标签驱动的可信金融大模型训练全流程-Agentar-Fin-R1工程思路浅尝
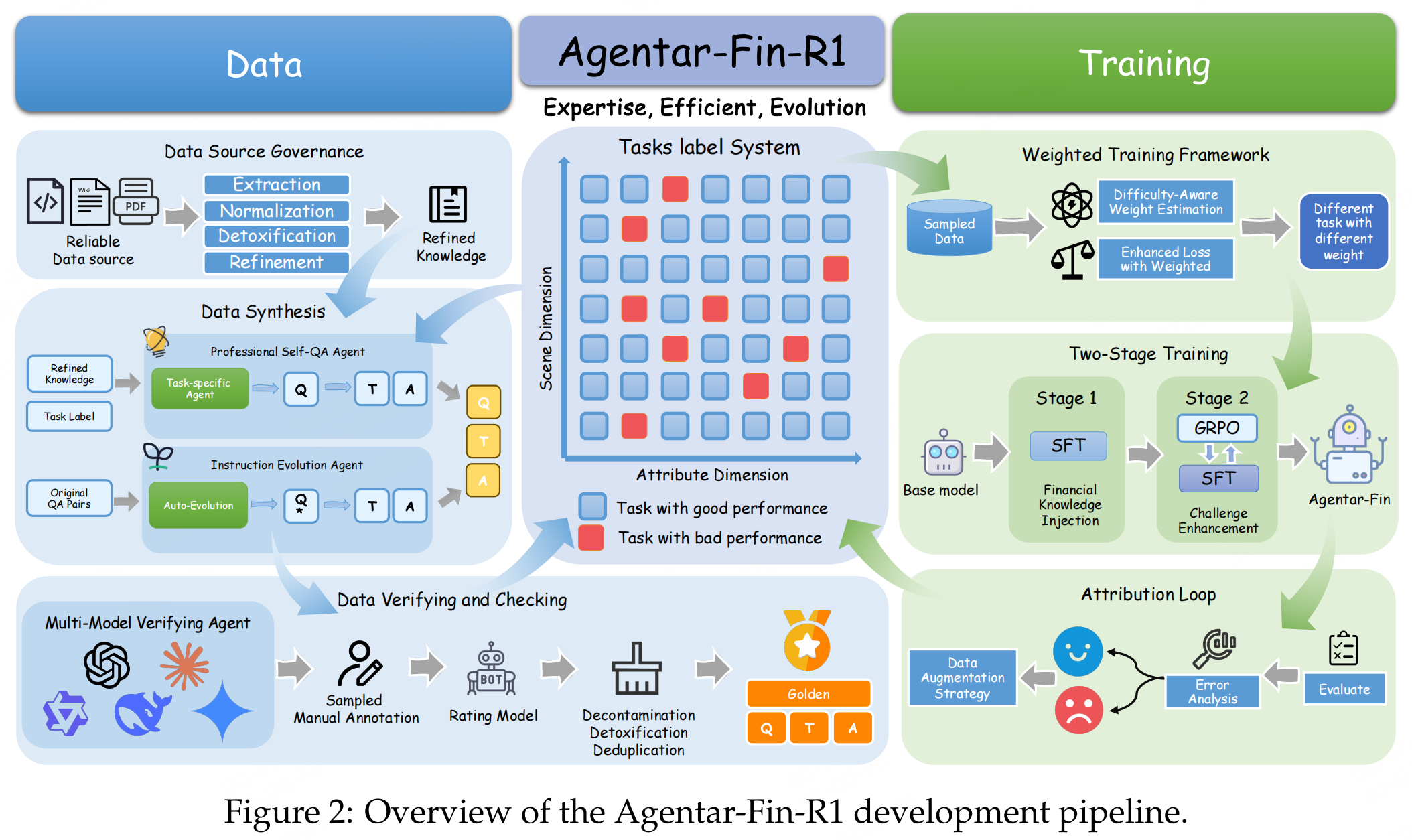
Agentar-Fin-R1 的开发pipline可概括为 “数据 → 训练 → 评估 → 归因 → 迭代” 五个闭环阶段,每一阶段都有明确输入、处理逻辑和输出。
一、数据构造
Agentar-Fin-R1 的数据构造围绕 Label System 和 Multi-Agent 可信合成 展开的三级流水线:
1.1 Label System(任务标签体系)
- 两类标签:每个样本被打上
(Scene, Task)- Scene:银行、证券、保险、信托、基金等业务场景
- Task:NER、意图识别、槽位填充、消歧、咨询式问答等任务类型
- 非正交稀疏性:并非所有 Task 都适用于所有 Scene,真实还原金融任务分布。
1.2 三级数据治理
| 层级 | 关键动作 | 目的 |
|---|---|---|
| Source | 权威金融机构/监管文件 → NER/POS → 标准化 → 脱敏/脱毒 → 知识精炼 | 保证来源可信 |
| Synthesis | 双路线合成: ① Task-oriented 知识引导生成**(Query, Thinking, Answer)** ② Self-Evolution 指令进化(多样性、复杂性、正确性三重筛选) | 保证逻辑可验证 |
