【完整源码+数据集+部署教程】无人机目标检测系统源码和数据集:改进yolo11-efficientViT
背景意义
研究背景与意义
随着无人机技术的迅猛发展,基于无人机的目标检测系统在多个领域中展现出巨大的应用潜力,包括农业监测、环境保护、城市管理和安全监控等。无人机能够在广阔的区域内高效地收集图像数据,这为实时目标检测提供了良好的基础。然而,传统的目标检测算法在处理复杂场景、快速移动目标和多样化背景时,往往面临着准确性和实时性不足的问题。因此,开发一种高效、准确的无人机目标检测系统显得尤为重要。
本研究旨在基于改进的YOLOv11模型,构建一个高效的无人机目标检测系统。YOLO(You Only Look Once)系列模型以其高速度和高准确率而闻名,尤其适合实时目标检测任务。通过对YOLOv11进行改进,我们期望能够进一步提升其在复杂环境下的检测性能,尤其是在处理多种目标类别时的表现。该系统将利用一个包含2100张图像的数据集,数据集中包含两类目标(类别0和类别1),为模型的训练和测试提供了丰富的样本。
在数据集的构建过程中,采用了实例分割的标注方式,使得模型不仅能够识别目标的存在,还能精确地分割出目标的轮廓。这一特性对于后续的应用场景,如精准农业和环境监测,具有重要的实际意义。此外,数据集的多样性和丰富性将为模型的泛化能力提供有力支持,确保其在不同环境下的适应性。
综上所述,本研究的开展不仅能够推动无人机目标检测技术的发展,还将为相关领域的实际应用提供重要的技术支持和理论依据,具有重要的学术价值和实际意义。
图片效果
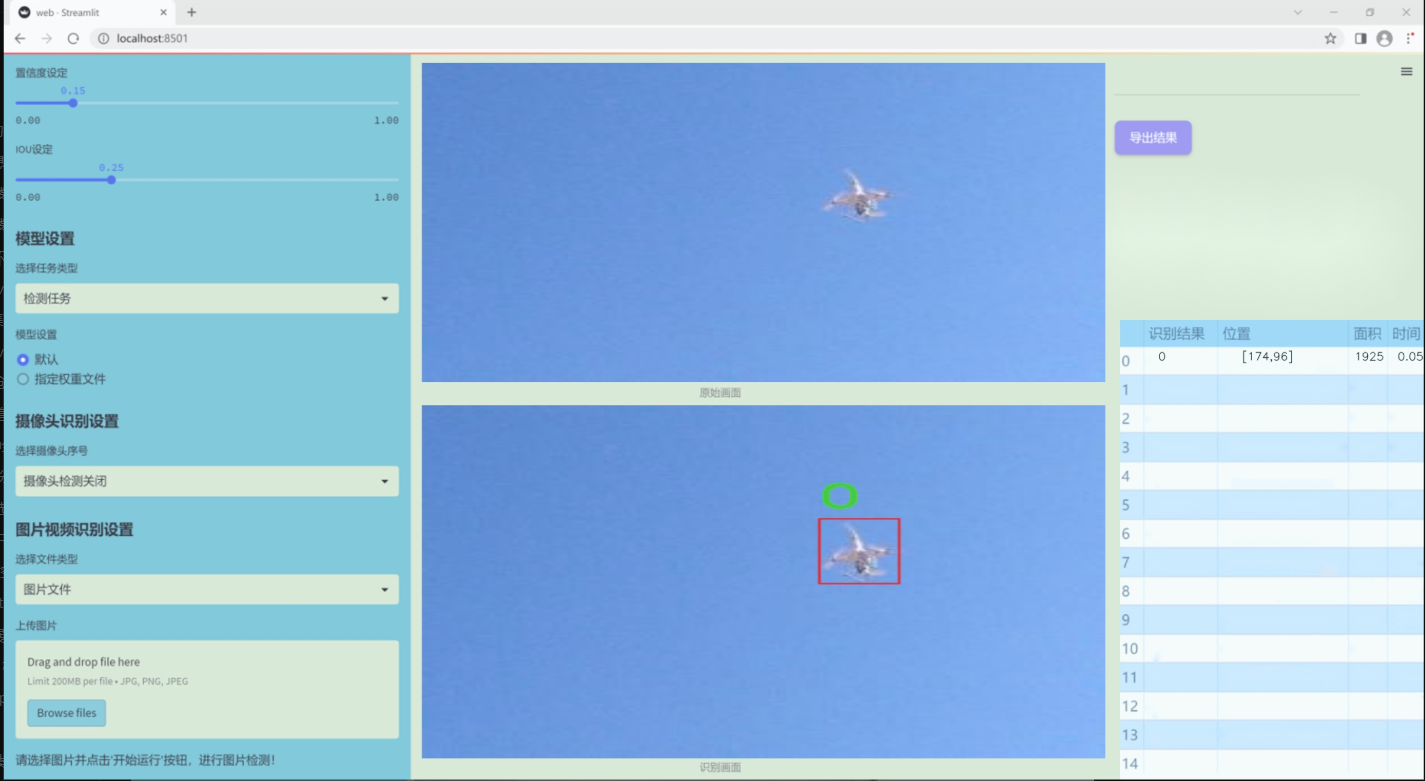
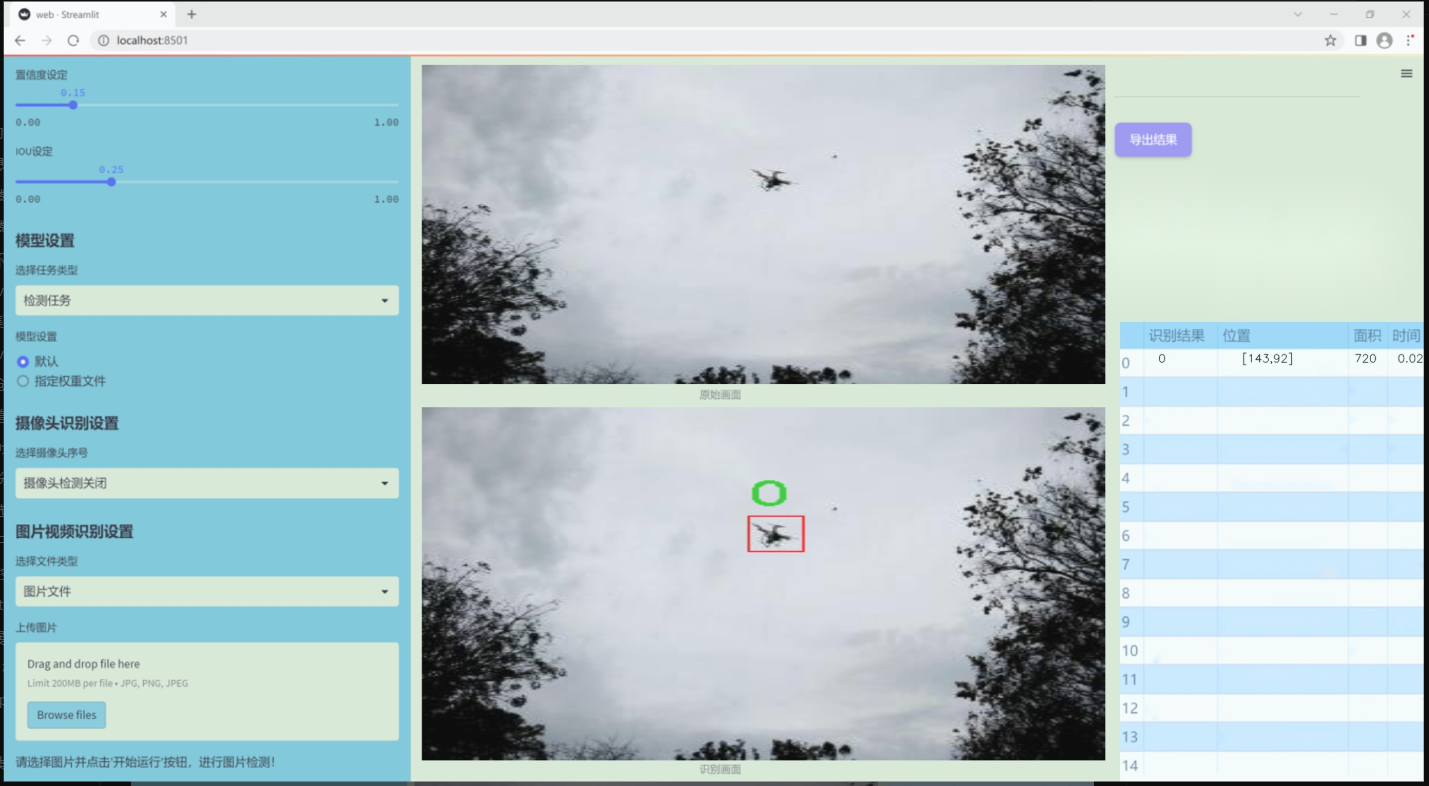
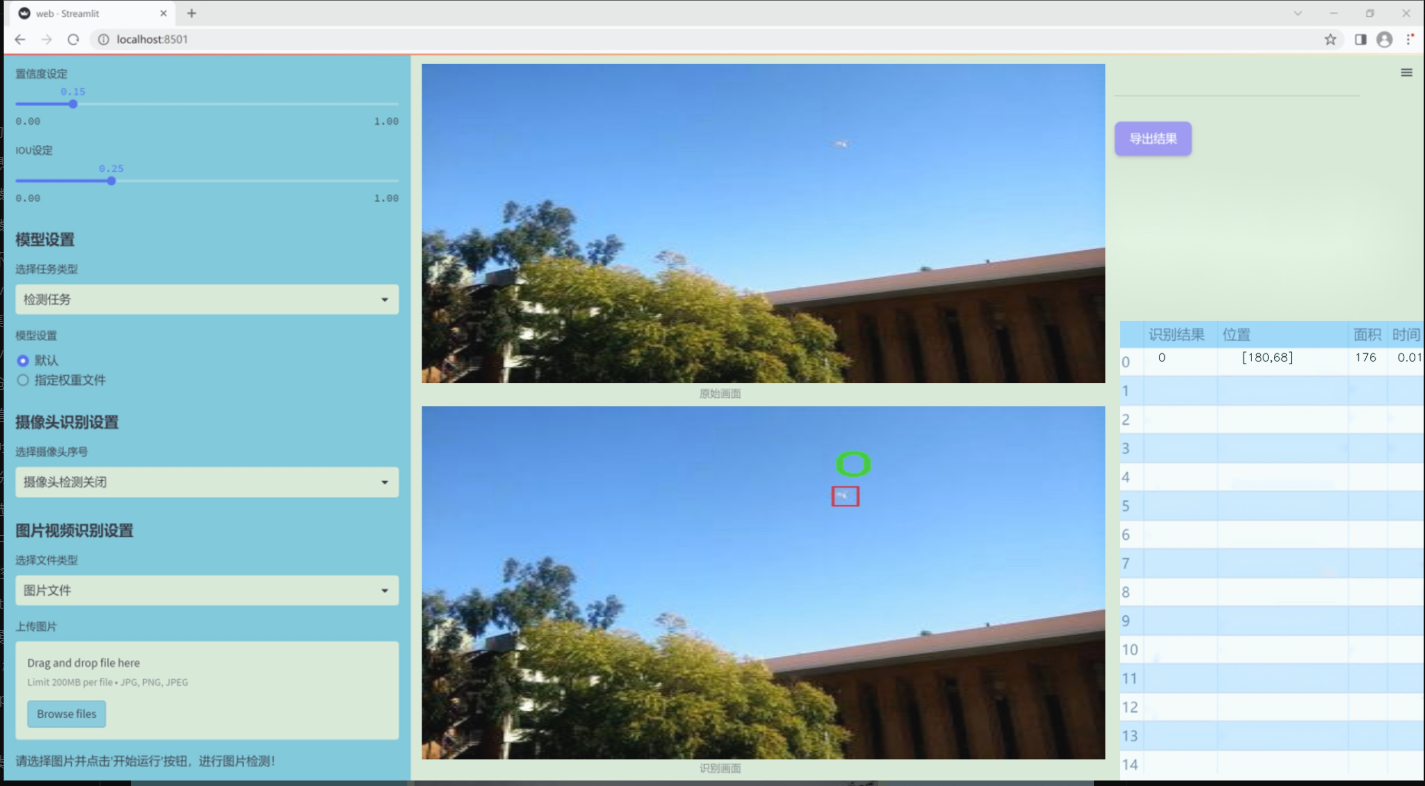
数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于无人机目标检测领域,旨在通过改进YOLOv11模型,提升无人机在复杂环境中的目标识别能力。该数据集涵盖了与无人机相关的多种场景和目标,具体类别数量为2,分别标记为’0’和’1’。这些类别可能代表不同类型的无人机目标,例如,类别’0’可能对应于特定型号的无人机,而类别’1’则可能代表其他类型的无人机或与无人机相关的物体。这种分类方式为模型提供了清晰的目标识别框架,使其能够在实际应用中更有效地进行目标检测。
数据集的构建过程中,采集了大量来自不同环境和条件下的无人机图像,确保数据的多样性和代表性。这些图像不仅包括城市和乡村的场景,还涵盖了不同天气条件下的拍摄,旨在提高模型的鲁棒性和适应性。此外,数据集中还包含了各种角度和距离下的无人机图像,以模拟实际操作中可能遇到的各种情况。这种丰富的图像数据为YOLOv11模型的训练提供了坚实的基础,使其能够在复杂的环境中准确识别和定位无人机目标。
通过对该数据集的深入分析和处理,我们期望能够显著提升无人机目标检测系统的性能,使其在实际应用中能够更快速、更准确地识别目标。这不仅有助于推动无人机技术的发展,也为相关领域的研究提供了重要的数据支持。总之,本项目的数据集在无人机目标检测的研究中具有重要的价值和意义,为未来的研究和应用奠定了坚实的基础。




核心代码
以下是经过简化和注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LayerNorm(nn.Module):
