【OLAP】trino安装和基本使用

目录
一、概述
1.1Trino不是什么
1.2Trino是什么
二、Trino特点
三、Trino架构
3.1架构和服务节点
3.2Trino数据模型
四、Trino安装部署
4.1配置JDK
4.2单机版(Coordinator和Worker同进程)
4.2.1启动服务
4.2.2下载客户端
五、配置HTTPS(coordinator)
5.1生成证书
5.2设置密码
5.3配置 kerberos认证
六、新增Worker
七、Hive连接器
7.1无kerberos的hive
7.2带kerberos的hive
7.3 访问hivecatalog异常
一、概述
Presto是Facebook开源的MPP(Massively Parallel Processing:大规模并行处理)架构的OLAP(on-line transaction processing:联机分析处理),完全基于内存的并⾏计算,可针对不同数据源,执行大容量数据集的一款分布式SQL交互式查询引擎。 它是为了解决Hive的MapReduce模型太慢以及不能通过BI或Dashboards直接展现HDFS数据等问题。
但是Presto目前有两大分支:PrestoDB(背靠Facebook)和PrestoSQL现在改名为Trino(Presto的创始团队),虽然PrestoDB背靠Facebook,但是社区活跃度和使用群体还是远不如Trino。所以这里以Trino为主展开讲解。
PrestoDB官方文档:https://prestodb.io/docs/current/
Trino官方文档:Trino documentation — Trino 476 Documentation
Trino 是一个运行速度极快的查询引擎,专为大数据分析设计,支持快速分布式 SQL 查询,帮助您探索数据宇宙。
1.1Trino不是什么
由于社区中的许多成员都将Trino称为数据库,因此首先定义一下Trino不是什么。不要误以为Trino理解SQL就意味着它具备标准数据库的功能。Trino不是通用关系型数据库。它不是MySQL、PostgreSQL或Oracle等数据库的替代品。Trino并非为处理在线事务处理(OLTP)而设计。对于许多其他为数据仓库或分析而设计和优化的数据库来说,也是如此。
1.2Trino是什么
Trino是一款旨在通过分布式高效查询海量数据的工具。如果你处理的是TB级或PB级的数据,你很可能正在使用与Hadoop和HDFS交互的工具。Trino被设计为使用MapReduce作业管道查询HDFS的工具(如Hive或Pig)的替代方案,但Trino并不局限于访问HDFS。Trino可以并且已经被扩展,以操作不同类型的数据源,包括传统的关系数据库以及其他数据源,如Oracle。Trino旨在处理数据仓库和分析:数据分析、聚合大量数据并生成报告。这些工作负载通常被归类为联机分析处理(OLAP)。
二、Trino特点
Trino是基于java开发的,对于大部分开发者和使用者而言,Trino容易学习并对特定的场景进行二次开发和性能优化等。多数据源、支持SQL、扩展性强、高性能,流水线模式。
- 多数据源:目前版本支持20多种数据源,几乎能覆盖所有常见情况,Elasticsearch 、Hive 、phoenix 、Kafka、Iceberg 、Local File、clickhouse 、MongoDB 、MySQL 、Redis等等;
- 支持SQL:完成支持ANSI SQL,提供SQL shell;
- 扩展性:支持开发自己的特定数据源的connector;
- 高性能:Trino基于内存计算,在绝大多数情况下,Trino的查询性能是hive的10倍以上,完全能实现交互式,实时查询;
- 流水线:Trino是基于PipeLine设计的,在进行大量设计处理过程中,终端不需要等待所有的数据计算完毕之后才能看到结果,计算一部分就可以看部分结果。
三、Trino架构
3.1架构和服务节点
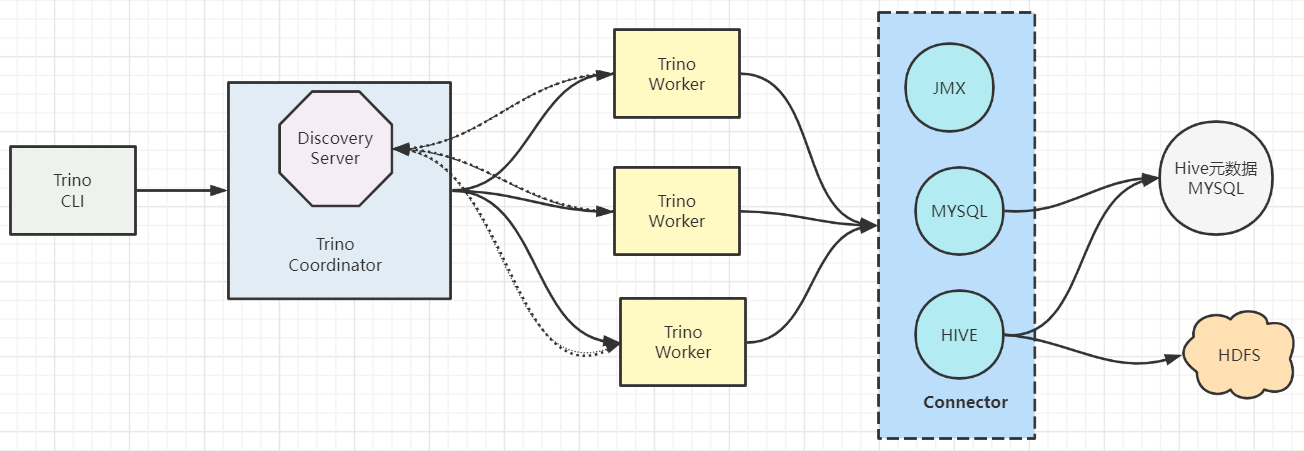
- Trino查询引擎是一个Master-Slave的架构,有两种进程
