神经网络 小土堆pytorch记录
一、神经网络基本骨架 nn_Moudle
1. nn.Module 基础
作用:所有神经网络模块的基类
核心功能:
封装网络层和参数
提供自动梯度计算
支持模型保存/加载
必须实现的方法:
__init__():初始化网络层forward():定义前向传播
码演示了如何创建一个简单的神经网络模型,继承自`nn.Module`,并实现`forward`方法。
import torch
from torch import nnclass Net_test(nn.Module):def __init__(self): # 修正:应该是__init__而不是__int__super(Net_test, self).__init__() # 修正:调用父类的__init__方法def forward(self, input):output = input + 1return outputnet_test = Net_test()
x = torch.tensor(1.0)
output = net_test(x) # 调用forward方法
print(output) # 输出: tensor(2.)拓展
典型神经网络结构
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(3, 16, 3) # 输入通道3,输出通道16,卷积核3x3self.pool = nn.MaxPool2d(2, 2) # 2x2最大池化self.fc = nn.Linear(16*14*14, 10) # 全连接层def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = x.view(-1, 16*14*14) # 展平x = self.fc(x)return x二、卷积概念
视频演示代码
import torch
import torch.nn.functional as F # 包含卷积等操作的函数库# 定义输入矩阵 (5x5)
input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32) # 添加dtype确保数据类型一致# 定义卷积核 (3x3)
kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]], dtype=torch.float32)# 重塑张量形状为 (batch_size, channels, height, width)
input = torch.reshape(input, (1, 1, 5, 5)) # 1个样本, 1个通道, 5x5大小
kernel = torch.reshape(kernel, (1, 1, 3, 3)) # 1个输出通道, 1个输入通道, 3x3卷积核print(input.shape) # torch.Size([1, 1, 5, 5])
print(kernel.shape) # torch.Size([1, 1, 3, 3])# 1. 步长为1的标准卷积
output = F.conv2d(input, kernel, stride=1)
print("步长1:\n", output)# 2. 步长为2的卷积(下采样)
output_2 = F.conv2d(input, kernel, stride=2)
print("步长2:\n", output_2)# 3. 步长为1并添加1像素填充
output_3 = F.conv2d(input, kernel, stride=1, padding=1)
print("填充1:\n", output_3). 卷积操作原理
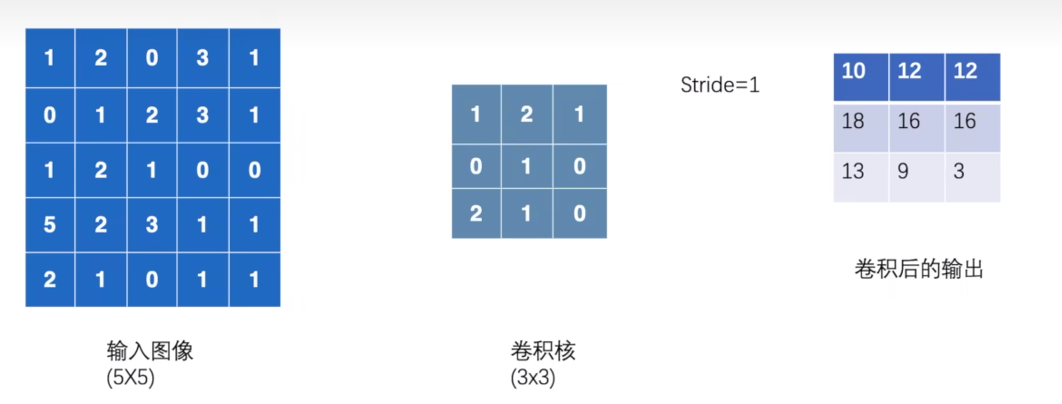
输入矩阵:5×5 的二维数据
卷积核:3×3 的权重矩阵
计算过程:
卷积核在输入上滑动
对应位置元素相乘后求和
输出特征图中的每个值 = ∑(局部区域 × 卷积核)
2. 卷积参数详解
| 参数 | 作用 | 计算公式 |
|---|---|---|
| stride | 滑动步长 | 输出尺寸 = (W - F + 2P)/S + 1 |
| padding | 边界填充 | P = 填充像素数 |
| kernel_size | 卷积核大小 | F×F |
| dilation | 空洞卷积 | 核元素间隔 |
3. 张量形状要求
输入:
(batch_size, in_channels, H, W)卷积核:
(out_channels, in_channels, kH, kW)输出:
(batch_size, out_channels, oH, oW)
4. 输出尺寸计算
通用公式:
输出高度 = floor((输入高度 + 2×padding - 卷积核高度) / stride) + 1 输出宽度 = floor((输入宽度 + 2×padding - 卷积核宽度) / stride) + 1
5. 三种卷积操作对比
| 类型 | 输入尺寸 | 参数 | 输出尺寸 | 特点 |
