【ECCV2024】AdaCLIP:基于混合可学习提示适配 CLIP 的零样本异常检测
AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection
代码:https://github.com/caoyunkang/AdaCLIP
论文链接:https://arxiv.org/abs/2407.15795v1
摘要:
1.点明工业异常的领域(零样本)和作用:
零样本异常检测(ZSAD) 【测试阶段不使用任何目标类别的图像】
作用:从任意新类别中识别图像中的异常
2.介绍模型名字+简单介绍自己在clip上创新+针对创新点详细讲解
模型名字:AdaCLIP
基础模型:CLIP
创新:
1.加入可学习提示
可学习提示
- 静态提示:在所有图像中共享,用于初步自适应CLIP
- 动态提示:为每个测试图像生成动态提示
- 混合提示:静态和动态提示的组合
2.加入辅助注释异常检测数据的训练来优化提示
3.实验结果:
数据集:在工业和医学领域的14个真实异常检测数据集
结果: AdaCLIP优于其他ZSAD方法,对不同类别甚至领域具有更好的泛化能力
4.分析创新点是否真的可以解决问题
分析各种辅助数据和优化提示对于增强泛化能力的重要性。
4 AdaCLIP
4.1 Overview
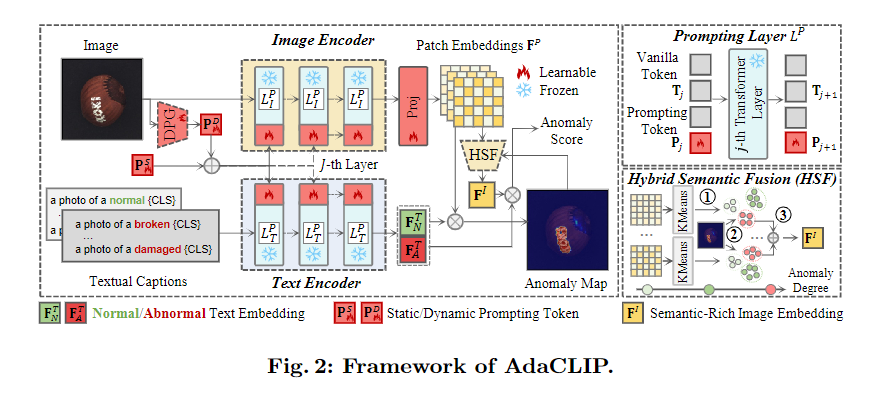
1.写模型的框架图如图几所示:
AdaCLIP的框架如图2所示
2.介绍模型的创新点:
AdaCLIP比较给定一个图像I的CLIP嵌入(总写):
通过计算正常/异常状态的图像和文本说明之间的CLIP嵌入空间中的相似度来检测异常,如“一张正常[CLS]的照片”和“一张异常[CLS]的照片”,其中[CLS]表示测试类别的名称,如“地毯”、“榛子”等。
创新点有3个:
- AdaCLIP通过合并图像的可学习参数L_l和文本编码器的可学习参数L_T来增强预训练的CLIP,两个可学习参数取代了原始的transformer层
- 在提示层,有 静态提示PS和动态提示PD
- 在图像编码器的末尾引入了一个投影层项目,以及一个用于提取语义丰富的图像嵌入以计算图像级异常评分的混合语义融合(HSF)模块。
