大数据MapReduce架构:分布式计算的经典范式

大数据MapReduce架构:分布式计算的经典范式
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。 ✨
每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径; 🔍
每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
- 大数据MapReduce架构:分布式计算的经典范式
- 探索MapReduce的星际旅程
- MapReduce的核心思想
- Map与Reduce:宇宙的两大基本力
- 一个简单的WordCount示例
- MapReduce架构详解
- MapReduce工作流程详解
- Shuffle过程详解
- MapReduce应用场景分析
- 典型应用场景
- 行业应用分布
- MapReduce与现代大数据框架对比
- 性能对比分析
- MapReduce的优势与局限
- 优势
- 局限
- MapReduce最佳实践
- 性能优化技巧
- MapReduce的演进与未来
- 星际编码之旅的终点:我的MapReduce实践心得
- 参考链接
- 关键词标签
探索MapReduce的星际旅程
作为一名数据工程师,我一直在寻找处理海量数据的最佳方法。还记得我第一次接触MapReduce时的震撼,那种简单而强大的编程模型彻底改变了我对大数据处理的认知。在过去几年中,我深入研究了MapReduce架构,从最初的概念理解到实际项目应用,再到与新兴框架的对比分析。
MapReduce就像宇宙中的引力法则,看似简单却能驾驭复杂的数据星系。它将复杂的大数据处理任务分解为Map和Reduce两个基本操作,使得即使是普通开发者也能轻松驾驭分布式计算的力量。在我看来,理解MapReduce不仅是掌握一项技术,更是领悟分布式计算的哲学思想。
在这篇文章中,我将带你深入探索MapReduce的核心原理、架构设计、工作流程以及实际应用场景。我们会通过生动的图表、代码示例和实际案例,揭示这一经典框架的魅力所在。同时,我也会分享我在实际项目中积累的经验和最佳实践,帮助你避开常见陷阱,充分发挥MapReduce的潜力。
无论你是大数据领域的新手,还是寻求深入理解的资深工程师,这篇文章都将为你提供全面而深入的MapReduce知识,让我们一起踏上这段星际编码之旅吧!
MapReduce的核心思想
MapReduce是由Google在2004年提出的一种编程模型,旨在解决大规模数据集的并行计算问题。其核心思想可以概括为"分而治之":将复杂的大数据处理任务分解为两个主要阶段。
Map与Reduce:宇宙的两大基本力
- Map阶段:将输入数据集分割成独立的数据块,交由Map函数处理,产生中间结果(键值对)
- Reduce阶段:对Map阶段产生的所有中间结果进行合并和处理,生成最终输出
这种简单而强大的模型使开发者能够专注于业务逻辑,而将分布式计算的复杂性交给框架处理。
一个简单的WordCount示例
让我们通过经典的单词计数示例来理解MapReduce的工作原理:
// Map函数:将文本分割为单词,每个单词输出<单词, 1>的键值对
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {// 将输入文本分割为单词StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());// 输出<单词, 1>的键值对context.write(word, one); // 核心输出操作}}
}// Reduce函数:汇总每个单词的计数
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;// 累加同一个单词的所有计数for (IntWritable val : values) {sum += val.get(); // 累加计数}result.set(sum);// 输出<单词, 总计数>的键值对context.write(key, result); // 最终结果输出}
}
在这个例子中,Map函数将文本分割为单词并输出<单词, 1>的键值对,而Reduce函数则汇总每个单词的计数,输出<单词, 总计数>的结果。这个简单的例子展示了MapReduce编程模型的核心思想。
