YoloV12改进策略:Block改进|MKP,多尺度卷积核级联结构,增强感受野适应性|即插即用|AAAI 2025
文章目录
- 1 论文信息
- 2 创新点
- 2.1 特征互补映射模块(FCM)
- 2.2 多内核感知单元(MKP)
- 2.3 冗余驱动的轻量化设计
- 3 方法
- 3.1 整体架构
- 3.2 MKP单元优化
- 3.3 MKP设计优势
- 4 效果
- 4.1 性能对比实验
- 4.2 消融实验
- 4.3 效率优势
- 5 论文总结
- 代码
- 完整代码
- Pzconv模块代码详解
- 辅助函数和基础模块
- Pzconv模块核心实现
- 测试代码
- 关键设计解析
- 1. 多尺度特征提取
- 2. 深度可分离卷积
- 3. 特征变换与非线性激活
- 4. 残差连接
- 5. 尺寸保持
- 改进策略
- 测试结果
- 总结
1 论文信息
FBRT-YOLO(Faster and Better for Real-Time Aerial Image Detection)是由北京理工大学团队提出的专用于航拍图像实时目标检测的创新框架,发表于AAAI 2025。论文针对航拍场景中小目标检测的核心难题展开研究,重点解决小目标因分辨率低、背景干扰多导致的定位困难,以及现有方法在实时性与精度间的失衡问题。
航拍图像目标检测是无人机、遥感监测等应用的关键技术,但面临独特挑战:图像中目标(如车辆、行人)通常仅由少量像素(<0.1%图像面积)构成,且易受云层、建筑群等复杂背景干扰。传统方法通过增加分辨率提升精度,但显著增加计算负担,难以满足嵌入式设备(如无人机芯片)的实时需求。FBRT-YOLO通过轻量化设计,在Visdrone、UAVDT和AI-TOD三大航拍数据集上实现了精度与速度的突破性平衡。
论文链接:https://arxiv.org/pdf/2504.20670
2 创新点
2.1 特征互补映射模块(FCM)
FCM模块致力于解决深层网络中小目标空间信息丢失这一根本问题。传统特征金字塔(如FPN)虽融合深浅层特征,但主干网络在传递过程中仍会弱化小目标的精确位置信息。FCM通过“拆分-变换-互补映射-聚合”四步策略实现信息融合:
- 通道分割:将输入特征按比例α拆分为两部分( X 1 ∈ R α C × H × W , X 2 ∈ R ( 1 − α ) C × H × W ) X¹∈R^{αC×H×W}, X²∈R^{(1-α)C×H×W}) X1∈RαC×H×W,X2∈R(1−α)C×H×W),其中α随网络深度动态调整(深层α更低以保留更多空间信息)。
- 定向变换:X¹分支通过3×3卷积提取语义信息,X²分支通过逐点卷积提取空间位置信息。
- 互补映射:通过通道交互(生成通道权重 W c W_c Wc)和空间交互(生成空间权重 W s W_s Ws)计算信息权重,强化关键特征。
- 特征聚合:按公式 Y = W c ⋅ X 1 + W s ⋅ X 2 Y = W_c·X¹ + W_s·X² Y=Wc⋅X1+Ws⋅X2融合信息,使深层特征同时保有语义和位置信息。
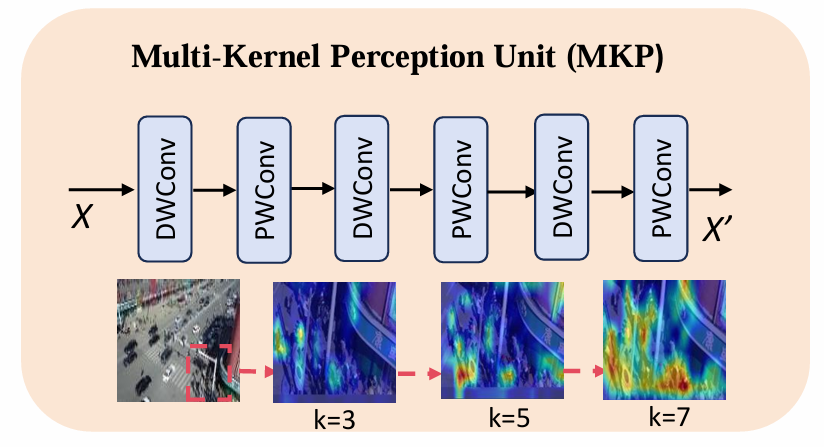
2.2 多内核感知单元(MKP)
针对航拍图像中目标尺度差异大的挑战,MKP取代了YOLO的最终下采样层,采用多尺度卷积核级联结构增强感受野适应性:
- 并行使用3×3、5×5、7×7卷积核提取不同尺度特征
- 通过逐点卷积(A)整合跨尺度信息,公式表达为: M K P ( X ) = A ( C o n v k = 3 ( X ) ⊕ C o n v k = 5 ( X ) ⊕ C o n v k = 7 ( X ) ) MKP(X) = A(Conv_{k=3}(X) ⊕ Conv_{k=5}(X) ⊕ Conv_{k=7}(X)) MKP(X)=A(Convk=3(X)⊕Convk=5(X)⊕Convk=7(X))
该设计避免单一卷积核的局限性:小卷积核感受野不足,大卷积核引入过多背景噪声。
2.3 冗余驱动的轻量化设计
传统检测器在高分辨率图像处理中存在结构冗余。FBRT-YOLO通过两项精简策略优化效率:
- 下采样层重构:用分组卷积替代标准卷积执行空间下采样,后续接逐点卷积扩展通道,参数量降至标准卷积的1/4(公式对比: P a r a m s s t d = k 2 C i n C o u t , P a r a m s o p t = k 2 C i n G + C i n C o u t Params_{std}=k²C_inC_out, Params_{opt}=k²C_inG + C_inC_out Paramsstd=k2CinCout,Paramsopt=k2CinG+CinCout,G为分组数)。
- 检测头简化:结合MKP单元移除冗余检测头,减少输出层计算量。
3 方法
3.1 整体架构
FBRT-YOLO以YOLOv8为基线,主干网络嵌入FCM模块替代原C2f单元,并在最后一层用MKP单元替换下采样操作。整体架构分为三阶段:
- 特征提取:输入图像经多层卷积,每阶段输出接入FCM模块融合空间-语义信息。
- 多尺度感知:MKP单元在最终阶段捕获大范围上下文,输出多尺度特征图。
- 检测头:精简后的头部输出预测框(类别、置信度、坐标)。
3.2 MKP单元优化
- 卷积核组合实验表明3/5/7为最佳尺寸(过小则感受野不足,过大引入噪声)
- 不同尺度间加入批归一化和LeakyReLU,避免梯度消失。
3.3 MKP设计优势
- 计算高效:深度可分离卷积大幅减少计算量
- 多尺度特征融合:不同尺寸的卷积核捕获不同范围的特征
- 残差学习:避免信息丢失,促进梯度流动
- 通道交互:1×1卷积促进通道间的信息交换
- 尺寸不变:适合嵌入各种网络架构
4 效果
4.1 性能对比实验
