Spring Boot + ShardingSphere 分库分表实战
🚀Spring Boot + ShardingSphere 实战:分库分表,性能暴增的终极指南!
✅ 适用场景:千万级大表、高并发、读写分离场景
✅ 核心框架:Spring Boot 3.x + ShardingSphere-JDBC 5.4.1
✅ 数据库:MySQL 8.x(主从结构)
✅ 特色亮点:覆盖垂直/水平分库、分表、自定义分片、公共表、广播表、Hint 强制路由
分库分表 vs 读写分离 vs 主从配置与数据库高可用架构区别
📚 目录
- 🌟 为什么选择 ShardingSphere?
- 📐 系统整体架构图
- 🧰 技术选型与版本说明
- ⚙️ 核心配置详解
- 🚦 常用查询效果演示
- 🚧 常见问题与优化建议
- 📎 参考资料与源码下载
🌟 为什么选择 ShardingSphere?
ShardingSphere 是 Apache 开源的数据库中间件生态系统,支持 JDBC 层嵌入和独立代理部署,拥有强大的分库分表、读写分离、数据加密、弹性扩容、分布式事务等能力。相比传统中间件,它更灵活、社区更活跃,适合大多数 Spring Boot 应用快速集成。
🔍 什么是 ShardingSphere?
ShardingSphere 是一个开源的分布式数据库中间件生态,最早由当当网开源(Sharding-JDBC),目前由 Apache 基金会孵化。
它包含 3 大组件:
| 组件 | 作用说明 |
|---|---|
| ShardingSphere-JDBC | 轻量级 Java JDBC 层分库分表工具(无需 Proxy) |
| ShardingSphere-Proxy | 基于 MySQL/PostgreSQL 协议的中间件代理层 |
| ShardingSphere-Sidecar | 面向 Kubernetes 的数据库 Mesh Sidecar |
本项目使用 ShardingSphere-JDBC,适合嵌入 Spring Boot 项目,无需额外服务。
🌟 ShardingSphere 的核心能力
| 能力项 | 说明 |
|---|---|
| ✅ 分库分表 | 支持标准、绑定表、广播表、Hint 路由等 |
| ✅ 读写分离 | 支持一主多从,负载均衡策略可配置 |
| ✅ 弹性扩容 | 数据迁移过程中支持双写、多活等策略 |
| ✅ 分布式事务 | 支持 Seata/XA/BASE 模式 |
| ✅ 数据加密 | 支持字段级加密与脱敏 |
| ✅ 容器/K8s 支持 | Proxy 和 Sidecar 支持云原生部署 |
| ✅ SQL 显示/日志跟踪 | 方便调试分片路由结果 |
🧠 为什么选它而不是其他?
| 对比项 | ShardingSphere | MyCat | Vitess/Federation |
|---|---|---|---|
| 📦 部署方式 | 代码嵌入(JDBC层)或独立服务 | 独立服务(代理层) | 代理层(复杂度较高) |
| 💡 配置方式 | YAML/Java/Registry/动态 | XML 配置复杂 | 支持 SQL 路由 |
| 🧩 特性完整度 | 高:分片+读写+事务+加密 | 分片较强,其他较弱 | 分布式强,学习成本高 |
| 🌐 社区活跃度 | 高(Apache孵化+大厂支持) | 较低(更新慢) | 中(主要在国外) |
| 💼 实际落地场景 | 电商、支付、运营平台等 | 早期用得多,现在转向替代 | 海外云厂商多 |
| 🧪 分布式事务支持 | ✅ Seata / BASE / XA | ❌ | ✅ |
📌 结论:ShardingSphere 在 兼容性、灵活性、社区支持 等方面都具备绝对优势,适合中大型项目长期维护。
🧪 哪种场景适合使用 ShardingSphere?
