mysql 慢sql优化篇
介绍
SQL 优化的核心目标是在保证结果正确性的前提下,减少数据库系统的资源消耗(CPU、IO、内存、网络)和提高查询响应速度。
如何定位识别慢sql
1、启用数据库慢sql日志监控
配置并启用数据库的慢查询日志,记录执行时间超过阈值的 SQL 语句。这是最直接有效的方法。(或者可以在应用中写mybatis拦截器,在invocation.proceed的前后增加时间统计,超过时间进行Cat告警发邮件给通知运维人员)
- 通过 SQL 命令开启数据库慢sql监控日志(临时生效,重启失效,永久生效的话需修改mysql配置文件)
-- 启用慢查询日志
SET GLOBAL slow_query_log = 'ON';-- 设置日志文件路径
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';-- 设置时间阈值(单位:秒)
SET GLOBAL long_query_time = 1; -- 生产环境将阈值设为更合理的值(如0.1-0.5秒)-- SET SESSION long_query_time = 1; -- 使当前会话立即生效, SET GLOBAL 只影响*新连接*的会话,不影响已存在的会话-- 启用记录未使用索引的查询(可选)
SET GLOBAL log_queries_not_using_indexes = 'ON';-- 验证配置是否生效
SHOW VARIABLES LIKE 'slow_query_log'; -- 应返回 ON
SHOW VARIABLES LIKE 'slow_query_log_file'; -- 返回路径
SHOW VARIABLES LIKE 'long_query_time'; -- 应返回 1.000000
验证分析慢查询日志
执行一个慢查询:
SELECT SLEEP(1.5); -- 故意执行一个1.5秒的查询
查看日志文件 /var/log/mysql/slow.log
root@ffbaa4d467a9:/var/log/mysql# more slow.log
/usr/sbin/mysqld, Version: 8.0.18 (MySQL Community Server - GPL). started with:
Tcp port: 3306 Unix socket: /var/run/mysqld/mysqld.sock
Time Id Command Argument
