【从源码角度深度理解 Python 的垃圾回收机制】:第1课引用计数篇
【从源码角度深度理解 CPython 的垃圾回收机制】:第1课引用计数篇-共计2课程
这里准确点应该是CPython解释器的垃圾回收机制,为了让大家不懵所以标题展示了使用Python。如果是Jython就没有这个原理,是另外的回收方式。
写这篇文章小故事:本来我是想学习下Python的进程/线程/协程,先从进程开始学习,然后知道了进程是操作系统进行资源分配的最小单位,线程是CPU调度的最小单位(也是操作系统能够进行运算调度的最小单位)。所以一个进程必定有一个线程也就是主线程来执行。(这里你可以把进程想象成一个“舞台”,它提供了布景、道具和空间(资源)。而线程就是在这个舞台上表演的“演员”。没有演员(线程),舞台(进程)再华丽也无法进行表演(执行程序)。因此,至少需要一个演员(线程)在舞台上(进程)进行表演,程序才能运行。所以,一个进程不可能没有线程。)
学到这里看起来是学习进程/线程/协程,没什么问题吧,那我是怎么一步步沦陷到Python的垃圾回收机制上的呢?这里还要从疑问入手。
学完了进程,也了解了进程,这个时候我产生了疑问:
疑问1:如果我有10个进程,如果是单核计算机,是不是每个进程都要等待排序进行?
答案1:是的,在单核 CPU 上,这 10 个进程不能真正并行运行,它们会“轮流执行”。但它们看起来像是同时运行,这是操作系统通过 时间片轮转(Time-Slicing) 实现的“并发”(concurrency),而不是“并行”(parallelism)。时间片长短是由操作系统的调度器决定的几毫秒-几百毫秒。
这个时候我就看了下虚拟机的电脑核心数:于是又产生了疑问
疑问2:这几个参数什么意思
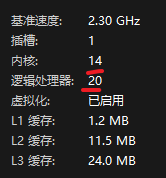
答案2:插槽1表示一个物理CPU的槽位置。内核14 表示有14个物理内核;逻辑处理器20:表示可能机器有超线程技术升让一个物理内核模拟成2个或者多个逻辑核,让系统识别有20个。其他的信息暂时不需要了解
疑问3:那如果我的电脑是20个逻辑核是不是有20个线程时,就可以每个逻辑核一个线程的运行?
答案3:对的,这个CPU可以同时处理(调度和执行)最多20个线程。
疑问4:为什么python不能用多线程呢?
答案4:Python对于CPU密集型不建议使用多线程,因为这个是会因为GIL锁导致无法使用多线程,其实一个时刻只有一个线程在运行,并不会用多核的优势。但是对于IO密集型的操作是可以的,比如一个线程等待读写磁盘时,这个时候CPU会让出来给其他线程用。
疑问5:CPython解释器为什么会有GIL锁呢?
答案5:简化CPython的内存管理和内部实现,尤其是在多线程环境下的线程安全问题。核心原因:保护引用计数机制:CPython使用引用计数作为其主要的内存管理机制。每个Python对象都有一个计数器,记录有多少变量或对象引用了它。当引用计数变为0时,对象占用的内存就会被立即释放。
从引用计数这里就引导了Python的垃圾回收机制
首先需要说明的是,“垃圾回收”本质上是一种内存管理机制,它决定了程序如何分配和释放内存。所谓“垃圾”,指的是程序中不再使用的内存空间,例如已创建但不再被引用的对象或方法所占用的资源。
有个很好的例子就是我们使用C语言时,是需要自己创建内存空间和释放内存空间的,比如:
#include <stdio.h>
#include <stdlib.h>int main() {int n = 5; // 假设我们要创建包含5个整数的数组int *arr;// 使用malloc为数组分配内存arr = (int*) malloc(n * sizeof(int));if (arr == NULL) { // 检查内存是否成功分配printf("内存分配失败\n");return 1;}// 初始化数组元素for (int i = 0; i < n; ++i) {arr[i] = i + 1;}// 打印数组元素printf("数组元素:");for (int i = 0; i < n; ++i) {printf("%d ", arr[i]);}printf("\n");// 释放已分配的内存free(arr);return 0;
}可以看到代码里面用了malloc 申请空间,用完后使用free释放空间。当我们使用高级语言的时候发现,我们已经不再需要自己申请和释放空间了。比如Python,其实是Python的解释器给我们回收了,那它怎么回收的呢?有什么策略呢?请看下面的内容讲解。
#! /bin/python
count = 10
print(count)一、Python 内存管理的基石:引用计数(Reference Counting)
Python 的内存管理主要依赖于引用计数(Reference Counting)机制。这是 Python 垃圾回收的第一道防线,也是最基础、最高效的机制。
1.1 什么是引用计数?
