【论文阅读 | TIV 2024 | CDC-YOLOFusion:利用跨尺度动态卷积融合实现可见光-红外目标检测】
论文阅读 | TIV 2024 | CDC-YOLOFusion:利用跨尺度动态卷积融合实现可见光-红外目标检测
- 1&&2. 摘要&&引言
- 3. 方法
- A. 架构概述
- B. 跨模态数据交换
- C. 跨尺度动态卷积融合
- 跨尺度特征增强模块
- 双动态卷积融合模块
- D. 跨模态核交互损失
- 4. 实验
- A. 数据集
- B. 设置
- C. 实验结果
- D. 与最先进方法的比较
- 5. 结论

题目:CDC-YOLOFusion: Leveraging Cross-scale Dynamic Convolution Fusion for Visible-Infrared Object Detection
期刊:IEEE Transactions on Intelligent Vehicles (TIV)
论文:paper
代码:code
年份:2024
1&&2. 摘要&&引言
由于能够深入挖掘可见光和红外特征,特征级融合方法在可见光 - 红外目标检测中表现出优异的性能。然而,大多数现有的特征级融合方法利用多个具有固定参数的卷积层来提取双模态特征,导致对多样化数据分布的适应性较低。
本文提出了一种基于跨尺度动态卷积的 YOLO 融合(CDC-YOLOFusion)网络,该网络引入了一种新颖的跨尺度动态卷积融合(CDCF)模块,以自适应地提取和融合与数据分布相关的双模态特征。
从技术上讲,CDC-YOLOFusion 首先设计了一种新颖的数据增强策略 “跨模态数据交换(CDS)”,用于在可见光和红外图像之间交换局部区域,有效捕捉局部区域内的跨模态相关性。在此基础上,所提出的 CDCF 通过引入差异注意力掩码,利用跨尺度增强特征辅助动态卷积预测,重点提取两种模态之间的差异特征。
我们的 CDCF 在一种新颖的跨模态核交互损失的有效引导下,旨在让学习到的核同时关注每种模态的共同显著特征和独特特征,以生成全面的特征。在三个具有代表性的检测数据集上进行的大量实验表明,CDCF 可以轻松嵌入到现有流水线中,获得一致的性能提升。
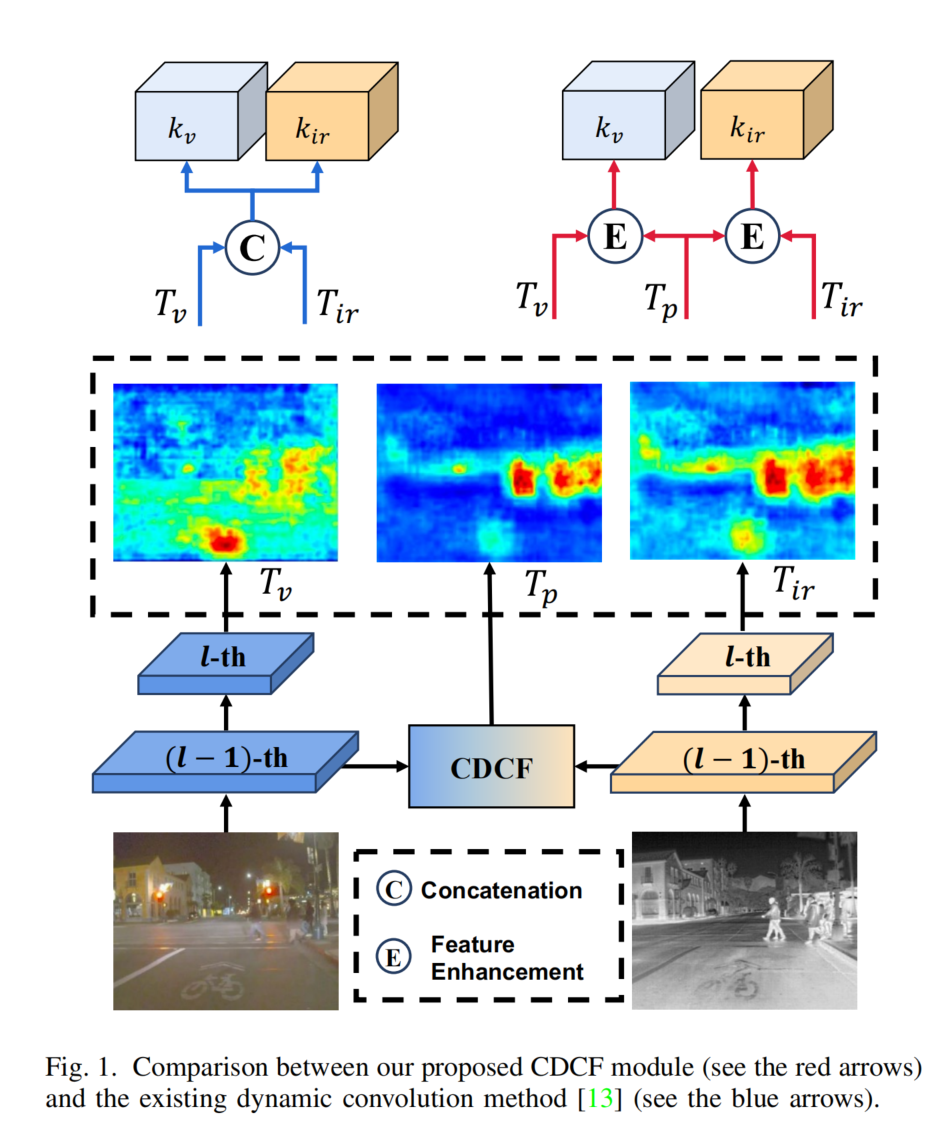
图1. 我们提出的CDCF模块(见红色箭头)与现有动态卷积方法[13](见蓝色箭头)的比较。
3. 方法
A. 架构概述
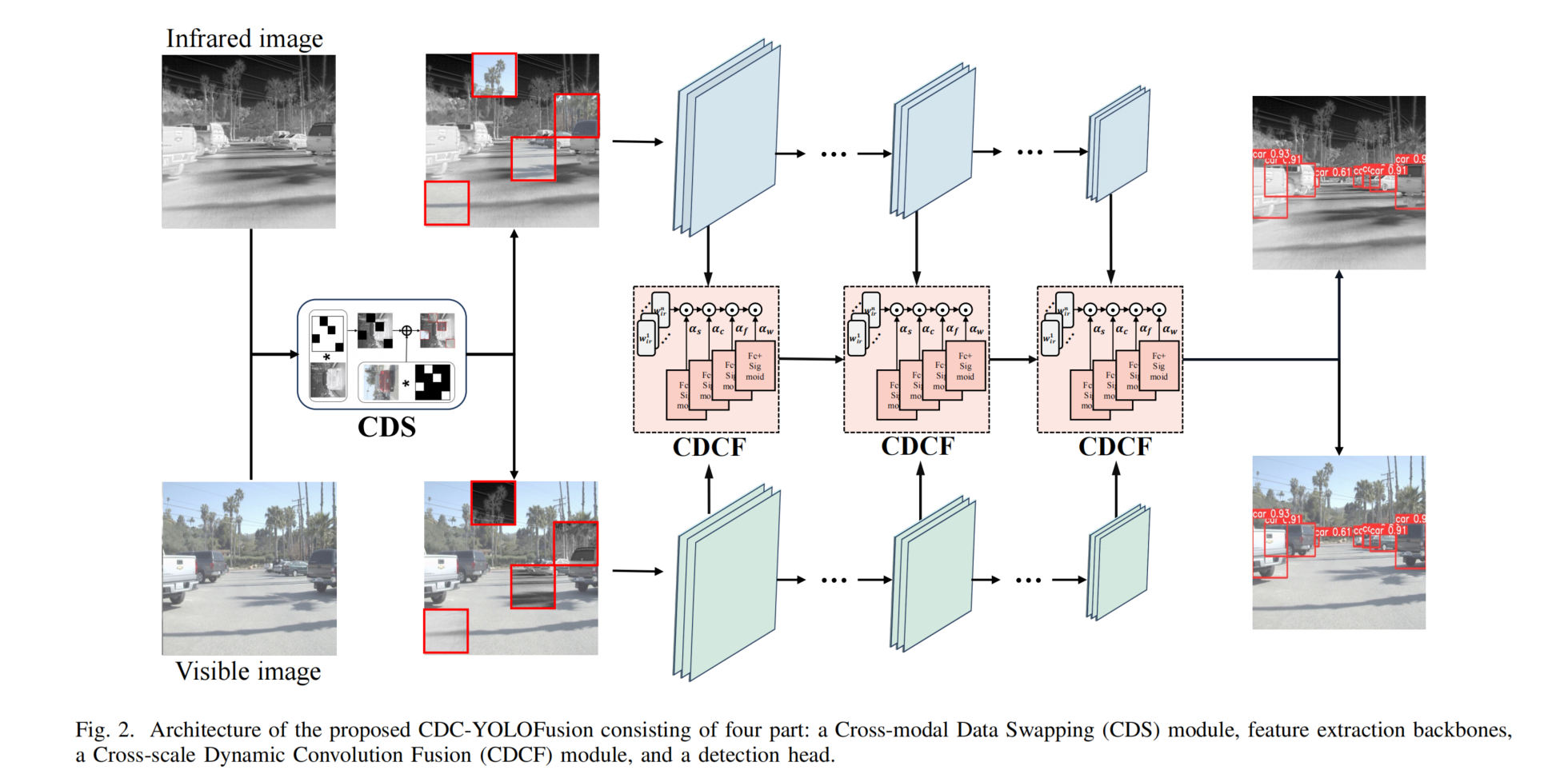
图2. 所提出的CDC-YOLOFusion的架构,由四个部分组成:跨模态数据交换(CDS)模块、特征提取骨干网络、跨尺度动态卷积融合(CDCF)模块和检测头。
传统数据增强技术多关注单模态数据,而CDS旨在提高模型对模态差异的理解,促进跨模态相关性学习。其通过将红外图像中的局部块替换为可见光图像中的对应块,生成含混合信息的图像输入特征提取分支。
图 2 展示了我们提出的 CDC-YOLOFusion 的流水线,它扩展了 YOLO v5 架构,采用双分支 CSPDarknet 骨干网络分别提取多尺度的可见光和红外特征。值得注意的是,我们引入了两个新颖的组件来提高检测性能:首先,我们引入了跨模态数据交换(CDS)模块用于预处理输入图像。CDS 促进有效的双模态数据交换和信息互补,产生混合的双模态数据,鼓励模型更好地探索跨模态特征。其次,我们引入了跨尺度动态卷积融合(CDCF)模块来促进多尺度双模态特征融合。与传统的卷积操作不同,CDCF 采用从输入数据中自适应学习的动态卷积核来捕捉更有价值的信息。此外,我们设计了一种新颖的 “跨模态核交互” 损失,通过利用双模态核的固有特征分布来引导双模态核的学习,从而生成用于稳健特征提取的信息核。
B. 跨模态数据交换
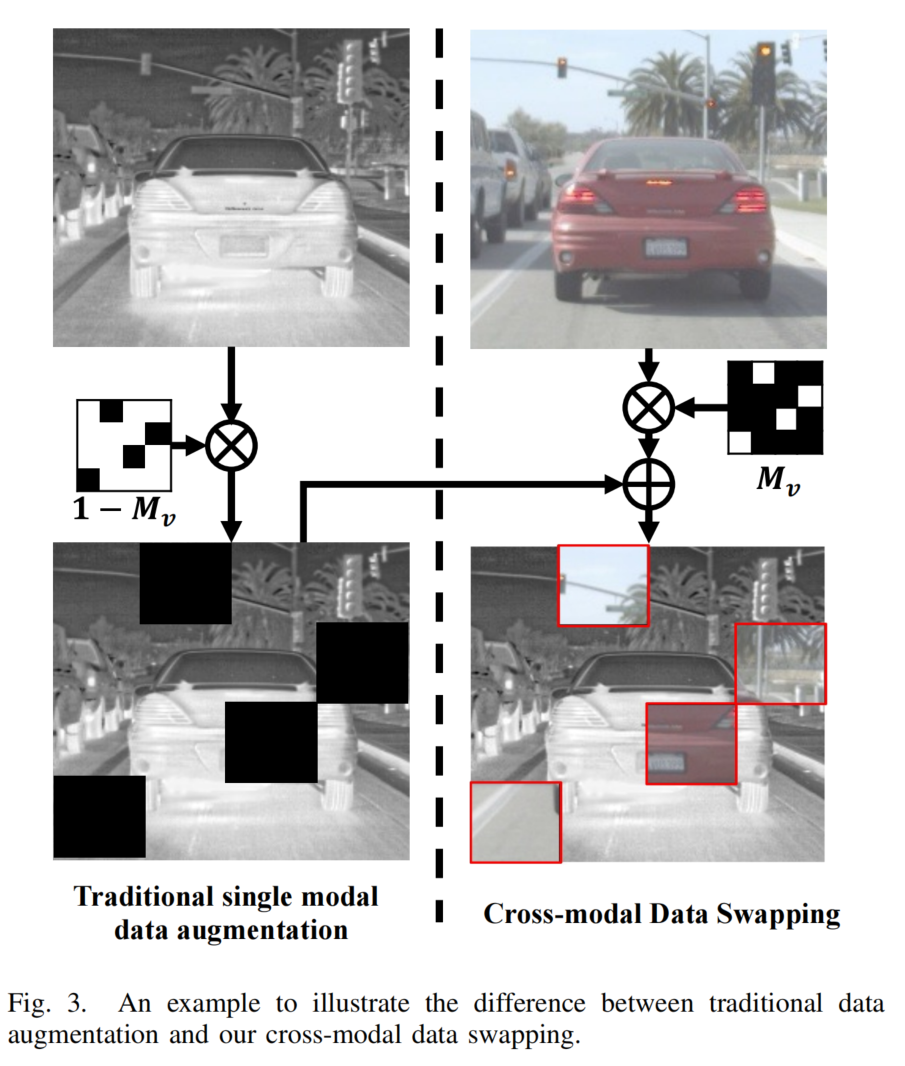
图3. 一个示例,用于说明传统数据增强与我们的跨模态数据交换之间的差异。
传统的数据增强技术,如裁剪(如图 3 所示),广泛应用于目标检测任务,有助于丰富训练数据集并增强模型的泛化能力。然而,现有的增强方法主要关注单模态数据,忽略了对跨模态增强技术的探索。相反,深入研究跨模态增强策略有望有效揭示不同模态之间的相关性,从而为特征提取网络提取稳健特征提供更好的指导。出于这一目的,我们引入了跨模态数据交换(CDS),旨在提高模型对模态差异的理解,并促进跨模态相关性的学习。图 3 展示了一个示例来说明 CDS 的效果,其中红外图像中的一个局部块被可见光图像中的对应块替换,从而生成一个混合信息的红外图像,随后将其输入到相应的特征提取分支以探索跨模态特征提取。
