【C++】异常详解(万字解读)
万字解读C++异常
- C++异常
- github地址
- 0. 前言
- 1. 传统 C 风格的错误处理:为何需要异常?
- 2. C++异常的概念
- 3. 异常的使用
- 3.1 异常的抛出和捕获
- 匹配原则
- 异常调用链上的“栈展开”
- 3.2 异常的重新抛出
- 3.3 异常安全与 RAII 思想
- 3.4 异常规范说明
- 4. 自定义异常体系——统一管理
- 1. 为什么要自定义统一体系
- 2. 常用自定义体系
- 异常类继承层次
- 处理函数
- 捕获模块
- 5. C++标准库中的异常体系
- 6. 异常的优缺点
- 7. 结语
C++异常
github地址
有梦想的电信狗
0. 前言
在 C++ 学习的过程中,异常(Exception) 是一个既重要又常常被忽视的知识点。很多初学者更习惯使用 错误码 或者 断言 来处理问题,却很少系统地去理解和使用异常机制。事实上,异常的设计初衷,就是为了解决 C 语言时代“错误处理困难、代码可读性差”的痛点。
在现代软件开发中,系统往往具有更高的复杂性,函数调用链很长,模块之间紧密协作。如果依赖传统的错误返回值,就需要“层层上传”,一旦遗漏检查就可能导致严重的 bug;而直接使用 assert 终止程序,也会让用户难以接受。C++ 提供的 异常机制 恰好为我们提供了一个优雅的解决方案:
- 错误信息能够在调用链上自动传递;
- 外层可以通过
catch块集中处理错误; - 结合
RAII思想,还能有效避免资源泄漏问题。
本文将带你系统学习 C++ 异常:从传统 C 风格错误处理的不足说起,再到异常的语法规则、抛出与捕获的过程、异常安全与 RAII、统一异常体系的设计,以及标准库提供的异常层次。通过循序渐进的讲解与丰富的代码示例,你将能够从根本上理解 C++ 异常机制的工作原理,并在工程实践中做到“用得明白,用得规范”。
1. 传统 C 风格的错误处理:为何需要异常?
C 语言中错误处理常见两种做法:
- 终止程序(如
assert为false时直接终止程序):缺陷:并不能明确知道是什么错误,用户难以接收错误信息- 内存错误(数组越界,未初始化/空指针/无效地址的访问,野指针,内存泄露,同一块空间释放多次等等)
- 除0错误,会直接终止程序
- 返回错误码(需配合
errno),缺陷:需要调用者层层检查和传递对应的错误,既繁琐又易出错- 如系统的很多库的接口函数都是通过把错误码放到errno中,表示错误
- 实际工程里,多数选择返回错误码,极少数“致命错误”直接终止。
