豆包1.6+PromptPilot实战:构建智能品牌评价情感分类系统的技术探索

豆包1.6+PromptPilot实战:构建智能品牌评价情感分类系统的技术探索
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
豆包1.6+PromptPilot实战:构建智能品牌评价情感分类系统的技术探索
引言
豆包技术背景
豆包模型概述
技术架构深度解析
性能表现
PromptPilot简介
PromptPilot核心理念
技术架构设计
智能优化机制
环境准备
豆包新模型+PromptPilot完成品牌评价情感
场景描述:
实践点:
数据资料:
体验流程:
1. 生成Prompt
2. 调式Prompt
3. 准备测评数据
技术挑战与解决方案
主要技术挑战
持续优化策略
未来发展趋势与展望
技术发展趋势
应用场景拓展
结论
引言
在数字化营销时代,品牌声誉管理已成为企业核心竞争力的重要组成部分。面对海量的用户评价数据,传统的人工分析方式已无法满足实时性和准确性的双重要求。本文基于火山引擎豆包新模型与PromptPilot工具的实战经验,深入探讨了智能品牌评价情感分类系统的构建过程,为企业数字化转型提供了新的技术路径。
豆包技术背景
豆包模型概述
豆包(Doubao)是字节跳动推出的新一代大语言模型,基于云雀模型架构进行深度优化。作为火山引擎AI服务的核心组件,豆包模型在中文语言理解、多模态处理和推理能力方面表现出色。
核心技术特点:
- 多模态融合能力:支持文本、图像、音频等多种数据类型的统一处理
- 中文优化:针对中文语言特性进行专门优化,在中文理解任务上表现优异
- 高效推理:采用先进的模型压缩和加速技术,实现低延迟高吞吐
- 可控生成:支持精细化的内容控制和安全过滤机制
技术架构深度解析
豆包模型采用了创新的Transformer架构优化,通过多层次的注意力机制实现高效的语言理解:
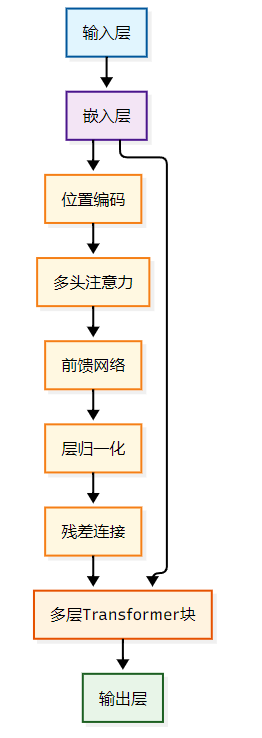
关键创新点:
- 多尺度注意力:结合局部和全局注意力机制,提升长文本理解能力
- 知识增强:融入大规模知识图谱,提升推理准确性
- 中文语言优化:针对中文语法特点进行专门的预训练优化
性能表现
根据公开测试数据,豆包模型在多项中文NLP任务上达到了业界先进水平:
| 任务类型 | 测试集 | 豆包模型表现 | 备注 |
| 情感分析 | 中文情感分析 | 94.2% | 准确率 |
