HTML应用指南:利用GET请求获取全国小米之家门店位置信息
小米之家作为小米公司打造的线下零售体验品牌,自2011年首家门店开业以来,凭借其“科技+新零售”的创新运营模式,迅速在全国范围内扩展,成为小米生态链体系中的重要一环。小米之家不仅销售小米全系智能硬件产品,还集产品体验、售后服务、品牌展示于一体,致力于为消费者提供一站式的智能生活解决方案,品牌始终坚持“让全球每个人都能享受科技的乐趣”的理念,依托小米强大的产品矩阵和供应链体系,结合线下门店的沉浸式体验空间,为用户带来高性价比、智能化、高品质的生活方式。小米之家在注重产品展示与销售的同时,也强调门店设计的科技感与用户体验的舒适度,营造出一种现代、简约、极富科技感的消费氛围。
本文将探讨如何通过GET请求从官方网站或公开接口中获取小米之家的门店分布信息,并展示使用Python的requests库发送GET请求的方法,以提取详细的门店位置数据。这些信息覆盖全国范围内的所有小米之家门店,并通过解析JSON格式的数据或HTML页面来处理响应内容。这种数据采集方式有助于我们更深入地了解小米之家在不同地区的市场布局策略、门店密度分布及其与消费人群之间的关系。通过结构化整理门店数据,还可以为后续的可视化分析、商圈研究以及品牌扩张趋势预测提供数据基础。
小米之家门店网址:小米之家门店查询-小米官方售后服务-小米官网
首先,我们找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
负载:对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里我们可以看到城市名,时间戳,还是明文,没有进行加密;
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有店铺列表的相关标签数据;
- 我们通过获取和改变行政区id及名称,来遍历全国门店数据;
- 地理编码→地址转经纬度,再通过coord-convert库实现GCJ-02转WGS84;
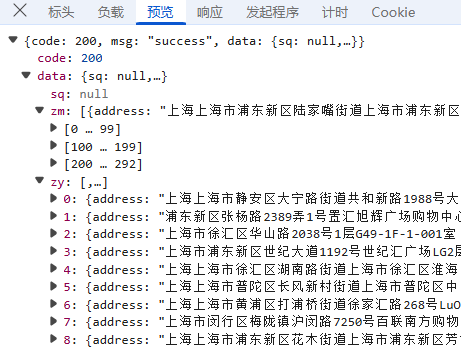
第一步:我们直接在"Fetch/XHR"先找到对应数据存储位置,获取所有店铺列表, 我们可以看到数据标签分为sq(授权), zm(专卖), 和 zy(直营)等不同类型的门店信息;

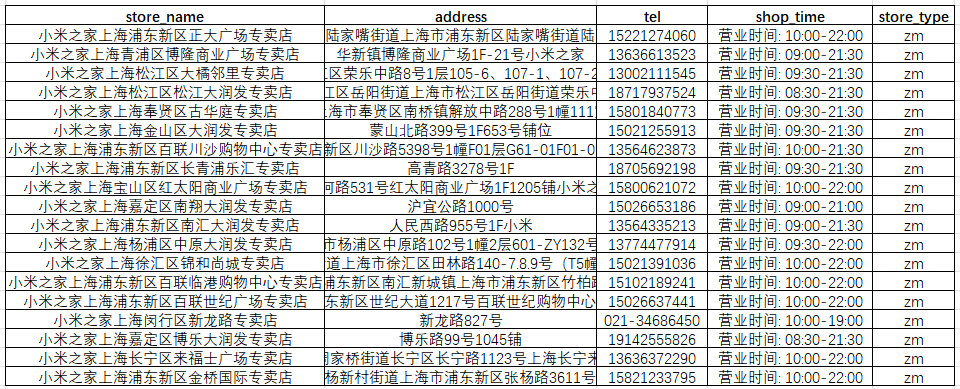
第二步:利用GET请求获取所有店铺列表,并根据标签进行保存,另存为csv,这里以上海市为例;
完整代码#运行环境 Python 3.11(特定城市版)
import csv
import requests
import time# 请求地址
url = "https://api2.service.order.mi.com/store/store_list"# 请求参数
params = {"area_type": 2,"area_id": 108,"area_name": "上海市","t": 1753431336 # 有时效的,需要替换成查询时页面的时间戳
}# 请求头(Headers)
headers = {# 替换成你自己访问时的表头
}# 发送请求
response = requests.get(url, params=params, headers=headers)# 检查响应状态码
if response.status_code == 200:data = response.json()# 确保 data 存在且不为空if data.get("code") == 200 and data.get("data"):stores = []# 提取 sq 类型门店信息if data["data"].get("sq"):for store in data["data"]["sq"]:stores.append({"store_name": store.get("store_name"),"address": store.get("address"),"tel": store.get("tel"),"shop_time": store.get("shop_time"),"store_type": "sq"})# 提取 zm 类型门店信息if data["data"].get("zm"):for