|---|---|---|---|---|
| 标准卷积 | 5×5 | stride=1, padding=0 | 3×3 | 原始特征提取 |
| 步长2卷积 | 5×5 | stride=2, padding=0 | 2×2 | 下采样特征 |
| 填充卷积 | 5×5 | stride=1, padding=1 | 5×5 | 保持空间尺寸 |
三、神经网络——卷积层
卷积层是CNN的基石,通过局部连接和权重共享高效提取空间特征。理解卷积参数对输出尺寸的影响是设计神经网络的关键。
视频代码
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 加载CIFAR10测试集
dataset = torchvision.datasets.CIFAR10(root="./P_10_dataset",train=False,transform=torchvision.transforms.ToTensor(),# 转换为Tensordownload=True)
# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=64)# 定义测试神经网络
class TestNet(nn.Module):def __init__(self):super(TestNet, self).__init__()# 创建卷积层self.conv1 = Conv2d(in_channels=3, # 输入通道数 (RGB)out_channels=6, # 输出通道数kernel_size=3, # 3x3卷积核stride=1, # 滑动步长padding=0) # 无填充def forward(self, x):x = self.conv1(x) # 应用卷积操作return x# 创建网络实例
test_net = TestNet()
# 创建TensorBoard写入器
writer = SummaryWriter("nn_conv2d_logs")
step = 0 # 步骤计数器# print(test_net)
for data in dataloader:imgs, targets = dataprint("输入形状:", imgs.shape)# 前向传播output = test_net(imgs)print("输出形状:", output.shape) # 输入形状: torch.Size([64, 3, 32, 32])# 将输入图像写入TensorBoardwriter.add_images("input", imgs, step)# 将输出特征图重塑为3通道格式以便可视化# 原始输出是6通道,我们将其重塑为[128, 3, 30, 30]# 输出形状: torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30]output = torch.reshape(output, (-1, 3, 30, 30))# 将输出图像写入TensorBoardwriter.add_images("output", output, step)step = step + 1writer.close() # 关闭写入器卷积层参数详解
Conv2d(in_channels=3, # 输入通道数out_channels=6, # 输出通道数kernel_size=3, # 卷积核大小stride=1, # 滑动步长padding=0, # 边界填充dilation=1, # 空洞卷积率groups=1, # 分组卷积bias=True, # 是否使用偏置padding_mode='zeros' # 填充模式
)卷积层工作原理
特征提取:
每个输出通道对应一个卷积核
卷积核在输入上滑动计算点积
不同卷积核提取不同特征(边缘、纹理等)
参数共享:
同一卷积核在整个输入上共享权重
显著减少参数量
局部连接:
每个输出值只依赖于输入的局部区域
保持空间结构信息
四、神经网络——最大池化的使用
池化层的作用与原理分析
池化层是卷积神经网络中的重要组件,其主要作用是降维和提取主要特征。最大池化层(Max Pooling)是最常用的池化操作,它通过在局部区域取最大值来保留最显著的特征。
池化层的作用:
降维减参:减少特征图的空间尺寸,降低计算复杂度
特征不变性:增强模型对微小位置变化的鲁棒性
防止过拟合:通过降低特征维度减少模型容量
扩大感受野:使后续层能看到更大的原始输入区域
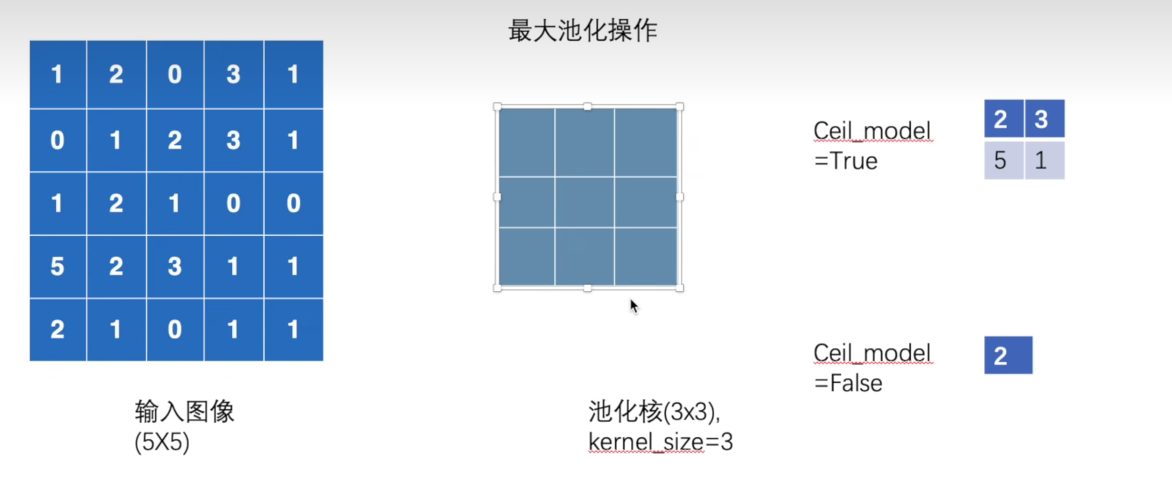
最大池化原理:
将输入特征图划分为固定大小的窗口(如2×2或3×3)
在每个窗口内取最大值作为输出
窗口按指定步长滑动,覆盖整个特征图
没有可学习的参数,是确定性的操作
视频代码
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 加载CIFAR10数据集
dataset = torchvision.datasets.CIFAR10(root="./P_10_dataset",train=False,transform=torchvision.transforms.ToTensor(), # 转换为Tensordownload=True)
# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=64)# input = torch.tensor([[1, 2, 0, 3, 1],
# [0, 1, 2, 3, 1],
# [1, 2, 1, 0, 0],
# [5, 2, 3, 1, 1],
# [2, 1, 0, 1, 1]], dtype=torch.float32)# input = torch.reshape(input, (-1, 1, 5, 5))
# print(input.shape)# 定义测试神经网络(仅包含最大池化层)
class TestNet(nn.Module):def __init__(self):super(TestNet, self).__init__()# 创建最大池化层self.maxpool1 = MaxPool2d(kernel_size=3, # 池化窗口大小3×3ceil_mode=True) # 当剩余区域不足池化核大小时,是否进行池化def forward(self, input):output = self.maxpool1(input) # 应用最大池化return output# 创建网络实例
test_net = TestNet()
# output = test_net(input)
# print(output)# 创建TensorBoard写入器
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, step)output = test_net(imgs)writer.add_images("output", output, step)step = step + 1writer.close()
2. 池化输出尺寸计算
输出高度 = floor((输入高度 + 2×padding - 池化核高度) / 步长) + 1 (ceil_mode=False) 或 输出高度 = ceil((输入高度 + 2×padding - 池化核高度) / 步长) + 1 (ceil_mode=True)
3. 池化层与卷积层的区别
| 特性 | 卷积层 | 池化层 |
|---|---|---|
| 参数 | 可学习权重 | 无参数 |
| 目的 | 特征提取 | 降维和特征不变性 |
| 计算 | 加权求和 | 取最大值/平均值 |
| 输出深度 | 可改变 | 与输入相同 |
池化层是CNN中用于降维和增强特征不变性的关键组件。最大池化通过保留局部区域的最显著特征,使网络对位置变化更加鲁棒。在现代网络设计中,虽然有时被步长卷积替代,但池化层仍然是处理空间信息的有效工具。理解池化参数对输出尺寸的影响是设计高效CNN的基础。
五、神经网络——非线性激活
激活函数是神经网络的"灵魂",它们决定了神经元如何响应输入。ReLU及其变体已成为现代深度学习的标准选择,因其计算高效且能有效缓解梯度消失问题。可以结合鱼书具体理解各个算法的原理。
视频代码
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 创建测试张量 (包含正负值)
input = torch.tensor([[1, -0.5],[-1, 3]])input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)dataset = torchvision.datasets.CIFAR10(root="./P_10_dataset",train=False,transform=torchvision.transforms.ToTensor(), # 转换为Tensordownload=True)
dataloader = DataLoader(dataset, batch_size=64)class Test_net(nn.Module):def __init__(self):super(Test_net, self).__init__()self.relu_1 = ReLU(inplace=False) # 初始化ReLU激活函数 (不修改原始输入)self.sigmoid_1 = Sigmoid() # 初始化Sigmoid激活函数def forward(self, input):# 选择使用ReLU或Sigmoid# output = self.relu_1(input) # ReLU激活output = self.sigmoid_1(input) # Sigmoid激活return outputtest_net = Test_net()
# output = test_net(input)
# print(output)
writer = SummaryWriter("logs_relu")
step = 0