Coordinator服务进程和worker服务进程组成。细分的话还有一个Discovery Server节点,Discovery Server通常内嵌于Coordinator节点中。 Coordinator主要作用是接收查询请求,解析查询语句,生成查询执行计划,任务调度和worker管理。Worker服务进程执行被分解的查询执行任务:taskWorker节点启动完成后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。- 如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Trino提供Hive元信息,Worker节点与HDFS交互读取数据。
3.2Trino数据模型
Trino就是通过Connector来访问不同的数据源的,相当于访问不同数据源的驱动程序,每种connector都实现了Trino的标准SPI接口,因此只要实现了标准SPI接口就可以制定特殊的Connector来访问数据源。
Trino采取三层表结构:
- Catalog
Trino中Catalog类似于mysql中的一个数据库实例,Schema类似于mysql当中的一个database。如用Trino去连接一个hive中的一个库
- Schema
Trino中的schema就相当于mysql中的一个具体的database。
- Table
Trino中的table和mysql中table含义一样
trino --server ip:port --catalog hive --schema xxx 这样就可以访问hive的中的xxx库。四、Trino安装部署
官方安装文档:Deploying Trino — Trino 476 Documentation
4.1配置JDK
将JDK放在trino目录下面 ,我直接 修改了launcher启动脚本
4.2单机版(Coordinator和Worker同进程)
下载 trino
https://repo1.maven.org/maven2/io/trino/trino-server/367/
# 解压后的路径
/opt/trino-367# 创建配置目录
mkdir etc dataetc目录下的配置文件
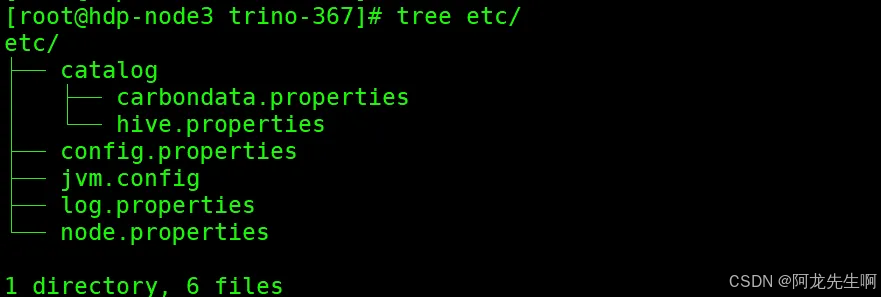 Config properties
Config properties
cat << EOF > etc/config.properties
# 设置该节点为coordinator节点
coordinator=true
# 指定HTTP服务器的端口。Trino使用HTTP进行内部和外部web的所有通信。
http-server.http.port=8086
# 查询可以在任何一台机器上使用的最大用户内存。【注意】也是不能配置超过jvm配置的最大堆栈内存大小
query.max-memory-per-node=2GB
# 查询可以使用的最大分布式内存。【注意】不能配置超过jvm配置的最大堆栈内存大小
query.max-memory=4GB
# hdp-node3也可以是IP
discovery.uri=http://hdp-node3:8086
# 允许在协调器上调度工作,也就是coordinator节点又充当worker节点用
node-scheduler.include-coordinator=true
EOF
node properties
cat << EOF > etc/node.properties
# 环境的名字。集群中所有的Trino节点必须具有相同的环境名称。
node.environment=production
# 此Trino安装的唯一标识符。这对于每个节点都必须是唯一的。可以填写md5值
node.id=trino-worker
# 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。
node.data-dir=/opt/trino-367/data
EOF
Log properties
cat << EOF > etc/log.properties
# 设置日志级别,有四个级别:DEBUG, INFO, WARN and ERROR
io.trino=INFO
EOFJVM config
cat << EOF > etc/jvm.config
-server
-Xmx6G
-XX:-UseBiasedLocking
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
EOF4.2.1启动服务
cd /opt/trino-367
./bin/launcher start
4.2.2下载客户端
下载客户端
cd /opt/trino-367
