HDFS基本操作训练(创建、上传、下载、删除)
注:文中涉及到的“doubinqian"为本人姓名,大家按实际需求自行更改
一、启动集群,在客户端查看集群信息
进入hadoop目录,输入以下命令启动相关服务
sbin/start-dfs.sh:启动 HDFS(分布式文件系统)相关进程,包括:NameNode(主节点,运行在 master):管理文件系统元数据(如目录结构、文件位置),是 HDFS 的 "大脑"。DataNode(从节点,运行在 slave1、slave2、slave3):存储实际数据块(Block),并根据 NameNode 指令进行数据读写。Secondary NameNode(运行在 master):辅助 NameNode 备份元数据,避免元数据丢失(非热备,仅定期合并编辑日志)。
sbin/start-yarn.sh:启动 YARN(资源管理器)相关进程,负责集群资源(内存、CPU)的分配与管理:ResourceManager(运行在 master):全局资源调度,接收应用程序提交并分配资源。NodeManager(运行在 slave 节点):管理单个节点的资源,启动和监控容器(Container)。
sbin/mr-jobhistory-daemon.sh start historyserver:启动 MapReduce 历史服务器,用于记录和查询已完成的 MapReduce 任务日志(通过 Web 界面访问)
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver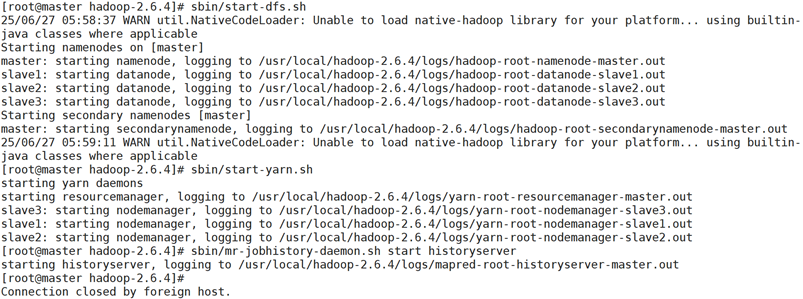
根据自己所用hadoop版本客户端端口号,在客户端查看集群信息
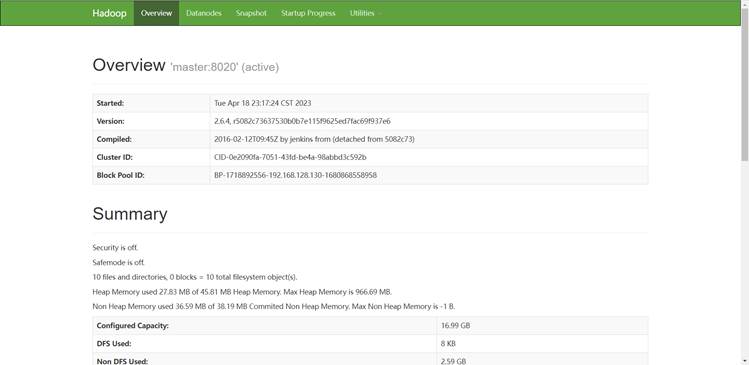
二、HDFS基本操作训练
(一)HDFS操作的基本逻辑
在开始具体操作前,先明确几个关键概念,帮助理解为什么 HDFS 操作是这样设计的:
- 分布式存储:HDFS 中的文件不是存在一台机器上,而是被拆分成多个 “数据块(Block)”,存储在集群中的多台 “数据节点(DataNode)” 上,默认每个块大小为 128MB(文档中可看到此配置)。
- 副本机制:为了防止数据丢失,每个数据块会被复制多份(文档中默认是 3 份),分别存在不同的 DataNode 上。
- 命令格式:HDFS 的操作命令统一以
hdfs dfs开头,后面跟具体操作(如创建目录、上传文件),类似 Linux 的lsmkdir等命令,但需要通过 HDFS 的客户端工具执行。
(二)具体操作详解
1. 创建目录:hdfs dfs -mkdir
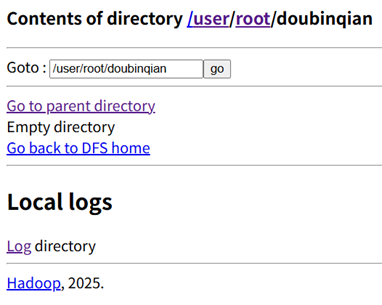
使用命令hdfs dfs -mkdir 创建目录/user/root/doubinqian
该命令只能在已有目录下创建目录,命令hdfs dfs -mkdir -p /user/root/text/doubinqian 则可以新建text目录的同时在其下新建子目录doubinqian
命令解析:
hdfs dfs:固定前缀,表示通过 HDFS 客户端执行操作。-mkdir:创建目录的参数(类似 Linux 的mkdir)。/user/root/doubinqian:HDFS 中的目标目录路径,这是一个 “绝对路径”(从根目录/开始)。
![]()
查看是否被成功创建
2. 上传文件:hdfs dfs -put
使用命令hdfs dfs -put,将/opt目录下的movies.dat、users.dat、rating.data上传至HDFS系统的/user/root/doubinqian目录下
命令解析:
-put:上传文件的参数。movies.dat:本地 Linux 系统中的文件路径(文档中该文件在/opt目录下,所以实际执行时是在/opt目录下运行的命令)。/user/root/doubinqian/movies.dat:HDFS 中的目标路径,指定了文件名(也可以省略文件名,直接写目录,会默认用原文件名)
(1)上传movies.dat

