MVSNet系列网络概述
目录
R-MVSNet
传统算法Plane Sweeping介绍
MVSNet论文解读
基于MVS的三维重建基础理论
MVS 重建算法流程
调整学习率的方法
R-MVSNet
MVSNet(ECCV2018)论文的改进
➢3D卷积换成GRU的时序网络来降低模 型大小
➢Loss改成了多分类的交叉熵损失
https://link.zhihu.com/?target=https%3A//github.com/YoYo000/MVSNet
GRU
➢GRU(Gate Recurrent Unit)是循环神经网络 (Recurrent Neural Network, RNN)的一种;
➢为了解决长期记忆和反向传播中的梯度等问题 而提出的;
➢使用同一个门控Z就同时可以进行遗忘和选择 记忆
参考链接:https://zhuanlan.zhihu.com/p/32481747
https://zhuanlan.zhihu.com/p/30844905
PointMVSNet
➢coarse-to-fine结构
➢预测一个粗糙的深度图,转成点云 进行优化depth
➢ PointFlow模块使用特征增强点云进 行深度残差预测
https://link.zhihu.com/?target=https%3A//github.com/callmeray/PointMVSNet
Fast-MVSNet
➢sparse-to-dense 和coarse-to-fine结构
➢采用稀疏的cost volume得到稀疏深度 图
➢Gauss-Newton layer对深度图进行优 化
➢速度快
https://github.com/svip-lab/FastMVSNet
P-MVSNet
➢采用Patch-Wise进行代价聚合提高匹配
精度
➢Hybrid 3D U-Net infer出高精度深度图
CVP-MVSNet
➢cost volume pyramid in a coarse-to-fine
➢目前是精度最高的网络,缺点速度慢, 计算昂贵
传统算法Plane Sweeping介绍
平面扫面算法将深度范围内分为一个个平面,深度范围可以由很多方法获得。如果平行平面足够密
集,空间被分割的足够细,那么,空间物体表面上的一点M一定位于众多平行平面中的其中一个平
面上。判断曲面上一点在哪个平面上的方法:所有可以看到曲面上的M的相机看到的是同一个颜
色,也就是物体在点M本来的颜色
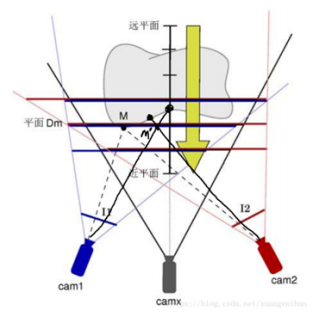
算法步骤:
深度图初始化
根据深度范围( dmin,dmax),等间隔初始化m层深度;
匹配代价计算
计算每个像素点在不同深度层的匹配代价(判断当前深度是否在曲面上) 左图的像素坐标 在当前深度下可以根据单应性矩阵H得到在右图的匹配点 如果当前深度对应在真实曲面上那么 与 对应的拍摄到的物体是一样的,可以通 过一些方法来计算它们的匹配度也就是我们说的匹配代价。
常用匹配代价:NCC,Census, ...
