无监督MVSNet系列网络概述
目录
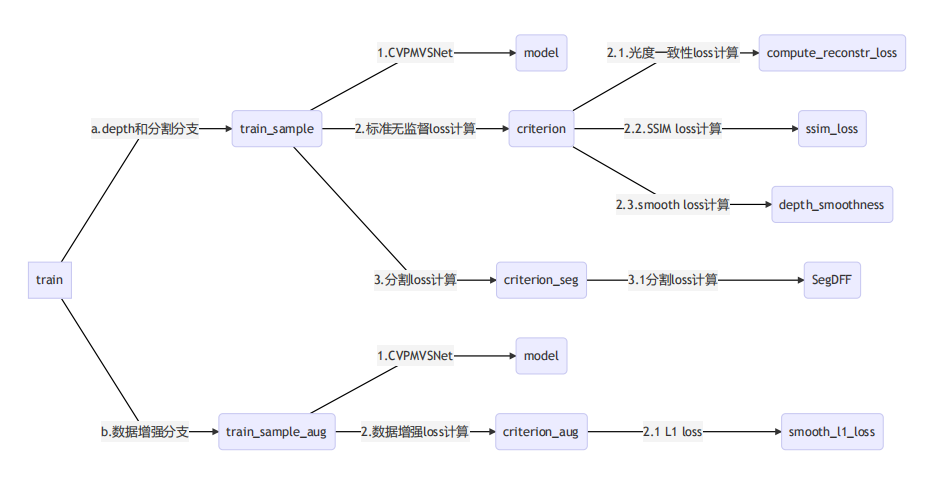
Unsup-MVSNet
PatchMatchNet代码总框架
算法流程
自监督网络JDACS-MS代码总框架
交叉熵
常用的三个Loss原理
VGG网络
Unsup-MVSNet
➢实现无监督的MVS
➢使用鲁棒的光度一致性Loss实现无监督 深度图估计,克服不同视图下的光照变化 和遮挡问题
https://link.zhihu.com/?target=https%3A//github.com/YoYo000/MVSNet
MVS2
➢在之前标准的无监督Loss基础上又提出 了cross-view一致性Loss
➢深度图优化采用SPN进行优化
M^3VSNet
➢结合pixel-wise和feature-wise构建Loss
➢加入法向量一致性Loss提高深度图估 计的准确性和连续性
PatchMatchNet代码总框架

算法流程
特征计算
基于FPN的多尺度特征提取
depth初始化:
如果是第一次迭代:随机初始化48层(参数可调)
如果是第二次及后续N次:在第一次迭代得到的深度图为中心上下采样几层(局部扰动),再
加上自适应传播从邻域N_neighbor传播过来的N_neighbor个深度图层。
匹配代价计算与代价聚合
得到depth hypothesis后,计算匹配代价(warp src的feature 到 ref对应depth层下,匹配
相似性计算见论文公式3),使用Pixel-wise view weight进行聚合得到[B,Ndepth,H,W](参
考公式5)
对每个像素和每个depth hypothesis,自适应采样一些邻域内的像素进行cost aggregation.