在 Python 中,每一个对象都有一个“引用计数”(ob_refcnt),用于记录有多少个变量或对象引用了它。当一个对象的引用计数降为 0 时,Python 会立即回收该对象所占用的内存。
a = [1, 2, 3] # 列表 [1,2,3] 的引用计数为 1
b = a # 又有一个变量引用它,引用计数变为 2
c = b # 引用计数变为 3b = None # b 不再引用,引用计数变为 2
c = "hello" # c 不再引用,引用计数变为 1
a = None # a 不再引用,引用计数变为 0 → 对象被立即回收1.2 引用计数的优点
- 实时性:对象一旦不再被引用,内存立即释放。
- 简单高效:无需复杂的算法,开销小。
1.3 Python中查看引用计数
import sys# 创建一个对象
my_list = [1, 2, 3]# 查看该对象的引用计数
ref_count = sys.getrefcount(my_list)
print(f"引用计数: {ref_count}")
输出结果:引用计数: 2
这里为什么会出现2次呢,是因为sys.getrefcount()调用时也会引用一次;
- 当你把对象传入
sys.getrefcount(obj)时,函数参数会创建一个临时引用,因此结果至少比你预期的多 1。 - 例如,如果你只定义了一个变量
my_list指向列表,你可能以为引用计数是 1,但getrefcount返回的是 2
import sysa = [1, 2, 3] # 引用计数 = 1 (a 指向它)
b = a # 引用计数 = 2 (a 和 b 都指向它)print(sys.getrefcount(a)) # 输出: 3 ❗(因为 getrefcount 调用时也临时引用了)# 注意:这个 3 来自:
# 1. 变量 a
# 2. 变量 b
# 3. getrefcount 函数参数的临时引用1.4 源码解释
1.4.1 问题:CPython是如何知道计数器等于0了,是不是每次触发计数器都会监测一次,类似如下代码清理该对象的内存空间?
def monitor(count): if count <=0: print("开始处理")……答案:是的,每次引用计数发生变化时(增或减),CPython 都会“监测”这个值。当减少操作导致计数变为 0 时,它会立即调用一个“清理函数”来释放对象内存。但这个不是使用Python而是使用C语言。
1. 技术细节:CPython 是怎么做到的?
想象每个对象住在一个“房间”里,门口挂着一个计数牌(引用计数),还有一个“自动销毁按钮”:
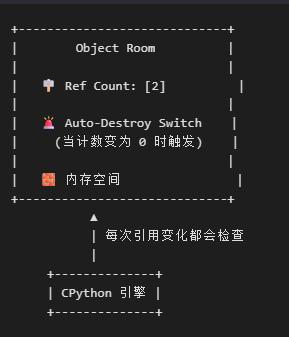
每当有人进入或离开房间(引用增加或减少),守卫(CPython 引擎)就会更新计数牌,并检查是否为 0。如果是,就按下“自动销毁按钮”。
类代码如下:
// 简化版 PyObject 结构(实际在 object.h 中)
typedef struct _object {Py_ssize_t ob_refcnt; // ← 引用计数器,就是它!struct _typeobject *ob_type; // 对象类型
} PyObject;CPython源码类代码:
/* Nothing is actually declared to be a PyObject, but every pointer to* a Python object can be cast to a PyObject*. This is inheritance built* by hand. Similarly every pointer to a variable-size Python object can,* in addition, be cast to PyVarObject*.*/
typedef struct _object {_PyObject_HEAD_EXTRAPy_ssize_t ob_refcnt; // 引用计数器struct _typeobject *ob_type;
} PyObject;2. 当引用减少时发生了什么?