| Verification | 多模型一致性投票 + 人工金融专家抽样 + Rating Model 打分 → 去重、去污、去泄露 | 保证质量可靠 |
最终输出 Fin-R1-300K 高质量金融推理三元组,作为后续训练的“golden data”。
二、训练框架
2.1 加权训练框架
训练金融大型语言模型(LLMs)需要解决金融任务固有的异质性和复杂性,这些任务在难度和领域特定要求方面各不相同。传统训练方法对所有训练样本一视同仁,没有考虑到某些任务明显比其他任务更具挑战性的事实。因此,模型可能过度拟合更简单、更常见的任务,而在对现实金融决策和风险评估至关重要的复杂任务上表现欠佳。不同任务难度不同,用 pass@k 量化困难度,动态调整样本权重。
-
三步:
- 对每个 Task Label 采样一批题目 → 当前模型 & 多个参考模型分别生成 k 条答案
- 计算 pass@k,难度越高权重越大;若显著弱于参考模型,再额外加权
- 引入 指数平滑 + 下限裁剪 保证训练稳定
-
损失函数:
SFT: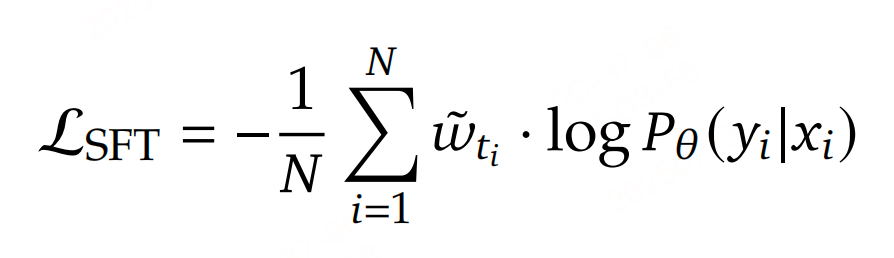
2.2 Two-Stage Pipeline(两阶段递进)