“”" 实现层归一化,支持两种数据格式:channels_last(默认)和 channels_first。 “”"
def init(self, normalized_shape, eps=1e-6, data_format=“channels_last”):
super().init()
# 权重和偏置初始化
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in [“channels_last”, “channels_first”]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):# 根据数据格式进行归一化if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return x
class Block(nn.Module):
“”" ConvNeXtV2 的基本块,包含深度卷积、归一化、激活等操作。 “”"
def init(self, dim, drop_path=0.):
super().init()
# 深度卷积层
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
self.norm = LayerNorm(dim, eps=1e-6)
# 逐点卷积层
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU() # 激活函数
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = nn.Identity() if drop_path <= 0. else DropPath(drop_path)
def forward(self, x):input = xx = self.dwconv(x) # 深度卷积x = x.permute(0, 2, 3, 1) # 维度转换x = self.norm(x) # 归一化x = self.pwconv1(x) # 逐点卷积x = self.act(x) # 激活x = self.pwconv2(x) # 逐点卷积x = x.permute(0, 3, 1, 2) # 维度转换x = input + self.drop_path(x) # 残差连接return x
class ConvNeXtV2(nn.Module):
“”" ConvNeXt V2 模型,包含多个特征分辨率阶段和残差块。 “”"
def init(self, in_chans=3, num_classes=1000, depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], drop_path_rate=0.):
super().init()
self.downsample_layers = nn.ModuleList() # 下采样层
# 初始化下采样层
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format=“channels_first”)