MapReduce架构详解
图1:MapReduce架构流程图 - 展示了MapReduce框架的核心组件及其交互流程
MapReduce框架(以Hadoop MapReduce为例)由以下核心组件构成:
- Client:提交MapReduce作业
- JobTracker/ResourceManager:作业调度和监控
- TaskTracker/NodeManager:执行具体的Map和Reduce任务
- HDFS/分布式存储:提供数据存储
MapReduce工作流程详解
图2:MapReduce执行时序图 - 展示了MapReduce作业从提交到完成的完整流程
- 作业提交:客户端提交作业到JobTracker
- 作业初始化:JobTracker初始化作业,创建作业执行计划
- 任务分配:JobTracker将Map和Reduce任务分配给TaskTracker
- Map执行:TaskTracker执行Map任务,处理数据分片,生成中间结果
- Shuffle和Sort:将Map输出按Key分组,排序,并传输到执行Reduce任务的节点
- Reduce执行:执行Reduce任务,处理中间结果,生成最终输出
- 结果存储:将结果写入HDFS或其他存储系统
Shuffle过程详解
Shuffle是MapReduce中最复杂也是最关键的环节,它连接Map和Reduce阶段,负责将Map输出的中间结果传输给Reduce任务。
// Map端Shuffle过程
public class MapOutputBuffer<K, V> {// Map输出被分区private int partitionFunction(K key) {return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;}// Map输出被排序private void sortAndSpill() {// 根据键排序IndexedSorter sorter = new QuickSort();sorter.sort(comparator, 0, count);// 写入磁盘FSDataOutputStream out = rfs.create(filename);// ...写入排序后的数据}
}// Reduce端Shuffle过程
public class Fetcher<K, V> {// 从Map任务获取中间结果public void fetchOutputs() {// 从多个Map任务获取属于此Reduce任务的数据// ...}// 合并多个Map输出private void mergeSort() {// 合并多个排序好的Map输出// ...}
}
Shuffle过程包含分区、排序、合并等多个步骤,是MapReduce性能优化的关键点。
MapReduce应用场景分析
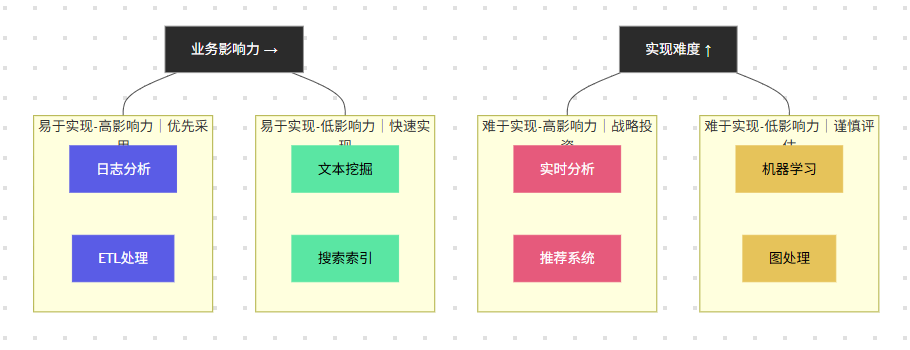
图3:MapReduce应用场景象限图 - 展示不同应用场景在实现难度和业务影响力维度的分布
从上图可以看出,MapReduce在ETL处理和日志分析等场景中具有高影响力且相对容易实现,而在实时分析等场景中虽有高影响力但实现难度较大。
从上图可以看出,MapReduce在ETL处理和日志分析等场景中具有高影响力且相对容易实现,而在实时分析等场景中虽有高影响力但实现难度较大。
典型应用场景
- 日志分析:处理大量服务器日志,提取有价值的信息
- ETL处理:数据抽取、转换和加载,为数据仓库准备数据
- 文本挖掘:处理大规模文本数据,进行情感分析、关键词提取等
- 搜索索引:构建搜索引擎的倒排索引
- 推荐系统:处理用户行为数据,生成推荐模型
行业应用分布
图4:MapReduce行业应用分布饼图 - 展示MapReduce技术在不同行业的应用占比
MapReduce与现代大数据框架对比
随着大数据技术的发展,出现了许多新的处理框架,如Spark、Flink等。下面我们对比一下MapReduce与这些现代框架的异同。
| 特性 | MapReduce | Spark | Flink | Storm | Presto |
|---|---|---|---|---|---|
