库制作与原理
一.库的概念
库是写好的现有的成熟的可复用的代码。本质上说库是一种可执行代码的二进制形式,可以被载入内存执行。
使得程序员在写程序时,不需要在从0开始的搭建工具,库就相当于工具库,为程序开发提供便捷。
库分为两种:
静态库 .a【Linux】,.lib【windows】
动态库 .so【Linux】,.dll【windows】
在不同版本中,我们可以通过不同的指令找到动静态库,所以库就是指定目录下的一个文件。静态库与动态库主要区别在于链接时机和程序的运行方式。下面我们来进行对比。
1.静态库
静态库在编译时直接被链接到可执行文件中的库文件,生成的程序无需在进行外部链接,可以独立运行。但是其占用空间较大,若库需要更新,那么整个程序都要重新进行更新。
2.动态库
动态库是运行时被动态加载到内存中的库文件。相当于是当一个共享系统,各个程序板块按需进行索取,无需同程序一同加载。内存占用低,更新便捷,灵活性较高。
二.库的制作与使用
在了解了动静态库之后,我们来谈谈如何创建一个库。
我们首先先创建几个文件充当我们的库使用。
文件内存储了代码进行功能实现。
接着我们将 .c 后缀的文件编译成 .o 后缀的文件,我们用指令 gcc -c *.c 将所有.c后缀名的文件编译成 .o 后缀。
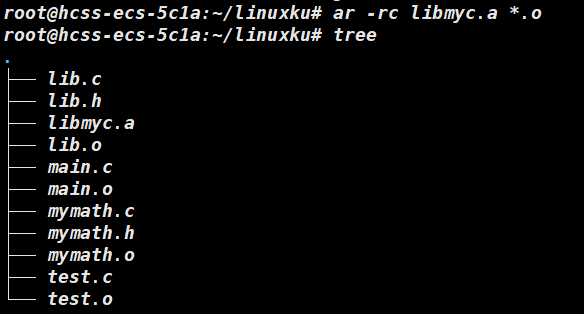
最后将所有 .o 后缀的文件链接成为一个libmyc.a 的静态库。
ar命令用于生成或修改归档文件的工具,-r是将指定文件插入或替换到归档文件中,-c是创建归档文件若已经存在,就会进行警告。后面是目标文件libmyc.a ,其中静态库命名是 lib<名称>.a 的形式。*.o 表示所有 .o 为后缀的文件。
所以简单来说,静态库就是将所有指定文件进行打包就叫静态库。
在面对不同的情景下,我们可以用不同的方法进行库的使用。例如当前别人想用我们的库。
第一种情况,可以直接将 .c 文件交给他,他在进行库的链接等操作,但这样会暴露我们的代码。
第二种情况,我们自己先将 .c 文件编译成 .o 文件再把文件交给他,这样打开.o 文件就会是二进制文件,他只需要将 .o 文件链接成库就可以使用了,这样就不会暴露我们的源代码,他也能使用我们的库。
第三种情况,若我们编译的 .o 文件较多,我们可以将 .o 文件链接成库,将库给他使用。这样他只需要将我们的 .h 后缀文件和库与他的文件进行链接,变成可执行程序即可。
那么我们怎样才能将库与 .o 文件进行链接呢?