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format=“channels_first”),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 特征分辨率阶段for i in range(4):stage = nn.Sequential(*[Block(dim=dims[i]) for _ in range(depths[i])])self.stages.append(stage)self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # 最后的归一化层self.head = nn.Linear(dims[-1], num_classes) # 分类头def forward(self, x):""" 前向传播,经过下采样层和特征阶段。 """res = []for i in range(4):x = self.downsample_layers[i](x) # 下采样x = self.stages[i](x) # 特征提取res.append(x)return res
代码注释说明:
LayerNorm:实现了层归一化,支持两种输入格式,能够在深度学习中对特征进行归一化处理。
Block:ConvNeXtV2的基本构建块,包含深度卷积、归一化、激活和残差连接,构成了网络的核心部分。
ConvNeXtV2:整个模型的定义,包含多个下采样层和特征提取阶段,通过多个Block进行特征学习,最后通过分类头输出结果。
这个程序文件定义了一个名为 ConvNeXt V2 的深度学习模型,主要用于图像分类任务。文件中包含了多个类和函数,具体功能如下:
首先,文件引入了必要的库,包括 PyTorch 和一些用于模型构建的模块。接着,定义了一个名为 LayerNorm 的类,该类实现了层归一化功能,支持两种数据格式:通道优先(channels_first)和通道最后(channels_last)。在 forward 方法中,根据输入数据的格式进行不同的归一化处理。
接下来,定义了一个 GRN 类,表示全局响应归一化层。该层通过计算输入的 L2 范数来进行归一化,并引入了可学习的参数 gamma 和 beta,以便在训练过程中调整输出。
然后,定义了 Block 类,这是 ConvNeXt V2 的基本构建块。每个块包含一个深度可分离卷积层、层归一化、一个点卷积层(通过线性层实现)、激活函数(GELU)、GRN 层和另一个点卷积层。最后,使用残差连接和随机深度(DropPath)技术来增强模型的表达能力。
接下来,定义了 ConvNeXtV2 类,这是整个模型的核心。该类的构造函数接收多个参数,包括输入通道数、分类头的类别数、每个阶段的块数、特征维度、随机深度率等。模型的结构由多个下采样层和特征提取阶段组成。下采样层通过卷积和层归一化逐步减少特征图的尺寸,而特征提取阶段则由多个 Block 组成。
在 ConvNeXtV2 的 forward 方法中,输入数据经过下采样层和特征提取阶段,最终返回特征图。
此外,文件还定义了一个 update_weight 函数,用于更新模型的权重。该函数会检查权重字典中的每个键是否存在于模型字典中,并且形状是否匹配,然后将匹配的权重更新到模型中。
最后,文件提供了一系列函数(如 convnextv2_atto、convnextv2_femto 等),用于创建不同规模的 ConvNeXt V2 模型。这些函数会根据预定义的深度和维度参数初始化模型,并在提供权重文件时加载相应的权重。
