《汇编语言:基于X86处理器》第9章 字符串和数组(2)
9.4二维数组
9.4.1 行列顺序
在汇编语言程序员看来,二维数组是一位数组的高级抽象。高级语言有两种方法在内存中存放数组的行和列:行主序和列主序,如图 9-1 所示。使用行主序(最常用)时,第一行存放在内存块开始的位置,第一行最后一个元素后面紧跟的是第二行的第一个元素。使用列主序时,第一列的元素存放在内存块开始的位置,第一列最后一个元素后面紧跟的是第二列的第一个元素。

用汇编语言实现二维数组时,可以选择其中的任意一种顺序。本章使用的是行主序。如果是为高级语言编写汇编子程序,那么应该使用高级语言文档中指定的顺序。
x86指令集有两种操作数类型:基址-变址和基址-变址-位移量,这两种类型都适用于数组。下面将对它们进行研究并通过例子来说明如何有效地使用它们。
9.4.2 基址-变址操作数
基址-变址操作数将两个寄存器(称为基址和变址)相加,生成一个偏移地址:
[base + index]
其中的方括号是必需的。32位模式下,任一32位通用寄存器都可以用作基址和变址寄存器。(通常情况下避免使用 EBP,除非进行堆栈寻址。)下面的例子是 32位模式中基址和变址操作数的各种组合:
.data
array WORD 1000h, 2000h, 3000h
.code
mov ebx, OFFSET array
mov esi, 2
mov ax, [ebx+esi] ;AX=2000h
mov edi, OFFSET array
mov ecx, 4
mov ax, [edi+ecx] ;AX=3000h
mov ebp, OFFSET array
mov esi, 0
mov ax, [ebp+esi] ;AX=1000h二维数组 按行访问一个二维数组时,行偏移量放在基址寄存器中,列偏移量放在变址寄存器中。例如,下表给出的数组为3行5列:
tableB BYTE 10h,20h,30h,40h,50h
Rowsize = ($-tableB)BYTE 60h, 70h,80h,90h,0A0hBYTE 0BOh, C0h, 0DOh, 0E0h, 0FOh该表为行主序,汇编器计算的常数Rowsize 是表中每行的字节数。如果想用行列坐标定位表中的某个表项,则假设坐标基点为 0,那么,位于行1列 2 的表项为 80h。将 EBX设置为该表的偏移量,加上(Rowsizerow_index),计算出行偏移量,将 ESI设置为列索引:
row_index = 1
column_index = 2
mov ebx, OFFSET tableB ;表偏移量
add ebx, RowSize * row_index ;行偏移量
mov esi, column_index
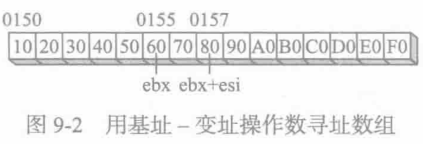
mov al, [ebx+esi] ;AL = 80h假设该数组位置的偏移量为0150h,则其有效地址表示为EBX+ESI,计算得0157h。图9-2展示了如何通过EBX加上ESI生成tableB[1,2]字节的偏移量。如果有效地址指向该程序数据区之外,那么就会产生一个运行时错误。
完整代码测试笔记
;9.4.2.asm 9.4.2 基址-变址操作数
;基址-变址操作数将两个寄存器(称为基址和变址)相加,生成一个偏移地址:
;[base + index].386
.model flat, stdcall
.stack 4096
ExitProcess PROTO,dwExitCode:DWORD.data
array WORD 1000h, 2000h, 3000h
tableB BYTE 10h, 20h, 30h, 40h, 50h
Rowsize = ($ - tableB)BYTE 60h, 70h, 80h, 90h, 0A0hBYTE 0B0h, 0C0h, 0D0h, 0E0h, 0F0h
row_index = 1
column_index = 2.code
main PROCmov ebx, OFFSET arraymov esi, 2mov ax, [ebx+esi] ;AX=2000hmov edi, OFFSET arraymov ecx, 4mov ax, [edi+ecx] ;AX=3000hmov ebp, OFFSET arraymov esi, 0mov ax, [ebp+esi] ;AX=1000h;二维数组mov ebx, OFFSET tableB ;表偏移量add ebx, RowSize * row_index ;行偏移量mov esi, column_indexmov al, [ebx + esi] ;AL = 80hINVOKE ExitProcess, 0
main ENDP
END main
运行调试:




1.计算数组行之和