#define Py_DECREF(op) \do { \PyObject *_py_decref_tmp = (PyObject *)(op); \if (--_py_decref_tmp->ob_refcnt == 0) { \_Py_Dealloc(_py_decref_tmp); \} \} while (0)我们来拆解这段代码,其中关键一步:
--_py_decref_tmp->ob_refcnt == 0这行代码做了两件事:
--:先将引用计数减 1。== 0:然后立即判断是否等于 0。
✅ 如果等于 0,就调用 _Py_Dealloc → 这个函数会调用对象类型的 tp_dealloc 方法(比如 list_dealloc、dict_dealloc),真正释放内存。
3. 举个真实例子:del my_list
my_list = [1, 2, 3]
del my_list # 引用计数从 1 → 0在 C 层发生了什么?
del my_list触发Py_DECREF(my_list)ob_refcnt从 1 减到 0Py_DECREF检测到== 0- 调用
_Py_Dealloc(my_list) - 找到
list类型的tp_dealloc函数(即list_dealloc) list_dealloc释放列表内部的数组和对象- 最终调用
free()归还内存
这里为了让读者朋友看懂我用了类代码,CPython3.8.14的源码如下:
/** CPython 引用计数核心函数:_Py_INCREF 和 _Py_DECREF* * 这些函数是 Python 自动内存管理的基石。* 所有 Python 对象的创建、使用和销毁都依赖于引用计数。* * 注意:此版本是用于调试模式(如 --with-pydebug 编译)的实现,* 包含文件名、行号追踪和负引用检测。*//*** 增加一个 Python 对象的引用计数* * @param op: 指向 PyObject 的指针* * 这是一个静态内联函数,性能极高,直接嵌入调用处。*/
static inline void _Py_INCREF(PyObject *op)
{/* 增加全局引用计数统计(仅在调试模式下有效) */_Py_INC_REFTOTAL;/* 关键操作:引用计数 +1 */op->ob_refcnt++;
}/*** 增加引用的宏定义* * 使用 _PyObject_CAST(op) 确保类型安全(转换为 PyObject*)* 自动传入当前文件名和行号,便于调试*/
#define Py_INCREF(op) _Py_INCREF(_PyObject_CAST(op))/*** 减少一个 Python 对象的引用计数* * 如果引用计数减到 0,自动调用 _Py_Dealloc 释放对象* * @param filename: 调用此函数的源文件名(用于调试)* @param lineno: 调用此函数的行号(用于调试)* @param op: 指向 PyObject 的指针* * 注意:filename 和 lineno 参数可能未使用,因此用 (void) 抑制编译器警告*/
static inline void _Py_DECREF(const char *filename, int lineno,PyObject *op)
{/* 抑制 "unused parameter" 编译警告 */(void)filename;(void)lineno;/* 减少全局引用计数统计(仅在调试模式下有效) */_Py_DEC_REFTOTAL;/* 关键操作:引用计数 -1 */if (--op->ob_refcnt != 0) {/* 如果引用计数不为 0,说明还有其他地方引用该对象 *//* 什么都不做,对象继续存活 */#ifdef Py_REF_DEBUG/* 在调试模式下,检查是否出现负引用(严重错误) */if (op->ob_refcnt < 0) {/* 引用计数为负!说明发生了 double free 或逻辑错误 *//* 触发致命错误,打印详细信息并终止程序 */_Py_NegativeRefcount(filename, lineno, op);}
#endif}else {/* 引用计数变为 0,说明没有其他引用指向该对象 *//* 可以安全释放内存了 */_Py_Dealloc(op);}
}/*** 减少引用的宏定义* * 自动传入当前文件名 (__FILE__) 和行号 (__LINE__)* 便于在调试时定位是哪一行代码导致了引用计数变化* * _PyObject_CAST(op) 确保 op 被正确转换为 PyObject* 类型*/
#define Py_DECREF(op) _Py_DECREF(__FILE__, __LINE__, _PyObject_CAST(op))总结:
问题 | 回答 |
Python 怎么知道引用计数为 0? | 每次调用 减少计数时,都会立即检查是否为 0 |
是不是每次都会监测? | ✅ 是的!每一次引用减少都是一次“检查 + 可能释放” |
类似 吗? | ✅ 完全正确! 宏就是这么写的 |
谁负责清理内存? |
函数(如 、 ) |
需要 GC 吗? | 对于普通对象不需要;只有循环引用才需要 模块 |
4. 那么每次增加的时候会监测引用个数?:
不会的,情况如下:
函数/宏 | 作用 | 是否检查计数 |
| 引用计数 +1 | ❌ 不检查,只增加 |
| 引用计数 -1,并检查是否为 0 | ✅ 如果为 0,触发销毁 |
举个例子:什么情况下会调用 Py_INCREF?
