rLLM:用于LLM Agent RL后训练的创新框架
rLLM:用于LLM Agent RL后训练的创新框架
本文介绍了rLLM,一个用于语言智能体后训练的可扩展框架。它能让用户轻松构建自定义智能体与环境,通过强化学习进行训练并部署。文中还展示了用其训练的DeepSWE等智能体的出色表现,以及rLLM未来的发展方向,值得关注。
📄 标题: [rLLM: A Framework for Post-Training Language Agents]
🌐 来源: [Notion Blog] + https://pretty-radio-b75.notion.site/rLLM-A-Framework-for-Post-Training-Language-Agents-21b81902c146819db63cd98a54ba5f31
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
背景
rLLM团队发布了rLLM-v0.1,这是一个用于语言智能体后训练的可扩展框架,支持用户构建自定义智能体和环境,通过强化学习进行训练并部署到实际工作负载中。此前,Agentica团队开源了两个模型:DeepScaleR和DeepCoder,推动了推理模型的强化学习训练民主化。但推理模型只是起点,真正的语言智能体需要在复杂、不确定的环境中进行推理、行动和交互。2025年下半年,团队进入语言智能体时代,发布了rLLM框架和基于其训练的DeepSWE模型,后者在SWEBench-Verified上取得了42.2%的Pass@1(测试时缩放为59.0%)的SOTA成绩。
rLLM框架
设计目标与理念
rLLM旨在支持智能体从经验中学习,即通过与动态环境的持续交互进行学习。现有大多数智能体框架仅关注编排和推理,对部署后学习支持不足。rLLM提供了灵活的框架来构建自定义智能体工作流,支持在实际环境中部署智能体以生成交互数据,并内置了基于强化学习的后训练支持。它采用分层模块化设计,既方便智能体构建者快速开发,又便于算法开发者进行定制研究。同时,rLLM作为一个前端层,可与不同的分布式强化学习训练引擎集成,目前使用verl作为训练后端。
快速上手示例
文档提供了一个约30行代码的示例,展示了如何训练一个使用Python解释器解决数学问题的工具智能体。通过使用rLLM的相关模块和函数,用户可以轻松完成训练任务。
import hydrafrom rllm.agents import ToolAgent
from rllm.data.dataset import DatasetRegistry
from rllm.environments.tools.tool_env import ToolEnvironment