# Time: 2025-07-15T03:31:45.217230Z
# User@Host: root[root] @ [172.17.0.1] Id: 13
# Query_time: 2.008421 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
use codereactor;
SET timestamp=1752550303;
/* ApplicationName=DBeaver 25.0.4 - SQLEditor <Script-2.sql> */ SELECT SLEEP(2)
LIMIT 0, 200;
使用日志分析工具
# 使用mysqldumpslow分析日志
mysqldumpslow -s t /var/log/mysql/slow.log# 输出示例:
root@ffbaa4d467a9:/var/log/mysql# mysqldumpslow -s t slow.logReading mysql slow query log from slow.log
Count: 1 Time=2.01s (2s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@[172.17.0.1]/* ApplicationName=DBeaver N.N.N - SQLEditor <Script-N.sql> */ SELECT SLEEP(N)LIMIT N, Nmysqldumpslow 是 MySQL 官方提供的慢查询日志分析工具,用于汇总和解析慢查询日志文件。
-s t:排序选项,按总查询时间(Total time)排序
可以使用linux的logrotate定期日志轮转,删除日志防止日志过大
2、工具定位慢sql
使用数据库提供的性能监控工具定位执行时间长、消耗资源多的 SQL。如使用Prometheus MySQL 性能监控,调试工具Arthas看执行耗时。
3、通过业务人员反馈或页面反应
关注用户反馈慢的操作或业务系统中性能瓶颈点。
4、通过语法/索引使用情况/数据量分析定位
通过查看sql语句语法判断是否可优化,如多表查询left join、深度分页查询等使用不当。
通过执行计划查看索引使用情况
通过表数据量分析,过大可以重新进行数据库设计
通过索引优化慢sql查询
1、了解索引
索引 (index) 是帮助MysoL高效获取数据的数据结构 (有序) 。在数据之外,数据库系统还维护着满足特定查找算法的数据结构 (B+树) ,这些数据结构以某种方式引用 (指向) 数据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