wget https://repo1.maven.org/maven2/io/trino/trino-cli/367/trino-cli-367.jar
mv trino-cli-367.jar trino-cli.jar
chmod +x trino-cli.jar# 连接测试
[root@hdp-node3 trino-367]# ./bin/trino-cli.jar --server hdp-node3:8086
trino> select * from hive.hive_test.employee_txn;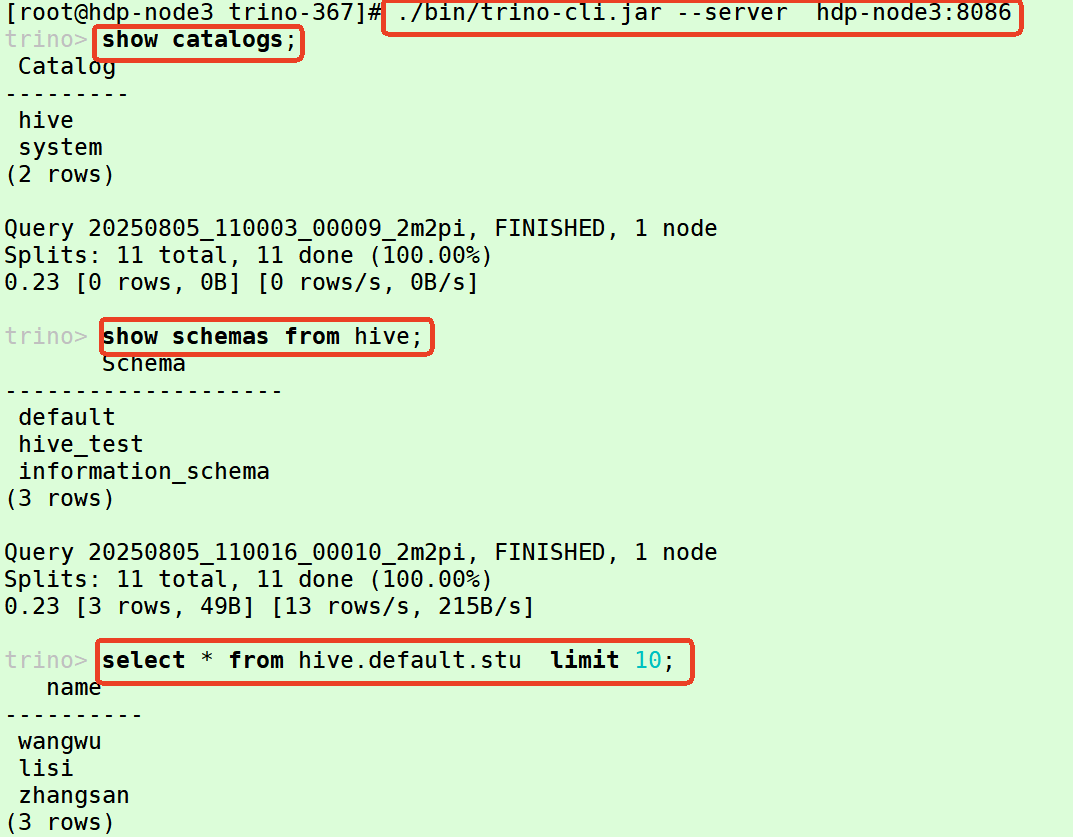
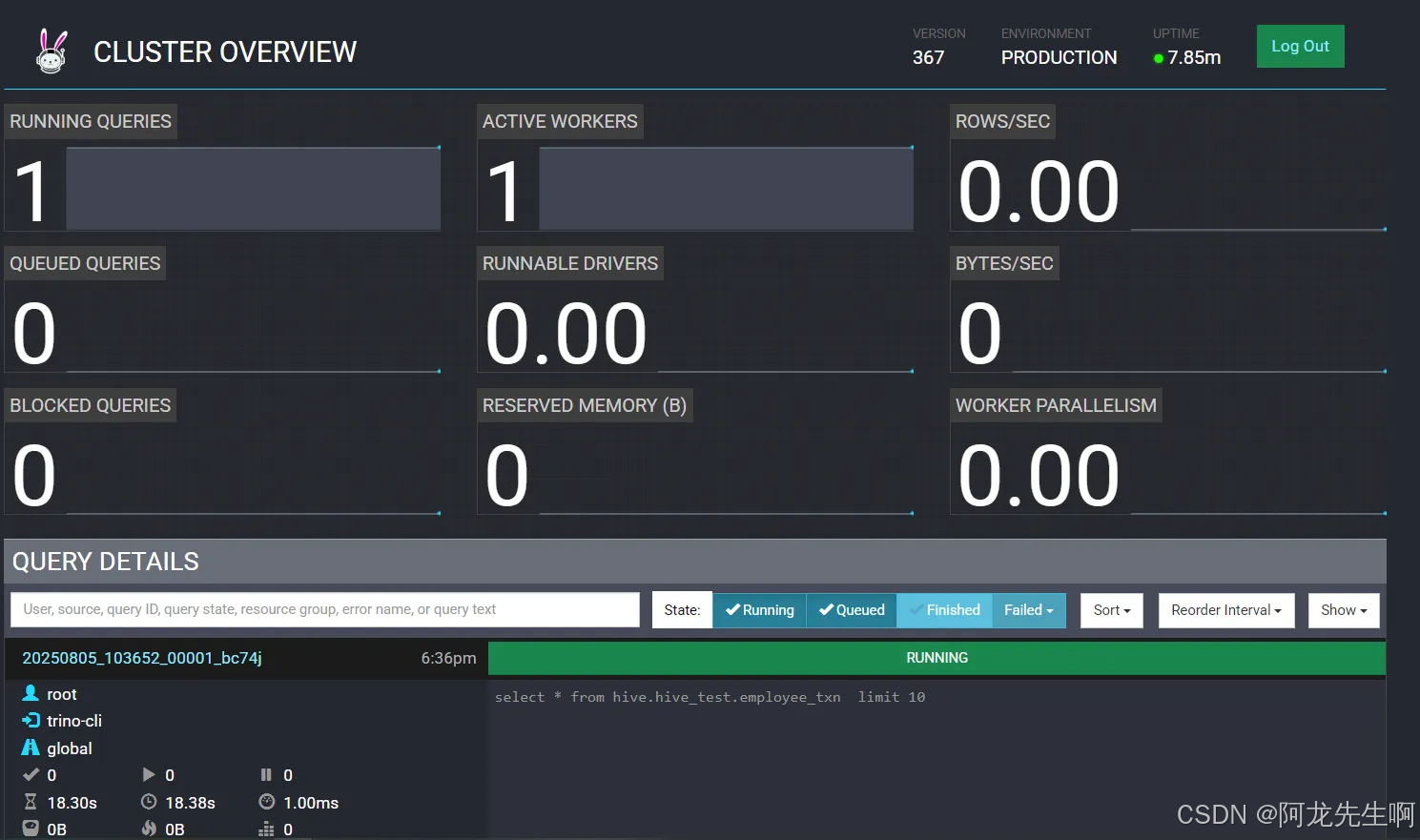
登录web查看任务http://hdp-node3:8086/ui/login.html 账号随便/密码为空
五、配置HTTPS(coordinator)
【注意】要使用trino的权限控制,从官方文档上看,需要先开启https,因此一定需要证书的。
5.1生成证书
cd /opt/trino-367
mkdir tls && cd tls
# 生成 CA 证书私钥
openssl genrsa -out trino.key 4096
# 生成 CA 证书
openssl req -x509 -new -nodes -sha512 -days 3650 \-subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=mytrino.com" \-key trino.key \-out trino.cert# 合并
cat trino.key trino.cert > trino.pem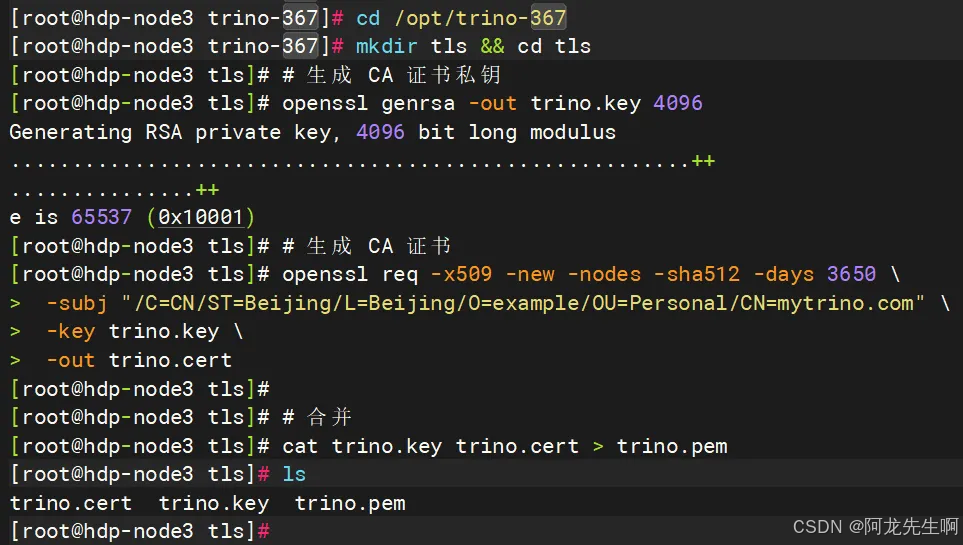
在etc/config.properties添加如下配置:
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/opt/trino-367/tls/trino.pem
# 节点之间不需要使用https通信,在内网部署无需,外网需打开,默认就是false
internal-communication.https.required=falseweb UI:https://hdp-node3:8443/ ,账号 :admin/123456
5.2设置密码
【注意】要使用trino的权限控制,从官方文档上看,需要开启https,因此一定需要证书的。
# etc/config.properties增加如下配置:
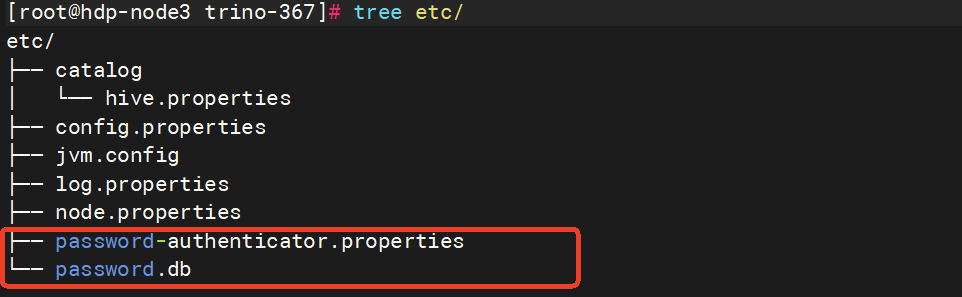
http-server.authentication.type=PASSWORD创建配置etc/password-authenticator.properties,此处可以配置使用LDAP或密码文件认证,这里测试我们先采用密码文件认证。
password-authenticator.name=file
file.password-file=/opt/trino-367/etc/password.dbetc/password.db内容如下:
admin:$2y$10$YG12RuoTiJjTzXFM.UgRy.AP.c2Me9KaKcYe6ufsy.ztpFRehnpE2password.db用户密码文件,一行就是一个用户名密码,用户密码用 : 隔开,比如我定义了一个admin/123456的用户。在使用bcrypt加密的时候,生成的密码可能是$2a$开头的,而根据trino文档内定义的password规范是需要$2y$开头的,这里需要注意。
在线Bcrypt密码生成工具: 在线Bcrypt密码生成工具-Bejson.com
重启
客户端访问输入密码
./bin/trino-cli.jar --server https://hdp-node3:8443 --user=admin --password --insecure 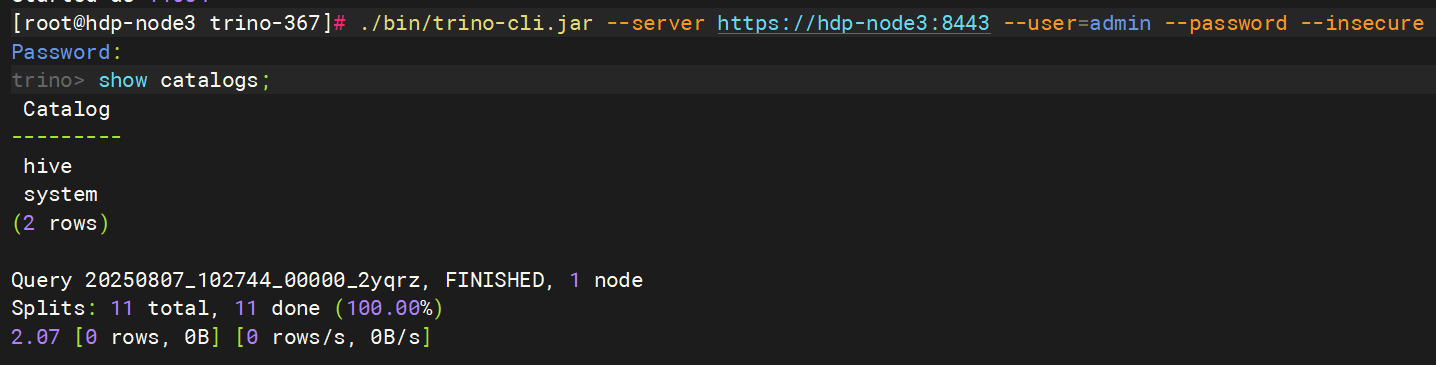
5.3配置 kerberos认证
官方文档:Kerberos authentication — Trino 476 Documentation
【注意】使用Kerberos认证时,访问Trino协调器必须通过TLS和HTTPS。
kadmin
addprinc -randkey trino@WINNER.COM