| 场景类型 | 是否推荐使用 | 说明 |
|---|---|---|
| 订单系统 | ✅ | 支持订单分库分表,按用户、时间分片都很灵活 |
| 用户系统 | ✅(广播表) | 用户表一般较小,可广播全库保持一致 |
| 内容系统 | ✅ | 文章/评论按ID、日期分表效果好 |
| 实时大数据 | ❌(不推荐) | 建议用 Flink + Hive/Spark |
| 跨库强事务需求 | ✅(结合 Seata) | ShardingSphere + Seata 实现分布式事务 |
| 多租户 SaaS | ✅ | 可按 tenant_id 分库分表 + 广播共享配置类 |
📌 总结一句话:
ShardingSphere 是 Java 世界中最成熟、最活跃的分库分表中间件,适合绝大多数业务场景,尤其适合 Spring Boot 用户接入。
📐 系统整体架构图
🧩 用户模块使用广播表,订单模块按 user_id 水平分库,order 表按年月分表,日志表归档存储。读写分离策略基于 SQL 类型自动路由到主库或从库。
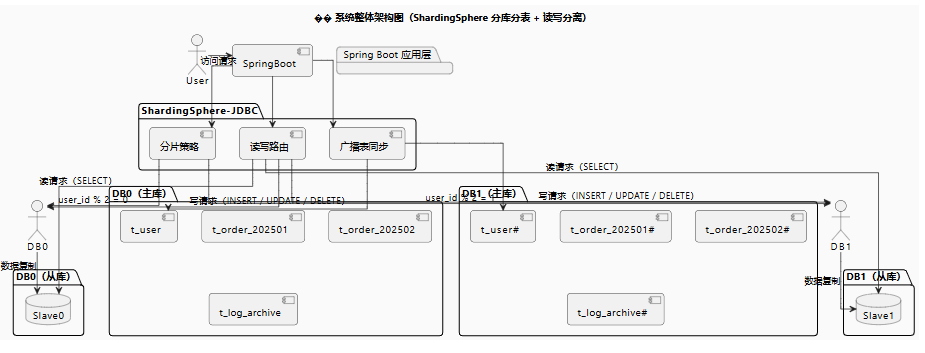
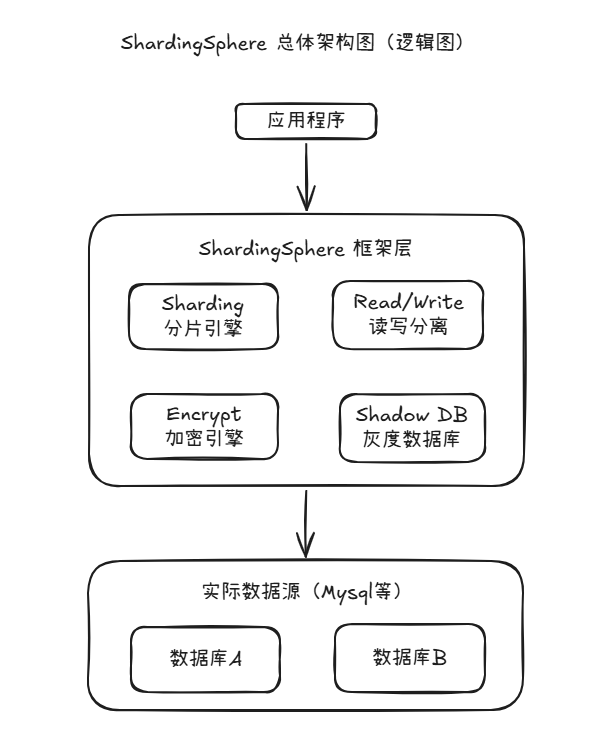
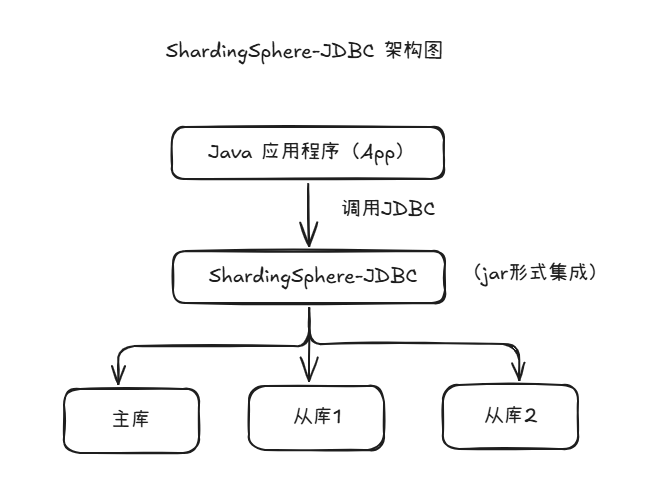
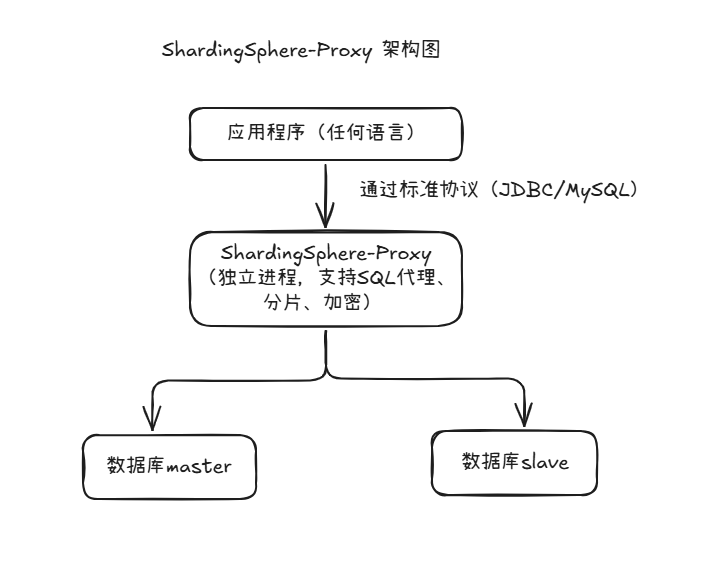
下面是一个标准的 ShardingSphere 架构图,展示其核心组件、功能模块和部署方式。架构可以分为三种模式:ShardingSphere-JDBC、ShardingSphere-Proxy、ShardingSphere-Sidecar(计划中)。这里我们重点展示 ShardingSphere-JDBC 和 ShardingSphere-Proxy 的部署结构:
✅ 一、ShardingSphere 总体架构图(逻辑图)
✅ 二、ShardingSphere 三种部署模式对比图
| 模式 | 架构位置 | 特点说明 |
|---|---|---|
| ShardingSphere-JDBC | Java 应用内部 | 嵌入式、轻量级,支持事务、本地运行、性能高。适合 Java 项目 |
| ShardingSphere-Proxy | 数据库代理层 | 类似 MySQL 中间件,跨语言支持(Python、Go等),统一访问 |
| ShardingSphere-Sidecar(未来) | Service Mesh(Istio)边车模式 | 云原生、K8s友好,服务间透明代理 |
✅ 三、ShardingSphere-JDBC 架构图
✅ 四、ShardingSphere-Proxy 架构图
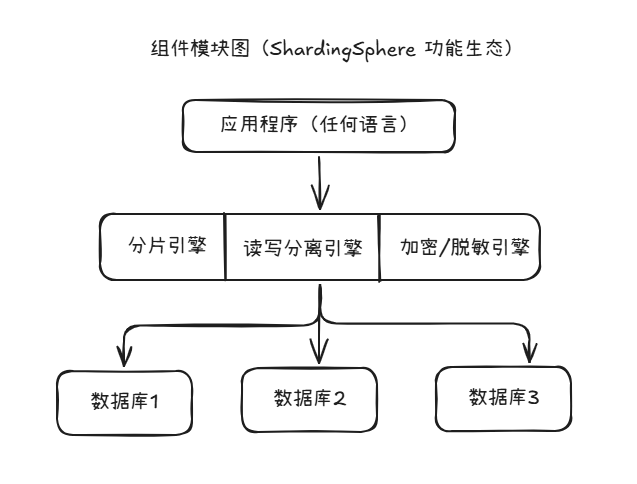
✅ 五、组件模块图(ShardingSphere 功能生态)
🧰 技术选型与版本说明
| 技术栈 | 说明 |
|---|---|
| Spring Boot | 3.1.5 |
| ShardingSphere-JDBC | 5.2.1 |
| MyBatis-Plus | 3.5.11 |
| MySQL | 8.0.x,一主两从 |
| dynamic-datasource | 与 ShardingSphere 不兼容,已弃用 |
| Lombok / HikariCP | 简化开发 / 高性能连接池 |
⚙️ 核心配置详解(application.yml)
📌 一、项目整体结构预览
sharding-demo/
├── src/
│ ├── main/
│ │ ├── java/com/example/shardingdemo/
│ │ │ ├── controller/
│ │ │ ├── entity/
│ │ │ ├── mapper/
│ │ │ ├── ShardingDemoApplication.java
│ └── resources/
│ ├── application.yml
├── pom.xml
🧱 二、核心依赖配置(pom.xml)
<dependencies><!-- Spring Boot Starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.16</version> <!-- 使用最新版本 --></dependency><!-- MyBatis Plus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>3.5.11</version></dependency><!-- ShardingSphere-JDBC --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.2.1</version></dependency><!-- MySQL Connector --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId></dependency><!-- Lombok & Fastjson 可选 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>
