分布式数据库中的“分布式连接”(Distributed Joins)
这段文字讲的是 分布式数据库中的“分布式连接”(Distributed Joins),特别是针对 Apache Ignite 这类分布式内存数据库的处理方式。下面我将逐段解释这段内容,帮助你更好地理解。
一、什么是分布式连接(Distributed Joins)
原文:
A distributed join is a SQL statement with a join clause that combines two or more partitioned tables.
解释:
- 分布式连接指的是在 分布式数据库 中,对两个或多个分布在不同节点上的表进行 JOIN 操作。
- 这些表是“分区的”(partitioned),也就是说数据被分片存储在多个节点上。
二、Colocated Join(共置连接)和 Non-Colocated Join(非共置连接)
原文:
If the tables are joined on the partitioning column (affinity key), the join is called a colocated join. Otherwise, it is called a non-colocated join.
解释:
-
Colocated Join(共置连接):
-
如果两个表是根据相同的列(称为分区列或亲和键 affinity key)进行分区的,并且你在该列上做 JOIN,那么这两个表的数据会在同一个节点上。
-
这样就可以在每个节点上 本地执行 JOIN,效率很高。
-
举例:表 A 和表 B 都按
customer_id分区,查询SELECT * FROM A JOIN B ON A.customer_id = B.customer_id就是 Colocated Join。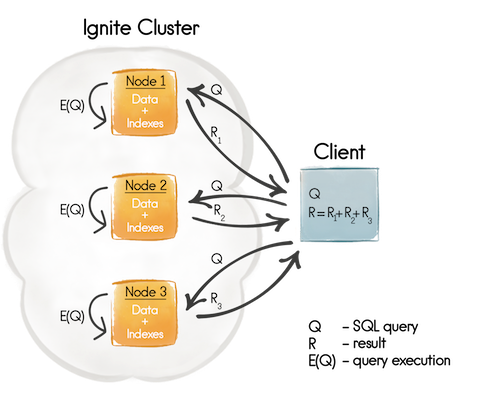
执行流程:
步骤 描述 说明 1. 查询分发(Q) 查询被发送到集群中所有相关的节点 每个节点收到相同的 SQL 查询语句 2. 本地执行(E(Q)) 每个节点只在自己的本地数据上执行查询 无需跨节点拉取数据 3. 结果汇总(R) 所有节点执行完后,结果被发送回客户端节点进行汇总 客户端节点负责最终结果合并 举个例子:
假设你有两个表:
- Customer(客户表):按
customer_id分区 - Order(订单表):也按
customer_id分区
你执行如下查询:
SELECT * FROM Customer c JOIN Order o ON c.id = o.customer_id WHERE c.region = 'US'- Ignite 会把这条查询发送到所有节点。
- 每个节点只处理自己本地的
Customer和Order数据(因为它们按customer_id共置)。 - 每个节点返回本地匹配的结果。
- 客户端节点把所有结果合并后返回给用户。
总结
概念 含义 Colocated Join JOIN 的字段是分区字段,数据在同一个节点上 Q(Query) 查询语句被发送到所有相关节点 E(Q)(Execution of Query) 每个节点在本地执行查询 R(Result) 结果被汇总到客户端节点 - Customer(客户表):按
-
-
Non-Colocated Join(非共置连接):
-
如果 JOIN 的列不是分区列,那么两个表的数据可能分布在不同的节点上。
-
这时就需要从其他节点 拉取数据,效率较低。
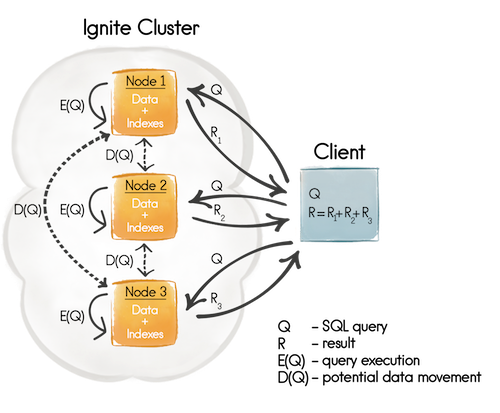
这段话讲的是 非共置连接(Non-Colocated Join) 在 Apache Ignite 这样的分布式数据库中是如何执行的,以及为什么它效率较低。我们可以逐步理解它的含义:执行过程详解
✅ 第一步:SQL 引擎在每个节点上执行查询
- 每个节点执行查询时,只处理自己本地的数据。
- 比如,节点 A 有部分
Table A的数据,但它没有对应的Table B数据。
❌ 第二步:节点发现缺少数据,需要从其他节点获取
- 如果 JOIN 的字段是 主键或亲和键,节点知道去哪个节点取数据 → unicast(单播)
- 否则,不知道去哪个节点取数据 → broadcast(广播)
📦 第三步:批量请求优化
- 为了避免频繁的网络请求,Ignite 会把多个请求 打包成一批发送,减少网络开销。
📌 举个例子说明
假设你有两个表:
- Customer(客户表),按
customer_id分区。 - Order(订单表),按
order_id分区(不是customer_id)。
现在你执行:
SELECT * FROM Customer c JOIN Order o ON c.id = o.customer_id- 因为
Order是按order_id分区的,不是按customer_id,所以两个表不是共置的。 - Ignite 无法在本地完成 JOIN,需要从其他节点获取
Order表中对应的数据。 - 如果
