PySpark
1. 前言介绍
Spark是Apache基金会旗下的顶级开源项目,用于对海量数据进行大规模分布式计算。
PySpark是Spark的Python实现,是Spark为Python开发者提供的编程入口,用于以Python代码完成Spark任务的开发
PySpark不仅可以作为Python第三方库使用,也可以将程序提交的Spark集群环境中,调度大规模集群进行执行。
2. 基础准备
PySpark库的安装
pip install pyspark
清华镜像:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
PySpark执行环境入口对象的构建
PySpark的执行环境入口对象是:类 SparkContext 的类对象

PySpark的编程模型

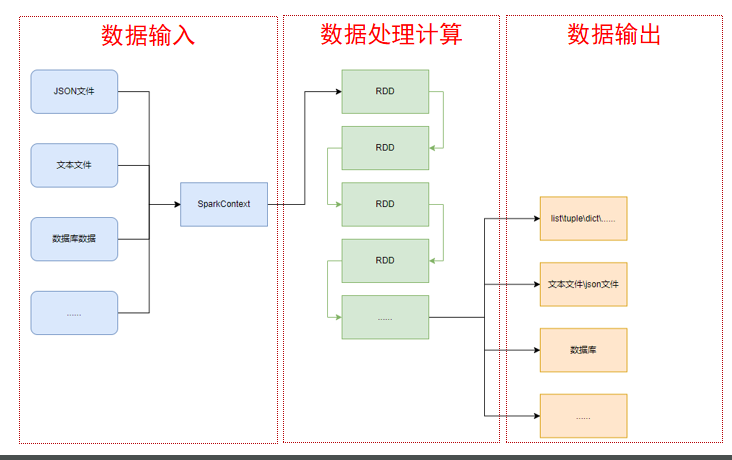
数据输入:通过SparkContext完成数据读取
数据计算:读取到的数据转换为RDD对象,调用RDD的成员方法完成计算
数据输出:调用RDD的数据输出相关成员方法,将结果输出到list、元组、字典、文本文件、数据库等
3. 数据输入
RDD对象
PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
PySpark数据输入的2种方法
PySpark支持通过SparkContext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转换为PySpark的RDD对象

注意: 字符串会被拆分出1个个的字符,存入RDD对象 字典仅有key会被存入RDD对象
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。

4. 数据计算
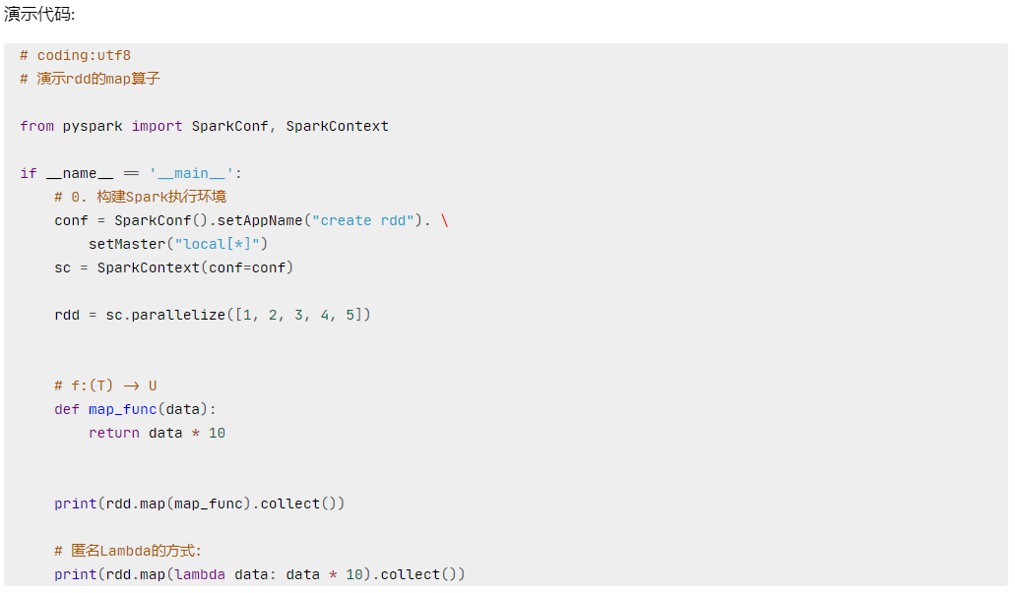
map
map算子(成员方法)
- 接受一个处理函数,可用lambda表达式快速编写
- 对RDD内的元素逐个处理,并返回一个新的RDD

eg:
链式调用 对于返回值是新RDD的算子,可以通过链式调用的方式多次调用算子。
flatMap
flatMap算子
- 计算逻辑和map一样
- 可以比map多出,解除一层嵌套的功能

eg:

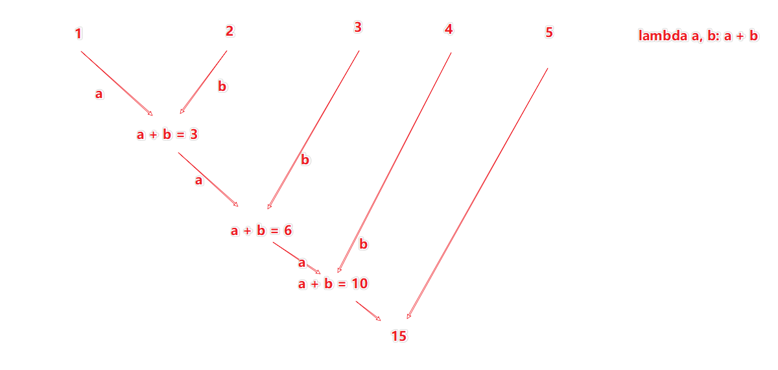
reduceByKey
reduceByKey算子 接受一个处理函数,对数据进行两两计算


WordCount案例
读取文件 统计文件内,单词的出现数量

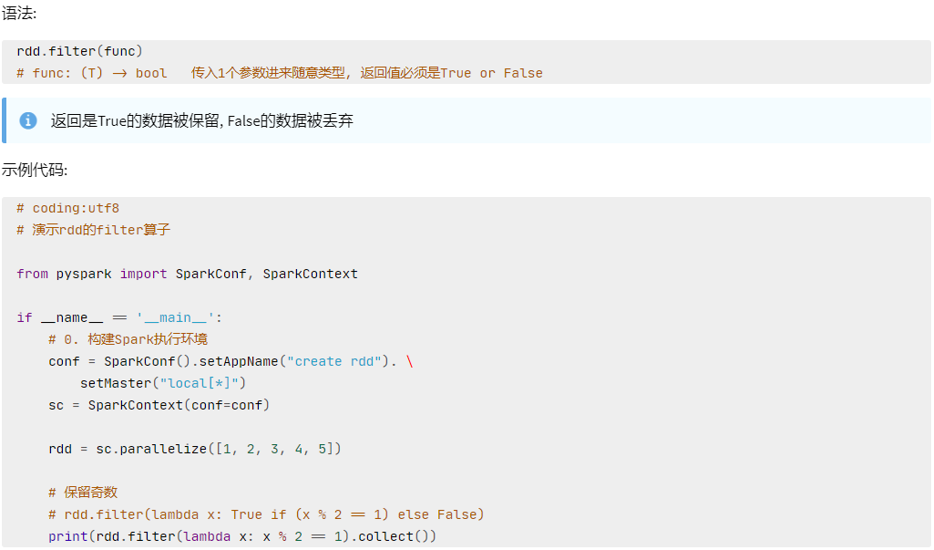
filter
filter算子
- 接受一个处理函数,可用lambda快速编写
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中
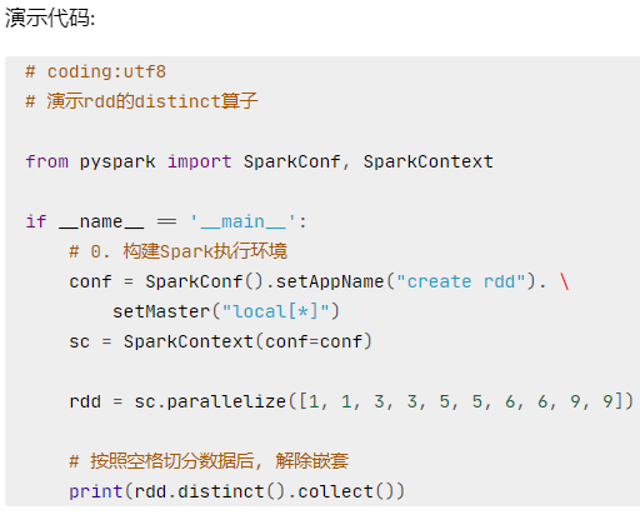
distinct
distinct算子 完成对RDD内数据的去重操作

sortBy
sortBy算子
- 接收一个处理函数,可用lambda快速编写
- 函数表示用来决定排序的依据
- 可以控制升序或降序
- 全局排序需要设置分区数为1

案例



5. 数据输出
输出为Python对象
Spark编程流程:
- 将数据加载为RDD(数据输入)
- 对RDD进行计算(数据计算)
- 将RDD转换为Python对象(数据输出)
数据输出的方法:
- collect:将RDD内容转换为list

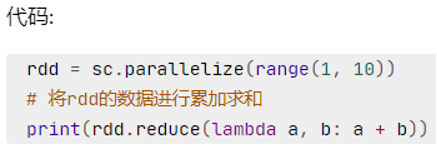
- reduce:对RDD内容进行自定义聚合

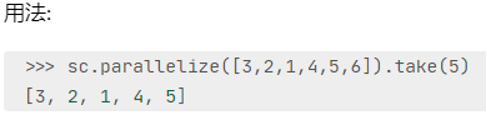
- take:取出RDD的前N个元素组成list
- count:统计RDD元素个数