例如:Census变换:
1.使用像素邻域内的局部灰度差异将像素灰度转换为比特串即为census值
2.基于Census变换的匹配代价计算方法是计算左右影像对应的两个像素的Census变换值
的汉明(Hamming)距离(两个比特串的对应位不相同的数量:先进行异或运算,再统
计运算结果中1的个数)
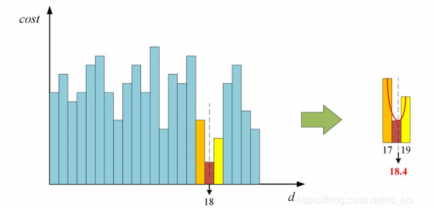
代价聚合
由于代价计算步骤只考虑了局部的相关性,对噪声非常敏感,无法直接用来计算最优视差,
通过该步骤,使聚合后的代价值能够更准确的反应像素之间的相关性。常用算法:SGM
深度图计算
根据匹配代价,从深度层中选择代价最小的层对应的深度即是计算的最佳深度
MVSNet论文解读
摘要
a.端到端的利用多帧图像来计算深度图
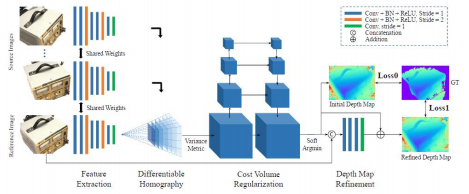
b.算法步骤:
提取图像特征
基于相机视锥体空间构建3D代价体,通过可微的单应矩阵warping
使用3D卷积正则化并回归出初始深度图
用参考图优化初始深度图得到最终的深度图
c.通过使用基于方差的代价指标将多个特征体映射为一个代价体,从而支持任意N个图像输入
特征提取
网络:使用8层2D卷积神经网络,其第 3 层、第 6 层的卷积步长设为 2(每次图像分辨率会减
少一半),特征提取网络的参数共享权重。输入是N张图像,输出是分辨率是原图的1/4,通
道是32的N张特征图。
虽然特征图经过了下采样, 但被保留下来像素的邻域信息已经被编码保存至 32 通道的特征描
述子中(即虽然特征图缩小了,但是每个特征图像素包含了原始像素周围的信息,因此在最终
的细化过程中不会丢失细节信息)。 与在原始图像上进行特征匹配对比, 使用提取的特征图
进行匹配显著提高了重建质量。
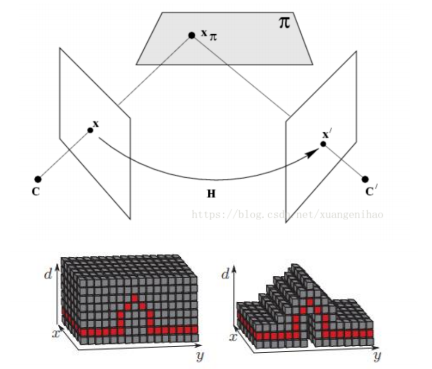
3D代价体的构建
可微分单应性矩阵将source图像的feature通过可微的单应性矩阵H,warp到参考图像相机前的这些平行平
面上,这一步的转换根据如下的单应矩阵进行计算。利用2D的feature生成3D的Feature
Volume。就是他把其他图像上的feature warp到参考图像的相机视锥中的256个深度平
面上。单应性矩阵通常描述处于同一平面的一些点在两张图像的转换关系,单应性矩阵
计算如下
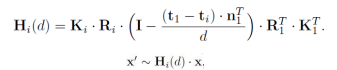
从上述warp得到N个feature volume合并成一个cost volume,作者采用的是基于方差的操
作,逐像素地求cost volume。这步操作使得可以输入任意N张图像
传统算法中,聚合的匹配代价是将所有source图像与reference图像匹配。作者的这个是让每
张图像都平等参与匹配代价计算,不会偏向reference图像。
代价体正则化
使用多尺度的3D CNN来正则化cost volume。论文中是使用一个四级的类似3D 版本的
U-Net结构。经过正则化后,通道数由32降到1。得到的probability volume其实就是在
每个像素下,每个深度的可能性大小。它不仅可以用于每像素深度的估计,而且可以用
于测量估计的深度值的可信度。
深度图计算
由上面得到了像素在每个深度层的概率,传统算法中会采用选取概率最大的深度值作为最终的
深度,但本网络中计算深度的数学期望作为初始深度图D的结果:
深度图优化
由于得到的初始深度图在物体边缘还是不够精细,使用rgb图像作为一个引导来优化深度图。这里
是将深度图与原始图像串连成一个四通道的输入,经过神经网络得到深度残差,然后加到之前的深
度图上从而得到最终的深度图。注意,优化前要把深度图归一化到[0,1],优化后再转换回来。
loss计算
两部分,初始深度图和refine后的深度图与真值的L1值:
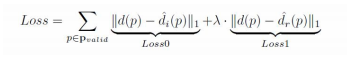
基于MVS的三维重建基础理论
三维信息表示方式
深度图(depth)/视差图(disparity)
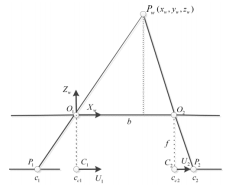
a.深度图:场景中每个点到相机的距离
视差图:同一个场景在两个相机下成像的像素的位置偏差dis
b.两者关系:depth=bf/dis
c. 是三维信息的常用表示方式
三维点云(pointcloud)
a.三维点云是某个坐标系下的点的数据集
b.包含了丰富的信息,包括三维坐标XYZ、颜色RGB等信息
三维网格(mesh)
a.由物体的邻接点云构成的多边形组成的
b.通常由三角形、四边形或者其它的简单凸多边形组成
纹理贴图模型(textured mesh)