所有邻域相对中心像素的权重与对应深度乘积和(参加公式6)
深度图计算与优化
得到所有costs以后,用softmax得到每个hypothesis对应的概率,然后求期望得到估计值。
优化这部分跟MVSNet相同,由ref的rgb引导计算一个残差与初始深度图加和即为优化后的深
度图
自监督网络JDACS-MS代码总框架
交叉熵
Cross Entropy损失函数常用于分类问题中,很容易的的进行求导计算

常用的结构:
1. 神经网络最后一层得到每个类别的得分scores(也叫logits);
2. 该得分经过sigmoid(或softmax)函数获得概率输出;
3. 模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算
参考链接:https://zhuanlan.zhihu.com/p/35709485
常用的三个Loss原理
SSIM Loss
度量两个图像之间的相似性
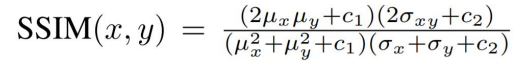
光度一致性Loss
warp N-1 Source图像到Refer图像上,计算两者的梯度和颜色差异
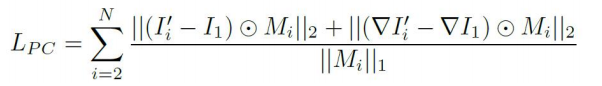
平滑Loss
深度图变化大的地方rgb的变化也比较大
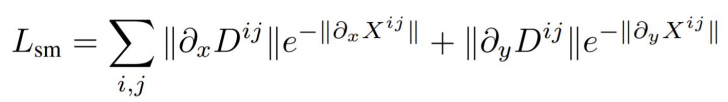
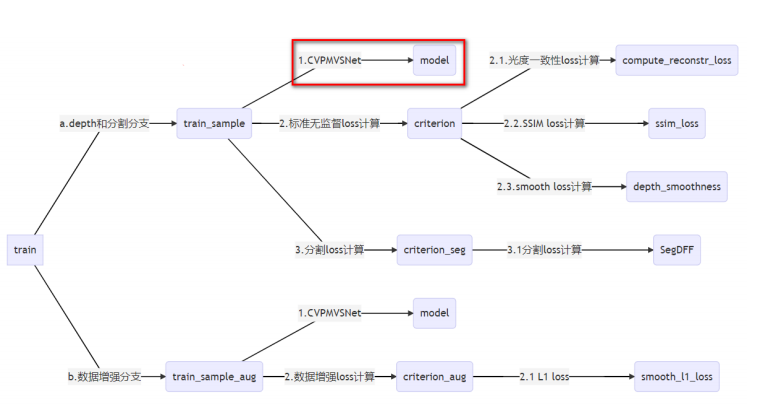
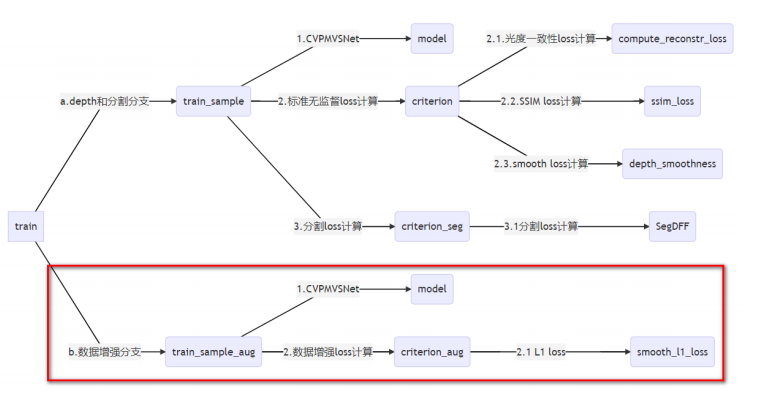
训练脚本 train.py 中 def train() 函数
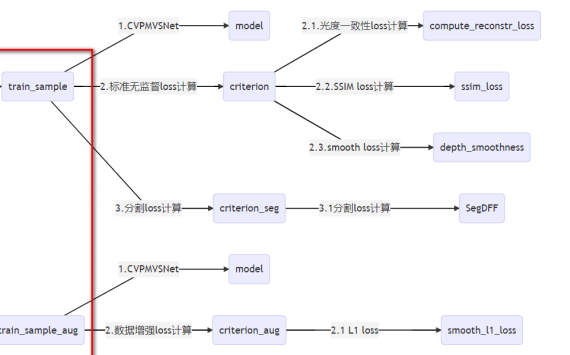
network.py 中CVP网络
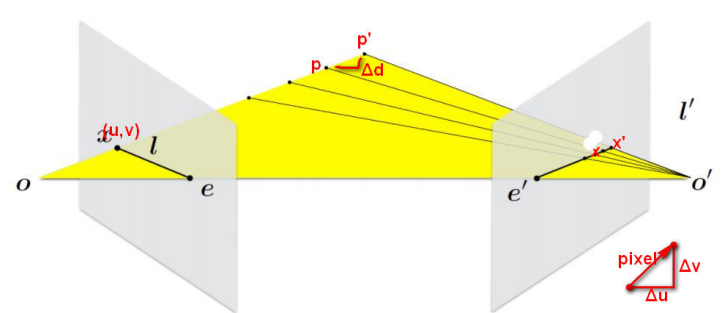
在第二个scale时,计算深度层的间隔推导如下:
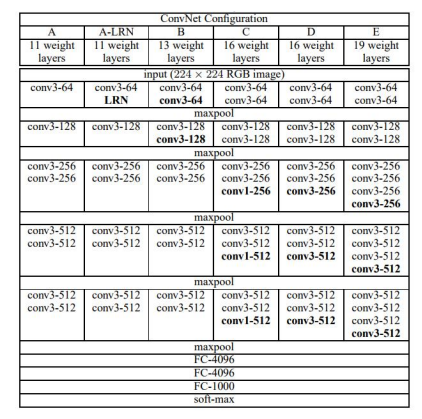
VGG网络
VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。
train.py 中 def train_sample_aug() 数据增强Loss
import numpy as np
from read_write_model import read_model, write_model
from tempfile import mkdtempdef compare_cameras(cameras1, cameras2):assert len(cameras1) == len(cameras2)for camera_id1 in cameras1:camera1 = cameras1[camera_id1]camera2 = cameras2[camera_id1]assert camera1.id == camera2.idassert camera1.width == camera2.widthassert camera1.height == camera2.heightassert np.allclose(camera1.params, camera2.params)def compare_images(images1, images2):assert len(images1) == len(images2)for image_id1 in images1:image1 = images1[image_id1]image2 = images2[image_id1]assert image1.id == image2.idassert np.allclose(image1.qvec, image2.qvec)assert np.allclose(image1.tvec, image2.tvec)assert image1.camera_id == image2.camera_idassert image1.name == image2.nameassert np.allclose(image1.xys, image2.xys)assert