首先,我们要将库文件与头文件 .h 拷贝到当前目录中,接着将文件包含库文件方法的文件编译成 .o 文件,将 .o 文件与库文件头文件进行链接,变成可执行程序。

我们用到上面这串指令将 .o 文件与可执行程序链接。
.o 后面跟着需要生成的指定可执行文件名;由于程序会默认在 lib 或 lib64 下寻找库,所以我们要用 -L. 指定为当前路径下的库 ,-L表示搜索库文件路径;-lmyc其中 -l 表示用于链接静态库或动态库,后面跟着库名 myc 。所以,我们要链接一个库,就要知道库的路径,以及库的名称
我们可以通过 ldd myexe 来查询程序所依赖的库

此时我们并没有发现先前使用的 myc 库,反而都是以 .so 为后缀的动态库。这是因为我们的 myc 是静态库,在编译时将自己的代码合并到可执行程序中去了,一旦可执行程序形成,就不再依赖静态库了。
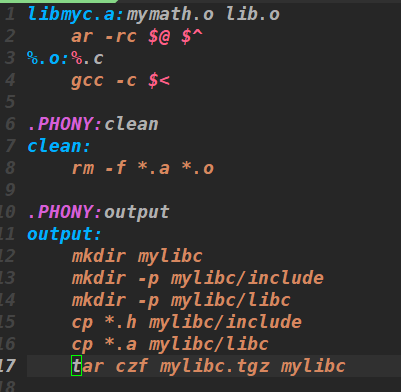
下面我们来自己制作打包一个库:
首先准备好库文件和头文件,将 .c 后缀文件编译成 .o 后缀文件,将 .o 文件与库文件进行链接形成 .a的库,将 .a 库与头文件分类后进行打包压缩,我们就可以将库交给别人使用了。
了解完静态库的使用后,我们来看一下动态库
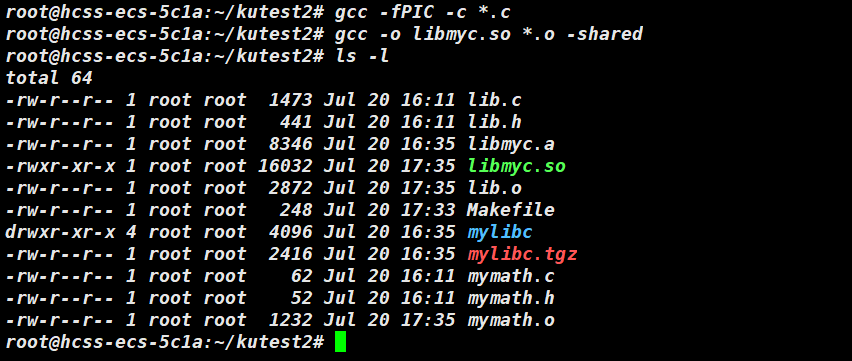
动态库不需要将库文件与 .o 文件进行链接,而是先将 .c 后缀名的文件编译成 .o ,gcc -fPIC -c *.o 其中 fPIC 是动态库链接
我们将生成的动态库与test 文件进行链接。
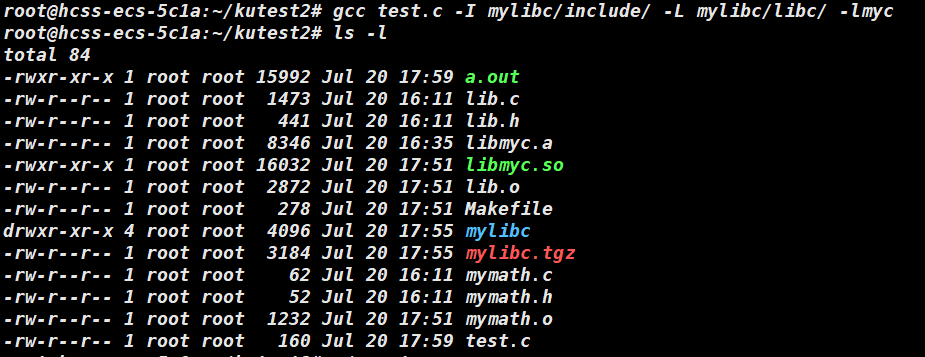
-I 后面跟着要链接的头文件位置,-L 后面跟着库文件的位置,-l 后面跟着库文件名字。
我们对生成的a.out 进行运行发现系统报错找不到库。
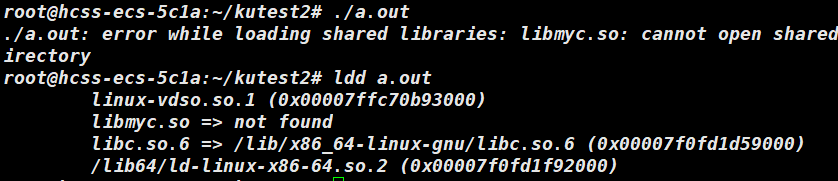
此处的 libmyc.so 显示为 not found,这是为什么呢???
