ConcurrentHashMapRedis实现二级缓存

1. 为什么使用ConcurrentHashMap?
在Java中,ConcurrentHashMap 是一个线程安全且高效的哈希表实现,广泛用于高并发场景。将其用作一级缓存的原因主要包括以下几点:
1.1. 线程安全性
ConcurrentHashMap是线程安全的,支持多个线程同时进行读写操作而不会出现数据不一致或竞态条件问题。这使其非常适合用作多线程环境下的缓存,因为缓存通常会被多个线程并发访问。- 传统的
Hashtable也是线程安全的,但它使用全局锁,性能较低。而ConcurrentHashMap使用分段锁(Segment)机制,将锁粒度降低,从而在高并发场景下性能更高。
1.2. 高效的并发访问
ConcurrentHashMap在高并发场景下表现出色,因为它通过分段锁(Segment)和无锁操作(如读操作)最大限度地减少了锁竞争。- 它支持高吞吐量和低延迟,非常适合缓存这种需要快速读写的场景。
1.3. 内存使用效率
ConcurrentHashMap在内存使用上非常高效,适合存储大量缓存数据。- 它通过动态调整容量和负载因子,确保内存的高效利用。
1.4. 扩展性
ConcurrentHashMap支持动态扩容,能够根据实际需求自动调整内部数组的大小,从而适应数据量的动态变化。- 这种特性使得它非常适合用作缓存,因为缓存的大小可能会随着业务需求的变化而动态调整。
1.5. 与缓存策略结合
- 一级缓存通常用于快速访问最近或频繁访问的数据,而
ConcurrentHashMap的高效性和线程安全性使其成为实现这一目标的理想选择。 - 它可以与其他缓存策略(如基于时间的过期、基于容量的淘汰等)结合使用,进一步提升缓存的性能和灵活性。
1.6. 集成方便
ConcurrentHashMap是 Java 标准库的一部分,使用简单且集成方便,无需引入额外的依赖。- 它可以与各种缓存框架(如 Ehcache、Caffeine)或自定义缓存实现无缝结合。
1.7. 补充介绍,多线程环境下使用哈希表
HashMap:线程不安全,不建议多线程环境使用ConcurrentHashMap:线程安全,但是使用的是分段锁(Segment)机制Hashtable:线程安全,但使用的是全局锁,对所有的操作都加锁,对性能有很大的影响,会导致严重的效率问题HashMap实现原理:
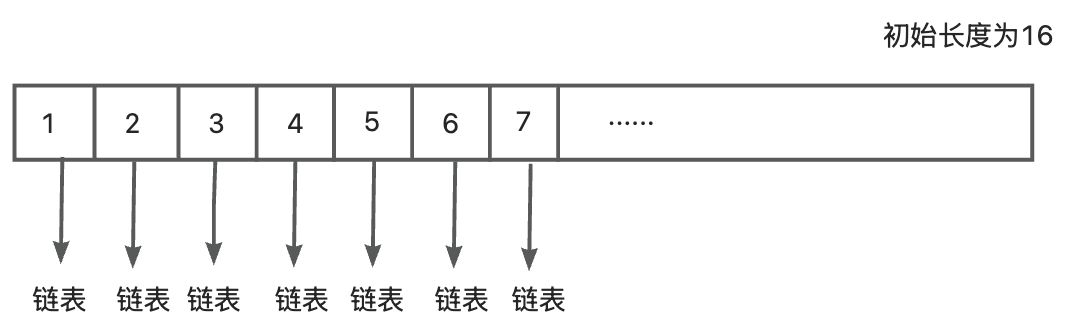
- put一个对象的时候,先根据对象的hashcode和数组的长度进行求余,通过余数来确定对象放在数组中的哪一个下表
- 每个hash桶中存放的是具体对象的链表