🧬 三、数据结构设计(核心表)
1️⃣ 用户表(广播表)
CREATE TABLE t_user (id BIGINT PRIMARY KEY,username VARCHAR(50),phone VARCHAR(20)
);
2️⃣ 订单主表(分库 + 分表)
CREATE TABLE t_order_0 (id BIGINT PRIMARY KEY,user_id BIGINT,order_no VARCHAR(64),amount DECIMAL(10,2),create_time DATETIME
);
CREATE TABLE t_order_1 (id BIGINT PRIMARY KEY,user_id BIGINT,order_no VARCHAR(64),amount DECIMAL(10,2),create_time DATETIME
);
CREATE TABLE t_order_2 (id BIGINT PRIMARY KEY,user_id BIGINT,order_no VARCHAR(64),amount DECIMAL(10,2),create_time DATETIME
);
⚙️ 四、application.yml 配置(核心)
spring:shardingsphere:datasource:names: ds0, ds1, ds2ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://mysql-master:3307/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: rootds1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://mysql-slave1:3308/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: rootds2:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://mysql-slave2:3309/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: rootrules:sharding:tables:t_order:actual-data-nodes: ds$->{0..2}.t_order_$->{0..2}table-strategy:standard:sharding-column: user_idsharding-algorithm-name: order-table-inline # 使用 sharding-algorithm-namedatabase-strategy:standard:sharding-column: user_idsharding-algorithm-name: order-db-inlinebroadcast-tables:- t_userdefault-database-strategy:none:default-table-strategy:none:sharding-algorithms:order-db-inline:type: INLINEprops:algorithm-expression: ds${user_id % 3}order-table-inline:type: INLINEprops:algorithm-expression: t_order_${user_id % 3}props:sql-show: true
ShardingSphere-JDBC 配置详解
1. 数据源配置 (datasource)
定义了 3 个 MySQL 数据源(ds0、ds1、ds2),分别指向主库和从库。
| 配置项 | 说明 |
|---|---|
spring.shardingsphere.datasource.names | 数据源名称列表(ds0, ds1, ds2) |
ds0.type | 数据源类型(HikariCP 连接池) |
ds0.driver-class-name | JDBC 驱动类(MySQL 8.0+) |
ds0.jdbc-url | 主库连接 URL(mysql-master:3307) |
ds0.username / ds0.password | 数据库登录凭据(root/root) |
ds1.jdbc-url | 从库 1 连接 URL(mysql-slave1:3308) |