我们前面的操作是将程序与动态库进行了链接,当程序加载到内存中变成可执行程序,而动态库没有加载到内存中,此时系统就找不到该动态库(区别于静态库,静态库是链接时将库直接合并到文件中去了) 。所以我们要将动态库与操作系统默认路径下的相链接。
动态库的链接主要有三种方法:
第一种是直接将库拷贝到系统中/lib64,在系统内部建立软链接。
第二种方法更改环境变量配置文件,相当于更改系统在默认路径下寻找的文件,更改的环境变量为$LD_LIBRARY_PATH。

三.ELF文件
前面提到库是由可执行代码的二进制形式构成载入内存的文件。当然这种二进制形式也有自己的格式,这种格式我们称为ELF格式。例如我们的 .o 文件与库文件就是ELF 格式的文件,它们链接形成的可执行程序也是ELF 格式的文件。
下面我们来看一下 ELF 格式文件的形式
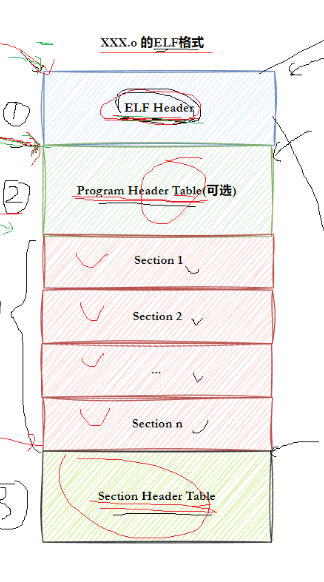
文件分为内容 + 属性,而 ELF 文件主要服务于文件内容的一种文件格式。
这里我们提前准备了一个程序 myexe ,我们先来认识 ELF Header 。
1. ELF Header
ELF Header 是 ELF 文件的起始部分,包含描述文件基本属性和布局的元数据,像 ELF 文件的目录,告诉我们如何处理文件内容。
输入指令 readelf -h myexe ,readelf 表示查看ELF 格式的指令,可以通过ELF Header 读取内容,-h 表示只看Header 部分。
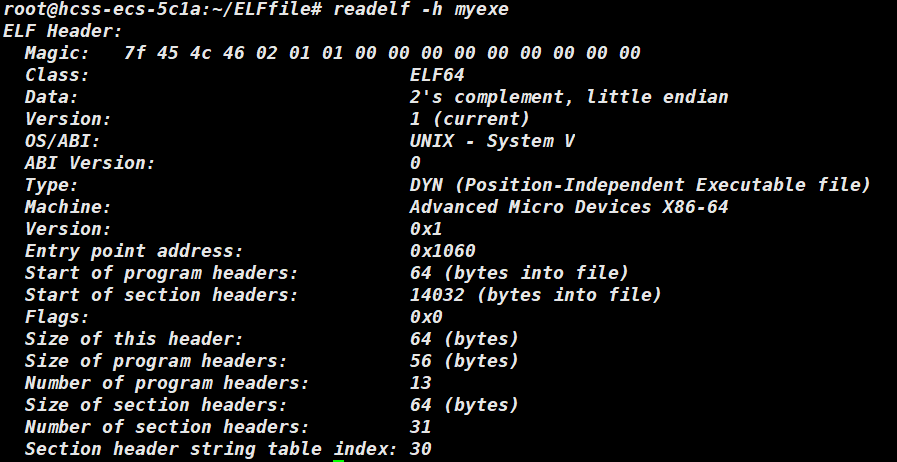
首位 Magic 为魔数,它的前 4 个字节是固定的为 7f 45 4c 46 通过ASCLL 码翻译就是ELF ,通过前4个字节就能识别出是否为 ELF 格式的文件;Data 表示当前机器的大小端;Type 表示当前文件的描述可执行文件,可重定位文件等;Machine 指定了 ELF 文件的目标架构,需要在 x86-64 