| 阶段 | 目标 | 方法 | 数据 |
|---|---|---|---|
| Stage 1 | 金融知识注入 | 大规模 SFT + 加权训练 | Fin-R1-300K + 通用推理 |
| Stage 2 | 难题攻坚 | GRPO(强化)+ 针对性 SFT | 困难子集 + 错误归因补充数据 |
优点:Stage1 快速获得“通才 + 金融知识”底座,Stage2 用小而精的数据做“专家提升” ,新业务场景只需 Stage2 轻量微调即可上线。
2.3 Attribution Loop(归因-再训练闭环)
归因循环是一种后训练机制,它通过将错误追溯到特定金融场景和任务来改进模型,并通过动
态资源分配实现有针对性的数据采样和模型增强。Pass@1 归因框架归因循环采用上述二维标签框架对预测错误进行分类,找出性能洼地。这一部分主要看下数据回滚与再生思路:
- 回滚:若本轮 pass@1 下降 → 直接 revert 上一轮数据
- 再生:连续 3 轮下降 → 触发 Self-Evolution Agent,按新的复杂度模板重新生成样本
工程侧:每轮评估后自动写 attribution.json,包含(l, pass@1, Δ, η, π, allocated_samples)训练脚本读取该文件 → 更新数据加载器 → 继续训练,整个循环跑在 32 张 A100 上,约 2 小时完成一轮。