基于变址的寻址简化了二维数组的很多操作。比如,用户可能想要计算一个整数矩阵中一行的和。下面的32位calc_row_sum程序(参见RowSum.asm)就计算了一个8位整数矩阵中被选中行的和数:
;-------------------------------------------------
;计算字节矩阵中一行的和数。
;接收:EBX=表偏移量,EAX=行索引
;;ECX=按字节计的行大小。
;返回:EAX为和数。
;-------------------------------------------------
calc_row_sum PROC USES ebx ecx edx esimul ecx ;行索引 x 行大小add ebx, eax ;行偏移量mov eax, 0 ;累加器mov esi, 0 ;列索引
L1: movzx edx, BYTE PTR[ebx+esi] ;取一个字节add eax, edx ;与累加器相加inc esi ;行中的下一个字节loop L1 ret
calc_row_sum ENDPBYTE PTR是必需的,用于声明MOVZX指令中操作数的类型。
2.比例因子
如果是为字数组编写代码,则需要将变址操作数乘以比例因子2。下面的例子定位行1列2 的元素值:
.data
tableW WORD 10h, 20h, 30h, 40h, 50h
RowsizeW = ($ - tableW)WORD 60h, 70h, 80h, 90h, 0A0hWORD 0B0h, 0C0h, 0D0h, 0E0h, 0F0h.code
row_index = 1
column_index = 2
mov ebx, OFFSET tableW ;表偏移量
add ebx, RowSizeW * row_index ;行偏移量
mov esi, column_index
mov ax, [ebx + esi * TYPE tableW] ;AX = 0080h本例的比例因子(TYPE tableW)等于 2。同样,如果数组类型为双字,则比例因子为4:
tableD DWORD 10h, 20h, ...etc.
.code
mov eax, [ebx+esi*TYPE tableD]完整代码测试笔记
;calc_row_sum.asm 9.4.2 基址-变址操作数
;计算数组行之和.386
.model flat, stdcall
.stack 4096
ExitProcess PROTO,dwExitCode:DWORD.data
tableD DWORD 1020h,3040h,5060h,7080h,90A0h
tableW WORD 10h, 20h, 30h, 40h, 50h
RowsizeW = ($ - tableW)WORD 60h, 70h, 80h, 90h, 0A0hWORD 0B0h, 0C0h, 0D0h, 0E0h, 0F0h.code
;-------------------------------------------------
;计算字节矩阵中一行的和数。
;接收:EBX=表偏移量,EAX=行索引
;;ECX=按字节计的行大小。
;返回:EAX为和数。
;-------------------------------------------------
calc_row_sum PROC USES ebx ecx edx esimul ecx ;行索引 x 行大小add ebx, eax ;行偏移量mov eax, 0 ;累加器mov esi, 0 ;列索引
L1: movzx edx, BYTE PTR[ebx+esi] ;取一个字节add eax, edx ;与累加器相加inc esi ;行中的下一个字节loop L1 ret
calc_row_sum ENDPmain PROCrow_index = 1column_index = 2mov ebx, OFFSET tableW ;表偏移量add ebx, RowSizeW * row_index ;行偏移量mov esi, column_indexmov ax, [ebx + esi * TYPE tableW] ;AX = 0080hmov ebx, OFFSET tableDmov esi, column_indexmov eax, [ebx+esi*TYPE tableD] ;EAX = 00005060hINVOKE ExitProcess, 0
main ENDP
END main
运行调试:


9.4.3 基址-变址-偏移量操作数
基址-变址-偏移量操作数用一个偏移量、一个基址寄存器、一个变址寄存器和一个可选的比例因子来生成有效地址。格式如下:
[base +index+displacement]
displacement[base + index]
Displacement(偏移量)可以是变量名或常量表达式。32位模式下,任一32 位通用寄存器都可以用作基址和变址寄存器。基址-变址-偏移量操作数非常适于处理二维数组。偏移量可以作为数组名,基址操作数为行偏移量,变址操作数为列偏移量。
双字数组示例 下面的二维数组包含了3行5列的双字:
tableD DWORD 10h,20h,30h,40h,50h
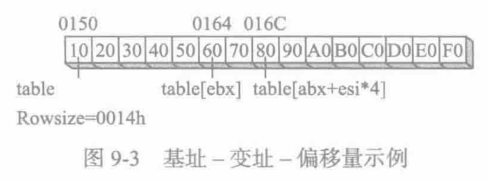
Rowsize = ($ - tableD)DWORD 60h, 70h,80h,90h,0A0hDWORD 0BOh, C0h, 0DOh, 0E0h, 0FOhRowsize 等于 20(14h)。假设坐标基点为 0,那么位于行1 列 2 的表项为 80h。为了访问到这个表项,将 EBX 设置为行索引,ESI 设置为列索引:
mov ebx, Rowsize ;行索引
mov esi, 2 ;列索引
mov eax, tableD[ebx +esi*TYPE tableD]设tableD开始于偏移量0150h处,图9-3展示了EBX和ESI相对于该数组的位置。偏移量为十六进制。
完整代码测试笔记
;9.4.3.asm 9.4.3 基址-变址-偏移量操作数
;基址-变址-偏移量操作数用一个偏移量、一个基址寄存器、一个变址寄存器和一个可选的比例因子来生成有效地址。格式如下:
;[base +index+displacement]
;displacement[base + index]
;Displacement(偏移量)可以是变量名或常量表达式。.386
.model flat, stdcall
.stack 4096
ExitProcess PROTO,dwExitCode:DWORD.data
tableD DWORD 10h, 20h, 30h, 40h, 50h
Rowsize = ($ - tableD)DWORD 60h, 70h, 80h, 90h, 0A0hDWORD 0B0h, 0C0h, 0D0h, 0E0h, 0F0h.code
main PROCmov ebx, Rowsize ;行索引mov esi, 2 ;列索引mov eax, tableD[ebx+esi*TYPE tableD] ;EAX = 00000080hINVOKE ExitProcess, 0
main ENDP
END main运行调试:

9.4.4 64 位模式下的基址-变址操作数
64 位模式中,若用寄存器索引操作数则必须为64位寄存器。基址-变址操作数和基址-变址-偏移量操作数都可以使用。
下面是一段小程序,它用gettableVal过程在64位整数的二维数组中定位一个数值如果将其与上一节中的32位代码进行比较,会发现ESI被替换为RSI,EAX和EBX也成了RAX和 RBX。
;TwoDimArrays.asm 9.4.4 64 位模式下的基址-变址操作数
;64位模式下的二维数组Crlf proto
WriteInt64 proto
ExitProcess proto.data
table QWORD 1,2,3,4,5
RowSize = ($ - table)QWORD 6,7,8,9,10QWORD 11,12,13,14,15.code
main proc;基址-变址-偏移量操作数mov rax, 1 ;行索引基点为0mov rsi, 4 ;列索引基点为0call get_tableVal ;RAX中为返回值call WriteInt64 ;显示返回值call Crlfmov ecx, 0 ;程序结束call ExitProcess
main endp
;---------------------------------------------
;返回四字二维数组中给定行列值的元素。
;接收:RAX=行数,RSI=列数
;返回:RAX中的数值
;---------------------------------------------
get_tableVal PROC USES rbxmov rbx, RowSizemul rbx ;乘积(低)=RAXmov rax, table[rax + rsi * TYPE table]ret
get_tableVal ENDP
end
编译运行
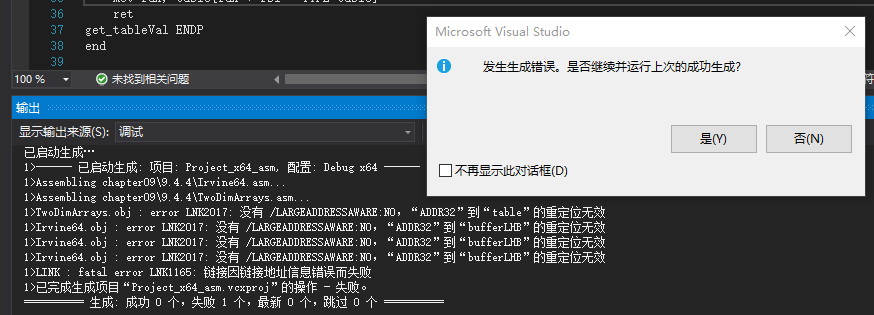
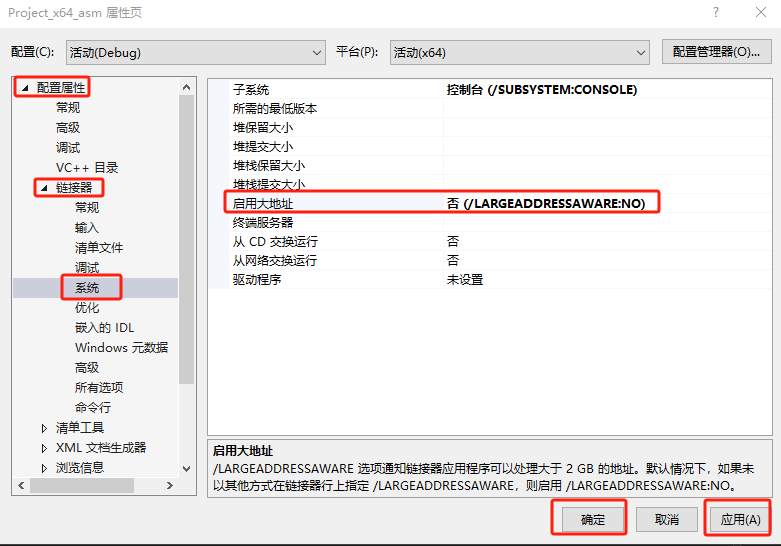
报错了,解决办法:右键项目==》【属性】==》【配置属性】==》【链接器】==》【系统】==》【启用大地址】设置为No,如下所示:
编译,运行调试:

9.4.5 本节回顾
1.32 位模式中,哪些寄存器能用于基址-变址操作数?
答:任意32位通用寄存器。
2.假设一双字二维数组有3个逻辑行和4个逻辑列。若ESI用作行索引,当从一行移到下一行时,ESI 应加多少?
答:4*TYPE DWORD = 16
3.32位模式可以使用EBP来寻址数组吗?
答:不可以,要保留EBP作为当前过程 堆栈帧的基址指针。
9.5 整数数组的检索和排序
为了找到更好的方法对大量数据集进行检索和排序,计算机科学家已经花费了相当多的时间和精力。与买一台更快的计算机相比,对于具体应用而言,选择最好的算法被证明更加有用。大多数学生在研究检索和排序时使用的是高级语言,如C++和Java。汇编语言则在算法研究上展示了一种不同的视角,它能让研究者看到底层的实现细节。
检索和排序提供了一个机会来尝试本章介绍的寻址方法。尤其是基址-变址寻址会被证明是有用的,因为程序员可以用一个寄存器(通常为EBX)作数组的基址,而用另一个寄存器(通常为ESI)索引数组中的任何位置。
9.5.1 冒泡排序
冒泡排序从位置0和1开始,对比数组的两个数值。如果比较结果为逆序,就交换这两个数。图9-4展示了对一个整数数组进行一次遍历的过程。
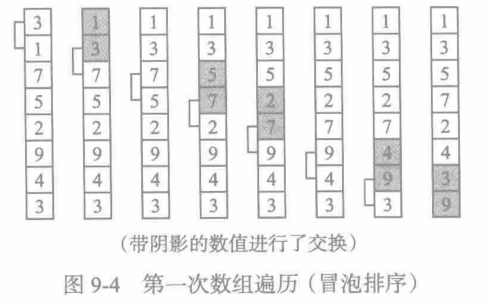
一次冒泡过程之后,数组仍没有按序排列但此时最高索引位置上是最大数。外层循环则开始对该数组再一次遍历。经过n-1次遍历后,数组就会按序排列。
冒泡排序对小型数组效果很好,但对较大的数组而言,它的效率就十分低下。计算机科学家在衡量算法的相对效率时,常常使用一种被称为“时间复杂度”(big-0)的概念来描述随着处理对象数量的增加,平均运行时间是如何增加的。冒泡排序是0(㎡)算法,这就意味着,它的平均运行时间随着数组元素(n)个数的平方增加。比如,假设1000个元素排序需要0.1秒。当元素个数增加10倍时,该数组排序所需要的时间就会增加10(100)倍。下表列出了不同数组大小需要的排序时间,假设1000个数组元素排序花费0.1秒:

对于一百万个整数来说,冒泡排序谈不上有效率,因为它完成任务的时间太长了!但是对于几百个整数,它的效率是足够的。
伪代码 用类似于汇编语言的伪代码为冒泡排序编写的简化代码是有用的。代码用N表示数组大小,cx1 表示外循环计数器,cx2 表示内循环计数器:
cx1 = N - 1
while(cx1 > 0)
{esi = addr(array)cx2 = cx1while(cx2 > 0){if(array[esi] > array[esi+4])exchange(array[esi], array[esi+4])add esi, 4dec cx2}dec cx1
}如保存和恢复外循环计数器等的机械问题被刻意忽略了。注意内循环计数(cx2)是基于外循环计数(cx1)当前值的,每次遍历数组时它都依次递减。
汇编语言 根据伪代码能够很容易生成与之对应的汇编程序,并将它表示为带参数和局部变量的过程:
;BubbleSort.asm 9.5.1 冒泡排序.386
.model flat, stdcall
.stack 4096BubbleSort PROTO, pArray:PTR DWORD, Count:DWORD
ExitProcess PROTO,dwExitCode:DWORD.data
tableD DWORD 100h, 20h, 3030h, 402h, 50h, 80h, 6070h, 6020h.code
main PROCINVOKE BubbleSort, OFFSET tableD, LENGTHOF tableDINVOKE ExitProcess, 0
main ENDP
;------------------------------------------
;使用冒泡算法,将一个32位有符号整数数组按升序进行排列
;接收:数组指针,数组大小
;返回:无
;------------------------------------------
BubbleSort PROC USES eax ecx esi,pArray:PTR DWORD, ;数组指针Count:DWORD ;数组大小mov ecx, Countdec ecx ;计数值减1
L1: push ecx ;保存外循环计数值mov esi, pArray ;指向第一个数值
L2: mov eax, [esi] ;取数组元素值cmp [esi + 4], eax ;比较两个数值jg L3 ;如果[ESI]<=[ESI+4],不交换xchg eax, [esi+4] ;交换两数mov [esi], eax
L3: add esi,4 ;两个指针都向前移动一个元素loop L2 ;内循环pop ecx ;恢复外循环计数值loop L1 ;若计数值不等于0,则继续外循环
L4: ret
BubbleSort ENDP
END main
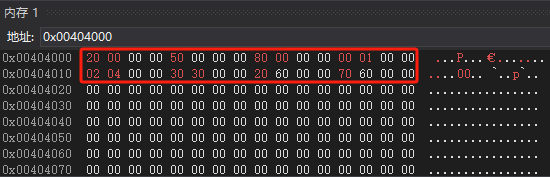
运行调试:
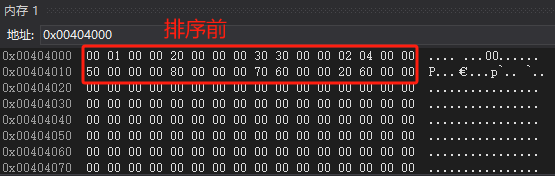
排序后
9.5.2 对半查找
数组查找是日常编程中最常见的一类操作。对小型数组(1000个元素或更少)而言,顺序查找(sequential search)是很容易的,从数组开始的位置顺序检查每一个元素,直到发现匹配的元素为止。对任意n个元素的数组,顺序查找平均需要比较 n/2 次。如果查找的是小型数组,则执行时间也很少。但是,如果查找的数组包含一百万个元素就需要相当多的处理时间了。
对半查找(binary search)算法用于从大型数组中查找一个数值是非常有效的。但是它有一个重要的前提:数组必须是按升序或降序排列。下面的算法假设数组元素是升序:
开始查找前,请求用户输入一个整数,将其命名为 searchVal。
1)被查找数组的范围用下标 first 和last 来表示。如果first >last,则退出查找,也就是说没有找到匹配项。
2)计算位于数组 first 和 last 下标之间的中点。
3)将searchVal与数组中点进行比较:
●如果数值相等,将中点送入EAX,并从过程返回。该返回值表示在数组中发现了匹配值。
●否则,如果 searchVal大于中点值,则将frst重新设置为中点后一位元素的位置。
●或者,如果searchVal小于中点值,则将last重新设置为中点前一位元素的位置。
4)返回步骤1)。
对半查找效率高的原因是它采用了分而治之的策略。每次循环迭代中,数值范围都被对半分为成两部分。通常它被描述为O(1ogn)算法,即,当数组元素增加"倍时,平均查找时间仅增加1og,倍。为了帮助了解对半查找效率有多高,表9-6列出了数组大小相同时,顺序查找和对半查找需要执行的最大比较次数。表中的数据代表的是最坏的情况--在实际应用中,经过更少次的比较就可能找到匹配数值。
表 9-6顺序查找与对半查找的最大比较次数 | ||
数组大小 | 顺序查找 | 对半查找 |
64 | 64 | 6 |
1 024 | 1 024 | 10 |
65 536 | 65 536 | 17 |
1 048 576 | 1 048 576 | 21 |
4 294 967 296 | 4 294 967 296 | 33 |
下面是用C++语言实现的对半查找功能,用于有符号整数数组:
//BinSearch.cpp 9.5.2 对半查找
//下面是用C++语言实现的对半查找功能,用于有符号整数数组:#include <iostream>using namespace std;int BinSearch(int values[], const int searchVal, int count)
{int first = 0;int last = count - 1;while (first <= last){int mid = (last + first) / 2;if (values[mid] < searchVal)first = mid + 1;else if (values[mid] > searchVal)last = mid - 1;elsereturn mid; //成功}return -1; //未找到
}int main()
{int arr[10] = { 10,15,20,25,30,35,40,45,50,55 };int index = BinSearch(arr, 40, 10);cout << "find 40 index========" << index << endl;index = BinSearch(arr, 60, 10);cout << "find 60 index========" << index << endl;return 0;
}运行结果:
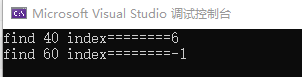
该 C++代码示例的汇编语言程序清单如下所示:
;BinarySearch.asm 9.5.2 对半查找.386
.model flat, stdcall
.stack 4096.code
;------------------------------------------
;BinarySearch
;在一个有符号整数数组中查找某个数值。
;接收:数组指针、数组大小、给定查找数值
;返回:若发现匹配项,则EAX=该匹配元素在数组中的位置;否则,EAX=-1。
;------------------------------------------
BinarySearch PROC USES ebx edx esi edi,pArray:PTR DWORD, ;数组指针Count:DWORD, ;数组大小searchVal:DWORD ;给定查找数值LOCAL first:DWORD, ;first的位置last:DWORD, ;last的位置mid:DWORD ;中点mov first, 0 ;first=0mov eax, Count ;last=(count-l)dec eaxmov last, eaxmov edi, searchVal ;EDI=searchValmov ebx, pArray ;EBX为数组指针
L1: ;mov eax, firstcmp eax, lastjg L5 ;退出查找;mid=(last+first)/2mov eax, lastadd eax, firstshr eax, 1mov mid, eax;EDX=values[mid]mov esi,midshl esi,2 ;将 mid 值乘4mov edx,[ebx+esi] ;EDX = values[mid];若EDX< searchVal(EDI)cmp edx,edijge L2;first=mid +1mov eax,midinc eaxmov first,eaxjmp L4;否则,若EDX>searchVal(EDI)
L2: cmp edx,edijle L3 ;可选项;last=mid-1mov eax,middec eaxmov last,eaxjmp L4;否则返回 mid
L3: mov eax,mid ;发现数值jmp L9 ;返回 mid
L4: jmp L1 ;继续循环
L5: mov eax,-1 ;查找失败
L9: ret
BinarySearch ENDP
END
测试程序
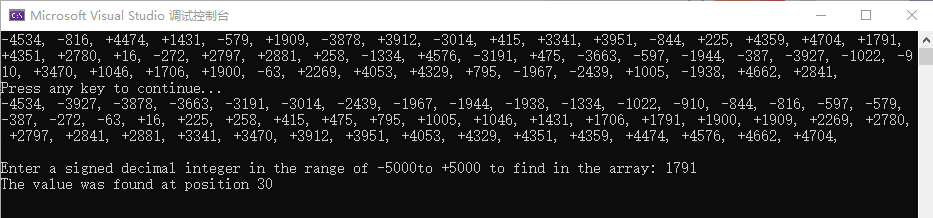
为了演示本章介绍的冒泡排序和对半查找功能,现在编写一个简单的程序顺序执行如下步骤:
●用随机整数填充数组
●显示该数组。
●用冒泡法对数组排序
●再次显示数组
●请求用户输入一个整数
●(在数组中)对半查找用户输人的整数
●显示对半查找的结果
每个过程都放在独立的源文件中,使得定位和编辑源代码更加方便。表 9-7 列出了每个模块及其内容。大多数编写专业的程序都会分为独立的代码模块。
表 9-7 冒泡排序/对半查找程序中的模块 | |
模块 | 内容 |
BinarySearchTest.asm | 主模块:包含main,ShowResult,和AskForSearchVal过程。包含程序入口,并管理整个任务序列 |
BubbleSort.asm | BubbleSort 过程:执行32位有符号整数数组的冒泡排序 |
BinarySearch.asm | BinarySearch 过程:执行32位有符号整数数组的对半查找 |
FillArray.asm | FilArray 过程:用一组随机数填充32位有符号整数数组 |
PrintArray.asm | PrintArray过程:将32位有符号整数数组写到标准输出 |
所有模块中的过程,除了BinarySearchTest.asm 外,都按照这种方式来编写,这易于在其他程序中使用它们而不用加以任何修改。这种做法相当可取,因为将来在重用已有代码时可以节约时间。Irvine32链接库就采用了同样的方法。下面的头文件(BinarySearch.inc)包含了被main 模块调用过程的原型:
;BinarySearch.inc 一冒泡排序/对半查找程序中使用的过程原型。;在32位有符号整数数组中查找一个数。
BinarySearch PROTO,pArray:PTR DWORD, ;指向数组Count:DWORD, ;数组大小searchVal:DWORD ;查找数值;用32位有符号随机整数填充数组
FillArray PROTO,pArray:PTR DWORD, ;指向数组Count:DWORD, ;元素个数LowerRange:SDWORD, ;随机数的下限UpperRange:SDWORD ;随机数的上限;将32位有符号整数数组写到标准输出
PrintArray PROTO,pArray:PTR DWORD,Count:DWORD;将数组按升序排列
BubbleSort PROTO,pArray:PTR DWORD,Count:DWORD
main模块,BinarySearchTest.asm的代码清单如下:
;BinarySearchTest.asm 冒泡排序和对半查找
;对一个有符号整数数组进行冒泡排序,并执行对半查找。
;main 模块,调用 BainarySearch,BubbleSort,FillArray和 PrintArrayINCLUDE Irvine32.inc
INCLUDE BinarySearch.inc ;过程原型
LOWVAL = -5000 ;最小值
HIGHVAL = +5000 ;最大值
ARRAY_SIZE = 50 ;数组大小AskForSearchVal PROTO
ShowResults PROTO.data
array DWORD ARRAY_SIZE DUP(?)
prompt BYTE "Enter a signed decimal integer "BYTE "in the range of -5000to +5000 "BYTE "to find in the array: ", 0msg1 BYTE "The value was not found.",0
msg2 BYTE "The value was found at position ", 0.code
main PROCcall Randomize;用有符号随机整数填充数组INVOKE FillArray, ADDR array, ARRAY_SIZE, LOWVAL, HIGHVAL;显示数组INVOKE PrintArray, ADDR array, ARRAY_SIZEcall WaitMsgcall Crlf;执行冒泡排序并再次显示数组INVOKE BubbleSort, ADDR array, ARRAY_SIZEINVOKE PrintArray, ADDR array, ARRAY_SIZE;实现对半查找call AskForSearchVal ;用EAX返回INVOKE BinarySearch, ADDR array, ARRAY_SIZE, eaxcall ShowResultsnopINVOKE ExitProcess, 0
main ENDP
;-------------------------------------------
;请求用户输入一个有符号整数。
;接收:无
;返回:EAX=用户输入的数值
;-------------------------------------------
AskForSearchVal PROCcall Crlfmov edx, OFFSET promptcall WriteStringcall ReadIntret
AskForSearchVal ENDP
;--------------------------------------------
;显示对半查找的结果值。
;接收:EAX=被显示数的位置
;返回:无
;--------------------------------------------
ShowResults PROC.IF eax == -1mov edx, OFFSET msg1call WriteString
.ELSEmov edx, OFFSET msg2call WriteStringcall WriteDec
.ENDIFcall Crlfcall Crlfret
ShowResults ENDP
END main
PrintArray 包含PrintArray 过程的模块清单如下:
;PrintArray.asm PrintArray 过程INCLUDE Irvine32.inc.data
comma BYTE ", ",0;------------------------------------------
;将32位有符号十进制整数数组写到标准输出,数值用逗号隔开
;接收:数组指针、数组大小
;返返回:无
;------------------------------------------
.code
PrintArray PROC USES eax ecx edx esi,pArray:PTR DWORD, ;数组指针Count:DWORD ;数组大小mov esi, pArraymov ecx, Countcld ;方向为正向
L1: lodsd ;加载[ESI]到EAXcall WriteInt ;发送到输出mov edx, OFFSET commacall WriteString ;显示逗号loop L1call Crlfret
PrintArray ENDP
END
FillArray 包含FillArray 过程的模块清单如下:
;FillArray.asm FillArray 过程INCLUDE Irvine32.inc.code
;------------------------------------------
;用LowerRange到(UpperRange-1之间的32位随机有符号整数序列填充数组。
;返回:无
;------------------------------------------
FillArray PROC USES eax edi ecx edx,pArray:PTR DWORD, ;数组指针Count:DWORD, ;元素个数LowerRange:SDWORD, ;范围下限UpperRange:SDWORD ;范围上限mov edi, pArray ;EDI为数组指针mov ecx, Count ;循环计数器mov edx, UpperRangesub edx, LowerRange ;EDX=绝对范围0..ncld ;方向标志位清零L1: mov eax, edx ;取绝对范围call RandomRange ; add eax, LowerRange ;偏移处理结果stosd ;将 EAX 保存到[edi]loop L1 ret
FillArray ENDP
END
BubbleSort 包含BubbleSort过程的模块清单如下:
;BubbleSort.asm 9.5.1 冒泡排序.386
.model flat, stdcall
.stack 4096.code
;------------------------------------------
;使用冒泡算法,将一个32位有符号整数数组按升序进行排列
;接收:数组指针,数组大小
;返回:无
;------------------------------------------
BubbleSort PROC USES eax ecx esi,pArray:PTR DWORD, ;数组指针Count:DWORD ;数组大小mov ecx, Countdec ecx ;计数值减1
L1: push ecx ;保存外循环计数值mov esi, pArray ;指向第一个数值
L2: mov eax, [esi] ;取数组元素值cmp [esi + 4], eax ;比较两个数值jg L3 ;如果[ESI]<=[ESI+4],不交换xchg eax, [esi+4] ;交换两数mov [esi], eax
L3: add esi,4 ;两个指针都向前移动一个元素loop L2 ;内循环pop ecx ;恢复外循环计数值loop L1 ;若计数值不等于0,则继续外循环
L4: ret
BubbleSort ENDP
END
运行调试:
9.5.3 本节回顾
1.假设一数组已经是顺序排列,则在 9.5.1 节的 BubbleSort 过程中,其外循环需要执行多少次?