环境下运行;Entry point address 记录了程序执行的起始点地址;start of program Headers 表示program Header table 表在文件中的偏移量;start of section headers 表示 section Header table 表在文件中的偏移量;size of this header 表示当前 ELF Headers 的大小,单位为字节;size of program headers 指的是每个 program header 的大小;number of program Headers 表示program Header 中的个数,那么整个 program Header Table 的大小就是number * size(字节)。
ELF Header 将文件的属性用结构体记录下来,写在 ELF 文件的开头处,使得操作系统和编译器可以识别出 ELF Header。记录文件起始地址,以及每个版块的偏移量,就可以通过起始地址加上偏移量的方法找到对应的版块。
2. Section 与 Section Header Table
Section 表示文件格式中的节,其中包含可执行代码段,数据段等等。Section Header Table 是记录各个 section信息的表。
输入指令 readelf -S myexe 可以通过 Section Header Table 查看当前程序节的相关信息。
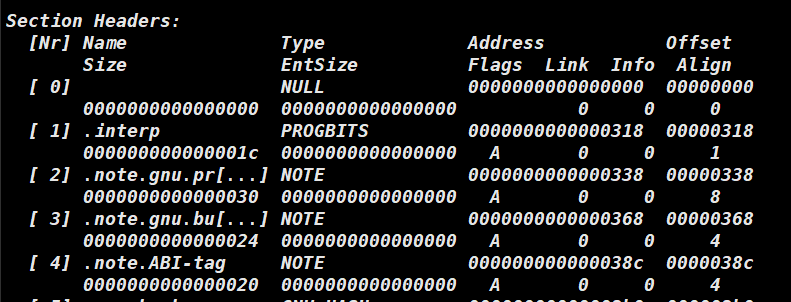
表中记录了每个节的类型名称,节的偏移量(offset),大小(size),flags(文件类型,可执行,需要合并等)。
3. Program Header Table
在讲解 Program Header Table 前需要理解 segment 的概念。编译器每次识别的时候都是4KB 的大小,但是每个section 的大小不一定为 4 KB 大小,所以这里引入了段(segment)的概念,将相同属性的section 合并到一起,每一个段大小为 4KB。