4.2 Prompting Layers 提示层
总结:
引入可学习提示向量替换CLIP原本的部分Transformer层-》实现对CLIP图像和文本编码器的轻量适配。这个提示层包括两种提示:静态提示(Static Prompts)和动态提示(Dynamic Prompts),用于构建混合提示(Hybrid Prompts)
作用:
AdaCLIP通过提示层引入少量可学习参数,增强了CLIP对异常类别的适应能力,既保持CLIP原始泛化能力,又实现对辅助异常数据的适配。
步骤:
提示层L_P I和L_P T,分别取代CLIP图像和文本编码器中原有的变压器层
图像提示层部分,保留了转换器的权重
- 输入:图像原始token序列(例如图像被切成一个个小块,每个小块变成一个向量)
操作:在这些图像向量前面拼接提示向量(包含静态提示 + 动态提示)
输出:拼接后的图像token序列,形式是**【提示向量 + 原始图像token】** - 输入:拼接后的图像token序列
操作:送入Transformer进行处理,提示向量通过注意力机制参与整个图像表示的生成
输出:包含提示信息的图像特征,能够更关注图像中可能的异常区域
文本提示层部分
-
输入:文本原始token序列(例如“这是一个损坏的[类别]”这样的句子,每个词会被转成一个向量)
操作:同样在这些文本向量前面拼接提示向量(也是静态提示 + 动态提示)
输出:拼接后的文本token序列,形式是**【提示向量 + 原始文本token】** -
输入:拼接后的文本token序列
操作:送入Transformer处理,提示向量参与整个文本表示生成
输出:包含提示信息的文本特征,更能代表正常/异常语义
4.3 Hybrid Learnable Prompts
总结:
混合可学习提示向量机制,即同时引入静态提示向量和动态提示向量,构建出混合提示向量,用于引导图像编码器和文本编码器更有效地识别异常。
作用:
针对已有研究提出“提示学习”,但单独使用静态提示或动态提示各有缺陷:只用静态提示,无法适应不同图像;只用动态提示,缺少对异常知识的统一抽象。
+静态提示提供统一的异常先验(所有图像都用一套),