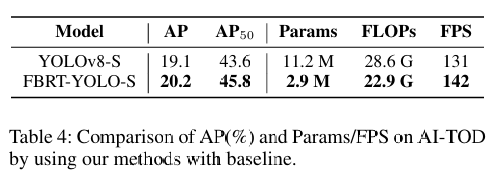
在三大航拍数据集上的测试表明,FBRT-YOLO全面超越现有实时检测器:
- Visdrone数据集:FBRT-YOLO-S模型AP达30.1%,较YOLOv8-S提升2.3%,参数量减少74%。
- UAVDT数据集:AP为18.4%,超过GLSAN(17.1%)和CEASC(17.6%)。
- AI-TOD数据集(小目标为主):AP50提升2.2%,GFLOPs降低20%。
表2:Visdrone数据集上模型性能对比
| 模型 | AP(%) | 参数量(M) | GFLOPs | 推理速度(FPS) |
|---|---|---|---|---|
| YOLOv8-S | 27.8 | 11.1 | 28.6 | 142 |
| FBRT-YOLO-S | 30.1 | 2.9 | 22.8 | 189 |
| RT-DETR-R34 | 28.9 | 19.2 | 98.3 | 156 |
| FBRT-YOLO-M | 30.2 | 18.7 | 76.5 | 173 |
4.2 消融实验
以YOLOv8-S为基线,逐步引入改进组件:
- 冗余优化:参数减少18%,计算负载降11%,精度略降0.2%(AP)。
- 添加FCM:AP50提升1.4%,因特征增强补偿了精度损失。
- 替换MKP:AP提升1.6%,训练收敛速度加快30%。
可视化热图显示,FBRT-YOLO对密集小目标的响应强度显著高于基线模型,尤其在车辆群、行人小目标等场景中关注区域更精确。
4.3 效率优势
- 边缘部署潜力:FBRT-YOLO-N仅2.9M参数,在嵌入式GPU上达189 FPS,较YOLOv8-N加速45%。
- 计算负载优化:MKP单元通过多核并行计算,单帧处理延迟降至5ms以下,满足无人机实时避障需求。
5 论文总结
FBRT-YOLO通过特征互补映射模块(FCM) 与多内核感知单元(MKP) 的创新设计,解决了航拍图像检测中小目标信息丢失和多尺度适应性不足的核心问题。其贡献主要体现在三方面:
- 理论层面:提出空间-语义信息互补映射机制,缓解深层网络位置信息衰减问题;
- 工程层面:轻量化设计(参数量最高降74%)满足嵌入式设备实时需求;
- 应用层面:在Visdrone等数据集上AP提升1.1-2.3%,为无人机安防、灾害监测提供高效解决方案。
代码
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as Fdef autopad(k, p=None, d=1): # kernel, padding, dilation"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""Perform transposed convolution of 2D data."""return self.act(self.conv(x))class Pzconv(nn.Module):def __init__(self, dim):super().__init__()self.conv1 = nn.Conv2d(dim, dim, 3,1, 1, groups=dim)self.conv2 = Conv(dim, dim, k=1, s=1, )self.conv3 = nn.Conv2d(dim, dim, 5,1, 2, groups=dim)self.conv4 = Conv(dim, dim, 1, 1)self.conv5 = nn.Conv2d(dim, dim, 7,1, 3, groups=dim)def forward(self, x):x1 = self.conv1(x)x2 = self.conv2(x1)x3 = self.conv3(x2)x4 = self.conv4(x3)x5 = self.conv5(x4)x6 = x5 + xreturn x6# print(x.shape)
if __name__ == "__main__":# 定义输入张量大小(Batch、Channel、Height、Wight)B, C, H, W = 16, 64, 40, 40input_tensor = torch.randn(B,C,H,W) # 随机生成输入张量dim=C# 创建 ARConv 实例block = Pzconv(dim=64)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")sablock = block.to(device)print(sablock)input_tensor = input_tensor.to(device)# 执行前向传播output = sablock(input_tensor)# 打印输入和输出的形状print(f"Input: {input_tensor.shape}")print(f"Output: {output.shape}")
Pzconv模块代码详解
辅助函数和基础模块
def autopad(k, p=None, d=1):"""自动计算padding大小以保持输出尺寸不变"""if d > 1:# 计算实际卷积核大小(考虑膨胀率)k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]if p is None:# 自动计算padding(卷积核大小的一半)p = k // 2 if isinstance(k, int) else [x // 2 for x in k]return pclass Conv(nn.Module):"""标准卷积模块(卷积+BN+激活)"""default_act = nn.SiLU() # 默认激活函数为SiLUdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()# 创建卷积层(自动计算padding)self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2) # 批归一化# 设置激活函数(默认为SiLU)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""应用卷积、批归一化和激活函数"""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""直接应用卷积和激活函数(跳过批归一化)"""return self.act(self.conv(x))