(2)上传users.dat

(3)上传ratings.dat

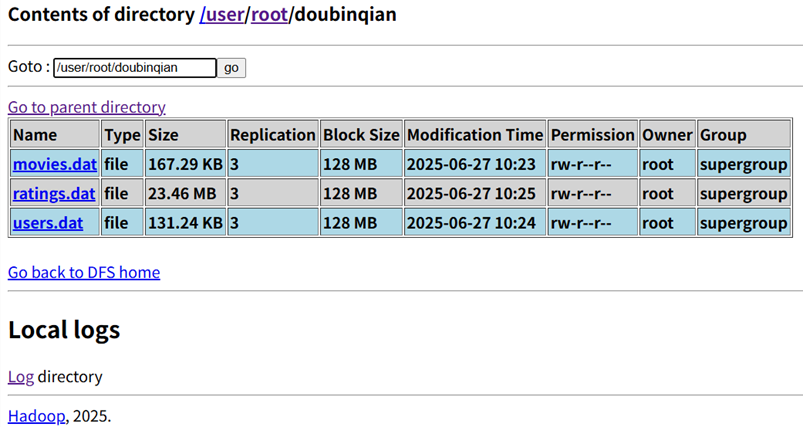
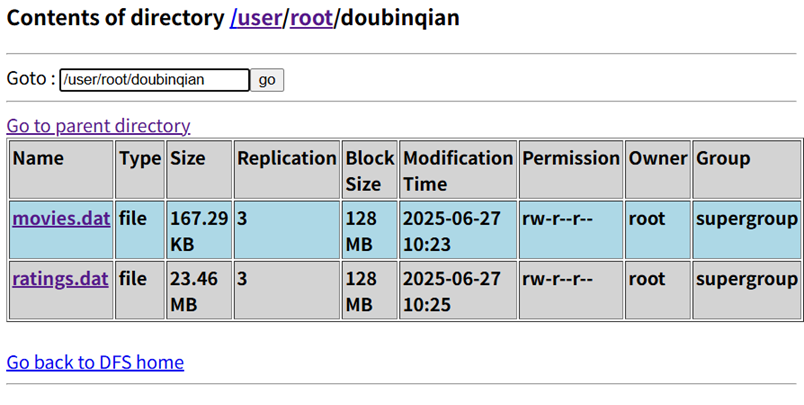
(4)客户端查看上传结果
通过 Web 界面查看
/user/root/doubinqian目录,显示三个文件:movies.dat(大小 167.29KB)、user.dat(131.24KB)、ratings.dat(23.46MB)。- 每个文件的 “Replication”(副本数)都是 3,这是 HDFS 默认的副本配置(保证数据安全,即使某台 DataNode 故障,还有其他副本可用)。
- “Block Size”(块大小)都是 128MB,由于这三个文件都小于 128MB,所以每个文件只占 1 个数据块。
3. 下载文件:hdfs dfs -get
使用命令hdfs dfs -get 从HDFS上下载users.dat文件到Linux本地目录/opt/doubinqian/中
命令解析:
-get:下载文件的参数。/user/root/doubinqian/users.dat:HDFS 中的源文件路径。/opt/doubinqian/:本地 Linux 的目标目录(如果目录不存在,需要先在本地创建,比如用mkdir /opt/doubinqian)。

下载成功
4. 删除文件:hdfs dfs -rm
使用hdfs dfs -rm 命令,删除HDFS上/user/root/doubinqian/目录下的users.dat文件
如果要删除整个目录,需要加 -r 参数(递归删除目录及其中的所有内容),例如删除doubinqian目录:hdfs dfs -rm -r /user/root/doubinqian
以下仅演示删除users.dat文件
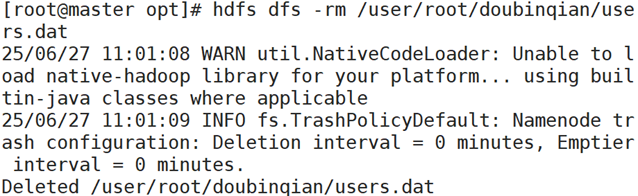
在客户端查看是否删除
(三)补充:常用的HDFS辅助命令
1.查看目录内容:hdfs dfs -ls <路径>
例如:显示/user/root/doubinqian目录下的所有文件(如文档中上传后的三个文件):
hdfs dfs -ls /user/root/doubinqian
2.查看文件内容:hdfs dfs -cat <文件路径>
例如:直接查看 HDFS 中文件的内容(适合小文件):
hdfs dfs -cat /user/root/doubinqian/movies.dat
3.复制 HDFS 中的文件:hdfs dfs -cp <源路径> <目标路径>
例如:将movies.dat复制到另一个目录/tmp:
hdfs dfs -cp /user/root/doubinqian/movies.dat /tmp/
4.移动 HDFS 中的文件:hdfs dfs -mv <源路径> <目标路径>
类似 “剪切粘贴”,例如将ratings.dat移动到/tmp:
hdfs dfs -mv /user/root/doubinqian/ratings.dat /tmp/