| 文本分类 | 新闻分类 | 96.7% | F1分数 |
| 阅读理解 | 中文阅读理解 | 89.3% | EM分数 |
| 对话生成 | 多轮对话 | 92.1% | BLEU分数 |
PromptPilot简介
PromptPilot核心理念
PromptPilot是火山引擎推出的智能提示词工程平台,旨在解决大模型应用中提示词设计、优化和管理的复杂性问题。作为一款面向大模型应用的全链路优化平台,PromptPilot覆盖了从构想、开发部署到迭代优化的全过程。
核心功能模块:
- 智能提示词生成:基于任务描述自动生成优化的提示词模板
- 交互式需求澄清:通过对话引导用户明确具体需求
- A/B测试框架:支持多版本提示词的效果对比和优化
- 实时监控与调优:提供提示词性能监控和自动调优机制
- 版本管理:完整的提示词版本控制和回滚机制
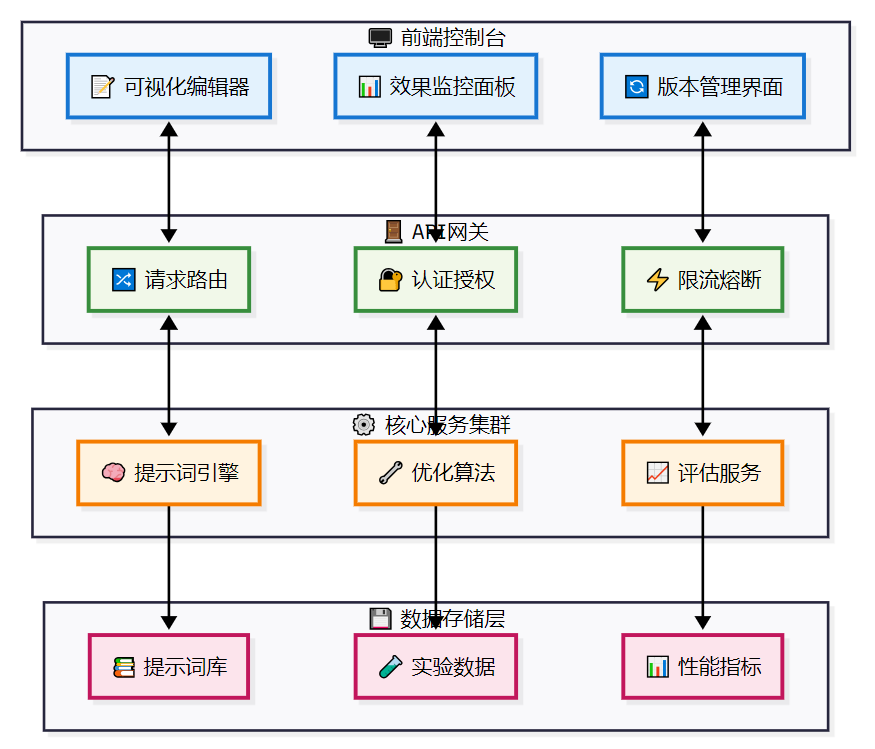
技术架构设计
PromptPilot采用微服务架构,实现了高可用、高扩展的服务体系:
智能优化机制
PromptPilot集成了多种先进的提示词优化策略:
1. 需求翻译器机制
平台作为"需求翻译器",通过交互过程捕捉用户意图,将模糊的想法转化为AI能精准执行的专业指令。
2. 闭环改进系统
def prompt_optimization_loop(initial_prompt, test_data):current_prompt = initial_promptfor iteration in range(max_iterations):# 执行测试results = evaluate_prompt(current_prompt, test_data)# 分析性能performance_metrics = analyze_results(results)# 如果达到目标性能,退出循环if performance_metrics['accuracy'] >= target_threshold:break# 基于反馈优化提示词current_prompt = optimize_prompt(current_prompt, results)return current_prompt3. 多模型接入能力
PromptPilot支持接入豆包、DeepSeek等多个大模型,提供灵活的模型选择和对比测试功能。
环境准备
