井字游戏的强化学习
一、说明
为了说明强化学习的一般思想并将其与其他方法进行对比,本文详细地考虑一个例子。就是哪怕是最简单最一般对弈过程中,强化学习实现的机制和原理。
二、扩展示例:井字游戏
想象一下孩子们熟悉的井字游戏。两名玩家轮流在三乘三的棋盘上游戏。一名玩家放置X,另一名玩家放置O,直到一名玩家通过将三个标记水平、垂直或对角线排列成一行(就像游戏中放置X的玩家那样)获胜:

如果棋盘上没有一方获得三连,则游戏为平局。由于熟练的棋手可以做到永不输,因此我们假设我们的对手是一位不完美的棋手,他的下法有时会出错,从而让我们获胜。事实上,目前我们假设平局和输棋对我们来说同样糟糕。我们如何才能构建一个能够发现对手下法缺陷并学会最大化获胜机会的棋手?
虽然这是一个简单的问题,但通过经典技术很难以令人满意的方式解决。例如,博弈论中经典的“极小极大”解法在这里并不适用,因为它假设了对手特定的游戏方式。例如,极小极大玩家永远不会达到可能输掉的游戏状态,即使事实上由于对手的失误,他总是能从该状态获胜。用于序列决策问题的经典优化方法,例如动态规划,可以为任何对手计算出最优解,但需要输入对手的完整规范,包括对手在每个棋盘状态下每一步的概率。我们假设这些信息对于这个问题来说并非先验可得,就像绝大多数实际问题一样。另一方面,这些信息可以根据经验估计,在这种情况下,可以通过与对手进行多次对弈来估计。解决这个问题的最佳方法是首先学习对手行为的模型,达到一定的置信度,然后应用动态规划,根据近似对手模型计算出最优解。最后,这与我们在本书后面讨论的一些强化学习方法并没有太大区别。
解决这个问题的进化方法是直接在可能的策略空间中搜索一个更有可能战胜对手的策略。在这里,策略是一种规则,它告诉玩家在游戏的每个状态(即三乘三棋盘上X和O的每种可能配置)下该如何走棋。对于每个被考虑的策略,都会通过与对手进行一定数量的游戏来估计其获胜概率。然后,这种评估将决定下一步考虑哪个或哪些策略。一种典型的进化方法会在策略空间中采用爬山法,逐步生成和评估策略,以期获得渐进式的改进。或者,或许可以使用一种遗传算法来维护和评估策略群体。实际上,可以应用数百种不同的优化方法。我们所说的直接搜索策略空间是指基于标量评估提出和比较 所有策略。
以下是使用强化学习和近似值函数解决井字游戏问题的方法。首先,我们建立一个数字表,每个数字代表游戏的每种可能状态。每个数字代表我们在该状态下获胜概率的最新估计值。我们将这个估计值视为状态的值,整个表格就是学习到的值函数。如果当前对 A 状态下获胜概率的估计值高于 B 状态下的估计值,则状态 A 的值高于状态 B,或者被认为比状态 B“更好”。假设我们总是玩 X,那么对于所有连续三个 X 的状态,获胜概率为 1,因为我们已经赢了。同样,对于所有连续三个 O 的状态,或者“已填满”的状态,正确的概率为 0,因为我们无法从这些状态获胜。我们将所有其他状态的初始值设置为 0.5,表示我们猜测获胜的概率为 50%。
我们与对手进行许多对局。为了选择走法,我们会检查每种可能走法(棋盘上每个空白处对应一种走法)可能导致的状态,并在表中查找它们的当前值。大多数情况下,我们会采取贪婪走法,选择导致状态值最大的走法,也就是估计获胜概率最高的走法。然而,偶尔我们也会从其他走法中随机选择。这些走法被称为探索性走法,因为它们会让我们体验到原本可能永远无法体验的状态。一场对局中做出和考虑的一系列走法可以用图 1.1所示的图表表示 。
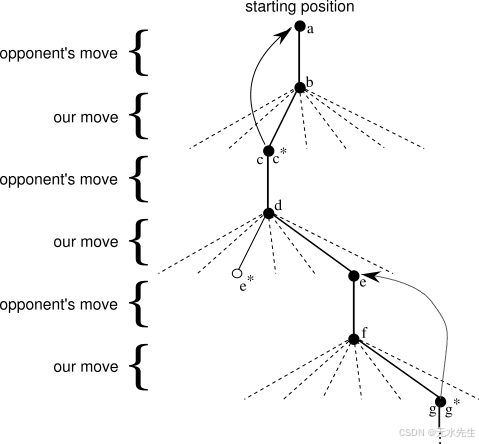
图 1.1: 井字游戏的一系列走法。实线表示游戏过程中采取的走法;虚线表示我们(强化学习玩家)考虑过但最终没有采取的走法。我们的第二步走法是探索性走法,这意味着即使另一个兄弟走法(导致 的走法)的排名更高,我们仍然采取了这一步。探索性走法不会导致任何学习,但我们的其他每一步走法都会带来学习,正如曲线箭头所示,并在文中详细说明,会导致备份。