总体来说,这个文件实现了一个灵活且高效的卷积神经网络架构,适用于各种图像分类任务,并提供了多种模型规模以适应不同的应用需求。
10.4 pkinet.py
以下是代码中最核心的部分,并附上详细的中文注释:
import math
import torch
import torch.nn as nn
class DropPath(nn.Module):
“”“实现随机深度(Drop Path)功能的模块,通常用于残差块中。”“”
def __init__(self, drop_prob: float = 0.1):super().__init__()self.drop_prob = drop_prob # 设置路径被丢弃的概率def forward(self, x: torch.Tensor) -> torch.Tensor:"""前向传播函数,应用随机深度。Args:x (torch.Tensor): 输入张量。Returns:torch.Tensor: 经过随机深度处理后的输出张量。"""if self.drop_prob == 0. or not self.training: # 如果丢弃概率为0或不在训练模式下,直接返回输入return xkeep_prob = 1 - self.drop_prob # 计算保留概率shape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # 处理不同维度的张量random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device) # 生成随机张量output = x.div(keep_prob) * random_tensor.floor() # 应用随机深度return output
class ConvFFN(BaseModule):
“”“使用卷积模块实现的多层感知机(MLP)”“”
def __init__(self, in_channels: int, out_channels: Optional[int] = None, hidden_channels_scale: float = 4.0,dropout_rate: float = 0., add_identity: bool = True, norm_cfg: Optional[dict] = None,act_cfg: Optional[dict] = None):super().__init__()out_channels = out_channels or in_channels # 如果未指定输出通道,则与输入通道相同hidden_channels = int(in_channels * hidden_channels_scale) # 计算隐藏通道数# 定义前向传播的层self.ffn_layers = nn.Sequential(nn.LayerNorm(in_channels), # 