- 账号准备:请确保您已注册火山方舟账号:注册火山方舟账号;并实名认证:火山方舟账号实名认证
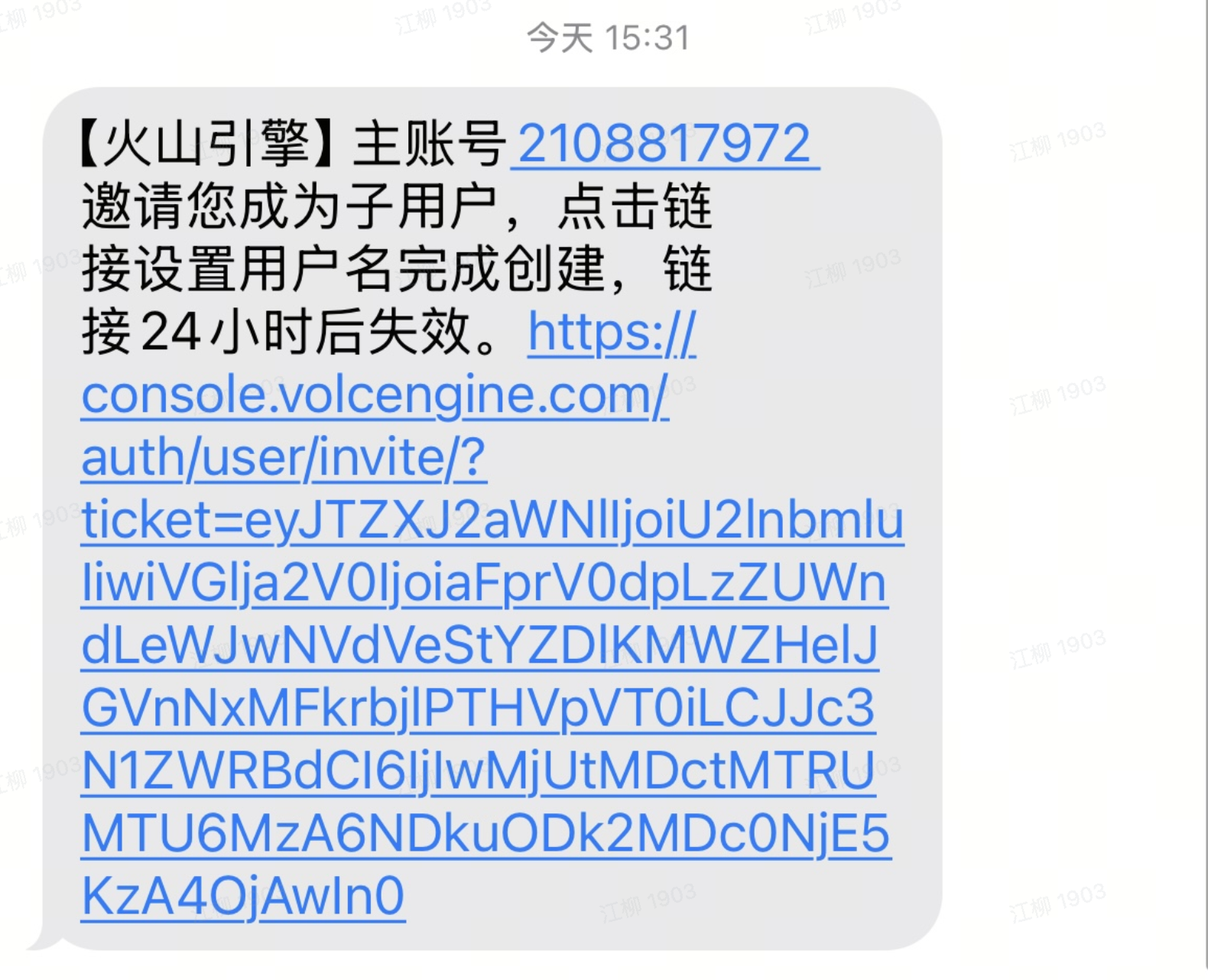
- 子账号准备:您将收到以下短信,点击链接,输入您的专属昵称
- 登录入口:账号登录-火山引擎
-
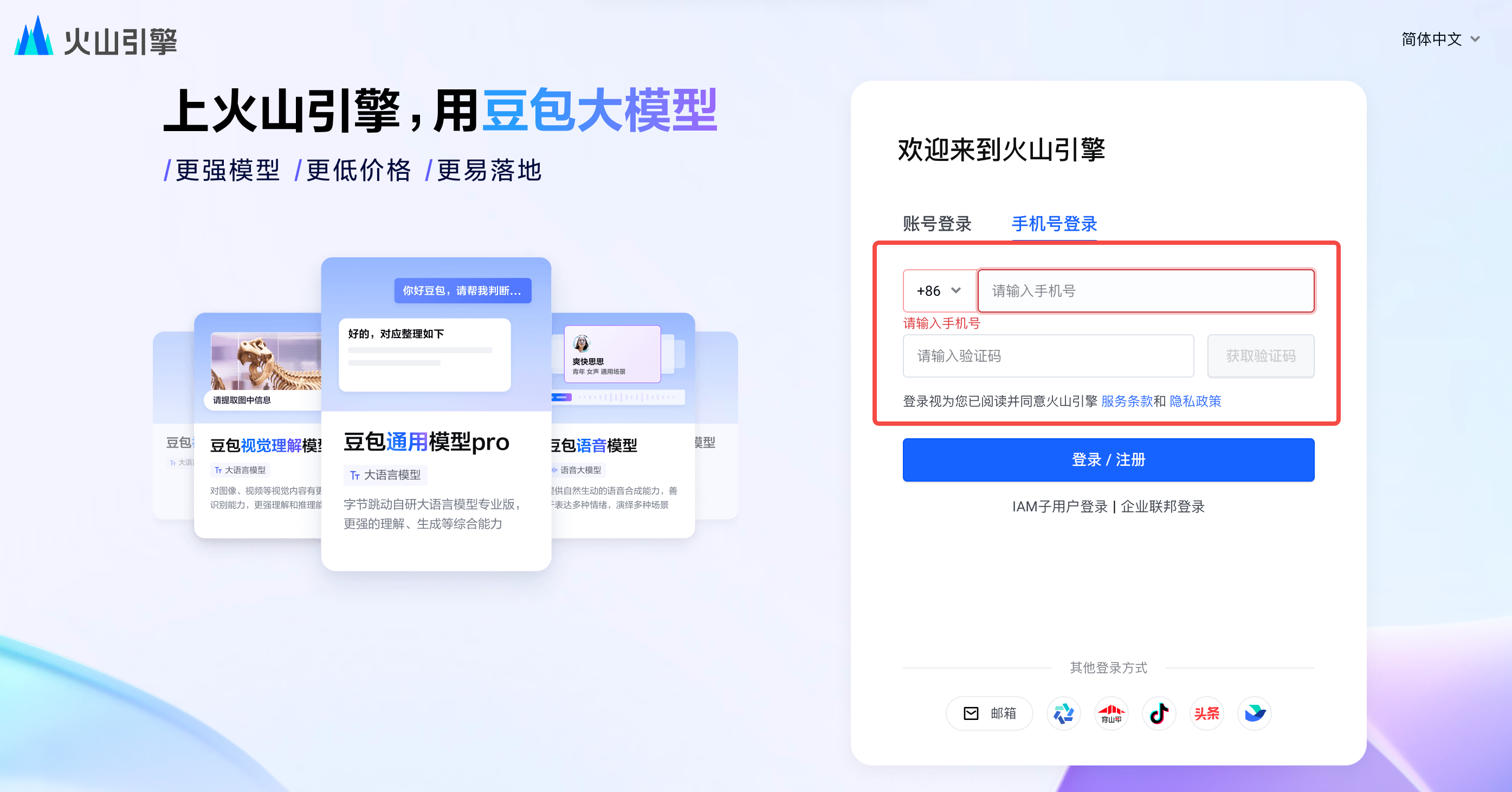
- 登录火山引擎官网,选择手机号登录
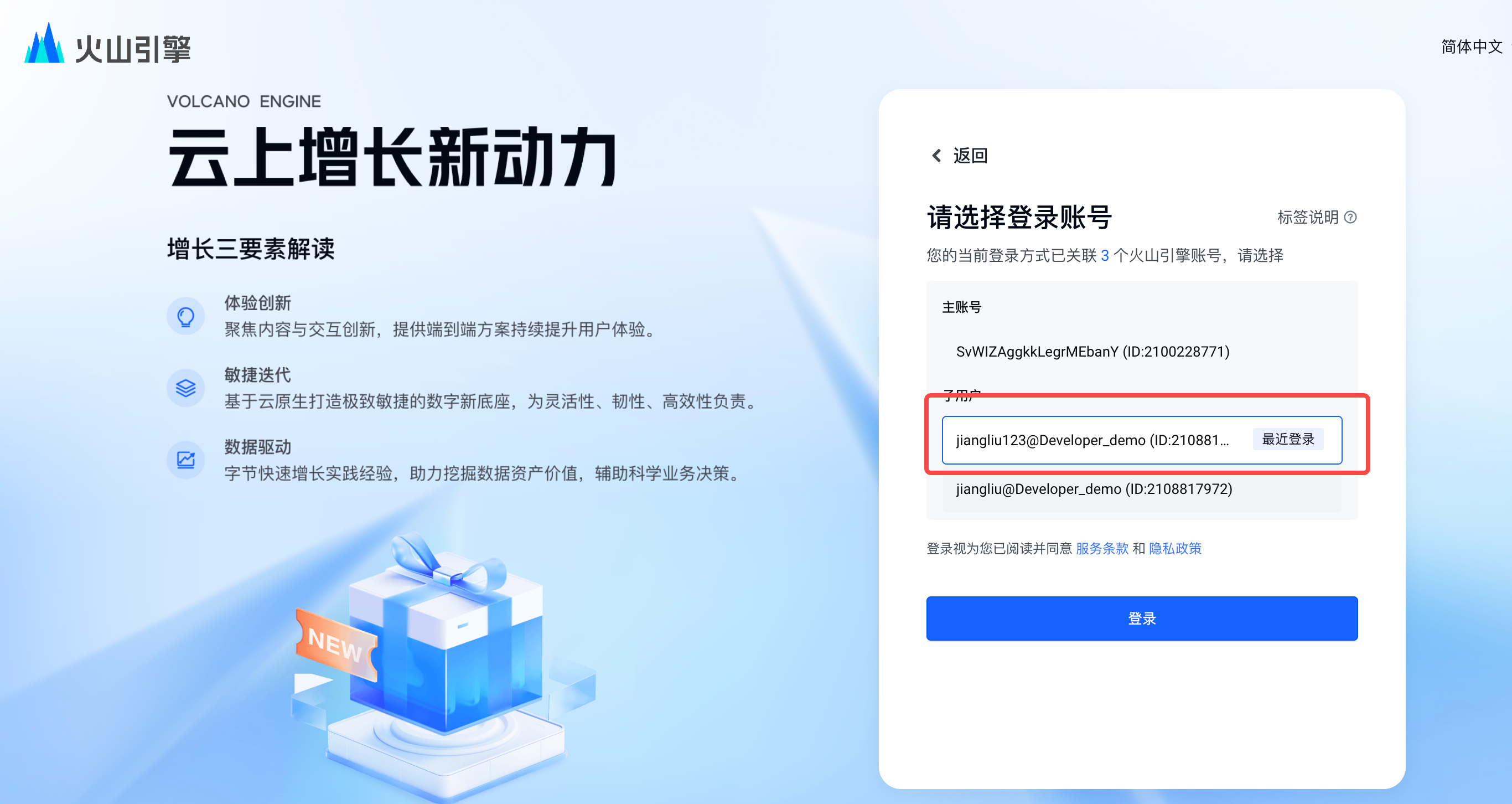
- Step2:选择子账号登录(XXX@Developer_demo)
- 登录火山引擎官网,选择手机号登录
- 豆包模型开通,开通模型后即可领取50万tokens免费体验额度
-
- 访问方舟控制台-开通管理开通模型服务(已提前为大家开通)
- 访问方舟控制台-API Key 管理创建 API Key,获取API key
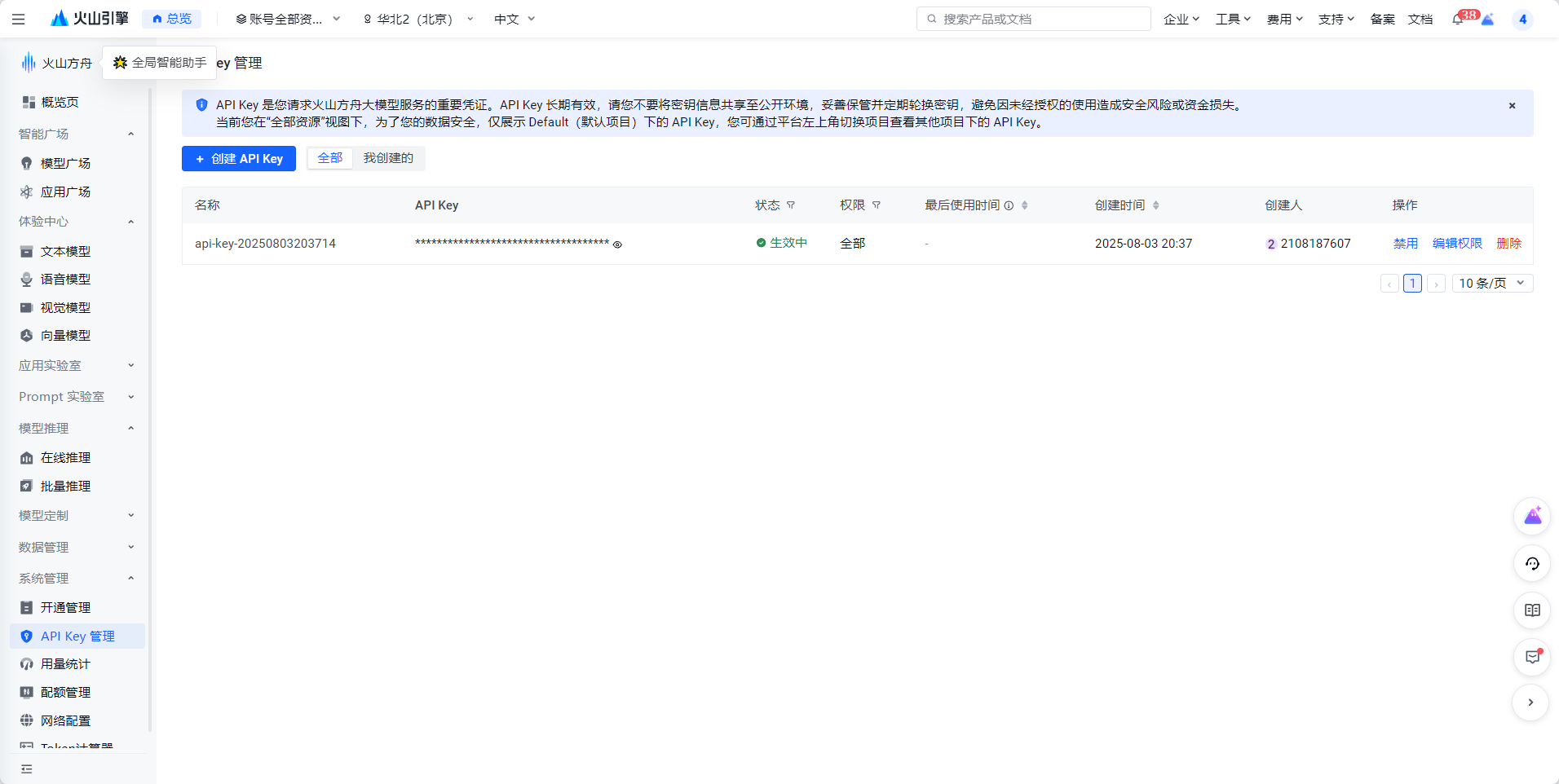
- 如您有开发经验,现场本地调用豆包模型API :需配置 Python 3.9 及以上版本和开发环境(如 VS Code、PyCharm),或使用自选语言环境完成基础准备,参考快速入门-调用模型服务--火山方舟
豆包新模型+PromptPilot完成品牌评价情感
准备好了环境之后,我们进入PromptPilot体验地址,使用豆包新模型+PromptPilot完成品牌评价情感。
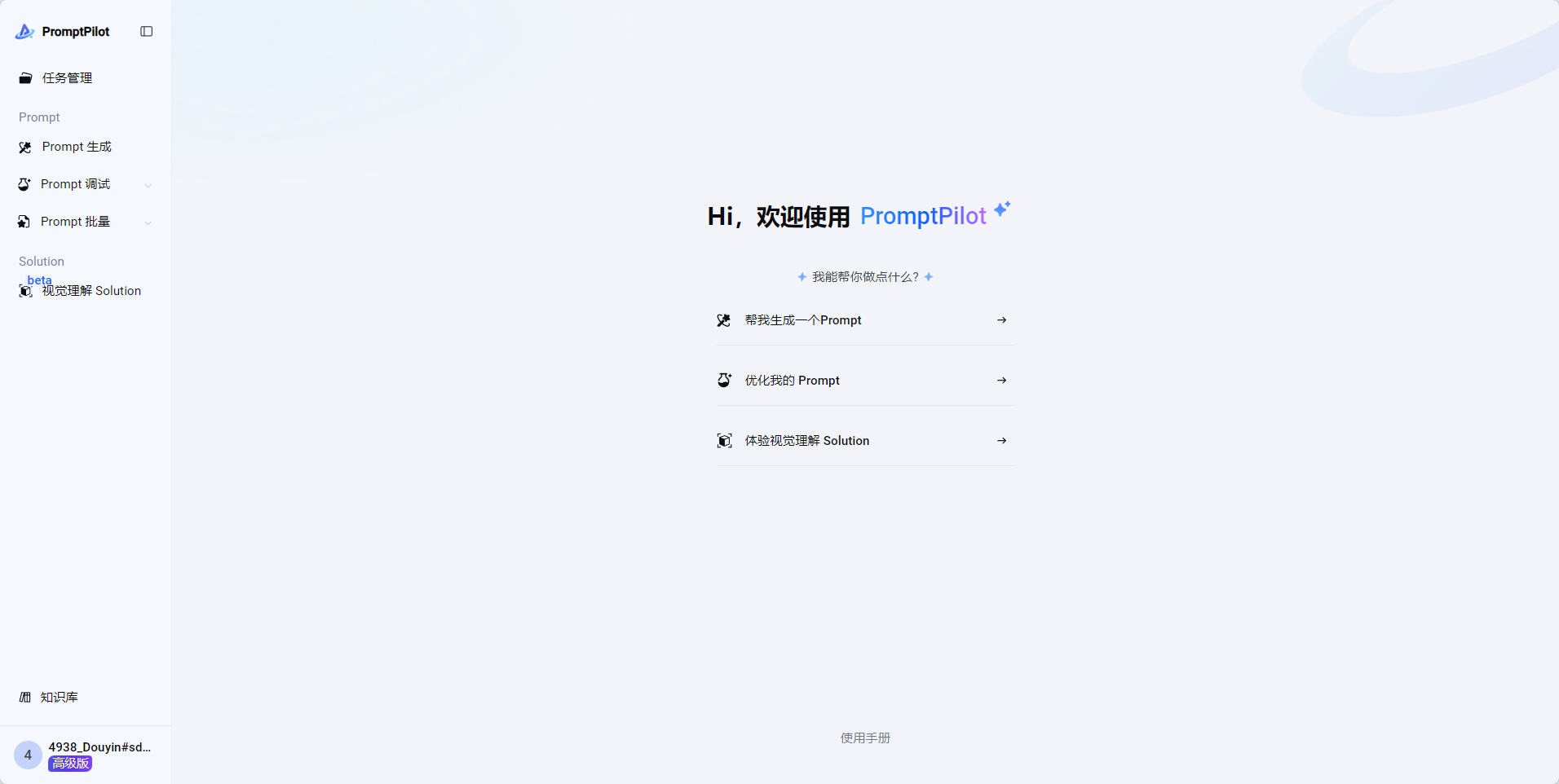
基于豆包模型和PromptPilot构建的品牌评价情感分类系统采用分层架构:
场景描述:
在互联网上,有很多客户发布的关于我们“脱敏品牌1”产品的内容和一些评价,有说我们这个面好吃的,有说这个饮料价格贵之类的,好的坏的都有,我们比较希望把这些内容能用大模型识别和格式化整理一下。首先要看一下,这些客户说的是正面评价还是负面评价;如果是负面的,就再分个类,看看是价格问题还是口味口感还是什么其他问题,然后看看对应的是哪个产品名,是牙膏还是饮料还是什么其他产品,给出来产品名称。我目前想到的是以下问题分类:
包装不当:产品包装相关的评价;
价格:产品价格相关的评价;
口味口感:食品类产品的口味、口感相关的内容;
食品安全:关于食品类产品卫生、安全性的内容;
售后维权:退换货等售后相关的内容;
其他:无法归类为前述标签的内容;
以JSON格式输出,字段是情感判断、评价维度、产品名称。实践点:
目标:学会文本内容理解的相关功能
