大数据技术入门精讲(Hadoop+Spark)
传统数据处理架构
结构化数据(具有固定格式或模式的数据。它通常存储在关系型数据库中,如MySQL、Oracle等。):数据库,数据仓库
非结构化(非结构化数据是指没有固定格式或模式的数据,通常是文本、图像、音频、视频等形式),半结构化数据(半结构化数据格式包括JSON、XML、HTML等):NoSQL数据库,并发程序。
现在数据海量增大后,需要更好的管理处理数据。
结构化数据中单机处理速度慢MPP架构邨彩扩展性和热点问题。
NoSQL数据库只负责存储,不负责计算。
*************
是否存在一套整体解决方案,可以存储海量结构化,半结构化,非结构化数据,并且可以处理海量数据,扩展性还很强。
——————就i是 大数据技术。 一种 为了满足数据达到海量后,对其进行存储和计算的一种技术。
特征: 1. 规模大;2.生成和处理速度极快;3.数据类型多样性;4.价值大,但价值密度低(有价值,但是数据量很大所以密度低)
-------------------------------
大数据应用场景:
离线处理场景,实时处理场景: 区分主要是依据数据是有界的还是无界的。 (实时数据就是无界的)
离线处理场景
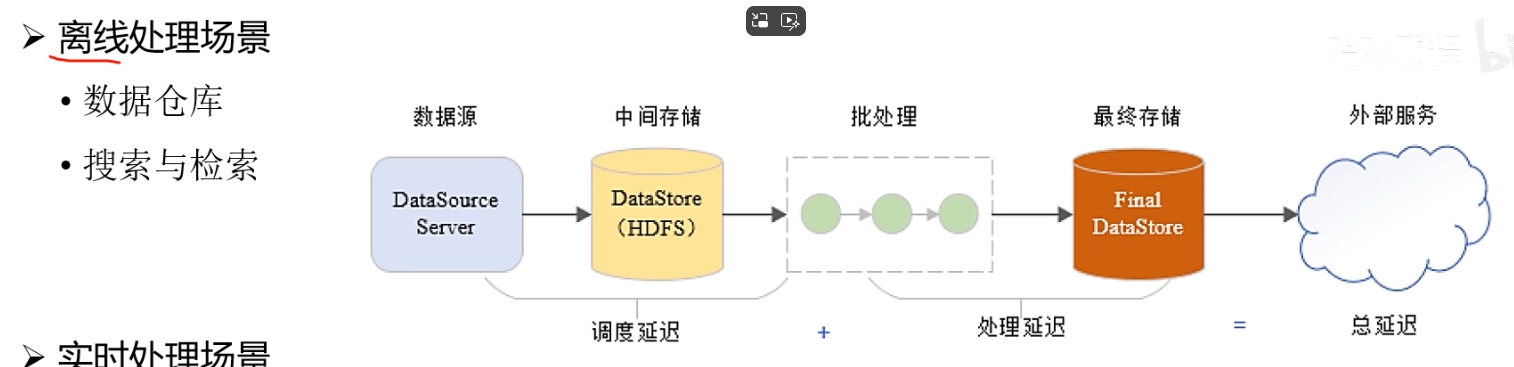
实时处理场景
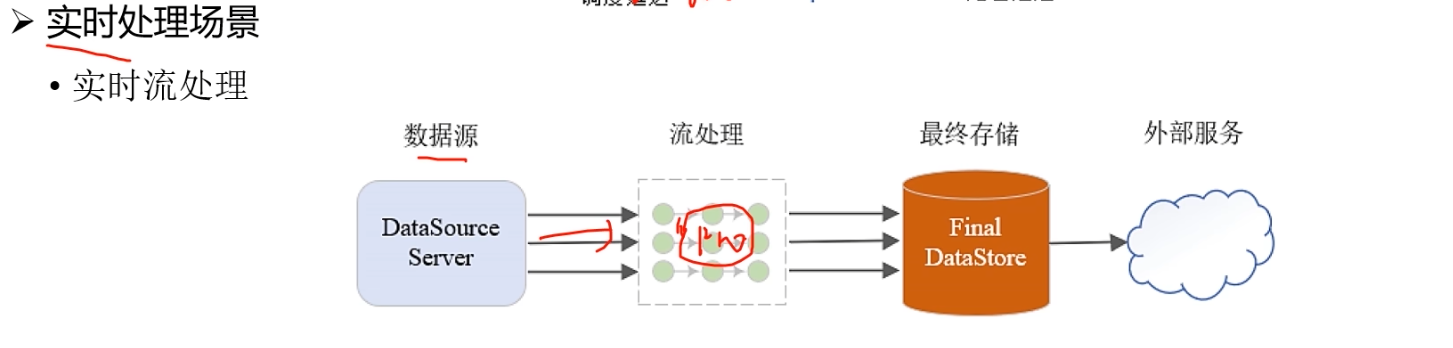
大数据计算技术的思想:移动计算而非移动数据,
基于大数据的搜索与检索
基于大数据的数据挖掘
基于大数据的实时流处理
大数据生态架构:
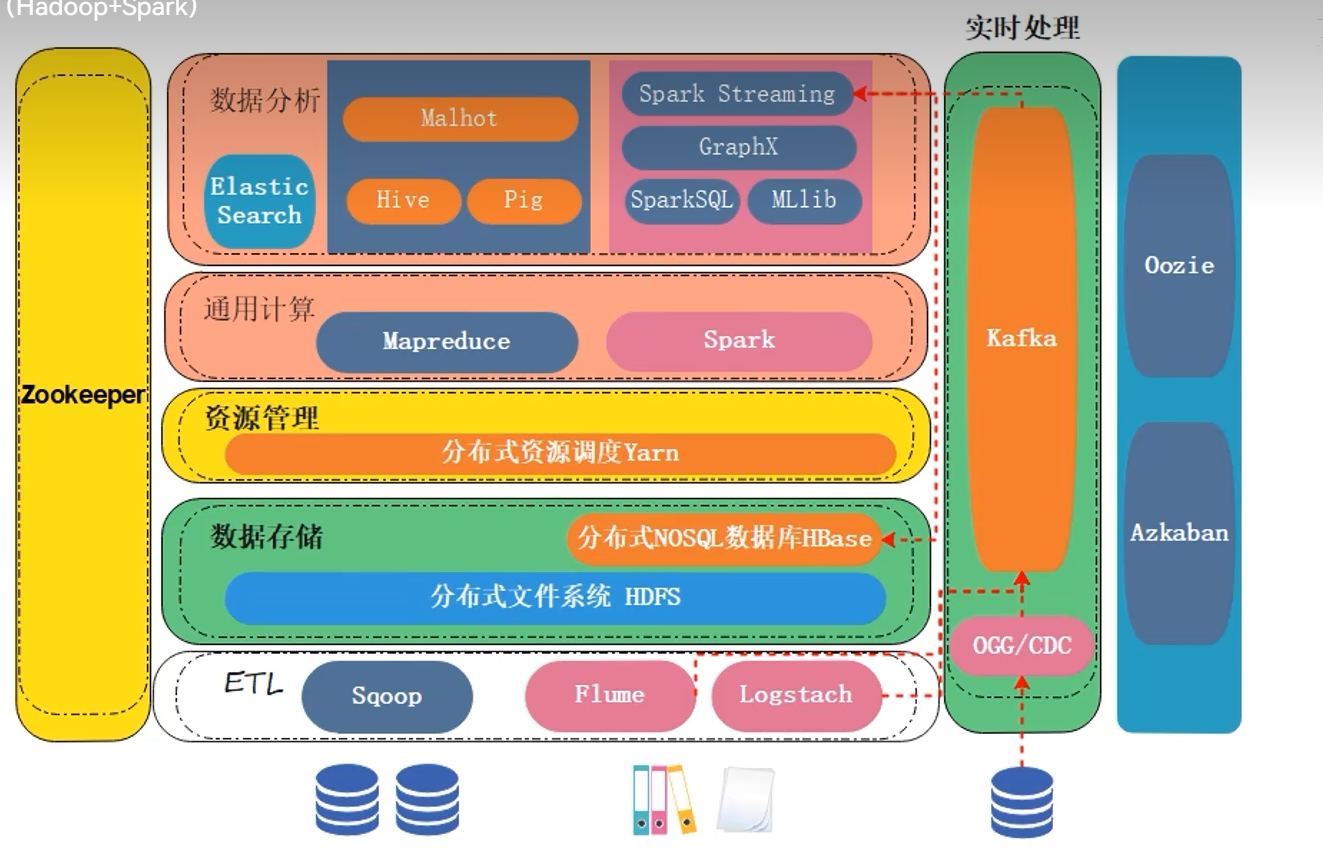
HDFS(更注重把海量数据存下,而不关注速度)
优点:高容错,高可用,高扩展
构建成本低,安全可靠
适合大规模离线批处理
缺点:不适合低延迟数据访问
不支持并发写入
不适合大量小文件存储(也是因为他计算的逻辑是移动计算而不是移动数据,所以小文件要移动很多次调度)
不支持文件随机修改(仅支持追加写入)
