YOLOv8目标检测网络结构理论
目录
YOLOv8的网络结构图:
Backbone
卷积块(Conv Block)
Conv2d层
BatchNorm2d层
SiLU激活函数
瓶颈块(Bottleneck Block)
C2f 模块结构
Neck
SPPF(空间金字塔池化快速)
PAN - FPN
Head
结构1.卷积层和激活函数:
2.预测层(Prediction Layers):
3.非极大值抑制
其他优化
YOLOv5 与 YOLOv8 的主要区别:
YOLOv8的网络结构图:
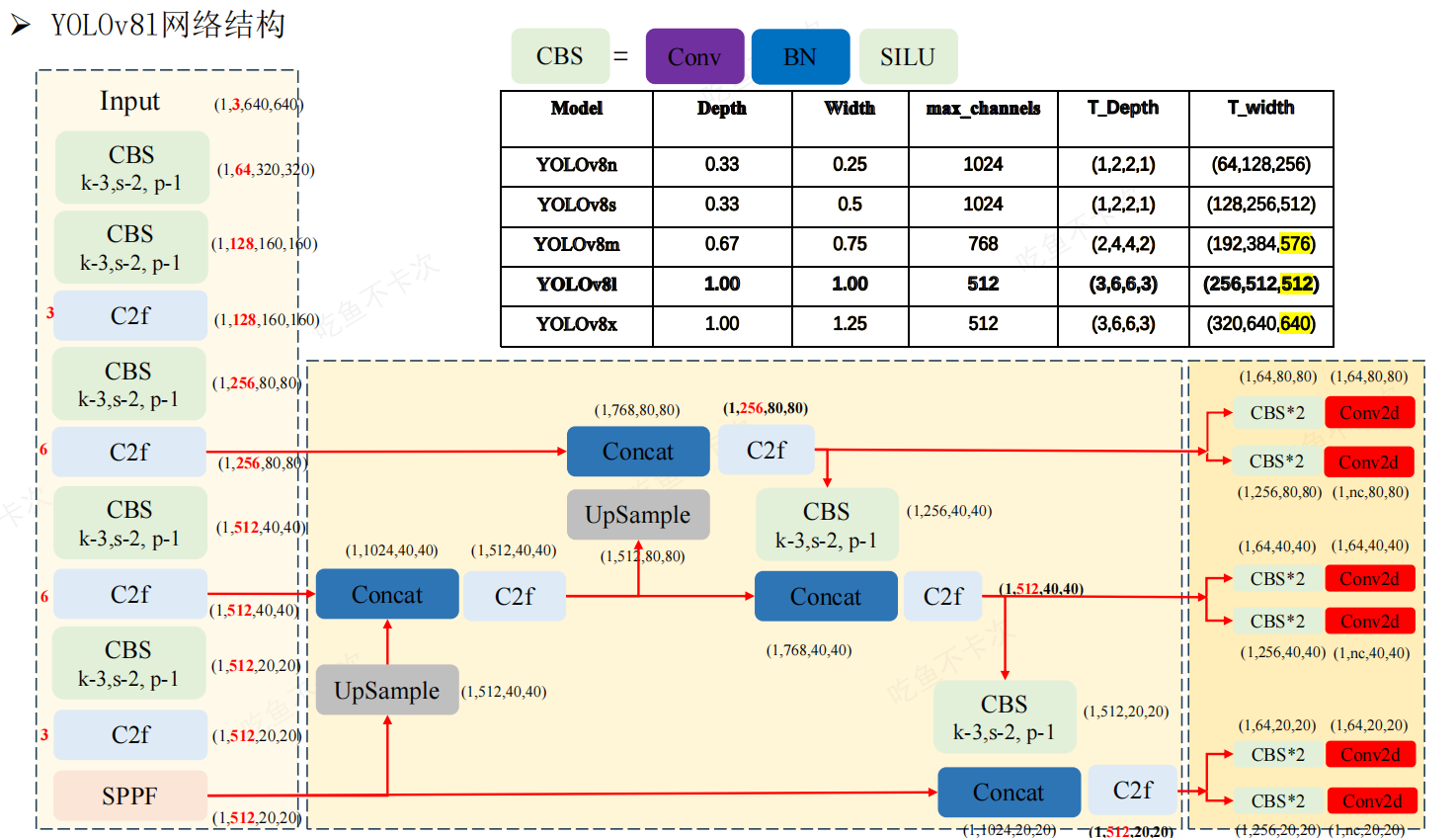
YOLOv8的网络结构主要由以下三大部分组成 :
Backbone
Backbone部分负责特征提取,采用了一系列卷积和反卷积层,同时使用了残差连接和瓶颈结构来减小网络的大小并提高性能。该部分采用了C2f模块作为基本构成单元,与YOLOv5的C3模块相比,C2f模块具有更少的参数量和更优秀的特征提取能力。具体来说,C2f模块通过更有效的结构设计,减少了冗余参数,提高了计算效率。此外,Backbone部分还包括一些常见的改进技术,如深度可分离卷积(Depthwise Separable Convolution)和膨胀卷积(Dilated Convolution),以进一步增强特征提取的能力。
卷积块(Conv Block)

Conv2d层
卷积是一种数学运算,涉及将一个小矩阵(称为核或滤波器)滑动到输入数据上,执行元素级的乘法,并将结果求和以生成特征图。“2D”在Conv2d中表示卷积应用于两个空间维度,通常是高度和宽度。
- k(kernel数量):滤波器或核的数量,代表输出体积的深度,每个滤波器负责检测输入中的不同特征,
- s(stride步幅):步幅,指滤波器/核在输入上滑动的步长。较大的步幅会减少输出体积的空间维度。
- p(padding填充):填充,指在输入的每一侧添加的额外零边框,有助于保持空间信息,并可用于控制输出体积的空间维度。
- c(channels输入通道数):输入的通道数。例如,对于RGB图像,c为3(每个颜色:红色、绿色和蓝色各一个通道)。
BatchNorm2d层
批归一化(BatchNorm2d)是一种在深度神经网络中使用的技术,用于提高训练稳定性和收敛速度。在卷积神经网络(CNN)中BatchNorm2d层特定地对2D输入进行批归一化,通常是卷积层的输出。它通过在每个小批次的数据中标准化特征,使每个特征在小批次中的均值接近0、方差接近1,确保通过网络的数据不会太大或太小,这有助于防止训练过程中出现的问题。
SiLU激活函数
