【机器人】HOV-SG 开放词汇 | 分层3D场景图 | 语言引导机器人导航
HOV-SG 结合开放词汇能力,提出分层3D场景图;(楼层级、房间级、对象级)
通过语言指令实现机器人导航的,核心特点是分层结构、开放词汇、3D场景图。
开放词汇,对物体和环境进行 语义特征提取与融合,能理解未预定义的类别。
来自RSS 2024,大规模、多层次的环境构建精确的、开放词汇的3 场景图,并使机器人能够通过语言指令在其中有效地导航。
论文地址:Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
代码地址:https://github.com/hovsg/HOV-SG
论文复现:https://blog.csdn.net/qq_41204464/article/details/149006741?spm=1001.2014.3001.5501
1、框架思路流程
HOV-SG 的框架流程,如下图所示,从原始 RGB-D 数据输入,到场景图构建,再到语言引导导航应用。
可拆解为 “特征提取→片段融合→场景图构建与语言导航” 三大核心阶段。
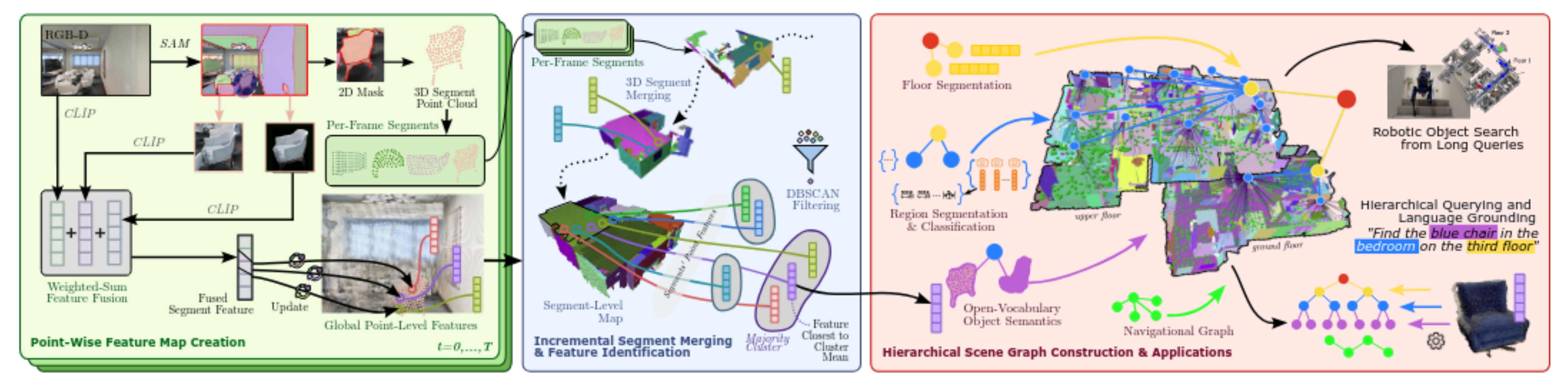
1.1、阶段 1:点级特征映射(Point-Wise Feature Map Creation)
目标:从 RGB-D 帧中提取开放词汇特征,为后续 3D 片段语义理解打基础。
- 输入:连续 RGB-D 帧(t=0→T),包含颜色和深度信息。
- 关键流程:
- SAM 分割:用 Segment Anything Model(SAM)生成 2D 掩码(Mask),投影到 3D 点云,得到逐帧 3D 片段(Per-Frame Segments)。
- 多源 CLIP 特征提取:对每个片段,提取三类 CLIP 特征:
- 全局图像特征(CLIP 对完整 RGB 图的编码);
- 带背景掩码特征(CLIP 对 “掩码 + 背景” 区域的编码);
- 无背景掩码特征(CLIP 对 “仅掩码” 区域的编码)。
- 作用:用 CLIP 实现 “开放词汇语义” 与 3D 点云的绑定,让片段具备识别任意类别(如 “电竞椅”“复古桌” )的潜力。
1.2、阶段 2:增量片段融合(Incremental Segment Merging & Feature Identification)
目标:解决逐帧分割的 “重复片段” 问题,构建稳定的3D片段地图。
- 核心问题:连续帧中同一物体可能被重复分割(如移动机器人视角变化时,椅子被拆分为多个片段 ),需合并冗余片段。
- 关键流程:
- 3D 片段合并:基于点云空间重叠度,合并同一物体的多帧片段,生成更完整的 3D 片段。
- DBSCAN 滤波:对片段内的点级特征聚类,筛选 “多数簇”(Majority Cluster),去除噪声点),用簇中心特征代表片段,提升鲁棒性。
- 输出:片段级地图,每个片段关联稳定的开放词汇特征,解决动态视角下的分割不一致问题。
阶段3 包含分层场景图构建、语言引导导航应用
1.3.1、阶段 3-1:分层场景图构建(Hierarchical Scene Graph Construction)
目标:将 3D 片段组织为 “楼层 - 区域 - 物体” 的分层语义结构,适配语言导航需求。
- 层级构建流程:
- 楼层分割(Floor Segmentation):分析点云高度直方图的密度峰值(如 0.2 米内的高度聚类 ),用 DBSCAN 分割楼层,构建楼层节点(红色 / 黄色节点 )。
- 区域分割与分类(Region Segmentation & Classification):在单楼层内,通过鸟瞰图(BEV)的墙壁掩码 + 分水岭算法分割房间区域;提取每个区域的 10 个代表性视图嵌入,用 CLIP 与文本(如 “office”“kitchen” )匹配,实现区域分类,构建房间节点(蓝色节点 )。
- 开放词汇物体语义(Open-Vocabulary Object Semantics):将 3D 片段(物体)与所属房间关联(通过 BEV 重叠度或距离 ),构建物体节点(紫色节点 ),形成 “楼层→房间→物体” 的层级边关系。
- 导航图构建(Navigational Graph):在自由空间(无障碍物区域)构建跨楼层 Voronoi 图,连接各楼层节点,支持路径规划。
- 输出:分层 3D 场景图,包含语义节点(楼层、房间、物体)和导航边(路径可行性)。
1.3.2、阶段 3-2:语言引导导航应用(Applications)
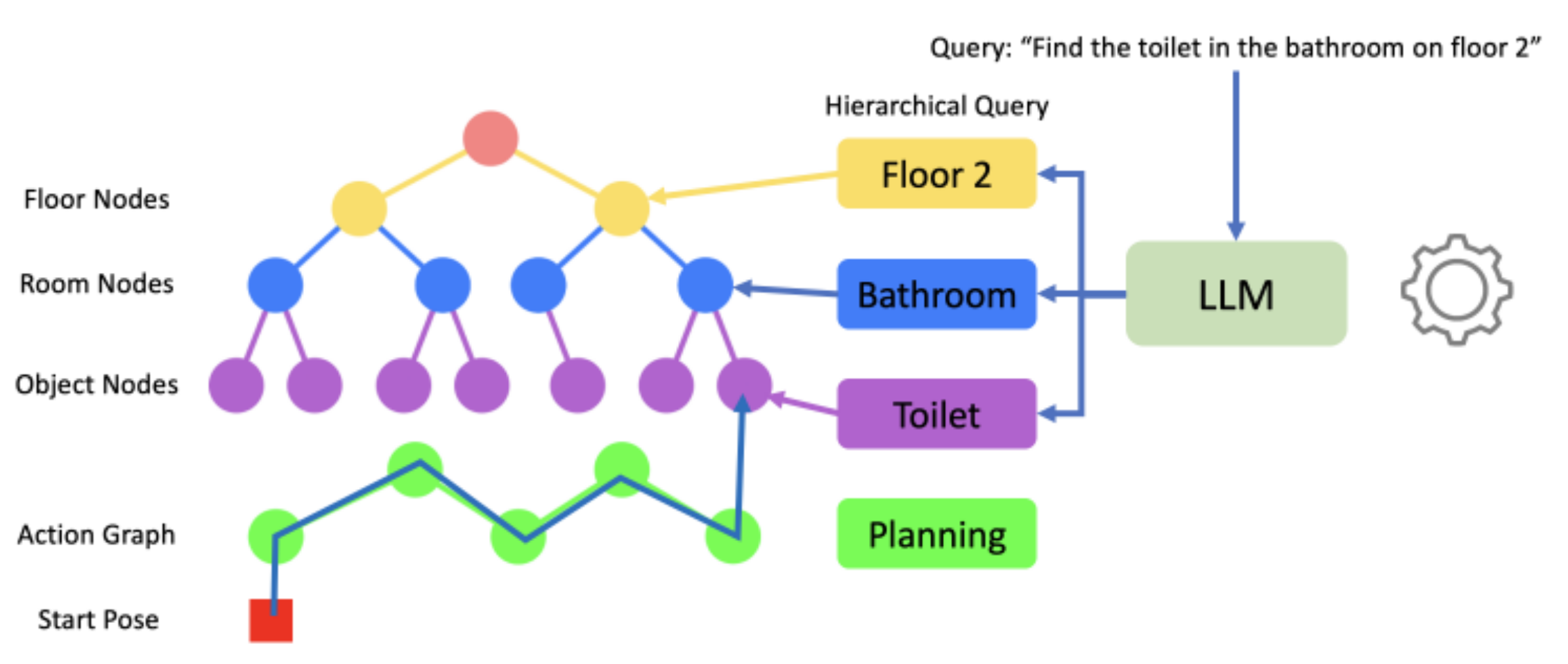
目标:将自然语言查询转化为场景图检索与导航行动,实现 “语言接地”。
- 语言查询拆解:用 LLM(如 GPT-3.5)将长指令(如 “Find the blue chair in the bedroom on the third floor” )拆解为 “楼层(third floor)- 区域(bedroom)- 物体(blue chair)” 三级子查询。
- 层级语义匹配:
- 楼层匹配:用 CLIP 特征余弦相似度,筛选场景图中对应楼层节点;
- 区域匹配:在楼层内,用视图嵌入匹配房间节点;
- 物体匹配:在房间内,用片段特征匹配物体节点。