场景 1:变量赋值
python深色版本a = [1, 2, 3]
b = a # b 引用了同一个 list 对象→ CPython 内部会对 a 指向的对象调用 Py_INCREF,引用计数 +1
场景 2:作为参数传给函数
python深色版本def func(x):passfunc(a) # a 被传入函数→ 在函数调用时,CPython 会对 a 调用 Py_INCREF,防止对象在函数执行期间被意外销毁
场景 3:添加到容器
python深色版本my_list = []
my_list.append(a) # a 被加入列表→ 列表会对其元素调用 Py_INCREF,确保元素不会提前被释放。
如下是增加引用时的CPython源码,可以看到只是进行了op->ob_refcnt++;其他没有什么操作。
/** CPython 引用计数核心函数:_Py_INCREF 和 _Py_DECREF* * 这些函数是 Python 自动内存管理的基石。* 所有 Python 对象的创建、使用和销毁都依赖于引用计数。* * 注意:此版本是用于调试模式(如 --with-pydebug 编译)的实现,* 包含文件名、行号追踪和负引用检测。*//*** 增加一个 Python 对象的引用计数* * @param op: 指向 PyObject 的指针* * 这是一个静态内联函数,性能极高,直接嵌入调用处。*/
static inline void _Py_INCREF(PyObject *op)
{/* 增加全局引用计数统计(仅在调试模式下有效) */_Py_INC_REFTOTAL;/* 关键操作:引用计数 +1 */op->ob_refcnt++;
}/*** 增加引用的宏定义* * 使用 _PyObject_CAST(op) 确保类型安全(转换为 PyObject*)* 自动传入当前文件名和行号,便于调试*/
#define Py_INCREF(op) _Py_INCREF(_PyObject_CAST(op))5. 清理数据时底层调用的都是xx_dealloc
在 CPython 中,当一个对象的引用计数降为 0 时,真正负责清理内存的,就是底层的 xx_dealloc 函数。
✅核心机制:tp_dealloc 是“真正的析构函数”
在 CPython 的对象系统中,每个类型(type) 都有一个结构体 PyTypeObject,其中包含一个关键字段:
typedef struct _typeobject {// ... 其他字段destructor tp_dealloc; // ← 就是它!真正的析构函数指针// ... 其他字段
} PyTypeObject;当某个对象的引用计数变为 0 时,CPython 会:
- 找到该对象的类型(
PyObject *ob_type) - 调用该类型的
tp_dealloc函数 - 这个函数才是真正释放内存的人
✅举几个常见的 xx_dealloc 函数
类型 | C 层 函数 | 作用 |
|
| 释放列表内部的数组,递减元素引用 |
|
| 释放哈希表,递减键值对的引用 |
/ |
| 释放字符串缓冲区 |
|
| 递减元组中每个元素的引用 |
自定义类实例 |
| 释放实例字典 和其他成员 |
🔍 以 list_dealloc 为例
static void
list_dealloc(PyListObject *op)
{Py_ssize_t i;PyObject **items = op->ob_item;Py_ssize_t len = Py_SIZE(op); // 获取列表长度// 第一步:递减列表中每个元素的引用计数for (i = 0; i < len; i++) {Py_XDECREF(items[i]); // Py_XDECREF 会自动处理 NULL}// 第二步:释放列表内部的数组内存PyMem_FREE(items);// 第三步:释放对象本身(调用类型对应的对象分配器)Py_TYPE(op)->tp_free((PyObject *)op);
}👉 注意:这里没有 __del__ 的影子!它直接操作内存。
🔄 __del__ 和 xx_dealloc 的关系
它们是两个不同层次的东西:
层级 | 函数 | 作用 | 是否必须 |
Python 层 |
| 用户自定义清理逻辑(如打印、关闭文件) | ❌ 可选 |
C 层 |
| 真正释放内存、递减引用、调用 | ✅ 必须 |
✅ 调用顺序(如果有 __del__)
- 引用计数变为 0
- CPython 发现该对象有
__del__方法 - 先调用
__del__(在对象还“活着”时) __del__执行完毕- 再调用
tp_dealloc(真正销毁对象)
⚠️ 注意:如果 __del__ 抛出异常,CPython 会忽略它并继续调用 tp_dealloc。
✅ 为什么 __del__ 不影响内存释放?