程序表头(Program Header Table)列举了所有段和他们的属性,表里记着每个段的开始位置和偏移量,长度。相当于,这张表是一张合并segment的方法表,在加载到内存时,OS 根据表将section 合并成 segment。编译器视角看待一个 ELF 文件就是一个一个 section,OS 系统看待就是 segment。
输入指令 readelf -l myexe 就可以查看。
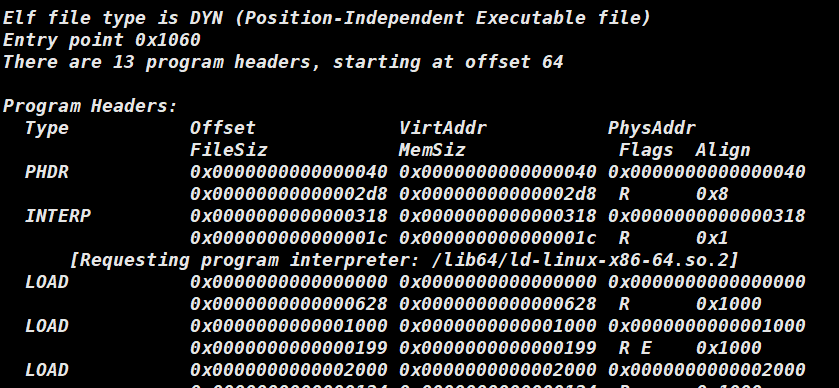
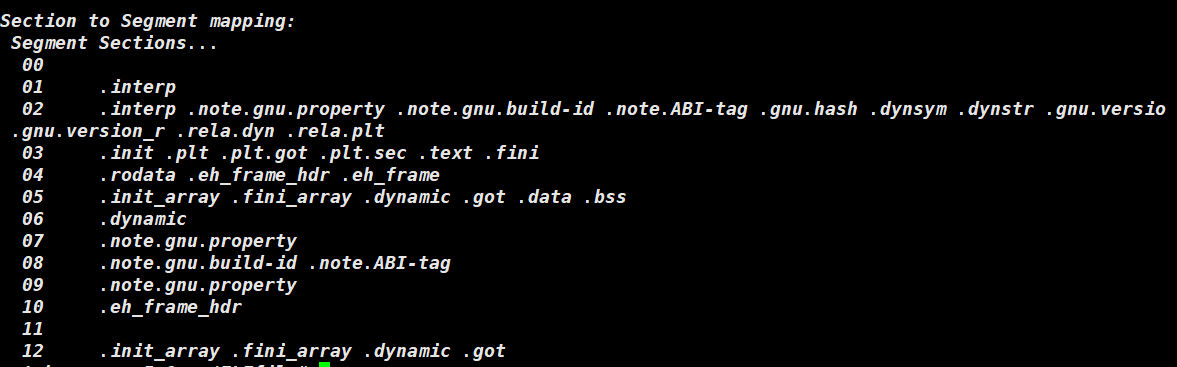
例如当前这个文件有 13 个program header,对于每个segment都记录了它的类型,偏移量,虚拟地址,物理地址。以及在每个 segment 中对于section的合并项。
section合并主要是为了减少页面碎片,提高内存使用效率。
四.链接与加载
1. 静态链接
静态链接指在编译阶段将程序所依赖的库代码完整复制到最终生成的可执行文件中,形成一个独立的二进制文件。
我们可以使用 objdump 来分析目标文件。
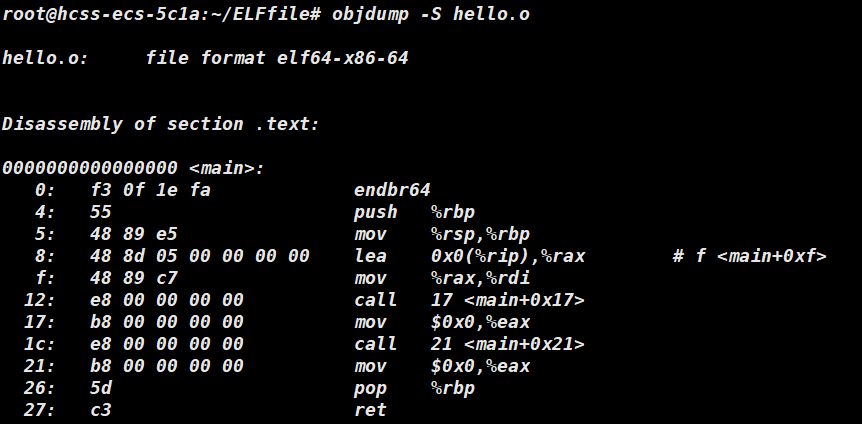
其中的call是关于函数的调用,我们可以观察到此处是没有地址的。只有当我们将文件进行链接之后,此处的地址才会被填充进去。我们将这些未定位的 .o 文件叫做可重定位目标文件,将这些函数填充进去叫做链接时地址重定位。
综上所述,静态链接就是把库中的 .o 进行合并,把编译之后所有的目标文件与静态库组合,拼装成一个独立的可执行文件,链接之后会根据重定位表找到那些需要被重定位的函数,从而修正它们的地址,这就是静态链接的过程。
2. ELF 加载与进程地址空间
进程地址空间
我们先来思考一个问题,一个ELF可执行程序在没有加载到内存的时候,是否存在地址呢?