- 路径规划与执行:基于导航图,规划从机器人当前位姿到目标物体的路径,支持跨楼层移动(如楼梯连接 ),完成 “语言指令→物理导航” 的闭环(Robotic Object Search from Long Queries)。
2、3D片段级 开放词汇映射
从机器人采集的 RGB-D 视频与“里程计”数据中,生成带有开放词汇语义特征的 3D 片段集合,为后续构建分层场景图提供基础。
3D空间中相邻的点,通常属于同一语义对象(如沙发的相邻点都属于 “沙发”),因此可将这些点合并为 “片段”(连续的 3D 点云),每个片段仅需一个代表性语义特征,大幅减少特征数量。
关键步骤 1:帧级 3D 片段融合 —— 构建完整的 3D 对象
该步骤的目的是将不同时刻、不同视角下拍摄的同一物体的局部片段,合并为完整的 3D 对象片段。具体流程如下:
- 2D 掩码提取:使用 SAM模型,对 RGB-D 视频的每一帧提取 2D 二进制掩码(即框出图像中的物体区域,如 “椅子”“桌子” 的 2D 范围)。
- 3D 反投影:结合深度信息,将 2D 掩码中的像素反投影到 3D 空间,生成局部 3D 点云(即该帧中物体的 3D 片段)。
- 全局融合:基于机器人的里程计数据(定位信息),将所有帧的 3D 片段转换到统一的全局坐标系。通过 “重叠度 metric” 判断片段是否属于同一物体。
- 创新融合策略:构建 “全连接图”(每个片段为节点,边权重为重叠度),合并高度连通的子图。这使得一个新片段可同时与多个已有片段合并,能填补片段间的间隙(如椅子的扶手和主体分别被拍摄,可通过该策略合并为完整椅子)。
关键步骤 2:片段级开放词汇特征计算 —— 赋予片段 “语言理解能力”
为每个 3D 片段分配能理解自然语言的特征(如 “沙发” 的特征能与文字 “沙发”“懒人沙发” 匹配),具体流程如下:
- 多源特征提取:对每个 2D SAM 掩码,提取三类图像的 CLIP 特征(CLIP 是能关联图像与文字的预训练模型):
- 全 RGB 帧特征(fg):包含物体的上下文信息;
- 掩码裁剪图像特征(fl):含背景的物体局部图像;
- 无背景掩码图像特征(fm):仅物体本身的图像。
- 特征融合:通过加权求和融合三类特征,公式为:fi = wgfg + wlfl + wmfm
其中权重之和为 1。这种融合平衡了上下文与物体细节,比仅用单一特征(如仅无背景掩码特征)的效果更优。 - 点级特征到片段特征的映射:将 2D 掩码的融合特征关联到全局 3D 点云中的最近点,得到点级特征;再对每个 3D 片段的所有点级特征进行 DBSCAN 聚类,选取最接近多数簇均值的特征作为该片段的代表性特征。这一步可去除噪声(如片段中混入的无关点特征),避免模式坍缩,增强语义准确性。