输出到文件中
输出到文件的方法:
- rdd.saveAsTextFile(路径)
- 输出的结果是一个文件夹
- 有几个分区就输出多少个结果文件
1

调用保存文件的算子,需要配置Hadoop依赖
- 下载Hadoop安装包
- http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz
- 解压到电脑任意位置
- 在Python代码中使用os模块配置:os.environ[‘HADOOP_HOME’] = ‘HADOOP解压文件夹路径’
- 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
- 下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
- https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll
修改rdd分区为一个
方式1,SparkConf对象设置属性全局并行度为1:

方式2,创建RDD的时候设置(parallelize方法传入numSlices参数为1):
![]()
![]()
6. 综合案例
搜索引擎日志分析:
读取文件转换成RDD,并完成:
- 打印输出:热门搜索时间段(小时精度)Top3
- 打印输出:热门搜索词Top3
- 打印输出:统计黑马程序员关键字在哪个时段被搜索最多
- 将数据转换为JSON格式,写出为文件
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.functions import hour, col
import json# 1. 初始化Spark环境
conf = SparkConf().setAppName("SearchAnalysis").setMaster("local[*]")
sc = SparkContext(conf=conf)
spark = SparkSession(sc)# 2. 读取数据文件(假设数据格式:timestamp,search_term)
# 示例数据格式:
# 2023-01-01 08:30:00,黑马程序员
# 2023-01-01 09:15:00,Python
search_data = sc.textFile("search_log.txt")# 3. 数据预处理
def parse_line(line):parts = line.split(',')return {'timestamp': parts[0],'hour': parts[0].split(' ')[1].split(':')[0], # 提取小时'search_term': parts[1]}parsed_data = search_data.map(parse_line).cache()# 4. 热门时间段Top3
hourly_counts = parsed_data.map(lambda x: (x['hour'], 1)) \.reduceByKey(lambda a, b: a + b) \.sortBy(lambda x: x[1], ascending=False)print("=== 热门搜索时间段Top3 ===")
for hour, count in hourly_counts.take(3):print(f"时段 {hour}:00 - {count}次搜索")# 5. 热门搜索词Top3
term_counts = parsed_data.map(lambda x: (x['search_term'], 1)) \.reduceByKey(lambda a, b: a + b) \.sortBy(lambda x: x[1], ascending=False)print("\n=== 热门搜索词Top3 ===")
for term, count in term_counts.take(3):print(f"{term}: {count}次搜索")# 6. 黑马程序员搜索时段分析
heimai_hours = parsed_data.filter(lambda x: x['search_term'] == '黑马程序员') \.map(lambda x: (x['hour'], 1)) \.reduceByKey(lambda a, b: a + b) \.sortBy(lambda x: x[1], ascending=False)print("\n=== 黑马程序员搜索高峰时段 ===")
for hour, count in heimai_hours.collect():print(f"时段 {hour}:00 - {count}次搜索")# 7. 转换为JSON并输出
result_json = {"top_hours": dict(hourly_counts.take(3)),"top_terms": dict(term_counts.take(3)),"heimai_hot_hours": dict(heimai_hours.collect())
}# 保存为JSON文件
with open("search_analysis.json", "w", encoding='utf-8') as f:json.dump(result_json, f, ensure_ascii=False, indent=2)print("\n分析结果已保存为 search_analysis.json")# 8. 关闭Spark
sc.stop()7. 分布式集群运行
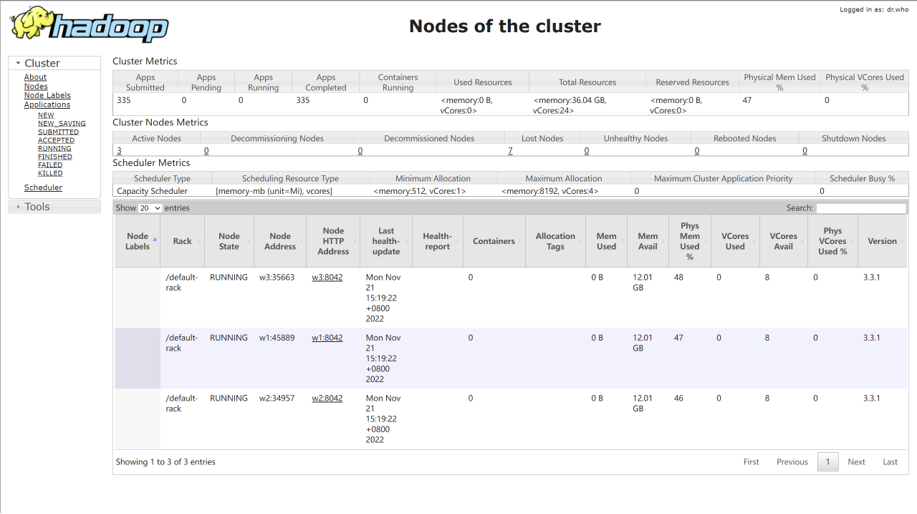
yarn集群上运行:
提交命令: bin/spark-submit --master yarn --num-executors 3 --queue root.teach --executor-cores 4 --executor-memory 4g /home/hadoop/demo.py