答:n-1次
2.在 BubbleSort 过程中,第一次遍历数组时内循环需执行多少次?
答:n-1次
3.在 BubbleSort 过程中,内循环执行的次数是否总相同?
答:否,每次都要减1
4.若(通过测试)发现一个有500个整数的数组排序需要0.5秒,那么当数组含有5000个整数时,冒泡排序需要多少秒?
答:T(5000) = 0.5 * 秒
9.6 Java字节码:字符串处理(可选主题)
第8章介绍了Java字节码,并说明了怎样将java.class 文件反汇编为可读的字节码格式。本节将展示Java 如何处理字符串,以及处理字符串的方法。
示例:寻址子串
下面的Java代码定义了一个字符串变量,其中包含了一个雇员ID和该雇员的姓氏。然后,调用substring方法将账号送入第二个字符串变量:
String empInfo="10034Smith";
String id=empInfo.substring(0,5);
对该Java代码反汇编,其字节码显示如下:
0: ldc #32; //字符串10034Smith
2: astore_0
3: aload_0
4: iconst_0
5: iconst_5
6: invokevirtual #34; //Method java/lang/String.substring
9: astore_1现在分步研究这段代码,并加上自己的注释。ldc指令把一个对字符串文本的引用从常量池加载到操作数栈。接着,astore_0 指令从运行时堆栈弹出该字符串引用,并把它保存到局部变量emplnfo中,其在部变量区域中的索引为0;
0: ldc #32 //加载文本字符串:10034Smith
2: astore 0 //保存到empInfo(索引0)接下来,aload 0指令把对emplnfo的引用压入操作数栈:
3:aload_0 //加载empInfo 到堆栈然后,在调用 substring 方法之前,它的两个参数(0和5)必须压人操作数栈。该操作由指令iconst 0 和iconst 5 完成:
4:iconst_0
5:iconst_5invokevirtual指令调用substring方法,它的引用ID号为34:
6:invokevirtual #34; // Method java/lang/String.substringsubstring 方法将参数弹出堆栈,创建新字符串,并将该字符串的引用压人操作数栈。其后的 astore_1指令把这个字符串保存到局部变量区域内索引 1的位置,也就是变量 id 所在的位置:
9: astore_19.7 本章小结
为了对内存进行高速访问,对字符串原语指令进行了优化,这些指令包括
●MOVS:传送字符串数据
●CMPS:比较字符串
●SCAS:扫描字符串
●STOS:存储字符串数据
●LODS:将字符串加载到累加器
在对字节、字或双字进行操作时,每个字符串原语指令都分别加上后缀B、W或D。
前缀REP 利用变址寄存器的自动增减重复执行字符串原语指令。例如,REPNE 与SCASB组合时,它就一直扫描内存字节单元,直到由EDI指向的内存数值等于 AL 寄存器中的值。每次执行字符串原始指令过程中,方向标志位DF决定变址寄存器是增加还是减少。
字符串和数组实际上是一样的。以往,一个字符串就是由单字节 ASCII码数组构成的,但是现在字符串也可以包含16位Unicode字符。字符串与数组之间唯一的重要区别就是字符串通常用一个空字节(包含 0)表示结束。
数组操作是计算密集型的,因为一般它会涉及循环算法。大多数程序 80%~ 90%的运行时间都用来执行其代码的一小部分。因此,通过减少循环中指令的条数和复杂度就可以提高软件的速度。由于汇编语言能控制每个细节,所以它是极好的代码优化工具。比如,通过用寄存器来代替内存变量,就能够优化代码块。或者可以使用本章介绍的字符串处理指令,而不是用MOV和CMP指令。
本章介绍了几个有用的字符串处理过程:Strcopy过程将一个字符串复制到另一个字符串。Str_length 过程返回字符串的长度。Str_compare 比较两个字符串。Str_trim 从一个字符串尾部删除指定字符。Str ucase 将一个字符串转换为大写字母。
基址-变址操作数有助于处理二维数组(表)。可以将基址寄存器设置为表的行地址,而将变址寄存器设置为被选择行的列偏移量。32 位模式中,所有 32 位通用寄存器都可以被用作基址和变址寄存器。基址-变址-偏移量操作数与基址-变址操作数类似,不同之处在于,前者还包含数组名:
[ebx + esi] ;基址-变址
array[ebx + esi] ;基址-变址-偏移量本章还用汇编语言实现了冒泡排序和对半查找。冒泡排序把一个数组中的元素按照升序或降序排列。对几百个元素的数组来说,它有很好的效率,但是对元素个数更多的数组则效率很低。对半查找在顺序排列的数组中实现单个数值的高速搜索。它易于用汇编语言实现。
9.8 关键术语和指令