3D 片段级开放词汇映射为 HOV-SG 奠定了基础:
- 效率提升:通过片段合并减少了特征数量,为后续分层场景图的轻量存储提供可能;
- 语义增强:多源特征融合与聚类去噪,使片段特征更准确地匹配语言描述;
- 兼容性:片段级表示自然支持后续 “楼层 - 房间 - 物体” 的分层关联(如将椅子片段关联到 “办公室” 房间)。
3、分层场景图构建
核心是将 3D 点云环境拆解为 “楼层→房间” 的层级结构,为后续语义导航打基础。
可按 “垂直分层(楼层分割)→水平分割(房间分割)” 两步解析:
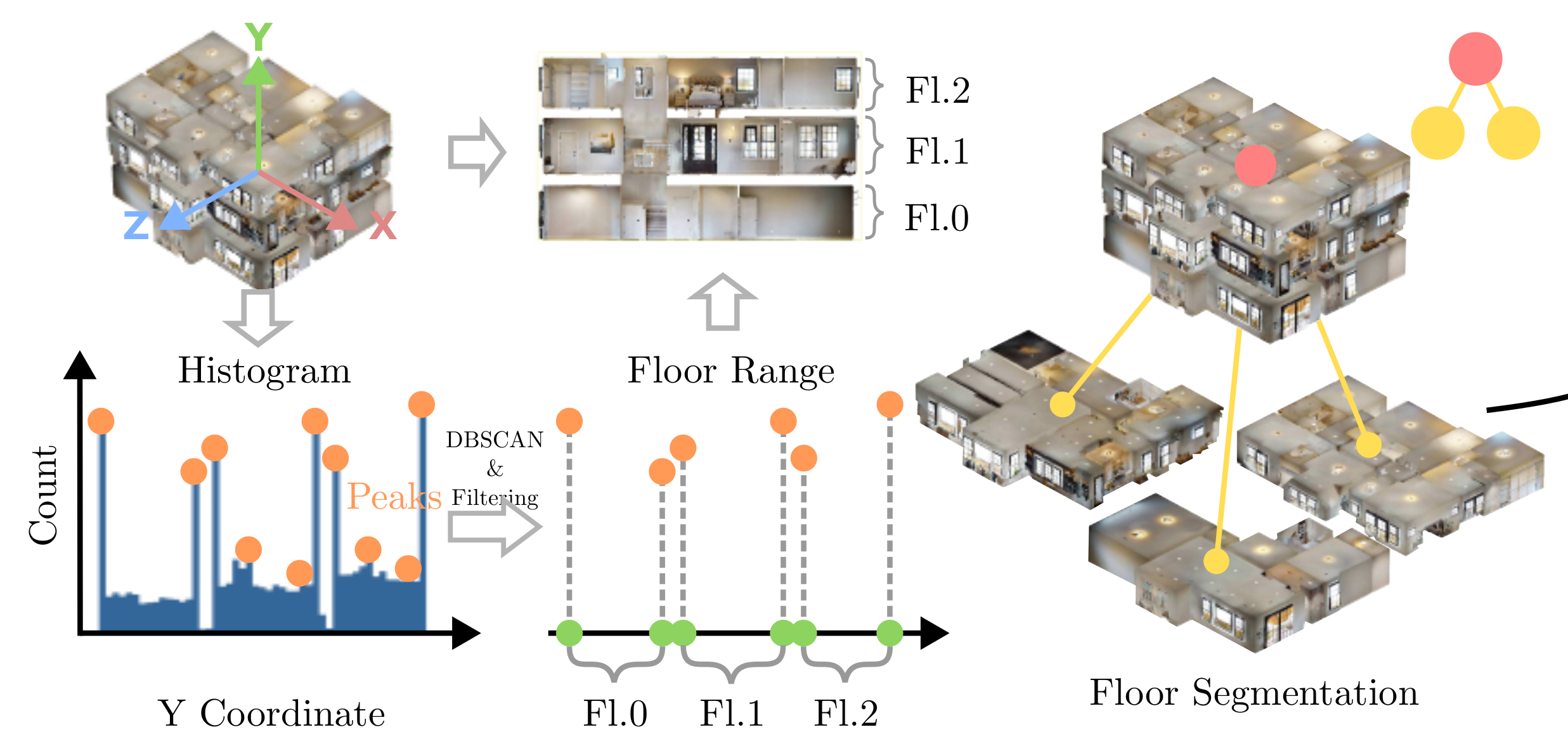
3.1、垂直分层:楼层分割(Floor Segmentation)
目标:识别多层建筑的垂直楼层边界,将 3D 点云按高度划分为独立楼层。
-
高度直方图分析(Histogram):
- 统计点云在 Y 轴(垂直方向)的坐标分布,生成高度直方图(如左图,横轴 Y 坐标,纵轴点数量)。
- 核心逻辑:楼层间因楼梯 / 楼板存在高度差,直方图会呈现 “峰值簇”(Peak),代表不同楼层的点云聚集区。
-
DBSCAN 聚类滤波(DBSCAN & Filtering):
- 对直方图峰值聚类,筛选出密集且稳定的簇(如 F1.0、F1.1、F1.2 ),作为楼层的高度范围(Floor Range)。
- 作用:过滤噪声峰值(如家具、人体等局部高度变化),精准识别楼层边界。
-
3D 楼层分割(Floor Segmentation):
- 根据筛选的 Y 轴范围,分割 3D 点云为独立楼层(如 F1.0、F1.1、F1.2 ),构建楼层节点(红色 / 黄色节点 )。
- 输出:每个楼层对应独立的 3D 子点云,为房间分割提供垂直范围约束。
3.2、水平分割:房间分割(Room Segmentation)
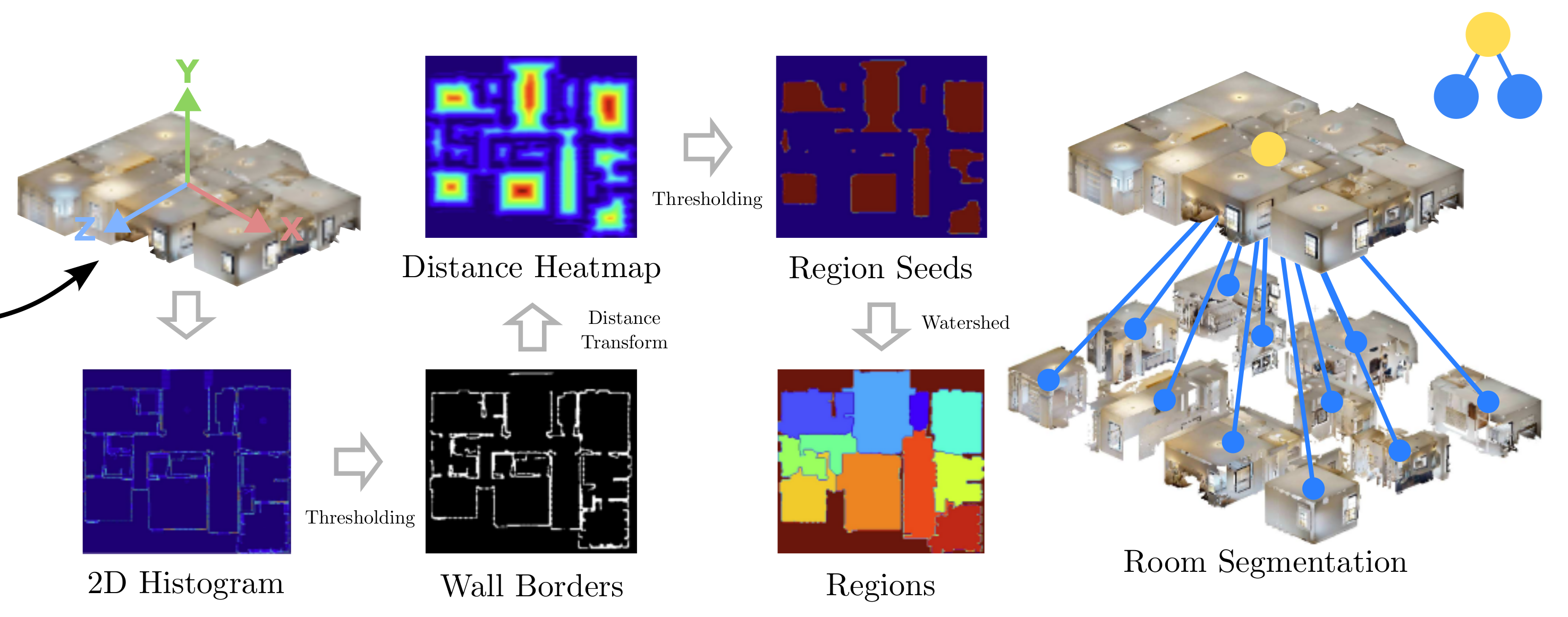
目标:在单楼层内,识别水平方向的房间边界,将楼层划分为独立区域。
-
2D 鸟瞰图转换(2D Histogram):
- 将单楼层的 3D 点云投影到 XY 平面(鸟瞰视角),生成 2D 高度直方图(如中图蓝色热力图 )。
-
墙壁边界提取(Wall Borders):
- 对 2D 直方图进行距离变换(Distance Transform)和阈值化(Thresholding),提取墙壁的 2D 掩码(黑色轮廓 )。
- 核心逻辑:墙壁是房间的物理边界,在鸟瞰图中表现为 “高密集条带”,距离变换后形成清晰轮廓。
-