具体来说,给定一对高度为 H、宽度为 W 的可见光 - 红外图像IvI_{v}Iv、Iir∈RH×WI_{ir} \in \mathbb{R}^{H \times W}Iir∈RH×W,我们首先为它们分别构建两个交换掩码MvM_{v}Mv、Mir∈RH×WM_{ir} \in \mathbb{R}^{H \times W}Mir∈RH×W,其中两个掩码中的每个初始元素都设置为 0。接下来,我们将每个掩码划分为N×NN \times NN×N个局部区域,并随机选择 N 个区域作为交换候选,将交换候选中的元素重置为 1。因此,它生成两个交换掩码来指导跨模态数据交换,实现方式如下(见图 3):
Imswap=Im⊙Mm+Im‾⊙(1−Mm)(1)I_{m}^{swap}=I_{m} \odot M_{m}+I_{\overline{m}} \odot\left(1-M_{m}\right) \tag{1}Imswap=Im⊙Mm+Im⊙(1−Mm)(1)
其中mmm、m‾∈{v,ir}\overline{m} \in\{v, ir\}m∈{v,ir},⊙\odot⊙表示元素级乘法,ImswapI_{m}^{swap}Imswap表示通过 CDS 生成的图像。CDS 执行跨模态部分数据交换,生成同时包含两种模态信息的混合图像。因此,与通过破坏单模态数据进行的传统裁剪和马赛克数据增强操作相比,CDS 提供了更丰富的训练数据,同时有效保留了多模态图像的统一高级语义。它能够巧妙地捕捉局部区域内的跨模态相关性,促进更丰富的跨模态互补细节的吸收。这反过来又增强了网络在训练过程中的鲁棒性。
C. 跨尺度动态卷积融合
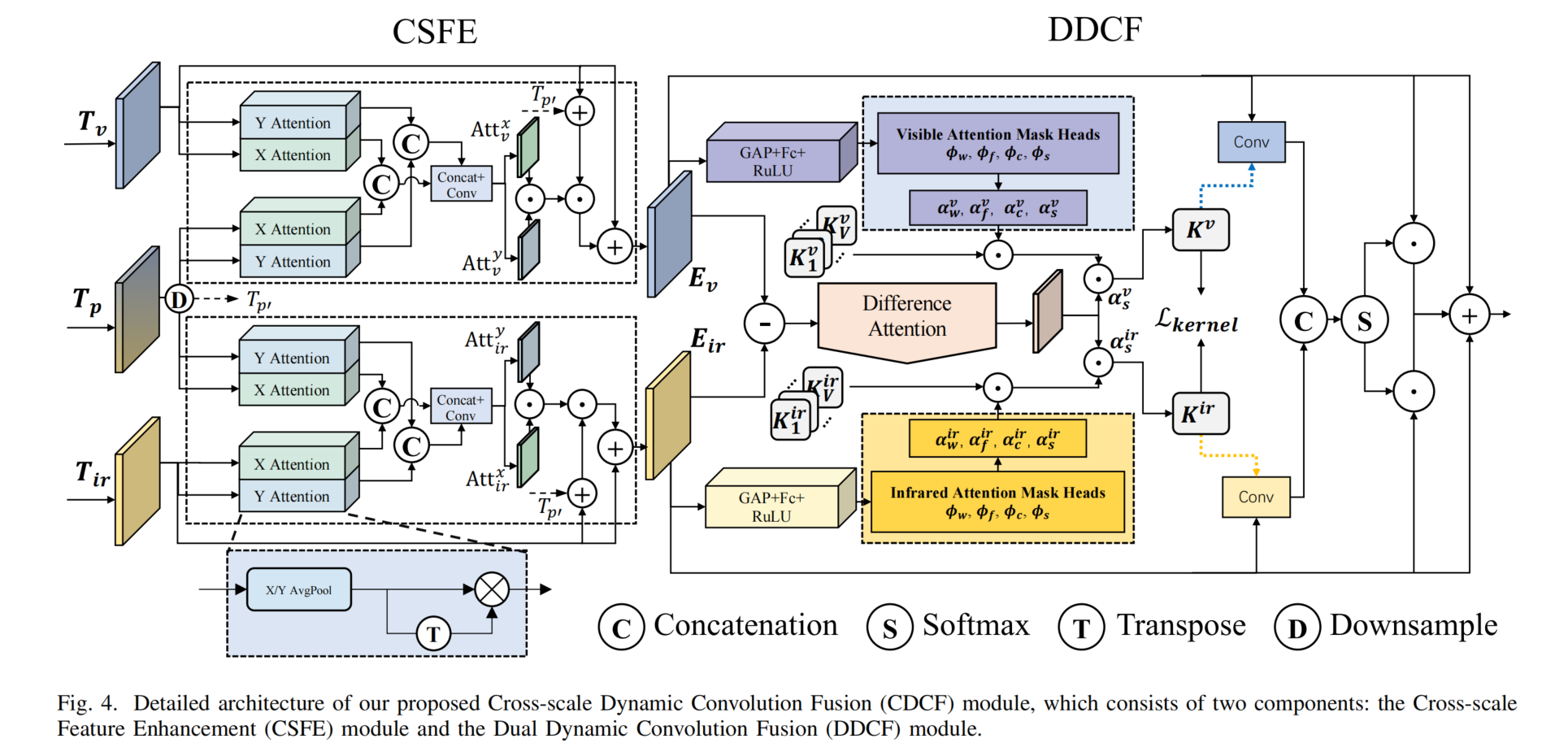
图4. 我们提出的跨尺度动态卷积融合(CDCF)模块的详细架构,该模块由两个组件组成:跨尺度特征增强(CSFE)模块和双动态卷积融合(DDCF)模块。
我们引入了跨尺度动态卷积融合(CDCF)模块,该模块通过利用每种模态数据的固有特征,独立学习适用于该模态数据的自适应核。图 4 展示了我们提出的 CDCF 模块的架构,它包括两个主要组件:跨尺度特征增强(CSFE)模块和双动态卷积融合(DDCF)模块。
跨尺度特征增强模块
我们的方法没有直接拼接双模态特征 [13],而是引入了跨尺度特征增强(CSFE)模块来生成增强的可见光和红外特征,用于预测动态卷积核。如图 4 所示,当给定第 l 层的一对可见光和红外特征TvT_{v}Tv、Tir∈RH×W×CT_{ir} \in \mathbb{R}^{H \times W \times C}Tir∈RH×W×C,以及 CDCF 生成的第 (l-1) 层的融合特征Tp∈R2H×2W×C/2T_{p} \in \mathbb{R}^{2H \times 2W \times C/2}Tp∈R2H×2W×C/2时,CSFE 首先使用 3×3 卷积核对TpT_{p}Tp进行下采样,以获得调整大小的融合特征Tp′∈RH×W×CT_{p'} \in \mathbb{R}^{H \times W \times C}Tp′∈RH×W×C。由于TpT_{p}Tp带来了更大尺度特征图提供的更丰富的特征,有助于通过跨尺度特征融合来指导当前层特征的增强。然后,受 [48] 的启发,我们分别对TvT_{v}Tv、TirT_{ir}Tir和Tp′T_{p'}Tp′采用 X 注意力和 Y 注意力机制。理论上,X/Y 注意力旨在探索高度 / 宽度与通道之间的复杂相关性,包括沿高度 / 宽度方向计算特征平均值,公式如下:
Ttx=1H∑0≤i<HTt(i,w)Tty=1W∑0≤j<WTt(h,j)(2)\begin{aligned} & T_{t}^{x}=\frac{1}{H} \sum_{0 \leq i<H} T_{t}(i, w) \\ & T_{t}^{y}=\frac{1}{W} \sum_{0 \leq j<W} T_{t}(h, j) \end{aligned} \tag{2}Ttx=H10≤i<H∑Tt(i,w)Tty=W10≤j<W∑Tt(h,j)(2)
其中t∈{p′,ir,v}t \in\{p', ir, v\}t∈{p′,ir,v},w∈[1,W]w \in[1, W]w∈[1,W],h∈[1,H]h \in[1, H]h∈[1,H],Tt(i,j)T_{t}(i, j)Tt(i,j)表示位置[i,j][i, j][i,j]处的特征向量。因此,我们的方法为 X 注意力生成三个注意力特征图TvxT_{v}^{x}Tvx、TirxT_{ir}^{x}Tirx、Tp′x∈RH×1×CT_{p'}^{x} \in \mathbb{R}^{H \times 1 \times C}Tp′x∈RH×1×C,为 Y 注意力生成TvyT_{v}^{y}Tvy、TiryT_{ir}^{y}Tiry、Tp′y∈R1×W×CT_{p'}^{y} \in \mathbb{R}^{1 \times W \times C}Tp′y∈R1×W×C。与常用的自注意力机制 [49] 相比,CSFE 中使用的跨尺度 X/Y 注意力能够更有效地探索相对位置信息和通道注意力信息之间的复杂相关性,同时仅略微增加计算和参数开销,在高度和宽度方向上产生显著的特征图,作为预测动态卷积核的指导。