from rllm.rewards.reward_fn import math_reward_fn
from rllm.trainer.agent_trainer import AgentTrainer@hydra.main(config_path="pkg://rllm.trainer.config", config_name="ppo_trainer", version_base=None)
def main(config):train_dataset = DatasetRegistry.load_dataset("deepscaler_math", "train")test_dataset = DatasetRegistry.load_dataset("aime2024", "test")agent_args = {"tools": ["python"], "parser_name": "qwen", "system_prompt": "You are a math assistant that can write python to solve math problems."}env_args = {"tools": ["python"],"reward_fn": math_reward_fn,}trainer = AgentTrainer(agent_class=ToolAgent,env_class=ToolEnvironment,agent_args=agent_args,env_args=env_args,config=config,train_dataset=train_dataset,val_dataset=test_dataset,)trainer.train()if __name__ == "__main__":main()
架构与主要组件
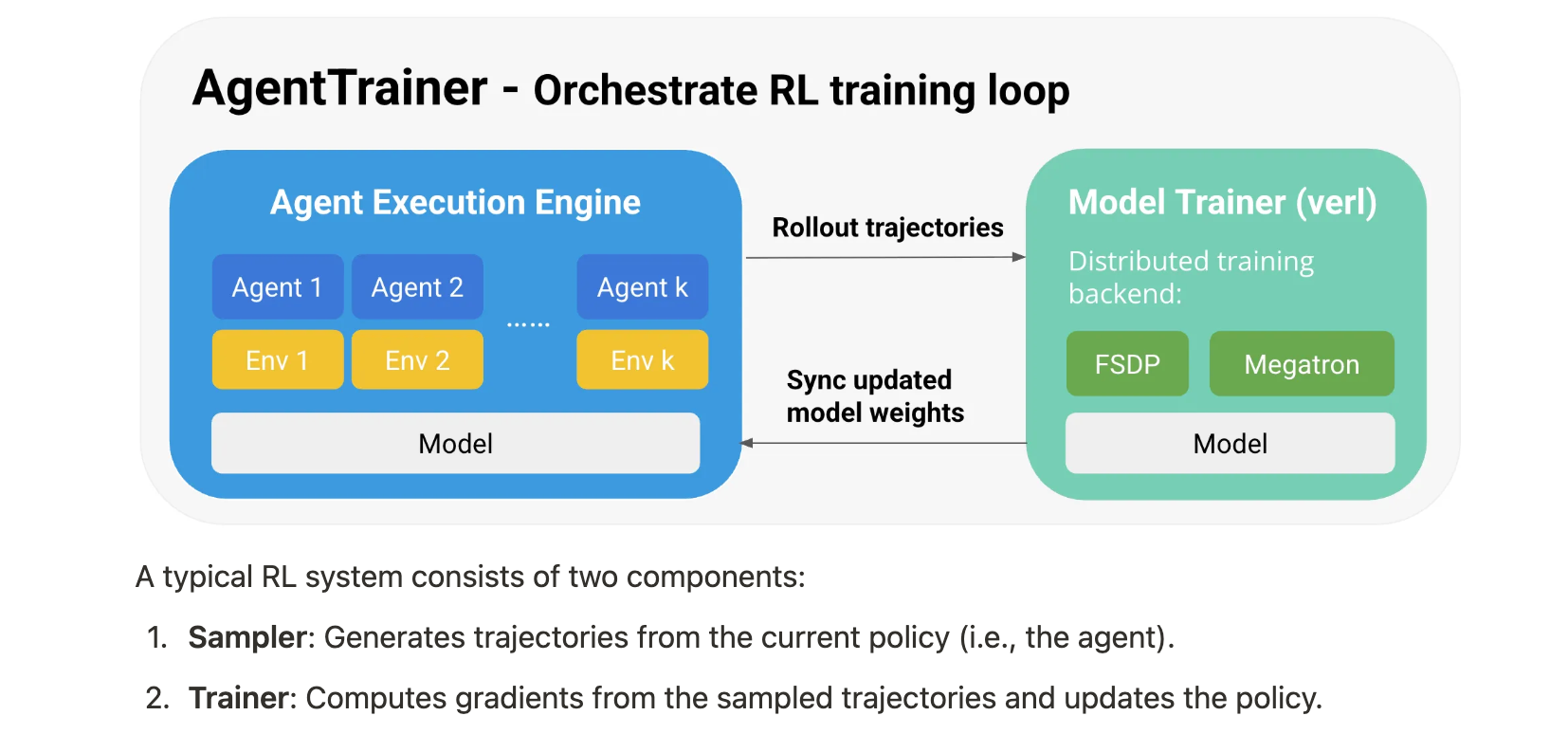
- 智能体和环境抽象:rLLM提供了简单的模块化接口,用户可以继承
BaseAgent和BaseEnv类来构建自定义智能体和环境。文档中给出了一个数学智能体和基础环境类的示例代码。
class MathAgent(BaseAgent):def __init__(self, accumulate_thinking=True):self.instruction = "Let's think step by step, and put your final answer within \\boxed{}."self._trajectory = Trajectory()self.messages = []self.accumulate_thinking = accumulate_thinkingdef