房间种子生成(Region Seeds):
- 对墙壁掩码反向阈值化(如右图红色热力图 ),生成房间种子点(Region Seeds)。
- 作用:种子点代表房间的核心区域,为分水岭算法提供分割起点。
-
分水岭算法分割(Watershed):
- 以墙壁掩码为 “水坝”,种子点为 “水源”,执行分水岭算法,分割出独立房间区域(彩色块 )。
- 输出:单楼层内的房间分割结果(如蓝色节点 ),每个房间对应 3D 点云的子区域。
流程本质:从 “3D 空间” 到 “层级语义” 的拆解。
整个流程的核心是 “垂直分层 + 水平分块”,将复杂 3D 环境按人类认知逻辑(楼层→房间)结构化:
- 垂直方向:用高度直方图 + DBSCAN,解决多层建筑的楼层划分;
- 水平方向:用鸟瞰图 + 分水岭,解决单楼层的房间划分。
4、房间类型识别
通过多视图 CLIP 特征与文本特征匹配,实现房间类型的开放词汇分类(如 “卧室”“餐厅” ),为分层场景图赋予语义。
可拆解为 “特征提取→聚类降维→语义匹配” 三步:
4.1、多视图特征提取(Room View CLIP Features)
目标:为每个房间提取代表性视觉特征,覆盖房间内的多样视角。
- 输入:房间区域(Room Regions)及关联的相机位姿(Associated Camera Views),即机器人在该房间采集的多视角 RGB 图像。
- 关键操作:
- 对每个相机视角的 RGB 图像,用 CLIP 模型提取图像特征(Room View CLIP Features),捕捉房间的视觉语义(如 “床、衣柜” 对应卧室特征 )。
- 作用:多视图特征覆盖房间内不同角度(如进门视角、窗边视角 ),避免单一视角的偏差,提升鲁棒性。
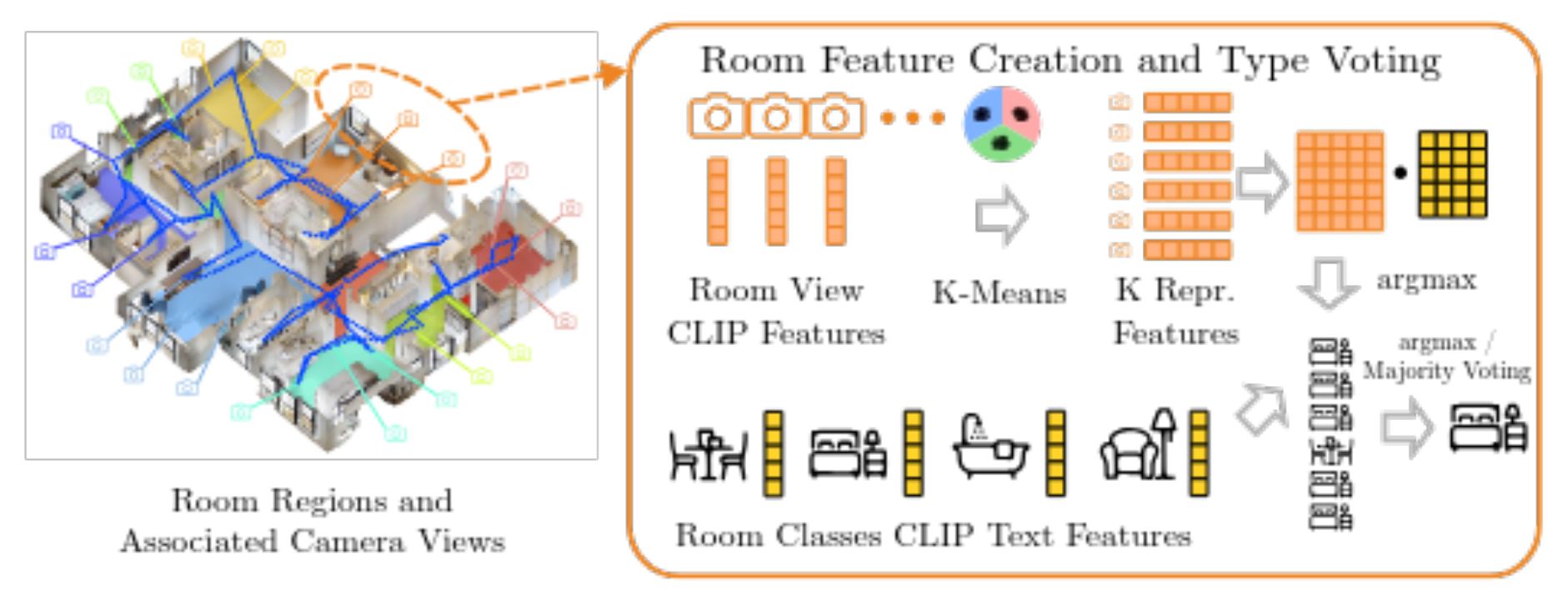
4.2、聚类降维(K-Means → K Repr. Features)
目标:从多视图特征中筛选最具代表性的 “原型特征”,降低计算成本。
-
K-Means 聚类:
- 将房间的所有视图 CLIP 特征输入 K-Means 算法(实验中 K=10 ),聚成 10 个簇(Cluster)。
- 核心逻辑:相似视角的特征会聚为一类(如房间内靠窗的多个视角可能聚为一簇 )。
-
提取原型特征(K Repr. Features):
- 对每个簇,计算簇中心特征(Closest to Mean),作为该簇的 “原型特征”(K Representative Features)。
- 作用:用 10 个原型特征替代大量原始视图特征,在保留语义信息的同时,大幅压缩数据量。