动态提示根据每张图像生成(个性化适应)
→ 二者结合,既能泛化、又能灵活
步骤:
- 输入:使用与测试类别不同的辅助数据集(包含标注的正常图像和异常图像)
操作:从这些图像中学习出一组静态提示向量,该向量对所有图像都一样
输出:一组共享的静态提示向量(作为基础提示) - 输入:训练阶段的辅助数据图像【在测试阶段也会根据测试图像生成动态提示向量】
操作:将图像送入冻结的预训练图像编码器,提取其全局特征;再通过一个可学习的线性变换,将特征转换成与图像相关的动态提示向量
输出:一组针对该图像定制的动态提示向量 - 输入:静态提示向量 + 动态提示向量
操作:将这两组提示向量直接相加,得到最终的混合提示向量
输出:用于后续提示层的混合提示向量 - 输入:混合提示向量 + 原始图像token(或文本token)
操作:将混合提示向量拼接在原始token前面,送入提示层中,通过注意力机制引导模型聚焦于异常相关区域或描述
输出:融合了提示信息的图像特征或文本特征 - 输入:图像经过提示层后得到的完整特征序列
操作:提取出图像的多个空间位置上的小块特征(patch特征),这些特征用于后续计算每个区域是否异常
输出:图像patch特征集合 FP = {FP₀,FP₁,…} - 输入:若干条带有“正常”、“异常”语义的文本句子。【举例:“一张正常的[类别]照片”、“一张损坏的[类别]照片”等】
操作:
(1)将每条文本句子分成一个个词(例如:“一张”、“正常的”、“类别”、“照片”),每个词被编码成一个向量,形成原始文本token序列;
(2)对于每个文本token序列,在其前面拼接提示向量(由静态提示 + 动态提示组成的混合提示向量);
(3)拼接结果为【提示token + 原始token】,组成完整的输入序列;
(4)输入这个序列到文本编码器中的提示层中进行处理(注意:原有Transformer被提示层替代);
(5)提示token通过注意力机制影响原始token的特征表示,让模型更关注描述中的“正常/异常”关键词;
(6)得到输出序列后,从中提取整个句子的语义特征,作为该文本的整体表示。
输出:
对“正常”描述文本,得到一个向量 FT_N(表示正常状态的语义特征);