SiLU(Sigmoid Linear Unit)激活函数,也称为Swish激活函数,是神经网络中使用的激活函数。SiLU激活函数定义如下:
其中,σ(x)是Sigmoid函数,定义为:
SiLU的关键特性是它允许平滑的梯度,这在神经网络训练过程中是有益的。平滑的梯度可以帮助避免如梯度消失等问题,这些问题会阻碍深度神经网络的学习过程.
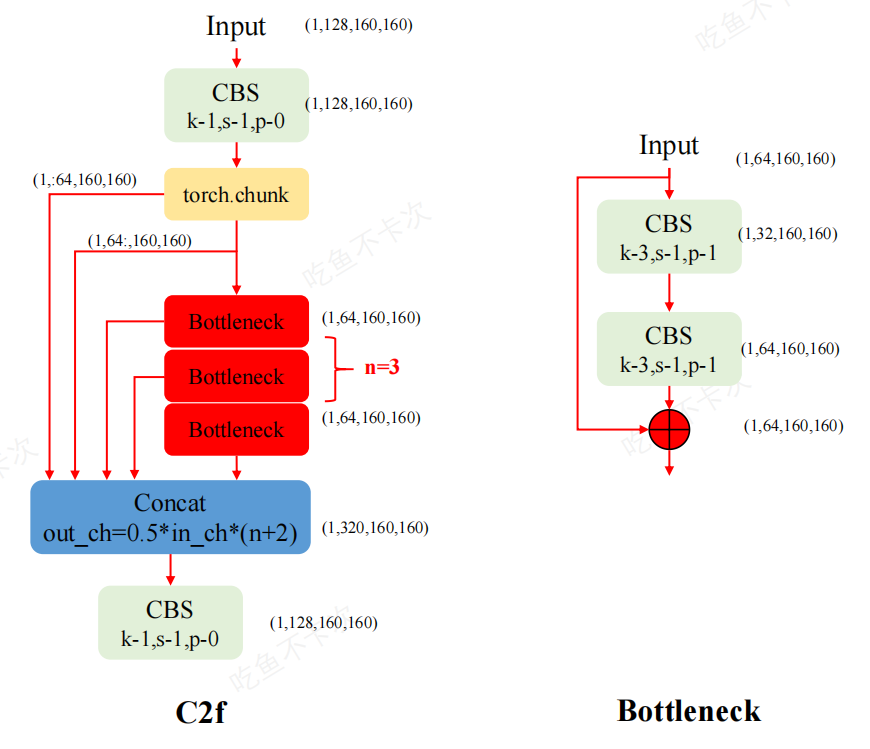
瓶颈块(Bottleneck Block)
YOLOv8瓶颈块结构说明
- 卷积层1(Conv 1):首先输入通过一个卷积层,通常卷积核大小为(1 x 1),用于减少特征图的通道数。
- 卷积层2(Conv 2):紧接着输入通过一个卷积层,通常卷积核大小为(3 x 3),用于提取特征并增加感受野。
- 跳跃连接 (Skip Connection):在卷积层之间加入跳跃连接,将输入直接连接到输出。这种连接方式可以缓解梯度消失问题,帮助网络更好地学习。
- 拼接(Concatenate):最后,将跳跃连接后的输出与卷积层的输出进行拼接,形成最终输出。
功能和优势
- 减少参数和计算量:通过(1 x 1)卷积层减少特征图的通道数,降低计算复杂度。
- 增加网络深度和非线性能力:通过增加(3 x3)卷积层,提取更多特征,提高模型表达能力。
- 跳跃连接:缓解梯度消失问题,帮助训练更深的网络。
C2f 模块结构
- C2f块: 首先由一个卷积块(Conv)组成,该卷积块接收输入特征图并生成中间特征图。
- 特征图拆分: 生成的中间特征图被拆分成两部分,一部分直接传递到最终的Concat块,另一部分传递到多个Bottieneck块进行进一步处理。
- Bottleneck块: 输入到这些Botleneck块的特征图通过一系列的卷积、归一化和激活操作进行处理,最后生成的特征图会与直接传递的那部分特征图在Concat块进行拼接(Concat)。通过多个Bottleneck块进一步提炼和增强特征,这些Bottle neck块可以捕捉更复杂的模式和细节。
- 模型深度控制: 在C2f模块中,Botleneck模块的数量由模型的depth_muliple参数定义,这意味着可以根据需求灵活调整模块的深度和计算复杂度,
- 最终卷积块:拼接后的特征图会输入到一个最终的卷积块进行进一步处理,生成最终的输出特征图.通过Concat块将直接传递的特征图和处理后的特征图进行融合,使得模型可以综合利用多尺度、多层次的信息输出生成最终特征图.
Neck
Neck部分负责多尺度特征融合,通过将来自Backbone不同阶段的特征图进行融合,增强特征表示能力。具体来说,YOLOv8的Neck部分包括以下组件:
SPPF(空间金字塔池化快速)