- 实际工程中,C语言基本都是使用返回错误码的方式处理错误,部分情况下使用终止程序处理非常严重的错误
小结: 当函数调用链很深时,错误码方案要求“层层返回”,既污染业务逻辑,又容易遗漏。
- 异常机制正是为解决此类痛点而生,异常不会终止程序,并且会将错误信息详细介绍。
- 先感受一下异常:
double Division(int a, int b) {if (b == 0)throw "Division by zero condition!";elsereturn ((double)a / (double)b);
}
void Func() {int len, time;cin >> len >> time;cout << Division(len, time) << endl;
}
int main() {//Func();try {Func();}catch (const char* errmsg) {cout << "异常已捕获: " << errmsg << endl;}catch (...) {cout << "unkown exception" << endl;}return 0;
}
-
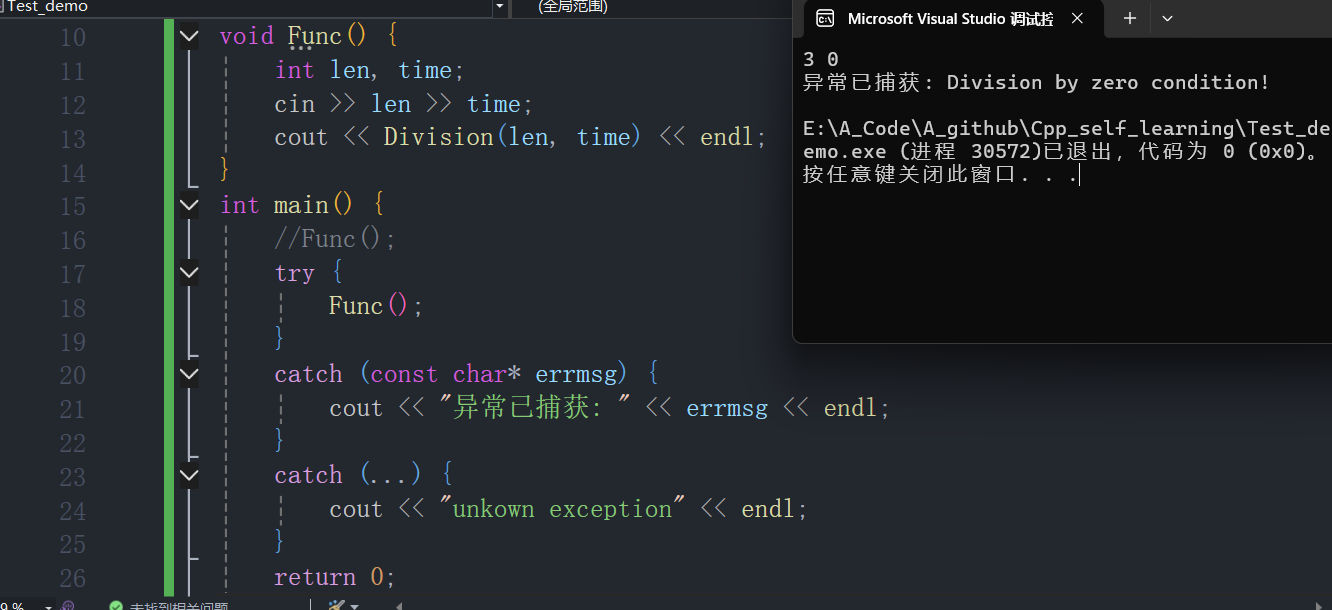
使用异常捕获除0错误,显示出异常的信息
-
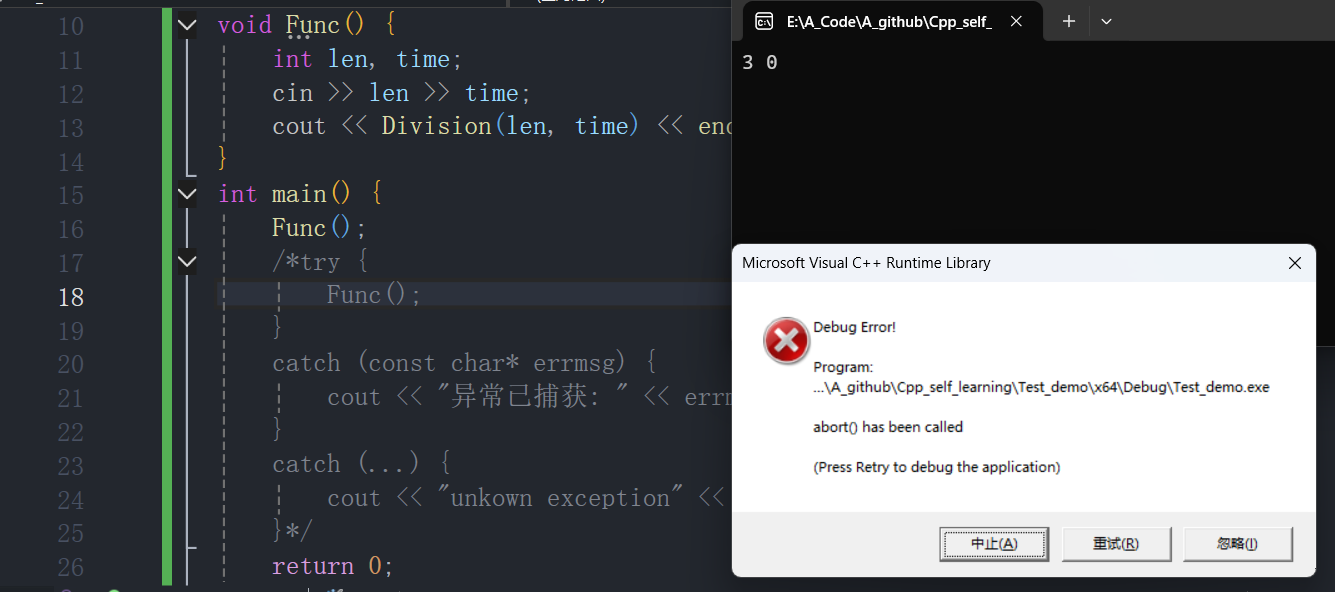
不使用异常,传统C语言直接终止程序
2. C++异常的概念
异常是面向对象语言处理错误的一种方式,当一个函数发现自己无法处理的错误时,可以抛出异常,让函数的直接或间接的调用者处理这个错误。异常的抛出和捕获由以下三个关键字配合完成:
-
throw:当问题出现时,程序会抛出一个异常(本质是抛出一个对象)。抛异常使用
throw关键字完成 -
try:
try块中包含可能出现异常的代码或者函数,try块中的代码被称为保护代码,放置可能抛出异常的代码,
-
catch(异常的类型):跟在
try块之后,用于捕捉异常。catch关键字用于捕获异常,可以设置多个catch捕获throw抛出的不同类型的异常(对象)。catch(...)可以捕获任意类型的异常,用来捕获没有显示捕获类型的异常,相当于条件判断最后的的else- 只有
try{ }块中抛出了异常,才会执行catch中的代码
-
在想要处理问题的地方,通过异常处理程序捕获异常。
使用方法如下:
- 注意:不论
try和catch块中有多少行代码,都必须加上{}
