2 Studying《Arm A715 Technical Reference Manual》
目录
2. The Cortex®‑A715 core
2.1 Cortex®‑A715 core features
2.2 Cortex®‑A715 core confifiguration options
2.3 DSU-110 dependent features
2.4 Supported standards and specifications
2.6 Design tasks
3. Technical overview
3.1 Core components
3.2 Interfaces
3.3 Programmers model
4. Clocks and resets
5. Power management
5.1 Voltage and power domains
5.2 Architectural clock gating modes //架构级的时钟门控模式
5.3 Power control
5.4 Core power modes
5.5 Performance and power management
5.6 Cortex®‑A715 core powerup and powerdown sequence
5.7 Debug over powerdown
6. Memory management
6.1 Memory Management Unit components
6.2 TLB entry content //TLB条目的内容
6.3 TLB match process //TLB匹配过程
6.4 Translation table walks //转换表遍历
6.5 Hardware management of the Access flag and dirty state //访问标志(Access Flag)和脏位(Dirty State)的硬件管理
6.6 Responses
6.7 Memory behavior and supported memory types
6.8 Page-based hardware attributes
7. L1 instruction memory system
7.1 L1 instruction cache behavior
7.2 L1 instruction cache Speculative memory accesses //L1指令缓存的推测性内存访问
7.3 Program flow prediction
8. L1 data memory system
8.1 L1 data cache behavior
8.2 Write streaming mode
8.3 Instruction implementation in the L1 data memory system
8.4 Internal exclusive monitor //内部独占监视器
8.5 Data prefetching
9. L2 memory system
9.1 L2 cache
9.2 Support for memory types
9.3 Transaction capabilities //事务能力
10. Direct access to internal memory
10.1 L1 cache encodings
10.2 L2 cache encodings
10.3 L2 TLB encodings
11. RAS Extension support
11.1 Cache protection behavior
11.2 Error containment //错误隔离
11.3 Fault detection and reporting
11.4 Error detection and reporting
11.5 Error injection //错误注入
11.6 AArch64 RAS registers
12. Utility bus
12.1 Base addresses for system components
13. GIC CPU interface
13.1 Disable the GIC CPU interface
13.2 AArch64 GIC system registers
14. Advanced SIMD and floating-point support
15. Scalable Vector Extensions support
16. System control
17. Debug
17.1 Supported debug methods
17.2 Debug register interfaces
17.3 Debug events
17.4 Debug memory map and debug signals
17.5 ROM table