对“异常”描述文本,得到一个向量 FT_A(表示异常状态的语义特征)。
4.4 Projection Layer 投影层
针对问题: 原始CLIP架构使图像块嵌入和文本嵌入的尺寸不匹配
方法:图像编码器添加一个带偏差的线性投影层Proj对齐了**块嵌入(FP)与正常(FT N)和异常(FT A)**文本的嵌入之间的维度
此外,投影层为CLIP自适应添加了一些可学习参数。
4.5 Pixel-Level Anomaly Localization像素级异常定位
- 测量补丁嵌入FP、文本嵌入FT N和FT a之间的余弦相似度-》得到异常得分。
定义从第i层开始的异常图如下:
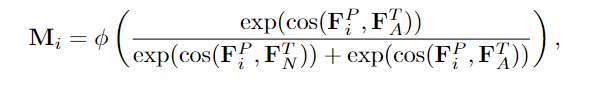
其中cos(·,·)表示余弦相似度,φ是一个重塑和插值函数,将块嵌入的异常得分转换为异常图 Mi∈R^H×W。 - 以多层次的方式获取来自多个层的异常图,并将这些异常图聚合为最终的预测M。
- 在训练过程中,AdaCLIP在辅助数据上使用dice损失和focal损失优化像素级异常图M。
4.6 Hybrid Semantic Fusion Module混合语义融合模块
总结:
图文融合模块,目的是将图像编码器提取的图像特征和文本编码器提取的语义特征结合起来,从而更准确地判断图像中哪些区域是异常的,哪些是正常的。
创新点:
原本:图像级AD的传统AD方法通常选择异常图的最大值作为异常分数,但这对噪声预测很敏感。
利用“正常文本特征”与“异常文本特征”引导图像特征中每个空间位置的判断,并使用注意力机制动态融合正常与异常信息,生成更可信的异常评分图。
作用:
语义丰富的图像嵌入有效地提高了图像级AD的性能
步骤:
1.使用KMeans将patch嵌入聚类到K组中
2.将异常图M中对应位置的得分进行平均,计算单个簇的异常得分。
3.选择异常得分最高的簇,计算其质心,并将其聚合为最终的语义丰富的图像嵌入FI
4.7 Image-Level Anomaly Detection图像级异常检测
- 提取语义丰富的图像嵌入FI
- 使用FI和文本嵌入FN A和FT A之间的余弦相似性,计算图像级异常分数S