因为:
__del__是在对象被销毁前调用的- 真正的内存释放是由
tp_dealloc完成的 - 即使你写一个无限循环的
__del__,最终tp_dealloc仍然会在它结束后被调用(除非程序卡死)
class Bad:def __del__(self):while True:pass # 死循环!但 tp_dealloc 不会被跳过,只是卡在这里obj = Bad()
del obj # 程序卡死,但内存最终不会泄露(只是不释放)✅ 总结
问题 | 回答 |
清理时底层调用的是 吗? | ✅ 是的! , 等 |
是底层调用的吗? | ❌ 不是,它是 Python 层的回调 |
谁负责释放内存? |
函数(即 ) |
每个类型都有 吗? | ✅ 是的,这是 的强制字段 |
不写 会影响内存释放吗? | ❌ 不会, 照常工作 |
del 不是“直接”调用 tp_dealloc,而是先调用 Py_DECREF 减少引用计数,如果引用计数变为 0,tp_dealloc
也就是说如果这个对象引用计数个数为100时,使用del减去的也是1 就变成99了。所以这个对象实际上还是没有被回收。
| ❌ 不是 |
| ✅ 是!每次 |
引用计数为 100, | ✅ 变成 99 |
什么时候对象被销毁? | ✅ 当引用计数减到 0 时 |
| ✅ 只有在引用计数变为 0 时才会 |
1.5 引用计数的致命缺陷:循环引用和__del__重生
1.5.1 循环引用
引用计数的致命弱点是无法处理循环引用。当两个或多个对象相互引用,形成一个闭环时,即使外部不再有引用,它们的引用计数也不会降为 0,导致内存泄漏。
def create_cycle():a = []b = []a.append(b) # a 引用 bb.append(a) # b 引用 a → 循环引用return aobj = create_cycle()
obj = None # 外部引用消失,但 a 和 b 仍相互引用,引用计数 > 0此时,a 和 b 构成的循环引用无法被引用计数机制回收,造成内存泄漏(就是说有无法使用的内存,因为这部分不用,但是也没法回收,就会造成内存浪费)
1.5.2 __del__重生
如果 __del__ 方法中意外重新创建了对对象的引用(“重生”),可能导致对象不被真正回收。
class BadDel:instance = Nonedef __init__(self):print("创建")def __del__(self):print("销毁")BadDel.instance = self # ❌ 在 __del__ 中重新引用自己!obj = BadDel()
del obj # 引用计数为 0,触发 __del__
# 但 __del__ 中又让类变量引用了它 → 对象没被真正销毁!__del__ 方法的调用时机并不总是确定的,因为它依赖于 Python 的垃圾回收机制。因此,不建议依赖 __del__ 来释放关键资源(如文件句柄、网络连接等)。更好的做法是使用上下文管理器(with 语句)或显式调用 close() 方法来确保资源的及时释放。
那么对于以上的情况,CPython如何处理呢?CPython提供GC(垃圾回收器)