addprinc -randkey trino/hdp-node3@WINNER.COM
ktadd -k /etc/security/keytabs/trino.service.keytab trino@WINNER.COM
ktadd -k /etc/security/keytabs/trino.service.keytab trino/hdp-node3@WINNER.COM
config.properties 完整配置如下:
# 设置该节点为coordinator节点
coordinator=true
# 指定HTTP服务器的端口。Trino使用HTTP进行内部和外部web的所有通信。
http-server.http.port=8086
# 查询可以在任何一台机器上使用的最大用户内存。【注意】也是不能配置超过jvm配置的最大堆栈内存大小
query.max-memory-per-node=2GB
# 查询可以使用的最大分布式内存。【注意】不能配置超过jvm配置的最大堆栈内存大小
query.max-memory=4GB
# hdp-node3也可以是IP
discovery.uri=http://hdp-node3:8086
# 允许在协调器上调度工作,也就是coordinator节点又充当worker节点用
node-scheduler.include-coordinator=true
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/opt/trino-367/tls/trino.keystore
http-server.https.keystore.key=password
internal-communication.shared-secret=password
http-server.process-forwarded=true#Kerberos 通常对 DNS 名称敏感。 将此属性设置为使用 FQDN 可确保正确操作和使用有效的 DNS 主机名。
node.internal-address-source=FQDN
# 多种认证方式用逗号分割
http-server.authentication.type=KERBEROS,PASSWORD
http-server.authentication.krb5.service-name=trino
http-server.authentication.krb5.principal-hostname=hdp-node3
http-server.authentication.krb5.keytab=/etc/security/keytabs/trino.service.keytab
http.authentication.krb5.config=/etc/krb5.conf
http-server.https.secure-random-algorithm=SHA1PRNG六、新增Worker
直接将trino-367 包拷贝到另一台服务器上,修改如下配置
node.properties
[root@hdp-node2 trino-367]# cat etc/node.properties
# 环境的名字。集群中所有的Trino节点必须具有相同的环境名称。
node.environment=production
# 此Trino安装的唯一标识符。这对于每个节点都必须是唯一的。可以填写md5值 -- 修改
node.id=trino-worker02
# 数据目录的位置(文件系统路径)。Trino在这里存储日志和其他数据。
node.data-dir=/opt/trino-367/data
config.properties
# 设置为false -- 修改
coordinator=false
# 指定HTTP服务器的端口。Trino使用HTTP进行内部和外部web的所有通信。
http-server.http.port=8086
# 查询可以在任何一台机器上使用的最大用户内存。【注意】也是不能配置超过jvm配置的最大堆栈内存大小
query.max-memory-per-node=2GB
# 查询可以使用的最大分布式内存。【注意】不能配置超过jvm配置的最大堆栈内存大小
query.max-memory=4GB
# hdp-node3也可以是IP
discovery.uri=http://hdp-node3:8086
# 允许在协调器上调度工作,也就是coordinator节点又充当worker节点用
node-scheduler.include-coordinator=true