customer_id是主键或亲和键,节点知道去哪个节点取数据(unicast)。 - 否则,只能广播请求,效率低。
📊 对比:Colocated vs Non-Colocated Join
特性 Colocated Join Non-Colocated Join JOIN 字段 分区字段(affinity key) 不是分区字段 数据位置 相同 JOIN 键的数据在同一个节点 数据可能在不同节点 执行方式 每个节点只处理本地数据 每个节点需要远程获取数据 网络开销 小(只有最终结果汇总) 大(需要远程拉取数据) 是否需要设置 不需要 必须设置 setDistributedJoins(true)性能 ✅ 高效 ❌ 低效 最佳实践建议
-
尽量使用 Colocated Join
- 设计表结构时,确保要 JOIN 的字段是分区字段(affinity key)。
- 例如:
Customer(customer_id)和Order(customer_id)都按customer_id分区。
-
非共置 JOIN 时要显式启用
SqlFieldsQuery query = new SqlFieldsQuery("SELECT ..."); query.setDistributedJoins(true); // 启用分布式 JOIN -
避免 Broadcast JOIN
- Broadcast 会增加网络负载,降低性能。
- 如果 JOIN 的字段不是主键或亲和键,尽量避免。
-
批量请求优化
- Ignite 会自动将请求打包发送,但仍应尽量减少不必要的跨节点访问。
-
三、为什么 Colocated Join 更高效?
原文:
Colocated joins are more efficient because they can be effectively distributed between the cluster nodes.
解释:
- 因为数据在同一个节点上,JOIN 操作可以 在每个节点上独立完成,不需要跨网络传输大量数据。
- 这样减少了网络开销,提高了性能。
四、Ignite 默认如何处理 JOIN?
原文:
By default, Ignite treats each join query as if it is a colocated join and executes it accordingly (see the corresponding section below).
解释:
- Ignite 默认假设你执行的是 Colocated Join。
- 如果不是,可能会导致 查询结果不正确,因为 Ignite 可能只在本地节点查找数据。
五、如何处理 Non-Colocated Join?
原文:
If your query is non-colocated, you have to enable the non-colocated mode of query execution by setting SqlFieldsQuery.setDistributedJoins(true); otherwise, the results of the query execution may be incorrect.
解释:
- 如果你执行的是 Non-Colocated Join,必须手动启用分布式连接模式:
SqlFieldsQuery query = new SqlFieldsQuery("SELECT ..."); query.setDistributedJoins(true); // 启用非共置连接模式 - 启用后,Ignite 会将查询发送到所有相关节点,并合并结果,虽然效率较低,但保证结果正确。
六、建议
原文:
If you often join tables, we recommend that you partition your tables on the same column (on which you join the tables). Non-colocated joins should be reserved for cases when it’s impossible to use colocated joins.
解释:
- 如果你经常需要做 JOIN 操作,建议将这些表按照 JOIN 的列进行分区(即使用相同的 affinity key)。
- 这样可以尽量使用高效的 Colocated Join。
- 只有在无法使用 Colocated Join 的情况下,才使用 Non-Colocated Join。
总结
| 概念 | 含义 | 是否高效 | 是否需要特殊设置 |
|---|---|---|---|
| Colocated Join | JOIN 的列是分区列,数据在同一节点 | ✅ 高效 | ❌ 不需要设置 |
| Non-Colocated Join | JOIN 的列不是分区列,数据可能在不同节点 | ❌ 效率低 | ✅ 必须设置 setDistributedJoins(true) |
如果你有具体的 SQL 示例或者使用场景,我也可以帮你分析是否是 Colocated Join 或者如何优化 JOIN 性能。