try {// 保护代码,可能出现错误,出现错误后抛异常
}
// catch 的括号中填异常的类型
catch (ExceptionName e1) {// 分支1
} catch (ExceptionName e2) {// 分支2
} catch (...) {// 兜底分支:捕获任意类型
}
关键点:
throw抛出的是对象,对象的类型决定匹配到哪个catch;- 可以有多分支;
catch(...)可兜底但无法区分具体错误。
3. 异常的使用
3.1 异常的抛出和捕获
匹配原则
异常的抛出和匹配原则:
- 异常是通过抛出对象而引发的,该对象的静态类型决定了应该激活哪个catch的处理代码。
- 异常抛出后,匹配的
catch处理代码是调用链中与该异常对象类型匹配且离抛出异常位置最近的那一个。 - 抛出异常对象后,会生成一个异常对象的拷贝。因为抛出的异常对象可能是一个临时对象(匿名对象),所以会生成一个拷贝对象抛出。
catch结束后该拷贝对象销毁(类比函数的按值返回)。
- catch(. . .)可以捕获任意类型的异常,但无法得知异常的具体信息。抛出了异常但没有被捕获时,程序会被终止。因此需要
catch(...)兜底 - 实际中抛出和捕获的类型并不是完全匹配,可以抛出派生类对象,使用基类捕获,便于统一处理与多态扩展(工程中非常实用)。
- 可用基类捕获派生类原因是:派生类可以赋值给基类,基类的指针或引用可以指向派生类
异常调用链上的“栈展开”
在函数调用链中异常栈展开的匹配原则:
- 首先检查抛出点
throw本身是否在某个try块 内,如果是,尝试就近查找匹配catch。- 如果有匹配的,则跳转到
catch的地方进行处理。
- 如果有匹配的,则跳转到
- 没有匹配的
catch,退出当前函数栈帧,到调用者的函数栈帧中查找匹配的catch语句。 - 一直查找至
main函数的栈帧,如果依旧没有catch块匹配,则终止程序;- 找到
catch匹配并处理后,从当前栈帧的catch子句之后继续往下执行。
- 找到
- 上述这个沿着调用链查找匹配的
catch子句的过程称为栈展开。 - 实践建议:
- 顶层栈帧(通常是main函数的栈帧)加上一个
catch(...)兜底,用于捕获任意类型的异常,避免异常漏出导致进程崩溃(程序直接终止)。
- 顶层栈帧(通常是main函数的栈帧)加上一个

结论:
按照函数调用链,一层一层往外找,直到找到匹配的catch块,直接跳到匹配的catch块执行,执行完catch,会继续往catch块后面的语句执行。相当于没有找到匹配的函数栈帧被释放了。