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/opt/trino-367/tls/trino.keystore
http-server.https.keystore.key=password
internal-communication.shared-secret=password
http-server.process-forwarded=true#Kerberos 通常对 DNS 名称敏感。 将此属性设置为使用 FQDN 可确保正确操作和使用有效的 DNS 主机名。
node.internal-address-source=FQDNhttp-server.authentication.type=KERBEROS,PASSWORD
http-server.authentication.krb5.service-name=trino
http-server.authentication.krb5.principal-hostname=hdp-node3
http-server.authentication.krb5.keytab=/etc/security/keytabs/trino.service.keytab
http.authentication.krb5.config=/etc/krb5.conf
http-server.https.secure-random-algorithm=SHA1PRNG
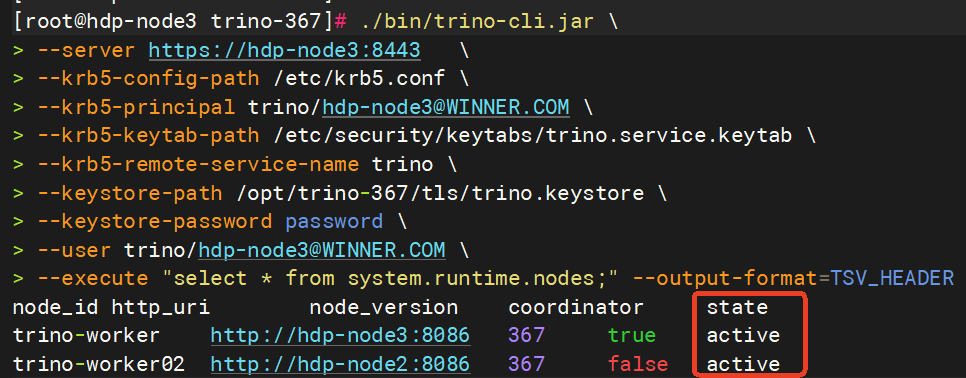
查表验证
./bin/trino-cli.jar \
--server https://hdp-node3:8443 \
--krb5-config-path /etc/krb5.conf \
--krb5-principal trino/hdp-node3@WINNER.COM \
--krb5-keytab-path /etc/security/keytabs/trino.service.keytab \
--krb5-remote-service-name trino \
--keystore-path /opt/trino-367/tls/trino.keystore \
--keystore-password password \
--user trino/hdp-node3@WINNER.COM \
--execute "select * from system.runtime.nodes;" --output-format=TSV_HEADER
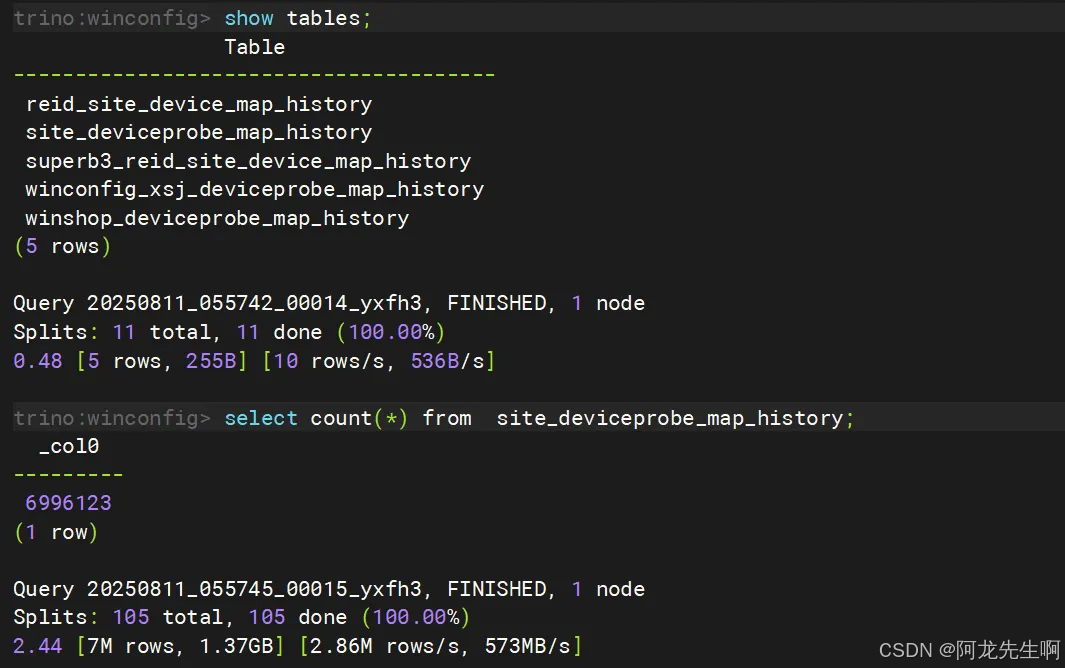
七、Hive连接器
连接器其实就是指定某种数据源,如下给出hive连接器示例。
7.1无kerberos的hive
[root@hdp-node3 trino-367]# cat etc/catalog/hive.properties
connector.name=hive
hive.metastore.uri=thrift://192.168.2.100:9083
hive.config.resources=/opt/datasophon/core-site.xml,/opt/datasophon/hdfs-site.xml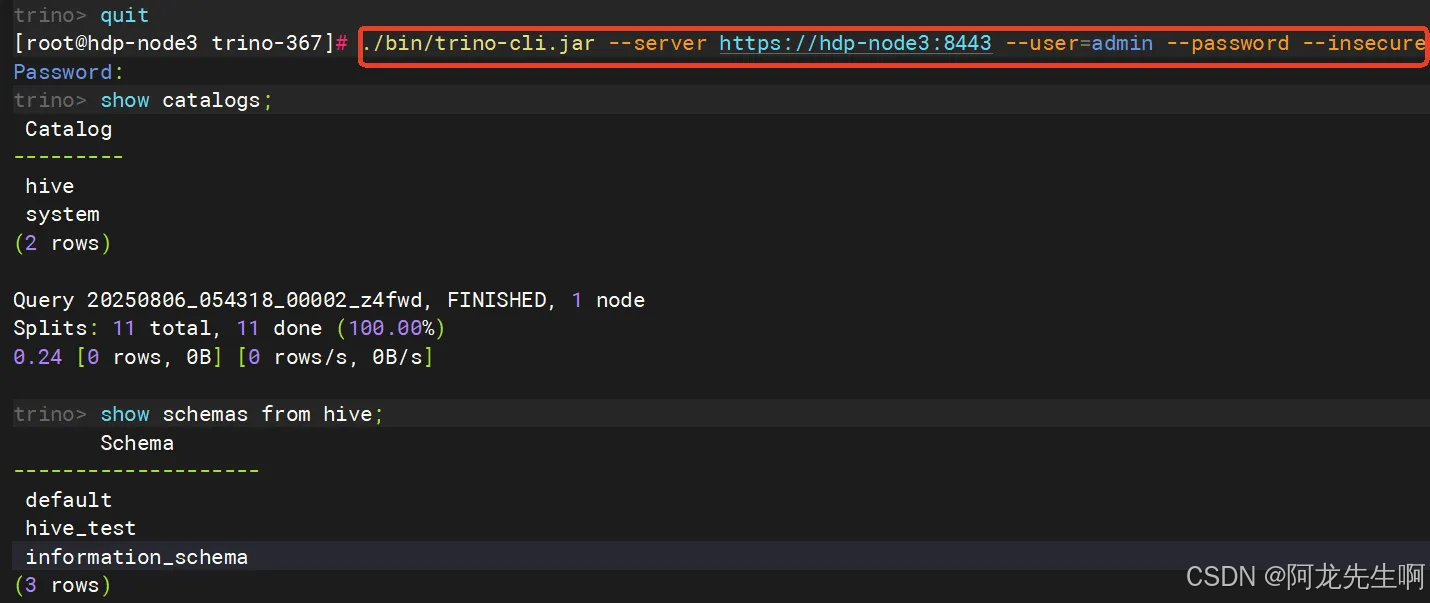
7.2带kerberos的hive
【注意】使用Kerberos认证时,访问Trino协调器必须通过TLS和HTTPS。
# 生成新的密钥库,包含 hdp-node3 作为主机名
keytool -genkeypair \-alias trino \-keyalg RSA \-keysize 2048 \-validity 3650 \-keystore /opt/trino-367/tls/trino.keystore \-storepass password \-keypass password \-dname "CN=hdp-node3, OU=Trino, O=Example, L=Beijing, ST=Beijing, C=CN" \-ext "SAN=dns:hdp-node3,dns:localhost,ip:127.0.0.1"config.properties
# 设置该节点为coordinator节点
coordinator=true