17.6 CoreSight™ component identifification
17.7 CTI register identifification values
17.8 External Debug registers
17.9 External ROM table registers
18. Performance Monitors Extension support
18.1 Performance monitors events
18.2 Performance monitors interrupts
18.3 External register access permissions
18.4 AArch64 Performance Monitors registers
18.5 External PMU registers
19. Embedded Trace Extension support
19.1 Trace unit resources
19.2 Trace unit generation options
19.3 Reset the trace unit
19.4 Program and read the trace unit registers
19.5 Trace unit register interfaces
19.6 Interaction with the Performance Monitoring Unit and Debug
19.7 ETE events
19.8 AArch64 Trace unit registers
19.9 External ETE registers
20. Trace Buffer Extension support
20.1 Program and read the trace buffer registers
20.2 Trace buffer register interface
21. Activity Monitors Extension support
21.1 Activity monitors access
21.2 Activity monitors counters
21.3 Activity monitors events
21.4 AArch64 Activity Monitors registers
21.5 External AMU registers
22. Statistical Profiling Extension Support
22.1 Statistical Profiling Extension events packet
22.2 Statistical Profiling Extension data source packet
2. The Cortex®‑A715 core
Cortex®-A715核心是一款平衡性能、低功耗和面积受限的产品,实现了Arm®v9.0-A架构。Arm®v9.0-A架构扩展了Arm®v8‑A架构中定义的架构,延伸至Arm®v8.5-A。Cortex®-A715核心面向大屏幕计算应用和智能手机应用。
Cortex®-A715核心实现在DSU-110 DynamIQ™集群内部。它连接到DynamIQ™共享单元-110(DSU-110),作为具有L3缓存和嗅控功能的完整互连。这种连接配置也用于具有不同类型核心的系统中,其中Cortex®-A715核心是平衡性能核心。
下图显示了一个带有四个Cortex®-A715核心的DynamIQ™集群的示例配置。
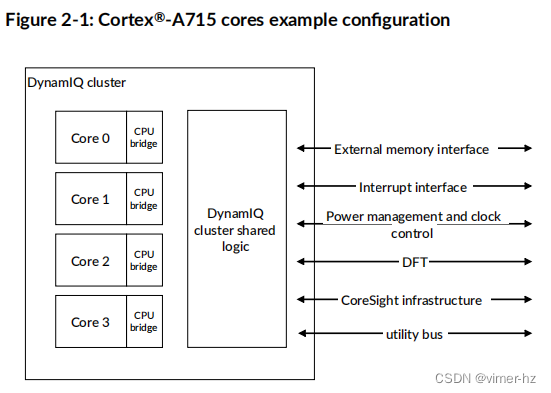
这份手册仅适用于Cortex®-A715核心。请将此手册与Arm® DynamIQ™ Shared Unit-110技术参考手册一起阅读,以获取有关DSU-110的详细信息。
这份手册并未提供完整的寄存器列表。请将此手册与Arm® A-profile架构参考手册一起阅读,以获取更多信息。
2.1 Cortex®‑A715 core features
您可以在独立的DynamIQ™配置中使用Cortex®-A715核心,也就是在Cortex®-A715核心的同质集群中使用。您还可以将Cortex®-A715核心用作异构集群中平衡性能的核心。
然而,无论是哪种集群配置,Cortex®-A715核心具有以下描述中列出的相同功能。
核心特性:
• 实现了Armv9.0-A A64指令集
• 所有异常级别(EL0至EL3)处于AArch64执行状态
• 内存管理单元(MMU)
• 40位物理地址(PA)和48位虚拟地址(VA)
• 通用中断控制器(GIC)CPU接口,用于连接外部中断分发器
• 支持从外部系统计数器输入64位计数的通用定时器接口
• 实现了可靠性、可用性和可维护性(RAS)扩展
• 实现了具有128位向量长度的可伸缩矢量扩展(SVE)和可伸缩矢量扩展2(SVE2)
• 集成的执行单元,具有高级单指令多数据(SIMD)和浮点支持