- 初始化的数组长度为16,中间还可能发生扩容,扩容的时候会对当前的表中的元素hash到新的哈希表中
- 链表的长度大于6的时候,同时数组的长度大于64时,链表会转化为红黑树
Hashtable实现原理:
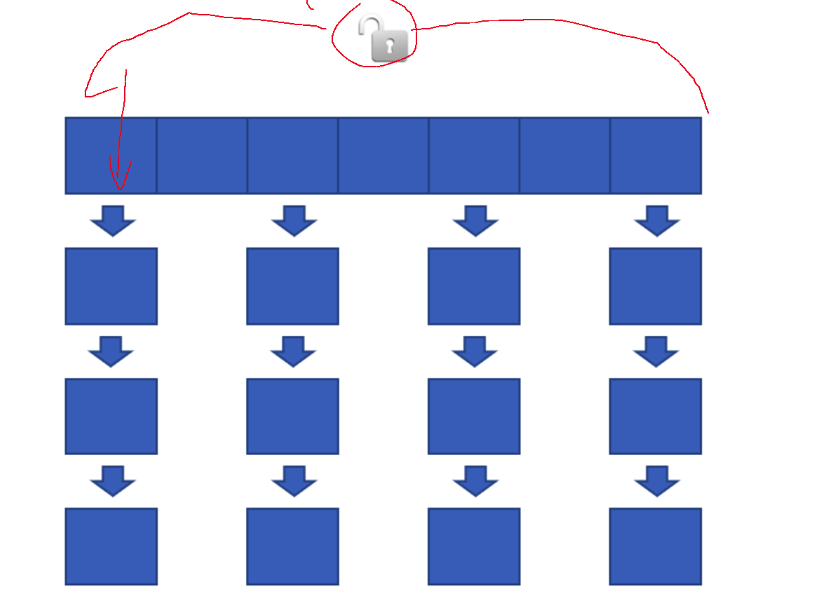
- 对数组进行全局加锁,但是实际操作的时候只会针对一个哈希桶,因此会对系统性能有很大影响,多线程环境不建议使用
ConcurrentHashMap实现原理:
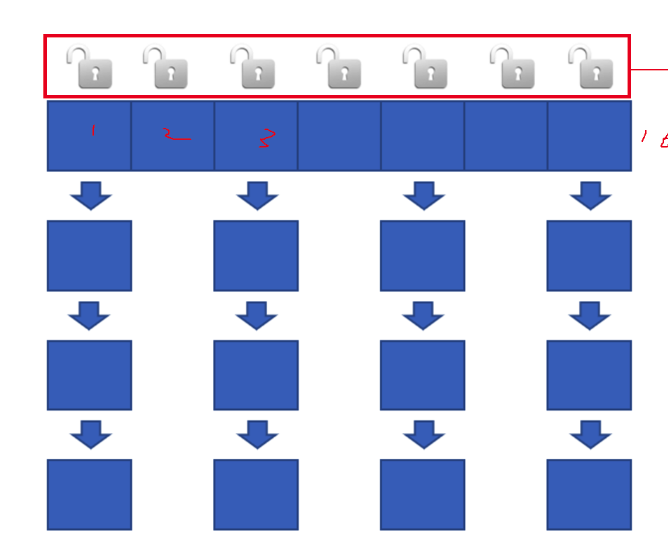
- 对于所操作的特定哈希桶实施加锁机制,而其余哈希桶则保持解锁状态,这意味着其他未锁定的哈希桶中的数据可以并行地执行读写操作。
- 理论上讲,系统支持的并发读写线程数量等同于哈希桶的数量,即每个哈希桶都可以独立地被一个线程访问而不影响其它桶的操作。
- 扩容优化策略包括:
a. 当检测到存储空间不足时,将底层数组容量翻倍。但值得注意的是,在此过程中,并非一次性迁移所有元素至新映射结构中,而是仅迁移当前正在访问的那个索引位置上的元素。
b. 此种方式导致在一段时间内存在两个版本的数据结构共存。
c. 在执行查询操作时,需同时对这两个版本的数据结构进行搜索以确保结果准确性。
d. 同样地,当需要删除条目时,也需要在这两份数据结构上分别实施删除动作。
e. 新增数据项时,则仅向最新扩展后的映射结构中添加。
f. 该设计采用了一种典型的空间换时间策略,通过牺牲一定的内存开销来换取更高的并发性能,这正是ConcurrentHashMap能够在高并发场景下表现优异的原因之一。更具其底层源码可以发现,在执行put操作的时候会进行加锁,使用CAS(Compare-And-Swap)操作和synchronized锁来保证线程安全,但是get操作不会加锁,它通过volatile语义来保证可见性,能够读取到最新的数据,它不会阻塞其他线程的并发访问,所以ConcurrentHashMap的设计是在线程安全和性能之间找到平衡点,get 操作的无锁化设计是其高性能的关键之一
g. 每次调用get或put方法时,都会触发一个过程:将旧映射中对应索引下的元素逐步迁移到新的映射中;只有当迁移完成后,才会从旧映射中移除这些元素。每次调用get、put方法的时候把旧的map中对应的下标中的元素搬运到新的map中,搬运完之后才会删除
1.8. 总结
ConcurrentHashMap 作为一级缓存的主要原因是其线程安全性、高效的并发访问能力、内存使用效率以及扩展性。这些特性使其非常适合在高并发场景下快速读写数据,从而提高应用性能。
2. 为什么选择Redis作为二级缓存?