对输入进行层归一化ConvModule(in_channels, hidden_channels, kernel_size=1, stride=1, padding=0, norm_cfg=norm_cfg, act_cfg=act_cfg),ConvModule(hidden_channels, hidden_channels, kernel_size=3, stride=1, padding=1, groups=hidden_channels, norm_cfg=norm_cfg, act_cfg=None),nn.GELU(), # 使用GELU激活函数nn.Dropout(dropout_rate), # 添加Dropout层ConvModule(hidden_channels, out_channels, kernel_size=1, stride=1, padding=0, norm_cfg=norm_cfg, act_cfg=act_cfg),nn.Dropout(dropout_rate), # 再次添加Dropout层)self.add_identity = add_identity # 是否添加恒等映射def forward(self, x):"""前向传播函数,执行FFN操作。Args:x (torch.Tensor): 输入张量。Returns:torch.Tensor: 输出张量。"""x = x + self.ffn_layers(x) if self.add_identity else self.ffn_layers(x) # 如果需要,添加恒等映射return x
class PKINet(BaseModule):
“”“多核卷积网络(Poly Kernel Inception Network)”“”
def __init__(self, arch: str = 'S', out_indices: Sequence[int] = (0, 1, 2, 3, 4), drop_path_rate: float = 0.1):super().__init__()self.out_indices = out_indices # 输出的层索引self.stages = nn.ModuleList() # 存储网络的各个阶段# 初始化网络的stem部分self.stem = Stem(3, 32) # 假设输入通道为3,输出通道为32self.stages.append(self.stem)# 根据给定的架构设置初始化各个阶段for i in range(4): # 假设有4个阶段stage = PKIStage(32, 64) # 这里的参数需要根据实际情况设置self.stages.append(stage)def forward(self, x):"""前向传播函数,依次通过各个阶段。Args:x (torch.Tensor): 输入张量。Returns:tuple: 各个阶段的输出。"""outs = []for i, stage in enumerate(self.stages):x = stage(x) # 通过每个阶段if i in self.out_indices: # 如果当前阶段在输出索引中outs.append(x) # 保存输出return tuple(outs) # 返回所有输出
创建网络实例
def PKINET_S():
return PKINet(‘S’)
if name == ‘main’:
model = PKINET_S() # 实例化模型
inputs = torch.randn((1, 3, 640, 640)) # 创建输入张量