1、底层数据结构B+树
默认使用的底层数据结构是B+树。
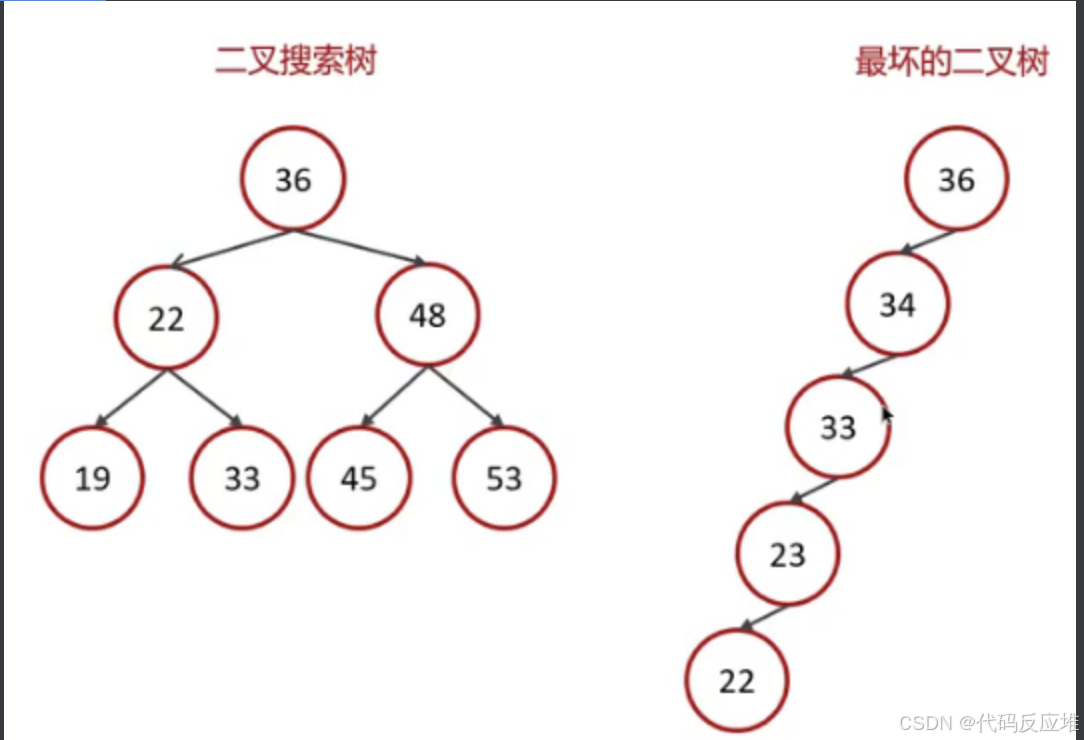
为什么不用二叉树,因为二叉树的时间复杂度不稳定,如下图二叉搜索树的时间复杂度为Ologn,最坏的二叉树的时间复杂度为On。
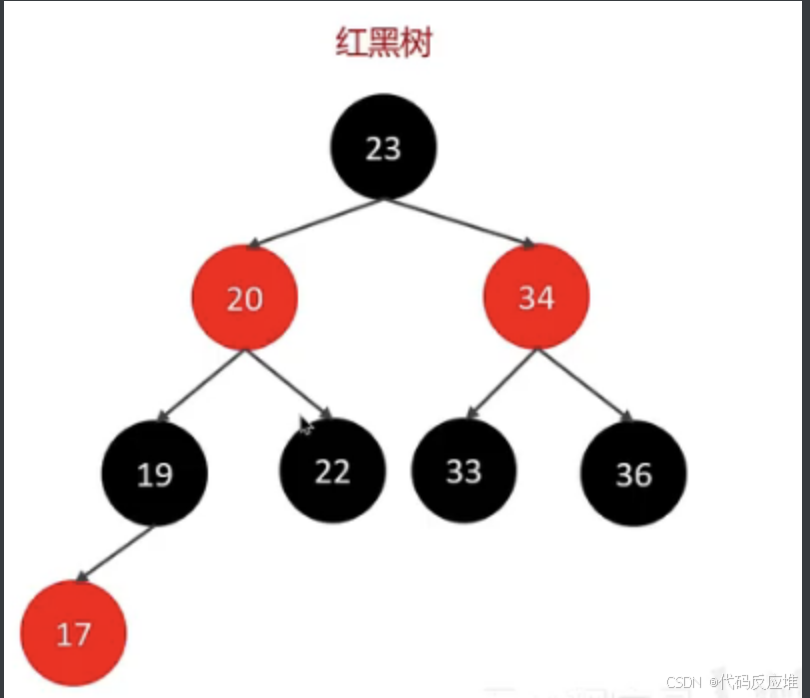
为什么不用红黑树,如下图红黑树,时间复杂度可以稳定为Ologn,但是红黑树也是个二叉树,每层只有两个子节点,如果一千万的数据都存储到红黑树中,就会使这个红黑树的层级非常高。所以就导致效率也不高。
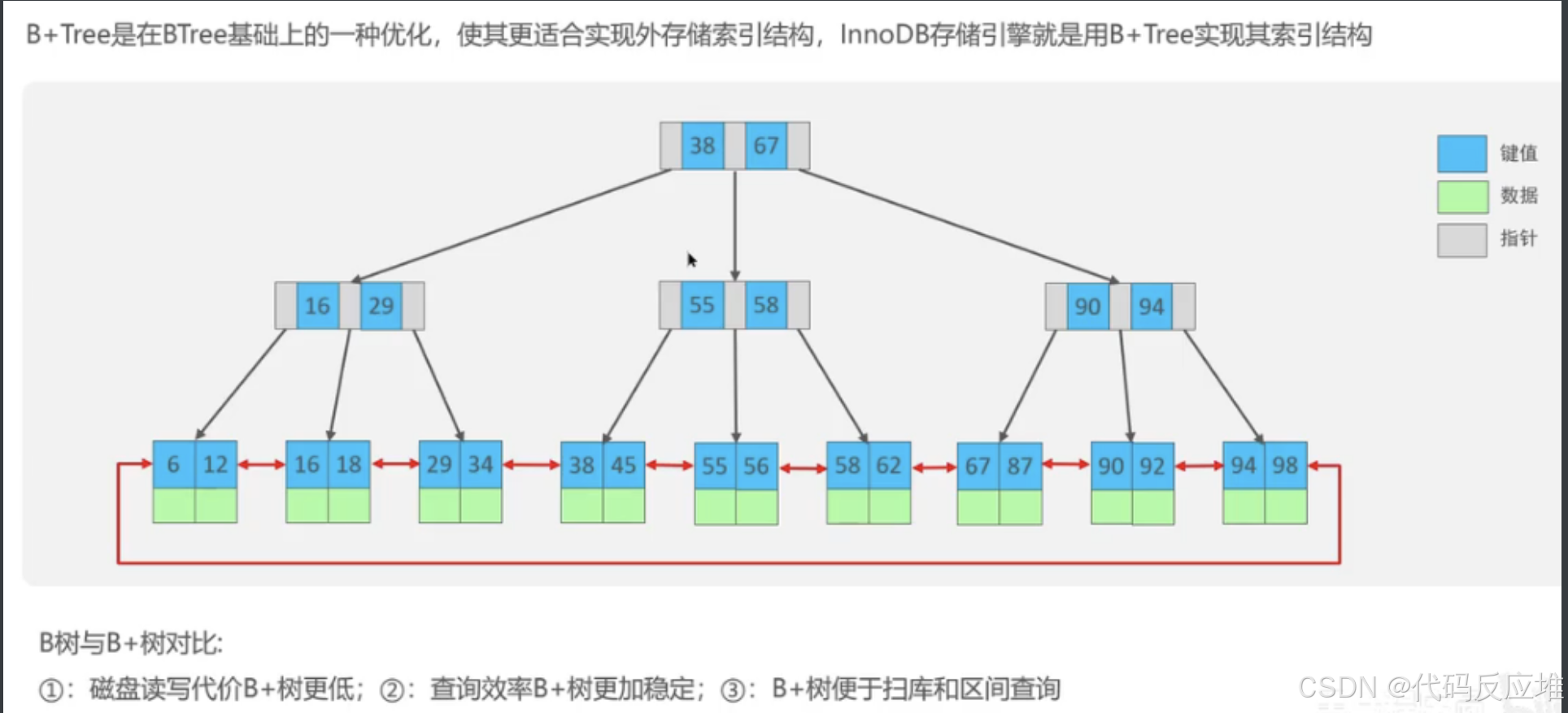
为什么不用B树,B树在每一个层级都存储了对应的业务数据,导致在查找过程中磁盘读写代价比较高。
使用B+树的优点如下:
1、对比B树,B+树只在叶子节点存储数据,所以磁盘读写代价低,
2、所有的键值和数据都会排列在叶子节点,如58键值对应的叶子节点也存在58键值和数据。所以最终都会在叶子节点去查找数据,查询效率比较稳定。
3、如下图叶子节点的红色箭头,通过双向指针进行连接的,所以B+树便于扫库和区间的查询。
2、聚簇索引、非聚簇索引
聚簇索引又称为聚集索引。非聚簇索引又称为非聚集索引。非聚集索引也称为二级索引。
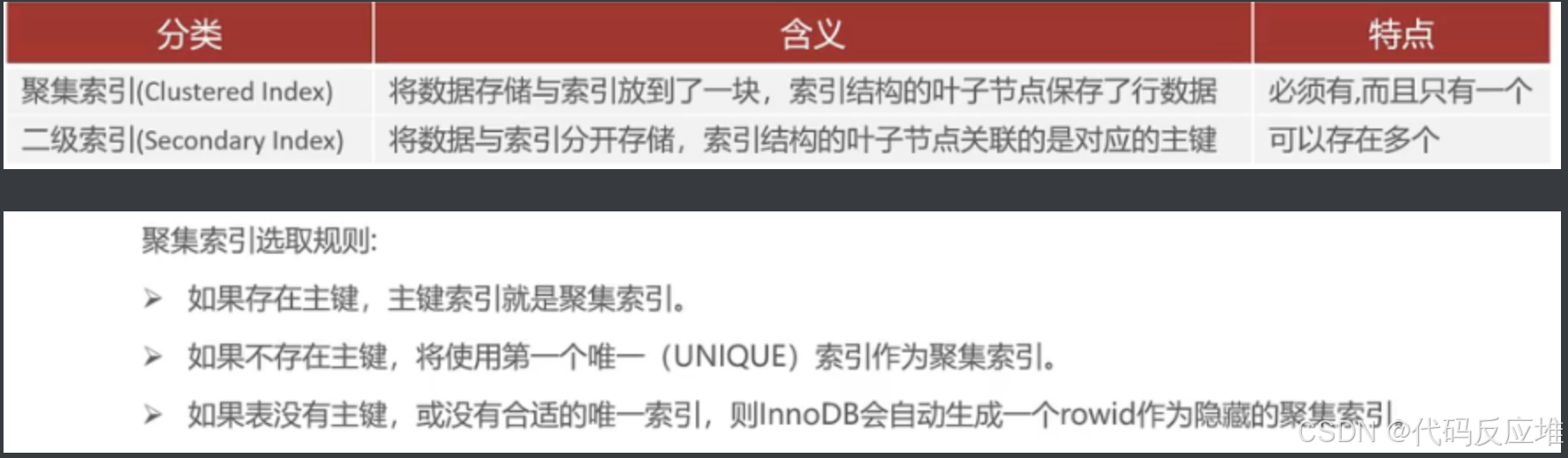
1、聚集索引实例
如下表中的id;
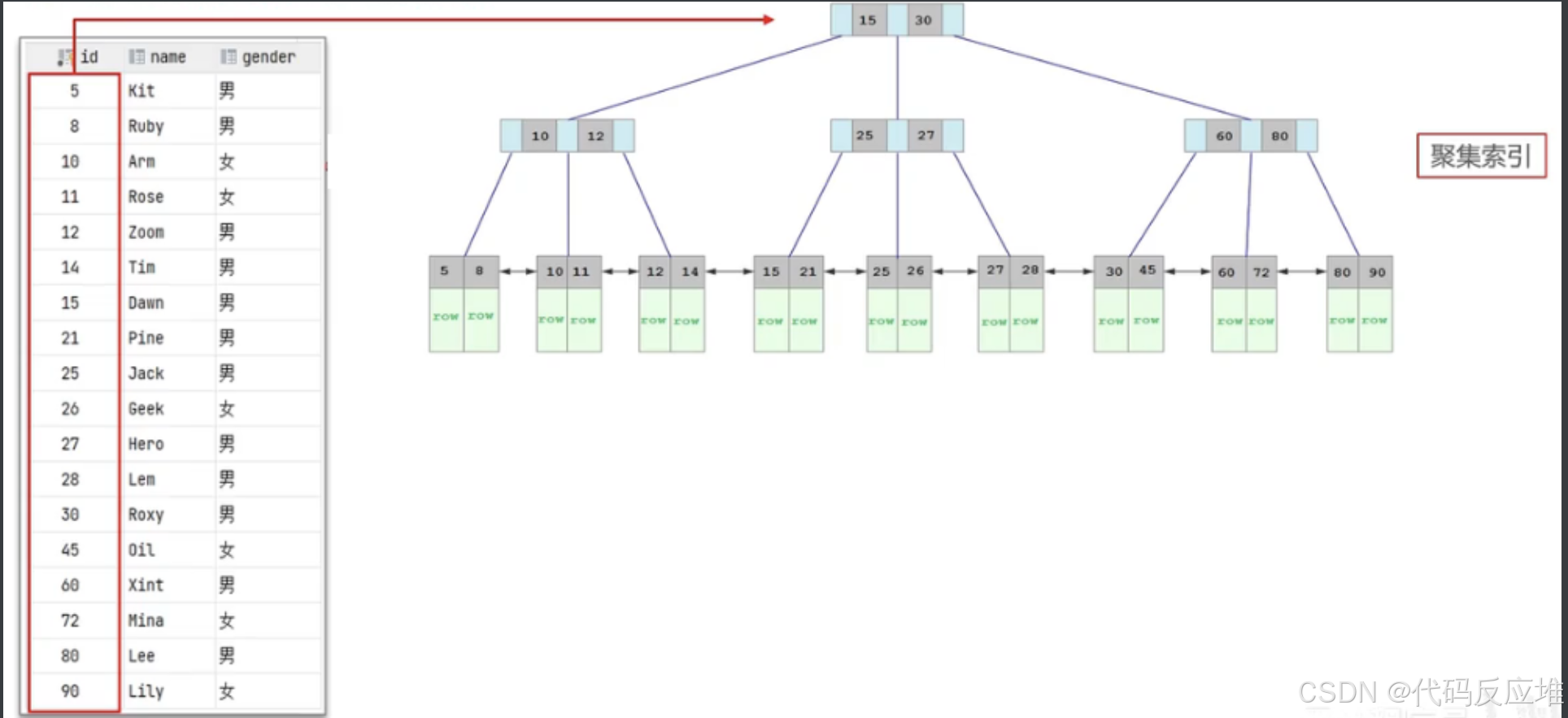
2、二级索引实例
如下:叶子节点存储的对应的主键。
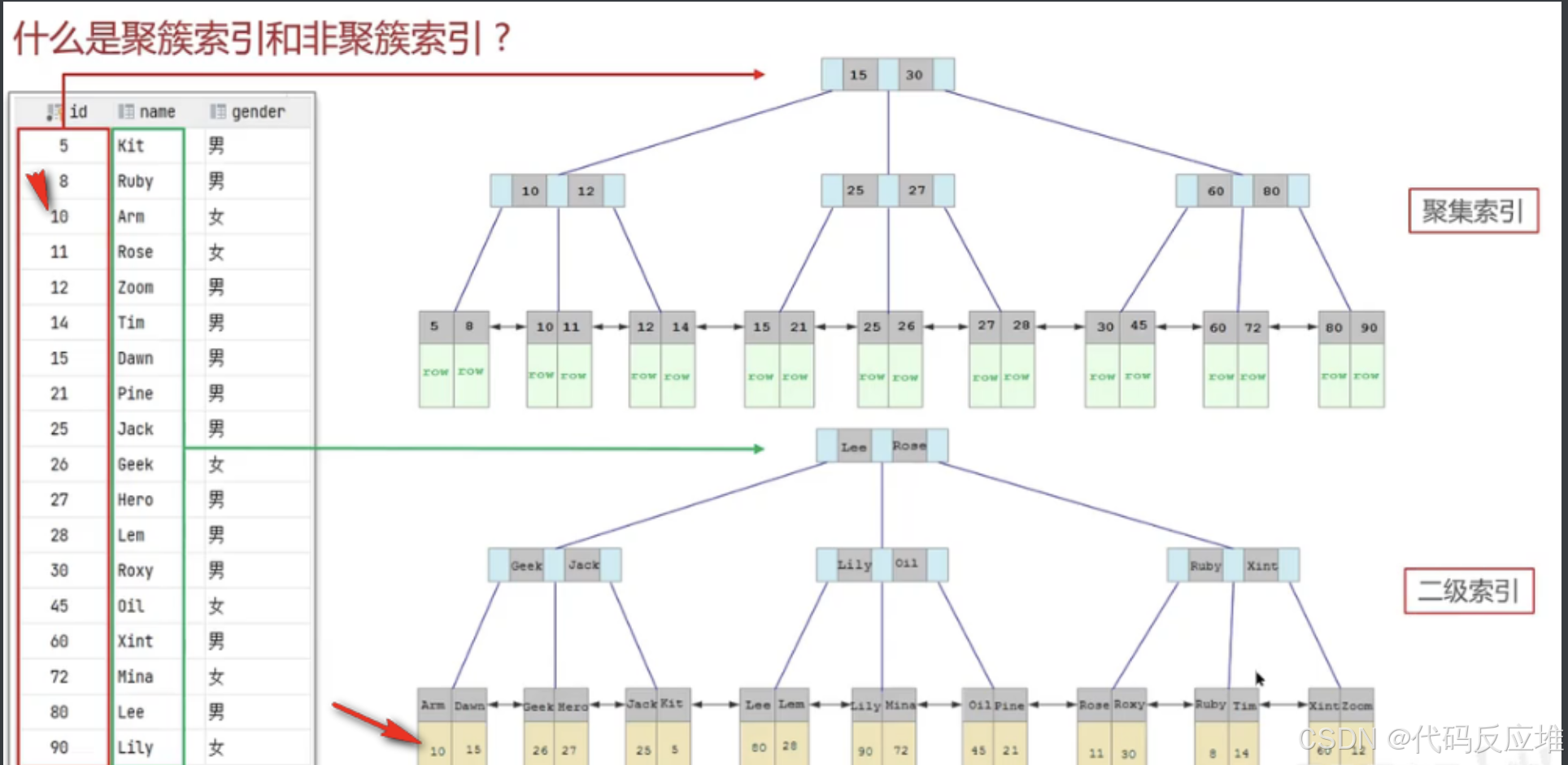
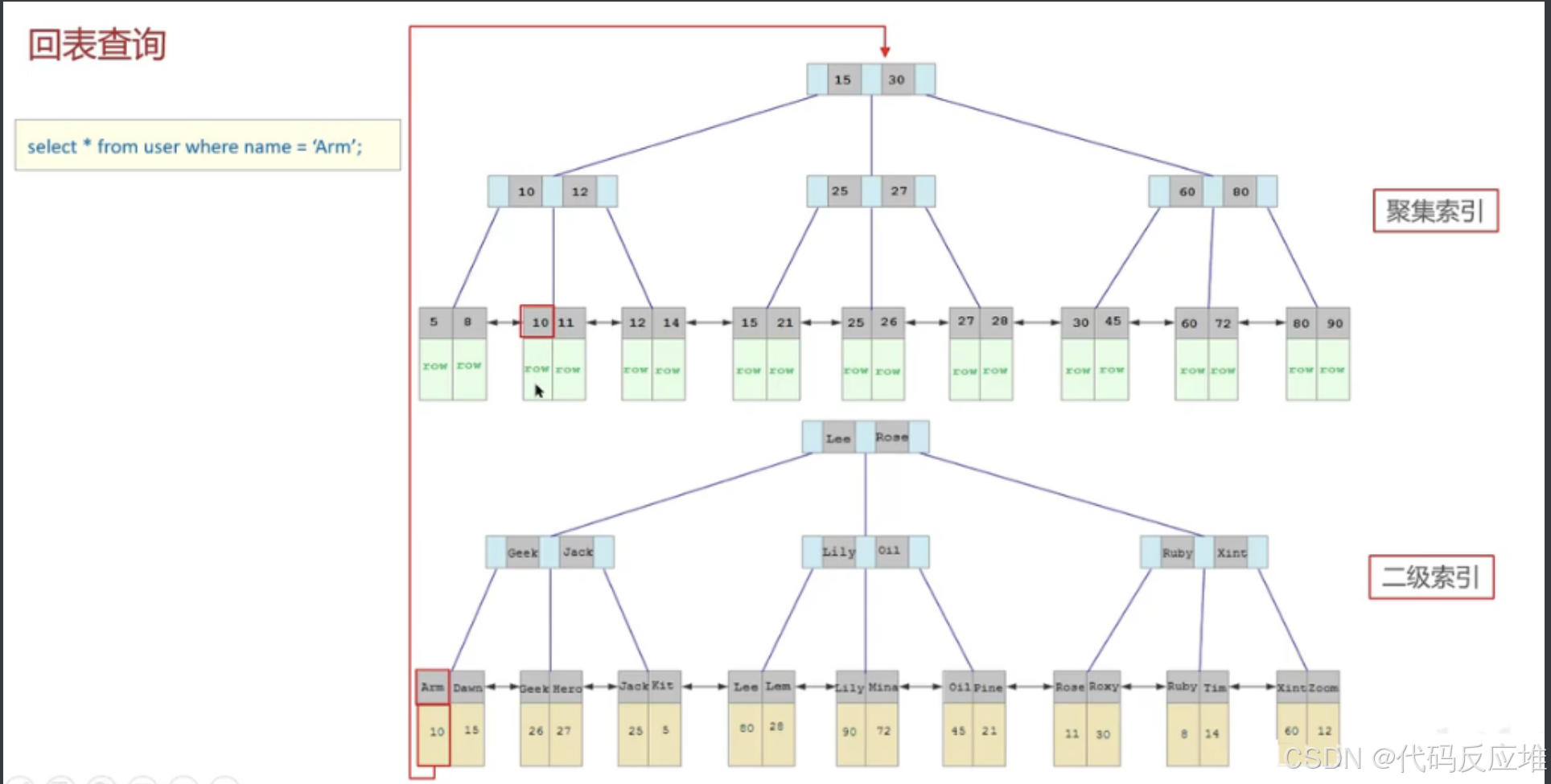
3、回表查询
如下图:由于根据name是二级索引,所以先查到主键10,然后根据主键再查聚簇索引,最终定位到10对应行row数据。这个过程就叫做回表查询。
4、覆盖索引
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到。
例子如下:id是主键索引,name是普通索引
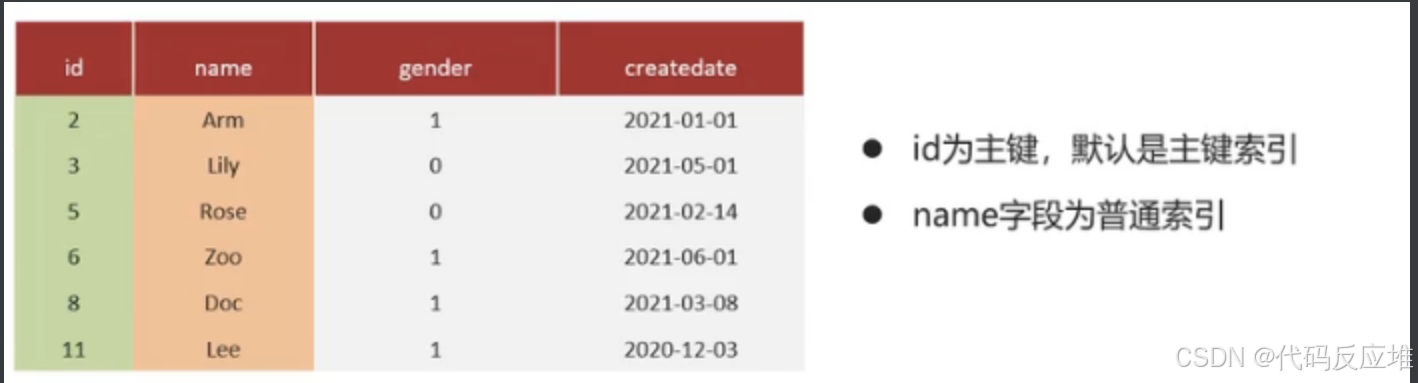

第三个sql,使用了回表查询,回表查询可以认为就是非覆盖索引。
5、前缀索引
所谓前缀索引,说白了就是对文本的前几个字符建立索引(具体是几个字符在建立索引时去指定),比如以产品名称的前 10 位来建索引,这样建立起来的索引更小,查询效率更快!