Pzconv模块核心实现
class Pzconv(nn.Module):def __init__(self, dim):"""初始化Pzconv模块:param dim: 输入和输出的通道数"""super().__init__()# 3x3深度可分离卷积(保持尺寸不变)self.conv1 = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)# 1x1标准卷积(包含BN和激活)self.conv2 = Conv(dim, dim, k=1, s=1)# 5x5深度可分离卷积(保持尺寸不变)self.conv3 = nn.Conv2d(dim, dim, 5, 1, 2, groups=dim)# 1x1标准卷积(包含BN和激活)self.conv4 = Conv(dim, dim, k=1, s=1)# 7x7深度可分离卷积(保持尺寸不变)self.conv5 = nn.Conv2d(dim, dim, 7, 1, 3, groups=dim)def forward(self, x):"""前向传播过程"""# 第一层:3x3深度可分离卷积x1 = self.conv1(x)# 第二层:1x1标准卷积(带BN和激活)x2 = self.conv2(x1)# 第三层:5x5深度可分离卷积x3 = self.conv3(x2)# 第四层:1x1标准卷积(带BN和激活)x4 = self.conv4(x3)# 第五层:7x7深度可分离卷积x5 = self.conv5(x4)# 残差连接:原始输入 + 最终输出x6 = x5 + xreturn x6
测试代码
if __name__ == "__main__":# 定义输入张量大小(Batch, Channel, Height, Width)B, C, H, W = 16, 64, 40, 40input_tensor = torch.randn(B, C, H, W) # 随机生成输入张量# 创建Pzconv实例block = Pzconv(dim=C)# 检测并设置设备(GPU优先)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")sablock = block.to(device)input_tensor = input_tensor.to(device)# 执行前向传播output = sablock(input_tensor)# 打印输入和输出的形状print(f"Input: {input_tensor.shape}")print(f"Output: {output.shape}")
关键设计解析
1. 多尺度特征提取
Pzconv模块结合了三种不同尺度的卷积核:
- 3×3卷积:捕捉局部特征
- 5×5卷积:捕捉中等范围特征
- 7×7卷积:捕捉更大范围的上下文信息
2. 深度可分离卷积
模块中的conv1、conv3和conv5使用了深度可分离卷积:
groups=dim参数使卷积在通道维度上独立进行- 大大减少了计算量和参数量
- 保持空间维度不变(padding设置得当)
3. 特征变换与非线性激活
模块中的conv2和conv4是1×1标准卷积:
- 包含批归一化(BN)和激活函数(SiLU)
- 增加非线性表达能力
- 进行通道间的信息交互
4. 残差连接
- 最终输出
x5与原始输入x相加 - 缓解深层网络的梯度消失问题
- 保留原始特征信息
5. 尺寸保持
所有卷积层都通过合理的padding设置保持了特征图的空间尺寸不变:
- 3×3卷积:padding=1
- 5×5卷积:padding=2
- 7×7卷积:padding=3
改进策略
对Pzconv模块做修改,增加通道的扩展和缩放,代码如下:
class Pzconv(nn.Module):def __init__(self, dim, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv1 = nn.Conv2d(dim, dim, 3,1, 1, groups=dim)self.conv2 = Conv(dim, dim*4, k=1, s=1, )self.conv3 = nn.Conv2d(dim * 4, dim, 5,1, 2, groups=dim)self.conv4 = Conv(dim, dim*4, 1, 1)self.conv5 = nn.Conv2d(dim * 4, dim, 7,1, 3, groups=dim)def forward(self, x):x1 = self.conv1(x)x2 = self.conv2(x1)x3 = self.conv3(x2)x4 = self.conv4(x3)x5 = self.conv5(x4)x6 = x5 + xreturn x6
将Pzconv复制到block.py中,如下图:
然后使用Pzconv替换ABlock的mlp,替换C3k2和C3k模块的Bottleneck,代码如下:
class C3k2(C2f):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""super().__init__(c1, c2, n, shortcut, g, e)self.m = nn.ModuleList(C3k(self.c, self.c, 2, shortcut, g) if c3k else Pzconv(self.c) for _ in range(n))class C3k(C3):"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):"""Initializes the C3k module with specified channels, number of layers, and configurations."""super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e) # hidden channels# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))self.m = nn.Sequential(*(Pzconv(c_) for _ in range(n)))
class ABlock(nn.Module):"""ABlock class implementing a Area-Attention block with effective feature extraction.This class encapsulates the functionality for applying multi-head attention with feature map are dividing into areasand feed-forward neural network layers.Attributes:dim (int): Number of hidden channels;num_heads (int): Number of heads into which the attention mechanism is divided;mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2;area (int, optional): Number of areas the feature map is divided. Defaults to 1.Methods:forward: Performs a forward pass through the ABlock, applying area-attention and feed-forward layers.Examples:Create a ABlock and perform a forward pass>>> model = ABlock(dim=64, num_heads=2, mlp_ratio=1.2, area=4)>>> x = torch.randn(2, 64, 128, 128)>>> output = model(x)>>> print(output.shape)Notes: recommend that dim//num_heads be a multiple of 32 or 64."""def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1):"""Initializes the ABlock with area-attention and feed-forward layers for faster feature extraction."""super().__init__()self.attn = AAttn(dim, num_heads=num_heads, area=area)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Pzconv(dim)self.apply(self._init_weights)def _init_weights(self, m):"""Initialize weights using a truncated normal distribution."""if isinstance(m, nn.Conv2d):nn.init.trunc_normal_(m.weight, std=0.02)if m.bias is not None:nn.init.constant_(m.bias, 0)def forward(self, x):"""Executes a forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor."""x = x + self.attn(x)x = x + self.mlp(x)return x在项目的根目录添加train.py脚本,代码如下:
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('ultralytics/cfg/models/v12/yolov12l.yaml')# Train the modelresults = model.train(data='VOC.yaml',epochs=10,batch=8,imgsz=640,scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9mosaic=1.0,mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6device="0",)
训练完成后,就可以看到测试结果!