- 进行softmax归一化
- 使用焦点损失优化图像级异常评分
实验
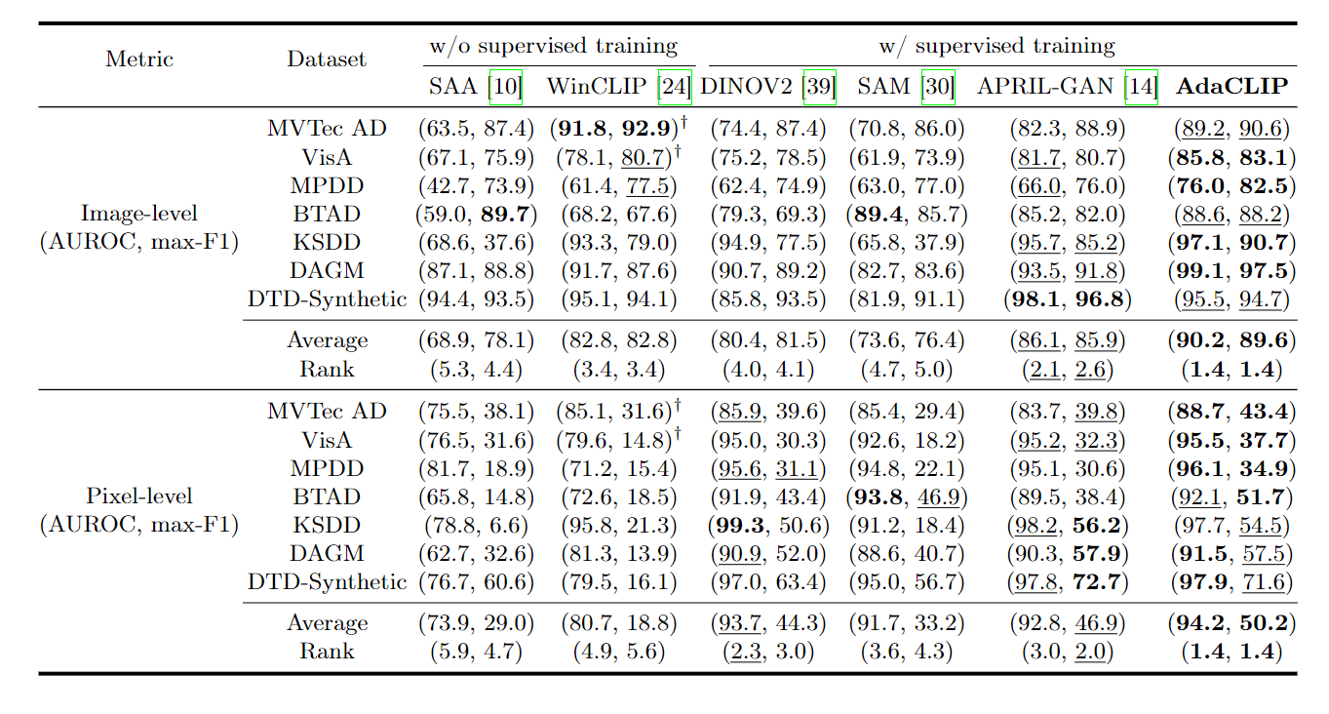
表1是在工业领域的数据集上跟其他零样本异常检测方法的比较。最好的用粗体标出,次好的用下划线标出。†表示取自原始论文的结果。Rank表示不同方法在不同数据集上的平均性能排名。
结果1:需要辅助数据训练
- 与未在辅助数据上进行训练的ZSAD方法相比,有训练的方法表现出优越的性能:1.利用手工文本提示的WinCLIP和SAA呈现出欠佳的性能。2.相反,用辅助数据调整DINOV2和SAM显示出良好的像素级ZSAD性能。
结论:
用辅助数据训练的ZSAD方法集的优越性能强调了预训练的vlm已经被赋予了异常检测的基本知识。通过适当的适应,这些现有的知识可以有效地用于ZSAD。
结果2:动态提示生成器和HSF模块帮助更高效迁移知识至新类别
-
AdaCLIP比其他ZSAD方法有显著的改进:
-
- 1.与第二名的方法相比,在max-F1上的图像级和像素级提高了3.7%和3.3%。
-
- 2.AdaCLIP在图像和像素级性能方面在所有数据集上都取得了最佳的总体排名。
- 2.AdaCLIP在图像和像素级性能方面在所有数据集上都取得了最佳的总体排名。
-
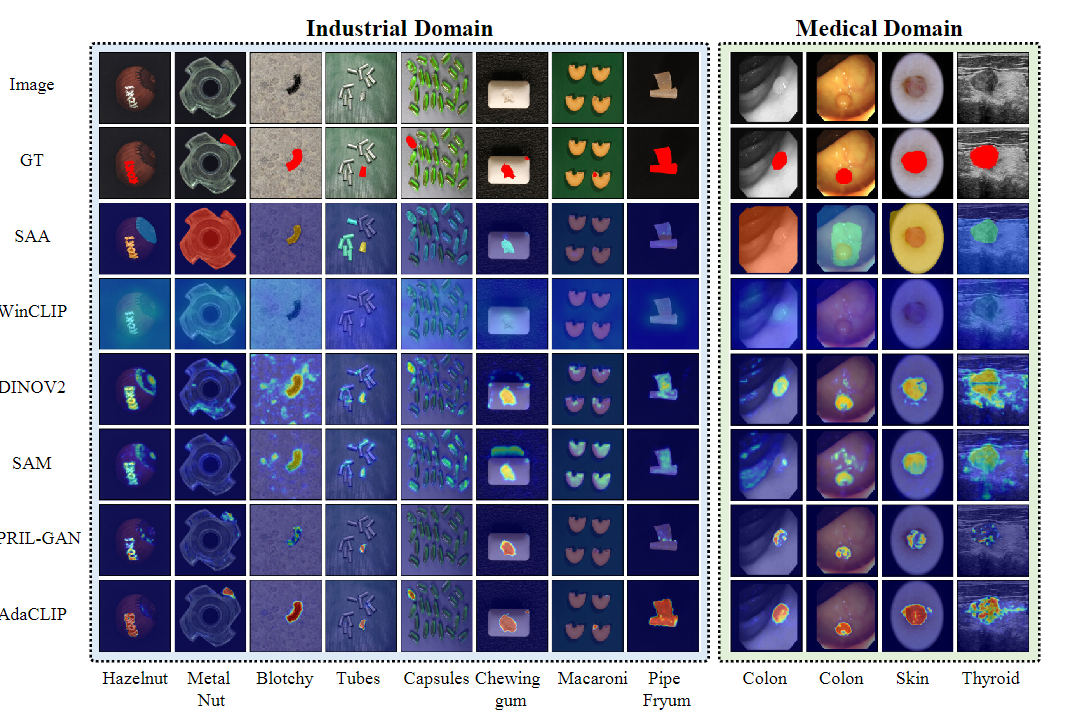
图3进一步展示了各种数据集的预测异常图的可视化:
1.与其他方法相比,AdaCLIP对新工业类别表现出更准确的分割:对tube、capsules、pipe fryum等挑战性类别的精确检测结果进一步凸显了AdaCLIP的优越性。2.AdaCLIP显示了对不同医疗类别的各种异常的精确检测,AdaCLIP在定位异常病变/肿瘤区域方面具有明显的优越性
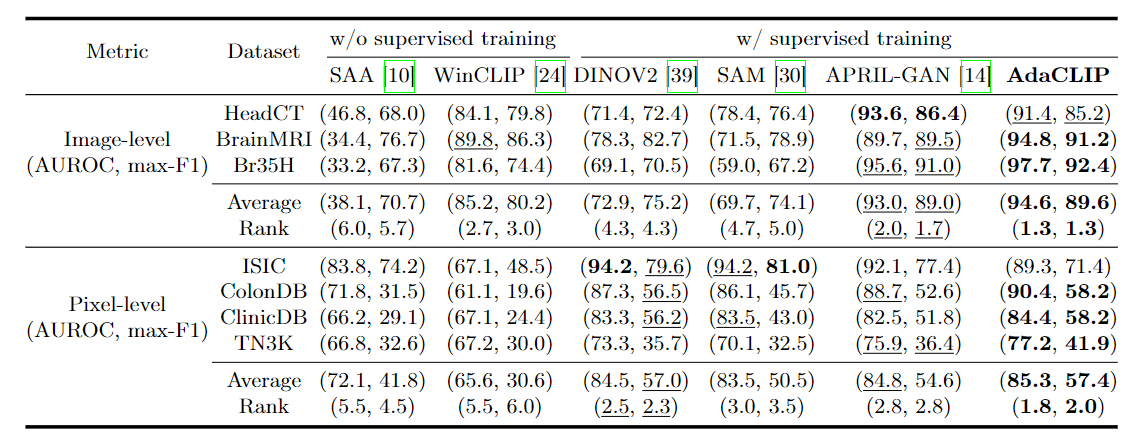
图2是零样本异常检测方法在医学领域数据集上的比较。最好的表现用粗体表示,第二好的表现用下划线表示。Rank表示不同方法在不同数据集上的平均性能排名。
结果:AdaClip基本上表现最好
训练方法的性能明显优于SAA和WinCLIP。AdaCLIP在这方面表现最好