缺点:无法使用前缀索引进行 ORDER BY 和 GROUP BY,也无法用来进行覆盖扫描,当字符串本身可能比较长,而且前几个字符完全相同,这个时候前缀索引的优势已经不明显了,就没有创建前缀索引的必要了。
6、复合索引
多字段建立的索引。
7、创建索引原则
1). 针对于数据量较大,且查询比较频繁的表建立索引。单表超过10万数据(增加用户体验)
2). 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
3). 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
4). 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
5). 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
6). 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
7). 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
2、分析是否正确使用了索引
1、执行计划分析索引使用情况
通过执行计划可分析聚合查询、多表查询、表数据量过大查询。
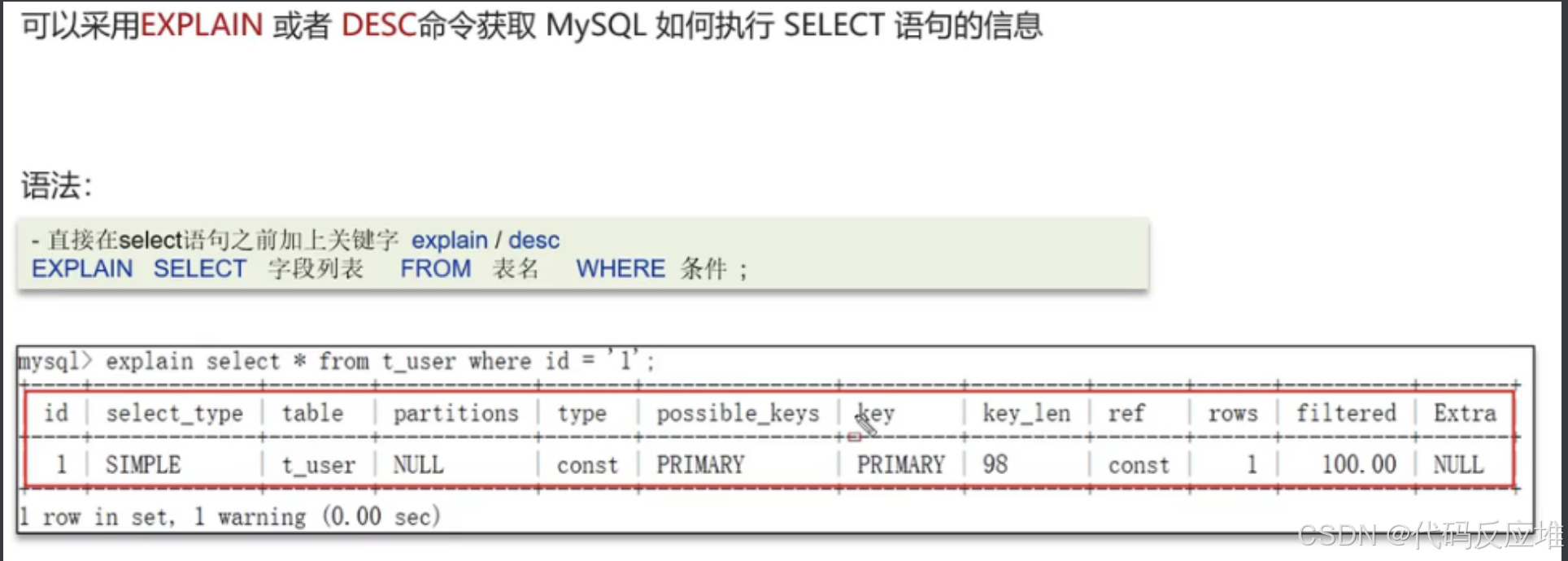
重点关注如下参数:
-
possible_keys可能使用到的索引
-
key实际命中的索引
-
key_len实际命中的索引占用的大小
-
Extra 额外的优化建议
-
type 表示sql的连接类型,性能由好到差为NULL、system、const、eq_ref、ref、range、index、all。
- NULL:表示这条sql执行中没有用到表,可以不用太关注
- system:查询mysql内置的表,在开发中也用的不多
- const: 根据主键查询的表
- eq_ref:根据主键索引查询或者唯一索引查询,所以只能返回一条数据
- ref:根据索引查询,可能是非唯一索引可返回多条数据。