文件存储过程: 文件一般被按照128M拆分成多个block块,然后存储在结点中,一个结点有多个block,结点也会定时上报存储了哪些数据,以便及时发现数据是否丢失等情况。

他的架构是这样的:
下面datanode存数据,相同颜色的是同样的数据(备份防丢),顶上的是管理单元, active是直接管理单元,standby是备份的管理信息,即备份结点(替补)。
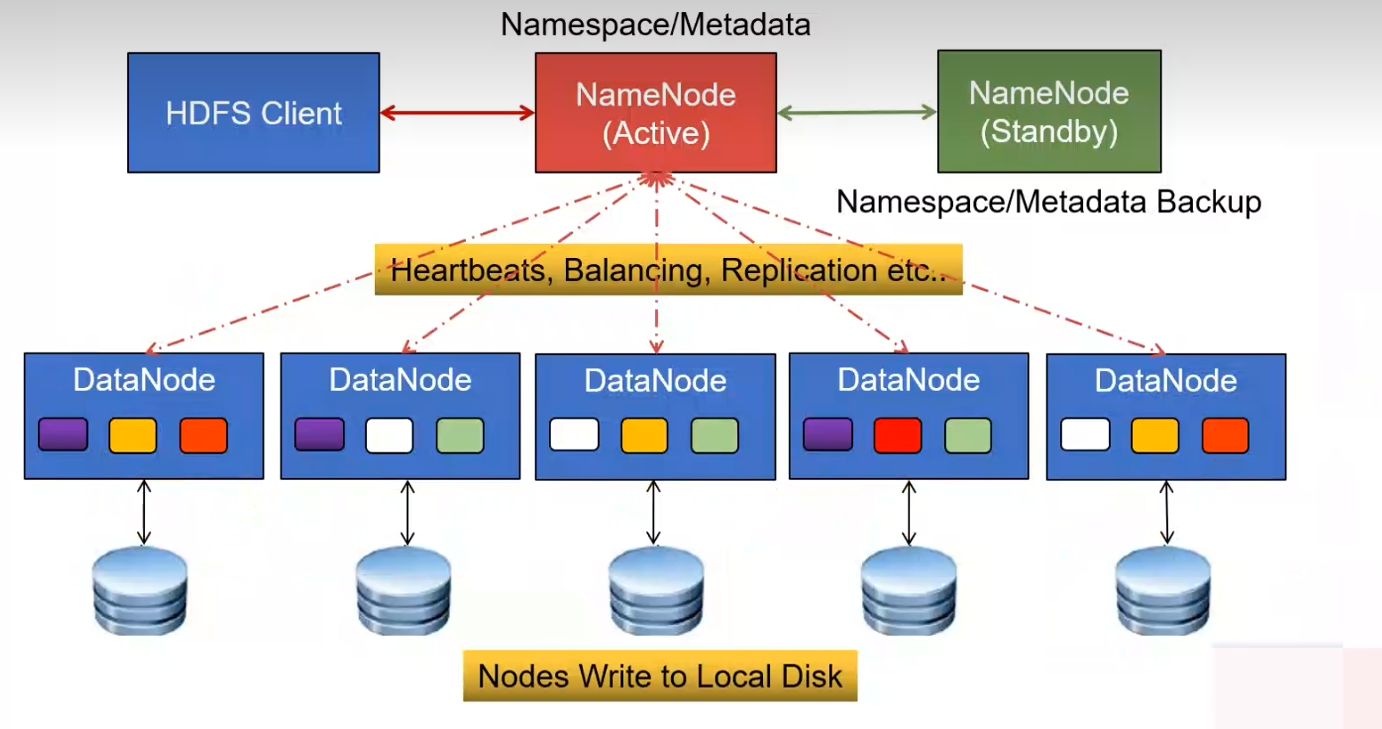
一个block块是128M,
一个数据会有三份,放在不同的node里面,怎么放置呢? (机房——机架——存储结点)
第一个副本存在最近的结点。 即 跳数最少的位置,如果两个位置跳数一样,就会选择最空闲的一跳。
第二个block会存在不同的机架,避免同时丢失的风险,因为同一个机架会接同一个交换机同一个电源,如果掉电或者坏了就会都丢了。
第三个block就会找与第二个block相同机架的其他结点。
最终block存在本地的磁盘上