3.2 异常的重新抛出
有时catch到⼀个异常对象后,需要对错误进行分类,其中的某种异常错误需要进行特殊的处理,其他错误则重新抛出异常给外层调⽤链处理。捕获异常后需要重新抛出时,直接 throw,就可以直接抛出。
- 场景一:
下⾯程序模拟展⽰了聊天时发送消息,发送失败捕获异常,但是可能在电梯地下室等场景手机信号不好,则需要多次尝试。
如果多次尝试都发送不出去,则就需要捕获异常再重新抛出,其次如果不是⽹络差导致的错误,捕获后也要重新抛出。
void _SeedMsg(const string& s) {if (rand() % 2 == 0)throw HttpException("⽹络不稳定,发送失败", 102, "put");else if (rand() % 7 == 0)throw HttpException("你已经不是对象的好友,发送失败", 103, "put");elsecout << "发送成功" << endl;
}void SendMsg(const string& s) {// 发送消息失败,则再重试3次for (size_t i = 0; i < 4; i++) {try {_SeedMsg(s);break;}catch (const Exception& e) {// 捕获异常,if中是102号错误,⽹络不稳定,则重新发送// 捕获异常,else中不是102号错误,则将异常重新抛出if (e.getid() == 102){// 重试三次以后否失败了,则说明⽹络太差了,重新抛出异常if (i == 3)throw;// 重试的逻辑cout << "开始第" << i + 1 << "重试" << endl;}elsethrow;//捕获到什么就抛什么}}
}int main() {srand(time(0));string str;while (cin >> str) {try {SendMsg(str);}catch (const Exception& e) {cout << e.what() << endl << endl;}catch (...) {cout << "Unkown Exception" << endl;}}return 0;
}
- 场景二:
在下面的代码场景里面,当b==0时,抛出异常,被main函数里面的catch捕获,代码直接跳到main函数里面执行,但是Func函数里面的 ptr1 没有被释放,怎么办?