涉及功能点:prompt生成,文本内容理解,包括:answer生成,反馈,评估和优化,以及数据集的基本操作
数据资料:
PE中级-评测case集.xlsx
体验流程:
1. 生成Prompt
- 进入PromptPilot
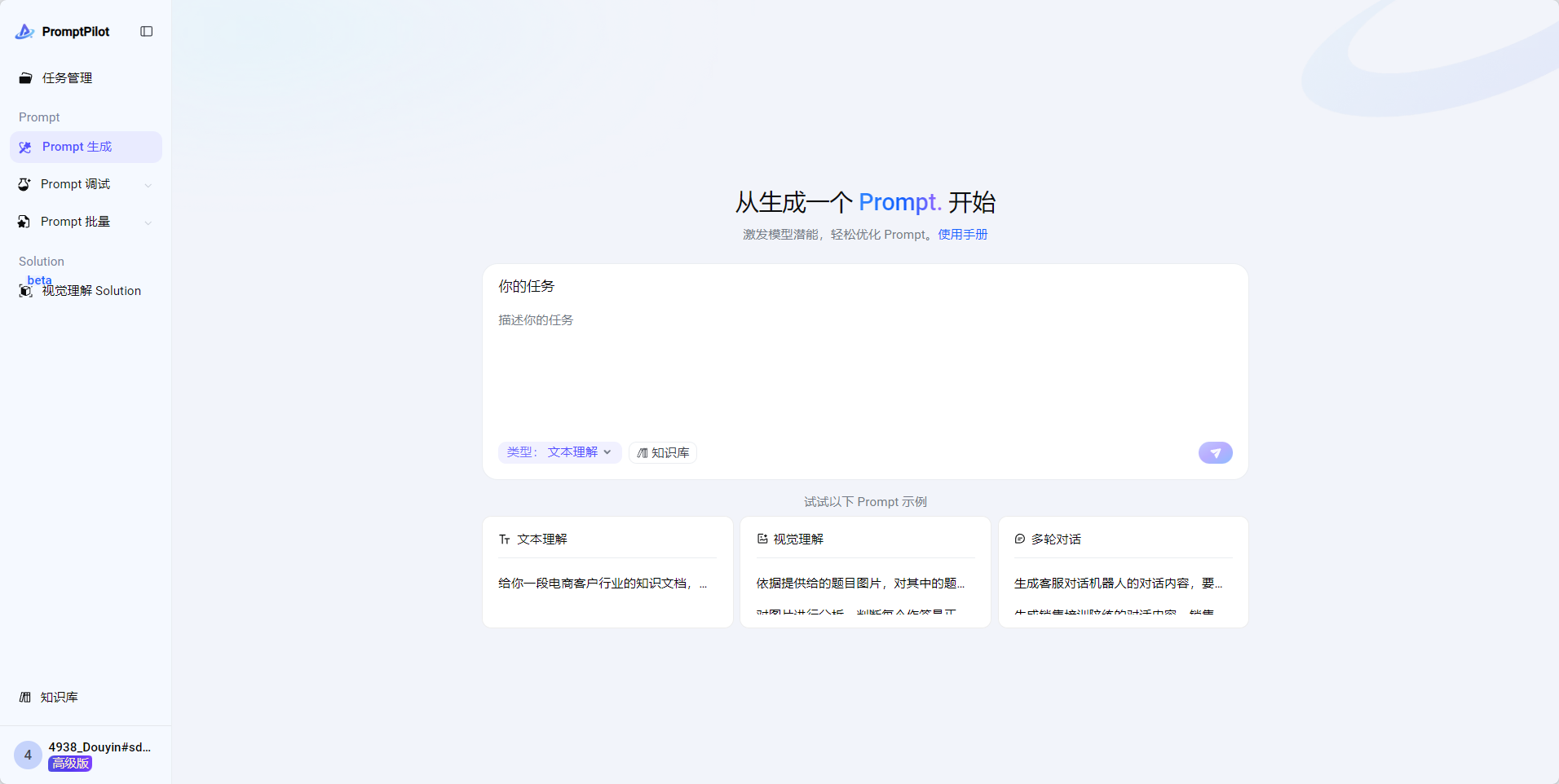
- 在“你的任务”栏内输入任务描述,点击“生成Prompt”
输入内容:
在互联网上,有很多客户发布的关于我们“脱敏品牌1”产品的内容和一些评价,有说我们这个面好吃的,有说这个饮料价格贵之类的,好的坏的都有,我们比较希望把这些内容能用大模型识别和格式化整理一下。首先要看一下,这些客户说的是正面评价还是负面评价;如果是负面的,就再分个类,看看是价格问题还是口味口感还是什么其他问题,然后看看对应的是哪个产品名,是牙膏还是饮料还是什么其他产品,给出来产品名称。我目前想到的是以下问题分类:
包装不当:产品包装相关的评价;
价格:产品价格相关的评价;
口味口感:食品类产品的口味、口感相关的内容;
食品安全:关于食品类产品卫生、安全性的内容;
售后维权:退换货等售后相关的内容;
其他:无法归类为前述标签的内容;
以JSON格式输出,字段是情感判断、评价维度、产品名称。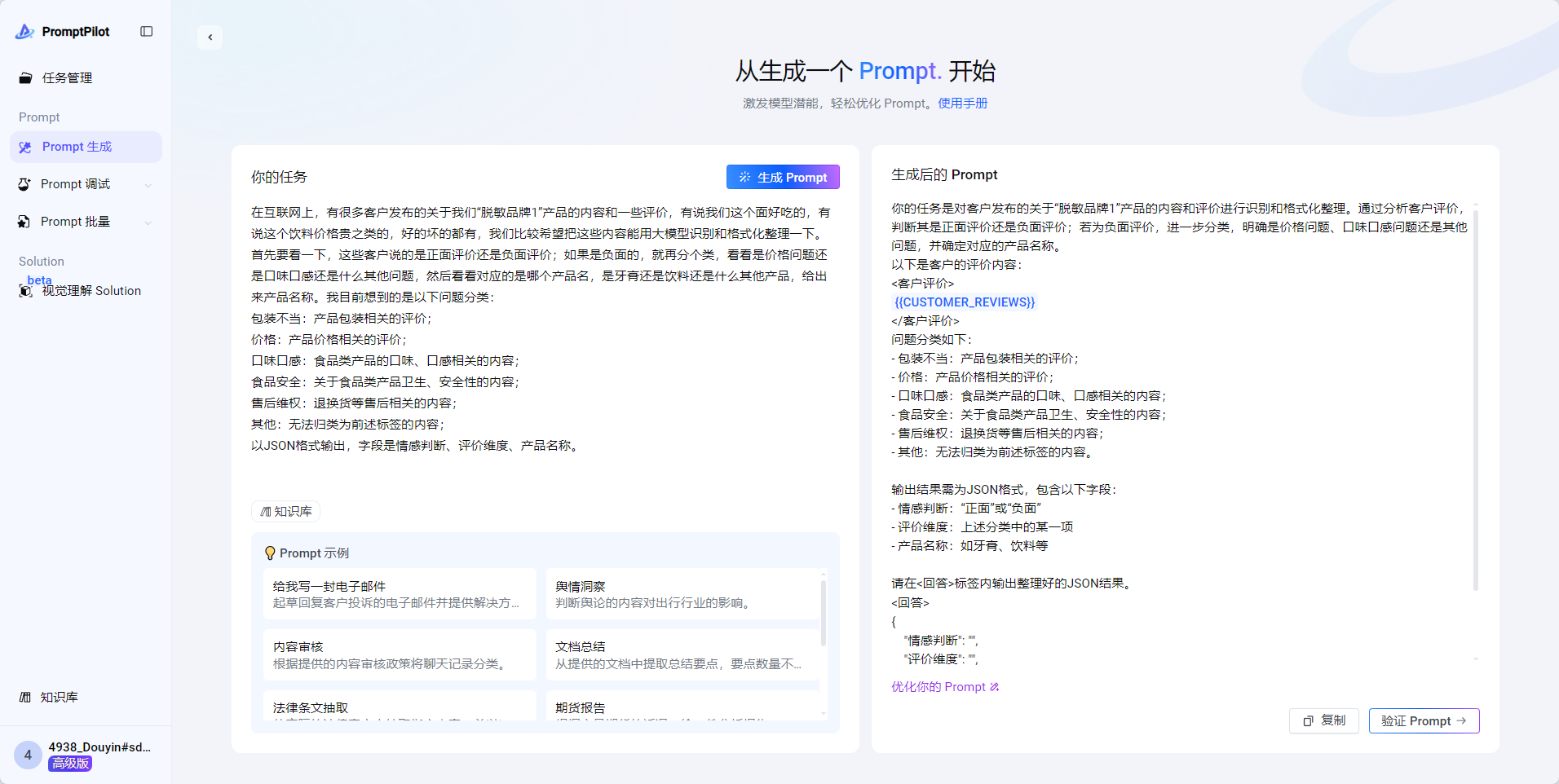
输出结果:
你的任务是对客户发布的关于“脱敏品牌1”产品的内容和评价进行识别和格式化整理。通过分析客户评价,判断其是正面评价还是负面评价;若为负面评价,进一步分类,明确是价格问题、口味口感问题还是其他问题,并确定对应的产品名称。
以下是客户的评价内容:
<客户评价>
{{CUSTOMER_REVIEWS}}
</客户评价>
问题分类如下:
- 包装不当:产品包装相关的评价;
- 价格:产品价格相关的评价;
- 口味口感:食品类产品的口味、口感相关的内容;
- 食品安全:关于食品类产品卫生、安全性的内容;
- 售后维权:退换货等售后相关的内容;
- 其他:无法归类为前述标签的内容。输出结果需为JSON格式,包含以下字段:
- 情感判断:“正面”或“负面”
- 评价维度:上述分类中的某一项
- 产品名称:如牙膏、饮料等请在<回答>标签内输出整理好的JSON结果。
<回答>
{"情感判断": "","评价维度": "","产品名称": ""
}
</回答>- 反馈和调试Prompt