store in data["data"]["zm"]:stores.append({"store_name": store.get("store_name"),"address": store.get("address"),"tel": store.get("tel"),"shop_time": store.get("shop_time"),"store_type": "zm"})# 提取 zy 类型门店信息if data["data"].get("zy"):for store in data["data"]["zy"]:stores.append({"store_name": store.get("store_name"),"address": store.get("address"),"tel": store.get("tel"),"shop_time": store.get("shop_time"),"store_type": "zy"})# 将数据写入 CSV 文件with open('mi_stores.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:fieldnames = ['store_name', 'address', 'tel', 'shop_time', 'store_type']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader()for store in stores:writer.writerow(store)print("门店信息已成功保存到 mi_stores.csv")else:print("没有门店数据返回")
else:print(f"请求失败,状态码: {response.status_code}")获取数据标签如下,store_name(店铺名称)、address(店铺名称地址)、tel(电话)、shop_time(营业时间)、store_type(店铺类型)坐标这里通过脚本拆成了两列,其他一些非关键标签,这里省略;
如果需要换成其他城市,直接把这里的城市换成对应的area_id,area_name,和时间戳即可;
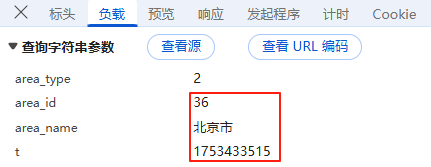
这样一个一个下比较慢,我们进行检索全国数据进行下载,首先,在"网络"里随便检索一个二级行政区,比如"石家庄市",我们要找到行政区编码放在哪里了;
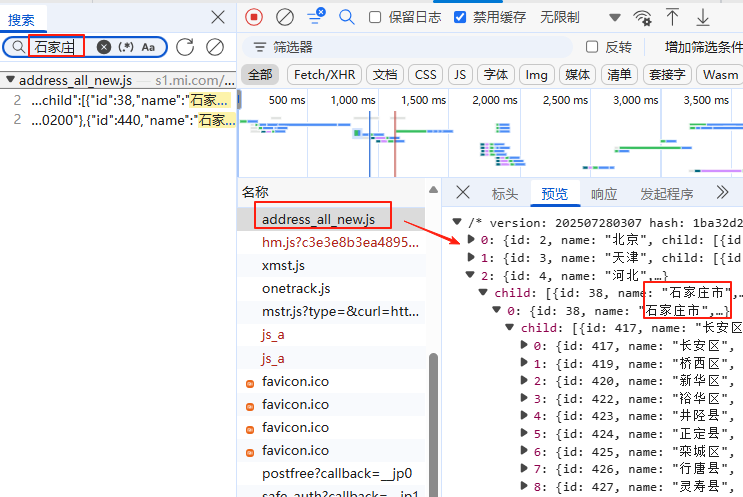
接下来,我们先下载js,然后可以在脚本目录下找到这个address_all_new.js文件;
完整代码#运行环境 Python 3.11
import requests
import os
import re
import json
import pandas as pd# JS 文件的 URL
url = "https://s1.mi.com/open/common/js/address_all_new.js"
# 本地保存路径
save_path = "address_all_new.js"def download_js_file(url, save_path):if os.path.exists(save_path):print(f"文件已存在,跳过下载:{os.path.abspath(save_path)}")returnprint(f"正在从 {url} 下载文件...")try:response = requests.get(url, timeout=10)response.raise_for_status()with open(save_path, "w", encoding="utf-8") as f:f.write(response.text)print(f"文件已成功保存到:{os.path.abspath(save_path)}")except requests.exceptions.RequestException as e:print(f"下载失败:{e}")exit(1)def extract_cities(js_path):with open(js_path, 'r', encoding='utf-8') as f:js_content = f.read()# 分号可有可无match = re.search(r'var data\s*=\s*(\[.