double Divide(int a, int b) {try{// 当b == 0时抛出异常if (b == 0) {string s("Divide by zero condition!");throw s;}elsereturn ((double)a / (double)b);}catch (int errid)cout << errid << endl;return 0;
}void Func() {int* ptr1 = new int[10];int len, time;cin >> len >> time;// 可能抛异常cout << Divide(len, time) << endl;delete[] ptr1;cout << "delete:" << ptr1 << endl;
}int main() {while (1){try{Func();}catch (const string& errmsg) {cout << errmsg << endl;} catch (...) {cout << "未知异常" << endl;}}return 0;
}
- 在Func函数中添加一个
try{}...catch{}语句,并对异常进行重新抛出来解决
void Func() {int* ptr1 = new int[10];int len, time;cin >> len >> time;try {cout << Divide(len, time) << endl;}catch (...) {delete[] ptr1;cout << "delete:" << ptr1 << endl;// 重新抛出,捕获到什么抛什么。这里的try,catch的目的就是释放ptr1,再重新抛出,对捕获到的异常该处理处理// 所以可见,重新抛出,是为了进行内存的释放或者场景一中业务的处理等throw;}delete[] ptr1;cout << "delete:" << ptr1 << endl;
}
更新后的Func函数的执行流:
- 无异常时:
catch块中的代码不执行,下面的代码delete[] ptr1正确释放了ptr1指针 - 出现异常时:执行
catch块中的代码,释放ptr1,单条throw语句将异常重新抛出,让外层栈帧对该异常进行处理
总结:
- 单个
catch不能完全处理时,可在完成必要清理后“重新抛出”,将异常交给更外层处理。在 C++ 中用于“原样抛出”的语法是throw;。
3.3 异常安全与 RAII 思想
- 构造函数:构造函数完成对象的构造和初始化,尽量不要抛异常,避免出现异常后执行流跳转,使对象处于不完整状态。
- 析构函数:尽量不要抛异常,执行流跳转后资源未被清理,可能导致资源泄漏甚至
terminate。 - 典型风险:
new/delete之间抛异常,delete未被执行导致内存泄漏;lock/unlock之间抛异常,锁没有被释放导致死锁。 - 解决思路:RAII(资源获取即初始化)——把资源放入对象,靠对象生命周期自动管理。
演示出现异常时先清理再 throw 的范式:
void Func() {int* array = new int[10];try {int len, time;std::cin >> len >> time;std::cout << Division(len, time) << std::endl;}// 抛异常后,捕获异常进行处理,再将异常重新抛出// 抛异常后,资源也能被正确释放catch (...) {std::cout << "出现异常时: delete []" << array << std::endl;delete[] array; // 清理资源throw; // 重新抛出,等待后面的代码或上层函数栈帧处理}// 未抛异常时,资源被正确释放std::cout << "正常情况: delete []" << array << std::endl;delete[] array; // 正常路径清理
}
- “异常经常导致资源泄漏,RAII 是通用解法(如智能指针管理内存,互斥量用守卫对象管理加解锁)”。
3.4 异常规范说明
-
为了让函数使用者明确该函数“可能抛什么”异常,可在函数尾部给出异常规格:
- 函数的后面加
throw(),表示函数不抛异常。void fun() throw(A, B, C, D);函数仅可能抛出列出的异常类型;void f() throw();表示不抛异常;- 若无异常接口声明,表示此函数可能抛出任意类型的异常;
- 函数的后面加
-
C++98中的std::exception类的成员函数,后面跟throw()的函数,表示该函数不会抛出异常

- 标准库中曾使用过:
operator new可能抛std::bad_alloc;operator delete声明不抛异常; -


但是上述
C++98的异常接口的声明的方式存在问题:
- 如果这个函数的可能会抛出的异常类型很多,那么就会造成使用者书写繁琐的问题。
- 所以这种方式的使用几乎很少
- C++11 引入
noexcept表示不抛异常,如thread() noexcept;,thread(thread&&) noexcept;。

// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常
void fun() throw(A,B,C,D);
// 这里表示这个函数只会抛出bad_alloc的异常
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数不会抛出异常
void* operator new (std::size_t size, void* ptr) throw();