对生成的prompt不满意?你可以手动修改,也可以在页面右下角直接点击“优化你的Prompt”,在对话框内输入你的反馈/优化要求。
比如:你需要关注模型的规则和输出结果格式。比如“最终的输出json里面产品名称可能涉及到多个,因此需要是一个list结构;不需要思考标签和output标签,最终直接输出json即可”。
你需要关注模型的规则和输出结果格式。比如“最终的输出json里面产品名称可能涉及到多个,因此需要是一个list结构;不需要思考标签和output标签,最终直接输出json即可”。则反馈内容:
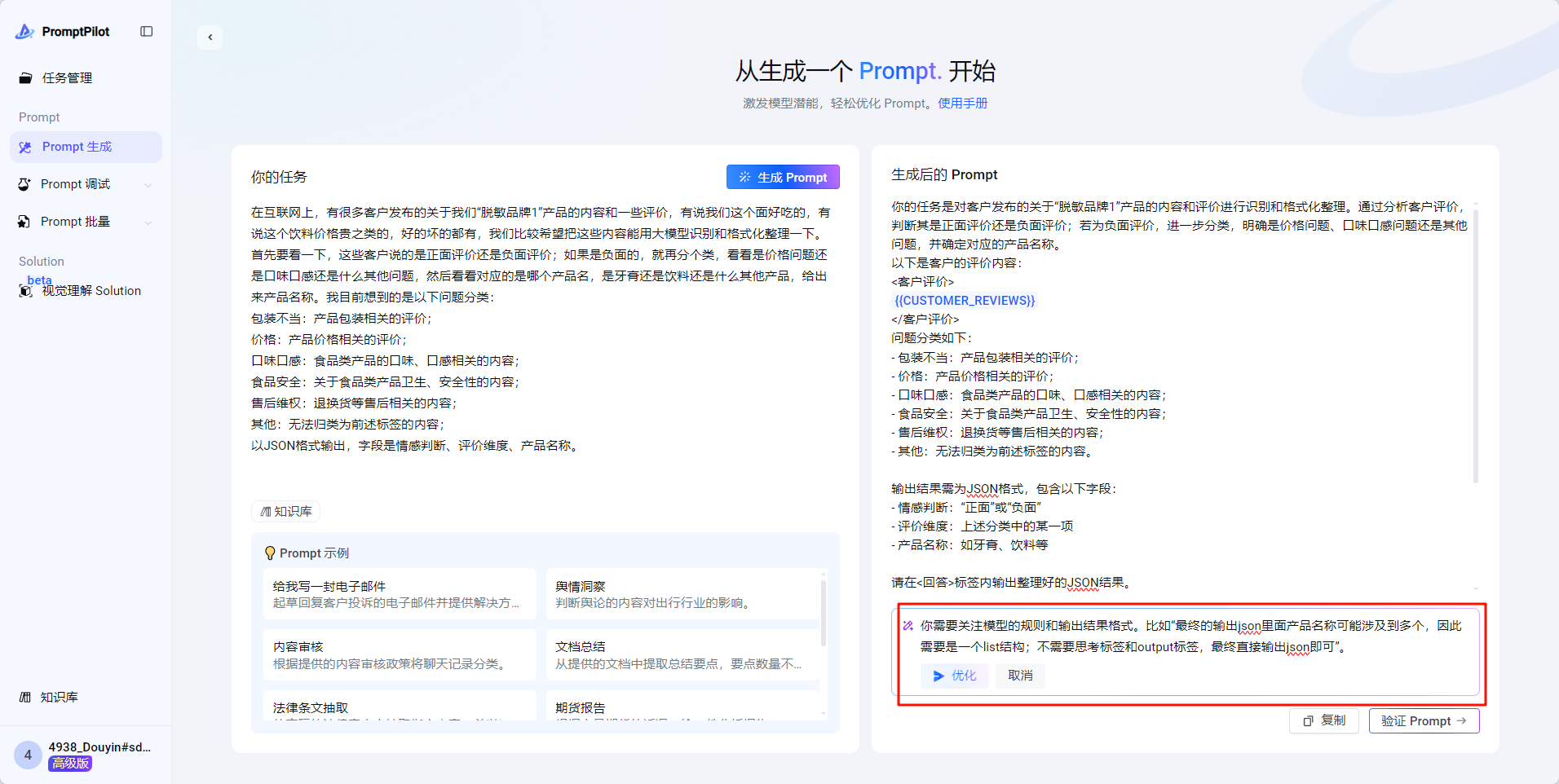
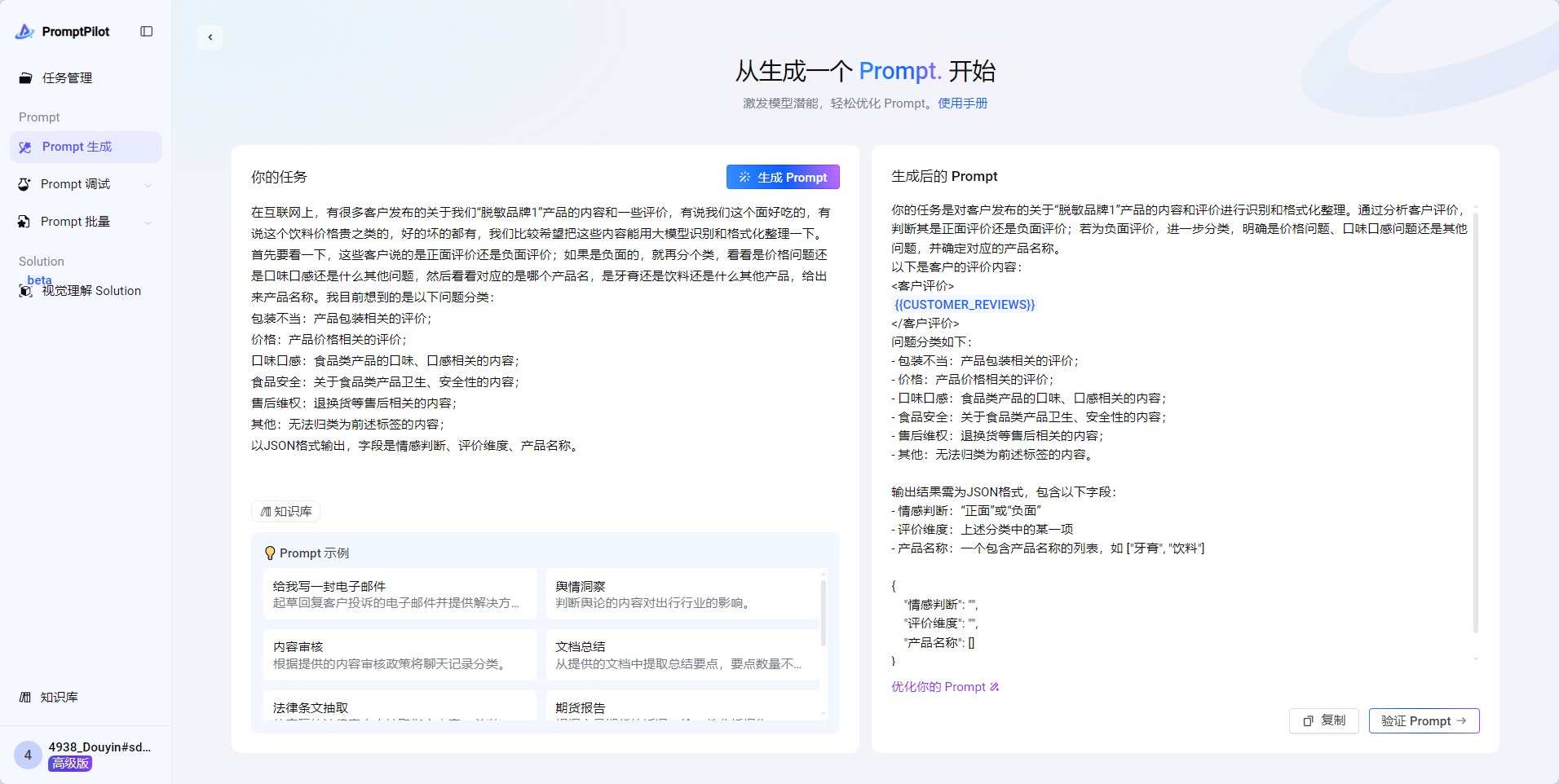
2. 调式Prompt
- 单case调试:接上一步,点击“验证Prompt”,进入Prompt调试页,选择对应的模式
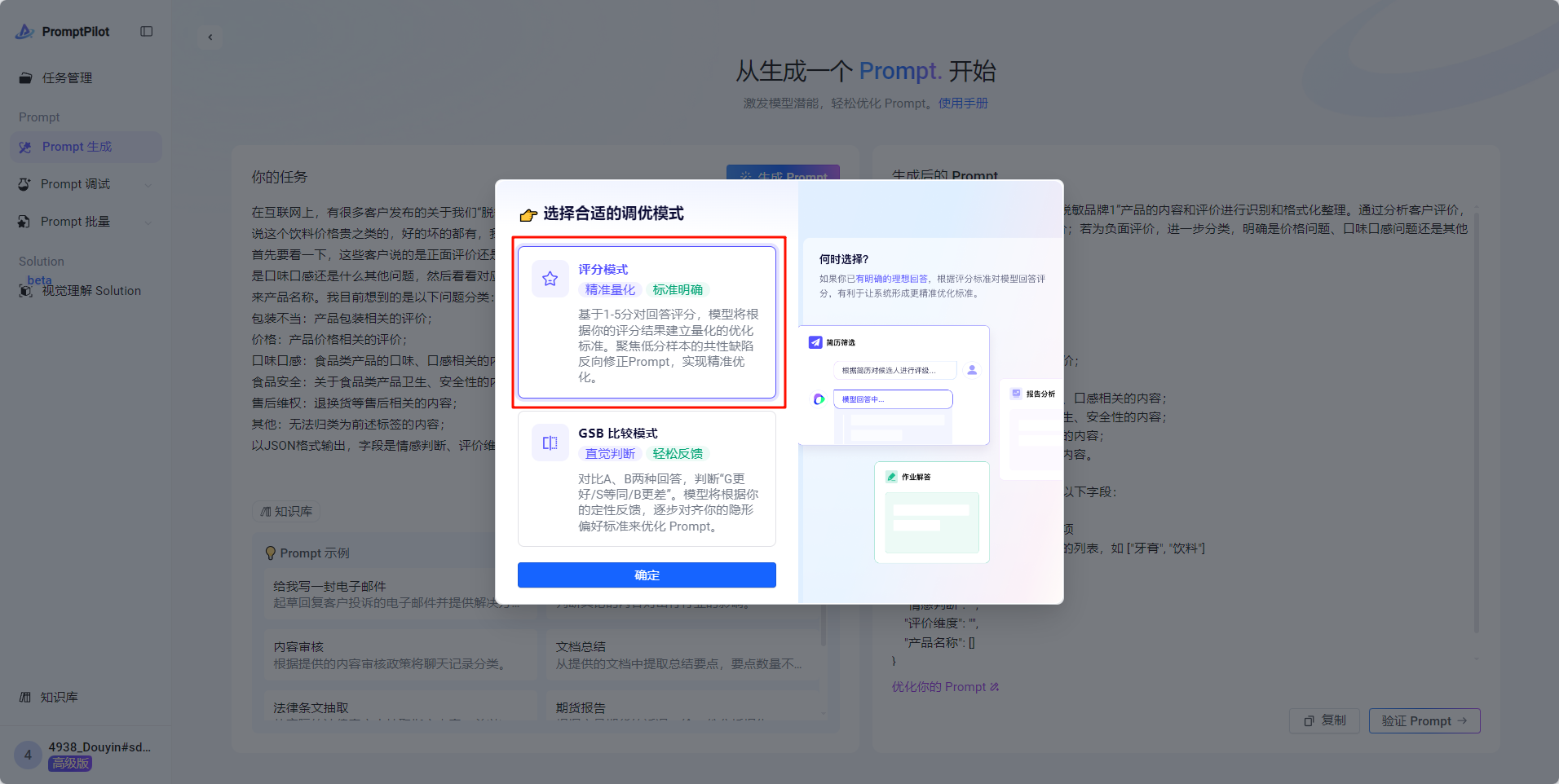
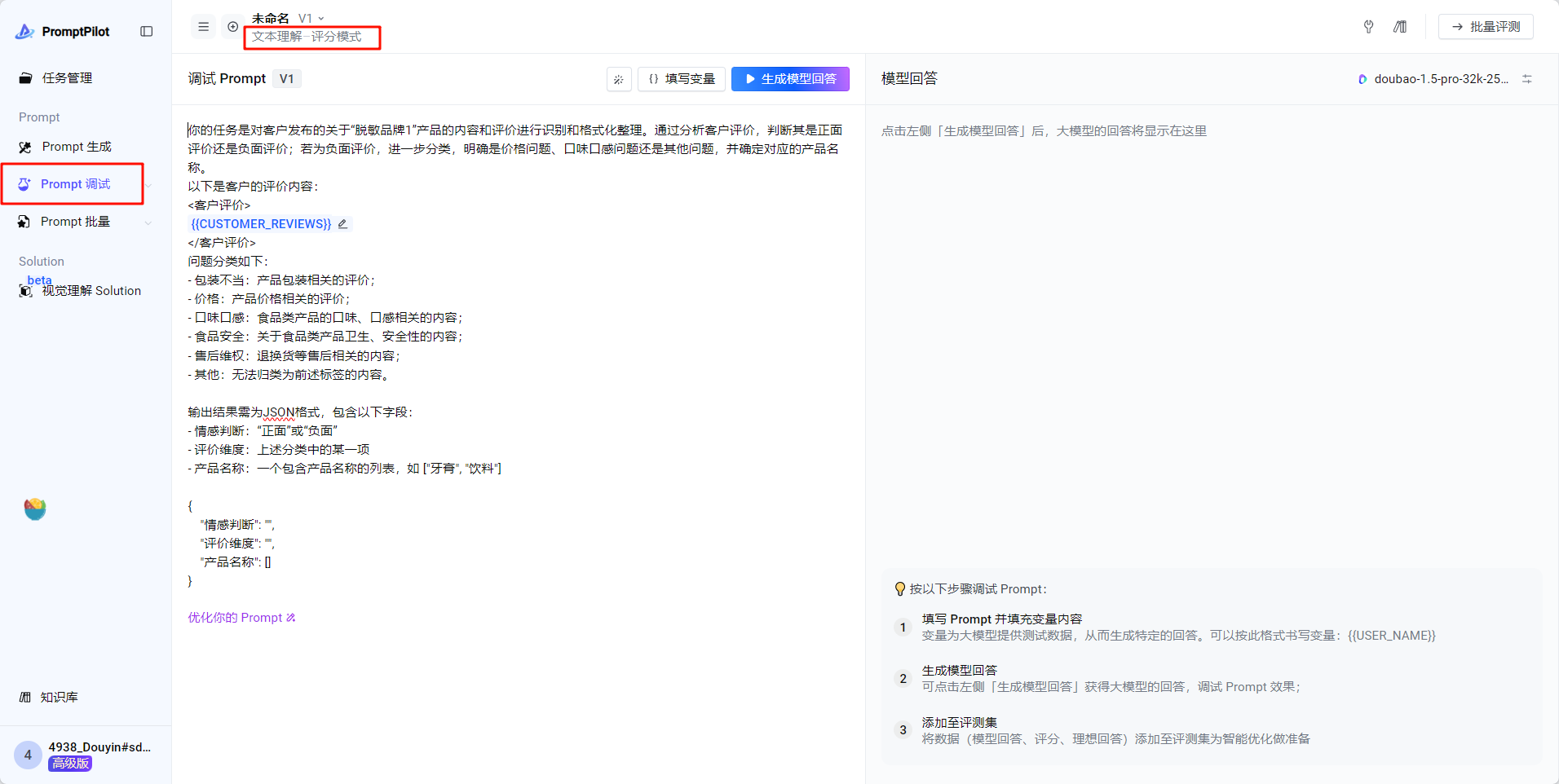
- 填写变量:就是客户给的输入case,可以从客户给的case集当中,随机取一条case,输入“变量内容对话框”,进行调试和生成回答。
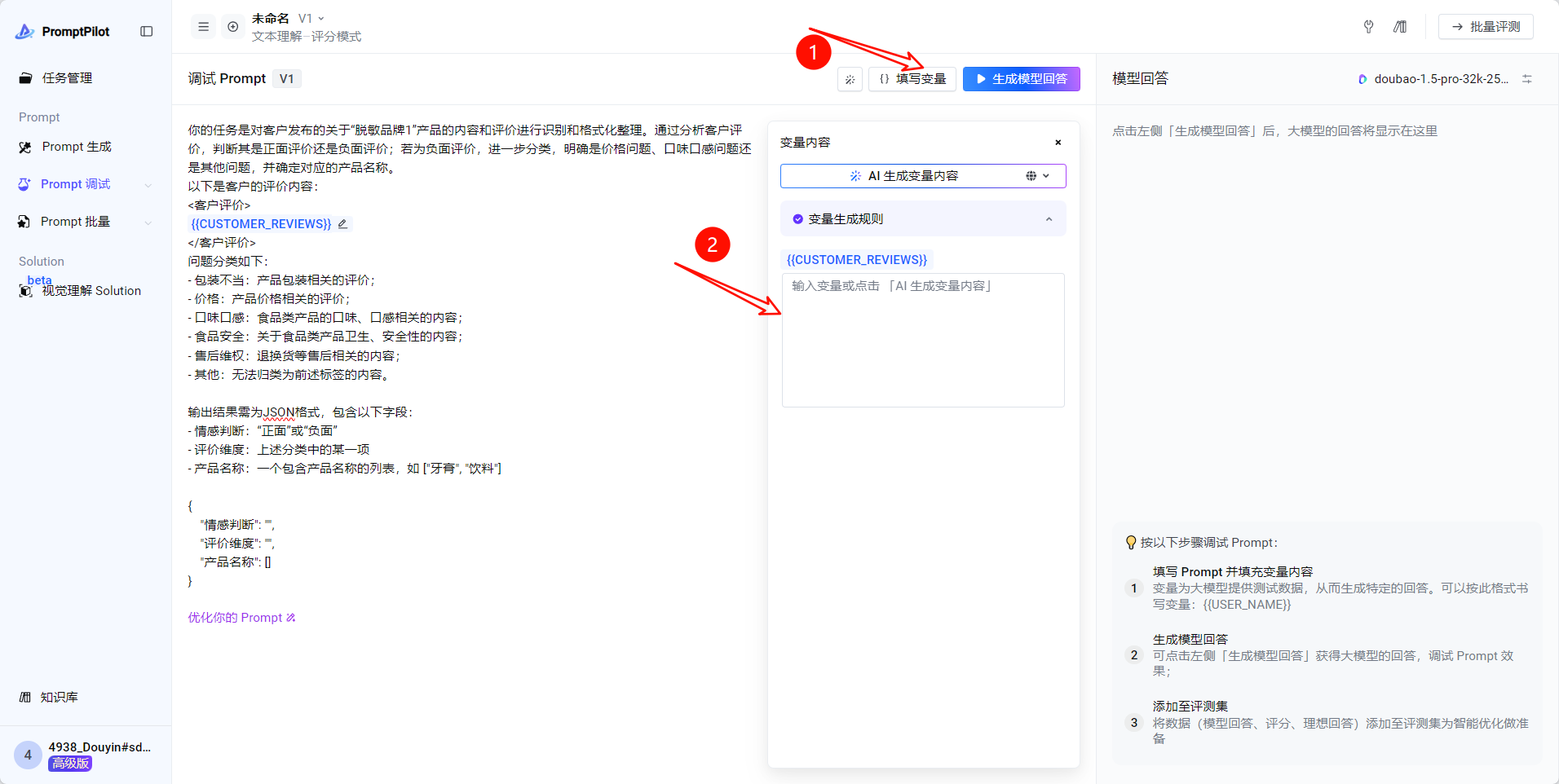
- 这里我们选择使用doubao-seed-1.6-thinking-250615来进行变量的生成
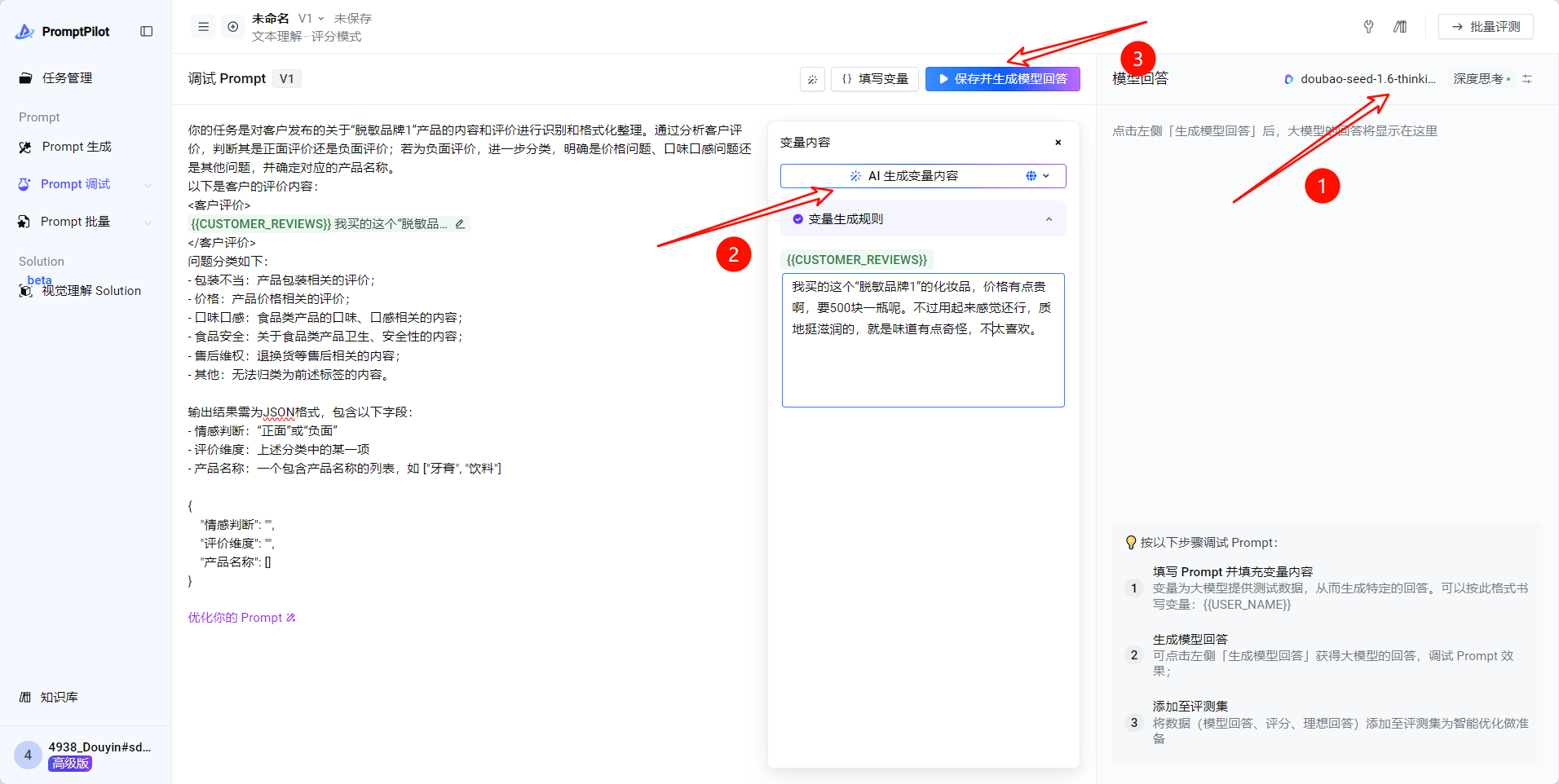
我买的这个“脱敏品牌1”的化妆品,价格有点贵啊,要500块一瓶呢。不过用起来感觉还行,质地挺滋润的,就是味道有点奇怪,不太喜欢。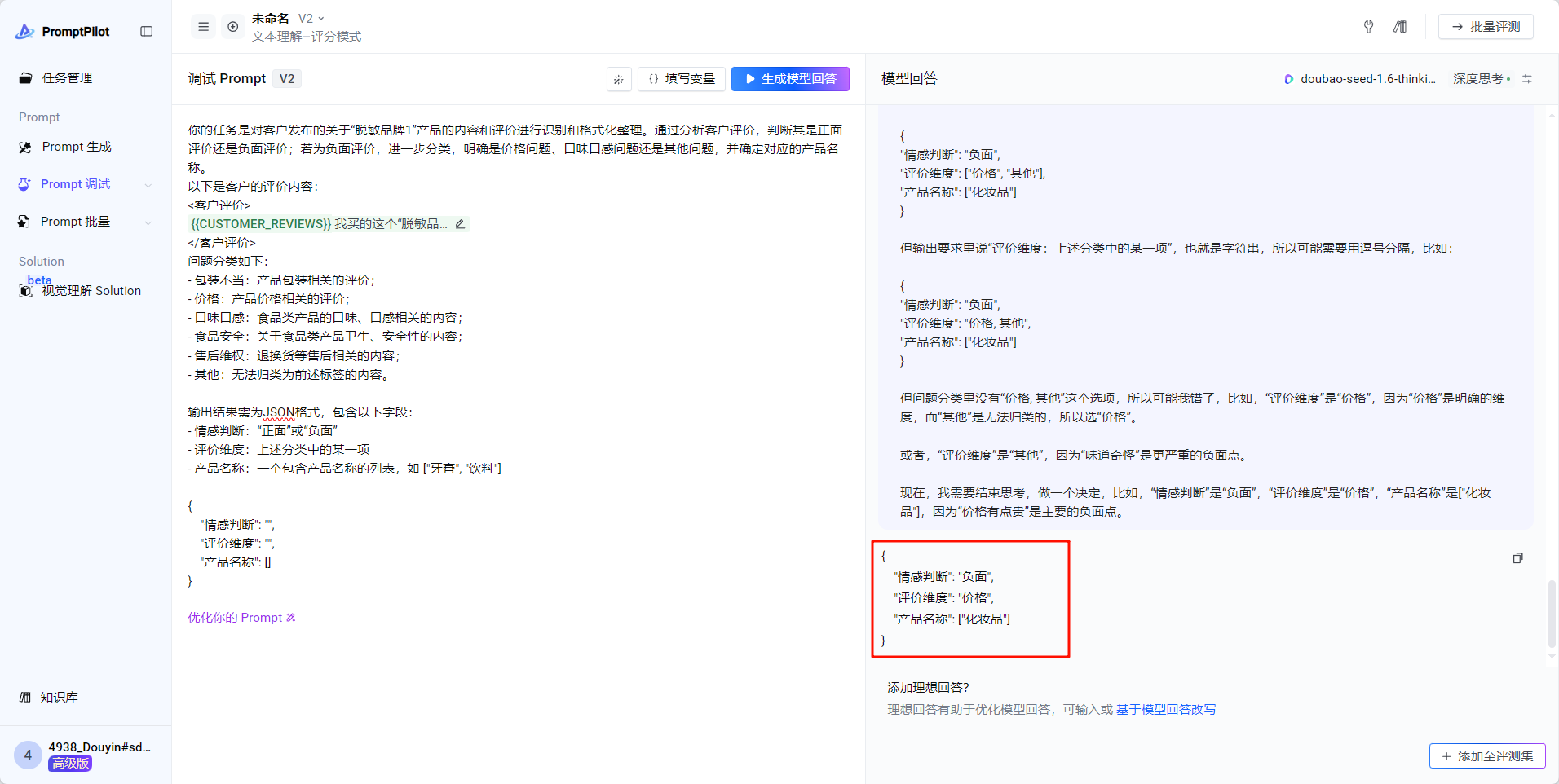
但是这里其实有一个问题!变量内容中是不允许有脱敏品牌的,所以在生成的时候添加一个规则
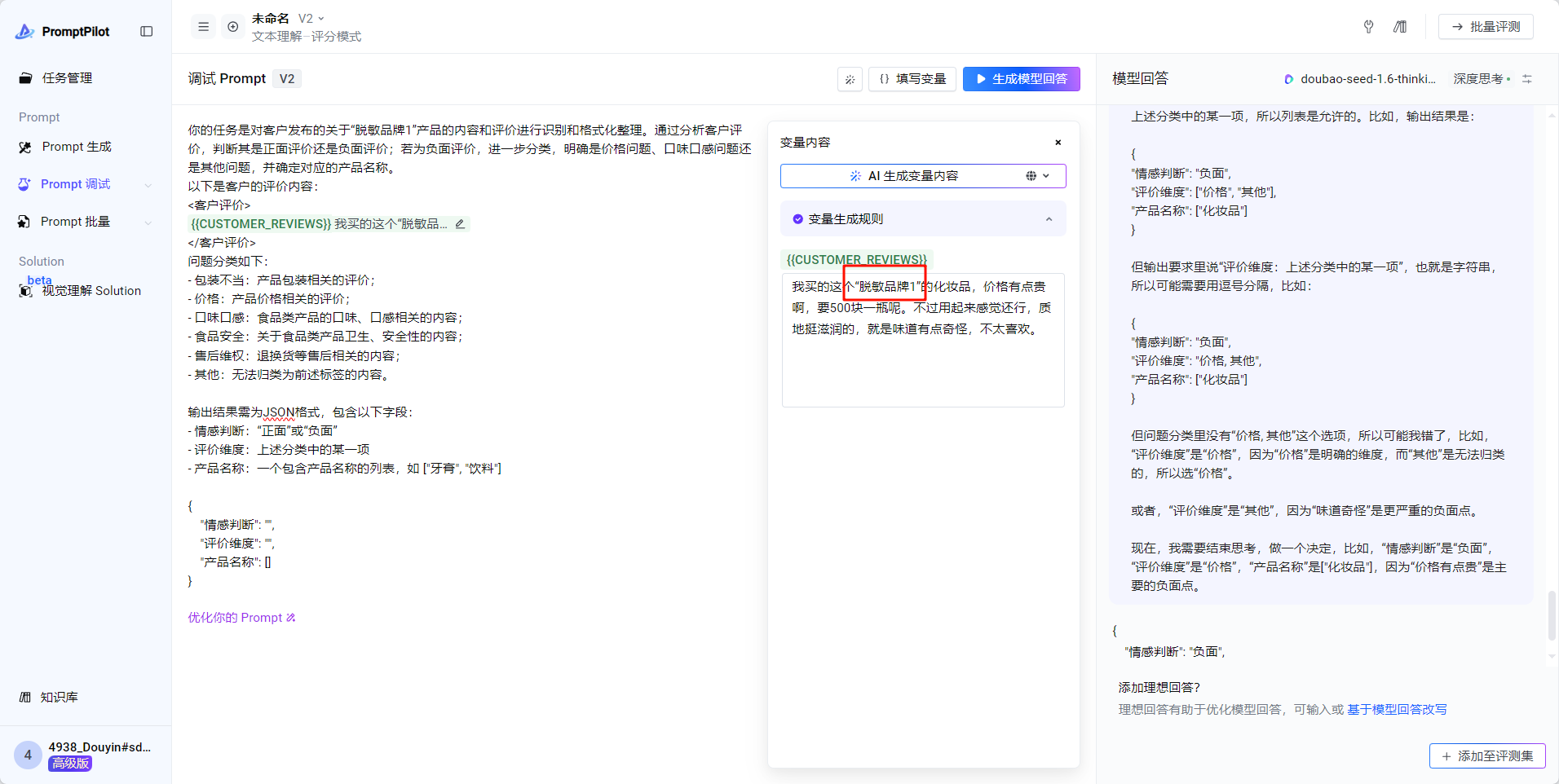
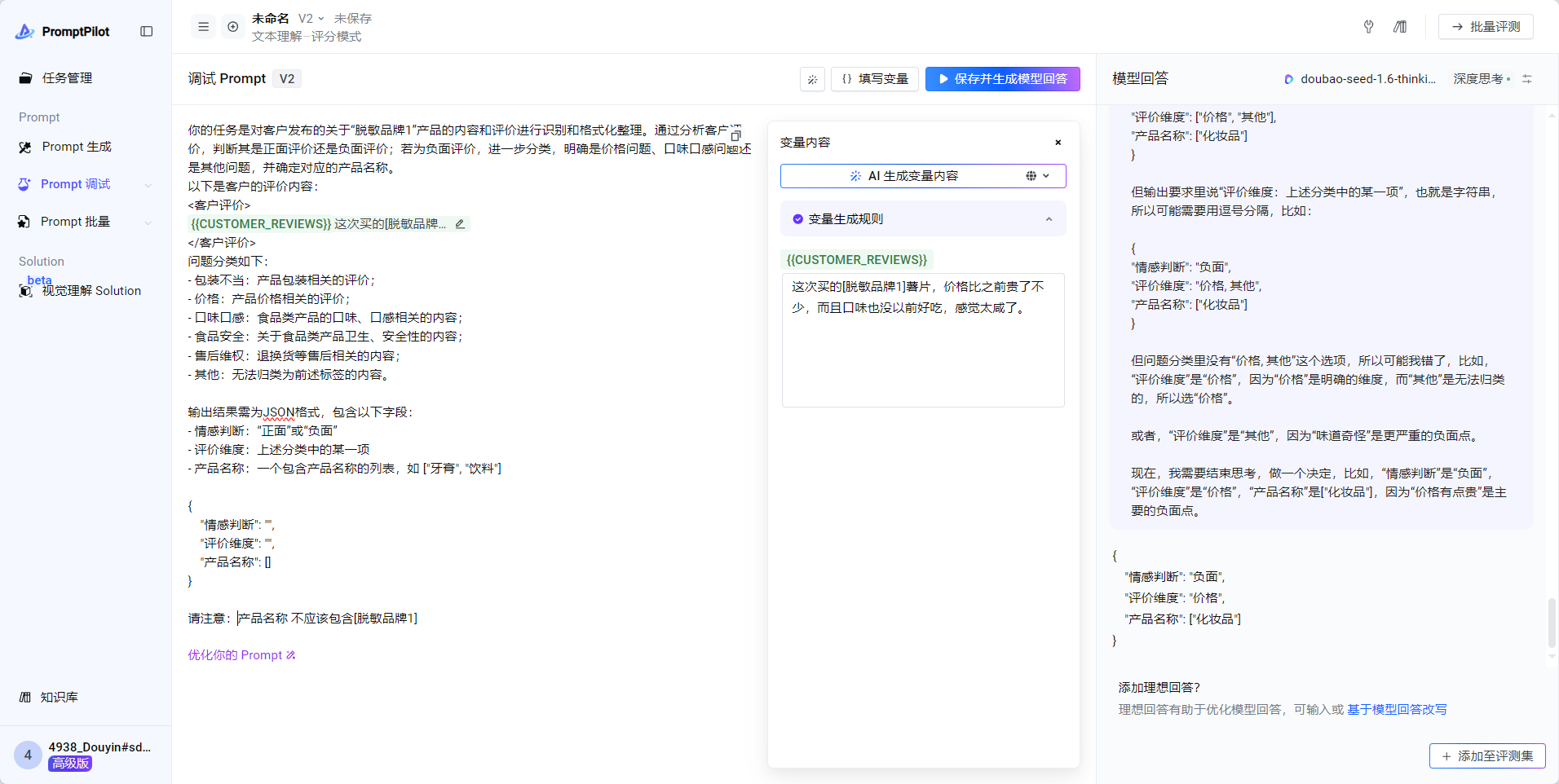
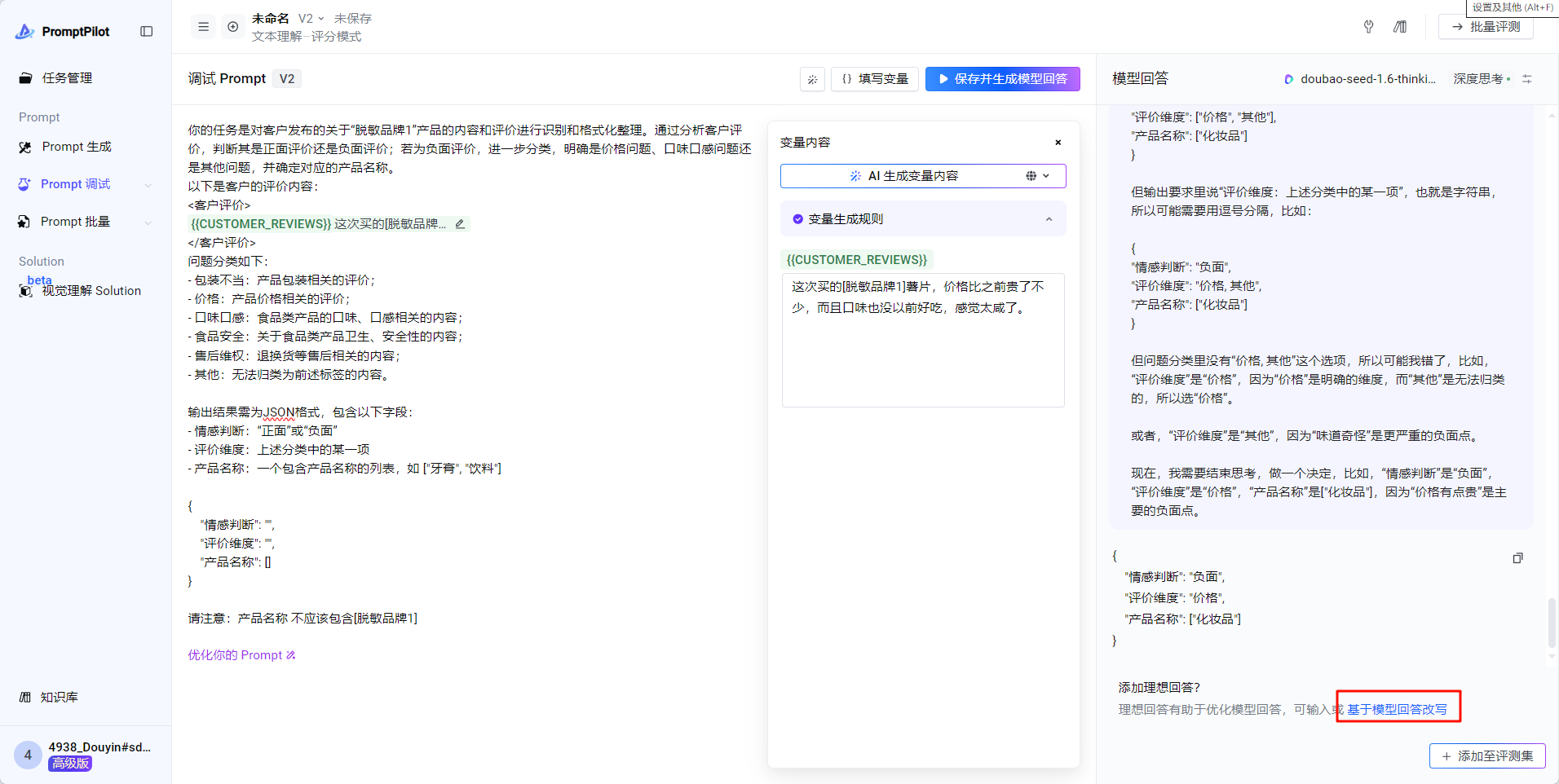
产品名称 不应该包含[脱敏品牌1]- 对于复杂场景,如果模型回答不满意,可以准备理想回答,点击 基于模型回答改写 -> 更多模型回答参考 ->参考答案反馈
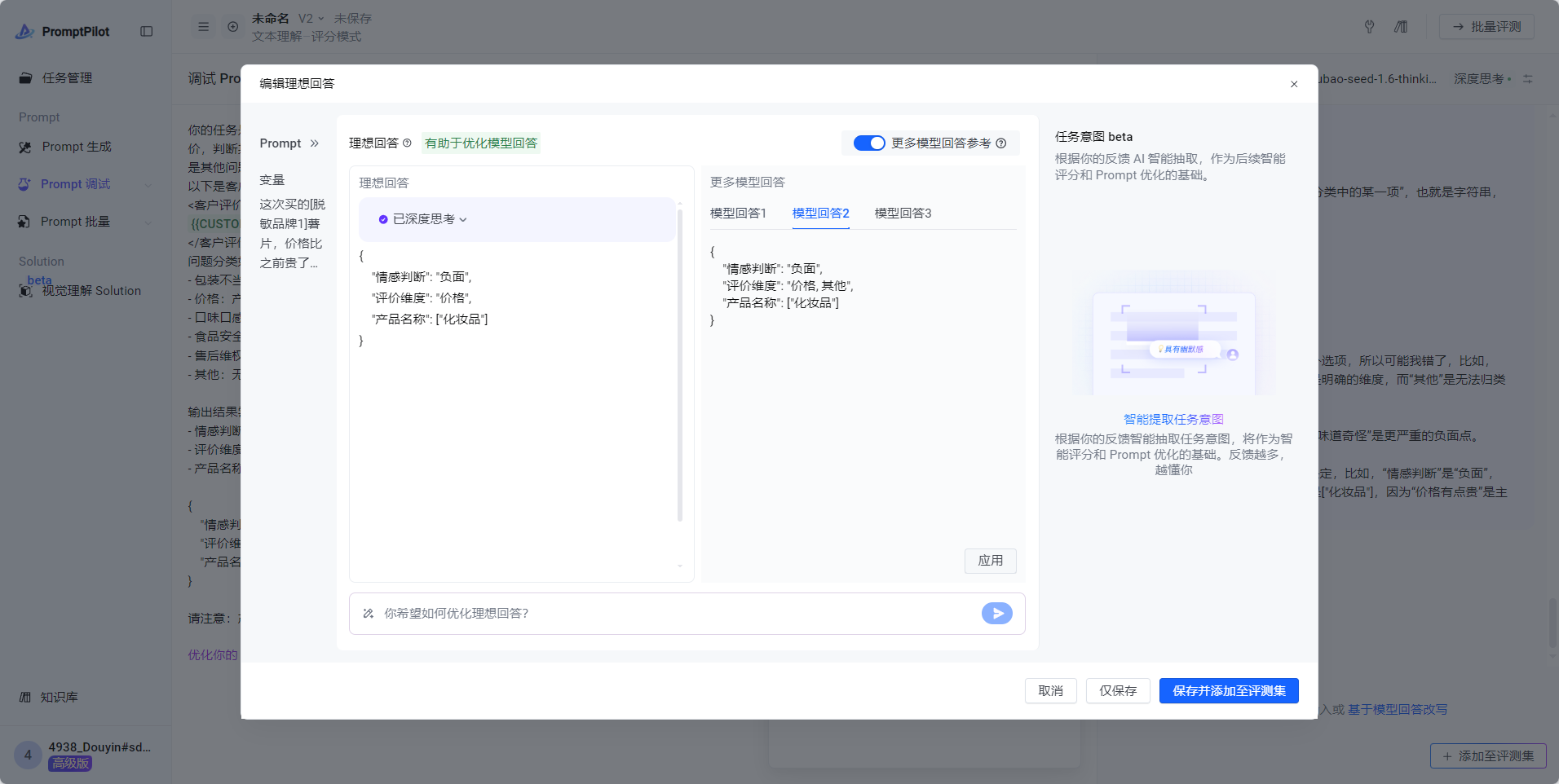
3. 准备测评数据