接下来,对于 X 注意力和 Y 注意力特征TtxT_{t}^{x}Ttx和TtyT_{t}^{y}Tty,我们计算其 Gram 矩阵Gtx∈RH×HG_{t}^{x} \in \mathbb{R}^{H \times H}Gtx∈RH×H和Gty∈RW×WG_{t}^{y} \in \mathbb{R}^{W \times W}Gty∈RW×W,以获得特征图内的高度 / 宽度相关信息,然后将它们分别与TtxT_{t}^{x}Ttx和TtyT_{t}^{y}Tty相乘,丰富通道与高度 / 宽度之间的关系捕捉,公式如下:
Gtx=Ttx×(Ttx)T,Gty=Tty×(Tty)TT^tx=Gtx×Ttx,T^ty=Gty×Tty(3)\begin{gathered} G_{t}^{x}=T_{t}^{x} \times\left(T_{t}^{x}\right)^{T}, G_{t}^{y}=T_{t}^{y} \times\left(T_{t}^{y}\right)^{T} \\ \hat{T}_{t}^{x}=G_{t}^{x} \times T_{t}^{x}, \hat{T}_{t}^{y}=G_{t}^{y} \times T_{t}^{y} \end{gathered} \tag{3}Gtx=Ttx×(Ttx)T,Gty=Tty×(Tty)TT^tx=Gtx×Ttx,T^ty=Gty×Tty(3)
其中t∈{p′,ir,v}t \in\{p', ir, v\}t∈{p′,ir,v},T^tx∈RH×1×C\hat{T}_{t}^{x} \in \mathbb{R}^{H \times 1 \times C}T^tx∈RH×1×C和T^ty∈R1×W×C\hat{T}_{t}^{y} \in \mathbb{R}^{1 \times W \times C}T^ty∈R1×W×C分别表示 X 和 Y 方向上的相关性增强注意力图。之后,我们利用跨尺度融合信息来增强每种模态,表示为:
T‾mx=C1([T^mx,T^p′x])T‾my=C2([T^my,T^p′y])(4)\begin{aligned} & \overline{T}_{m}^{x}=C_{1}\left(\left[\hat{T}_{m}^{x}, \hat{T}_{p'}^{x}\right]\right) \\ & \overline{T}_{m}^{y}=C_{2}\left(\left[\hat{T}_{m}^{y}, \hat{T}_{p'}^{y}\right]\right) \end{aligned} \tag{4}Tmx=C1([T^mx,T^p′x])Tmy=C2([T^my,T^p′y])(4)
其中m∈{ir,v}m \in\{ir, v\}m∈{ir,v},C1C_{1}C1和C2C_{2}C2是两个卷积层,[] 表示拼接操作。T‾mx∈RH×1×C\overline{T}_{m}^{x} \in \mathbb{R}^{H \times 1 \times C}Tmx∈RH×1×C和T‾my∈R1×W×C\overline{T}_{m}^{y} \in \mathbb{R}^{1 \times W \times C}Tmy∈R1×W×C分别是 X 和 Y 方向上的跨尺度增强单模态特征图。为了使T‾mx\overline{T}_{m}^{x}Tmx和T‾my\overline{T}_{m}^{y}Tmy能够在两个方向上拼接以进行信息交互,我们将T‾mx\overline{T}_{m}^{x}Tmx重塑为T‾mx′∈R1×H×C\overline{T}_{m}^{x'} \in \mathbb{R}^{1 \times H \times C}Tmx′∈R1×H×C。然后,我们将它们拼接以实现信息交互,获得激活的注意力图Attm∈R1×(W+H)×CAtt_{m} \in \mathbb{R}^{1 \times (W+H) \times C}Attm∈R1×(W+H)×C,表示宽度、高度和通道中的显著特征图:
Attm=[Attmx′,Attmy]=g([T‾mx′,T‾my])(5)Att_{m}=\left[Att_{m}^{x'}, Att_{m}^{y}\right]=g\left(\left[\overline{T}_{m}^{x'}, \overline{T}_{m}^{y}\right]\right) \tag{5}Attm=[Attmx′,Attmy]=g([Tmx′,Tmy])(5)
其中g()g()g()是由卷积层、批归一化层和激活函数组成的函数。Attmx′∈R1×H×CAtt_{m}^{x'} \in \mathbb{R}^{1 \times H \times C}Attmx′∈R1×H×C和Attmy∈R1×W×CAtt_{m}^{y} \in \mathbb{R}^{1 \times W \times C}Attmy∈R1×W×C表示交互后宽度、高度和通道中的新显著特征图。然后我们将Attmx′Att_{m}^{x'}Attmx′重塑为Attmx∈RH×1×CAtt_{m}^{x} \in \mathbb{R}^{H \times 1 \times C}Attmx∈RH×1×C。最后,这两个注意力图作用于输入特征TmT_{m}Tm以获得增强特征EmE_{m}Em,表示为:
Em=Attmx⊙Attmy⊙(Tm+Tp′)+Tm(6)E_{m}=Att_{m}^{x} \odot Att_{m}^{y} \odot\left(T_{m}+T_{p'}\right)+T_{m} \tag{6}Em=Attmx⊙Attmy⊙(Tm+Tp′)+Tm(6)
双动态卷积融合模块
给定一个高度为 H、宽度为 W、通道数为CinC_{in}Cin的输入特征x∈RH×W×Cinx \in \mathbb{R}^{H \times W \times C_{in}}x∈RH×W×Cin,以及 V 个卷积核K1,K2,...,KVK_{1}, K_{2}, ..., K_{V}K1,K2,...,KV,现有的动态卷积方法 [40] 从 X 中构建四个特征注意力掩码,包括空间注意力掩码αs∈RV×k×k\alpha_{s} \in \mathbb{R}^{V \times k \times k}αs∈RV×k×k、输入通道注意力掩码αc∈RV×Cin\alpha_{c} \in \mathbb{R}^{V \times C_{in}}αc∈RV×Cin、输出通道注意力掩码αf∈RV×Cout\alpha_{f} \in \mathbb{R}^{V \times C_{out}}αf∈RV×Cout和核注意力掩码αw∈RV\alpha_{w} \in \mathbb{R}^{V}αw∈RV,公式如下:
αt=ϕt(x)(7)\alpha_{t}=\phi_{t}(x) \tag{7}αt=ϕt(x)(7)
其中t∈{s,c,f,w}t \in\{s, c, f, w\}t∈{s,c,f,w},ϕ\phiϕ表示由全局平均池化层(GAP)、全连接层(FC)、ReLU 激活函数和头部分支组成的序列操作。然后,将这些掩码应用于 V 个卷积核,得到聚合的动态卷积核 K,计算如下:
K=αw1⊙αf1⊙αc1⊙αs1⊙K1+⋯+αwV⊙αfV⊙αcV⊙αsV⊙KV(8)\begin{gathered} K=\alpha_{w_{1}} \odot \alpha_{f_{1}} \odot \alpha_{c_{1}} \odot \alpha_{s_{1}} \odot K_{1}+\cdots+ \\ \alpha_{w_{V}} \odot \alpha_{f_{V}} \odot \alpha_{c_{V}} \odot \alpha_{s_{V}} \odot K_{V} \end{gathered} \tag{8}K=αw1⊙αf1⊙αc1⊙αs1⊙K1+⋯+αwV⊙αfV⊙αcV⊙αsV⊙KV(8)
其中αtv\alpha_{t_{v}}αtv表示αt\alpha_{t}αt中的第 v 个元素。得到的动态卷积核K∈Rk×k×Cin×CoutK \in \mathbb{R}^{k \times k \times C_{in} \times C_{out}}K∈Rk×k×Cin×Cout可以通过探索各种注意力维度动态适应特征 X,从而帮助模型提取增强的目标检测特征。在此基础上,我们的方法进一步深入研究可见光和红外特征之间的差异,并引入特征差异注意力掩码αd\alpha_{d}αd。这一添加使我们的卷积核能够更好地探索模态间的独特性,并促进互补特征的提取。具体来说,给定一对输入的可见光和红外特征(Ev,Eir)(E_{v}, E_{ir})(Ev,Eir),我们的方法首先采用模态差异提取网络生成差异注意力掩码αdv/ir∈RV×k×k\alpha_{d}^{v/ir} \in \mathbb{R}^{V \times k \times k}αdv/ir∈RV×k×k,表示为:
αdm=σ(hA(Em−Em‾)+hM(Em−Em‾))(9)\alpha_{d}^{m}=\sigma\left(h_{A}\left(E_{m}-E_{\overline{m}}\right)+h_{M}\left(E_{m}-E_{\overline{m}}\right)\right) \tag{9}αdm=σ(hA(Em−Em)+hM(Em−Em))(9)
其中mmm、m‾∈{v,ir}\overline{m} \in\{v, ir\}m∈{v,ir},σ\sigmaσ表示 sigmoid 函数,hAh_{A}hA是由多层感知机(MLP)和全局最大池化层组成的网络,hMh_{M}hM是由 MLP 和全局平均池化层组成的网络,MLP 是由 1×1 卷积、ReLU 激活函数和另一个 1×1 卷积组成的独特感知机网络。因此,通过将掩码αd\alpha_{d}αd纳入公式(8),我们得到依赖于模态的动态卷积核KmK^{m}Km如下:
Km=αw1m⊙αf1m⊙αc1m⊙αs1m⊙αd1m⊙K1m+⋯+αwVm⊙αfVm⊙αcVm⊙αsVm⊙αdVm⊙KVm(10)\begin{array}{r} K^{m}=\alpha_{w_{1}}^{m} \odot \alpha_{f_{1}}^{m} \odot \alpha_{c_{1}}^{m} \odot \alpha_{s_{1}}^{m} \odot \alpha_{d_{1}}^{m} \odot K_{1}^{m}+\cdots+ \\ \alpha_{w_{V}}^{m} \odot \alpha_{f_{V}}^{m} \odot \alpha_{c_{V}}^{m} \odot \alpha_{s_{V}}^{m} \odot \alpha_{d_{V}}^{m} \odot K_{V}^{m} \end{array} \tag{10}Km=αw1m⊙αf1m⊙αc1m⊙αs1m⊙αd1m⊙K1m+⋯+αwVm⊙αfVm⊙αcVm⊙αsVm⊙αdVm⊙KVm(10)
其中αwvm\alpha_{w_{v}}^{m}αwvm、αfvm\alpha_{f_{v}}^{m}αfvm、αcvm\alpha_{c_{v}}^{m}αcvm、αsvm\alpha_{s_{v}}^{m}αsvm分别表示模态 m 上的核注意力掩码、输出通道注意力掩码、输入通道注意力掩码和空间注意力掩码中的第 v 个元素。具体来说,我们的方法将公式(6)中的EmE_{m}Em输入到公式(7)中以计算这些参数,包括空间注意力掩码αsm∈RV×k×k\alpha_{s}^{m} \in \mathbb{R}^{V \times k \times k}αsm∈RV×k×k、输入通道注意力掩码αcm∈RV×Cin\alpha_{c}^{m} \in \mathbb{R}^{V \times C_{in}}αcm∈RV×Cin、输出通道注意力掩码αfm∈RV×Cout\alpha_{f}^{m} \in \mathbb{R}^{V \times C_{out}}αfm∈RV×Cout、核注意力掩码αwm∈RV\alpha_{w}^{m} \in \mathbb{R}^{V}αwm∈RV和差异注意力掩码αdm∈RV×k×k\alpha_{d}^{m} \in \mathbb{R}^{V \times k \times k}αdm∈RV×k×k,上述注意力掩码沿第一维度分为 V 个子掩码,即αsvm∈RK×K\alpha_{s_{v}}^{m} \in \mathbb{R}^{K \times K}αsvm∈RK×K、αcvm∈RCin\alpha_{c_{v}}^{m} \in \mathbb{R}^{C_{in}}αcvm∈RCin、αfvm∈RCout\alpha_{f_{v}}^{m} \in \mathbb{R}^{C_{out}}αfvm∈RCout、αwvm∈R\alpha_{w_{v}}^{m} \in \mathbb{R}αwvm∈R和αdvm∈RK×K\alpha_{d_{v}}^{m} \in \mathbb{R}^{K \times K}αdvm∈RK×K。将来自五种注意力掩码的 V 个子掩码与 V 个卷积核聚合后,我们得到如公式(10)所示的动态卷积核KmK^{m}Km。接下来,我们将依赖于模态的动态卷积核KmK^{m}Km与相应的模态特征相乘,得到增强特征:
Fm=Em∗Km(11)F_{m}=E_{m} * K^{m} \tag{11}Fm=Em∗Km(11)