• 支持可选的密码扩展功能
密码扩展功能需要单独许可。
• 活动监视单元(AMU)
Cache特性:
• 独立的L1数据缓存和指令缓存
• 私有的、统一的L2数据和指令缓存
• 可选的错误保护,支持奇偶校验或纠错码(ECC),允许在L1指令缓存、数据缓存、L2缓存和L2转换查找缓冲区(TLB)上进行单错误修正和双错误检测(SECDED)
• 支持内存系统资源分区和监控(MPAM)
调试特性:
• Armv9.0-A调试逻辑
• 性能监视单元(PMU)
• 嵌入式跟踪扩展(ETE)
• 跟踪缓冲扩展(TRBE)
• 可选实现统计分析扩展(SPE)
• 可选嵌入式逻辑分析器(ELA),ELA-600
ELA-600需要单独许可。
相关信息请参阅第31页的技术概述。
2.2 Cortex®‑A715 core confifiguration options
在构建时配置中,您可以选择满足实现需求的选项。
可配置性是基于每个核心的,也就是说,在一个集群中,不同的Cortex®-A715核心可以具有不同的配置选项。
您可以使用以下选项来配置您的Cortex®-A715核心实现:
缓存保护
您可以选择配置是否启用缓存保护。
统计分析扩展(SPE)
您可以选择配置是否启用统计分析扩展(SPE)。
PMU计数器
您可以选择配置PMU计数器的数量为6或20。
密码扩展功能
您可以选择配置是否启用密码扩展功能。密码扩展功能需要单独许可。
L1数据缓存大小
您可以选择配置L1数据缓存大小为32KB或64KB。
L1指令缓存大小
您可以选择配置L1指令缓存大小为32KB或64KB。
L2缓存大小
您可以选择配置L2缓存大小为128KB、256KB或512KB。
CoreSight™嵌入式逻辑分析器(ELA)
您可以选择包含支持集成ELA-600。ELA-600需要单独许可。
时序闭合
您可以配置L2数据缓存RAM的时序行为。
有关详细的配置选项和指南,请参阅Arm® Cortex®-A715 Core Configuration and Integration Manual中的RTL配置过程部分。
2.3 DSU-110 dependent features
某些DynamIQ™共享单元-110(DSU-110)特性和行为的支持取决于您所许可的核心是否支持特定功能。
以下表格描述了在您的Cortex®-A715核心中支持哪些基于DSU-110的特性。

Cryptographic Extension: 密码扩展功能
Maximum Power Mitigation Mechanism (MPMM): 最大功率缓解机制(MPMM)
Performance Defined Power (PDP) feature: 性能定义功率(PDP)功能
DISPBLKy signal supported: 支持DISPBLKy信号
Statistical Profiling Extension (SPE) architecture: 统计分析扩展(SPE)体系结构
2.4 Supported standards and specifications
Cortex®-A715核心采用Arm®v9.0-A架构。Arm®v9.0-A架构扩展了在Arm®v8-A架构中定义的架构,直到Arm®v8.5-A。Cortex®-A715核心还实现了特定的Arm®v8-A架构扩展,并支持互连、中断、计时器、调试和跟踪体系结构。
Cortex®-A715核心仅支持AArch64架构的所有异常级别,从EL0到EL3,并支持每个架构版本的所有强制性功能。
以下表格显示了Cortex®-A715核心支持的每个Arm®v8-A架构版本的可选功能。
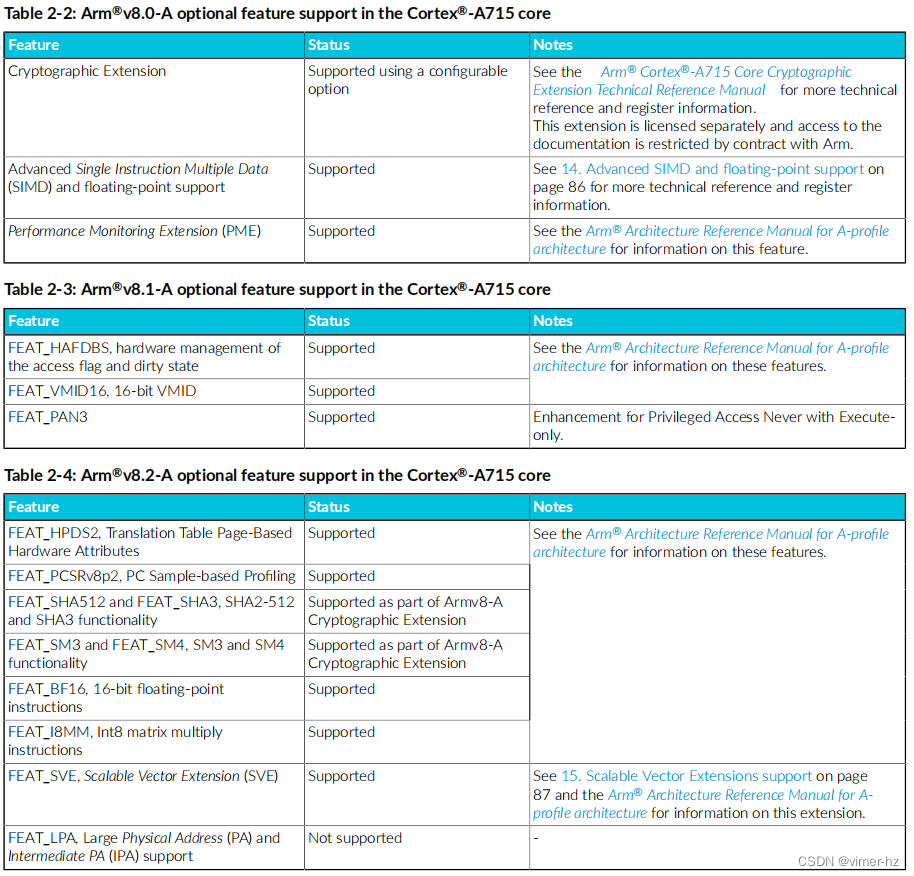
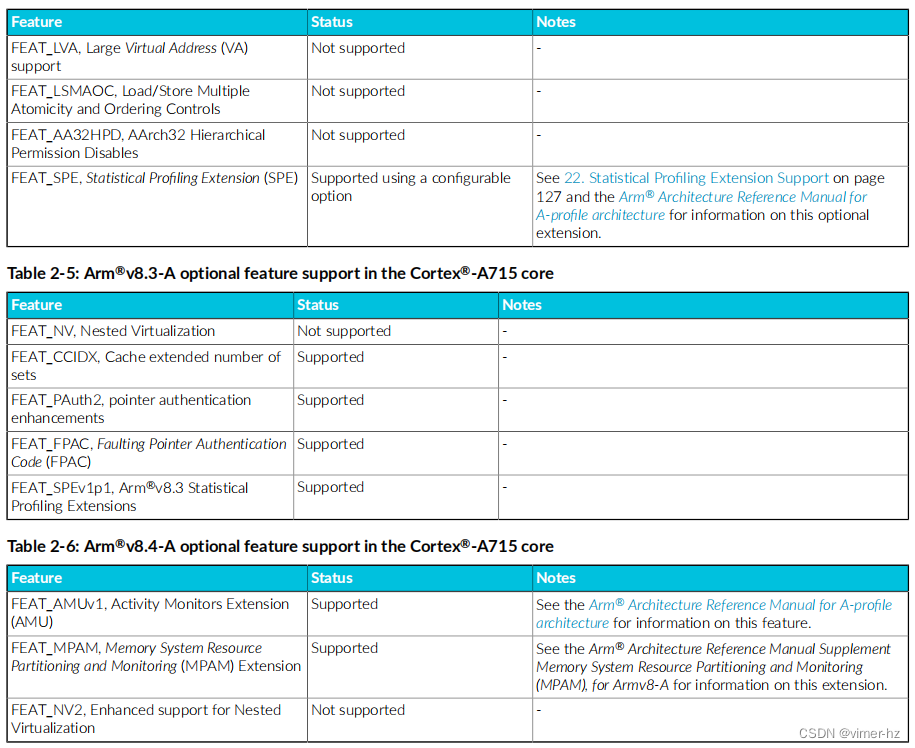
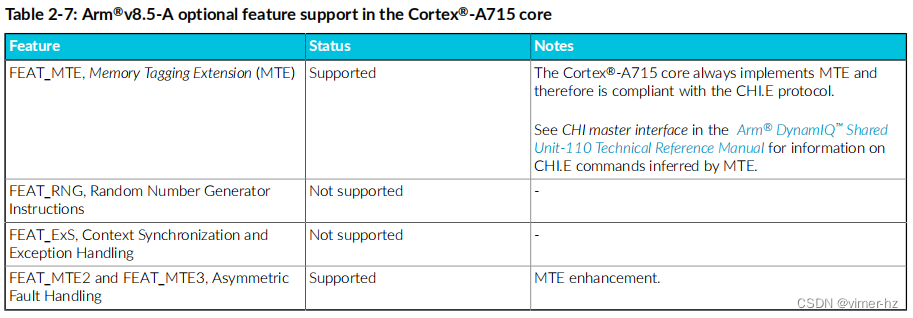

以下表格显示了Cortex®-A715核心支持的Arm®v9.0-A功能。
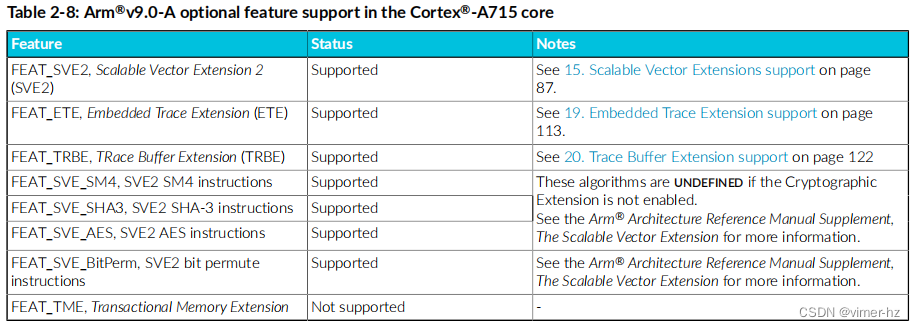
以下表格显示了Cortex®‑A715核心支持的其他标准和规范。
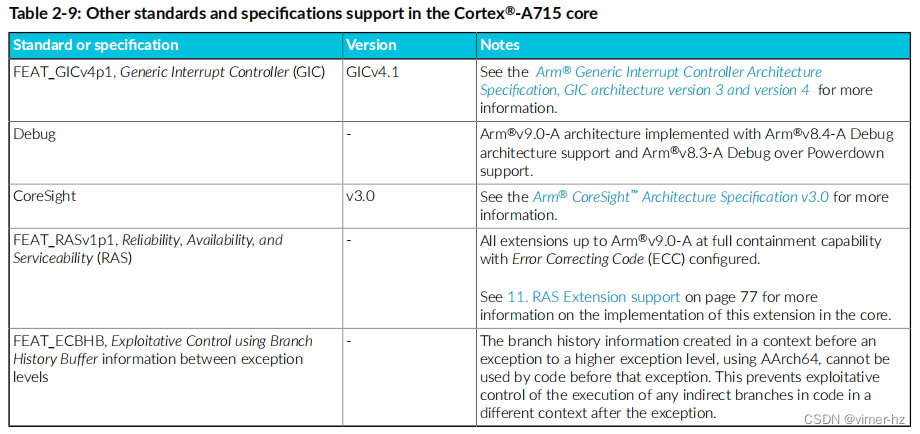
相关信息:第31页上的核心组件
2.6 Design tasks
Cortex®‑A715核心以SystemVerilog的可综合RTL描述形式提供。在使用Cortex®‑A715核心之前,您需要进行实现、集成和编程。
以下是不同参与方可能执行的各项任务:
实现
实现者配置RTL,添加供应商单元/RAM,并将设计通过综合和布局布线(P&R)步骤生成硬宏单元。
实现者选择影响如何呈现RTL源文件的选项。这些选项可能会影响最终宏单元的面积、最大频率、功耗和功能。
可以在实现流程中添加其他组件,例如DFT结构和必要时的电源开关。
集成