- range: 根据索引查询的,但是条件是范围查询。
- index:走的是全索引查询,会去遍历整个索引树,在去检索数据,效率不高。
- all:不走索引,全盘扫描数据,效率不高
2、是否命中索引判断
通过key实际命中的索引、key_len实际命中的索引占用的大小两者即可判断出是否命中索引。
3、使用了索引但有优化空间
Extra 额外的优化建议,如果出现了回表查询也就是Using index condition,则还有继续优化的空间

4、根据sql连接类型判断
如果连接类型为如下index和all,通常需要优化
index:走的是全索引查询,会去遍历整个索引树,在去检索数据,效率不高。
all:不走索引,全盘扫描数据,效率不高
3、正确使用索引原则
1、最佳左前缀法则
如下:我们在tb_seller表建立了一个复合索引,字段顺序name、status、address;
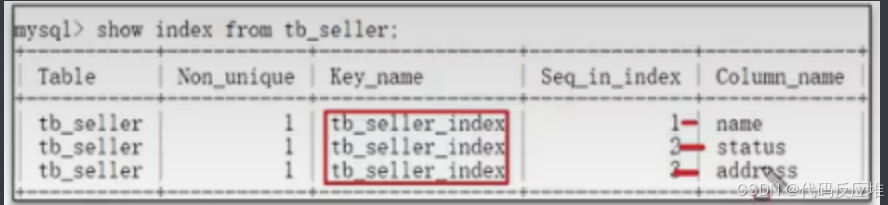
如下查询时需要按顺序查询,都命中了索引;

如下违反了左前缀法则,导致没有命中索引


2、范围查询右边的列
如下图第二个sql,status字段使用了范围查询,导致address不走索引了,所以key_len长度值只用309。只有name和status才走了索引。
status > '1' 破坏了索引的有序连续性,导致后续 address 无法使用索引

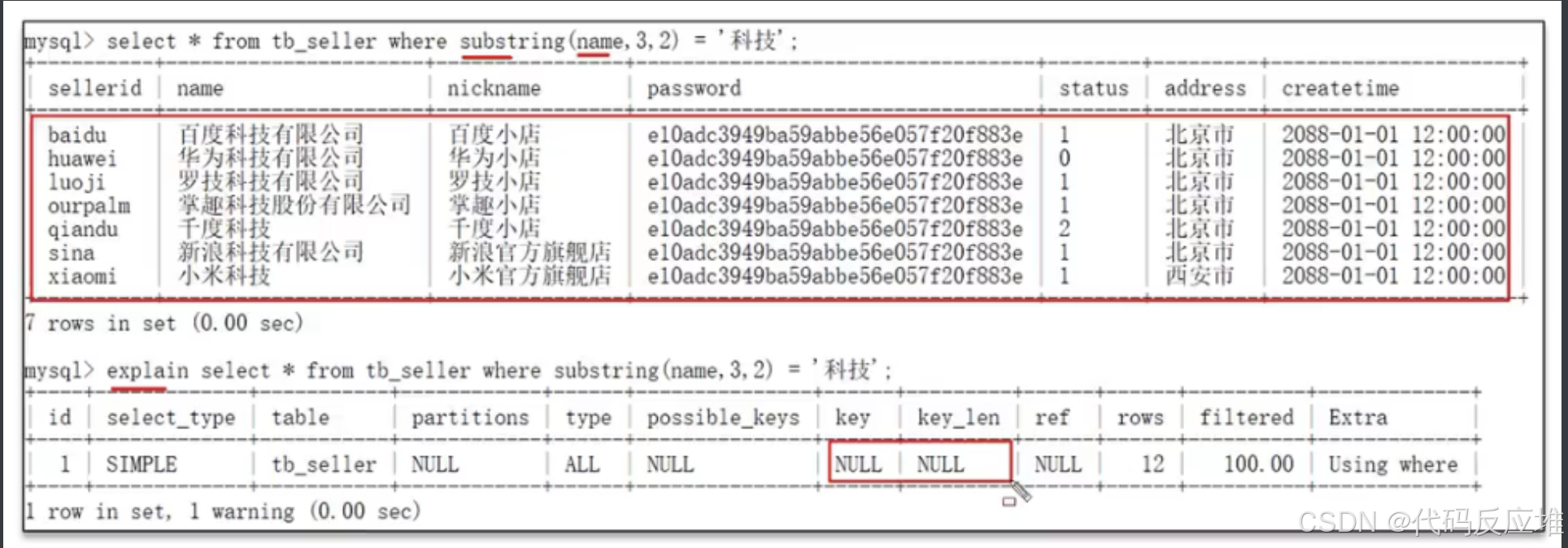
3、索引列使用函数
如下图:索引列使用了substring导致索引失效了。
4、索引列使用类型转换

5、模糊查询的%在前面
如下图:如果模糊查询时%放在前面,会导致索引失效。
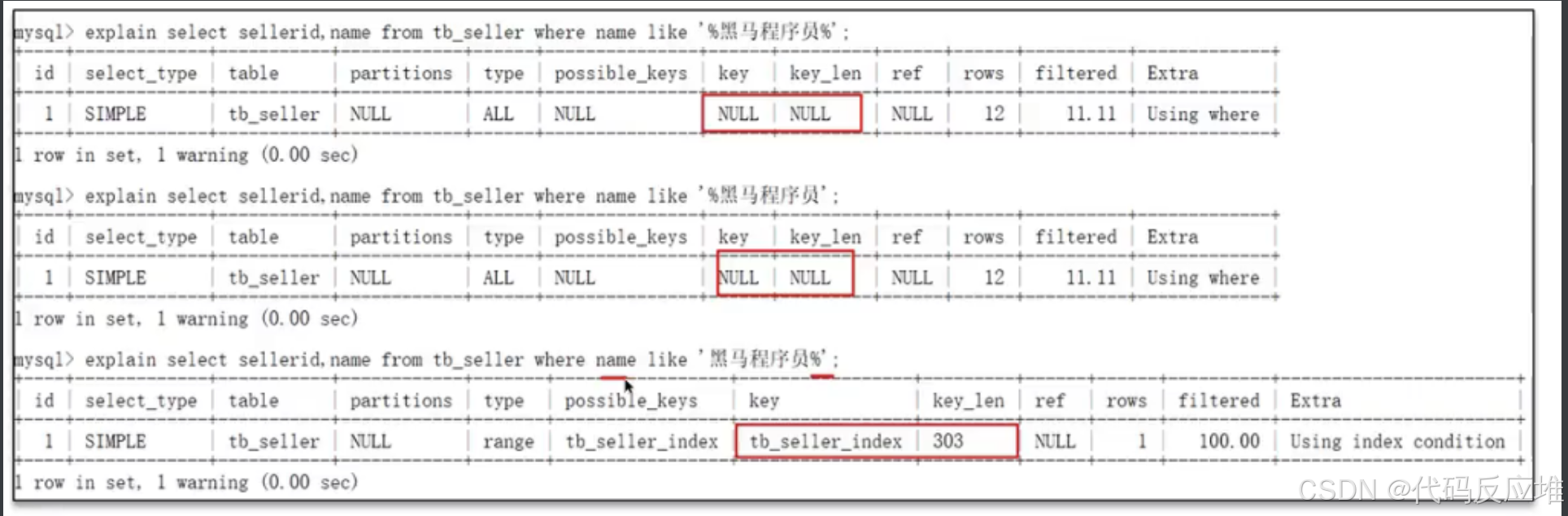
超大数据分页查询的优化
1、通过覆盖索引优化
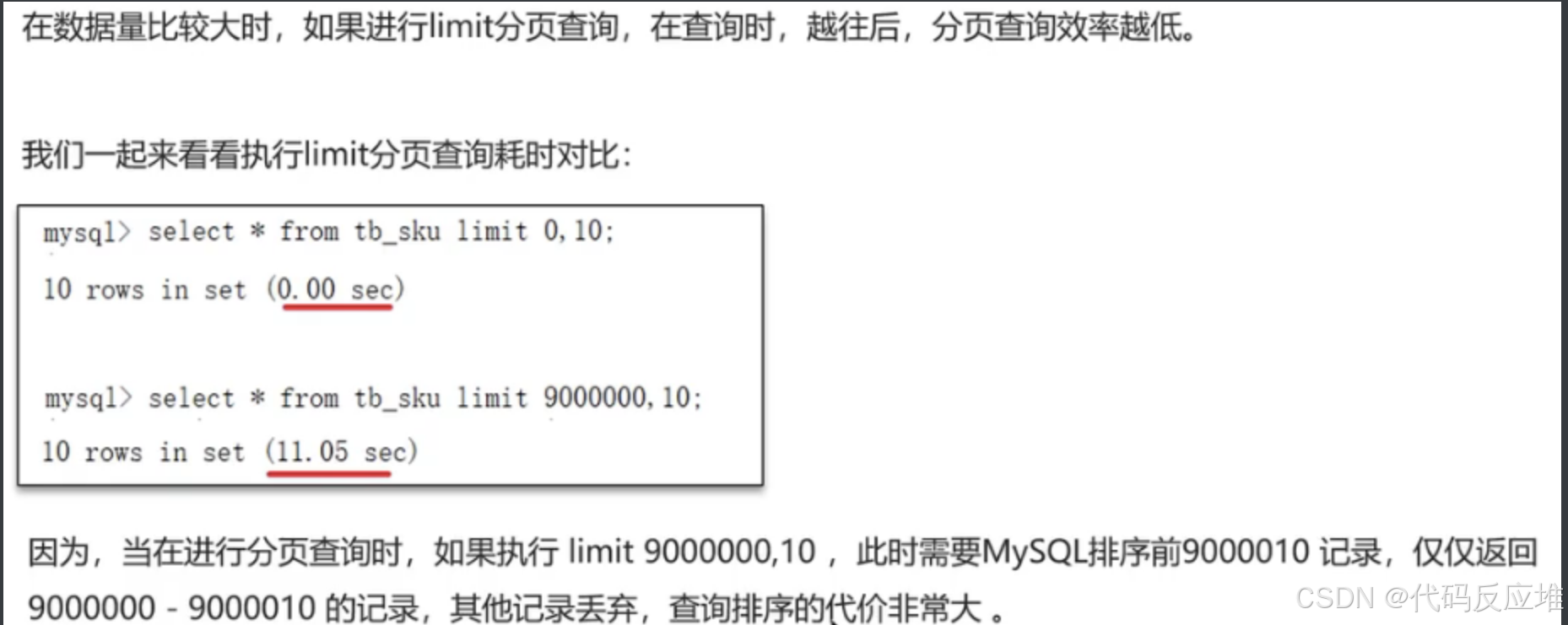
先通过表中的id进行分页查询,就能筛选出id集合。在通过id集合和原来的表做关联查询。即可得到结果。
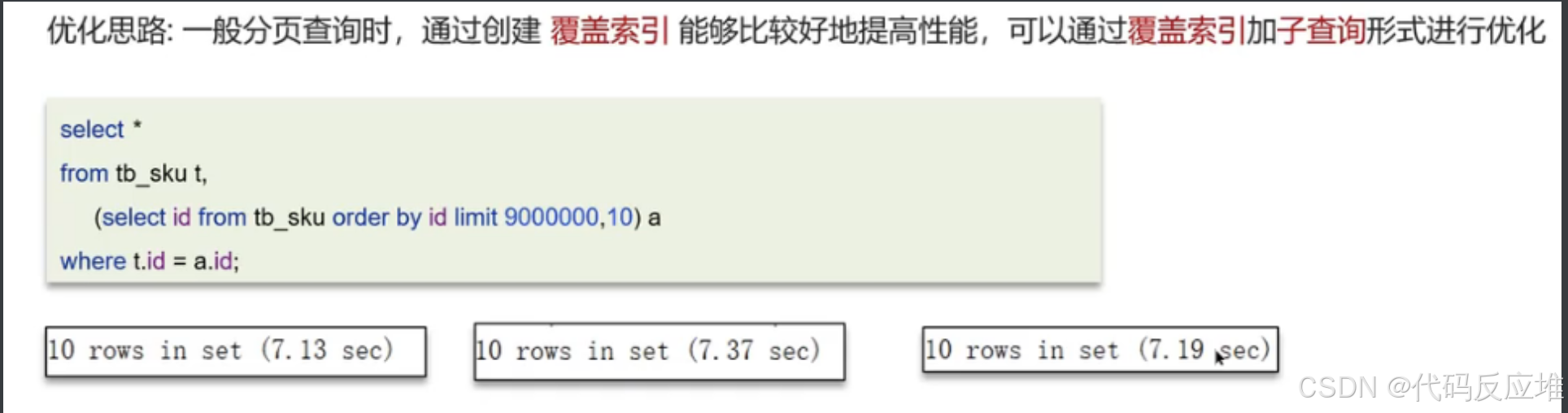
提升了4秒。