for data in dataloader:imgs, targets = datawriter.add_images("input", imgs, global_step=step)output = test_net(imgs)writer.add_images("output", output, step)step += 1writer.close()
1. 激活函数的作用
引入非线性:使神经网络能够学习复杂模式
特征变换:将输入映射到新的特征空间
梯度控制:影响反向传播中的梯度流动
输出规范化:将输出限制在特定范围
2. 常见激活函数对比
| 激活函数 | 公式 | 输出范围 | 特点 | 适用场景 |
|---|---|---|---|---|
| ReLU | max(0, x) | [0, ∞) | 计算简单,缓解梯度消失 | 隐藏层首选 |
| Sigmoid | 1/(1+e⁻ˣ) | (0, 1) | 平滑,可解释性强 | 输出层(二分类) |
| Tanh | (eˣ - e⁻ˣ)/(eˣ + e⁻ˣ) | (-1, 1) | 中心化输出 | RNN/LSTM |
| Leaky ReLU | max(αx, x) α≈0.01 | (-∞, ∞) | 解决"死神经元"问题 | 深层网络 |
| Softmax | eˣᵢ/Σeˣⱼ | (0, 1) Σ=1 | 概率分布 | 多分类输出层 |
3. 激活函数选择指南
隐藏层:优先使用ReLU及其变体
二分类输出层:Sigmoid
多分类输出层:Softmax
RNN/LSTM:Tanh或Sigmoid
深层网络:Leaky ReLU或ELU
六、神经网络——线性层及其他层介绍
视频代码
import torchvision
import torch
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader# 加载CIFAR10数据集
dataset = torchvision.datasets.CIFAR10(root="./P_10_dataset",train=False,transform=torchvision.transforms.ToTensor(), # 转换为Tensordownload=True)
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)# 定义测试神经网络
class TestNet(nn.Module):def __init__(self):super(TestNet, self).__init__()# 创建卷积层self.linear_1 = Linear(196608, 10)def forward(self, input):output = self.linear_1(input)return output# 创建网络实例
test_net = TestNet()for data in dataloader:imgs, targets = dataprint(imgs.shape)# output = torch.reshape(imgs, (1, 1, 1, -1))output = torch.flatten(imgs)print(output.shape)output = test_net(output)print(output.shape)一般也不平展,不介绍了
七、神经网络——搭建小实战和Sequential的使用
Sequential容器是构建顺序网络结构的高效工具,它简化了前向传播的实现。理解各层参数如何影响输出尺寸是设计有效CNN的关键。
视频代码
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriterclass Test_net(nn.Module):def __init__(self):super(Test_net, self).__init__()# self.conv_1 = Conv2d(3, 32, 5, padding=2)# self.maxpool_1 = MaxPool2d(2)# self.conv_2 = Conv2d(32, 32, 5, padding=2)# self.maxpool_2 = MaxPool2d(2)# self.conv_3 = Conv2d(32, 64, 5, padding=2)# self.maxpool_3 = MaxPool2d(2)# self.flatten = Flatten()# self.linear_1 = Linear(1024, 64)# self.linear_2 = Linear(64, 10)# 使用Sequential容器简化网络定义self.model_1 = Sequential(# 第一层卷积:输入通道3(RGB),输出通道32,5x5卷积核,填充2保持尺寸Conv2d(3, 32, 5, padding=2),# 2x2最大池化,步长2(默认等于池化核大小)MaxPool2d(2),# 第二层卷积:输入32通道,输出32通道Conv2d(32, 32, 5, padding=2),# 再次池化MaxPool2d(2),# 第三层卷积:输入32通道,输出64通道Conv2d(32, 64, 