void* operator new (std::size_t size, void* ptr) noexcept; // C++11
现代 C++ 已弃用旧式
throw(TypeList)规格而统一到noexcept,但理解其设计意图有助于阅读旧代码。
4. 自定义异常体系——统一管理
1. 为什么要自定义统一体系
为什么要自定义? 如果多个不同模块的团队“随心所欲”地抛各种类型(int、const char*、自定义结构体…),外层就很难一网打尽。最佳实践是统一继承自共同基类,外层只需捕获基类对象,通过派生类虚函数的重写,实现异常的多态处理。

2. 常用自定义体系
服务端常用的异常处理层次如下:
异常类继承层次
class Exception {
public:Exception(const std::string& errmsg, int id): _errmsg(errmsg), _id(id){}virtual std::string what() const {return _errmsg; }
protected:std::string _errmsg;int _id;
};class SqlException : public Exception {
public:SqlException(const std::string& errmsg, int id, const std::string& sql): Exception(errmsg, id), _sql(sql) {}std::string what() const override {return "SqlException:" + _errmsg + "->" + _sql;}
private:const std::string _sql;
};class CacheException : public Exception {
public:using Exception::Exception;std::string what() const override {return "CacheException:" + _errmsg;}
};class HttpServerException : public Exception {
public:HttpServerException(const std::string& errmsg, int id, const std::string& type): Exception(errmsg, id), _type(type) {}std::string what() const override {return "HttpServerException:" + _type + ":" + _errmsg;}
private:const std::string _type;
};
处理函数
用一条服务链演示从最外层统一处理:
void SQLMgr() {srand(time(0));if (rand() % 7 == 0) {throw SqlException("权限不足", 100, "select * from name = '张三'");}
}
void CacheMgr() {srand(time(0));if (rand() % 5 == 0) throw CacheException("权限不足", 100);else if (rand() % 6 == 0) throw CacheException("数据不存在", 101);SQLMgr();
}
void HttpServer() {srand(time(0));if (rand() % 3 == 0) throw HttpServerException("请求资源不存在", 100, "get");else if (rand() % 4 == 0) throw HttpServerException("权限不足", 101, "post");CacheMgr();
}
捕获模块
int main() {while (1) {std::this_thread::sleep_for(std::chrono::seconds(1));try {HttpServer();} catch (const Exception& e) { // 只捕获基类std::cout << e.what() << std::endl; // 多态} catch (...) {std::cout << "Unkown Exception" << std::endl;}}
}
- 利用继承和多态,我们最终只需写两个
catch模块:catch (const Exception& e):只捕获基类异常,基类的引用可以指向多个派生类的异常- 基类的引用指向派生类对象时, 通过虚函数的重写,就实现了指向哪个模块,就调用哪个异常模块
catch (. . .):捕获任意类型的异常作为兜底,防止异常抛出后未被捕获导致程序终止
- 这个设计的好处:统一入口、统一上下文信息(错误码、信息、上下文如 SQL 语句或 HTTP 方法),且易于扩展。
5. C++标准库中的异常体系
标准库提供了以 std::exception 为基类的异常层次(如 std::bad_alloc、std::out_of_range 等)。


-
我们可以在工程里继承
exception实现自己的自定义异常类- 我们想要捕获标准库中的异常,只需
catch (const std::exception& e){ }即可 - 因为标准库中的各种异常类,都是
std::exception的派生类,基类的指针或引用指向派生类,可以实现多态调用