SPPF模块(Spatial Pyramid Pooling Fast):用于不同尺度的池化操作,将不同尺度的特征图拼接在一起,提高对不同尺寸目标的检测能力。
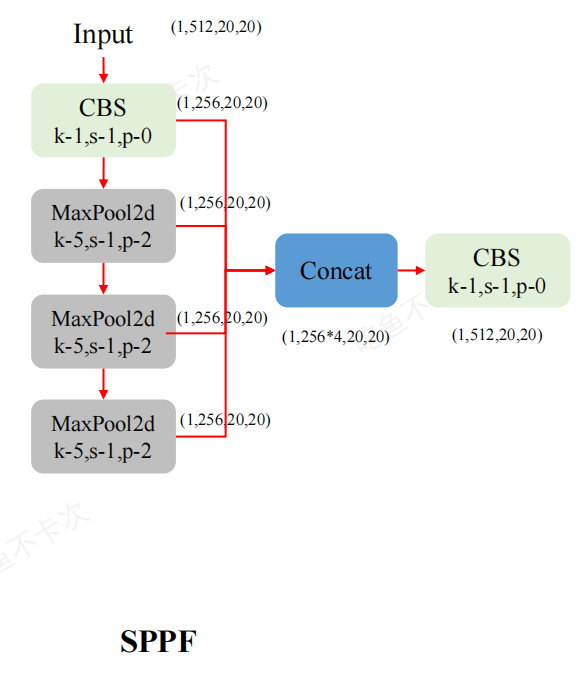
SPPF伪代码:
import torch
import torch.nn as nnclass SPPFBlock(nn.Module):
def __init__(self, in_channels, out_channels, pool_size=5):
super(SPPFBlock, self).__init__()
self.initial_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_channels),
nn.SiLU()
)
self.pool1 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2)
self.pool2 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2)
self.pool3 = nn.MaxPool2d(kernel_size=pool_size, stride=1, padding=pool_size // 2)
self.final_conv = nn.Sequential(
nn.Conv2d(out_channels * 4, out_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_channels),
nn.SiLU()
)
def forward(self, x):
x_initial = self.initial_conv(x)
x1 = self.pool1(x_initial)
x2 = self.pool2(x1)
x3 = self.pool3(x2)
x_concat = torch.cat((x_initial, x1, x2, x3), dim=1)
x_final = self.final_conv(x_concat)
return x_final# 使用示例
sppf_block = SPPFBlock(in_channels=64, out_channels=128)
output = sppf_block(input_tensor)
PAA模块(Probabilistic Anchor Assignment):用于智能地分配锚框,以优化正负样本的选择,提高模型的训练效果。