集成者将宏单元连接到SoC中。此任务包括将其连接到存储系统和外设。
集成者通过将输入引脚连接到特定值来配置核心的某些特性。这些配置设置会影响在进行任何软件配置之前的启动行为,并且还可以限制软件可用的选项。
软件编程
系统程序员开发软件来配置和初始化核心,并测试应用软件。
程序员通过向寄存器编程数值来配置核心。编程的数值会影响核心的行为。
最终设备的操作取决于构建配置、配置输入和软件配置。
请参阅Arm® Cortex®‑A715 Core Configuration and Integration Manual中的RTL配置过程,以及Arm® DynamIQ™ Shared Unit-110 Configuration and Integration Manual中关于实现选项的内容。此外,还请参阅Arm® DynamIQ™ Shared Unit-110 Configuration and Integration Manual中有关信号描述的内容。
3. Technical overview
Cortex®‑A715核心中的组件旨在使其成为一个平衡性能的核心。主要组件包括:
• L1指令和L1数据存储系统
• L2存储系统
• 寄存器重命名
• 指令解码
• 指令发射
• 执行流水线
• 存储管理单元(MMU)
• 追踪单元和追踪缓冲区
• 性能监控单元(PMU)
• 活动监控单元(AMU)
• 通用中断控制器(GIC)CPU接口
• 分支预测
Cortex®‑A715核心通过CPU桥与DynamIQ™ Shared Unit-110(DSU-110)进行接口连接。
Cortex®‑A715核心实现了Arm®v9.0-A架构。Arm®v9.0-A架构扩展了Arm®v8‑A架构中定义的架构,一直延伸到Arm®v8.5-A。
程序员模型和实现的体系结构特性(例如通用计时器)符合第25页上所述的2.4支持的标准和规范。
3.1 Core components
Cortex®‑A715核心包括一系列组件,旨在使其成为一个平衡性能、低功耗且面积受限的产品。Cortex®‑A715核心包括一个CPU桥,将核心连接到DynamIQ™ Shared Unit-110(DSU-110)。DSU-110将核心连接到外部存储系统和片上系统(SoC)的其他部分。
下图显示了Cortex®‑A715核心的组件。
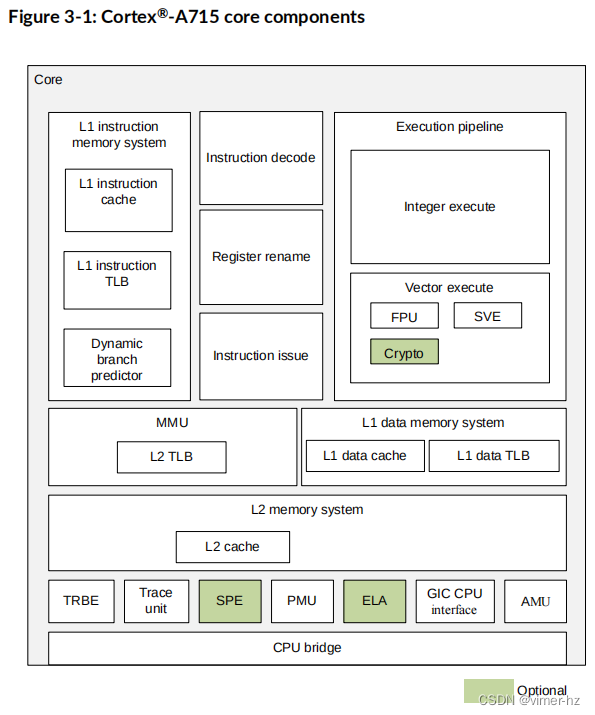
L1 instruction memory system
L1指令存储系统从指令缓存中获取指令,并将指令流传递给指令解码单元。
L1指令存储系统包括:
• 32KB或64KB的4路组相联式L1指令缓存,每个缓存行大小为64字节
• 完全关联的L1指令转换后置缓冲器(TLB),原生支持4KB、16KB、64KB和2MB页面大小
• 动态分支预测器
Instruction decode
指令解码单元将AArch64指令解码为一个内部格式,并将其传递到执行流水线中。解码单元负责解析指令的操作码、操作数和操作顺序,并将其转换为可被执行的内部表示形式,以供后续阶段执行。这样,处理器可以正确地理解和执行指令的操作。解码完成后,解码单元将解码后的指令传递给执行流水线的下一个阶段,从而启动指令的实际执行过程。
Register rename
寄存器重命名单元执行寄存器重命名,以便实现乱序执行,并将解码的指令发送到各种发布队列。
寄存器重命名是一种技术,通过为指令中的目标寄存器分配重命名寄存器,来解决由于指令间数据依赖关系而导致的数据冲突。这样,不同的指令可以并发地使用相同的物理寄存器,从而允许指令乱序执行,提高了处理器的性能。
寄存器重命名单元负责分配重命名寄存器,并将解码的指令发送到相应的发布队列。发布队列是用于保存将要执行的指令,并确保它们按照正确的顺序进入执行阶段。通过寄存器重命名和发布队列的组合使用,处理器能够更高效地利用指令级并行性,提升整体执行效率。
Instruction issue
指令分发单元控制解码后的指令何时被分派到执行流水线。它包括用于存储待分派到执行流水线的指令的发布队列。
Integer execute
执行流水线包括整数执行单元,用于执行算术和逻辑数据处理操作。
Vector execute
矢量执行单元是执行流水线的一部分,用于执行高级SIMD和浮点运算。矢量执行单元执行可扩展矢量扩展(SVE)和可扩展矢量扩展2(SVE2)指令,并可选择执行加密指令。
-高级SIMD和FP支持
高级SIMD是一种媒体和信号处理架构,主要添加了用于音频、视频、3D图形、图像和语音处理的指令。浮点数架构提供对单精度和双精度浮点操作的支持。
-加密扩展
加密扩展在Cortex®‑A715核心中是可选的。加密扩展向高级SIMD和可扩展矢量扩展(SVE)指令集添加了新指令,加速以下功能:
- 高级加密标准(AES)加密和解密。
- 安全哈希算法(SHA)函数SHA-1、SHA-3、SHA-224、SHA-256、SHA-384和SHA-512。