update_from_env(self, observation, reward, done, info, **kwargs):if not self.trajectory.steps:question = observation["question"]formatted_observation = f"{question} {self.instruction}"else:formatted_observation = "Your previous answer may contain a mistake. Please review it."self.messages.append({"role": "user", "content": formatted_observation})def update_from_model(self, response, **kwargs):self.messages.append({"role": "assistant", "content": response})new_step = Step(chat_completions=copy.deepcopy(self.chat_completions))self.trajectory.steps.append(new_step)return Action(action=response)def reset(self):self._trajectory = Trajectory()self.messages = []@propertydef chat_completions(self):messages = copy.deepcopy(self.messages)if not self.accumulate_thinking:for msg in messages[:-1]:if msg["role"] == "assistant":_, sep, after = msg["content"].partition("</think>")if sep:msg["content"] = afterreturn messages@propertydef trajectory(self):return self._trajectorydef get_current_state(self):assert self._trajectory.stepsreturn self._trajectory.steps[-1]class BaseEnv(ABC):@abstractmethoddef reset(self) -> tuple[dict, dict]:pass@abstractmethoddef step(self, action: Any) -> tuple[Any, float, bool, dict]:passdef close(self):return@staticmethod@abstractmethoddef from_dict(info: dict) -> "BaseEnv":raise NotImplementedError("Subclasses must implement 'from_dict'")- AgentExecutionEngine:这是一个高性能的采样器,负责协调智能体和环境之间的交互,支持全异步、并行的轨迹滚动。在强化学习训练过程中,它与训练器无缝集成,支持多种强化学习算法。文档展示了如何使用它进行轨迹收集的示例。
engine = AgentExecutionEngine(agent_class=ToolAgent,agent_args={"tools": ["python"], "parser_name": "qwen"},env_class=ToolEnvironment,env_args={"tools": ["python"], "reward_fn": math_reward_fn},engine_name="openai",rollout_engine_args={"base_url": "http://localhost:30000/v1"},tokenizer=AutoTokenizer.from_pretrained("Qwen/Qwen3-4B"),sampling_params={"temperature": 0.6, "top_p": 0.95, "model": "Qwen/Qwen3-4B"},max_response_length=16384,max_prompt_length=2048,n_parallel_agents=64,
)test_dataset = DatasetRegistry.load_dataset("aime2024", "test")
tasks = test_dataset.repeat(n=8) # For pass@k evaluationresults = asyncio.run(engine.execute_tasks(tasks))
compute_pass_at_k(results)
- AgentTrainer:提供了一个简单的高级接口,用户可以指定训练工作负载和配置,调用
train()方法即可使用强化学习训练智能体。它使用AgentExecutionEngine作为轨迹采样器,verl作为模型训练器,并使用Ray来协调采样器和训练器之间的控制流。文档中给出了使用AgentTrainer进行强化学习训练的示例。
@hydra.main(config_path="pkg://rllm.trainer.config", config_name="ppo_trainer", version_base=None)