| 处理模型 | 批处理 | 批处理+微批处理 | 批处理+流处理 | 流处理 | 交互式查询 |
| 性能 | 中等 | 高(内存计算) | 高(流式) | 高(实时) | 高(内存) |
| 延迟 | 高 | 中等 | 低 | 极低 | 低 |
| 容错机制 | 重新执行任务 | Lineage+检查点 | 检查点+保存点 | 消息确认 | 查询重启 |
| 编程难度 | 中等 | 低 | 中等 | 中等 | 低(SQL) |
| 内存使用 | 低 | 高 | 中等 | 中等 | 高 |
| 适用场景 | 批量ETL | 通用分析 | 流处理+批处理 | 实时分析 | 交互式查询 |
性能对比分析
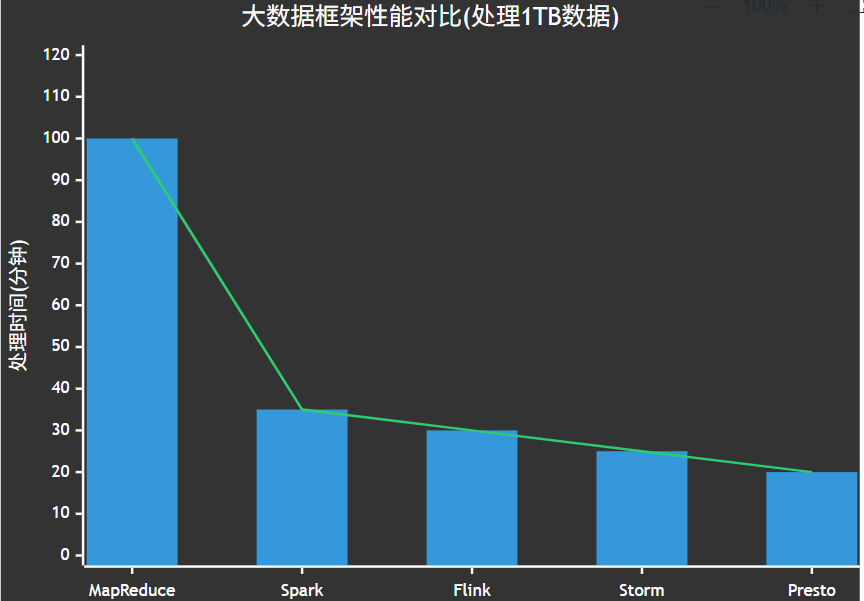
图5:大数据框架性能对比XY图 - 展示不同框架处理相同数据量的时间对比
从图表可以看出,MapReduce在处理相同数据量时需要的时间明显多于其他现代框架,这主要是因为其基于磁盘的处理模式,而Spark、Flink等框架采用了内存计算模型,大大提高了处理效率。
MapReduce的优势与局限
优势
- 高可扩展性:可以轻松扩展到数千节点
- 高容错性:任务失败自动重试,数据多副本存储
- 编程模型简单:只需实现Map和Reduce函数
- 适合批处理:对大规模数据批处理效果好
局限
- 高延迟:不适合实时或交互式分析
- 迭代计算效率低:每次迭代都需要读写磁盘
- 仅支持批处理:不支持流处理
- 编程模型受限:复杂算法实现困难
MapReduce最佳实践
“MapReduce的真正力量不在于它的性能,而在于它使普通程序员能够利用分布式系统的强大功能,而无需成为分布式系统专家。”
— Jeffrey Dean,Google高级研究员,MapReduce论文作者
性能优化技巧
- 合理设计键值对:键的设计直接影响数据分布和处理效率
// 不良实践:使用时间戳作为键,可能导致数据倾斜
public void map(Object key, Text value, Context context) {// 使用时间戳作为键context.write(new Text(System.currentTimeMillis()), value);
}// 良好实践:使用复合键或哈希键,确保均匀分布
public void map(Object key, Text value, Context context) {// 使用哈希值作为键的一部分,确保分布均匀int partition = Math.abs(value.hashCode() % numPartitions);context.write(new Text(partition + "_" + originalKey), value);
}
- 使用Combiner减少数据传输:在Map端进行局部聚合,减少网络传输
// 配置Combiner,与Reducer使用相同的类
job.setCombinerClass(IntSumReducer.class);// Combiner示例(与Reducer相同)
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}
}
- 避免数据倾斜:确保键的分布均匀,避免热点
// 处理数据倾斜的策略:键加盐
public void map(Object key, Text value, Context context) {// 对热点键添加随机前缀if (isHotKey(key)) {int salt = new Random().nextInt(10); // 0-9的随机数context.write(new Text(salt + "_" + key), value);} else {context.write(new Text(key), value);}
}// 在Reduce阶段去除盐值
public void reduce(Text key, Iterable<IntWritable> values, Context context) {// 提取原始键(去除盐值)String originalKey = key.toString().substring(key.toString().indexOf("_") + 1);// 处理逻辑...