其中 * 表示卷积操作。最后,我们对两个卷积结果FirF_{ir}Fir和FvF_{v}Fv进行互补融合,它们包含模态属性和模态间可变性,确保融合结果FfF_{f}Ff包含模态共性和独特可变性。具体公式如下:
G^ir,G^v=Softmax([Fir,Fv])Ff=G^ir⊙Fir+Fir+G^v⊙Fv+Fv(12)\begin{gathered} \hat{G}_{ir}, \hat{G}_{v}=Softmax\left(\left[F_{ir}, F_{v}\right]\right) \\ F_{f}=\hat{G}_{ir} \odot F_{ir}+F_{ir}+\hat{G}_{v} \odot F_{v}+F_{v} \end{gathered} \tag{12}G^ir,G^v=Softmax([Fir,Fv])Ff=G^ir⊙Fir+Fir+G^v⊙Fv+Fv(12)
与从拼接的多模态特征生成动态卷积核相比,我们的方法采用增强的单模态特征作为生成动态卷积核KvK_{v}Kv和KirK_{ir}Kir的原始数据。这种方法最大限度地保留了不同模态输入数据中的独特特征,使核能够专注于特定于模态的特征。此外,差异特征注意力的引入使卷积核对模态间差异更加敏感,使它们能够选择性地提取差异特征以进行互补融合。
D. 跨模态核交互损失
为了通过 CDCF 有效引导动态卷积核的生成,我们的方法采用监督学习,并引入了一种新颖的损失函数 “核交互损失(KI Loss)”。给定从不同模态中学习到的两个待学习核KvK_{v}Kv和KirK_{ir}Kir,我们的方法旨在开发能够捕捉两种模态的共同显著特征,同时识别每种模态中独特显著特征的核函数。这使得能够准确识别双模态数据中的互补特征。基于这一思想,我们的方法利用 Jensen-Shannon(JS)散度 [50] 来衡量分布之间的差异。JS 散度评估两个分布之间的相似性,当它们相似时接近零,不相似时达到 1。通过利用这一散度度量,我们的方法计算KvK_{v}Kv和KirK_{ir}Kir之间的 JS 值,旨在最小化分布差异,以便两个核都能有效捕捉两种模态的共同特征,表示为:
Lc=Djs(Kv,Kir)(13)\mathcal{L}_{c}=D_{js}\left(K_{v}, K_{ir}\right) \tag{13}Lc=Djs(Kv,Kir)(13)
同时,我们的方法旨在让KvK_{v}Kv和KirK_{ir}Kir分别捕捉可见光和红外数据中的独特特征。我们使用两个核之间的差异来表示这种独特特征捕捉,记为Sv∣irS_{v|ir}Sv∣ir和Sir∣vS_{ir|v}Sir∣v,分别对应可见光和红外数据中的独特特征检测。这种关系表示为:
Sv∣ir=sign(Kv−Kir),Sir∣v=sign(Kir−Kv)(14)S_{v|ir}=sign\left(K_{v}-K_{ir}\right), S_{ir|v}=sign\left(K_{ir}-K_{v}\right) \tag{14}Sv∣ir=sign(Kv−Kir),Sir∣v=sign(Kir−Kv)(14)
其中sign()sign()sign()是符号函数,将所有负值设为零。因此,我们的方法期望Sv∣irS_{v|ir}Sv∣ir和Sir∣vS_{ir|v}Sir∣v表现出具有高 JS 值的不同分布,有效捕捉两种模态的独特特征。最终,我们的核交互损失LKIL_{KI}LKI公式如下:
LKI=μDjs(Kv,Kir)−(1−μ)Djs(Sv∣ir,Sir∣v)(15)\mathcal{L}_{KI}=\mu D_{js}\left(K_{v}, K_{ir}\right)-(1-\mu) D_{js}\left(S_{v|ir}, S_{ir|v}\right) \tag{15}LKI=μDjs(Kv,Kir)−(1−μ)Djs(Sv∣ir,Sir∣v)(15)
其中μ\muμ是平衡权重。LKIL_{KI}LKI要求学习到的动态卷积核捕捉共同的显著特征,同时关注每种模态的独特特征。这种双重关注有助于提取更全面的特征,从而提高模型的目标检测性能。
实现:所提出的跨尺度动态卷积融合模块在各种特征尺度上运行,生成多尺度融合特征,这些特征被输入到预测头以产生最终的检测结果。在训练过程中,我们使用由两个主要组件组成的复合损失函数:目标检测损失(包括边界框回归LbboxL_{bbox}Lbbox、目标分类LclsL_{cls}Lcls和目标置信度LobjL_{obj}Lobj)和 CDCFM 中的 KI 损失LKIL_{KI}LKI。最终的损失函数公式如下:
L=λLKI+Lbbox+Lcls+Lobj(16)\mathcal{L}=\lambda \mathcal{L}_{KI}+\mathcal{L}_{bbox}+\mathcal{L}_{cls}+\mathcal{L}_{obj} \tag{16}L=λLKI+Lbbox+Lcls+Lobj(16)
其中λ\lambdaλ是平衡权重。
4. 实验
A. 数据集
我们在 VEDAI [14]、FLIR [15] 和 LLVIP [16] 上进行实验,以评估我们的 CDC-YOLOFusion。
- VEDAI [14]:该航空数据集主要用于车辆检测,存在小目标尺寸、多方向性、光照和阴影变化、镜面反射及遮挡等挑战。提供九类严格对齐的可见光和红外图像对,含1250对两种分辨率(1024×1024和512×512)的图像对。我们使用更高分辨率,其中1089对用于训练,161对用于测试。
- FLIR [15]:为多光谱目标检测带来挑战,涵盖白天和黑夜条件下的三类(“人”“车”“自行车”)。原始数据集图像对未对齐,本研究使用[51]中的对齐版本,含5142对可见光-红外图像对,其中4129对用于训练,1013对用于测试。
- LLVIP [16]:该大规模行人数据集在低光环境下拍摄,多数图像处于极暗环境。所有可见光-红外图像对在空间和时间上严格对齐,含15488对图像,12025对用于训练,其余3463对用于测试。
B. 设置
我们的方法基于CSPDarknet53在YOLOv5架构上构建双分支特征提取骨干网络,分别提取多尺度的可见光和红外特征。在CDCF模块中,跨模态核交互损失LKIL_{KI}LKI中参数μ=0.6\mu=0.6μ=0.6。第一个CDCF层仅使用DDCF模块融合骨干网络特征;从第二层开始,CDCF在通过DDCF融合前使用CSFE增强特征。
训练在NVIDIA GeForce RTX A6000上进行,采用SGD优化器,批处理大小设为8,公式(16)中权重λ=0.5\lambda=0.5λ=0.5,初始学习率0.001,权重衰减0.0005,动量0.937。共训练500个epoch以确保模型良好收敛。
C. 实验结果
消融实验:检验CDS和CDCF模块的实用性,设计四种实验设置(见表1)。
- 第一种:排除CDS和CDCF,用“加法”融合原始对齐图像对训练骨干网络。
- 第二种:在CDC-YOLOFusion框架内,用元素级加法替代CDCF进行特征融合。
- 第三种:使用CDCF模块,但CDS数据交换概率为0。
- 第四种:同时使用CDS和CDCF。
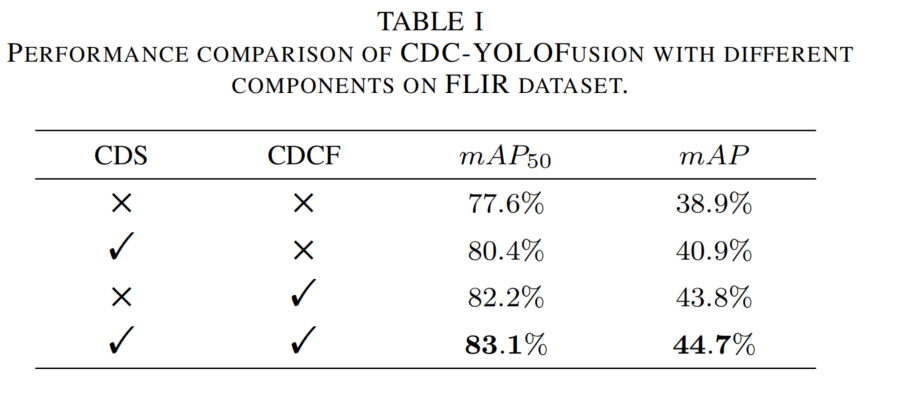
表1 CDC-YOLOFusion在FLIR数据集上不同组件的性能比较
结果表明:
- CDS能提升性能,mAP从38.9%升至40.9%,其局部区域交换策略帮助骨干网络学习跨模态相关性。
- 单独使用CDCF可显著提升mAP(+4.9%),归因于多尺度特征聚合和动态卷积机制,在LKIL_{KI}LKI指导下生成的卷积核专注于模态独特特征和共同特征。
- 两者结合性能最佳(mAP=44.7%),证明CDC-YOLOFusion有效性。
CDS的评估:评估CDS的图像处理策略及N×NN \times NN×N区域划分中NNN的影响(见表2)。
- 当N=10N=10N=10时,CDS性能最佳(mAP=44.7%),同NNN下比裁剪策略mAP高约0.5%,说明CDS增强了模型对模态差异的理解。
- N=5N=5N=5时交换区域过小,难以提供足够跨模态知识;N=15N=15N=15时区域过大,导致原始数据信息丢失过多。
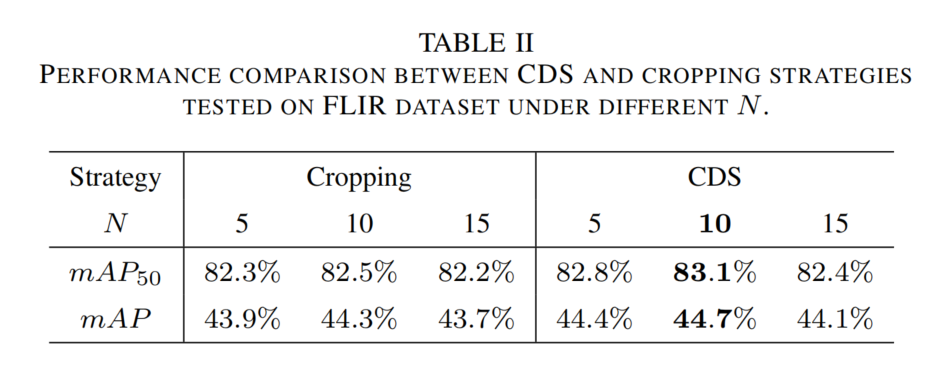
表2 FLIR数据集上CDS和裁剪策略在不同NNN下的性能比较
此外,评估CDS数据增强概率(见表3),概率为0.3时性能最佳。概率过高会破坏单模态信息,过低则无法提供足够跨模态知识。
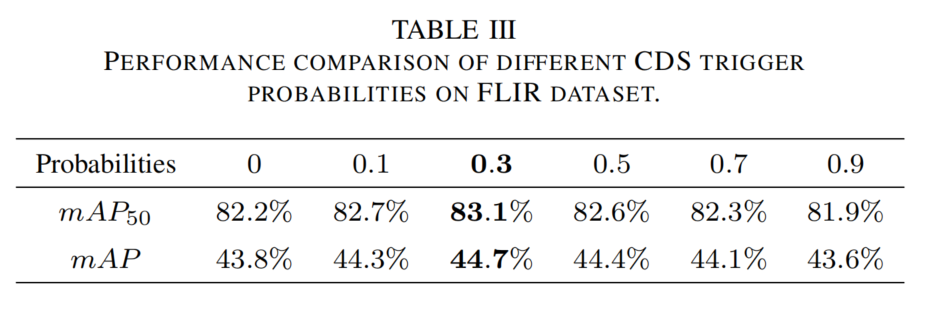
表3 FLIR数据集上不同CDS触发概率的性能比较
CDCF的评估:评估CDCF中CSFE和DDCF的作用(见表4)。
- 不使用DDCF时,用元素级加法替代融合。
- 使用DDCF时,对比是否采用差异特征注意力αd\alpha_{d}αd。
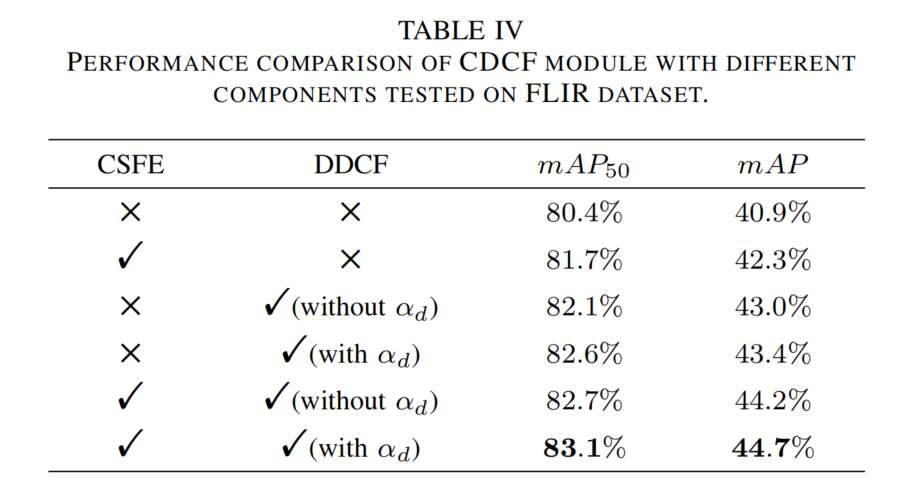
表4 FLIR数据集上CDCF模块不同组件的性能比较
结果显示:
- 单独使用CSFE,mAP提升1.4%,其跨尺度特征增强为动态卷积核生成提供丰富多尺度特征。
- 单独使用DDCF,mAP提升约2.5%,利用模态信息生成动态卷积核可关注跨模态特征;引入αd\alpha_{d}αd可进一步提升mAP约0.5%,增强捕捉模态间差异特征的能力。