- Armv8.2-SM SM3哈希函数和SM4加密和解密指令。
- 有限域算术,用于诸如Galois/Counter Mode和椭圆曲线密码术等算法。
可选的加密扩展不包含在基本产品中。Arm仅在额外的Cortex®‑A715核心许可证下提供加密扩展。
-可扩展矢量扩展
可扩展矢量扩展(SVE)和可扩展矢量扩展2(SVE2)是Armv8-A架构的扩展。
它们是对AArch64高级SIMD和浮点功能的补充,而不是替代品。
L1 data memory system
L1数据内存系统执行加载和存储指令,并处理内存一致性请求。
L1数据内存系统包括:
- 32KB或64KB的4路组关联缓存,其中缓存行大小为64字节。
- 全关联的L1数据TLB,原生支持4KB、16KB、64KB和2MB的页面大小。
Memory Management Unit
内存管理单元(MMU)通过一组虚拟地址到物理地址映射和内存属性,在转换表中提供细粒度的内存系统控制。当地址被转换时,这些映射关系会保存在TLB中。TLB条目包括全局标识符(ASID)和地址空间标识符(ASID),以防止上下文切换导致的TLB无效。它们还包括虚拟机标识符(VMID),以防止虚拟机切换时由虚拟机监视程序导致的TLB无效。
L2 memory system
L2内存系统包括L2缓存。L2缓存是私有的,每个核心具有8路组关联性。您可以将其RAM大小配置为128KB、256KB或512KB。L2内存系统通过CPU桥连接到DSU-110。
Embedded Trace Extension and Trace Buffer Extension
Cortex®‑A715核心支持一系列的调试、测试和跟踪选项,包括跟踪单元和跟踪缓冲区。
Cortex®‑A715核心还包括一个ROM表,其中包含系统中的组件列表。调试器可以使用ROM表确定实现了哪些CoreSight™组件。
Cortex®‑A715核心的所有调试和跟踪组件都在本手册中进行了描述。有关嵌入式逻辑分析仪(ELA)的更多信息,请参阅Arm® CoreSight™ ELA-600嵌入式逻辑分析仪技术参考手册。
Statistical Profiling Extension
在Cortex®‑A715核心中,统计分析扩展(SPE)是可选的。Cortex®‑A715核心实现了Arm®v8.2-A架构中的SPE。SPE提供了执行指令的性能特性的统计视图,软件开发者可以利用这些统计数据来优化代码,以实现更好的性能。
Performance Monitoring Unit
性能监控单元(PMU)提供了6个或20个性能监视器,可以配置为收集每个核心和内存系统的操作统计数据。这些信息可用于调试和代码性能分析。
Activity Monitoring Unit
Cortex®‑A715核心实现了Arm®v8.4-A架构中的活动监视器扩展。活动监视器在活动监视单元(AMU)中提供有用的信息,用于系统功耗管理和持续监控。
GIC CPU interface
通用中断控制器(GIC)CPU接口,与外部分发器组件集成时,是支持和管理集群系统中断的资源。
CPU bridge
在一个集群中,每个Cortex®‑A715核心和DSU-110之间有一个CPU桥。CPU桥控制核心和DSU-110之间的缓冲和同步。CPU桥是异步的,允许每个核心具有不同的频率、功耗和面积实现点。您可以配置CPU桥以同步运行,而不影响其他始终同步的接口,如调试和跟踪。
相关信息:
6. 内存管理(第51页)
7. L1指令内存系统(第60页)
8. L1数据内存系统(第63页)
9. L2内存系统(第68页)
13. GIC CPU接口(第84页)
18. 性能监控扩展支持(第98页)
19. 嵌入式跟踪扩展支持(第113页)
20. 跟踪缓冲区扩展支持(第122页)
21. 活动监视器扩展支持(第123页)
22. 统计分析扩展支持(第127页)
3.2 Interfaces
DynamIQ™ Shared Unit-110 (DSU-110)是用于管理所有Cortex®‑A715核心与片上系统(SoC)之间的外部接口的模块。
您可以参考Arm® DynamIQ™ Shared Unit-110技术参考手册中的技术概述,以获取有关这些接口的详细信息。
3.3 Programmers model
Cortex®‑A715核心实现了Arm®v9.0-A架构。Arm®v9.0-A架构扩展了Arm®v8‑A架构,一直延伸到Arm®v8.5-A。Cortex®‑A715核心在所有异常级别(EL0到EL3)都支持AArch64执行状态。
您可以参考Arm® Architecture Reference Manual for A-profile architecture,以获取有关程序员模型的更多信息。
相关信息:
2.4 支持的标准和规范(第25页)
4. Clocks and resets