表设计方面优化
比如设置合适的数值 (tinyint int bigint) ,要根据实际情况选择、设置合适的字符串类型 (char和varchar) char定长效率高,varchar可变长度,效率稍低
使用合适的语法优化慢sql查询
1、分析使用union all 代替union和or
union会将重复的数据去重,union all 不会。所以union all 少了过滤操作,自然效率就高。
当 SQL 查询包含大量 OR 条件时,即使都建了索引MySQL 往往难以有效使用索引,导致全表扫描性能下降,可以使用union all 代替
最终务必使用 EXPLAIN 分析执行计划,验证索引使用情况。
性能对比测试 (100万行数据)
| 方法 | 执行时间 | 扫描行数 | 索引使用 |
|---|---|---|---|
| OR 条件查询 | 2.8s | 1,000,000 | ❌ 全表扫描 |
| UNION ALL | 0.4s | 8,500 | ✅ 多索引 |
| CASE 表达式 | 1.2s | 1,000,000 | ❌ 全表扫描 |
| 派生表+JOIN | 0.6s | 12,000 | ✅ 索引 |
2、分析使用内连代替左连和右连
Join优化 能用inner join 就不用left join right join,如必须使用 一定要以小表为驱动表,
(虽然优化器自动选择小表作为驱动表,自己写了优化器也会少优化步骤)
3、IN 、 EXISTS、INNER JOIN的适用场景选择
IN :先执行子查询,缓存结果集,再用外层查询匹配,适用于子查询的结果集数据小的,并且外层查询列有索引
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders WHERE amount > 1000) -- 订单量远小于用户量
EXISTS : 外层查询逐条代入子查询验证是否存在,适用外层查询结果集小的,子查询连接列有索引。
(现代MySQL优化器(v5.7+)会自动将部分IN查询重写为EXISTS)
SELECT * FROM products p