# 指定HTTP服务器的端口。Trino使用HTTP进行内部和外部web的所有通信。
http-server.http.port=8086
# 查询可以在任何一台机器上使用的最大用户内存。【注意】也是不能配置超过jvm配置的最大堆栈内存大小
query.max-memory-per-node=2GB
# 查询可以使用的最大分布式内存。【注意】不能配置超过jvm配置的最大堆栈内存大小
query.max-memory=4GB
# hdp-node3也可以是IP
discovery.uri=http://hdp-node3:8086
# 允许在协调器上调度工作,也就是coordinator节点又充当worker节点用
node-scheduler.include-coordinator=true
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/opt/trino-367/tls/trino.keystore
http-server.https.keystore.key=password
internal-communication.shared-secret=password
http-server.process-forwarded=true#Kerberos 通常对 DNS 名称敏感。 将此属性设置为使用 FQDN 可确保正确操作和使用有效的 DNS 主机名。
node.internal-address-source=FQDNhttp-server.authentication.type=KERBEROS,PASSWORD
http-server.authentication.krb5.service-name=trino
http-server.authentication.krb5.principal-hostname=hdp-node3
http-server.authentication.krb5.keytab=/etc/security/keytabs/trino.service.keytab
http.authentication.krb5.config=/etc/krb5.conf
http-server.https.secure-random-algorithm=SHA1PRNGjvm.config
-server
-Xmx8G
-XX:-UseBiasedLocking
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
-XX:+UnlockDiagnosticVMOptions
-XX:+UseAESCTRIntrinsics
-Dsun.security.krb5.debug=true
-Djava.security.krb5.conf=/etc/krb5.confhive catalog
[root@hdp-node3 trino-367]# cat etc/catalog/hive.properties
connector.name=hive
hive.metastore.uri=thrift://hdp-node2:9083
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/_HOST@WINNER.COM;
hive.metastore.client.principal=trino/hdp-node3@WINNER.COM
hive.metastore.client.keytab=/etc/security/keytabs/trino.service.keytab
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.trino.principal=trino/hdp-node3@WINNER.COM
hive.hdfs.trino.keytab=/etc/security/keytabs/trino.service.keytab
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
hive.hdfs.impersonation.enabled=true
# 是否开启向Hive的外部表写入数据,默认是False
hive.non-managed-table-writes-enabled=true客户端访问
./bin/trino-cli-367-executable.jar \
--server https://hdp-node3:8443 \