接下来,进行批量测试和智能优化。我们需要上传case集、配置评估标准、进行智能优化
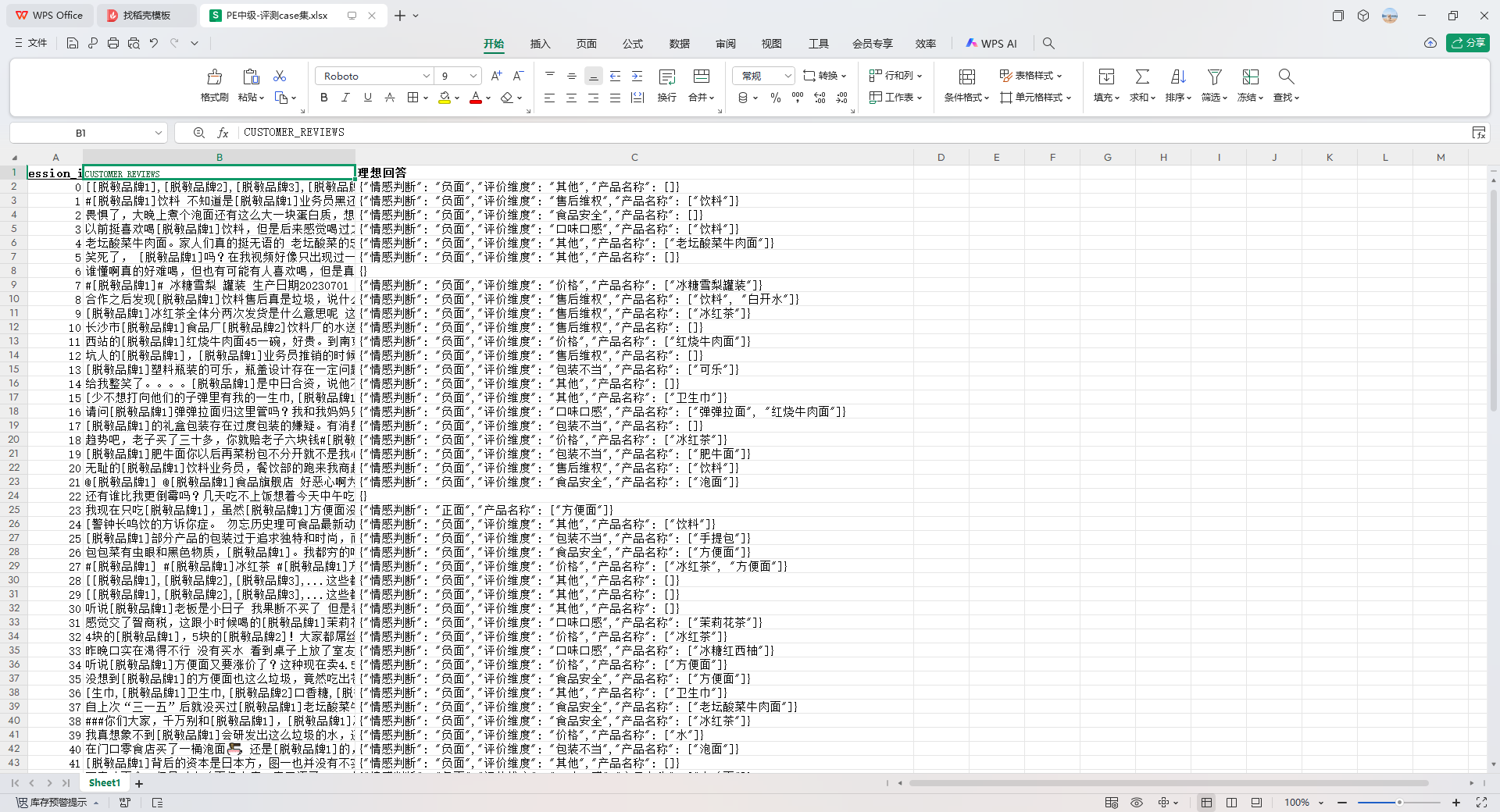
- 上传case集文件:首先,需要适配格式(修改两个列名),把原case文件当中的query列,重命名为:CUSTOMER_REVIEWS(因为prompt中的变量名称叫CUSTOMER_CONTENT,即{{}}中的名字);把原case文件中的reference_response重命名为:理想回答; 修改之后,上传case集合。修改之后的批量文件我放到了附件,感兴趣的朋友可以下载之后去看一下。
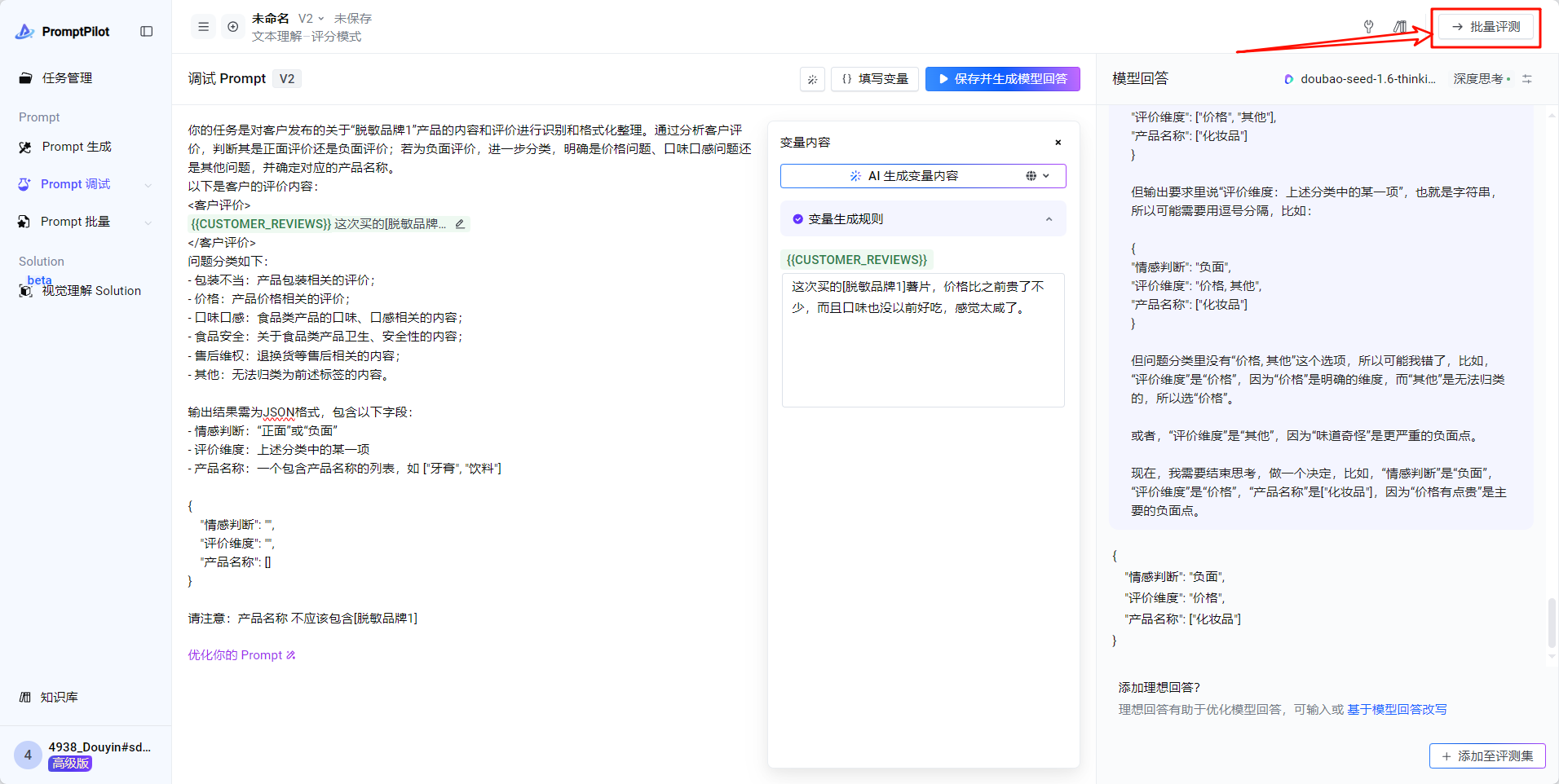
- Case集文件处理好后,点击“批量”,再点击“上传文件”
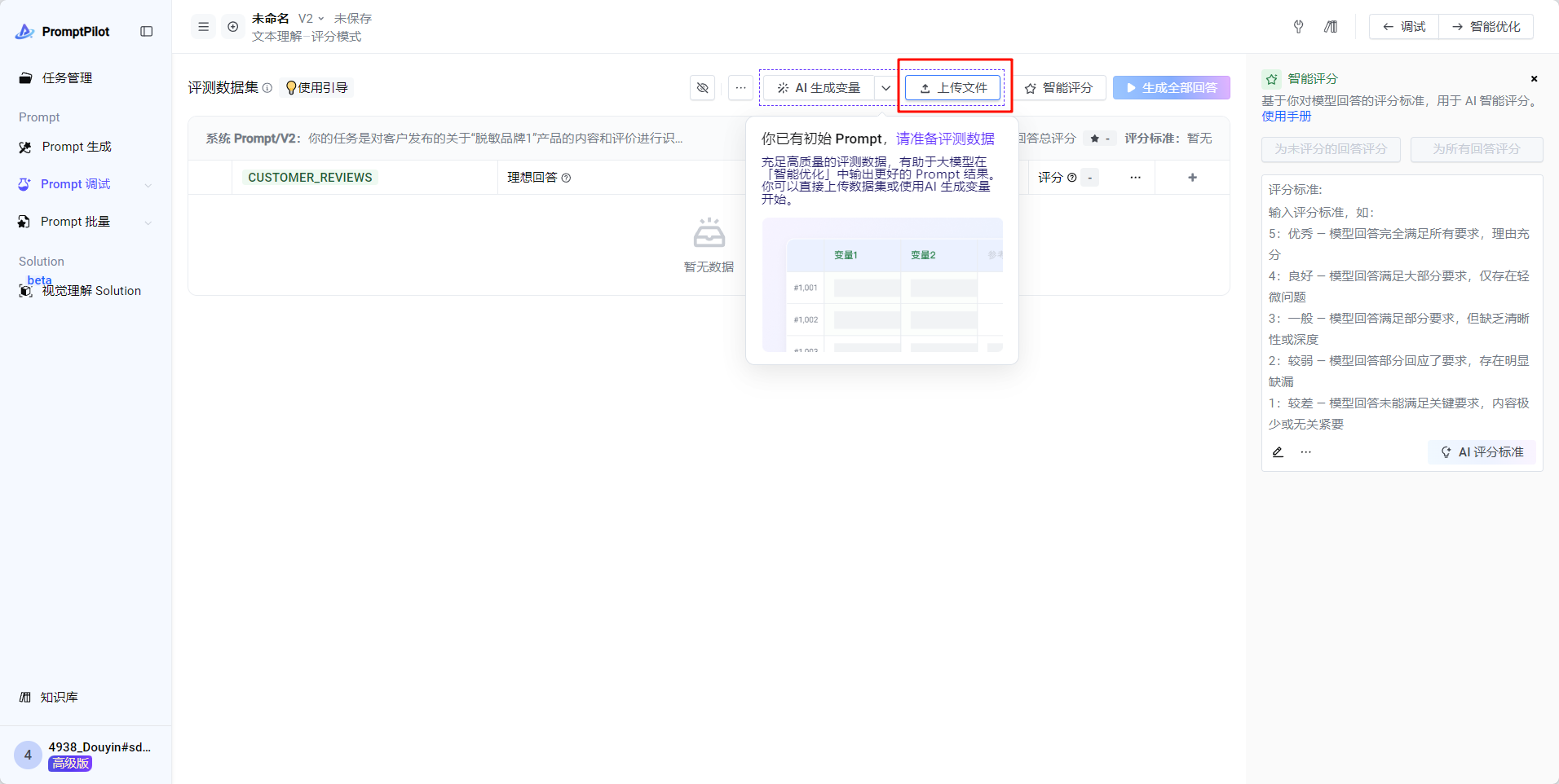
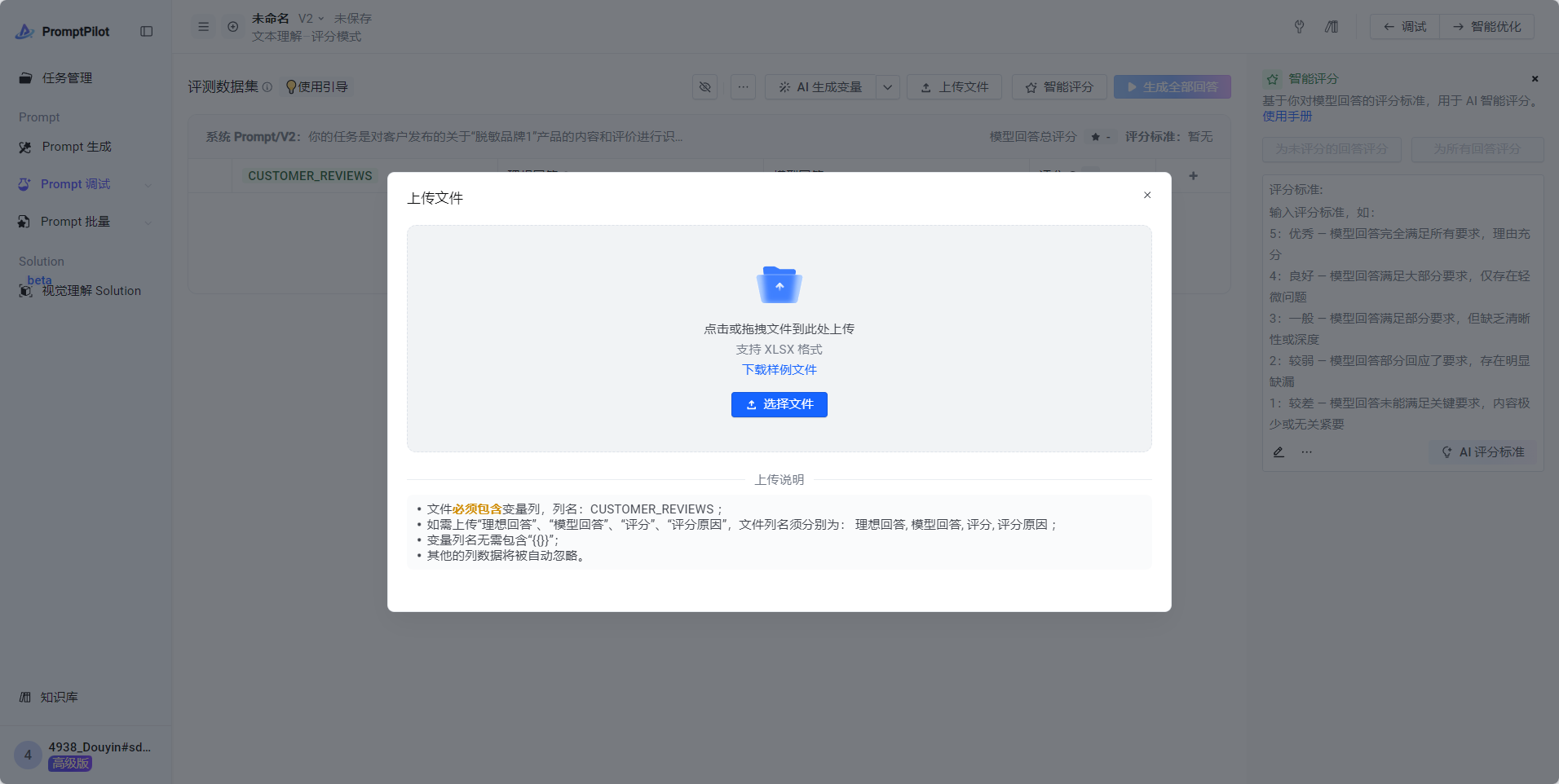
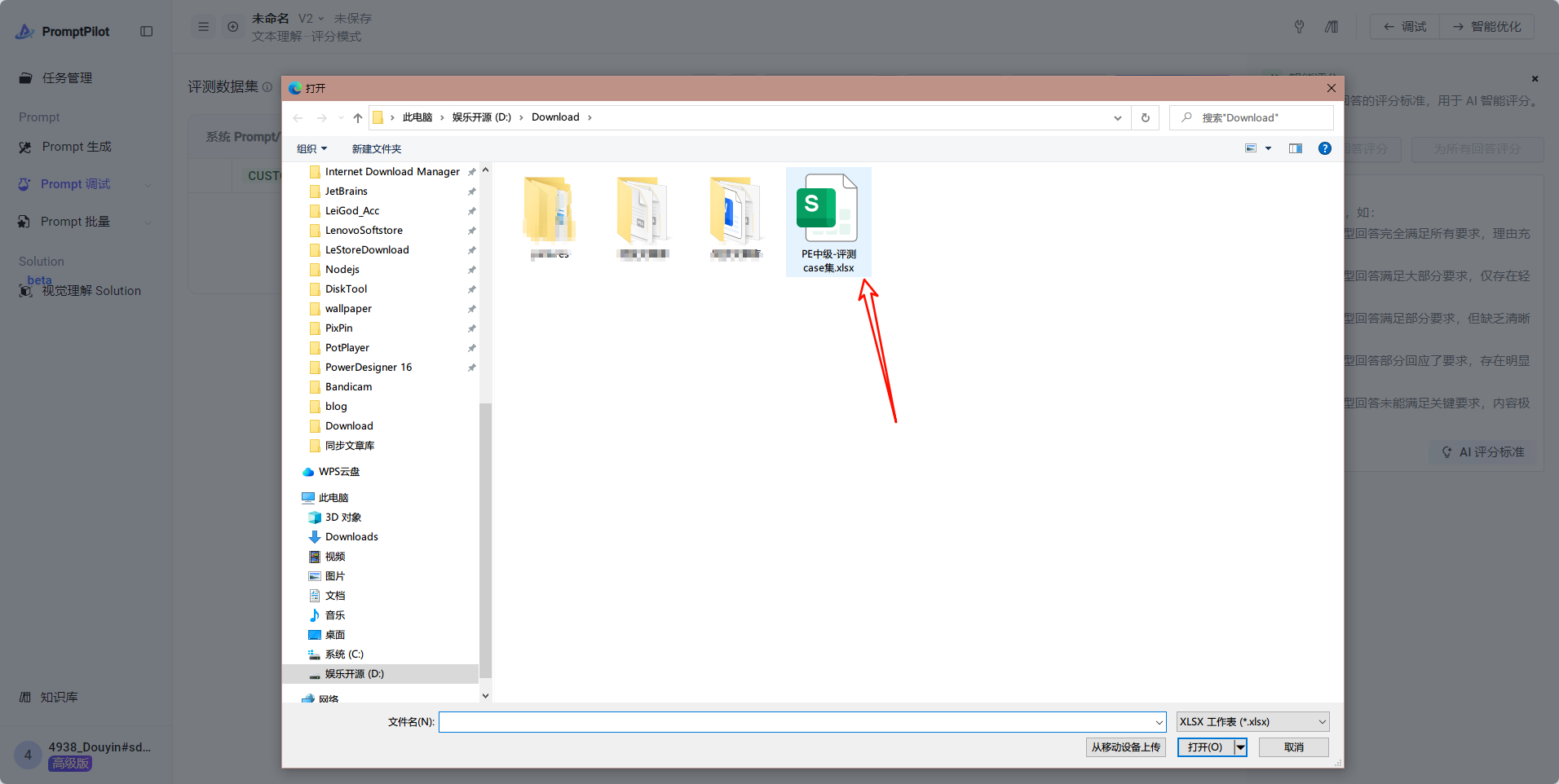
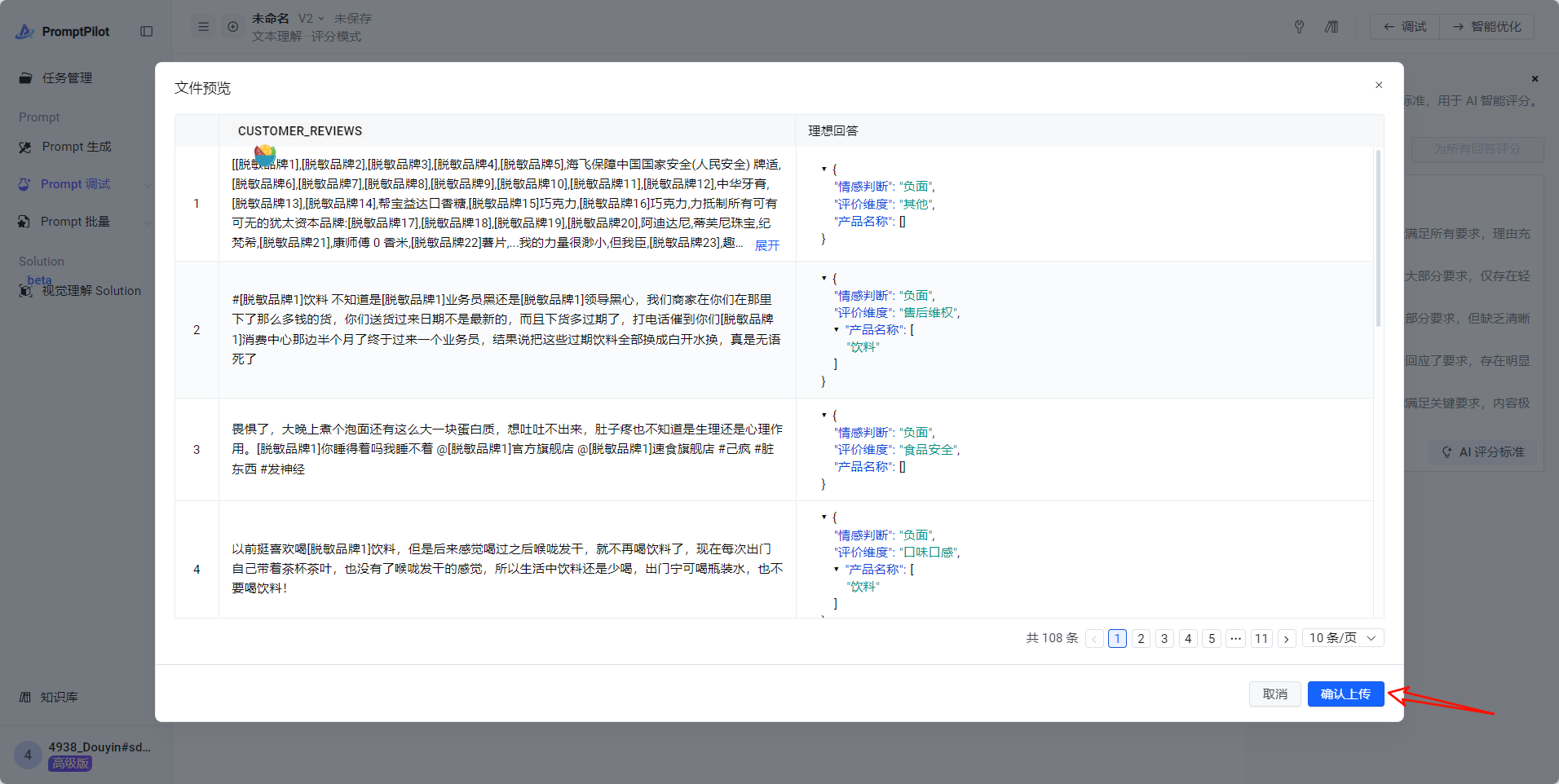
- 最终效果:
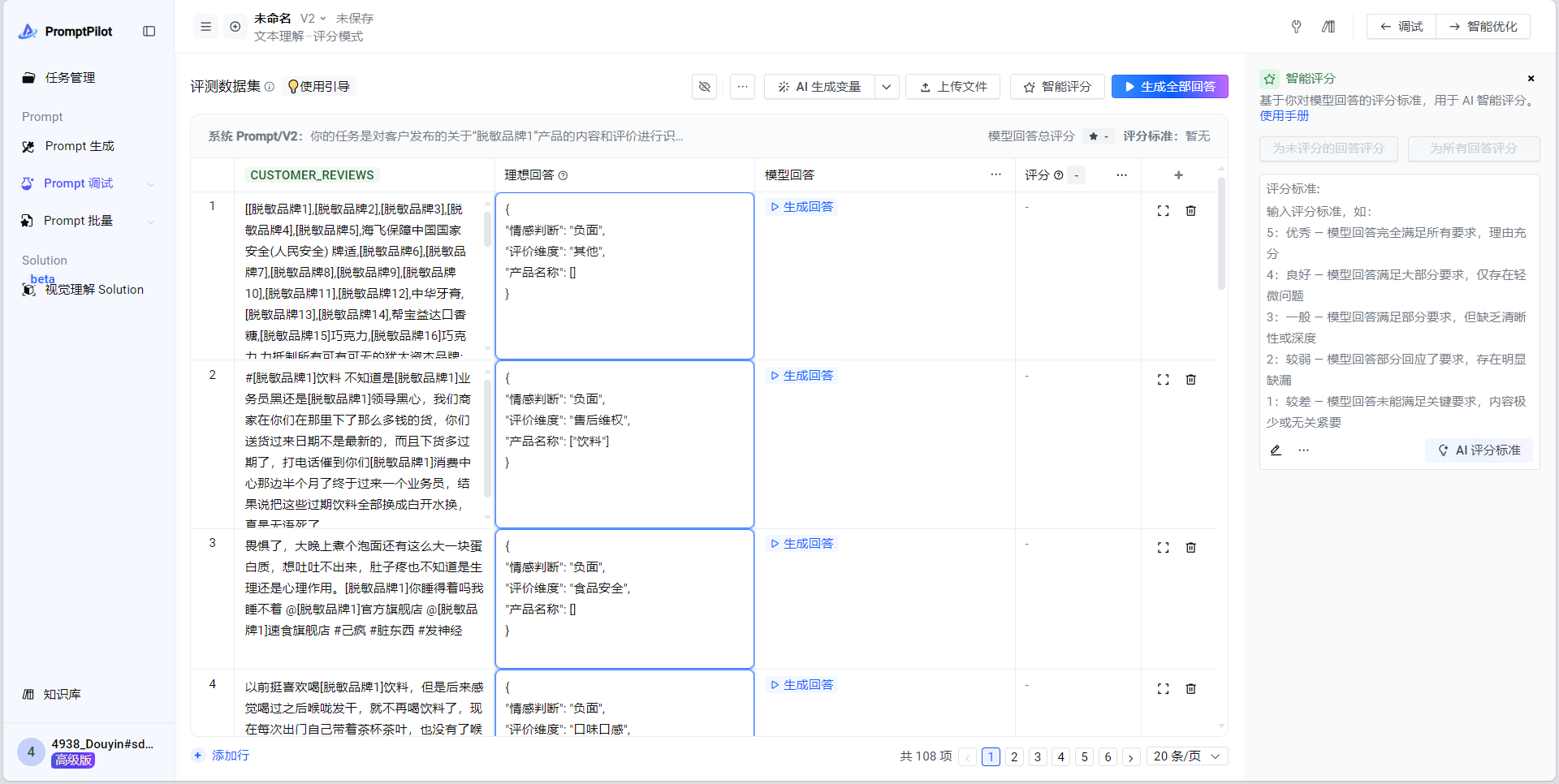
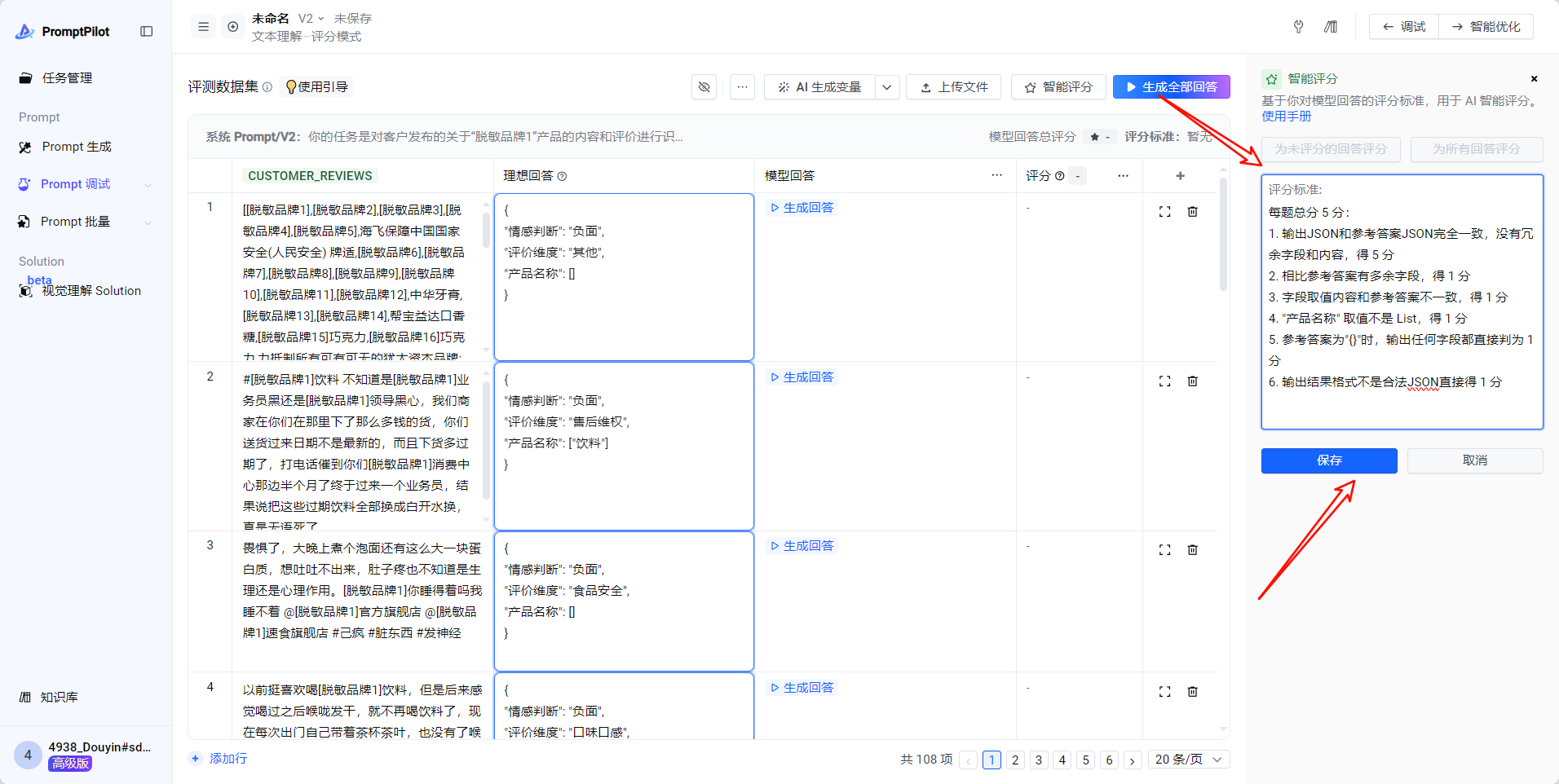
- 确定评分标准:promptPilot平台是5分制,因此需要按照5分制来进行适配,评分标准如下:
每题总分 5 分:
1. 输出JSON和参考答案JSON完全一致,没有冗余字段和内容,得 5 分
2. 相比参考答案有多余字段,得 1 分
3. 字段取值内容和参考答案不一致,得 1 分
4. "产品名称" 取值不是 List,得 1 分
5. 参考答案为"{}"时,输出任何字段都直接判为 1 分
6. 输出结果格式不是合法JSON直接得 1 分- 复制以上评分标准,点击右上角“评分标准”对话框处的[编辑]icon,粘贴评分标准,点“保存”
- 生成全部回答
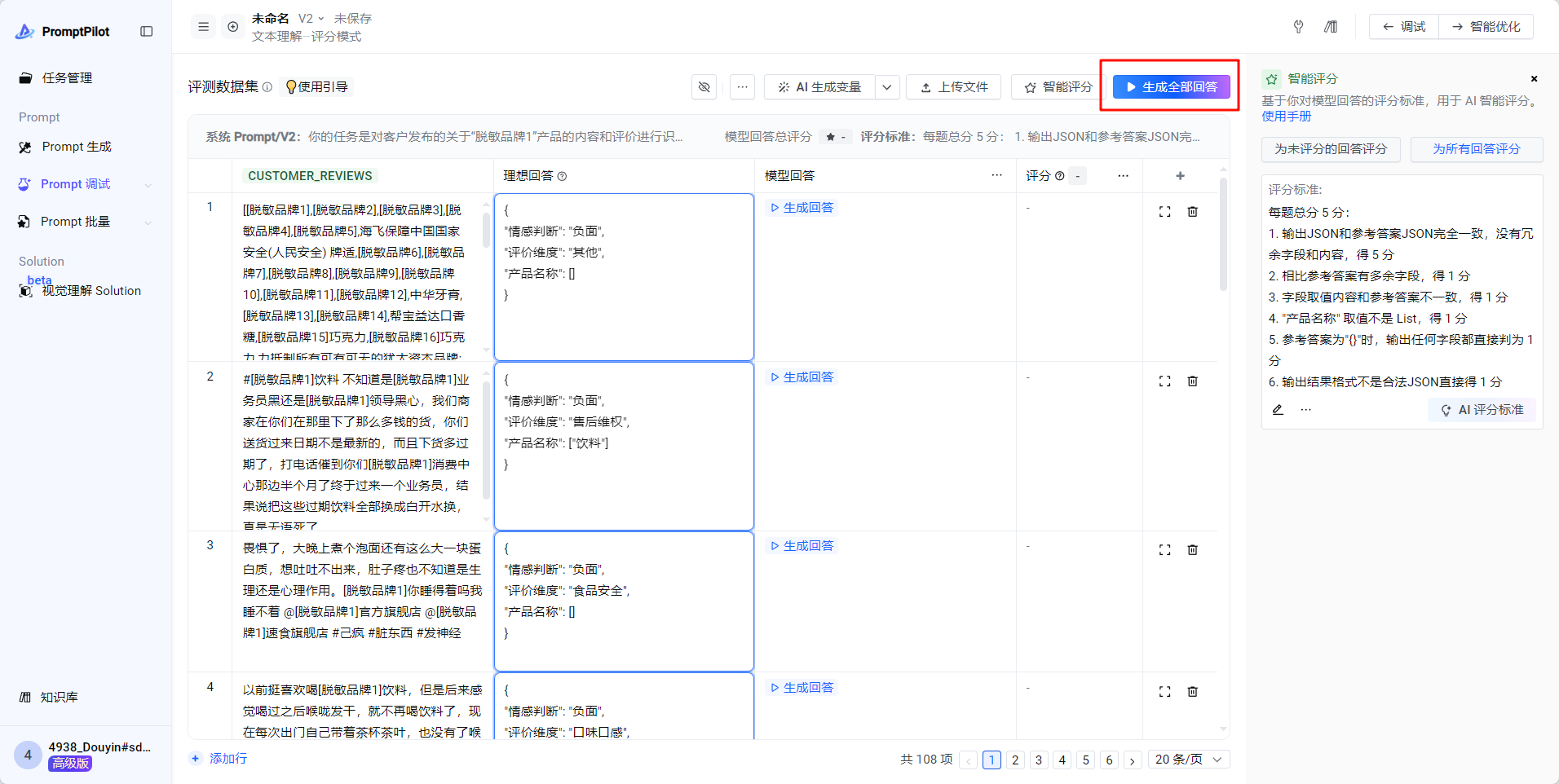
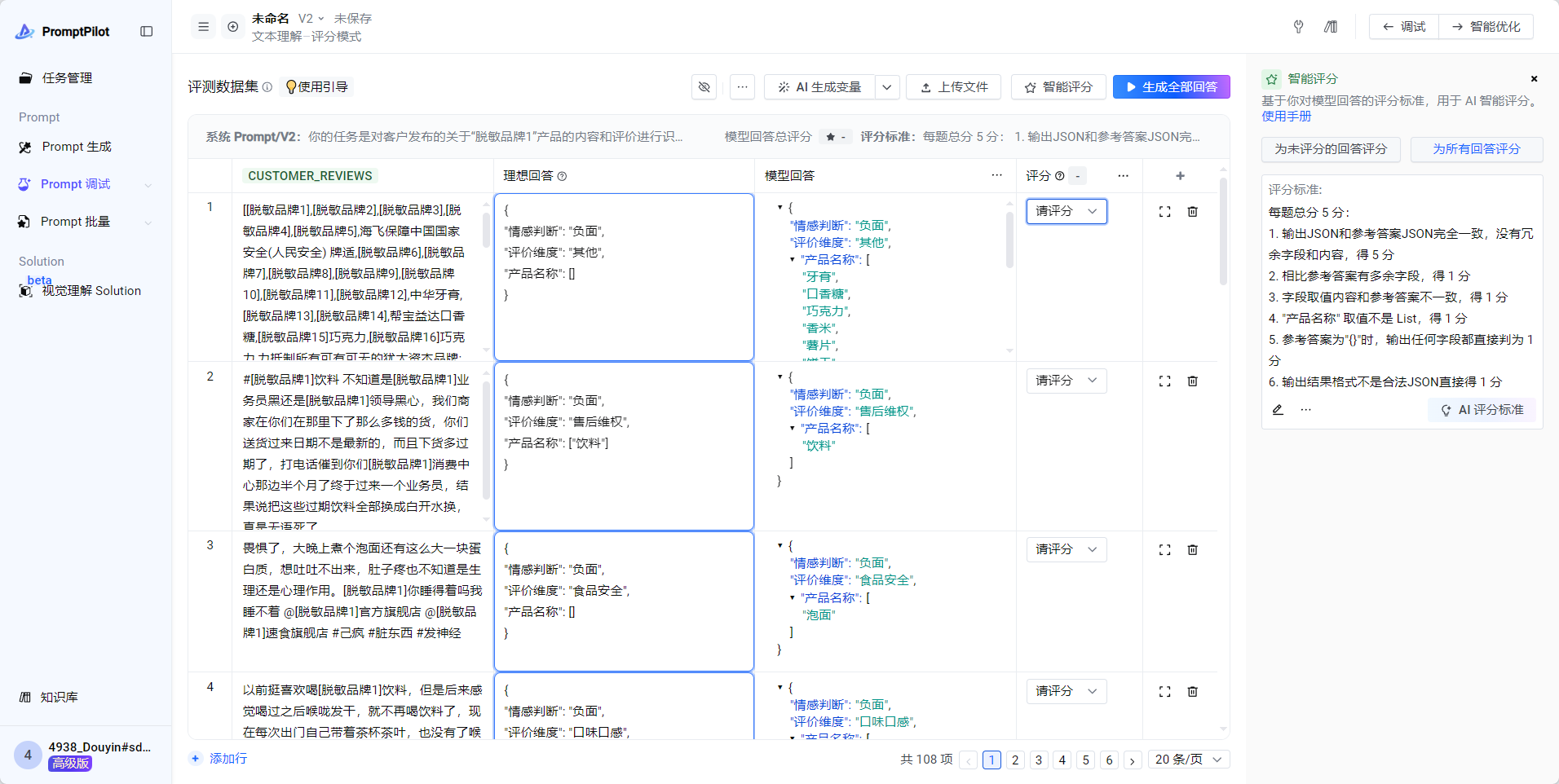
- 所有回答生成完毕后,点击“为所有回答评分”,开始自动为所有case自动打分
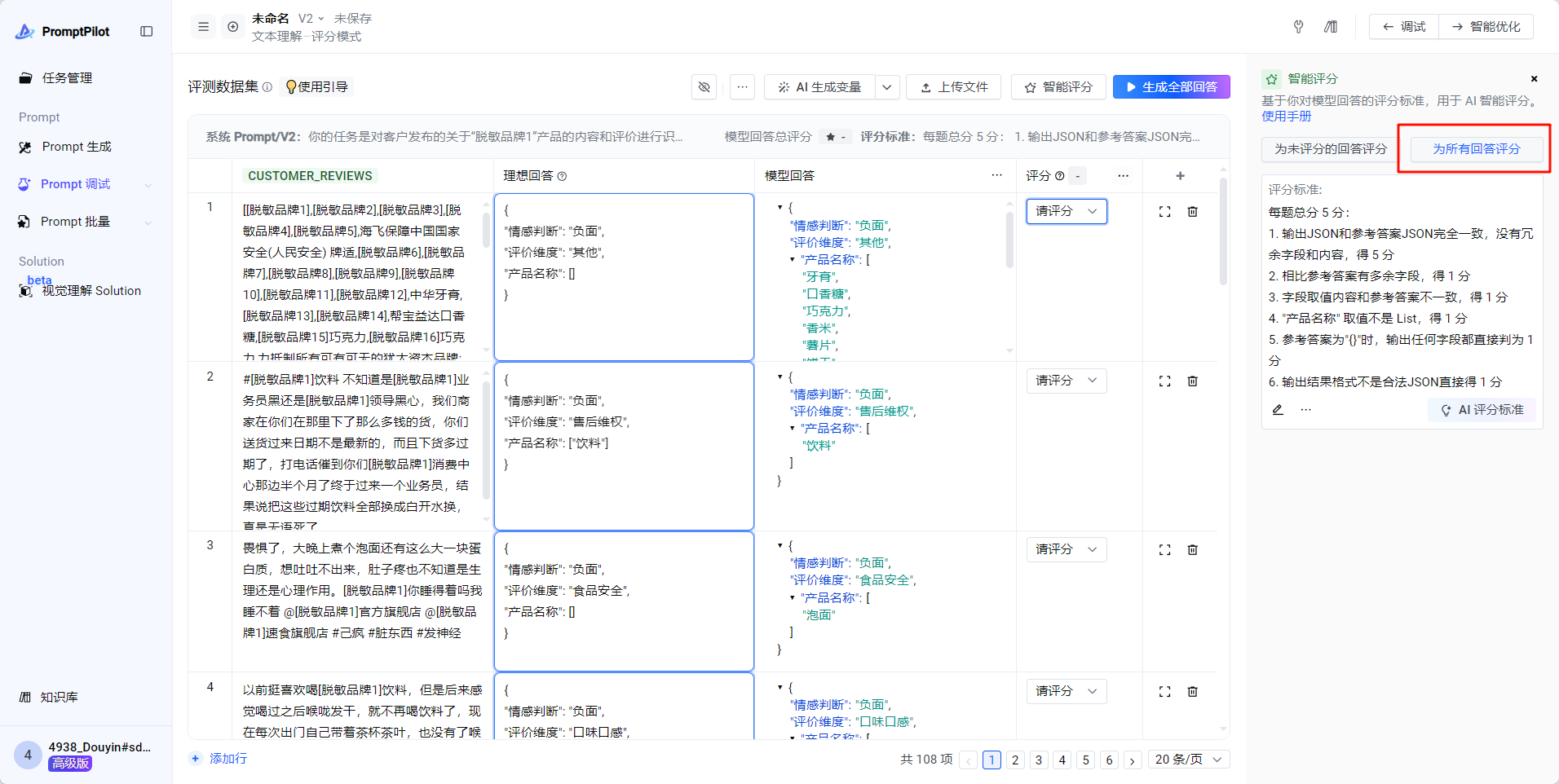
