推荐系统学习笔记(十)多目标排序模型
用户-笔记的交互
对于每篇笔记,系统会记录:曝光次数/点击次数/点赞次数/收藏次数/转发次数
计算公式:
点击率 = 点击次数/曝光次数
点赞率 = 点赞次数/点击次数
收藏率 = 收藏次数/点击次数
转发率 = 转发次数/点击次数
排序模型融合这些预估分数做排序。
多目标模型
模型结构
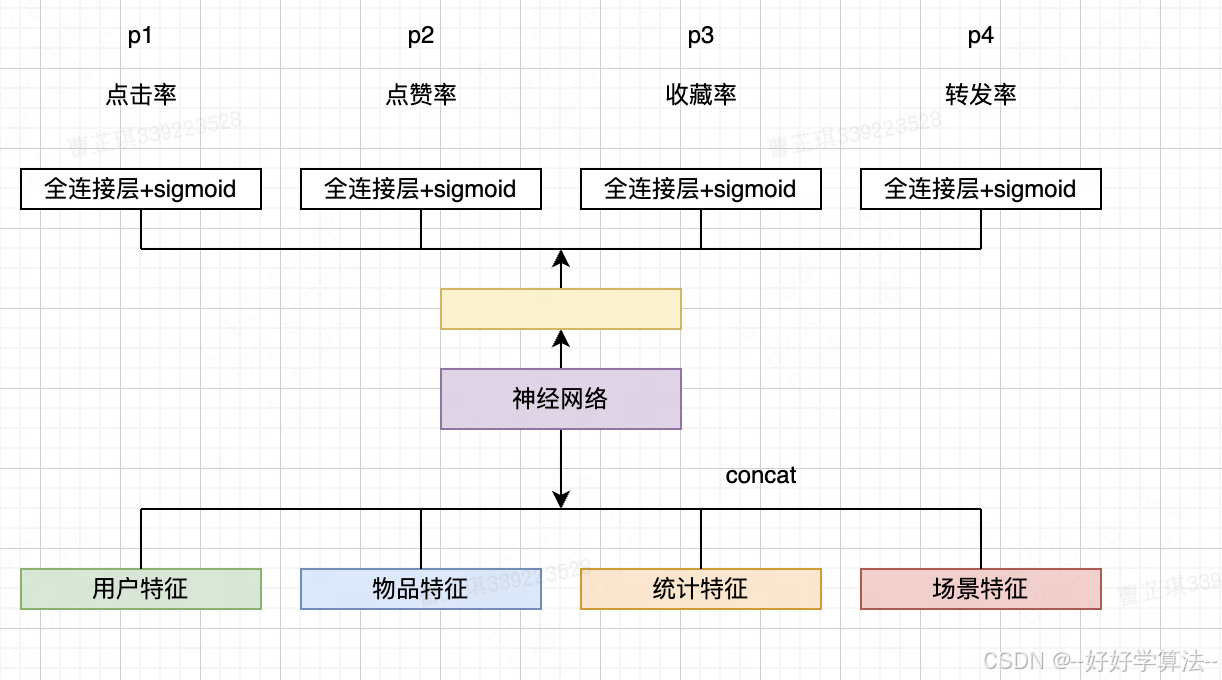
场景特征包括用户所在的时间、地点等,比如候选物品在不同的城市、季节以及节假日影响,用户对其有完全不同的兴趣程度
这里的神经网络模型可以根据任务自行选择。
损失函数:
训练
困难:类别不平衡
例如,点击vs未点击,收藏vs未收藏。显然,负样本的数量要远远多于正样本。常见的解决方案是进行负样本降采样(down-sampling):
1. 保留一小部分负样本,让正负样本数量平衡;
2. 减少了负样本数量,节约计算。
预估值校准
在模型输出各个指标预估值之后,需要先进行预估值校准,才能做后续的排序。主要原因在于:
举个例子:
设正样本、负样本数量为 和
。
真实点击率:(期望)
对负样本做降采样,抛弃一部分负样本。使用 个负样本,
是采样率。
预估点击率:(期望)
由于负样本变少,预测点击率大于真实点击率。
预估值校准就是希望通过函数调整预估值,使得其能与真实值一致,根据上述两个点击率的等式可得对点击率预估值的校准公式为
推导过程如下:
