JobSet:Kubernetes 分布式任务编排的统一解决方案
JobSet–Kubernetes 分布式任务编排的统一解决方案
在 Kubernetes 生态中,分布式机器学习训练和高性能计算(HPC)工作负载的编排一直是技术难点。随着大语言模型(LLM)等大型 AI 模型的兴起,单主机资源已无法满足需求,训练任务往往需要跨越数千个加速器芯片和主机。为此,Kubernetes 社区推出了 JobSet——一个专为分布式任务设计的开源 API,旨在为这类工作负载提供统一、高效的编排方案。本文将深入解析 JobSet 的核心概念、工作原理,并通过实例详解其配置参数与实践应用。
一、为什么需要 JobSet?
Kubernetes 现有的任务编排方案在应对分布式 ML/HPC 工作负载时存在明显局限,这正是 JobSet 诞生的背景。
1. 现有方案的痛点
-
框架绑定的碎片化问题:以 KubeFlow 训练 Operator 为例,它为不同框架(PyTorch、TensorFlow、MPI 等)设计了独立的自定义 API(如 PyTorchJob、TFJob)。这些 API 语义和行为各异,增加了跨框架管理的复杂性,且难以统一优化。
-
原生 Job API 的功能缺口:Kubernetes 原生 Job API 虽支持批处理工作负载(如带索引的完成模式、Pod 失效策略等),但在分布式 ML/HPC 场景中存在关键短板:
- 无法支持多模板 Pod:分布式任务常包含多种 Pod 类型(如驱动节点与工作节点),需不同容器配置和资源请求,原生 Job 仅支持单一 Pod 模板。
- 缺乏任务组管理:大规模任务需跨网络拓扑(如多机架)部署,对网络延迟敏感,需将通信本地化,原生 Job 无此能力。
- 缺失Pod 间通信管理:分布式任务依赖 Pod 间低延迟通信,需手动配置无头服务等资源,操作繁琐。
- 无灵活的启动顺序控制:部分框架(如 Ray 需先启动驱动节点,MPI 需先就绪工作节点)对启动顺序有要求,原生 Job 无法满足。
二、JobSet 核心概念与工作原理
JobSet 以 Kubernetes Job API 为基础,通过抽象层填补了分布式工作负载的编排空白,其核心设计思路是将分布式任务建模为一组协同工作的子 Job。
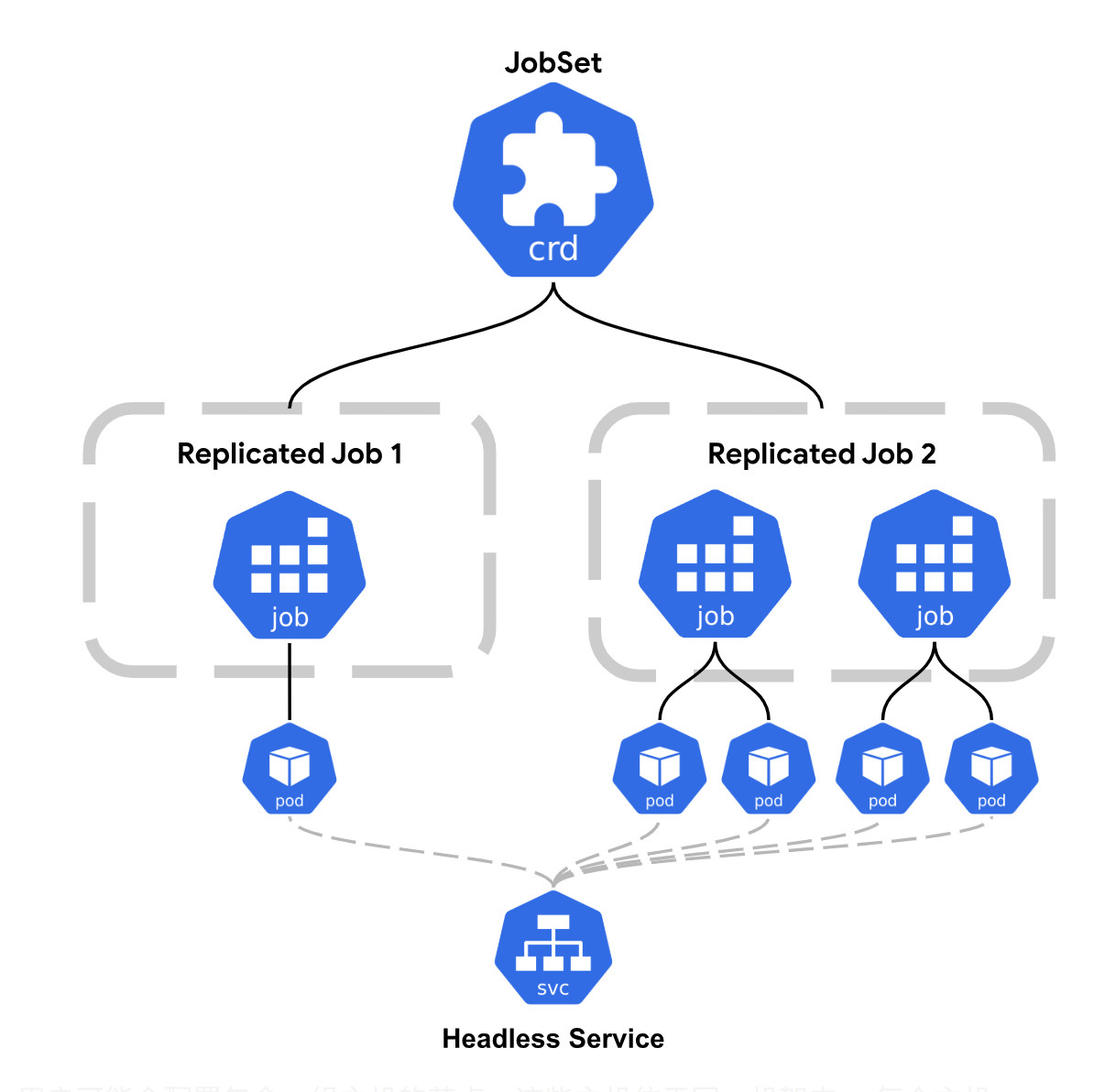
1. 核心抽象:ReplicatedJob
ReplicatedJob 是 JobSet 的核心概念,本质是“带副本数的 Job 模板”。它允许用户定义一种 Pod 类型的配置(如资源请求、失效策略等),并指定该类型需要运行的副本数量。
例如,在分布式训练的“驱动-工作节点”模式中,可定义两个 ReplicatedJob:
- 一个副本的“驱动节点”ReplicatedJob(负责协调训练);
- 多个副本的“工作节点”ReplicatedJob(负责实际计算)。
通过 ReplicatedJob,JobSet 实现了多模板 Pod 管理,满足不同类型节点的差异化需求。
2. 关键特性解析
JobSet 的特性围绕分布式 ML/HPC 工作负载的核心需求设计,具体包括:
(1)任务组与拓扑感知调度
大规模分布式任务对网络延迟极其敏感(如跨机架通信可能导致性能下降)。JobSet 支持按拓扑域的独占放置,通过注解 alpha.jobset.sigs.k8s.io/exclusive-topology 可将子任务绑定到特定拓扑域(如节点池、机架),确保通信本地化。
例如,在 TPU 集群中,JobSet 可将每个子任务分配到独立的 TPU 切片(加速器岛),使切片内的 Pod 通过高带宽链路(如 ICI 网格)通信,仅在切片间通过数据中心网络同步梯度,大幅降低延迟。
(2)自动管理 Pod 间通信
分布式任务依赖 Pod 间高效通信,JobSet 会自动创建和管理无头服务(Headless Service),通过 Pod 主机名实现直接通信,无需用户手动配置网络资源。这一特性对需要频繁数据交换的场景(如分布式梯度同步)至关重要。
(3)可配置的成功与失效策略
- 成功策略:控制 JobSet 何时标记为“完成”,支持“Any”(任一子任务完成)或“All”(所有子任务完成)。例如,可配置为“仅当所有工作节点完成时,JobSet 才完成”。
- 失效策略:定义任务失败时的处理逻辑,通过
failurePolicy.maxRestarts指定最大重启次数。若子任务失败,JobSet 可重启整个任务组,使工作负载从检查点恢复;未指定时,任一子任务失败则整个 JobSet 标记为失败。
三、实践示例:基于 JobSet 的 TPU 分布式训练
以下是使用 JobSet 在 GKE 集群中运行 Jax 分布式训练的示例,我们将逐行解析配置参数的作用。
# 运行简单的 Jax 工作负载
apiVersion: jobset.x-k8s.io/v1alpha2 # JobSet API 版本
kind: JobSet # 资源类型为 JobSet
metadata:name: multislice # JobSet 名称annotations:# 为每个子任务独占拓扑域,此处指定节点池alpha.jobset.sigs.k8s.io/exclusive-topology: cloud.google.com/gke-nodepool
spec:failurePolicy:maxRestarts: 3 # 最多重启 3 次(任务失败时)replicatedJobs: # 定义子任务组(ReplicatedJob 列表)- name: workers # 子任务名称(工作节点组)replicas: 4 # 子任务副本数(对应 4 个 TPU 切片)template: # Job 模板(每个副本对应一个 Job)spec:parallelism: 2 # 每个 Job 并行运行的 Pod 数(每个 TPU 切片的虚拟机数量)completions: 2 # 每个 Job 需完成的 Pod 数(与 parallelism 一致,确保所有 Pod 运行)backoffLimit: 0 # Pod 失败后不重试(适合快速失败场景)template: # Pod 模板spec:hostNetwork: true # 使用主机网络(降低容器网络开销)dnsPolicy: ClusterFirstWithHostNet # 结合主机网络的 DNS 策略nodeSelector: # 节点选择器(指定运行的 TPU 节点)cloud.google.com/gke-tpu-accelerator: tpu-v5-lite-podslice # TPU 类型cloud.google.com/gke-tpu-topology: 2x4 # TPU 拓扑结构(2 个虚拟机,每个 4 个芯片)containers:- name: jax-tpu # 容器名称image: python:3.8 # 基础镜像ports: # 暴露端口(用于 Pod 间通信)- containerPort: 8471- containerPort: 8080securityContext:privileged: true # 特权模式(需访问 TPU 设备)command: # 容器启动命令- bash- -c- |# 安装 Jax 及 TPU 支持pip install "jax[tpu]" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html# 验证 TPU 设备数量python -c 'import jax; print("Global device count:", jax.device_count())'sleep 60 # 保持容器运行以便观察resources:limits:google.com/tpu: 4 # 请求 4 个 TPU 核心
关键参数解析
-
元数据与 API 版本
apiVersion: jobset.x-k8s.io/v1alpha2:指定 JobSet 的 API 版本(当前为 alpha 版,未来可能有变动)。alpha.jobset.sigs.k8s.io/exclusive-topology:注解确保每个子任务(ReplicatedJob)独占指定的拓扑域(此处为 GKE 节点池),避免跨域通信导致的延迟。
-
失效策略
failurePolicy.maxRestarts: 3:当子任务失败时,JobSet 最多重启 3 次,适合需要容错的分布式训练场景(如从检查点恢复)。
-
ReplicatedJob 配置
replicas: 4:创建 4 个相同的子任务,对应 4 个 TPU 切片(每个切片为一个独立的加速器岛)。parallelism: 2和completions: 2:每个子任务包含 2 个 Pod(对应 TPU 切片的 2 个虚拟机),确保所有计算资源被充分利用。
-
Pod 模板配置
hostNetwork: true和dnsPolicy: ClusterFirstWithHostNet:使用主机网络减少容器网络开销,同时保证 DNS 解析正常,适合对网络延迟敏感的场景。nodeSelector:指定 Pod 只能调度到包含tpu-v5-lite-podslice加速器且拓扑为2x4的节点,确保硬件资源匹配。resources.limits.google.com/tpu: 4:为每个 Pod 请求 4 个 TPU 核心,满足 Jax 分布式训练的计算需求。
-
容器命令
安装 Jax 的 TPU 支持库并验证设备数量,确保分布式环境正确初始化。sleep 60用于保持容器运行,方便观察任务状态。
四、未来展望与参与方式
TPU 核心,满足 Jax 分布式训练的计算需求。
- 容器命令
安装 Jax 的 TPU 支持库并验证设备数量,确保分布式环境正确初始化。sleep 60用于保持容器运行,方便观察任务状态。
四、未来展望与参与方式
JobSet 为 Kubernetes 分布式任务编排提供了统一的解决方案,它不仅简化了 ML/HPC 工作负载的部署与管理,更通过灵活的扩展机制适配了多样化的硬件与框架需求。随着生态的成熟,JobSet 有望成为分布式任务编排的标准 API,推动 Kubernetes 在 AI 与高性能计算领域的进一步普及。