4.3、语义匹配与投票(Room Classes CLIP Text Features → argmax/Majority Voting)
目标:将原型特征与房间类型文本特征匹配,通过投票确定房间类型。
-
文本特征准备(Room Classes CLIP Text Features):
- 预定义房间类型的文本描述(如 “dinning room”“bedroom” ),用 CLIP 提取对应的文本特征(Text Features)。
-
跨模态匹配:
- 计算每个原型特征与所有房间类型文本特征的余弦相似度(如卧室特征与 “bedroom” 文本特征相似度高 )。
-
投票决策:
- argmax 投票:对每个原型特征,取相似度最高的文本类别(argmax);
- Majority Voting:统计 10 个原型特征的类别投票,取多数票作为房间最终类型(如 7 个原型特征匹配 “bedroom”,则判定为卧室 )。
流程本质:用 CLIP 实现 “视觉 - 语言” 对齐的房间分类。
整个流程的核心是 “多视图采样→特征聚类→跨模态投票”,解决房间类型识别的两大难题:
- 视角多样性:通过多相机视图和 K-Means 聚类,覆盖房间内不同角度,避免单一视角偏差;
- 开放词汇适配:借助 CLIP 的视觉 - 语言对齐能力,无需重新训练模型,即可识别新房间类型(如 “电竞房” )。
5、导航图构建
为机器人在多层建筑中规划路径,构建 “单层可通行图 + 跨层连接图”。
流程本质:从 “单楼层通行” 到 “跨楼层连通” 的路径网络。
5.1、单层导航图构建(Single-floor Navigational Graph)
目标:在单楼层内,识别可通行区域并构建 Voronoi 图,支持路径规划。
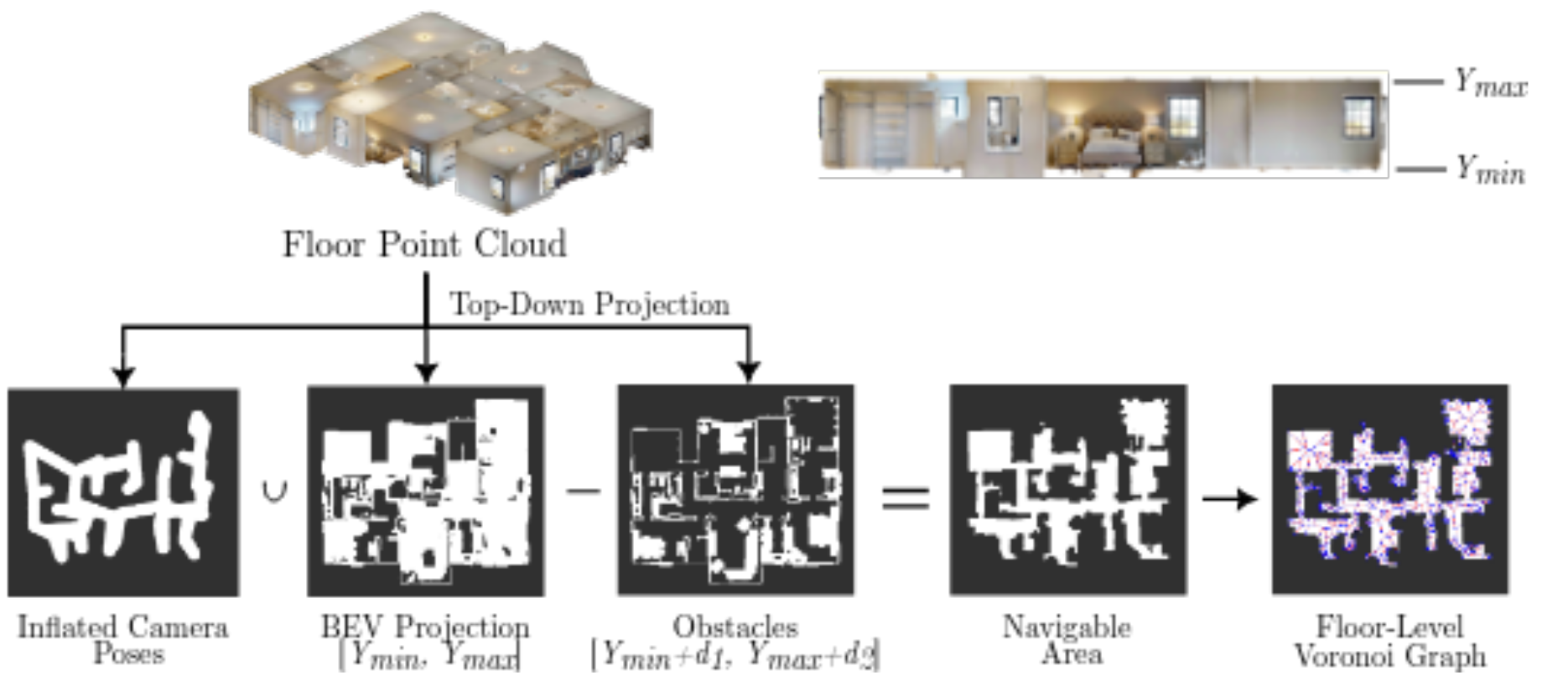
- 输入:单楼层点云(Floor Point Cloud)、相机位姿(Inflated Camera Poses)、障碍物信息(Obstacles)。
- 关键流程:
- 投影与 mask 生成:
- 将楼层点云 “顶视投影”(Top-Down Projection)到 2D 鸟瞰图(BEV);
- 膨胀相机位姿(Inflated Camera Poses,扩大相机占据空间,避免路径穿过相机 );
- 提取障碍物 mask(Obstacles,如家具、墙壁 )。
- 可通行区域计算(Navigable Area):
- 用公式 Navigable=BEV−(Obstacles∪Inflated Camera Poses) ,扣除障碍物和相机占据的空间,得到机器人可通行的 2D 区域(白色部分 )。