}
- 合理设置任务数:根据集群规模和数据量调整Map和Reduce任务数
// 设置Map任务数(通过控制输入分片大小)
job.getConfiguration().setLong("mapreduce.input.fileinputformat.split.minsize", 128 * 1024 * 1024); // 128MB// 设置Reduce任务数
job.setNumReduceTasks(10); // 根据集群规模和数据量设置合适的值
MapReduce的演进与未来

图6:大数据处理框架演进时间线 - 展示大数据技术从MapReduce到现代框架的发展历程
这条时间线展示了大数据处理技术从MapReduce开始的演进历程,反映了从批处理到流处理、从单一框架到生态系统的发展趋势,以及与AI技术的深度融合。
虽然MapReduce已不再是大数据处理的唯一选择,但它的思想和原则仍然影响着现代大数据框架的设计。随着Spark、Flink等新一代框架的兴起,MapReduce的应用场景逐渐聚焦于特定的批处理任务。
星际编码之旅的终点:我的MapReduce实践心得
作为一名数据工程师,我在多个项目中应用了MapReduce技术,从最初的摸索到如今的熟练应用,这段旅程让我收获颇丰。MapReduce就像是大数据处理的"Hello World",它不仅是一种技术,更是一种思维方式。
在我看来,MapReduce最大的魅力在于它的简单与强大的平衡。通过简单的Map和Reduce两个操作,我们就能构建出复杂的数据处理流程。这种"分而治之"的思想不仅适用于MapReduce,也是解决各种复杂问题的通用方法。
在实际项目中,我发现MapReduce虽然在性能上不如新兴框架,但在稳定性和可靠性方面仍有其独特优势。特别是在处理超大规模数据时,MapReduce的容错机制能够确保作业的可靠完成。我曾经处理过一个包含数十亿条记录的日志分析任务,尽管过程耗时较长,但MapReduce框架的稳定性让我能够安心等待结果,而不必担心中途失败。
当然,随着技术的发展,我们也需要与时俱进。在新项目中,我已经开始更多地使用Spark和Flink等现代框架,它们在性能和灵活性方面确实提供了更好的体验。但是,理解MapReduce的原理和思想,对于掌握这些新框架仍然至关重要。
如果你正在学习大数据技术,我强烈建议你从MapReduce开始,理解其核心思想和工作原理,这将为你后续学习更复杂的框架奠定坚实基础。就像我们需要先学会走路,才能跑步一样,MapReduce是你大数据之旅的第一步,也是最重要的一步。
让我们在代码的宇宙中继续探索,用技术的力量解决更多实际问题,创造更大的价值!
🌟 我是 励志成为糕手 ,感谢你与我共度这段技术时光!
✨ 如果这篇文章为你带来了启发:
✅ 【收藏】关键知识点,打造你的技术武器库
💡【评论】留下思考轨迹,与同行者碰撞智慧火花
🚀 【关注】持续获取前沿技术解析与实战干货
🌌 技术探索永无止境,让我们继续在代码的宇宙中:
• 用优雅的算法绘制星图
• 以严谨的逻辑搭建桥梁
• 让创新的思维照亮前路
📡 保持连接,我们下次太空见!
参考链接
- MapReduce: Simplified Data Processing on Large Clusters
- Apache Hadoop Official Documentation
- Understanding the MapReduce Paradigm
- Hadoop MapReduce vs. Apache Spark
- Evolution of Big Data Processing Frameworks
关键词标签
#MapReduce #Hadoop #分布式计算 #大数据处理 #批处理