*\])\s*;?', js_content, re.DOTALL)if not match:raise ValueError('未找到data数组')json_str = match.group(1)data = json.loads(json_str)cities = []for province in data:for city in province.get('child', []):cities.append({'id': city['id'], 'name': city['name']})return citiesif __name__ == "__main__":download_js_file(url, save_path)cities = extract_cities(save_path)df = pd.DataFrame(cities)df.to_csv('all_cities.csv', index=False, encoding='utf-8-sig')print('所有市及其id已保存为 all_cities.csv')
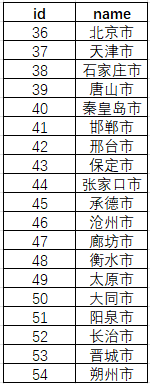
然后,我们直接读取这个JS数据(address_all_new.js文件),因为数据除了直辖市外,最大尺度可以到二级行政区,所以我们读取所有"市"级别的id和name,并保存为all_cities.csv;

完整代码#运行环境 Python 3.11(全国版)
import csv
import requests
import time
from datetime import datetime# API 配置
url = "https://api2.service.order.mi.com/store/store_list"
headers = {# 替换成你自己访问时的表头
}def fetch_store_data(area_id, area_name):params = {"area_type": 2,"area_id": area_id,"area_name": area_name,"t": int(time.time())}try:print(f"[{datetime.now()}] 正在请求 {area_name} 的数据...")response = requests.get(url, params=params, headers=headers, timeout=10)if response.status_code == 200:data = response.json()if data.get("code") == 200 and data.get("data"):stores = []store_types = {'sq': '授权店', 'zm': '专卖店', 'zy': '直营店'}for key, label in store_types.items():if data["data"].get(key):for store in data["data"][key]:stores.append({"store_name": store.get("store_name", "").strip(),"address": store.get("address", "").strip(),"tel": store.get("tel", "").strip(),"shop_time": store.get("shop_time", "").strip(),"store_type": label,"city": area_name})print(f"[{datetime.now()}] 成功获取 {len(stores)} 家门店")return storeselse:print(f" {area_name} 返回数据为空或 code 不为 200")return []else:print(f"请求失败,状态码: {response.status_code}")print(f"响应内容: {response.text}")return []except