- Voronoi 图构建(Floor-Level Voronoi Graph):
- 在可通行区域内,构建 Voronoi 图(紫色点线结构 ),Voronoi 边沿可通行区域边界分布,为路径规划提供 “骨架”。
- 投影与 mask 生成:
- 作用:Voronoi 图的边是机器人最优路径的近似(如沿走廊、绕开障碍物 ),降低路径规划的计算复杂度。
5.2、跨层导航图构建(Cross-floor Navigational Graph)
目标:连接不同楼层的导航图,支持跨楼层路径规划(如通过楼梯)。
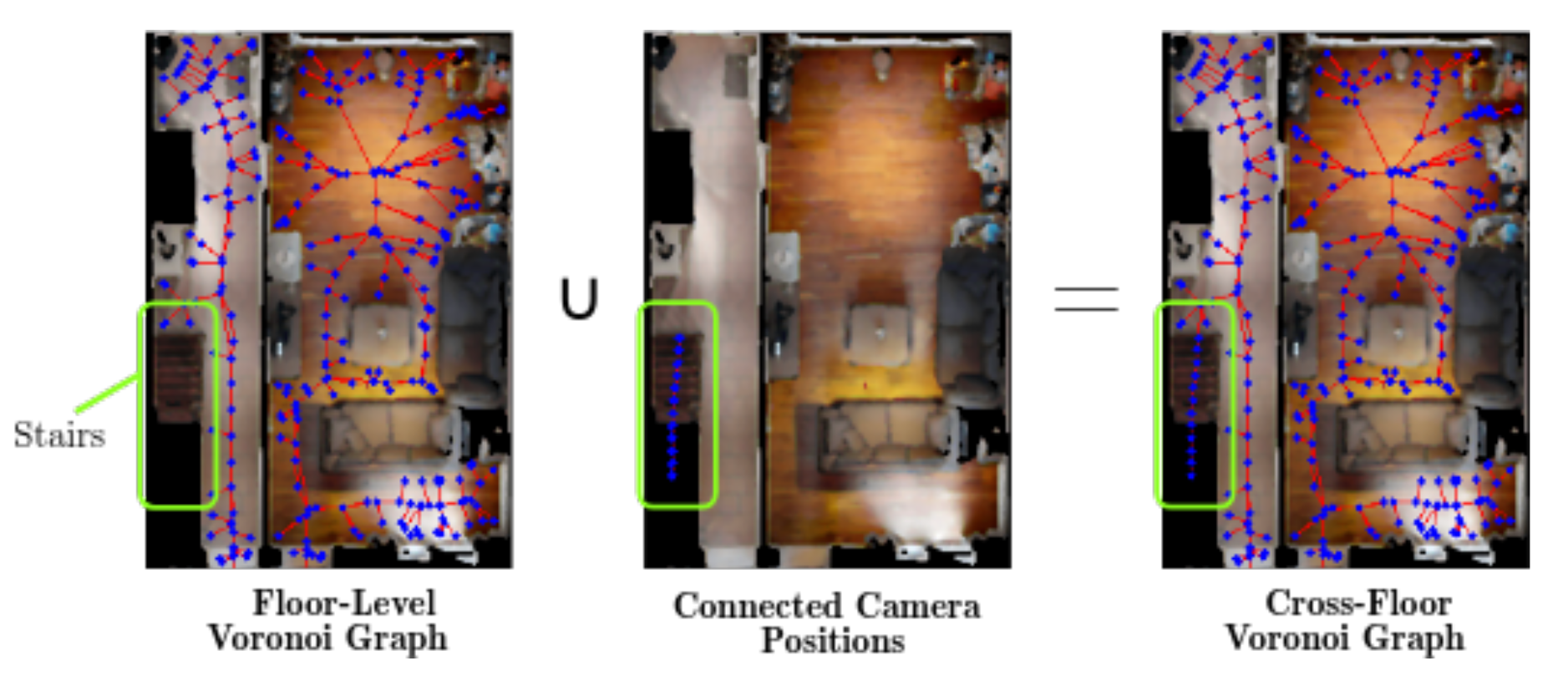
- 输入:各楼层的 Voronoi 图(Floor-Level Voronoi Graph)、楼梯区域的相机位姿(Connected Camera Positions,机器人在楼梯处的可通行位姿 )。
- 关键流程:
- 识别楼梯连接(Stairs):
- 在单楼层 Voronoi 图中,标记楼梯区域(绿色框 ),该区域是跨楼层的 “通道”。
- 跨层位姿连接(Connected Camera Positions):
- 提取楼梯区域内,不同楼层的相机位姿(如 F1 楼梯口和 F2 楼梯口的位姿 ),作为跨层连接点。
- 跨层 Voronoi 图合并(Cross-Floor Voronoi Graph):
- 将各楼层 Voronoi 图,通过楼梯连接点合并,形成跨楼层的连续导航图(蓝色点线结构贯通 F1 和 F2 )。
- 识别楼梯连接(Stairs):
- 作用:让机器人能规划跨楼层路径(如从 F1 客厅→楼梯→F2 卧室 ),实现多层建筑的长距离导航。
流程本质:用 CLIP 实现 “视觉 - 语言” 对齐的房间分类
整个流程的核心是 “多视图采样→特征聚类→跨模态投票”,解决房间类型识别的两大难题:
- 视角多样性:通过多相机视图和 K-Means 聚类,覆盖房间内不同角度,避免单一视角偏差;
- 开放词汇适配:借助 CLIP 的视觉 - 语言对齐能力,无需重新训练模型,即可识别新房间类型(如 “电竞房” )。
这种设计为 HOV-SG 的 “语言引导导航” 提供物理路径基础 。
当机器人需执行 “三楼卧室取物” 指令时,导航图能规划出 “当前楼层→楼梯→目标楼层→目标房间” 的完整路径,是实现实际导航的关键支撑。
6、实验验证与结果
真实世界语言引导导航评估,验证 HOV-SG 在真实多层建筑中的实用性
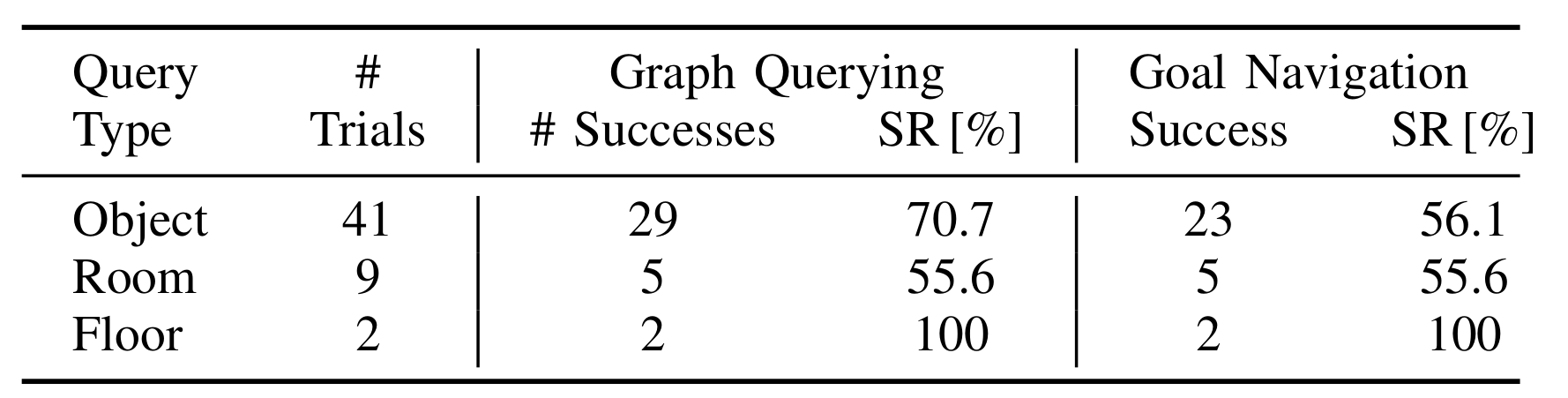
- 使用波士顿动力 Spot 机器人,在两层办公楼中采集数据,构建 HOV-SG;