为了实现动态的功耗节省,Cortex®‑A715核心支持分层时钟门控(hierarchical clock gating)。它还支持热重启(Warm Reset)和冷重启(Cold Reset)。
每个Cortex®‑A715核心只有一个时钟域,并接收一个时钟输入信号。这个时钟输入信号由CPU桥中的一个架构级时钟门控进行控制。
此外,Cortex®‑A715核心实施了广泛的时钟门控,包括:
• 针对各种模块的区域时钟门控,可以关闭部分时钟树
• 可以关闭单独寄存器或寄存器组的本地时钟门控
Cortex®‑A715核心从DynamIQ™ Shared Unit-110(DSU-110)侧的CPU桥接收以下复位信号:
• 热重启,用于对核心中除了以下部分之外的所有寄存器进行复位:
◦ 调试逻辑的一些部分
◦ 跟踪单元逻辑的一些部分
◦ 可靠性、可用性和服务性(RAS)逻辑
• 冷重启,用于对核心中的逻辑进行复位,包括调试逻辑、跟踪逻辑和RAS逻辑。
有关核心时钟门控和复位方案的完整描述,请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的以下章节:
• 时钟和复位
• 使用功耗策略单元进行电源和复位控制
5. Power management
Cortex®‑A715核心提供了控制动态功耗和静态功耗散发的机制。
动态功耗管理包括以下特性:
• 分层时钟门控
• 每个核心的动态电压频率调节(DVFS)
静态功耗管理包括以下特性:
• 关机(Powerdown)
• 动态保留(Dynamic retention),这是一种低功耗模式,保留寄存器和RAM状态
5.1 Voltage and power domains
DynamIQ™ Shared Unit-110(DSU-110)的功耗策略单元(PPU)用于控制Cortex®‑A715核心的功耗管理。该核心支持一个功耗域 PDCORE 和一个系统功耗域 PDCLUSTER。同样,它支持一个核心电压域 VCORE 和一个集群系统电压域 VCLUSTER。功耗域和电压域具有相同的边界。
PDCORE 功耗域包含了所有的Cortex®‑A715核心逻辑以及属于 VCORE 域的部分核心异步桥接逻辑。PDCLUSTER 功耗域包含了属于 VCLUSTER 域的CPU桥接的部分逻辑。
下图显示了Cortex®‑A715核心的功耗域和电压域。它还显示了覆盖CPU桥接系统侧的集群功耗域和电压域。

如果满足以下条件之一,您可以将VCORE和VCLUSTER电压域连接到相同的电源上:
• 核心配置为与DSU-110同步运行,共享相同的时钟。
• 核心不需要支持动态电压频率调节(DVFS)。
在具有多个Cortex®‑A715核心的集群中,每个核心都有一个 PDCORE<n>功耗域,其中n是核心的实例编号。如果不存在某个核心,则相应的功耗域也不存在。
下图显示了一个示例Cortex®‑A715配置的功耗域,其中包含一个四核心集群:

夹持(clamping)单元位于功耗域之间,通过功耗意图文件(UPF)进行推断,而不是在RTL中实例化。有关更多信息,请参阅Arm® Cortex®‑A715核心配置和集成手册中的功耗管理部分。
Arm® Cortex®‑A715核心配置和集成手册是一份机密文档,只有在获得相应产品许可证的情况下才可以获得。
关于DSU-110集群功耗域和电压域的详细信息,请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的功耗管理部分。
5.2 Architectural clock gating modes //架构级的时钟门控模式
WFI(Wait For Interrupt)和WFE(Wait For Event)指令将核心置于低功耗模式。这些指令会禁用时钟树顶部的时钟信号。核心保持完全供电并保留其状态。
5.2.1 Wait for Interrupt and Wait for Event
等待中断(WFI)和等待事件(WFE)是一种功能,通过禁用大部分核心时钟将核心置于低功耗状态,同时保持核心供电。当核心处于WFI或WFE状态时,输入时钟会在CPU桥接处对核心进行外部门控。
在WFI或WFE低功耗状态下唤醒核心所需的逻辑会消耗少量的动态功耗。除此之外,绘制的功耗仅限于静态漏电流。
当核心执行WFI或WFE指令时,它会等待核心中的所有指令(包括显式的内存访问指令)执行完毕,然后进入低功耗状态。WFI和WFE指令还确保存储指令已更新缓存或已提交给L3内存系统。
当事件寄存器被设置时执行WFE指令不会导致进入低功耗状态,但会清除事件寄存器。
核心在以下事件发生时退出WFI或WFE状态:
- 核心检测到复位信号。
- 核心检测到架构定义的WFI或WFE唤醒事件。
WFI和WFE唤醒事件可以包括物理中断和虚拟中断。
有关进入低功耗状态和唤醒事件的更多信息,请参阅Arm®架构参考手册A型架构部分。
5.2.2 Low-power state behavior considerations