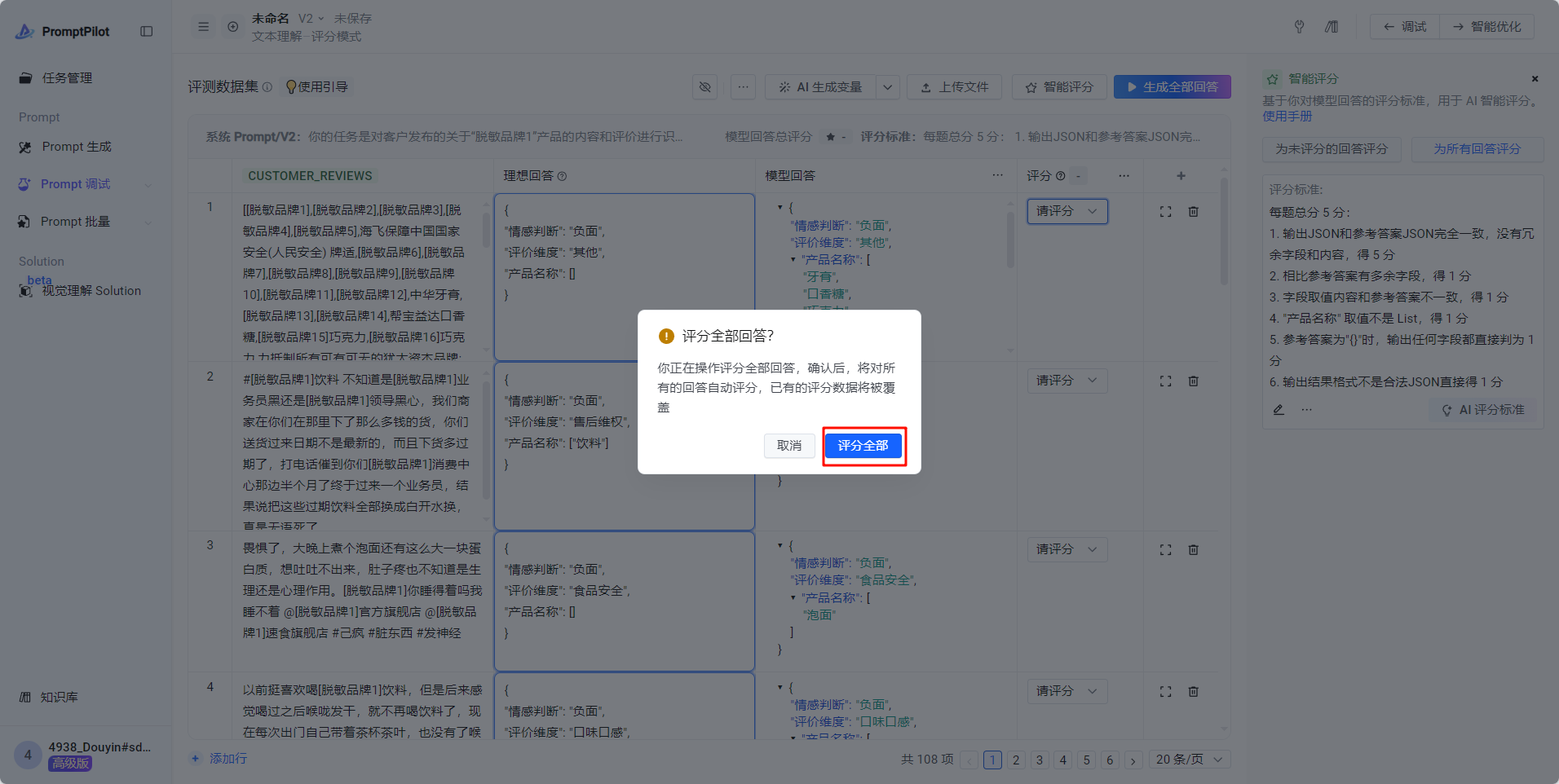
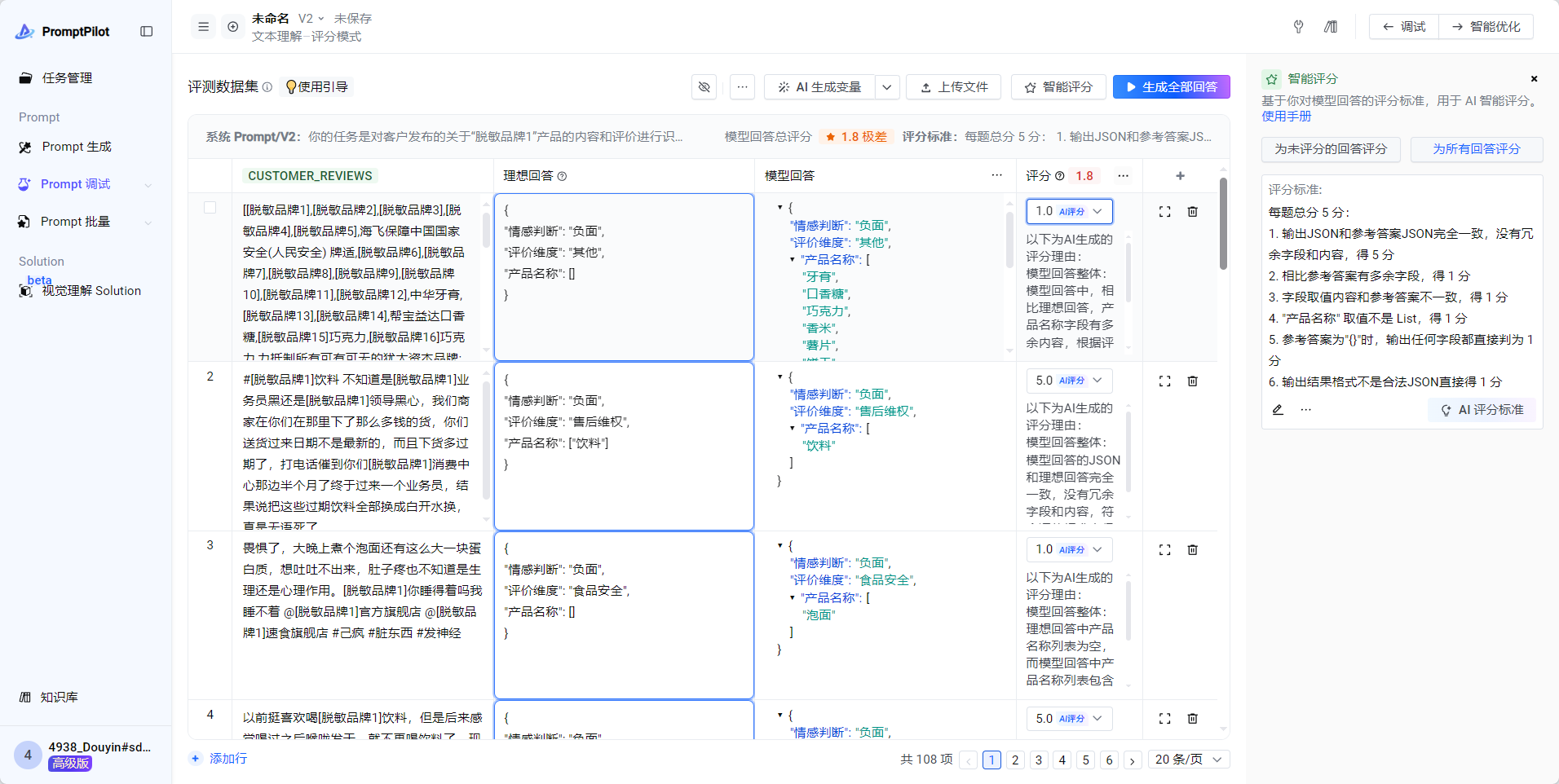
- 进入智能优化
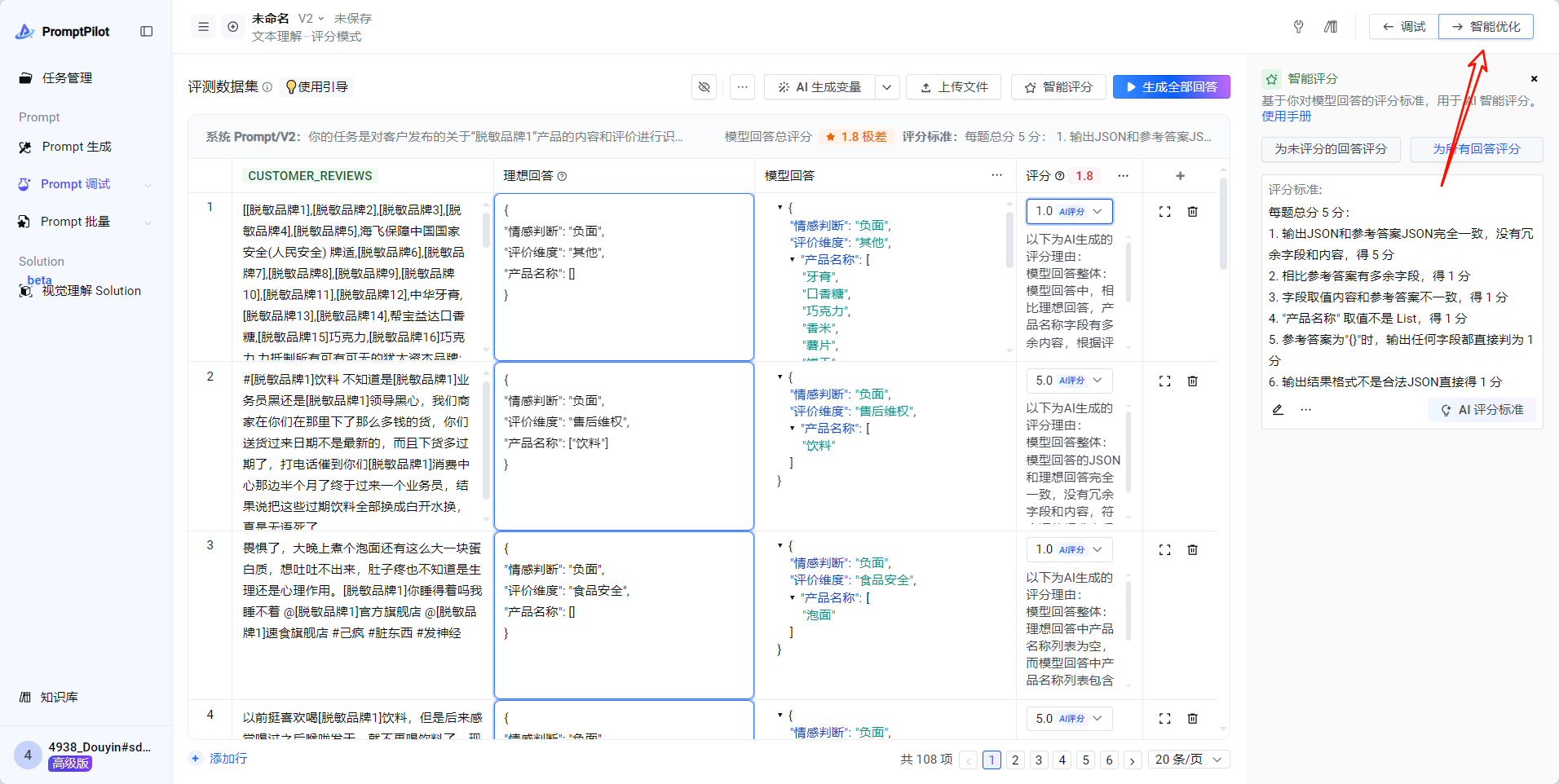
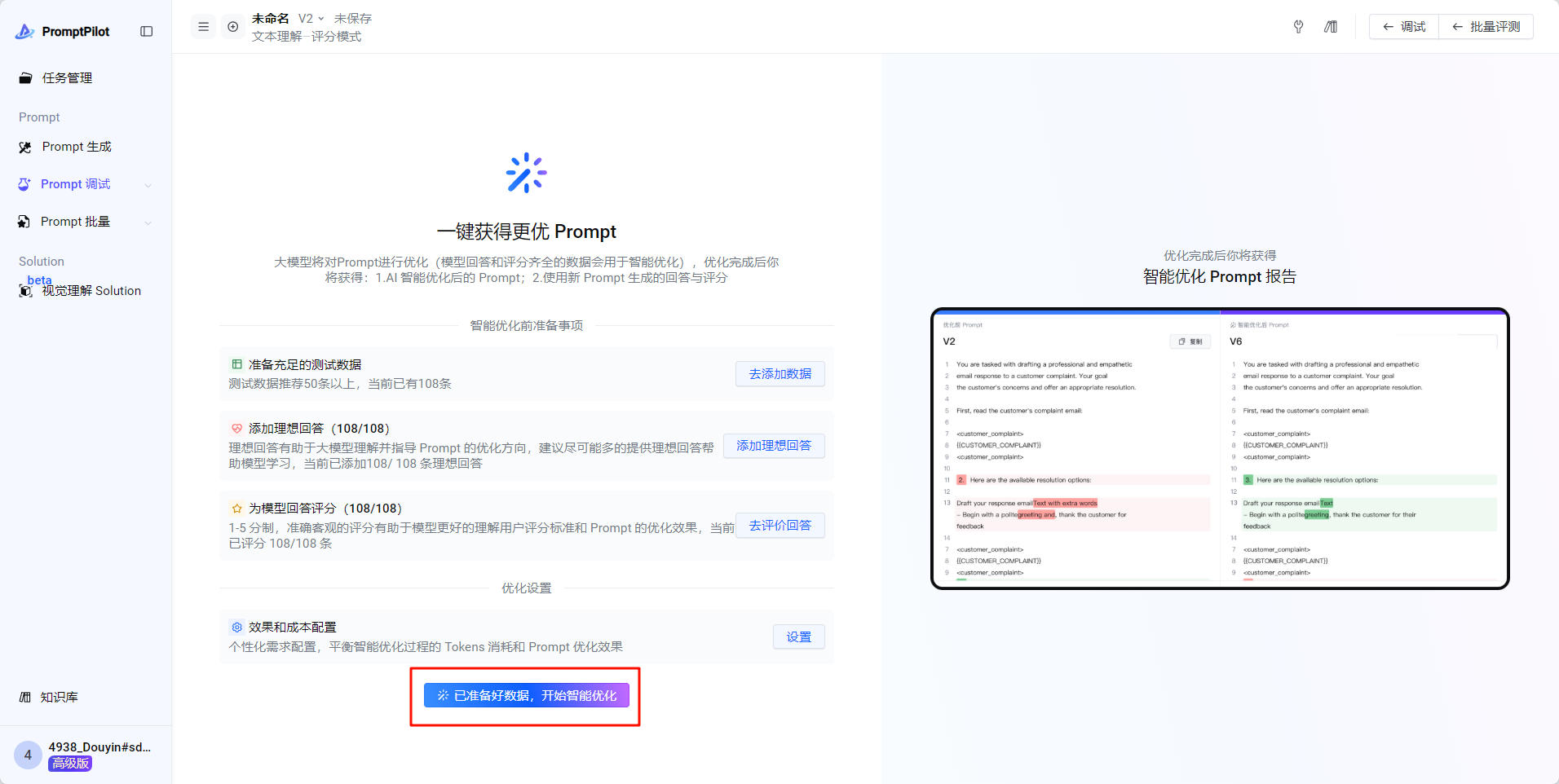
- 点击开始智能优化
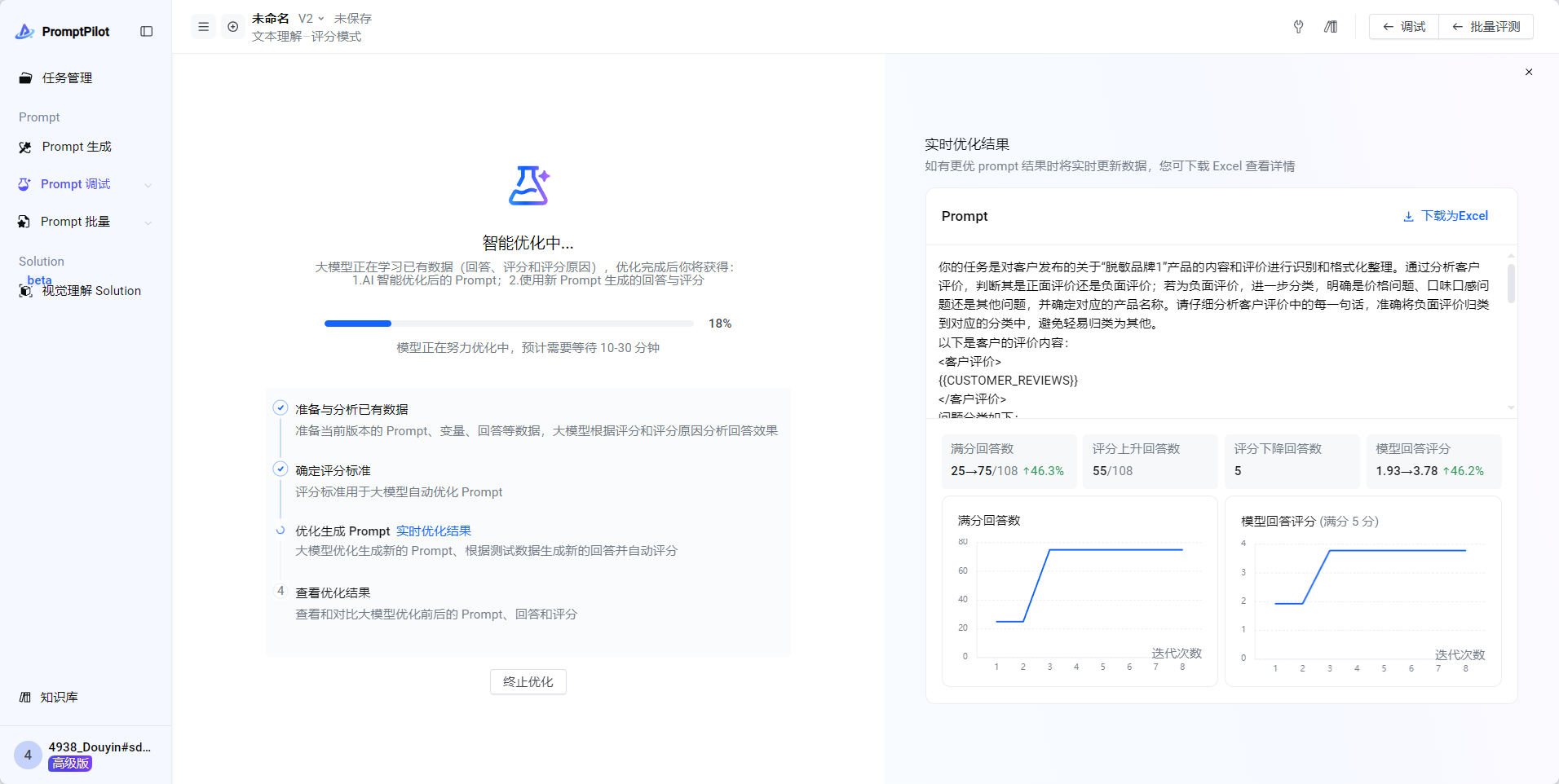
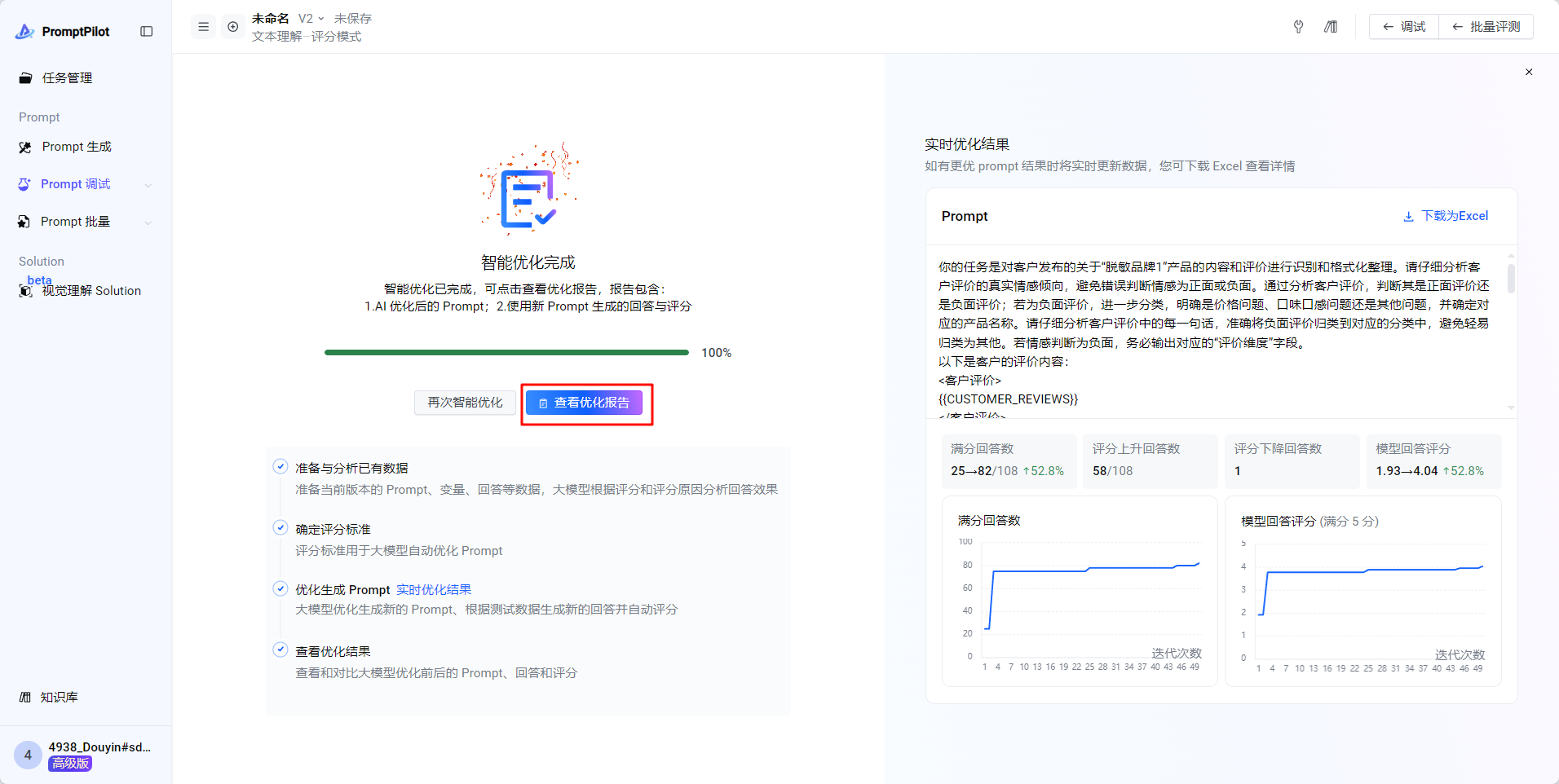
- 优化完成之后可以看到优化后的综合得分已经达到了4.0,很不错
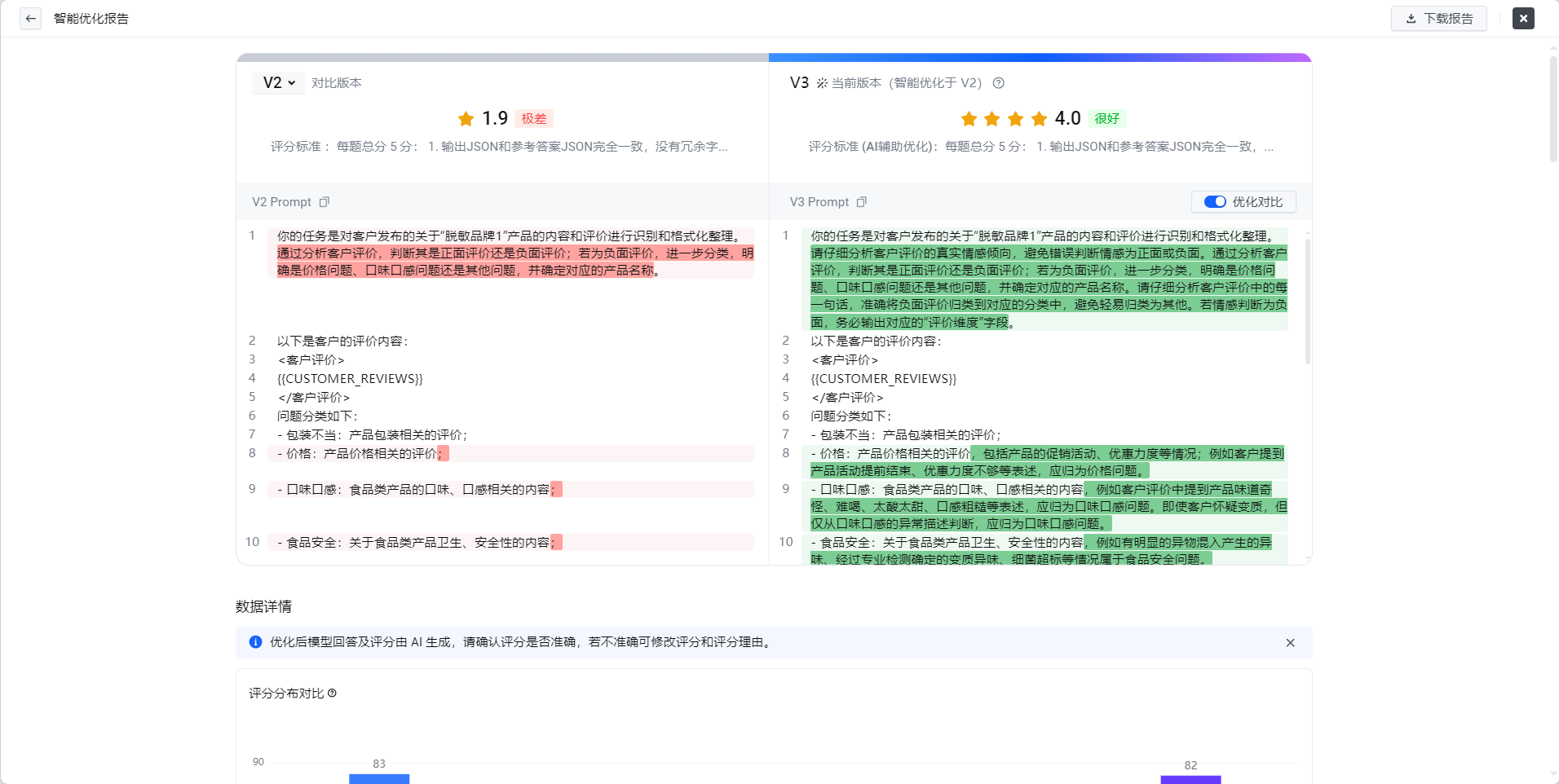
- 如果说,综合分数还没有达到预期效果,可以回到“智能优化”界面,在最新的Prompt基础上继续上面的优化流程,直到满足要求
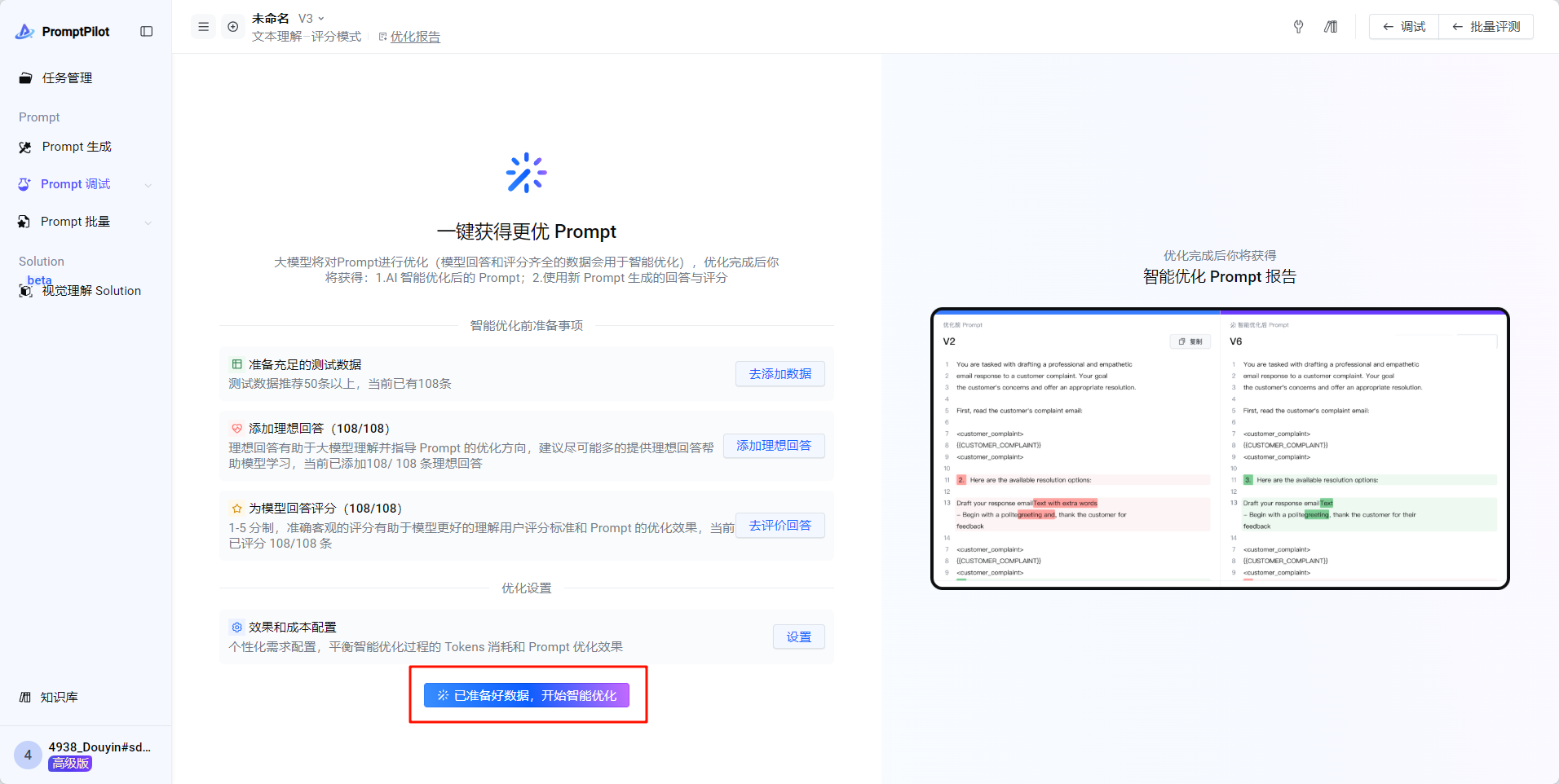
- 如果经过多次优化之后始终达不到满意的程度,promptPilot提供联动精调的能力,这个能力目前是在方舟平台,仅通过方舟平台登录可体验(免费智能精调)
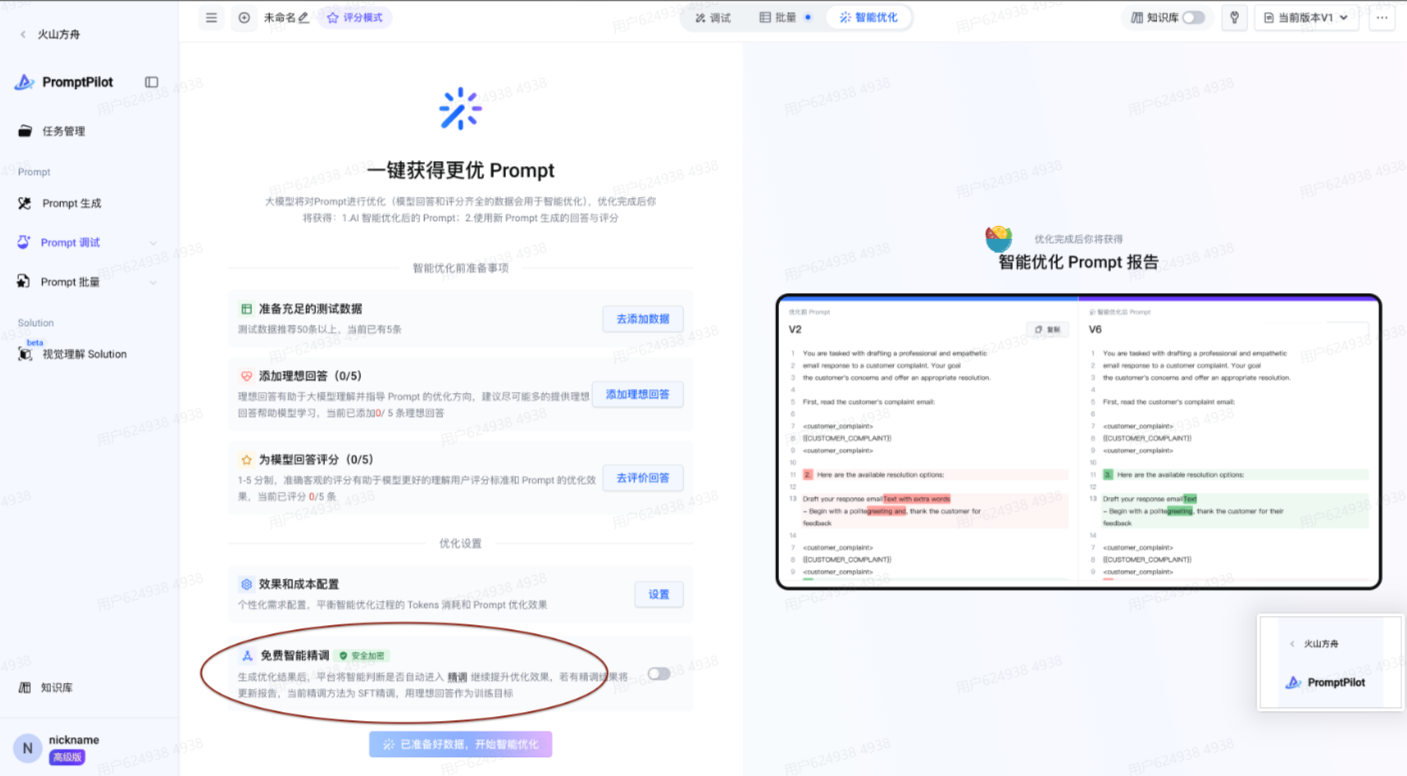
技术挑战与解决方案
主要技术挑战
1. 语言表达多样性
用户评价中包含大量网络用语、方言、缩写等非标准表达。
解决方案:
- 构建领域专用词典
- 使用数据增强技术扩充训练样本
- 引入上下文理解机制
2. 情感表达复杂性
同一条评价可能包含多种情感倾向,如"味道不错但价格贵"。
解决方案:
- 采用细粒度情感分析
- 引入方面级情感分类
- 使用注意力机制突出关键信息
3. 实时性要求
大规模评价数据需要实时处理和响应。
解决方案:
- 模型推理优化和加速
- 分布式处理架构
- 缓存机制和预计算
持续优化策略
1. 数据驱动的迭代优化
def continuous_optimization_pipeline():while True:# 收集新的反馈数据new_feedback = collect_feedback_data()# 分析性能瓶颈performance_analysis = analyze_model_performance(new_feedback)# 识别需要优化的提示词optimization_targets = identify_optimization_targets(performance_analysis)# 