- 测试 41 个对象目标、9 个房间目标、2 个楼层目标,基于自然语言指令(如 “find the plant in the office on floor 0”)评估。
- 检索成功率:楼层 100%,房间 55.6%,对象 70.7%;
- 导航成功率:对象 56.1%,房间和楼层 100%。
波士顿动力 Spot 机器人:

在HM3D数据集,可视化分层3D场景图的效果
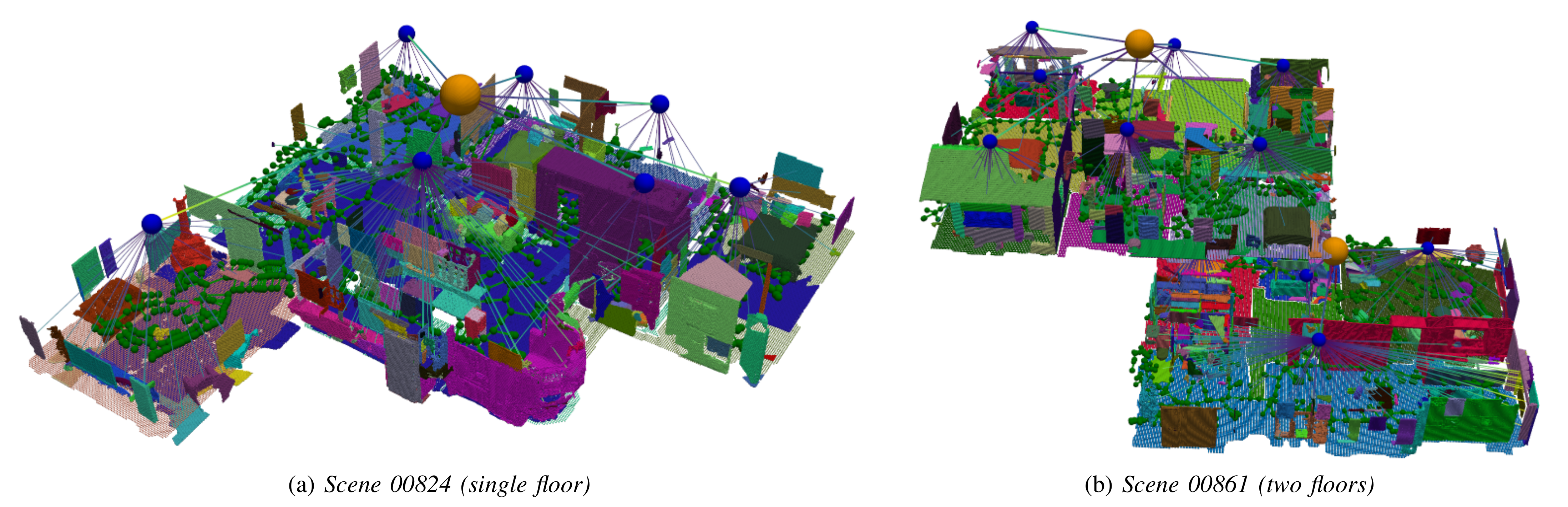
HM3DSem 数据集中,多层环境下语言引导导航的可视化效果。
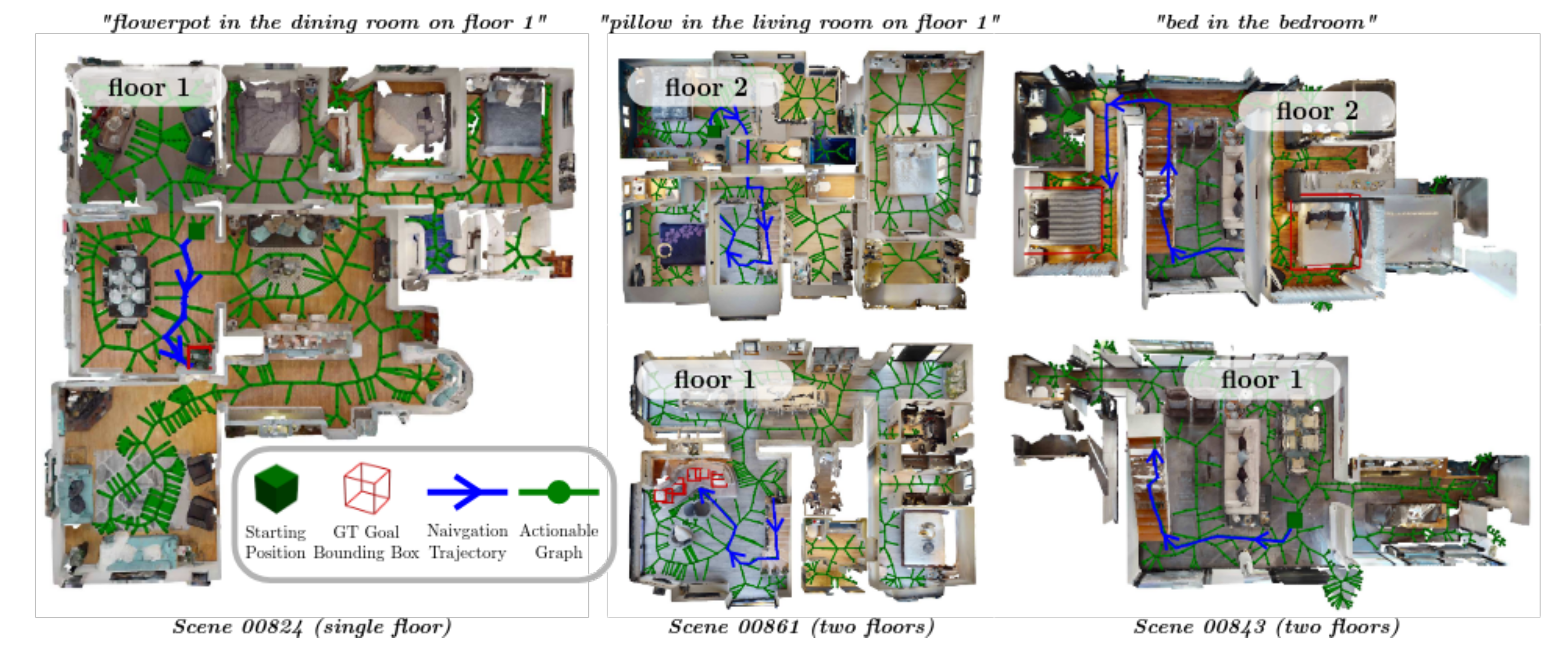
- 在某些情况下,存在多个与指令匹配的地面真实物体。
- 在 1 米以内的距离内,停在任何一个地面真实物体上均视为成功。
分享完成~
相关文章推荐:
UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】具身导航 VLN 最新论文汇总 | Vision-and-Language Navigation-CSDN博客
【机器人】复现 UniGoal 具身导航 | 通用零样本目标导航 CVPR 2025-CSDN博客
【机器人】复现 WMNav 具身导航 | 将VLM集成到世界模型中-CSDN博客
【机器人】复现 ECoT 具身思维链推理-CSDN博客
【机器人】复现 SG-Nav 具身导航 | 零样本对象导航的 在线3D场景图提示-CSDN博客
【机器人】复现 3D-Mem 具身探索和推理 | 3D场景记忆 CVPR 2025 -CSDN博客
【机器人】复现 Embodied-Reasoner 具身推理 | 具身任务 深度推理模型 多模态场景 长远决策 多轮互动_embodied reasoner-CSDN博客
【机器人】DualMap 具身导航 | 动态场景 开放词汇语义建图 导航系统-CSDN博客
【机器人】ForesightNav | 高效探索 动态场景 CVPR2025_pointnav中的指标介绍-CSDN博客
【机器人】复现 HOV-SG 机器人导航 | 分层 开放词汇 | 3D 场景图-CSDN博客
【机器人】复现 DOV-SG 机器人导航 | 动态开放词汇 | 3D 场景图-CSDN博客
【机器人】复现 Aether 世界模型 | 几何感知统一 ICCV 2025-CSDN博客
【机器人】Aether 多任务世界模型 | 4D动态重建 | 视频预测 | 视觉规划 -CSDN博客
【机器人】REGNav 具身导航 | 跨房间引导 | 图像目标导航 AAAI 2025-CSDN博客