WHERE EXISTS (SELECT 1 FROM inventory WHERE product_id = p.id AND stock < 10 -- 库存不足的商品极少
)
INNER JOIN : 表间直接关联,单次扫描。当数据量大且连接列有高效的索引时,更有优势。
/* 测试场景:查询有订单的用户 */
-- 方式1:IN子查询 (2.8s)
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders)-- 方式2:EXISTS (1.5s)
SELECT * FROM users u
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.user_id = u.id)-- 方式3:INNER JOIN (0.8s) ★最优
SELECT DISTINCT u.*
FROM users u
INNER JOIN orders o ON u.id = o.user_id
实际业务场景优先尝试 JOIN 方案,然后可以使用EXPLAIN 查看各个方案的执行计划及耗时
4、GROUP BY 列 + ORDER BY 列建立复合索引
复合索引消除 90% 以上的 Using filesort 和 Using temporary 问题(),显著提升包含分组和排序操作的查询性能
-- 原始查询
SELECT department, AVG(salary)
FROM employees
GROUP BY department
ORDER BY hire_date DESC;-- 优化索引 ✅
CREATE INDEX idx_dept_hire ON employees(department, hire_date DESC);
包含 WHERE 条件
-- 原始查询
SELECT department, COUNT(*)
FROM employees
WHERE hire_date > '2020-01-01'
GROUP BY department
ORDER BY COUNT(*) DESC;-- 优化方案:
CREATE INDEX idx_hire_dept ON employees(hire_date, department);
Using filesort 和 Using temporary这两个是 MySQL 执行计划(EXPLAIN)中的关键指标,揭示了查询执行的潜在性能问题。
Using filesort(文件排序):当 MySQL 无法使用索引完成排序操作时,需要将结果集放入内存或磁盘进行排序的过程。
Using temporary(临时表):当 MySQL 需要创建临时表来存储中间结果时出现的标志
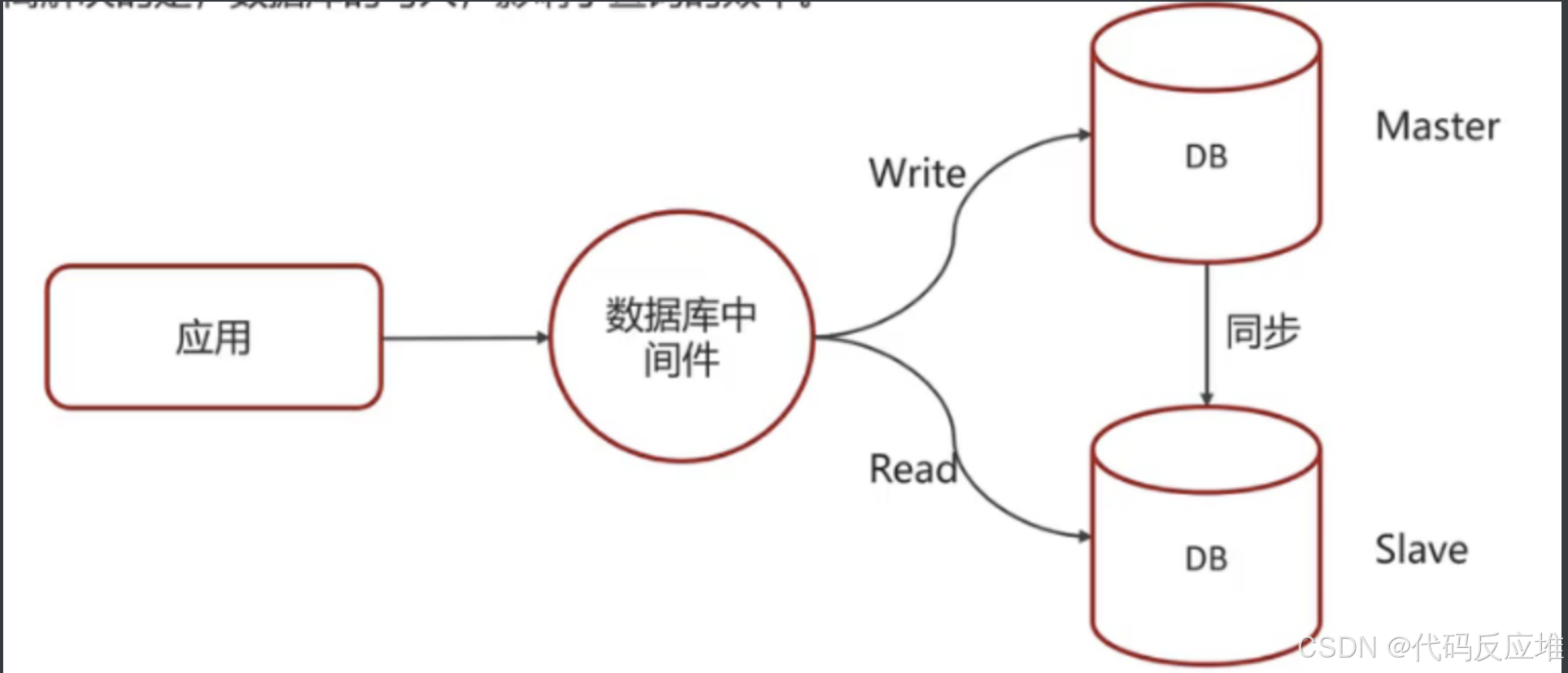
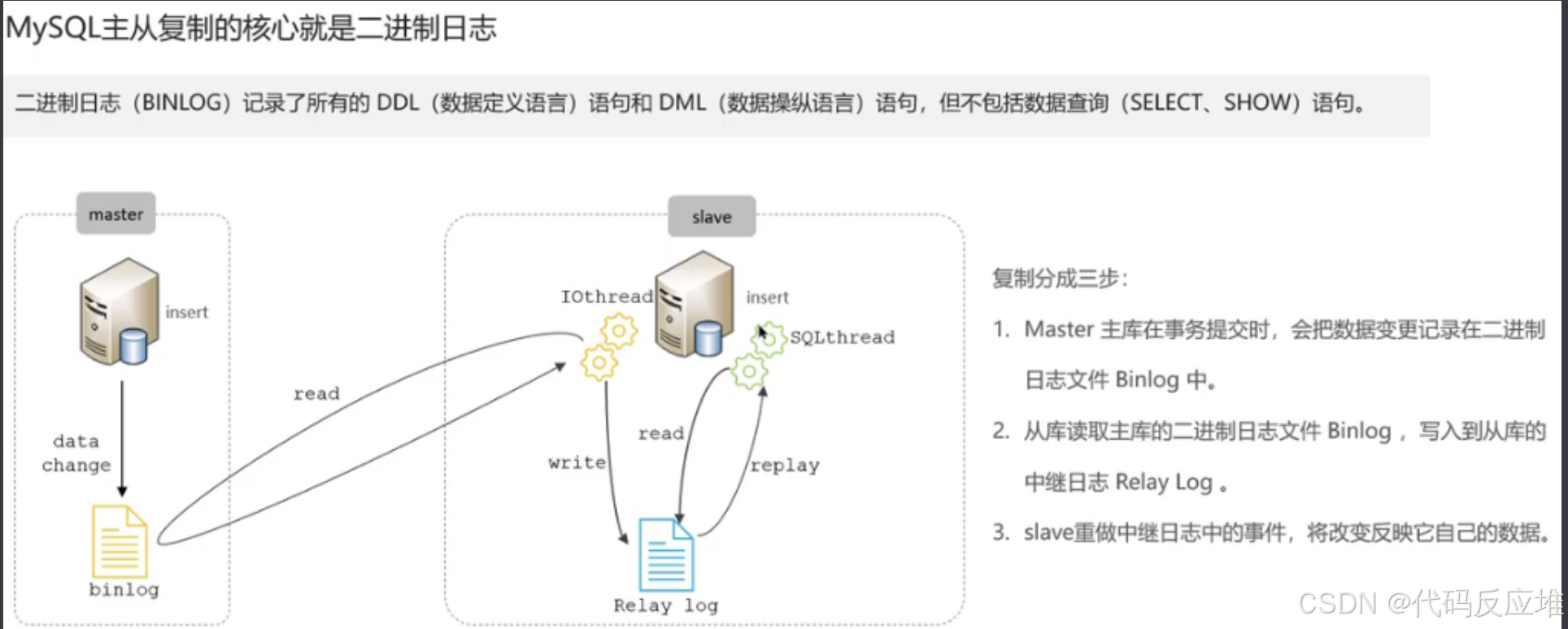
使用主从同步读写分离优化
如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响 可以采用读写分离的架构。读写分离解决的是,数据库的写入影响查询的效率问题
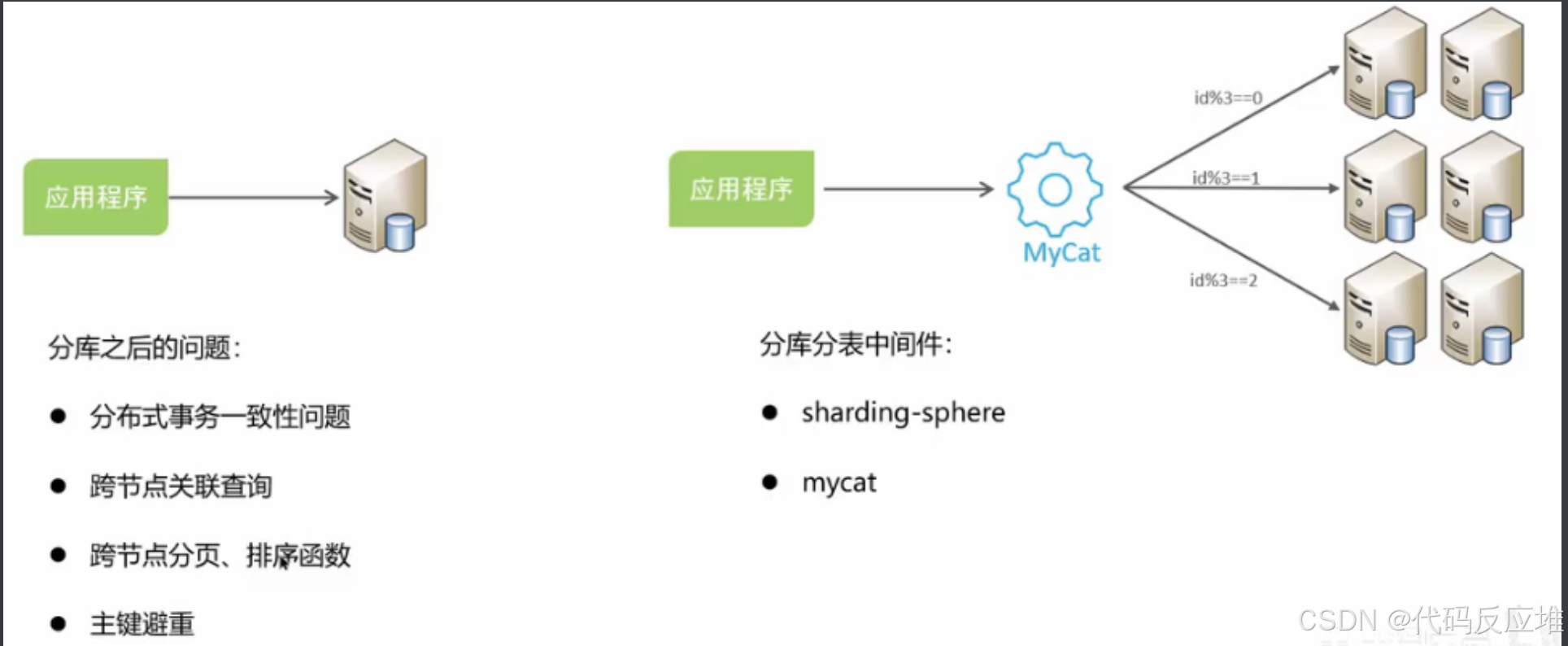
使用分库分表优化
1、使用场景
使用主从同步读写分离有效的分担了访问压力。但是当表的数据量多了,这时要考虑分库分表。
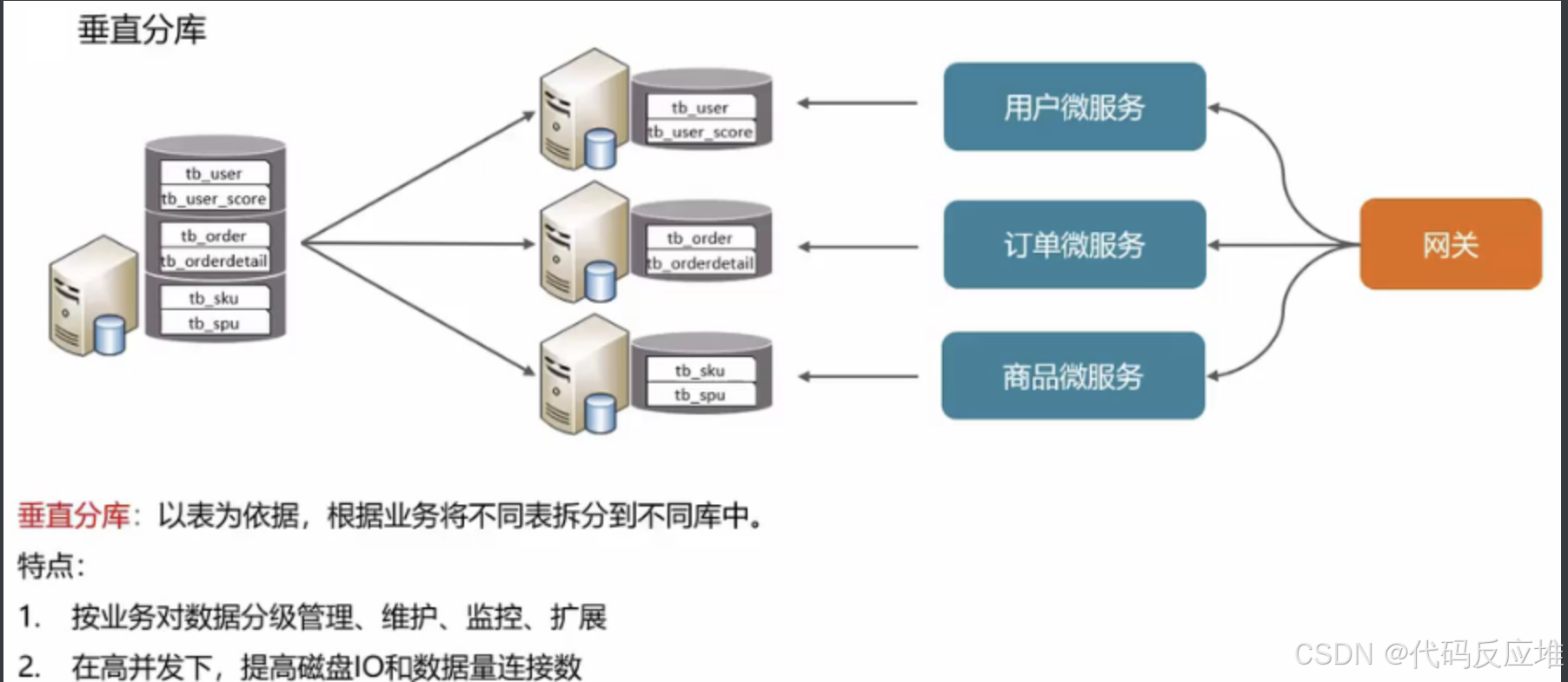
1、垂直拆分
1、垂直分库
已业务为依据将不同业务表,存储到不同的库中,类似微服务一样。
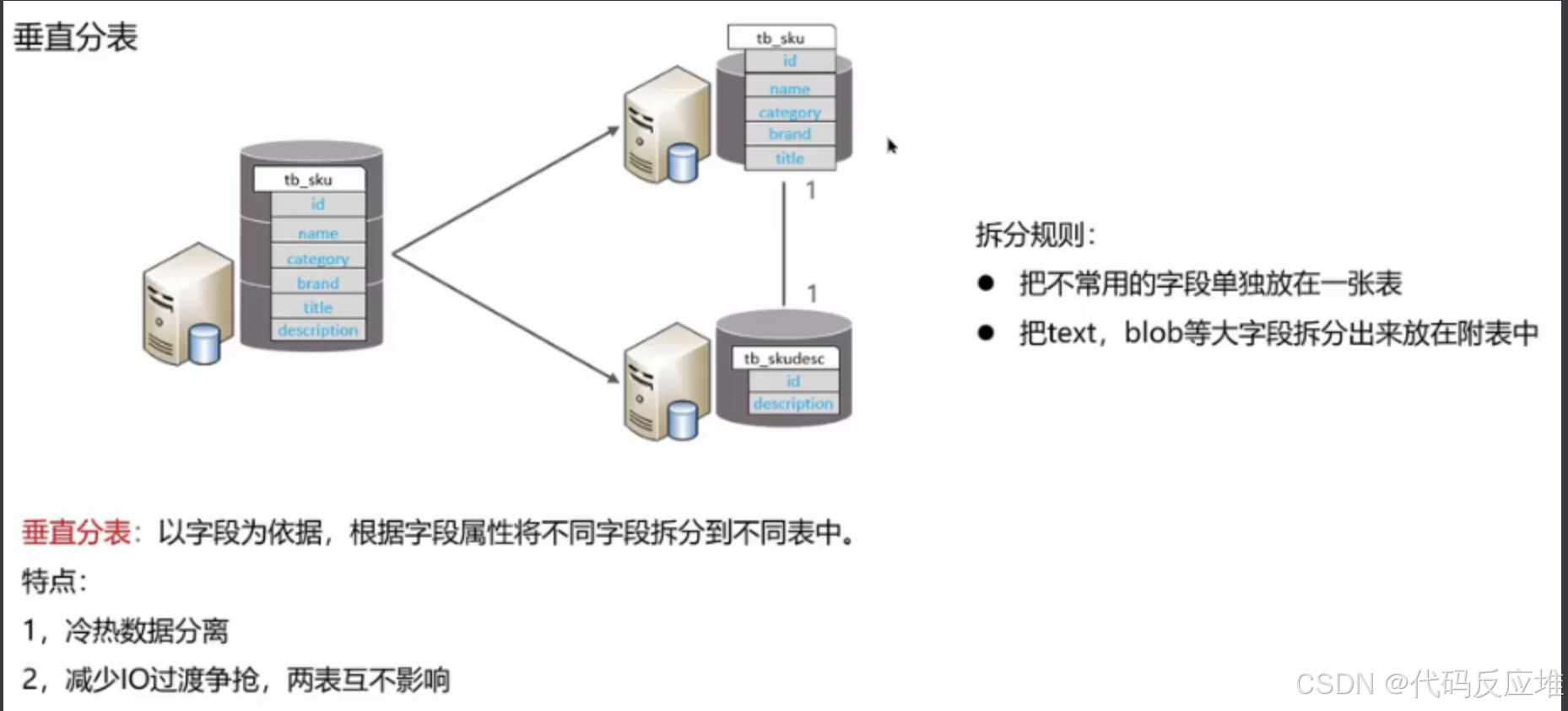
2、垂直分表
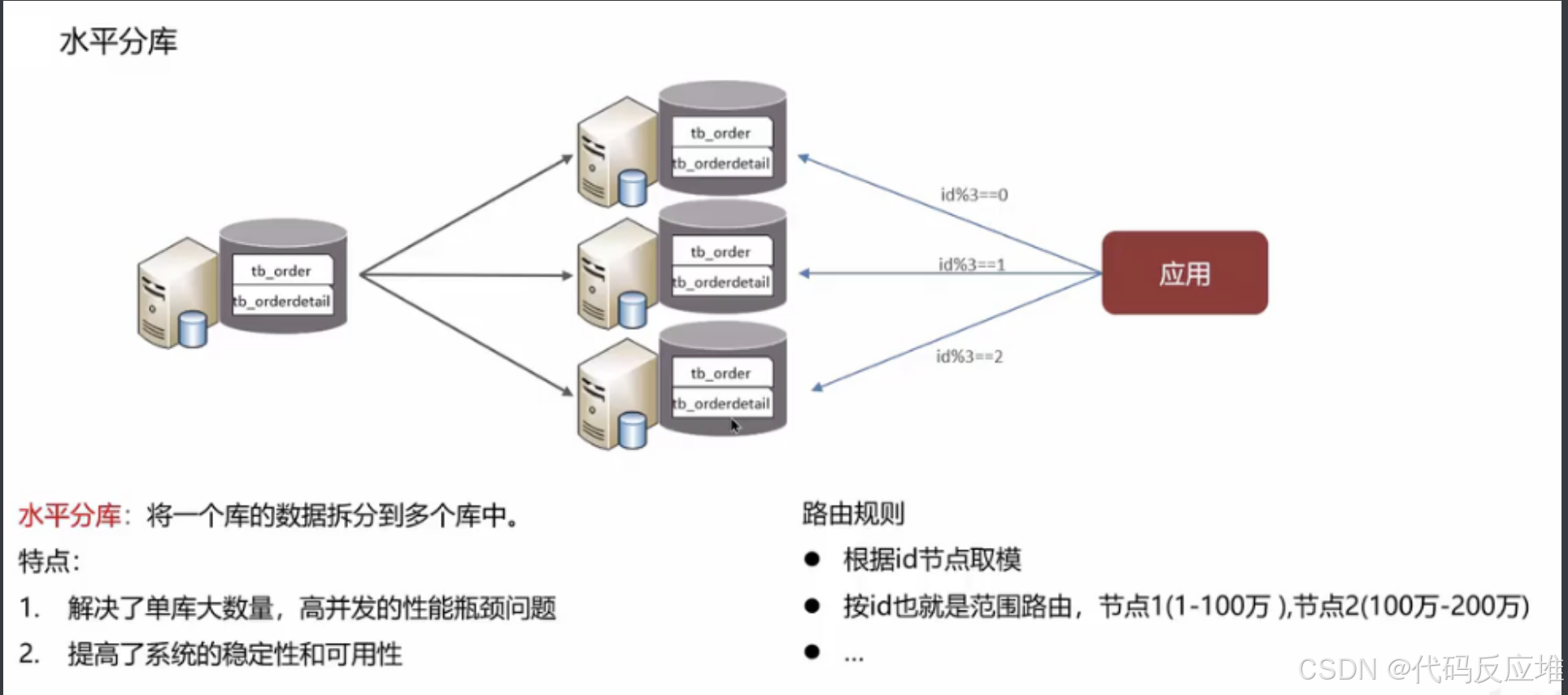
2、水平拆分
1、水平分库
业务表都存在于每个库中,根据数据量和数据特征,将不同数据写入到不同库中。类似于高可用集群
2、水平分表
在一个库当中建立多张表,同样根据数据量或数据特征存储在不同表中。
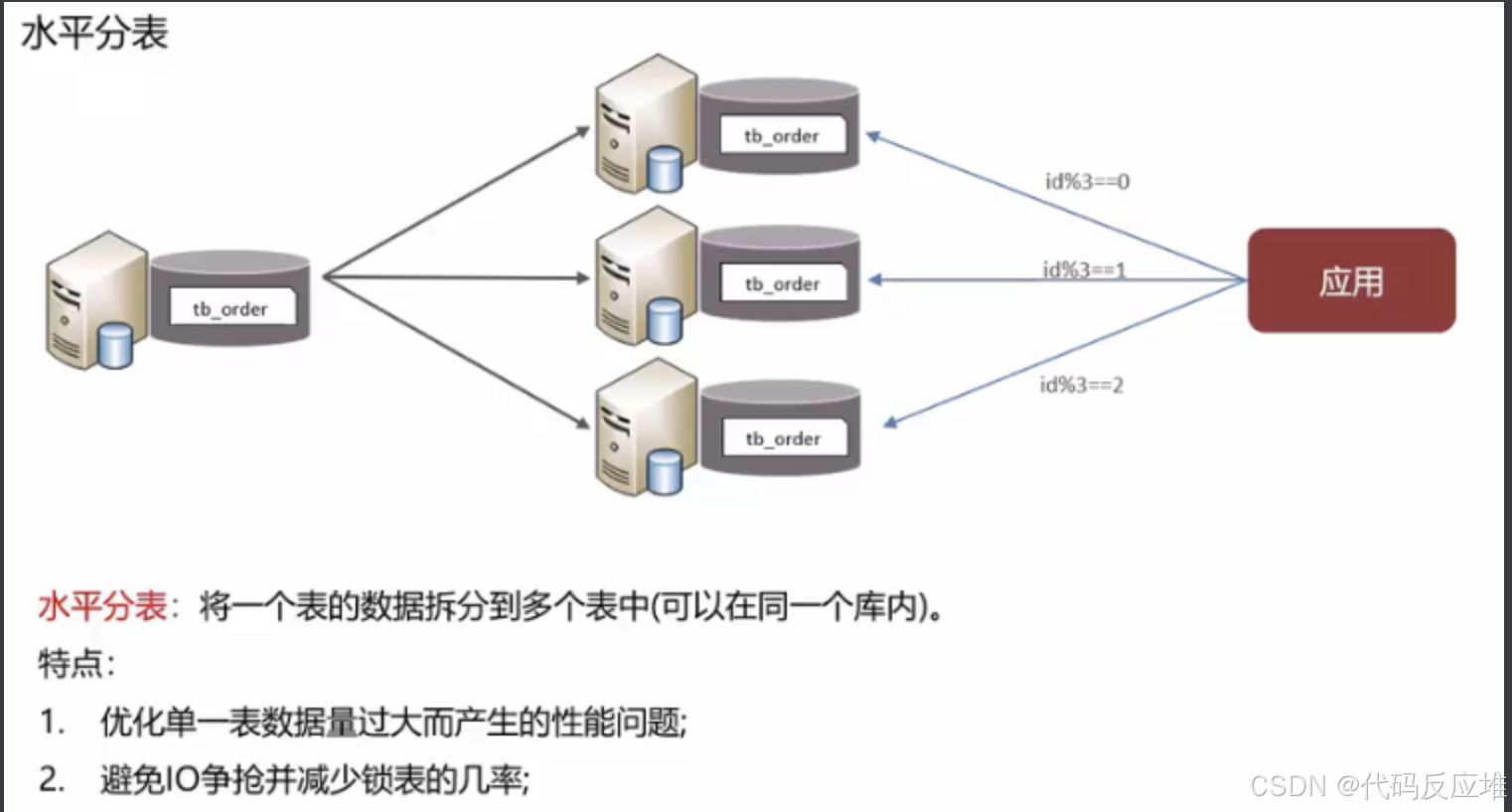
3、分库分表中间件sharding-sphere/mycat等中间件
sharding-sphere/mycat 通过中间件解决了分库分表带来的一系列问题,如分布式事务一致性、跨节点关联查询等等。