在游戏过程中,我们会改变自身所处状态的值。我们试图使它们更准确地估计获胜概率。为此,我们将每次贪婪移动后的状态值“回退”到移动前的状态,如图 1.1中的箭头所示。更准确地说,将先前状态的当前值调整得更接近后续状态的值。这可以通过将先前状态的值稍微向后续状态的值移动来实现。如果我们令表示贪婪移动前的状态,令 表示移动后的状态,那么对 估计值的更新(记为 )可以写成
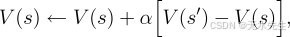
其中,V(s′)−V(s)V(s')-V(s)V(s′)−V(s) 是一个称为步长参数的较小正分数,它影响学习率。此更新规则是时间差分学习方法的一个例子,之所以这样称呼,是因为它的变化基于两个不同时间点估计值的差异。
上述方法在此任务上表现相当出色。例如,如果步长参数随时间适当减小,该方法对于任何固定的对手,都能收敛到在玩家采取最优策略的情况下,在每个状态下获胜的真实概率。此外,随后采取的行动(探索性行动除外)实际上是对抗对手的最优行动。换句话说,该方法收敛到了一种用于游戏的最优策略。如果步长参数没有随时间完全减小到零,那么该玩家在对抗那些慢慢改变游戏方式的对手时也能表现出色。
这个例子说明了进化方法和学习价值函数的方法之间的区别。为了评估一项策略,进化方法必须将其固定并与对手进行多场对弈,或者使用对手的模型模拟多场对弈。获胜频率可以无偏估计该策略的获胜概率,并可用于指导下一步的策略选择。但每次策略调整都需在多场对弈之后进行,并且只考虑每场对弈的最终结果:对弈过程中发生的情况将被忽略。例如,如果玩家获胜,那么其在对弈中的所有行为都会被计入,无论特定动作对胜利的重要性如何。甚至从未发生过的动作也会被计入!相比之下,价值函数方法允许评估单个状态。最终,进化方法和价值函数方法都会搜索策略空间,但学习价值函数会利用对弈过程中可用的信息。
这个简单的例子展现了强化学习方法的一些关键特性。首先,它强调在与环境(在本例中是与对手玩家)互动的同时进行学习。其次,它有一个明确的目标,正确的行为需要规划或预见,并将选择的延迟效应考虑在内。例如,简单的强化学习玩家会学习如何为目光短浅的对手设置多步陷阱。强化学习解决方案的一个显著特点是,它无需使用对手模型,也无需对未来状态和动作的可能序列进行显式搜索,就能实现规划和前瞻的效果。
虽然这个例子展示了强化学习的一些关键特性,但它过于简单,可能会让人觉得强化学习比实际用途更有限。虽然井字棋是双人游戏,但强化学习也适用于没有外部对手的情况,即“对抗自然的游戏”。强化学习并不局限于行为分解成独立回合的问题,例如井字棋的独立游戏,奖励只在每个回合结束时才生效。当行为无限期持续,并且可以随时获得不同程度的奖励时,强化学习同样适用。
井字棋的状态集相对较小且有限,而强化学习则可用于状态集非常大甚至无限大的情况。例如,Gerry Tesauro(1992, 1995)将上述算法与人工神经网络相结合,学习玩西洋双陆棋,该游戏的状态集约为。如此多的状态,不可能只体验其中一小部分。Tesauro 的程序比之前任何程序都学得更好,现在的水平已经与世界顶级人类棋手相当(参见第 11 章)。神经网络赋予程序基于经验进行泛化的能力,因此在新状态下,它会根据网络确定的过去遇到的类似状态所保存的信息来选择移动方式。强化学习系统在处理如此庞大的状态集问题时的表现与其基于过去经验进行泛化的程度密切相关。正是在这个角色中,我们最需要结合强化学习的监督学习方法。神经网络并不是实现这一目标的唯一方法,也不一定是最好的方法。
在这个井字棋的例子中,学习开始时除了游戏规则之外没有任何先验知识,但强化学习绝不意味着对学习和智能抱有“白板”式的视角。相反,先验信息可以通过多种方式融入强化学习,这对于高效学习至关重要。在井字棋的例子中,我们也可以访问真实状态,而强化学习也可以应用于部分状态被隐藏,或者当学习者认为不同的状态相同时。然而,这种情况要困难得多,本书不会对其进行过多的讨论。
三、后记
最后,井字棋玩家能够预见未来,并了解其每种可能的动作会导致的状态。为此,它必须拥有一个游戏模型,使其能够“思考”其环境将如何响应其可能永远不会做出的动作而变化。许多问题都是这样的,但在其他一些问题中,甚至缺乏一个短期行动影响模型。强化学习可以应用于任何一种情况。强化学习并非必须,但如果模型可用或可学习,则可以轻松使用。