res = model(inputs) # 前向传播
for i in res:
print(i.size()) # 打印输出的尺寸
代码核心部分说明:
DropPath 类:实现了随机深度的功能,可以在训练过程中随机丢弃某些路径,增强模型的泛化能力。
ConvFFN 类:实现了一个多层感知机,使用卷积模块代替全连接层,适合处理图像数据。
PKINet 类:构建了一个多核卷积网络的框架,包含多个阶段,每个阶段可以有不同的结构和参数设置。通过前向传播函数,依次通过各个阶段并返回输出。
这些核心部分构成了模型的基础,提供了构建和训练深度学习模型所需的基本功能。
这个程序文件 pkinet.py 实现了一个名为 PKINet 的深度学习模型,主要用于图像处理任务。模型结构灵感来源于多核卷积(Poly Kernel Convolution)和注意力机制,旨在提高特征提取的能力和效率。文件中包含多个类和函数,下面对其主要内容进行说明。
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,以及一些可能的外部库(如 mmcv 和 mmengine),用于构建神经网络模块和初始化权重。接着,定义了一些通用的辅助函数,如 drop_path 和 make_divisible,用于实现随机深度和确保通道数可被特定值整除。
接下来,定义了一些基础模块,包括 DropPath、BCHW2BHWC、BHWC2BCHW、GSiLU、CAA、ConvFFN、Stem、DownSamplingLayer、InceptionBottleneck、PKIBlock 和 PKIStage。这些模块组合在一起形成了 PKINet 的核心结构。
DropPath 模块实现了随机深度的功能,通过在训练过程中随机丢弃部分路径来增强模型的泛化能力。
BCHW2BHWC 和 BHWC2BCHW 用于在不同的张量维度之间转换,以适应不同的卷积操作。
GSiLU 是一种激活函数,结合了全局平均池化和 Sigmoid 函数。
CAA 是上下文锚注意力模块,旨在增强特征表示能力。
ConvFFN 是一个多层感知机,使用卷积模块实现,包含前馈神经网络的结构。
Stem 和 DownSamplingLayer 是用于特征提取和下采样的基本模块。
InceptionBottleneck 和 PKIBlock 结合了多种卷积核大小的卷积操作,形成了复杂的特征提取块。
PKIStage 代表模型的一个阶段,由多个 PKIBlock 组成,并包含下采样和特征融合的功能。
最后,PKINet 类是整个模型的主体,负责构建网络的各个阶段,并定义了模型的前向传播逻辑。模型的架构设置在 arch_settings 字典中定义,允许用户选择不同的网络配置(如 T、S、B 三种版本)。在 init 方法中,模型根据选择的架构设置构建各个阶段,并初始化权重。
在文件的最后部分,定义了三个函数 PKINET_T、PKINET_S 和 PKINET_B,用于创建不同版本的 PKINet 模型。程序的入口部分示例了如何创建一个 PKINET_T 模型并进行一次前向传播,输出每个阶段的特征图大小。
整体来看,这个文件实现了一个复杂的深度学习模型,包含多种先进的特征提取和处理技术,适合用于图像分类、目标检测等任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