np.array_equal(image1.point3D_ids, image2.point3D_ids)def compare_points(points3D1, points3D2):for point3D_id1 in points3D1:point3D1 = points3D1[point3D_id1]point3D2 = points3D2[point3D_id1]assert point3D1.id == point3D2.idassert np.allclose(point3D1.xyz, point3D2.xyz)assert np.array_equal(point3D1.rgb, point3D2.rgb)assert np.allclose(point3D1.error, point3D2.error)assert np.array_equal(point3D1.image_ids, point3D2.image_ids)assert np.array_equal(point3D1.point2D_idxs, point3D2.point2D_idxs)def main():import sysif len(sys.argv) != 3:print("Usage: python read_model.py ""path/to/model/folder/txt path/to/model/folder/bin")returnprint("Comparing text and binary models ...")path_to_model_txt_folder = sys.argv[1]path_to_model_bin_folder = sys.argv[2]cameras_txt, images_txt, points3D_txt = \read_model(path_to_model_txt_folder, ext=".txt")cameras_bin, images_bin, points3D_bin = \read_model(path_to_model_bin_folder, ext=".bin")compare_cameras(cameras_txt, cameras_bin)compare_images(images_txt, images_bin)compare_points(points3D_txt, points3D_bin)print("... text and binary models are equal.")print("Saving text model and reloading it ...")tmpdir = mkdtemp()write_model(cameras_bin, images_bin, points3D_bin, tmpdir, ext='.txt')cameras_txt, images_txt, points3D_txt = \read_model(tmpdir, ext=".txt")compare_cameras(cameras_txt, cameras_bin)compare_images(images_txt, images_bin)compare_points(points3D_txt, points3D_bin)print("... saved text and loaded models are equal.")print("Saving binary model and reloading it ...")write_model(cameras_bin, images_bin, points3D_bin, tmpdir, ext='.bin')cameras_bin, images_bin, points3D_bin = \read_model(tmpdir, ext=".bin")compare_cameras(cameras_txt, cameras_bin)compare_images(images_txt, images_bin)compare_points(points3D_txt, points3D_bin)print("... saved binary and loaded models are equal.")if __name__ == "__main__":main()