在项目的根目录添加val.py脚本,代码如下:
from ultralytics import YOLOif __name__ == '__main__':# Load a model# model = YOLO('yolov8m.pt') # load an official modelmodel = YOLO('runs/detect/train/weights/best.pt') # load a custom model# Validate the modelmetrics = model.val(split='val') # no arguments needed, dataset and settings rememberedsplit='val’代表使用验证集做测试,如果改为split=‘test’,则使用测试集做测试!
在项目的根目录添加test.py脚本,代码如下:
from ultralytics import YOLOif __name__ == '__main__':# Load a model# model = YOLO('yolov8m.pt') # load an official modelmodel = YOLO('runs/detect/train/weights/best.pt') # load a custom modelresults = model.predict(source="ultralytics/assets", device='0',save=True) # predict on an imageprint(results)
test脚本测试assets文件夹下面的图片,save设置为true,则保存图片的测试结果!
测试结果
10 epochs completed in 0.407 hours.
Optimizer stripped from runs\detect\train6\weights\last.pt, 63.8MB
Optimizer stripped from runs\detect\train6\weights\best.pt, 63.8MBValidating runs\detect\train6\weights\best.pt...
Ultralytics 8.3.63 🚀 Python-3.9.21 torch-2.3.1 CUDA:0 (NVIDIA GeForce RTX 3090, 24575MiB)
YOLOv12l summary (fused): 778 layers, 31,293,744 parameters, 0 gradients, 89.3 GFLOPsClass Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 15/15 [00:03<00:00, 3.82it/s]all 230 1412 0.571 0.29 0.266 0.164c17 40 131 0.357 0.679 0.479 0.353c5 19 68 0.429 0.5 0.484 0.298helicopter 13 43 0.41 0.233 0.249 0.123c130 20 85 0.142 0.271 0.116 0.0687f16 11 57 0.1 0.421 0.154 0.072b2 2 2 1 0 0 0other 13 86 0.279 0.0677 0.142 0.0561b52 21 70 0.36 0.643 0.542 0.39kc10 12 62 0.412 0.613 0.544 0.369command 12 40 0.287 0.45 0.311 0.206f15 21 123 0.372 0.22 0.248 0.114kc135 24 91 0.354 0.297 0.27 0.152a10 4 27 1 0 0.00119 0.000836b1 5 20 0 0 0.0196 0.0106aew 4 25 0.991 0.04 0.113 0.0939f22 3 17 1 0 0.0326 0.0194p3 6 105 0.89 0.886 0.924 0.584p8 1 1 1 0 0.0663 0.0265f35 5 32 1 0 0.0299 0.0121f18 13 125 0.677 0.824 0.838 0.519v22 5 41 0.025 0.00793 0.0644 0.0272su-27 5 31 0.594 0.839 0.833 0.499il-38 10 27 0.242 0.579 0.285 0.169tu-134 1 1 1 0 0 0su-33 1 2 1 0 0 0an-70 1 2 1 0 0.153 0.122tu-22 8 98 0.493 0.255 0.287 0.13
Speed: 0.1ms preprocess, 10.5ms inference, 0.0ms loss, 1.6ms postprocess per image
总结
完整代码如下:
通过网盘分享的文件:yolov12-615
链接: https://pan.baidu.com/s/1Oq8Geyq5Y9xtF1AMwo3BXg?pwd=iecc 提取码: iecc
--来自百度网盘超级会员v3的分享