要考虑到某些事件如何影响Cortex®‑A715核心的等待中断(WFI)和等待事件(WFE)低功耗状态行为。
在核心处于WFI或WFE状态时,当检测到以下任一事件时,核心内部的时钟会临时启用:
- 必须由核心L1数据缓存或L2缓存处理的系统嗅探请求
- 必须由核心L1指令缓存、L1数据缓存、L2缓存或TLB处理的缓存或转换查找缓冲器(TLB)维护操作
- 在效用总线接口上的访问
- 通过高级外设总线(APB)接口进行的通用中断控制器(GIC)CPU访问或调试访问
当时钟被临时启用时,核心不会退出WFI或WFE状态。
有关WFI和WFE的更多信息,请参阅Arm®架构参考手册A型架构部分。
5.3 Power control
DynamIQ™ Shared Unit-110(DSU-110)的功耗策略单元(PPU)控制着所有核心和集群的功耗模式转换。
每个核心都有自己的PPU来控制其自身的核心功耗域。此外,还有一个用于控制整个集群的PPU。
PPU决定并请求任何功耗模式的变更。然后,Cortex®‑A715核心执行达到请求的功耗模式所需的任何操作。例如,在接受请求之前,核心可能会关闭时钟、清除缓存或禁用一致性。
有关集群和核心的PPU的更多信息,请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的以下章节:
- 功耗管理
- 使用功耗策略单元进行功耗和复位控制
5.4 Core power modes
Cortex®‑A715核心的功耗域具有一组定义好的功耗模式,以及这些模式之间的合法转换。每个核心的功耗模式可以独立于集群中的其他核心。
核心的功耗策略单元(PPU)在集群级别管理该核心的功耗模式之间的转换。有关更多信息,请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的功耗管理部分。
以下表格显示了支持的Cortex®‑A715核心功耗模式。
未在下表中显示的功耗模式不受支持,不能出现。违反合法的功耗模式可能会导致不可预测的结果。您必须遵守第48页上描述的动态功耗管理、上电和下电序列。


以下图示显示了Cortex®‑A715核心功耗域支持的模式以及它们之间的合法转换。

相关信息:
5.2 第40页上的架构时钟门控模式
5.4.4 第44页上的全保持模式
5.2.1 第40页上的等待中断和等待事件模式
5.4.1 On mode
在On模式下,Cortex®‑A715核心处于开启状态并完全可操作。
可以将核心初始化为On模式。完成向On模式的转换后,所有缓存都是可访问和一致的。除了启用缓存的正常架构步骤外,不需要额外的软件配置。
5.4.2 Off mode
在关机模式下,核心完全断电,不保留任何状态。
在关机模式下,所有核心逻辑和RAM都处于关闭状态。该域无法使用,所有核心状态都会丢失。L1和L2缓存会被禁用、清除和失效,并且在进入关机模式时,核心会自动退出一致性。
在此模式下,冷重启可以重置核心。
当核心域关闭时,尝试对核心调试寄存器进行外部调试访问或者对实用总线进行访问会在内部调试接口返回错误响应。该错误表示核心不可用。
当核心处于关机模式时,可以访问DebugBlock中与External Debug Over PowerDown (EDOPD)功能相关的特定于核心的调试寄存器。
5.4.3 Emulated off mode
在模拟关机模式下,所有核心域逻辑和RAM都保持开启状态。所有调试寄存器必须保留其状态,并可以通过外部调试接口进行访问。所有其他功能接口的行为与核心处于关机模式时相同。
5.4.4 Full retention mode //全保持模式
全保持模式是一种通过功耗策略单元(PPU)进行控制的动态保持模式。在唤醒时,可以恢复核心的全部功率,并继续执行。
在全保持模式下,仅提供保持寄存器和RAM状态所需的功率。核心处于保持状态,无法操作。
当满足以下所有条件时,核心进入全保持模式:
• 保持定时器已到期。有关设置保持定时器的更多信息,请参见A.1.17 IMP_CPUPWRCTLR_EL1,CPU电源控制寄存器。
• 核心处于等待中断(WFI)或等待事件(WFE)的低功耗状态。
• 核心时钟没有因以下任何原因而被临时启用:
◦ L1或L2快速缓存的snoop操作
◦ 缓存或转换查找缓冲器(TLB)的维护操作
◦ 调试或通用中断控制器(GIC)访问
核心在检测到以下任何事件时退出全保持模式:
• WFI或WFE的唤醒事件,根据Arm®架构参考手册(A-profile architecture)的定义。
• 需要临时启用核心时钟的事件,而不会退出WFI或WFE低功耗状态。例如:
◦ L1或L2快速缓存的snoop操作
◦ 缓存或TLB的维护操作
◦ 来自DynamIQ™ Shared Unit-110(DSU)的DebugBlock的调试访问
◦ GIC访问
5.4.5 Debug recovery mode //调试恢复模式