- 我们想要捕获标准库中的异常,只需
-
但很多公司更愿意自建一套统一、好用的异常体系(见上节),在顶层捕获基类即可。因为C++标准库设计的不够好用
- 使用标准库抛出异常的例子:
try {std::vector<int> v(10, 5);v.reserve(1000000000); // 可能因内存不足抛出异常v.at(10) = 100; // 下标越界抛异常
} catch (const std::exception& e) { // 捕获标准库异常基类std::cout << e.what() << std::endl;
} catch (...) {std::cout << "Unkown Exception" << std::endl;
}
要点:对 STL/第三方库,我们应当了解其抛出的异常类型并据此捕获,或在外层用统一基类处理。
6. 异常的优缺点
优点:
- 相比错误码的方式,设计好的异常对象可清晰携带各种错误信息,甚至包含堆栈调用信息,定位程序的
bug更高效 - 传统返回错误码的方式有个很大的问题:在函数调用链中,深层的函数返回了错误,那么我们需要层层返回错误,最外层才能拿到错误。异常有效地避免了错误码的“层层返回”,外层直接在
catch统一处理; - 大量三方库(如
Boost、gtest/gmock等)都使用异常,那么我们使用这些库也需要学习使用异常 - 某些函数签名不便返回错误(如构造函数、引用返回的
operator等),异常更合适。比如:- 构造函数没有返回值,不方便使用错误码方式处理。
T& operator[](size_t pos)这样的函数,如果pos越界了只能使用异常或者终止程序处理,无法通过返回值表示错误
-
层层返回错误码的缺陷:
-
给出对照:
- 错误码方案:底层
ConnectSql出错 → 返回给ServerStart→ 再返回main→main再处理; - 异常方案:在调用链任意层抛异常,直接跳到顶层
catch,由main集中处理即可。
- 错误码方案:底层
// 1.下面这段伪代码我们可以看到ConnnectSql中出错了,先返回给ServerStart,ServerStart再返回给main函数,main函数再针对问题处理具体的错误。
// 2.如果是异常体系,不管是ConnnectSql还是ServerStart及调用函数出错,都不用检查,因为抛出的异常异常会直接跳到main函数中catch捕获的地方,main函数直接处理错误。
int ConnnectSql() {//用户名密码错误if (...)return 1;//权限不足if (...)return 2;
}
int ServerStart() {if (int ret = ConnnectSql() < 0)return ret;int fd = socket()if(fd < 0)return errno;
}
int main() {if(ServerStart()<0)...return 0;
}
缺点:
- 异常会导致程序的执行流乱跳转,并且是运行时出错抛异常就会乱跳转。这会给我们跟踪调试以及分析程序时带来困难。
- 存在一定性能开销(一般可忽略),性能开销来源于要返回对象的拷贝。现代硬件速度很快,这个影响基本忽略不计。
C++没有垃圾回收机制,资源需要自己管理。异常非常容易导致内存泄漏、死锁等异常安全问题。这个需要使用RAII来处理资源的管理问题,学习难度较高。- C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,生态不统一。
- C++并没有规定异常的使用规范。随意抛异常,外层不好捕获,所以尽量按照异常规范使用。规范有两点:
- 抛出异常类型为派生类,都继承自一个基类。
- 函数是否抛异常、抛什么异常,都在函数后面加上
throw()的方式规范化。
结论:异常总体“利大于弊”,工程上鼓励使用异常,前提是严格规范与RAII 落地。
7. 结语
异常并不是一个“锦上添花”的语法,而是 C++ 提供的一套完整的错误处理机制。掌握它,意味着你能够在项目中写出更安全、更健壮、更具可维护性的代码。
通过本文的学习,我们了解了:
- C 风格错误处理的缺陷,以及异常存在的意义;
try、catch、throw的基本语法与调用链上的栈展开;- 异常重新抛出、异常安全与 RAII 的重要性;
- 如何设计一套统一的异常体系,让错误处理更加可控;
- C++ 标准库中异常体系的应用,以及它与工程实践的结合。
工程实践清单:
- 统一异常体系:项目内统一从共同基类继承(如
Exception),最外层捕获基类即可;不要随意抛基本类型或字符串。 - 保留兜底:在顶层(线程入口/
main)准备catch(...)兜底,保证服务稳定性。 - 只在能修复的地方捕获:不能彻底处理时,清理后
throw;重新抛出,不要“吞掉”异常。 - 异常安全与 RAII:任何“获取—释放”对,都优先用 RAII 封装;构造/析构尽量不抛异常。
- 对外接口的契约:明确“是否抛异常/可能抛何种异常”,现代 C++ 统一用
noexcept传达“不抛”语义。 - 与标准库/三方库协作:了解其异常类型;外层以
std::exception或自家基类做统一拦截与日志。
总结一句话:异常是把双刃剑,若能合理设计并配合 RAII 使用,它会让你的程序更健壮;若滥用或忽视规范,它反而会成为隐藏 bug 的温床。
以上就是本文的所有内容了,如果觉得文章对你有帮助,欢迎 点赞⭐收藏 支持!如有疑问或建议,请在评论区留言交流,我们一起进步
分享到此结束啦
一键三连,好运连连!你的每一次互动,都是对作者最大的鼓励!
征程尚未结束,让我们在广阔的世界里继续前行!🚀