图5展示CDCF模块效果,深红色表示显著特征,蓝色为背景特征。骨干网络初始特征TirT_{ir}Tir和TvT_{v}Tv差异明显,CDCF生成的动态卷积核细化特征后,FvF_{v}Fv和FirF_{ir}Fir特征分布相似,目标区域增强,噪声被抑制,融合特征FfF_{f}Ff指导准确检测。
CSFE中注意力机制评估:比较X/Y注意力与自注意力(见表5)。X/Y注意力以更少参数(153.6 M vs 204.2 M)和更快测试速度(65.1 ms vs 109.2 ms)实现更高精度,因其能以较低成本提供相对位置和通道信息。

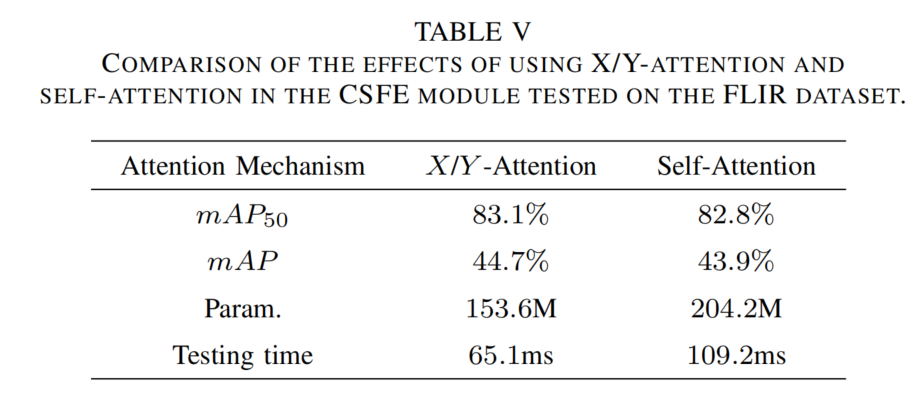
表5 FLIR数据集上CSFE模块中X/Y注意力与自注意力的效果比较
DDCF中卷积核数量评估:评估聚合卷积核数量VVV的影响(见表6)。V=4V=4V=4时性能最佳,V<4V<4V<4时特征表示能力受限,V>4V>4V>4时精度稳定但参数增加。
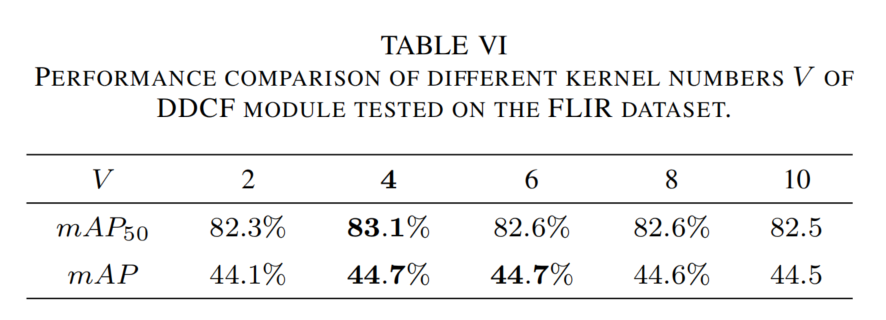
表6 FLIR数据集上DDCF模块不同核数量VVV的性能比较
CDCF模块通用性评估:将CDCF集成到三种骨干网络(见表7),与基线融合方法(元素级加法)相比,在CFT、LRAF-Net和YOLO v5上分别获得2.9%、1.3%和4.9%的绝对增益,证明其在CNN和Transformer-based骨干网络上的稳健性。
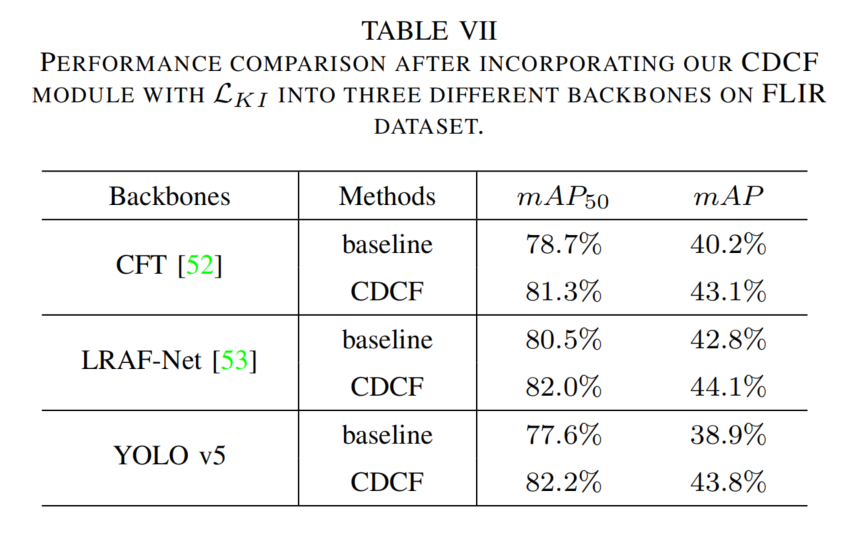
表7 FLIR数据集上CDCF模块集成到不同骨干网络的性能比较
KI损失的评估:评估公式(15)中权重μ\muμ的影响(见表8),μ=0.6\mu=0.6μ=0.6时性能最佳(mAP=44.7%)。μ\muμ过小,动态卷积核忽略共同特征;μ\muμ过大,忽略独特特征,均导致性能下降。
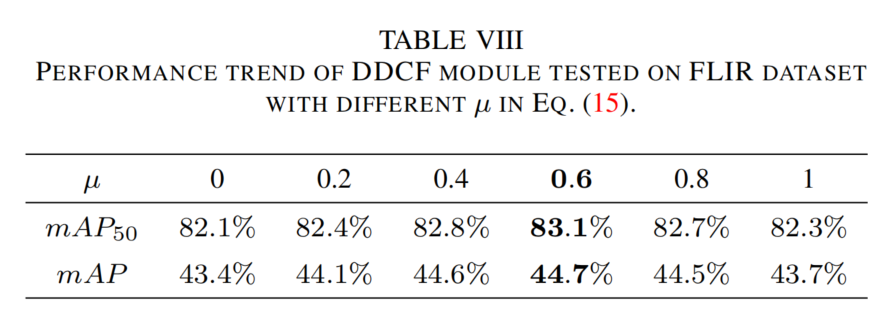
表8 公式(15)中不同μ\muμ值下DDCF模块在FLIR数据集上的性能趋势
评估公式(16)中权重λ\lambdaλ的影响(见表9),λ=0.5\lambda=0.5λ=0.5时性能最佳(mAP=44.7%)。λ\lambdaλ过小,引导卷积核能力弱;λ\lambdaλ过大,掩盖目标检测损失,均导致性能下降。
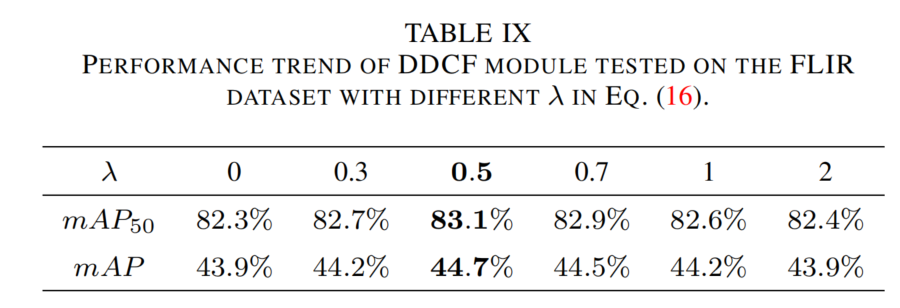
表9 公式(16)中不同λ\lambdaλ值下DDCF模块在FLIR数据集上的性能趋势
D. 与最先进方法的比较
将CDC-YOLOFusion与单模态和多模态检测器在三个数据集上比较(表10-12)。
- 单模态中,红外检测器通常优于可见光检测器,因夜间可见光失效而红外可提供目标特征。
- 多模态方法因融合两种特征性能更优,CDC-YOLOFusion表现最佳,mAP提升约2%-3%,原因在于:CDS提供跨模态特征;CDCF生成含模态特定和共同特征的动态卷积核;KI损失约束提取共同和独特特征。
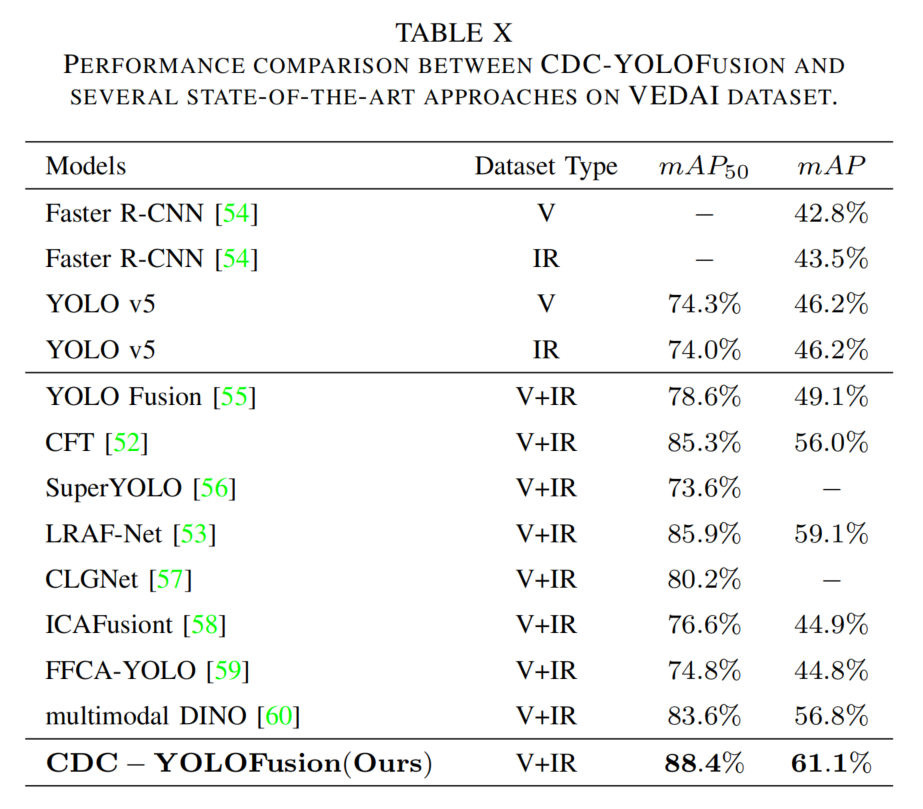
表10 VEDAI数据集上的性能比较
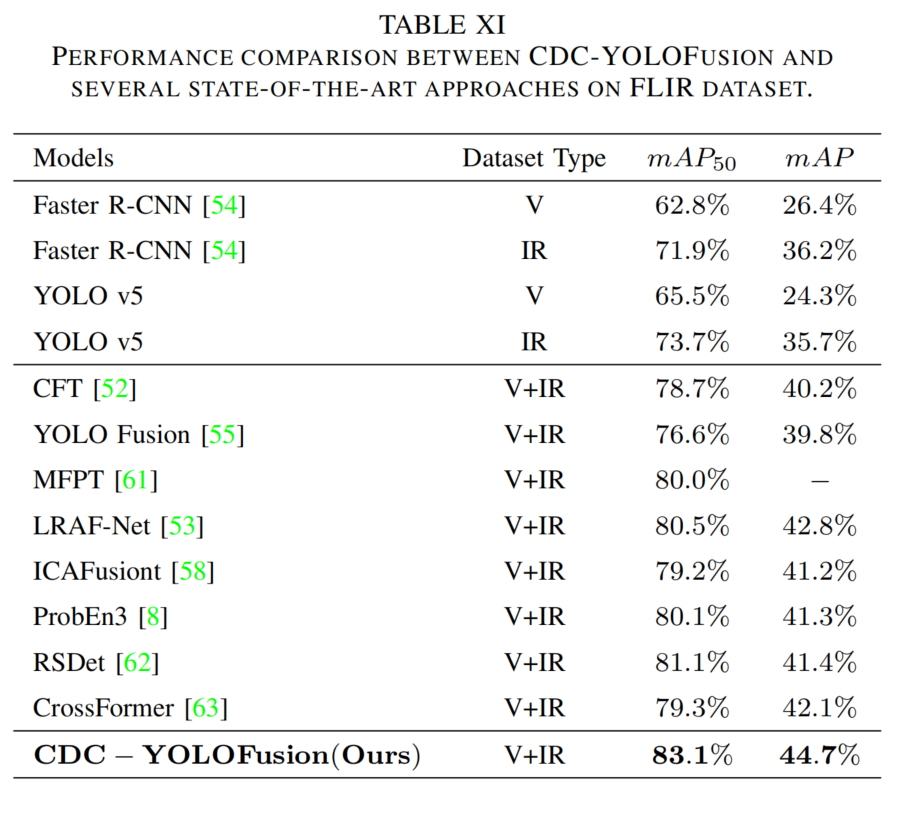
表11 FLIR数据集上的性能比较
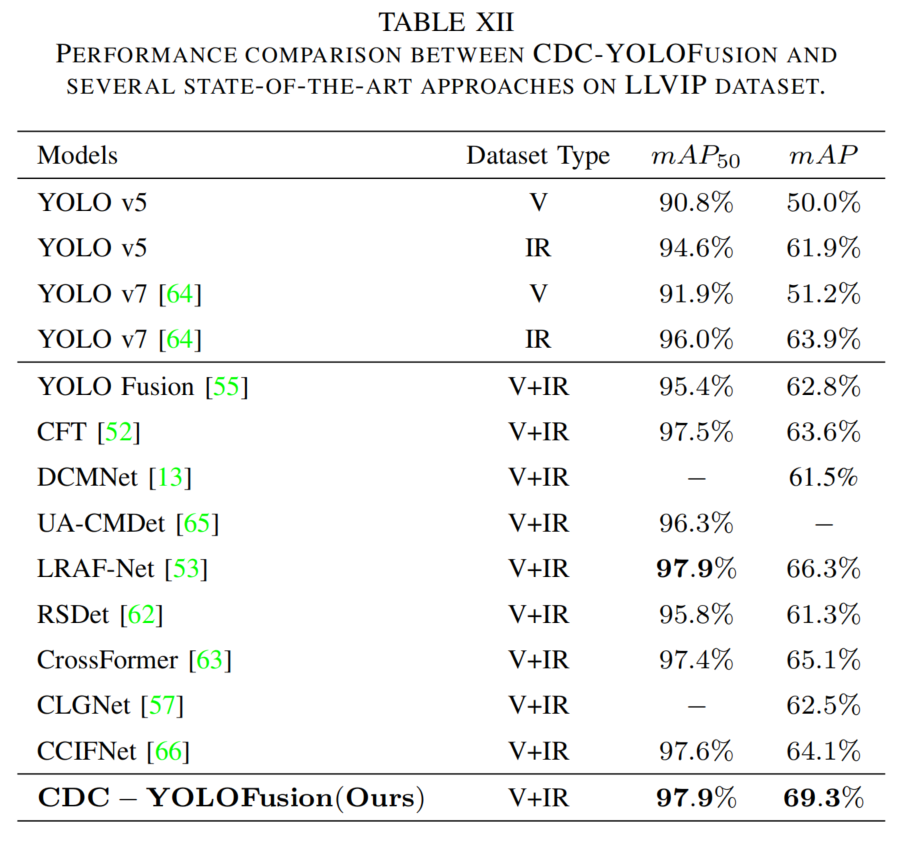
表12 LLVIP数据集上的性能比较
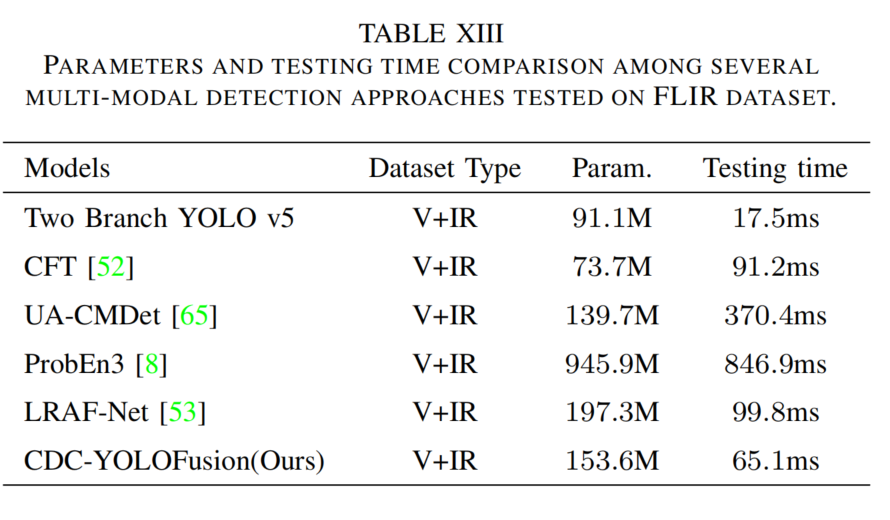
表13比较模型参数和推理时间,CDC-YOLOFusion在参数(153.6 M)和推理时间(65.1 ms)上平衡良好,优于LRAF-Net等方法。
表13 FLIR数据集上多模态检测方法的参数和测试时间比较
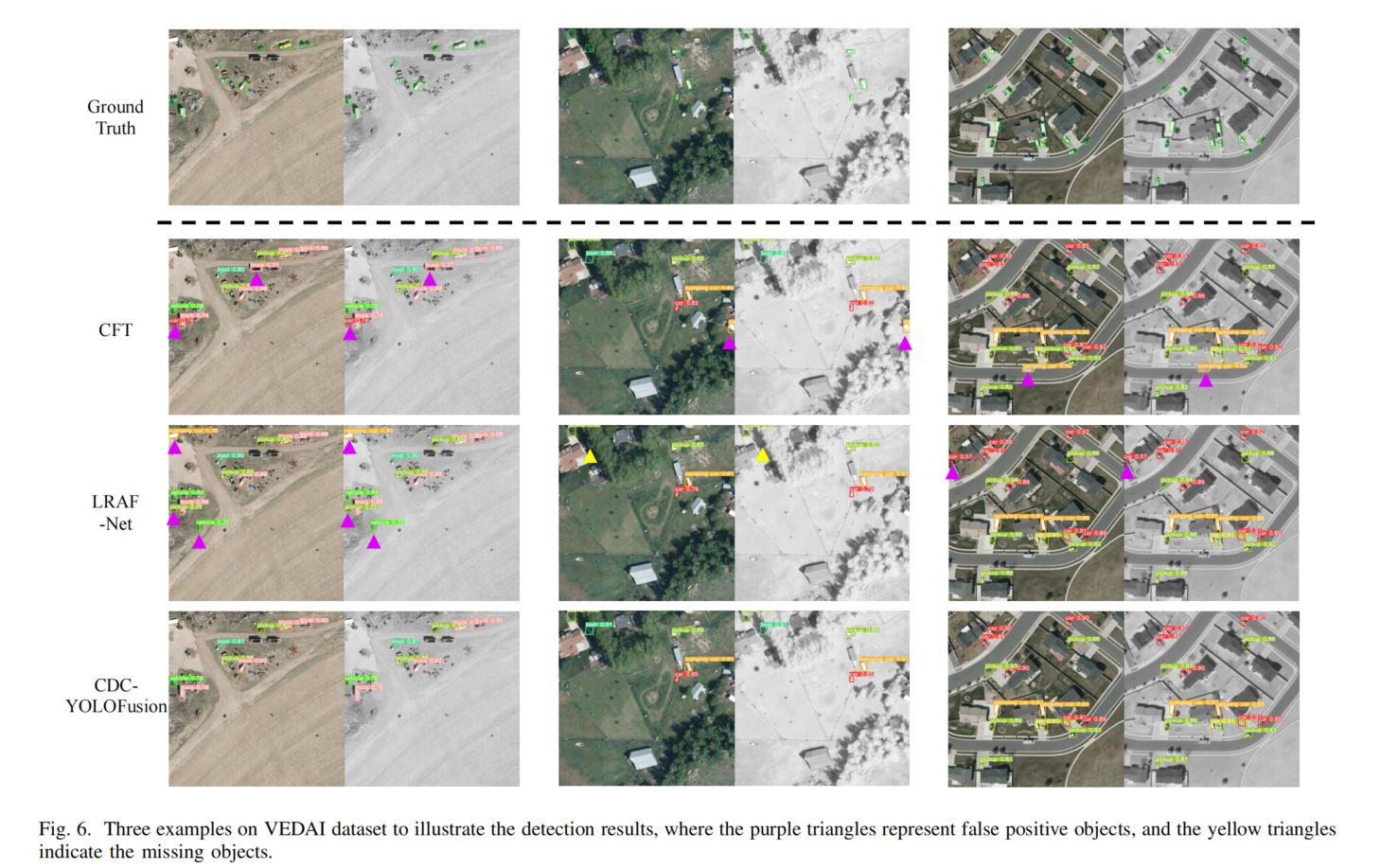
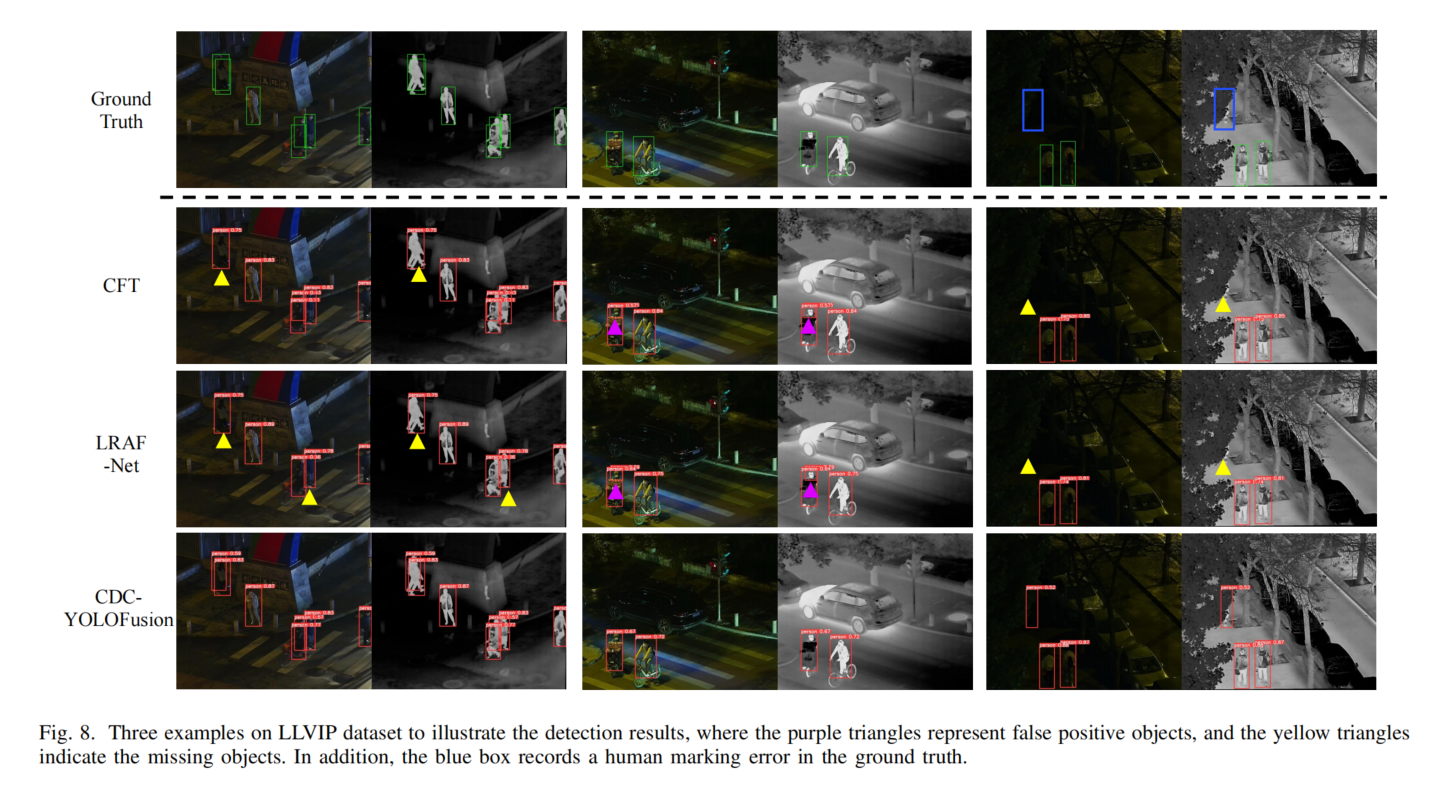
图6-8展示检测结果示例,CDC-YOLOFusion在小目标检测、易混淆目标识别、密集及遮挡场景中表现优异,因CSFE利用跨尺度特征、CDS和DDCF提供模态相关信息、KI损失引导特征提取。

5. 结论
本文提出用于可见光-红外目标检测的CDC-YOLOFusion,首次引入跨尺度动态卷积学习和有监督核学习提升性能。技术上:
- 采用跨模态数据交换生成含两种模态信息的混合图像,促进检测。
- 设计跨尺度动态卷积融合模块,利用跨尺度特征生成有效卷积核,在跨模态核交互损失监督下产生稳健融合特征,支持精确检测。
三个数据集上的大量实验证明CDC-YOLOFusion的有效性,在可见光-红外目标检测中实现最先进性能。