5, padding=2),# 第三次池化MaxPool2d(2),# 展平层:将多维特征图转换为一维向量Flatten(),# 全连接层:输入1024维,输出64维Linear(1024, 64),# 输出层:输入64维,输出10维(对应CIFAR-10的10个类别)Linear(64, 10))def forward(self, x): # 顺序通过所有层x = self.model_1(x)return x# def forward(self, x):# x = self.conv_1(x)# x = self.maxpool_1(x)# x = self.conv_2(x)# x = self.maxpool_2(x)# x = self.conv_3(x)# x = self.maxpool_3(x)# x = self.flatten(x)# x = self.linear_1(x)# x = self.linear_2(x)# return x# 创建网络实例
test_net = Test_net()
print(test_net) # 打印网络结构
# 创建模拟输入:64张32x32的RGB图像
input = torch.ones((64, 3, 32, 32))
# 前向传播
output = test_net(input)
print(output.shape)
# 使用TensorBoard可视化网络结构
writer = SummaryWriter("logs_seq")
writer.add_graph(test_net, input) # 添加计算图
writer.close()1. Sequential容器的作用
简化代码:将多层网络组合为单一模块
顺序执行:自动按顺序执行各层
结构清晰:使网络定义更易读和维护
打印友好:整体打印网络结构
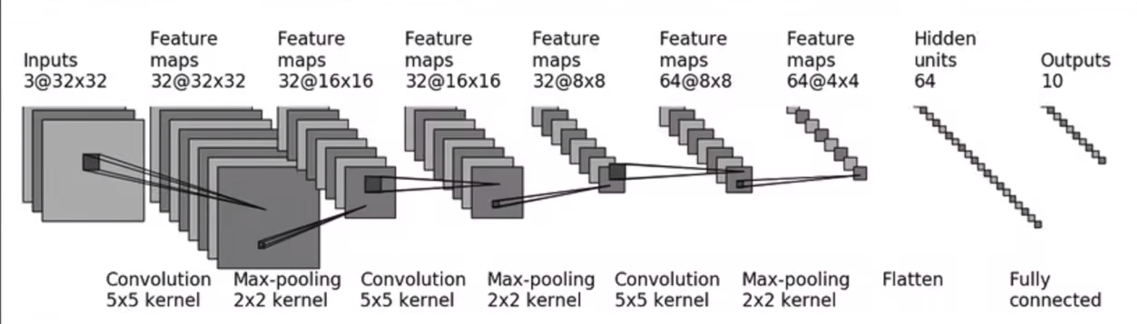
2. 网络结构参数推导
| 层 | 参数 | 计算 | 输出尺寸 |
|---|---|---|---|
| 输入 | - | - | [64, 3, 32, 32] |
| Conv1 | in=3, out=32, kernel=5, padding=2 | (32-5+4)/1+1=32 | [64, 32, 32, 32] |
| MaxPool1 | kernel=2 | 32/2=16 | [64, 32, 16, 16] |
| Conv2 | in=32, out=32, kernel=5, padding=2 | (16-5+4)/1+1=16 | [64, 32, 16, 16] |
| MaxPool2 | kernel=2 | 16/2=8 | [64, 32, 8, 8] |
| Conv3 | in=32, out=64, kernel=5, padding=2 | (8-5+4)/1+1=8 | [64, 64, 8, 8] |
| MaxPool3 | kernel=2 | 8/2=4 | [64, 64, 4, 4] |
| Flatten | - | 64×4×4=1024 | [64, 1024] |
| Linear1 | in=1024, out=64 | - | [64, 64] |
| Linear2 | in=64, out=10 | - | [64, 10] |
3. 关键层解析
卷积层(Conv2d):
核心参数:输入通道、输出通道、卷积核大小
尺寸公式:
输出尺寸 = (输入尺寸 - 卷积核大小 + 2×填充)/步长 + 1本例:使用padding=2保持尺寸不变
池化层(MaxPool2d):
核心参数:池化核大小
默认步长=池化核大小
作用:降维和特征不变性
展平层(Flatten):
作用:将多维特征图转换为一维向量
输入:
[batch, channels, height, width]输出:
[batch, channels×height×width]
全连接层(Linear):
核心参数:输入维度、输出维度
作用:学习全局特征组合
实际使用时,往往需要再丰富一下
实际应用建议
添加激活函数:
self.model_1 = Sequential(Conv2d(3, 32, 5, padding=2),nn.ReLU(), # 添加激活函数MaxPool2d(2),... )添加正则化:
self.model_1 = Sequential(Conv2d(3, 32, 5, padding=2),nn.BatchNorm2d(32), # 批量归一化nn.ReLU(),... )添加Dropout防止过拟合:
self.model_1 = Sequential(...,Flatten(),nn.Dropout(0.5), # 全连接层前添加DropoutLinear(1024, 64),... )学习率调整:
optimizer = torch.optim.Adam(test_net.parameters(), lr=0.001)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)