Exception e) {// 发送失败,标记为失败(后续可重试)msg.setStatus("FAILED");outboxRepository.save(msg);}}
}
(5)处理异常与重试
发送失败重试:对status = FAILED的消息,可设置重试次数(如最多3次),超过次数后触发告警(人工介入);
发送器崩溃:发送器重启后,通过status = PENDING或FAILED的消息继续处理,不丢失消息;
消息队列崩溃:发送器会因发送失败标记消息为FAILED,待队列恢复后重试。
(6)关键要点
1.消息幂等性:
发送器可能因网络波动重试发送,接收方需通过id(消息唯一标识)处理重复消息(如“先查后处理”或“乐观锁”)。
2.发件箱表清理:
已发送(SENT)的消息可定期清理(如保留7天),避免表数据过大影响查询性能。
3.发送器可靠性:
发送器需保证高可用(如多实例部署),避免单点故障导致消息积压。
4.与事件溯源结合:
若系统采用事件溯源(Event Sourcing)模式,发件箱表可直接复用事件日志(Event Log),无需额外存储。
5.有一定的消息延时
如果使用定时任务,需要接受一定时间的消息延时。
3、变更数据捕获(Change Data Capture,CDC)
(1)简介
变更数据捕获(Change Data Capture,CDC) 是一种核心的数据同步与分发技术,其本质是实时捕获数据库中数据的增删改(INSERT/DELETE/UPDATE)变更,并将这些变更以结构化格式传递给下游系统,无需侵入业务代码即可实现数据的实时流转。
这里建议使用Canal、FlinkCDC。
Flink从入门到实践(三):数据实时采集 - Flink MySQL CDC
docker使用canal订阅mysql的binlog,springboot使用canal订阅mysql的binlog
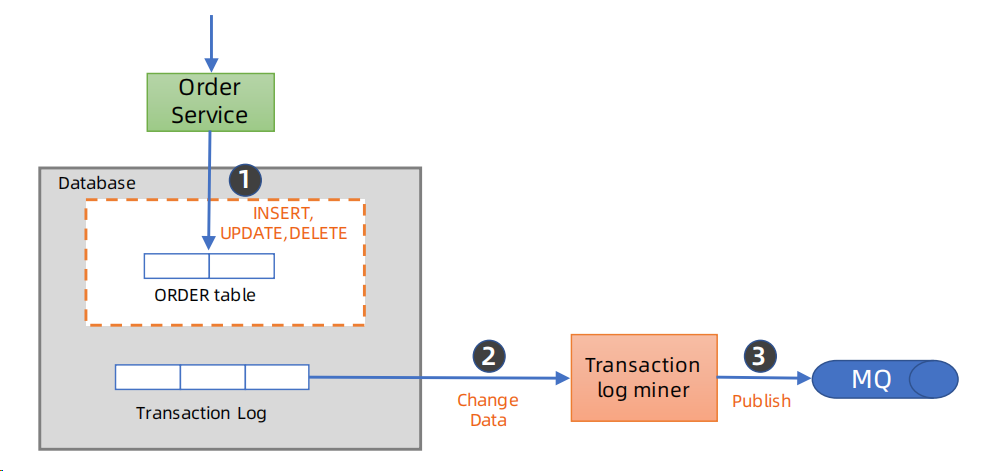
(2)与发件箱模式的对比
| Transaction Outbox | CDC | |
|---|---|---|
| 复杂性 | 相对简单 | 复杂(高可用/监控) |
| Pulling延迟和开销 | 近实时,有一定性能开销 | 较实时,性能开销小 |
| 应用侵入性 | 有 | 无 |
| 适用场合 | 早期/中小规模 | 中大规模,有独立框架团队治理维护 |
参考资料
杨波老师《分布式系统案例课》