ds2.jdbc-url | 从库 2 连接 URL(mysql-slave2:3309) |
2. 分片规则 (rules.sharding)
(1) 表分片配置 (tables)
配置 t_order 表的分库分表策略。
| 配置项 | 说明 |
|---|---|
t_order.actual-data-nodes | 实际数据节点格式: - ds$->{0..2}.t_order_$->{0..2} 表示: - 数据源:ds0、ds1、ds2 - 表:t_order_0、t_order_1、t_order_2 |
t_order.table-strategy | 表分片策略(按 user_id 分片) |
t_order.database-strategy | 库分片策略(按 user_id 分库) |
(2) 分片算法 (sharding-algorithms)
定义库和表的分片算法。
| 算法名称 | 类型 | 算法表达式 | 说明 |
|---|---|---|---|
order-db-inline | INLINE | ds${user_id % 3} | 根据 user_id % 3 路由到 ds0/ds1/ds2 |
order-table-inline | INLINE | t_order_${user_id % 3} | 根据 user_id % 3 路由到 t_order_0/t_order_1/t_order_2 |
(3) 广播表 (broadcast-tables)
配置 t_user 表为广播表(所有库全量同步)。
| 配置项 | 说明 |
|---|---|
broadcast-tables | 广播表列表(t_user) |
(4) 默认策略 (default-*)
显式禁用默认分库分表策略(仅对未配置的表生效)。
| 配置项 | 说明 |
|---|---|
default-database-strategy.none | 默认不分库 |
default-table-strategy.none | 默认不分表 |
3. 属性配置 (props)
| 配置项 | 说明 |
|---|---|
sql-show: true | 打印 SQL 日志(调试用) |
完整配置总结
| 层级 | 关键配置项 | 作用 |
|---|---|---|
| 数据源 | datasource.names | 定义 3 个数据源(ds0, ds1, ds2) |
| 分片规则 | tables.t_order.actual-data-nodes | 逻辑表 t_order 映射到 3 个库的 3 张分表(共 9 张表) |
| 分片策略 | database-strategy / table-strategy | 按 user_id 分库分表 |
| 分片算法 | order-db-inline / order-table-inline | 通过取模运算路由数据 |
| 广播表 | broadcast-tables: t_user | t_user 表在所有库中全量同步 |
| 调试 | sql-show: true | 打印实际执行的 SQL |
潜在问题检查
- 表名冲突
- 确保数据库中不存在名为
order的表(你的配置已使用t_order,无冲突)。
- 确保数据库中不存在名为
- 分表是否创建
- 需手动创建所有分表(如
ds0.t_order_0,ds1.t_order_1等)。
- 需手动创建所有分表(如
- 分片键类型
user_id应为数值类型(否则%运算可能失败)。
- SQL 日志验证
- 启用
sql-show: true后,观察日志确认路由是否正确。
- 启用
示例 SQL 路由结果
假设 user_id = 5:
-
分库路由:
5 % 3 = 2→ds2 -
分表路由:
5 % 3 = 2→t_order_2 -
最终 SQL:
INSERT INTO t_order_2 (id, user_id, ...) VALUES (?, 5, ...)执行在 ds2 数据源上。
通过以上配置,ShardingSphere 会根据 user_id 自动将数据分散到不同的库和表中。如果仍有问题,建议检查:
- 数据库表是否已创建。
- 分片键
user_id的值是否符合预期。 - 日志中输出的实际 SQL 是否符合分片逻辑。
🧩 五、Java 实体与 DAO 层设计
实体类
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;import java.math.BigDecimal;
import java.time.LocalDateTime;@Data
@TableName("t_order")
public class Order {private Long id;private Long userId;private String orderNo;private BigDecimal amount;private LocalDateTime createTime;