存在地址,但是是虚拟地址并不是实际的物理地址。只有当程序加载到内存中时才会分配实际的物理地址。对于 ELF 文件的编址采用平坦模式,平坦模式用一段连续的线性地址存储代码段,数据段,堆栈等。按照线性地址统一编址。
下面我们来理解一下逻辑地址,虚拟地址,物理地址三个概念。
逻辑地址存在于 ELF 文件中,是程序代码中使用的地址。虚拟地址是程序运行时看到的地址,存在于内存当中。物理地址是硬件内存的地址。这三者可以进行转换,逻辑地址->虚拟地址->物理地址。
ELF 加载
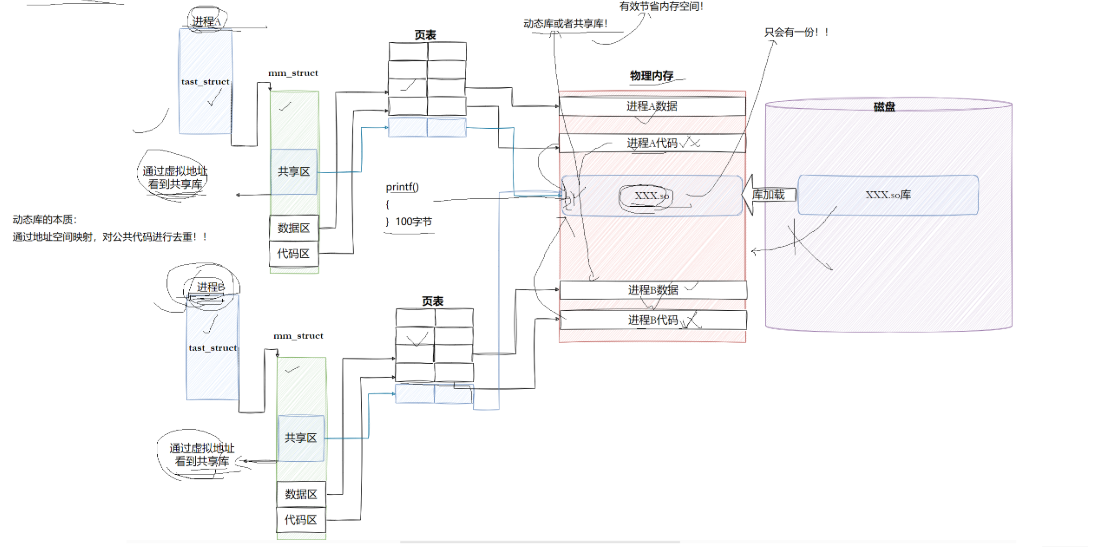
ELF 文件通过二进制的形式存储,其中记录的指令用的都是逻辑地址和虚拟地址,当 ELF 文件加载到内存中时,CPU 会为其分配实际的物理地址。进程的结构体中存在着一个页表,用来映射实际的物理地址与虚拟地址的映射关系。CPU 中的CR3指针指向着页表的起始位置,使得 CPU 可以拿到每一行的指令,CPU 中的 EIP 存储着CPU 下一行要执行的指令,在加载前会将 ELF 的Entry point address 加载进入内存让 EIP 拿到每个 ELF 文件的起始虚拟地址,通过 MMU 将虚拟地址与页表进行映射最终拿到物理地址。至此,CPU 完成了闭环,进来的是虚拟地址,出去的是物理地址。
3. 动态链接与动态库加载
动态链接区别于静态链接,动态链接在文件链接时不会进行合并,而当程序运行时才会进行链接。运行时,库从磁盘加载到内存当中,此时库也有了自己的物理地址,库存在于堆和栈之间的共享区当中,由于存在着物理地址与虚拟地址,所以它也会存入页表中(物理地址与虚拟地址的映射)。动态库的好处在于可以有效的节省空间,所有需要当前库的进程都会将库的地址存入到自己的虚拟地址空间中(共享区),相当于动态库就是一个公共用品,任何一个进程都可以使用它。所以说,动态库就是通过地址空间映射对公共代码进行去重。