PAN模块(Path Aggregation Network):包括两个PAN模块,用于不同层次特征的路径聚合,通过自底向上和自顶向下的路径增强特征图的表达能力。
PAN - FPN
在 YOLOv8 中,PAN(特征金字塔) -FPN(路径聚合网络)的实现结合了 FPN 和 PAN 的优点,具体如下:
1.多尺度特征提取:
YOLOv8 的主干网络首先提取出不同尺度的特征图。通过 FPN 构建自顶向下的特征金字塔,实现多尺度特征的初步融合。
2.双向特征融合:
在 FPN 的基础上,引入 PAN 的自底向上路径,将低层特征逐层传递到高层,进一步丰富多尺度特征。通过横向连接,将不同尺度的特征进行融合,确保每一层的特征都包含丰富的上下文信息。
3.增强的特征表示:
PAN-FPN 通过双向路径的融合,使得特征图包含更丰富的上下文信息和语义信息,增强了模型对不同尺度目标的检测能力。
Head
Head部分负责最终的目标检测和分类任务,包括一个检测头和一个分类头:
结构1.卷积层和激活函数:
Head部分通常包括若干卷积层和激活函数。这些卷积层用于进一步处理Neck部分输出的特征图,以提取更多的高级特征。常见的激活函数包括ReLU或Leaky ReLU,能够引入非线性,从而提升特征表达能力。
2.预测层(Prediction Layers):
在YOLOv8中,预测层是关键组件,负责生成最终的检测结果。预测层包括三个主要输出:
- 1.边界框回归(Bounding Box Regression):预测目标的位置和大小。通常输出四个值,分别对应边界框的中心坐标(x,y)和宽度、高度(w,h)。
- 2.置信度评分(Confidence Scores):预测每个边界框内是否包含目标,以及目标的置信度。
- 3.类别概率(Class Probabilities):预测目标属于每个类别的概率。
3.非极大值抑制
(Non-Maximum suppression, NMS)最终的预测结果会经过非极大值抑制处理,以去除重复的检测框。NMS保留置信度最高的边界框,并移除与之重罍度高的其他边界框,确保每个目标只被检测一次。
其他优化
除了上述结构外,YOLOv8还引入了一些新的优化技术,如:
Anchor-free机制:减少了锚框的超参数设置,通过直接预测目标的中心点来简化训练过程。
自适应NMS(Non-Maximum Suppression):改进了传统的NMS算法,通过自适应调整阈值,减少误检和漏检,提高检测精度自动混合精度训练(Automatic Mixed Precision Training):通过在训练过程中动态调整计算精度,加快训练速度,同时减少显存占用。
YOLOv5 与 YOLOv8 的主要区别:
YOLOv5 与 YOLOv8 的主要区别-CSDN博客