def main(config):train_dataset = DatasetRegistry.load_dataset("hotpotqa_combined", "train")val_dataset = DatasetRegistry.load_dataset("hotpotqa_combined", "test")tool_map = {"local_search": LocalRetrievalTool}env_args = {"max_steps": 20,"tool_map": tool_map,"reward_fn": search_reward_fn,}agent_args = {"system_prompt": SEARCH_SYSTEM_PROMPT, "tool_map": tool_map, "parser_name": "qwen"}trainer = AgentTrainer(agent_class=ToolAgent,env_class=ToolEnvironment,config=config,train_dataset=train_dataset,val_dataset=val_dataset,agent_args=agent_args,env_args=env_args,)trainer.train()
强化学习算法
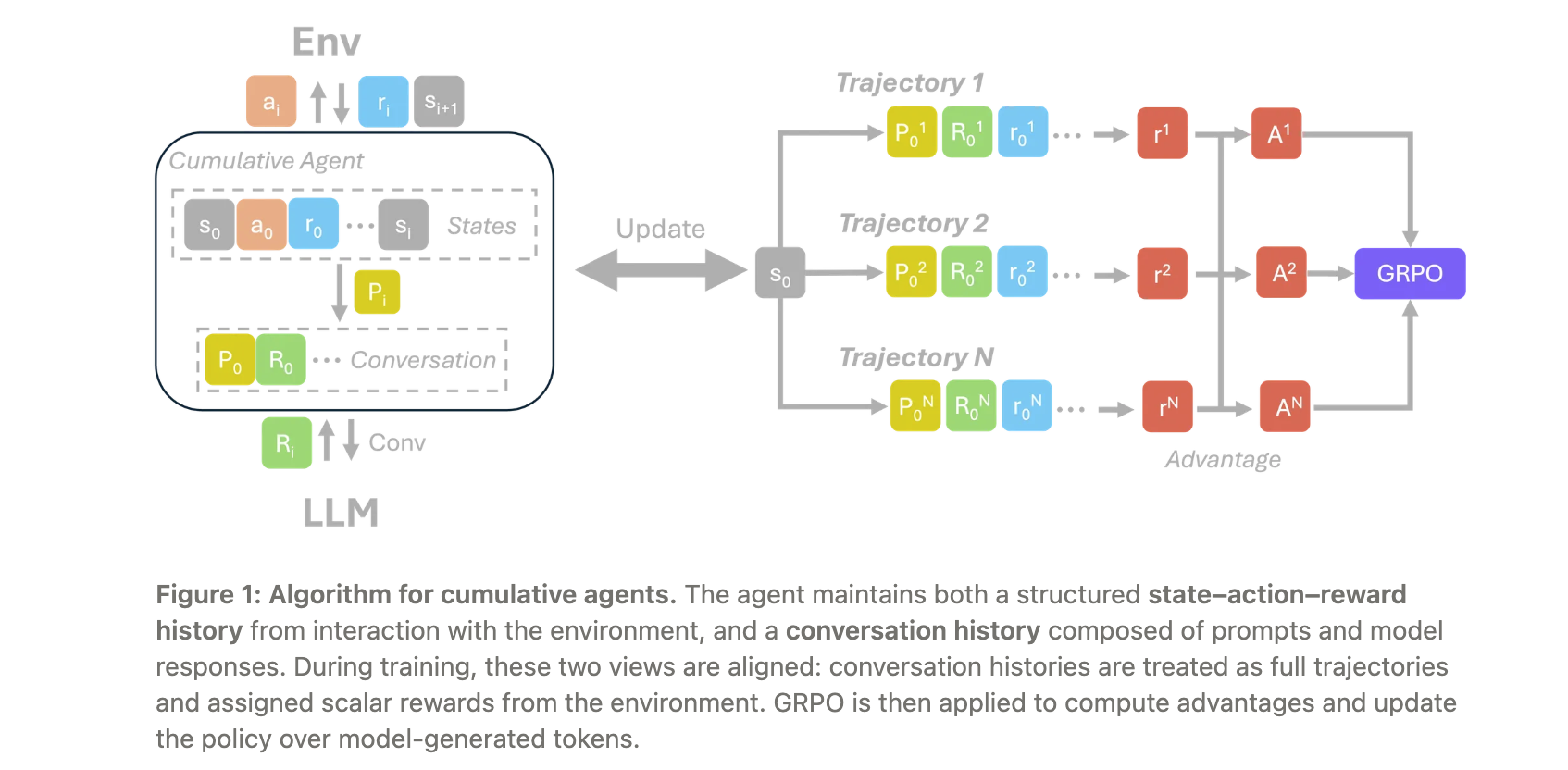
根据智能体随时间累积上下文的方式,rLLM将智能体分为累积智能体和非累积智能体,并为它们分别提供了不同的强化学习算法。
- 累积智能体:使用GRPO with Observation Masking算法,在训练时屏蔽非模型生成的标记,仅对模型生成的标记计算损失。该方法已用于训练DeepSWE等模型。
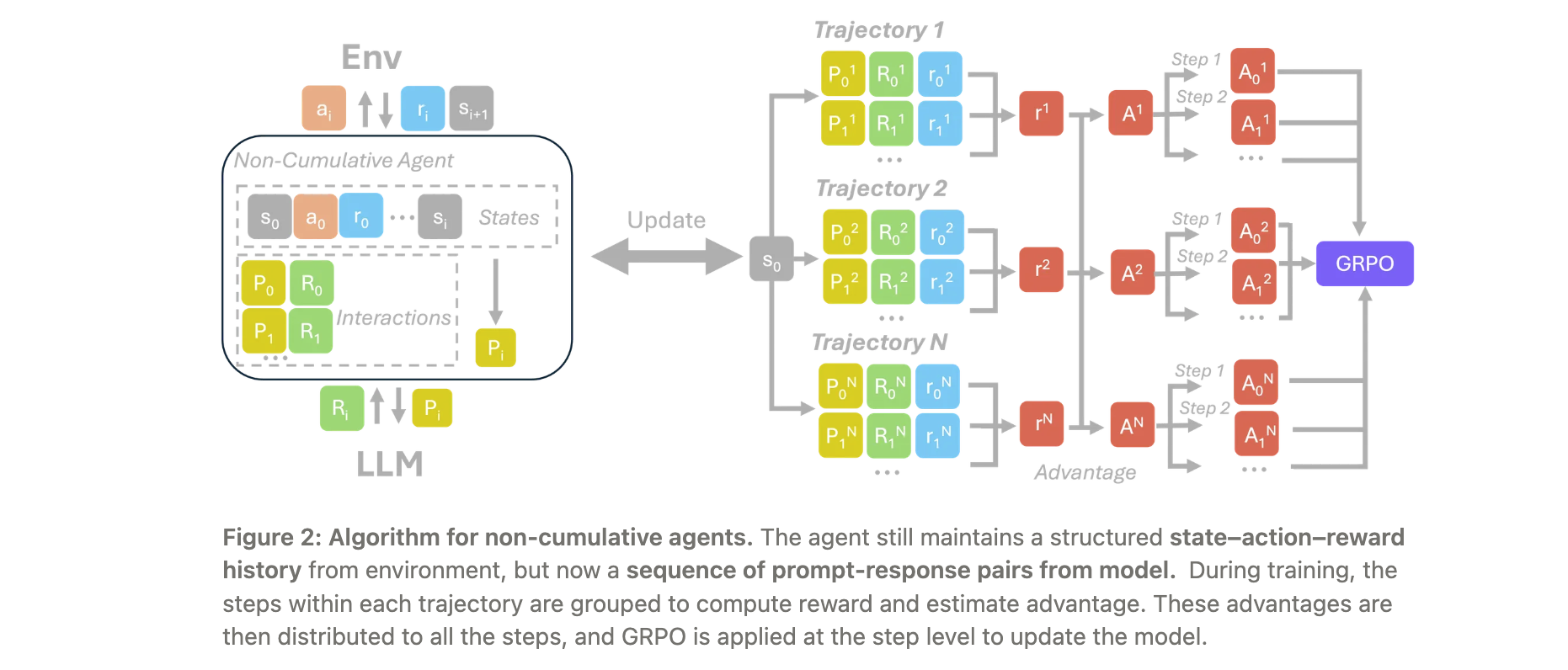
- 非累积智能体:支持两种方法,即Stepwise GRPO with Advantage Broadcasting和Stepwise GRPO with Per-Step Grouping。前者将最终步骤的优势广播到所有先前步骤,适用于早期行动对最终结果有重要贡献但缺乏细粒度奖励的情况;后者为每个步骤分配独立的奖励,并按步骤位置分组计算优势,适用于轨迹对称的情况。
内置语言智能体
rLLM包含一系列内置的智能体和环境,涵盖多个领域,如通用工具使用智能体、DeepSWE(SOTA编码/软件工程智能体)、DeepScaleR和DeepCoder(数学/编码推理模型)、FrozenLake智能体和WebAgent等。用户还可以使用rLLM的模块化API和训练引擎构建和训练自己的自定义智能体和环境,并欢迎贡献回rLLM社区。