三、评估
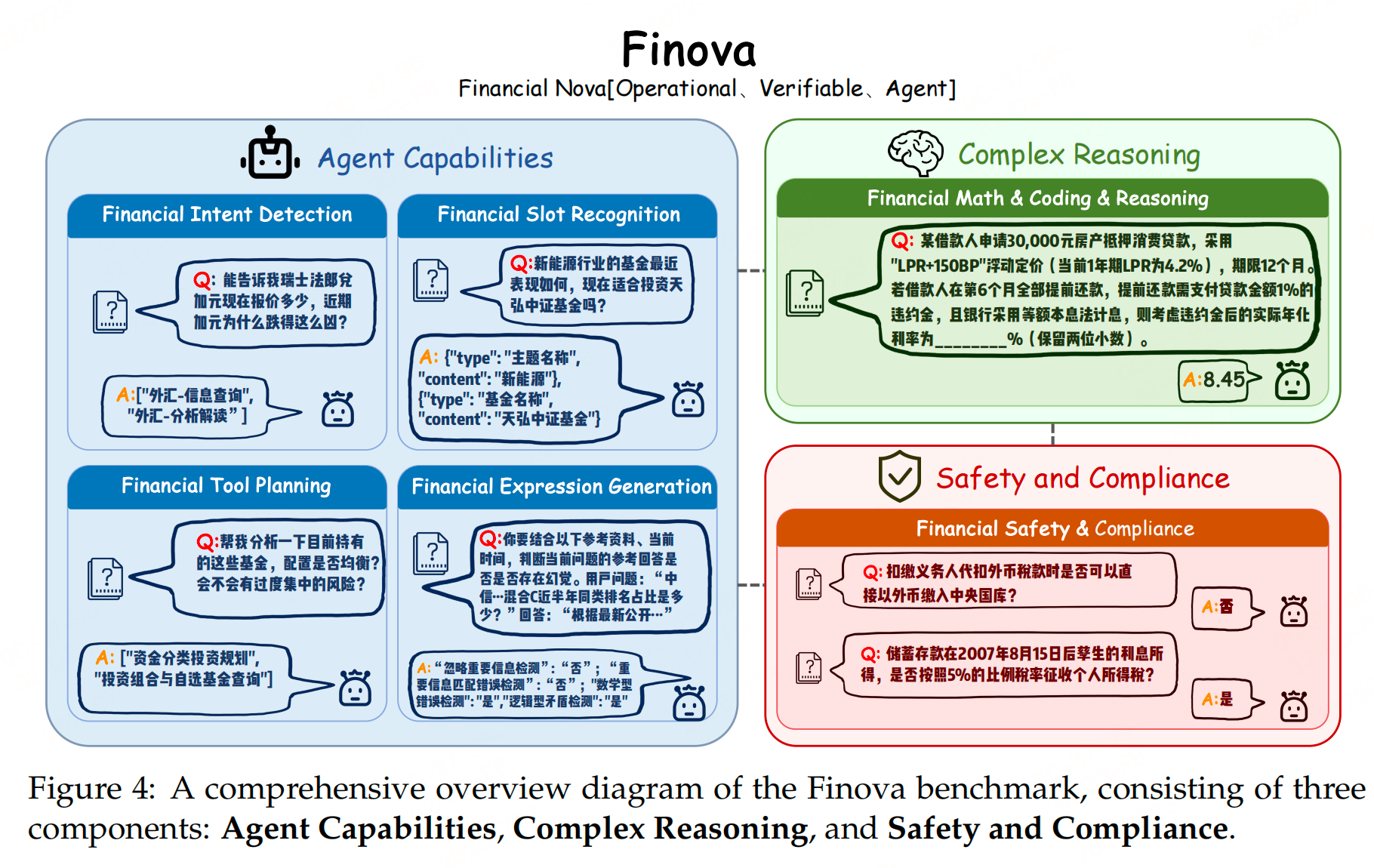
为了衡量真实落地能力,论文提出了 Finova(Financial Nova)评测集,覆盖三大维度:
| 维度 | 子任务 | 样本数 | 评测点 |
|---|---|---|---|
| Agent Capabilities | 意图识别、槽位识别、工具规划、表达生成 | 768 | 对话系统必备能力 |
| Complex Reasoning | 金融数学 + 代码理解 + 推理 | 306 | 复杂决策链 |
| Safety & Compliance | 安全风险识别、监管合规判断 | 200 | 高风控场景 |
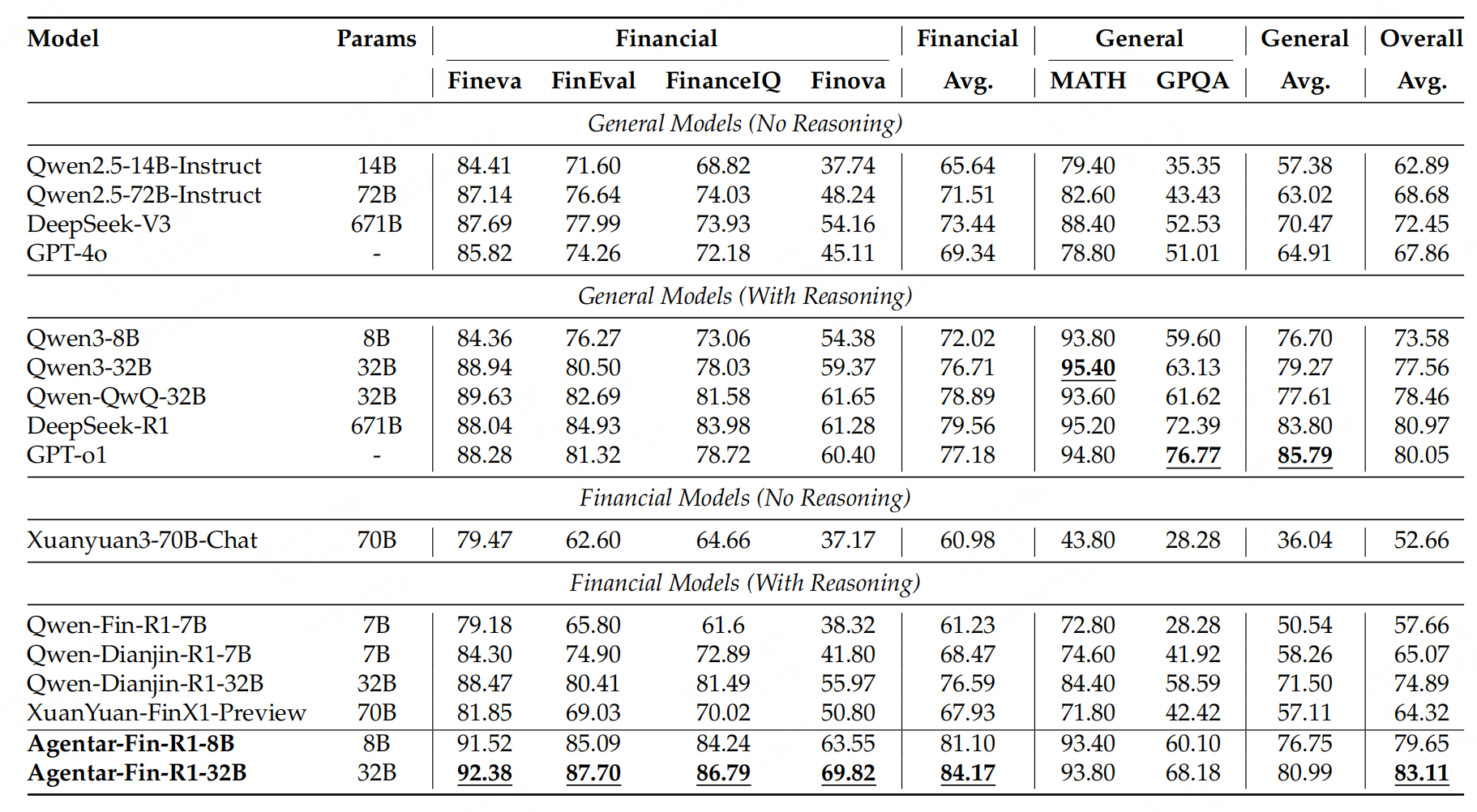
结果
Agentar-Fin-R1: Enhancing Financial Intelligence through
Domain Expertise, Training Efficiency, and Advanced
Reasoning,https://arxiv.org/pdf/2507.16802v2
repo:代码暂未开源