【Java】一篇详解HashMap的扩容机制!!
如果小伙伴对HashMap的扩容机制不了解,那么这篇文章带你吃透扩容机制,如果对你有帮助,希望可以点赞、收藏!!
HashMap的扩容机制是为了应对元素数量增长导致的哈希冲突加剧问题,通过扩大数组容量来分散元素,保证查询效率。
其核心逻辑是:当数组数量超过阈值时,将数组容量翻倍,并将旧数组元素迁移到新数组中。
一、扩容核心参数:
3个关键参数:
- 容量(capacity):哈希表底层数组的长度,默认初始容量为16(必须是2的幂次)。
- 负载因子(loadFactor):衡量数组填充程度的阈值比例,默认为0.75。
- 阈值(threshold):出发扩容的临界值,计算公式为:threshold=capacity*loadFactor(16*0.75=12)。
二、扩容触发条件:
当HashMap的元素数量size超过阈值时,触发扩容。
即:if(size>threshold) ->执行扩容
三、扩容完整流程(以JDK1.8为例)
JDK1.8中HashMap底层为 数组+链表+红黑树,扩容流程优化后更高效,步骤如下:
1.计算新容量:
新容量=旧容量×2
2.计算新阈值:
新阈值=新容量×负载因子
3.创建新数组:
根据新容量创建一个更大的数组。
4.迁移元素:
将旧元素中的所有元素(链表/红黑树节点)重新计算索引,迁移到新数组中。
四、关键:元素迁移的索引计算:
由于容量一直为2的幂次,JDK1.8中元素迁移时的新索引可以通过高位判断快速计算,无需重新计算哈希值。
- 旧容量为
oldCap(如 16),新容量为newCap = oldCap × 2(如 32)。 - 元素在旧数组中的索引为
oldIndex(通过 hash & (oldCap - 1) 计算)。 - 新索引只有两种可能:
若元素哈希值的第n位(n为oldCap的幂次,如 16 是 2⁴,n=4)为0 → 新索引 =oldIndex。
若第n位为1 → 新索引 =oldIndex + oldCap。
五、举例:
假设我们有一个初始状态的HashMap:
- 容量
oldCap = 16(数组索引 0~15),阈值threshold = 12,负载因子0.75。
步骤 1:触发扩容
当插入第 13 个元素时,size = 13 > threshold = 12,触发扩容:
- 新容量newCap = 16 × 2 = 32(数组索引 0~31)。
- 新阈值newThreshold = 32 × 0.75 = 24。
步骤 2:迁移元素(以两个元素为例)
假设旧数组中有两个元素,哈希值(简化后)如下:
- 元素 A:
hash = 0001 0101(二进制,共 8 位示意) - 元素 B:
hash = 0011 0101
计算旧索引:
旧容量16的二进制是10000,oldCap - 1 = 15(二进制01111)。
- 元素 A 旧索引:hash & 15 = 0001 0101 & 0000 1111 = 0101 → 5。
- 元素 B 旧索引:hash & 15 = 0011 0101 & 0000 1111 = 0101 → 5(与 A 哈希冲突,在旧数组索引 5 处形成链表)。
计算新索引:
新容量32是100000,oldCap = 16的二进制是10000,关键看哈希值的第 4 位(从 0 开始数,对应 16 的幂次位):
- 元素 A 的 hash 第 4 位:0001 0101 → 第 4 位是0(从右数第 5 位,因 0~3 位是低 4 位) → 新索引 = 旧索引5。
- 元素 B 的 hash 第 4 位:0011 0101 → 第 4 位是1 → 新索引 = 旧索引5 + 16 = 21。
迁移结果:
- 元素 A 从旧数组索引 5 迁移到新数组索引 5。
- 元素 B 从旧数组索引 5 迁移到新数组索引 21。
两者在新数组中不再冲突,链表被 “打散”,查询效率提高。
六、JDK1.7与1.8扩容的核心差异:
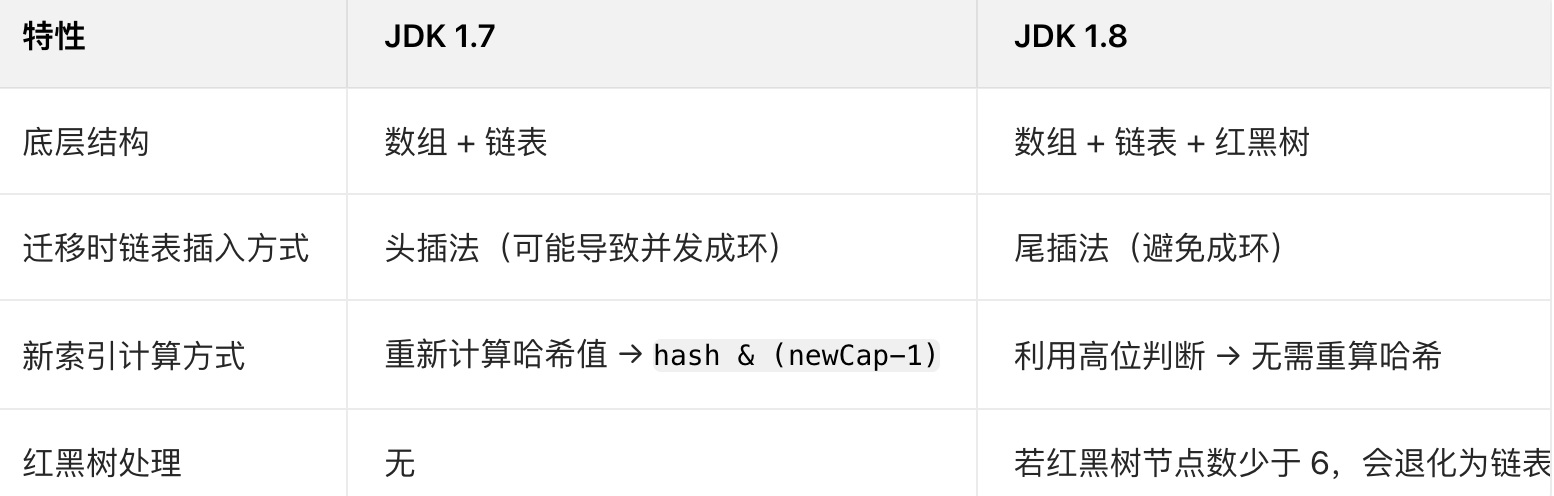
七、总结:
- HashMap通过"容量翻倍+元素迁移"实现扩容,核心目的是减少哈希冲突。
- JDK1.8的优化(如高效索引计算、尾插法)让扩容更高效且安全。
- 实际开发中,若能预估元素数量,建议初始化时指定容量,如:(new HashMap<>(1000)),减少扩容次数以提升性能。