a.带有颜色信息的三维网格模型
b.所有的颜色信息存储在一张纹理图上,显示时根据
每个网格的纹理坐标和对应的纹理图进行渲染得到
高分辨率的彩色模型
MVS 重建算法流程
常用的两大重建算法:Plane Sweeping和PatchMatch
MVS三维重建的核心就是立体匹配,通过两幅图像的对应点的匹配关系可以根据三角测量关系得到
深度信息实现三维几何的重建,流程如下:
深度图初始化
匹配代价计算(光度一致性测量)
匹配代价聚合
深度图计算
深度图优化,滤波等后处理
调整学习率的方法
在模型训练的优化部分,调整最多的一个参数就是学习率,合理的学习率可以使优化器快速收敛。
一般在训练初期给予较大的学习率,随着训练的进行,学习率逐渐减小。
等间隔调整学习率
#step_size epoch间隔大小,比如10 在10 20 ..会调整学习率,调整率是gamma
#last_epoch是指上一个epoch
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1,
last_epoch=-1)按设定的间隔调整学习率
#milestones(list)-一个list,每一个元素代表何时调整学习率,list元素必须是递增的,
#调整率是gamma
#last_epoch是指上一个epoch
class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1,
last_epoch=-1按指数衰减调整学习率,调整公式: lr = lr * gamma**epoch
#last_epoch是指上一个epoch
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)以余弦函数为周期,并在每个周期最大值时重新设置学习率
#last_epoch是指上一个epoch
#T_max(int)- 一次学习率周期的迭代次数,即T_max个epoch之后重新设置学习率。
#eta_min(float)- 最小学习率,即在一个周期中,学习率最小会下降到eta_min,默认值为0
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0,
last_epoch=-1)当某指标不再变化(下降或升高),调整学习率
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min',
factor=0.1, patience=10, verbose=False, threshold=0.0001,
threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
#参数
mode(str)- 模式选择,有 min和max两种模式,min表示当指标不再降低(如监测loss),max表示当
指标不再升高(如监测accuracy)。
factor(float)- 学习率调整倍数(等同于其它方法的gamma),即学习率更新为 lr = lr *
factor patience(int)- 直译——"耐心",即忍受该指标多少个step不变化,当忍无可忍时,调整学
习率。注,可以不是连续5次。
verbose(bool)- 是否打印学习率信息, print('Epoch {:5d}: reducing learning rate'
' of group {} to {:.4e}.'.format(epoch, i, new_lr))
threshold(float)- Threshold for measuring the new optimum,配合threshold_mode
使用,默认值1e-4。作用是用来控制当前指标与best指标的差异。
cooldown(int)- “冷却时间“,当调整学习率之后,让学习率调整策略冷静一下,让模型再训练一段
时间,再重启监测模式。
min_lr(float or list)- 学习率下限,可为float,或者list,当有多个参数组时,可用list进
行设置。
eps(float)- 学习率衰减的最小值,当学习率变化小于eps时,则不调整学习率为不同参数组设定不同学习率调整策略。调整规则为,lr = base_lr * lmbda(self.last_epoch)
#last_epoch是指上一个epoch
#lr_lambda(function or list)-一个计算学习率调整倍数的函数,输入通常为step,当有多个参
数组时,设为list。
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)