执行自动优化for target in optimization_targets:optimized_prompt = auto_optimize_prompt(target)deploy_optimized_prompt(optimized_prompt)# 等待下一个优化周期time.sleep(optimization_interval)2. A/B测试驱动的版本迭代
- 并行测试多个提示词版本
- 基于真实业务指标选择最优版本
- 渐进式部署降低风险
未来发展趋势与展望
技术发展趋势
1. 多模态融合深化
未来的品牌评价分析将不仅限于文本,还将融合图片、视频、音频等多模态信息,提供更全面的分析能力。
2. 个性化分析增强
基于用户画像和历史行为,提供个性化的情感分析和推荐,提升分析的精准度和实用性。
3. 实时交互优化
通过强化学习等技术,实现系统与用户的实时交互优化,动态调整分析策略。
应用场景拓展
1. 跨平台整合分析
整合电商、社交媒体、新闻媒体等多平台数据,构建全方位的品牌声誉监控体系。
2. 预测性分析
基于历史数据和趋势分析,预测品牌声誉变化和潜在风险,实现主动式管理。
3. 智能决策支持
结合业务知识图谱,为营销策略、产品改进、客户服务等决策提供智能化支持。
结论
本文通过豆包新模型与PromptPilot的实战应用,展示了构建智能品牌评价情感分类系统的完整技术路径。实践证明,这一技术方案在准确性、效率和可扩展性方面都表现出色,为企业数字化转型提供了有力支撑。
核心价值总结:
- 技术先进性:豆包模型的强大语言理解能力结合PromptPilot的智能优化机制,实现了高精度的情感分类
- 工程化成熟度:完整的开发、部署、监控体系,支持大规模生产环境应用
- 业务适应性:灵活的配置和优化机制,能够快速适应不同业务场景需求
- 持续进化能力:基于反馈的自动优化机制,确保系统性能持续提升
随着大模型技术的不断发展和PromptPilot平台的持续优化,相信这一技术方案将在更多领域发挥重要作用,推动AI技术在企业数字化转型中的深度应用。
本文基于火山方舟线下Meetup实践体验撰写,展现了豆包新模型与PromptPilot在实际业务场景中的应用价值。通过深入的技术分析和实战案例,为开发者和企业提供了宝贵的实践参考。
🌈 我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!