}Mapper接口
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.shardingdemo.entity.Order;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}Controller接口
import cn.hutool.core.util.IdUtil;
import com.example.shardingdemo.entity.Order;
import com.example.shardingdemo.mapper.OrderMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.math.BigDecimal;
import java.time.LocalDateTime;
import java.util.List;@RestController
@RequestMapping("/order")
public class OrderController {@Autowiredprivate OrderMapper orderMapper;@PostMapping("/create")public String createOrder() {Order order = new Order();order.setId(IdUtil.getSnowflakeNextId());order.setUserId(1001L);order.setOrderNo("ORDER_" + System.currentTimeMillis());order.setAmount(new BigDecimal("99.99"));order.setCreateTime(LocalDateTime.now());orderMapper.insert(order);return "OK";}@GetMapping("/list")public List<Order> listOrders() {return orderMapper.selectList(null);}
}
🚦 常用查询效果演示
✅ 写入数据
Logic SQL: INSERT INTO t_order ( id, user_id, order_no, amount, create_time ) VALUES ( ?, ?, ?, ?, ? )
Actual SQL: ds2 ::: INSERT INTO t_order_2 ( id, user_id, order_no, amount, create_time ) VALUES (?, ?, ?, ?, ?) ::: [1952250075647401984, 1001, ORDER_1754287663743, 99.99, 2025-08-04T14:07:43.743983]
计算 userId=1001 的路由结果
(1) 分库计算
1001 % 3 = 2 // 余数为 2
目标库:ds2(对应 ds${2})
(2) 分表计算
1001 % 3 = 2 // 余数仍为 2
目标表:t_order_2(对应 t_order_${2})
✅ 查询数据
Actual SQL: ds2 ::: SELECT id,user_id,order_no,amount,create_time FROM t_order_0 WHERE id=? UNION ALL SELECT id,user_id,order_no,amount,create_time FROM t_order_1 WHERE id=? UNION ALL SELECT id,user_id,order_no,amount,create_time FROM t_order_2 WHERE id=? ::: [1952241523566383104, 1952241523566383104, 1952241523566383104]
👉 自动路由,跨表/跨库查询时支持 Merge 结果集
🚧 常见问题与优化建议
| 问题/瓶颈 | 原因分析 | 优化建议 |
|---|---|---|
| 跨库查询慢 | 无法使用索引 | 避免跨库;结合分片键做等值过滤 |
| 写入热点库慢 | 分片策略不均匀 | 使用雪花 ID + hash 分库分表策略 |
| SQL 不支持 | 复杂 JOIN / 子查询等 | 拆分逻辑到应用层,使用绑定表提升性能 |
| 分布式事务处理 | 多库事务需要协调 | 引入 Seata 或采用 BASE 最终一致性方案 |
| 分片表扩容麻烦 | 表名写死、规则不灵活 | 使用 Hint / 时间分片表达式 / Inline 表达式 |
📎 参考资料与源码下载
- 🔗 官方文档(ShardingSphere)
💬 如果你觉得这篇文章对你有帮助,欢迎点赞 + 收藏 + 评论,一起交流分库分表最佳实践!