python-----机器学习中常用的数据预处理
在机器学习项目中,数据预处理是构建高性能模型的基础环节。高质量的数据预处理往往比复杂的算法选择对最终结果的影响更大。本文将全面介绍数据预处理的流程、技术和最佳实践。
为什么需要数据预处理?
现实世界的数据几乎总是"脏"的,常见问题包括:
- 缺失值
- 异常值
- 不一致的格式
- 噪声数据
- 不相关的特征
数据预处理的目标是将原始数据转化为适合机器学习算法的高质量数据集。
2. 数据预处理操作
2.1 数据分割
from sklearn.model_selection import train_test_split# 分离特征和目标变量
X = data.drop('Target', axis=1)
y = data['Target']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) #测试集占数据的20% 随机种子42个2.2处理缺失值:
isnull():
判断是否为空,是则是True不空则是False,将数据sum()即可获得究竟有几个缺失值。
# 检查缺失值
print(data.isnull().sum())# 处理方法
# 1. 删除缺失值
data_clean = data.dropna()# 2. 填充缺失值
data['Age'].fillna(data['Age'].median(), inplace=True) # 数值型
data['Category'].fillna(data['Category'].mode()[0], inplace=True) # 类别型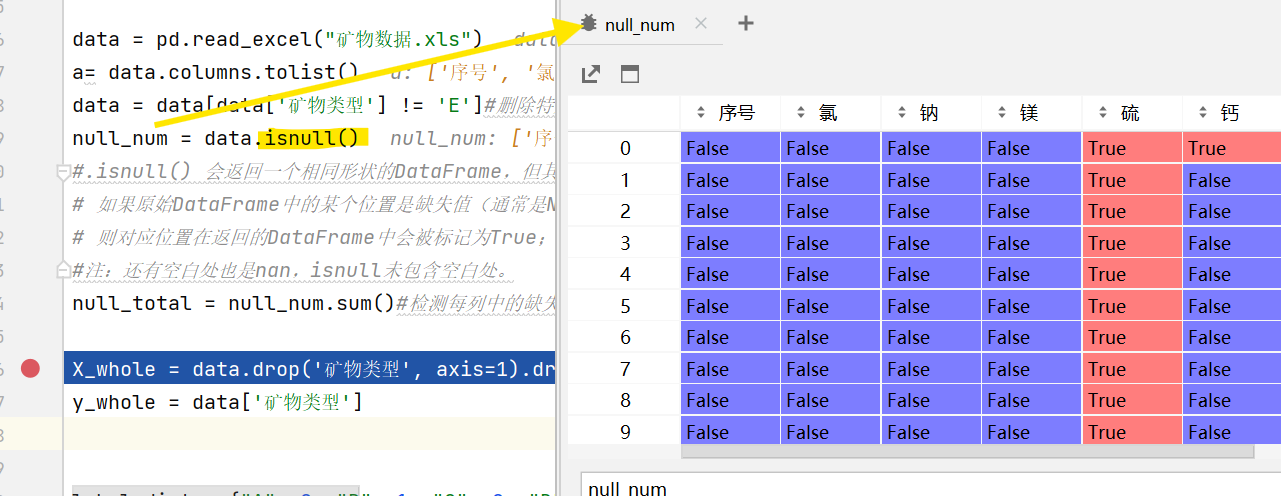
各列空值的个数
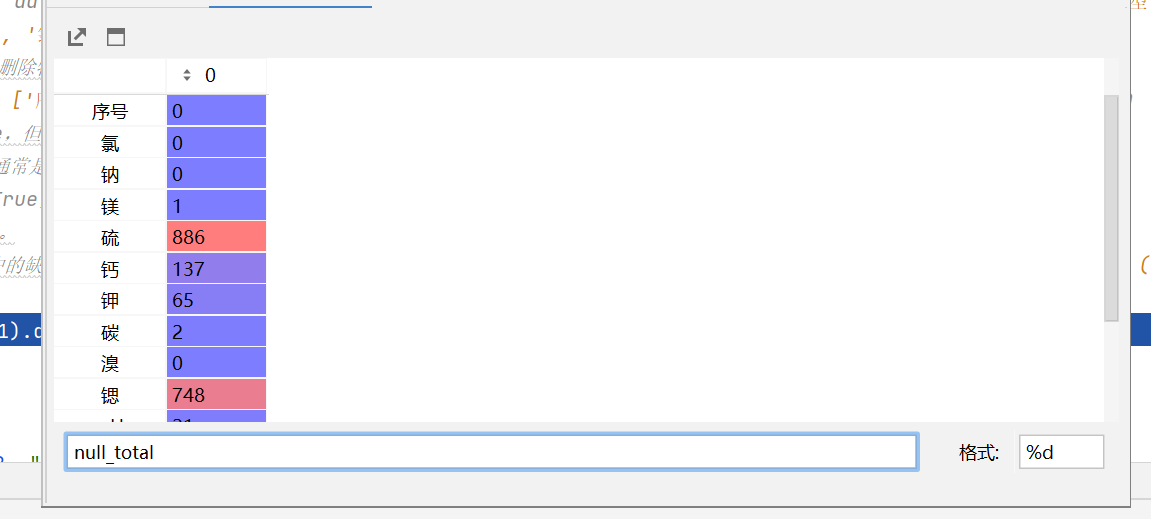
dropna():去除NaN值
2.3 数据收集与理解
import pandas as pd# 加载数据
data = pd.read_csv('dataset.csv')# 初步探索
print(data.head()) # 查看前几行
print(data.info()) # 数据概览
print(data.describe()) # 统计摘要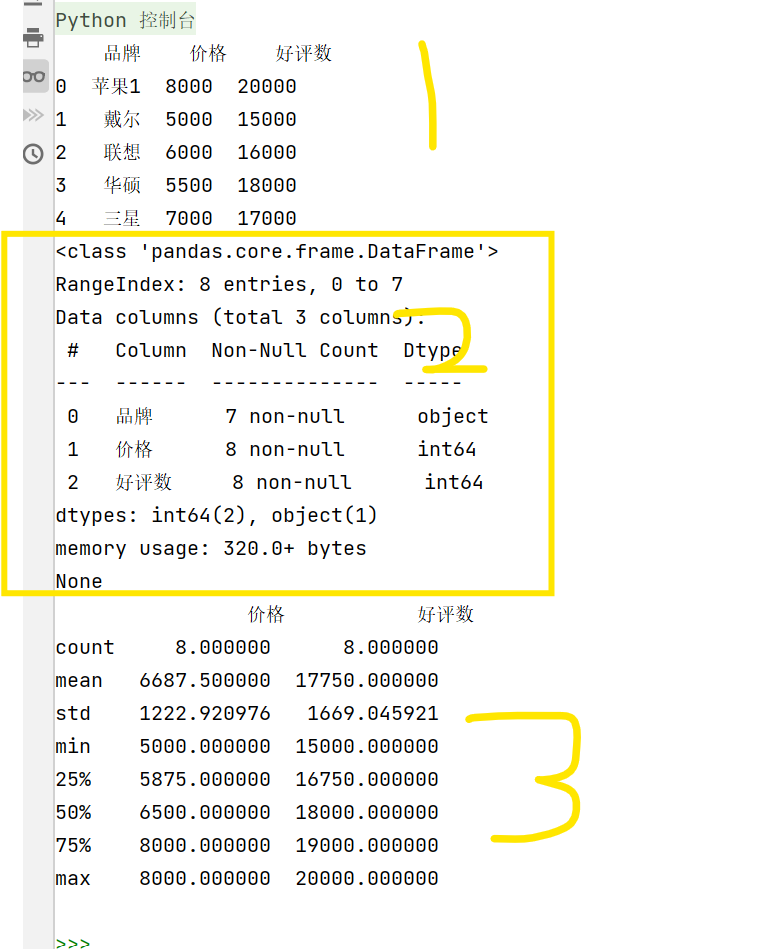
2.3特征标准化处理:
# 标准化 (Z-score标准化)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['Age', 'Income']] = scaler.fit_transform(data[['Age', 'Income']])# 归一化 (Min-Max缩放)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['Age', 'Income']] = scaler.fit_transform(data[['Age', 'Income']])2.4 特征选择
选择与对模型训练更重要的特征
# 基于相关性的特征选择
correlation_matrix = data.corr()
high_corr_features = correlation_matrix[abs(correlation_matrix['Target']) > 0.5].index
data = data[high_corr_features]# 使用方差阈值
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=0.1)