requests.exceptions.RequestException as e:print(f"网络请求异常: {e}")return []except Exception as e:print(f"解析数据异常: {e}")return []def save_to_csv(stores, filename='mi_stores_all_cities.csv'):if not stores:print("无数据可保存")returntry:with open(filename, 'w', newline='', encoding='utf-8-sig') as f:fieldnames = ['store_name', 'address', 'tel', 'shop_time', 'store_type', 'city']writer = csv.DictWriter(f, fieldnames=fieldnames)writer.writeheader()writer.writerows(stores)print(f"门店信息已成功保存到 {filename}")except Exception as e:print(f"保存文件失败: {e}")def main():all_stores = []cities_file = r'E:\data\all_cities.csv'try:with open(cities_file, 'r', encoding='utf-8-sig') as csvfile:reader = csv.DictReader(csvfile)for row in reader:area_id = row['id']area_name = row['name']stores = fetch_store_data(area_id, area_name)all_stores.extend(stores)time.sleep(1) # 防止请求过于频繁被封禁except FileNotFoundError:print(f"文件未找到: {cities_file}")except Exception as e:print(f"读取城市列表时发生错误: {e}")save_to_csv(all_stores)if __name__ == "__main__":main()第三步:地理编码和坐标系转换,这里因为数据标签没有直接的坐标数据,需要把获取的门店地址进行地理编码,具体实现方法可以参考我这篇文章:地址转坐标:利用高德API进行批量地理编码_高德地图api-CSDN博客;
这里直接下载转换结果,坐标系GCJ-02,当然还有个别地址描述太模糊的或者格式无法识别,会查不出坐标,手动查一下坐标即可,大部分还是可以查到的,因为当前坐标系是GCJ02,需要批量转成WGS84/BD09的话可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online),也可以通过coord-convert库实现GCJ-02转WGS84;
对CSV文件中的门店坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化,这里我们以上海市为例;
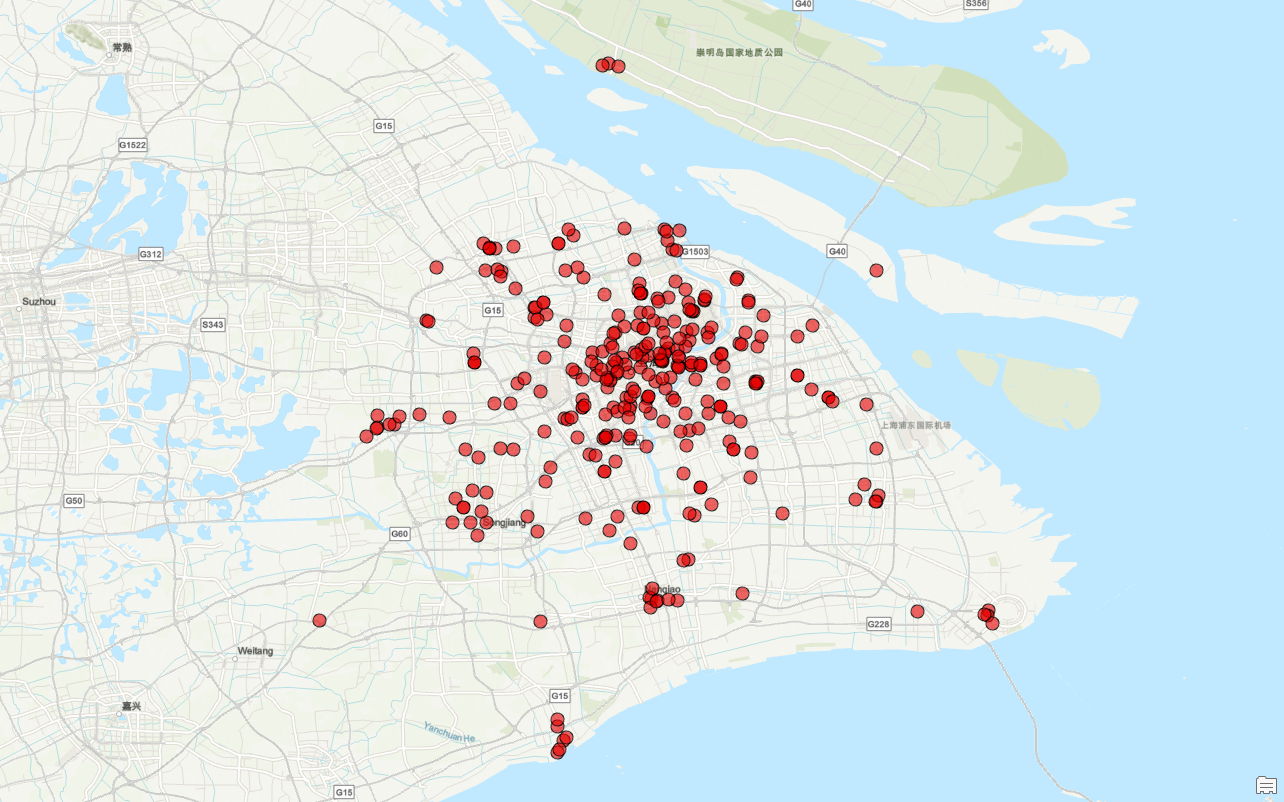
接下来,我们进行看图说话:
小米之家门店高度集中在城市中心区域,尤其是浦东新区以及黄浦江两岸等商业活动频繁、人口密集的地段。这些区域不仅是上海市经济的核心地带,而且交通便利,人流量大,有助于吸引更多的消费者。
此外,小米之家门店往往沿着主要的交通线路布置,如G15、G40等高速公路沿线,这不仅提高了顾客到达的便捷性,也增加了品牌的曝光度。尽管在郊区和卫星城的小米之家数量相对较少,但在上海的主要交通枢纽和重要地标附近,如上海浦东国际机场等地,仍能看到其布局的身影,显示出小米之家对于高人流地点的重视。
值得注意的是,在中心城区内形成了多个门店非常密集的"热点区域",这些地方通常是大型购物中心或交通枢纽所在地,拥有极高的客流量和消费能力。然而,整体来看,小米之家的分布并不均匀,呈现出明显的聚集与稀疏现象,反映了不同区域市场需求和战略重点的差异。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。