2.1. 高可用性和持久化
- Redis 提供了多种持久化机制(如 RDB 和 AOF),能够在服务器重启后恢复数据,避免缓存数据丢失。
ConcurrentHashMap是内存中的数据结构,数据仅存在于 JVM 内存中,不具备持久化能力。
2.2. 丰富的数据结构
- Redis 提供了多种数据结构(如字符串、列表、哈希、集合、有序集合等),能够更灵活地支持复杂的缓存需求。
ConcurrentHashMap仅支持键值对的简单存储,功能相对单一。
2.3. 分布式支持
- Redis 是一个分布式数据库,支持多节点集群,能够满足高并发、大规模数据场景下的缓存需求。
ConcurrentHashMap是单机内存数据结构,无法直接支持分布式场景。
2.4. 4. 高性能
- Redis 的单线程模型通过事件驱动和非阻塞 IO 实现了高性能的读写操作,特别适合高并发场景。
ConcurrentHashMap是基于 CAS 和分段锁实现的,虽然性能很高,但在高并发场景下可能会因锁竞争导致性能下降。
2.5. 缓存穿透、击穿、失效问题的解决方案
- Redis 提供了多种机制来解决缓存穿透(如布隆过滤器)、缓存击穿(如互斥锁)和缓存失效(如预热)等问题。
ConcurrentHashMap难以直接解决这些问题,需要额外的逻辑实现。
2.6. 数据共享和一致性
- Redis 可以作为分布式缓存,支持多个服务实例共享缓存数据,保证数据一致性。
ConcurrentHashMap是单机的,无法实现跨服务实例的数据共享。
2.7. 缓存分层
- Redis 通常作为二级缓存,而
ConcurrentHashMap作为一级缓存(本地内存缓存)。这种分层设计能够优化性能,同时降低内存占用。 - 本地缓存(一级缓存)负责快速访问,Redis(二级缓存)负责数据持久化和跨服务共享。
2.8. 支持复杂业务逻辑
- Redis 提供了丰富的命令和事务支持,能够直接在缓存层处理一些复杂的业务逻辑。
ConcurrentHashMap仅支持简单的键值操作,无法处理复杂逻辑。
2.9. 总结
Redis 作为二级缓存的优势在于其高性能、分布式能力、持久化支持和丰富的功能,能够弥补 ConcurrentHashMap 的不足。通过将 ConcurrentHashMap 作为一级缓存(本地内存缓存),Redis 作为二级缓存(分布式缓存),可以构建一个高效、可靠、可扩展的缓存系统。
3. 使用ConcurrentHashMap和redis实现二级缓存的优点和缺点
3.1. 优点
- 性能分层优化
- ConcurrentHashMap(本地缓存):内存级访问速度(纳秒级),减少高频热点数据的重复远程请求。
- Redis(远程缓存):提供跨进程/节点的数据共享,支持高并发读取,避免直接穿透到数据库。
- 降低数据库压力
- 两级缓存组合可拦截大多数查询请求,尤其在突发流量下,本地缓存直接响应请求,减少对Redis和数据库的负载。
- 适应分布式与单机场景
- 本地缓存:适用于单机高频热点数据(如配置信息)。
- Redis:解决分布式环境下多节点数据一致性问题。
- 资源利用优化
- 本地缓存节省网络开销,Redis支持丰富的数据结构(如Hash、SortedSet)和持久化能力。
3.2. 缺点
- 数据一致性挑战
- 同步延迟:本地缓存更新可能滞后于Redis,尤其是在分布式场景下(如某节点未及时收到失效通知)。
- 更新策略复杂性:需实现双重失效机制(如Redis Pub/Sub通知本地缓存失效),增加代码复杂度。
- 资源占用风险
- 本地内存压力:ConcurrentHashMap缓存过多数据可能导致JVM内存溢出或频繁GC。
- Redis运维成本:需监控内存、持久化策略,集群部署增加运维复杂度。
- 缓存异常场景放大
- 缓存穿透:本地和Redis均未命中时,请求可能直接击穿到数据库。
- 雪崩风险:两级缓存同时失效可能导致数据库瞬时压力激增。
- 设计复杂度高
- 需实现缓存逐级加载(如本地→Redis→DB)、锁竞争控制(如本地缓存未命中时,避免多个线程重复加载数据)。
3.3. 适用场景建议
- 推荐使用:读多写少的高频数据(如商品详情、配置信息),且对一致性要求不苛刻(允许短暂过期)。
- 避免使用:写多读少或强一致性场景(如库存扣减),本地缓存频繁失效会抵消性能优势。
3.4. 优化思路
- 一致性保障
- 通过Redis的Pub/Sub或定时轮询,主动失效本地缓存。
- 对本地缓存设置较短TTL,结合写后更新策略(Write-Through)。
- 异常防护
- 本地缓存使用软引用(SoftReference)防止内存溢出。
- Redis层增加分布式锁或熔断机制,避免缓存击穿。
- 监控与治理
- 监控本地缓存命中率、Redis内存使用率。
- 使用Guava Cache或Caffeine替代ConcurrentHashMap,支持容量限制、权重过期等策略。
通过合理设计,ConcurrentHashMap+Redis二级缓存可显著提升系统性能,但需在一致性、复杂度、资源消耗之间谨慎权衡。
4. Java Spring项目中的使用
4.1. ConcurrentHashMap一级缓存
package com.project.demo.Admin.cache;import com.project.demo.Admin.model.constant.CacheConstant;
import com.project.demo.Admin.model.response.GetTrendResponse;
import lombok.extern.slf4j.Slf4j;import java.time.Duration;
import java.time.LocalDateTime;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;/*** @className: LocalCache* @author: 顾漂亮* @date: 2025/7/22 11:33*/
@Slf4j
//本地缓存 -- 一级缓存