selected_features = selector.fit_transform(data)2.5 处理类别不平衡
当不同类别的数据及其不平衡的时候,为例更好的效果,可以采用上采样和下采样的方法来平衡数据。
上采样:在少的数据内加入插值,使少的数据类型等于多的
from imblearn.over_sampling import SMOTEsmote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)下采样:减少多的数据类型使其与少的数据类型数目相同
positive = data[data['Class']==0] #多的类型
negetive = data[data['Class']==1] #少的类型
positive = positive.sample(len(negetive)) #使多数类折掉一部分和少数类一样多
data=pd.concat([positive,negetive]) #将两个数据结合
x_1 = data.drop("Class",axis=1) #去除最后一列剩下的作为x
y_1 = data.Class #最后一列作为y2.6 文本数据预处理
有时候,样本数据是文字,为了能够训练我们需要将文字转换为向量
from sklearn.feature_extraction.text import TfidfVectorizertfidf = TfidfVectorizer(max_features=1000, stop_words='english')
X_text = tfidf.fit_transform(data['Text_Column'])fit_transform()实际上是两个操作的组合:
1.1 fit()阶段 - 学习文本特征
统计所有文档中的词汇(构建词汇表)评估词的重要性,确定特征空间维度,基于所有唯一词汇建立特征维度
1.2 transform()阶段 - 实际转换:将每个文档转换为向量
转换成向量示例:
这样可以进行训练
2.7 时间序列预处理
# 滚动窗口特征
data['Rolling_Mean_7'] = data['Value'].rolling(window=7).mean()
data['Rolling_Std_7'] = data['Value'].rolling(window=7).std()# 差分处理
data['Value_Diff'] = data['Value'].diff()2.8特征创建
# 从现有特征创建新特征
data['Income_to_Age_Ratio'] = data['Income'] / data['Age']# 从日期提取特征
data['Date'] = pd.to_datetime(data['Date'])
data['Year'] = data['Date'].dt.year
data['Month'] = data['Date'].dt.month
data['Day'] = data['Date'].dt.day5. 预处理最佳实践
- 保持一致性:对训练集和测试集应用相同的预处理步骤
- 避免数据泄露:只在训练集上拟合预处理器,然后应用到测试集.
记录所有步骤:确保预处理过程可重现
迭代优化:根据模型表现调整预处理策略
可视化验证:通过图表检查预处理效果
结语
数据预处理是机器学习项目中至关重要的一环。通过系统性地清洗、转换和增强数据,我们可以显著提高模型的性能和鲁棒性。本文介绍的技术和代码示例为常见的数据预处理任务提供了实用指南,但实际应用中需要根据具体数据和问题进行调整和扩展。