--krb5-config-path /etc/krb5.conf \
--krb5-principal trino/hdp-node3@WINNER.COM \
--krb5-keytab-path /etc/security/keytabs/trino.service.keytab \
--krb5-remote-service-name trino \
--keystore-path /opt/trino-367/tls/trino.keystore \
--keystore-password password \
--user trino/hdp-node3@WINNER.COM \
--catalog hive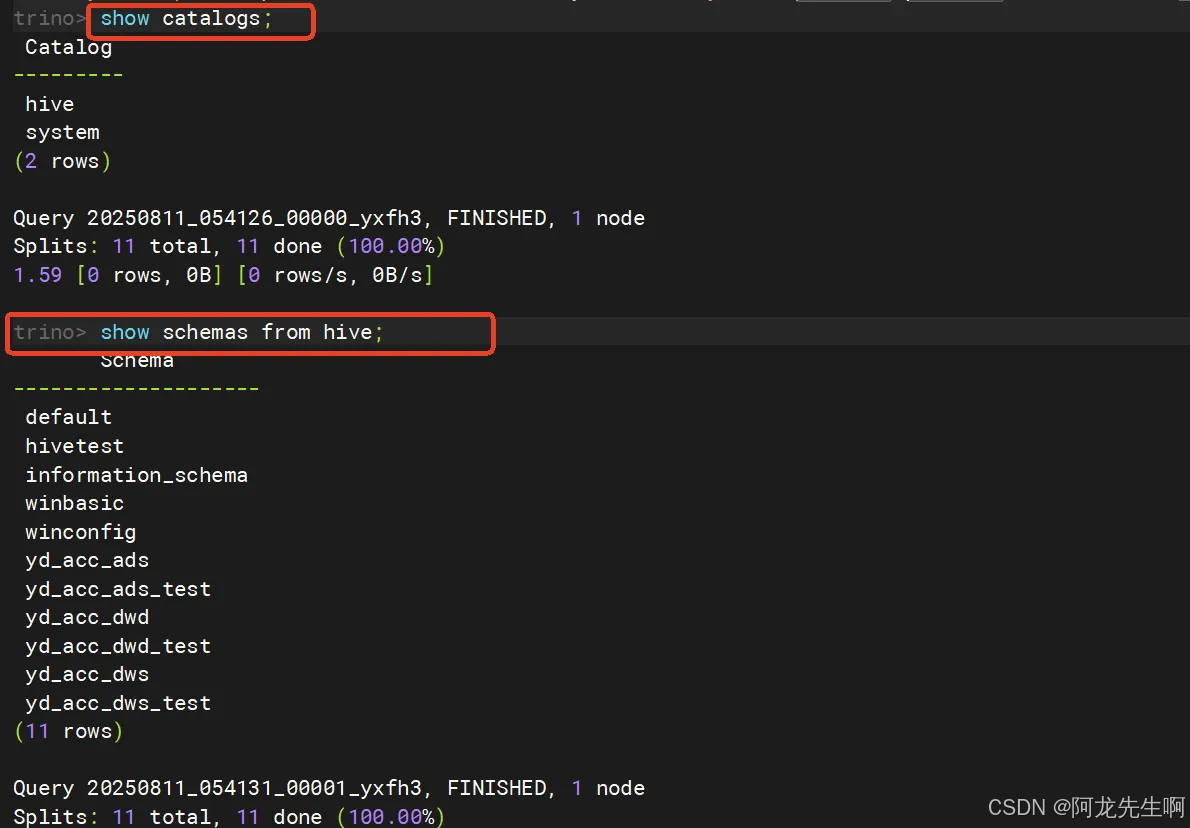
执行查询
7.3 访问hivecatalog异常
2025-08-11T13:34:06.371+0800 ERROR SplitRunner-0-92 io.trino.execution.executor.TaskExecutor Error processing Split 20250811_053355_00000_97364.2.0.0-0 io.trino.connector.informationschema.InformationSchemaSplit@35e48236 (start = 1.6171929350256409E10, wall = 9739 ms, cpu = 0 ms, wait = 2 ms, calls = 1)
com.google.common.util.concurrent.UncheckedExecutionException: java.lang.RuntimeException: javax.security.auth.login.LoginException: Message stream modified (41)at com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2055)at com.google.common.cache.LocalCache.get(LocalCache.java:3966)at com.google.common.cache.LocalCache.getOrLoad(LocalCache.java:3989)at com.google.common.cache.LocalCache$LocalLoadingCache.get(LocalCache.java:4950)at com.google.common.cache.LocalCache$LocalLoadingCache.getUnchecked(LocalCache.java:4956)at io.trino.plugin.hive.metastore.cache.CachingHiveMetastore.get(CachingHiveMetastore.java:261)at io.trino.plugin.hive.metastore.cache.CachingHiveMetastore.getAllDatabases(CachingHiveMetastore.java:295)at io.trino.plugin.hive.HiveMetastoreClosure.getAllDatabases(HiveMetastoreClosure.java:66)at io.trino.plugin.hive.metastore.SemiTransactionalHiveMetastore.getAllDatabases(SemiTransactionalHiveMetastore.java:197)at io.trino.plugin.hive.HiveMetadata.listSchemaNames(HiveMetadata.java:416)at io.trino.plugin.base.classloader.ClassLoaderSafeConnectorMetadata.listSchemaNames(ClassLoaderSafeConnectorMetadata.java:205)at io.trino.metadata.MetadataManager.listSchemaNames(MetadataManager.java:293)at