public class LocalCache {// 提供线程安全的操作,适合多线程环境下的缓存访问,支持高效的并发读写操作private static final ConcurrentHashMap<String, CacheItem> cache = new ConcurrentHashMap<>();// 使用ScheduledExecutorService实现定时清理过期数据,创建了一个单线程的调度执行器 (newScheduledThreadPool(1))private static final ScheduledExecutorService cleaner = Executors.newScheduledThreadPool(1);// 定时任务,每一分钟清理一次static {cleaner.scheduleAtFixedRate(LocalCache::cleanExpiredCache,0, //等待几分钟后开始,此处0代表立即开始CacheConstant.CLEANUP_INTERVAL_MINUTES, //每隔指定分钟进行一次TimeUnit.MINUTES); // 时间单位,此处以分钟为单位log.info("清除ConcurrentHashMap中的缓存");}// 缓存项包装类,记录存储时间private static class CacheItem{final GetTrendResponse value; //存储的数据类型final LocalDateTime storedTime; //开始存储的时间//初始化数据CacheItem(GetTrendResponse value) {this.value = value;this.storedTime = LocalDateTime.now(); //获取当前系统的时间戳}}/*** 获取缓存* @param key 键* @return 值*/public static GetTrendResponse get(String key) {CacheItem item = cache.get(key);if (item != null && !isExpired(item)){return item.value;}return null;}/*** 添加缓存* @param key 键* @param value 值*/public static void put(String key, GetTrendResponse value) {cache.put(key, new CacheItem(value));}/*** 清理过期缓存*/private static void cleanExpiredCache() {log.info("开始清理ConcurrentHashMap中过期缓存");int initialSize = cache.size(); // 初始缓存大小cache.entrySet().removeIf(entry -> isExpired(entry.getValue()));int finalSize = cache.size(); // 清理之后缓存大小log.info("清理了{}个缓存项,剩余{}个缓存项", initialSize - finalSize, finalSize);}/*** 判断缓存是否过期* @param item 键* @return true:过期,false:未过期*/private static boolean isExpired(CacheItem item) {//1. 计算从存储时间到现在的时间差Duration duration = Duration.between(item.storedTime, LocalDateTime.now());//2. 检查是否超过了缓存有效期return duration.toMinutes() > CacheConstant.CACHE_EXPIRY_MINUTES;}/*** 关闭定时任务,调用 cleaner.shutdown() 来关闭 ScheduledExecutorService,避免内存泄露和资源浪费*/public static void shutdown() {cleaner.shutdown();}
}4.2. 使用Redis结合Spring Cache进行二级缓存
package com.project.demo.common.config.cache;import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.StringRedisSerializer;import java.time.Duration;/** @className: RedisConfig* @author: 顾漂亮* @date: 2025/7/29 16:49*//*** Redis缓存配置类* 用于配置Spring Cache与Redis的整合,定义缓存管理器及序列化方式*/
@EnableCaching // 启动缓存功能
@Configuration
public class RedisConfig {/*** 创建缓存管理器* @param factory Redis连接工厂* @return 缓存管理器*/@Beanpublic RedisCacheManager cacheManager(RedisConnectionFactory factory) {RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig() //获取Redis缓存的默认配置作为基础配置.serializeKeysWith(RedisSerializationContext //配置缓存键(key)的序列化方式,Key: "users::1".SerializationPair.fromSerializer(new StringRedisSerializer())).serializeValuesWith(RedisSerializationContext //配置缓存值(value)的序列化方式,Value: {"id":1,"name":"张三"}.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));return RedisCacheManager.builder(factory) //构建Redis缓存管理器.cacheDefaults(config).build();}
}