io.trino.metadata.MetadataListing.listSchemas(MetadataListing.java:100)at io.trino.metadata.MetadataListing.listSchemas(MetadataListing.java:95)at io.trino.connector.informationschema.InformationSchemaPageSource.addSchemataRecords(InformationSchemaPageSource.java:316)at io.trino.connector.informationschema.InformationSchemaPageSource.buildPages(InformationSchemaPageSource.java:225)at io.trino.connector.informationschema.InformationSchemaPageSource.getNextPage(InformationSchemaPageSource.java:183)at io.trino.operator.TableScanOperator.getOutput(TableScanOperator.java:311)at io.trino.operator.Driver.processInternal(Driver.java:388)at io.trino.operator.Driver.lambda$processFor$9(Driver.java:292)at io.trino.operator.Driver.tryWithLock(Driver.java:685)at io.trino.operator.Driver.processFor(Driver.java:285)at io.trino.execution.SqlTaskExecution$DriverSplitRunner.processFor(SqlTaskExecution.java:1076)at io.trino.execution.executor.PrioritizedSplitRunner.process(PrioritizedSplitRunner.java:163)at io.trino.execution.executor.TaskExecutor$TaskRunner.run(TaskExecutor.java:488)at io.trino.$gen.Trino_367____20250811_053005_2.run(Unknown Source)at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: java.lang.RuntimeException: javax.security.auth.login.LoginException: Message stream modified (41)修改了 krb5.cof
vim /etc/ krb5.conf删除 krb5.conf 配置文件里的 renew_lifetime = xxx 这行配置即可参考文章
javax.security.auth.login.LoginException: Message stream modified (41)-CSDN博客
Kerberos authentication — Trino 476 Documentation
大数据Hadoop之——基于内存型SQL查询引擎Presto(Presto-Trino环境部署) - 大数据老司机 - 博客园
【大数据】通过 docker-compose 快速部署 Presto(Trino)保姆级教程 - 大数据老司机 - 博客园
【大数据】Presto(Trino)SQL 语法进阶 - 大数据老司机 - 博客园
presto(trino)+kerberos+https - mzjnumber1 - 博客园
Presto/Trino的Hive Connector的使用(内部表、外部表、分区表):
Presto/Trino的Hive Connector的使用(内部表、外部表、分区表)_presto分区表-CSDN博客
HDFS file system support — Trino 476 Documentation
trino 安装(带web ui 与 coordinator 和 worker 与 coordinator 安全通讯)_trino webui-CSDN博客