调试恢复模式支持对外部看门狗触发的复位事件(例如看门狗超时)进行调试。
默认情况下,当核心从关机模式切换到开机模式时,会使其缓存失效。使用调试恢复模式可以在复位后观察到复位前存在的L1缓存和L2缓存内容。缓存的内容会被保留,在切换回开机模式时不会被修改。
除了保留缓存内容,调试恢复还支持保留可靠性、可用性和可维护性(RAS)状态。在调试恢复模式下,必须从外部应用 DSU-110 DynamIQ™ 集群范围的 Warm 复位。当将核心切换到开机模式时,RAS和缓存状态会被保留。
调试恢复仅用于调试目的。不得将其用于功能目的,因为在进入此模式时无法保证缓存的正确操作。
调试恢复模式可以在任何时候发生,而核心的状态没有保证。此类请求会立即被接受,因此对核心、DynamIQ™集群或更广泛的系统的影响是不可预测的,并且可能需要进行更广泛的系统复位。特别地,在复位时,可能会完成复位时的任何未完成的内存系统事务。
核心不期望在复位后完成这些事务,可能会导致系统死锁。
如果系统在调试恢复模式下向DynamIQ™集群发送散列请求,则取决于集群状态:
• 散列请求可能会获得响应并干扰缓存的内容。
• 散列请求可能无法获得响应并导致系统死锁。
5.4.6 Warm reset mode //热复位模式
热复位(Warm reset)会重置除追踪逻辑、调试寄存器和可靠性、可用性和可维护性(RAS)寄存器之外的所有状态。
当Cortex®‑A715核心从CPU桥的DynamIQ™共享单元-110(DSU-110)一侧接收到热复位信号时,将会应用热复位来重置该核心的状态。
Cortex®‑A715核心实现了Arm®v8‑A Reset Management Register,即RMR_EL3。当核心在EL3模式下运行时,如果将RMR_EL3.RR位设置为1,则会请求进行热复位。
有关RMR_EL3的更多信息,请参阅Arm® A-profile体系结构参考手册。
5.5 Performance and power management
Cortex®‑A715核心实现了性能和功耗管理(PPM)功能,可用于限制核心内部的高活动事件或在效率和峰值性能之间进行权衡。
PPM功能包括:
• 最大功耗缓解机制(MPMM)
• 性能优化功耗(PDP)
5.5.1 Maximum Power Mitigation Mechanism //最大功耗缓解机制
最大功率缓解机制(MPMM)是一种功耗管理功能,用于检测和限制高活动事件,特别是高功率的加载-存储事件和向量单元指令。在评估期间,如果高活动事件的计数超过预定义的阈值,MPMM会临时限制指令执行速率和内存系统事务。MPMM提供了三个档位,使其能够限制特定类别的工作负载。每个MPMM档位以不同的适应性水平来限制工作负载,其中档位0产生最激进的节流效果,而档位2最不激进。活动监控单元(AMU)为每个档位提供度量数据。外部功耗控制器可以利用这些度量数据来进行SoC功耗的预算管理,方式包括:
• 限制能够执行高活动负载的核心数量
• 切换到不同的动态电压和频率调整(DVFS)工作点
MPMM并不旨在限制接近典型功率水平的工作负载。MPMM的事件检测和限制目标是限制那些比典型整数工作负载具有显著更高功耗的工作负载。
MPMM不能作为唯一的电气安全机制。它本质上是一种在核心级别操作的局部辅助机制。MPMM并不替代粗粒度紧急功耗降低方案,但它确实最大程度减少了出现这类方案的可能性。它是第一道防线而不是完整的解决方案。
相关信息:
A.2.1 IMP_CPUPPMCR_EL3,在第253页的全局PPM配置寄存器
A.4.27 IMP_CPUMPMMCR_EL3,在第320页的全局MPMM配置寄存器
B.1.1 CPUPPMCR,在第468页的全局PPM配置寄存器
B.1.2 CPUMPMMCR,在第470页的全局MPMM配置寄存器
5.5.2 Performance Defined Power //性能优化功耗
性能优化功耗(PDP)是一种功耗管理功能,通过在常规工作负载上降低功耗范围来换取峰值性能。
PDP的配置可在三个可能值中选择不同的适应性水平。当适应性水平增加时,平均工作负载功耗减少,但会导致不同工作负载的性能损失增加。
//性能损失->功耗减少
PDP对以下方面产生影响:
• 核心功耗降低。核心功耗减少,效率提高。
• 外部内存系统功耗降低。调节内存请求带宽以降低内存系统的功耗。
5.5.3 Dispatch block //调度阻塞
在极端核心温度或功耗条件下,您可以临时停止处理器的前进进程,而不停止时钟。
DSU-110边界上提供了一个引脚,可以直接用于强制处理器停顿,持续时间为引脚被激活的期间。当处理器停顿时,新指令的调度将停止。然而,已经调度的指令将继续按照正常方式执行和完成。
5.6 Cortex®‑A715 core powerup and powerdown sequence
对于 Cortex®-A715 核心,没有特定的顺序来启动。要关闭核心,您必须按照特定的顺序进行操作。在复位后,不需要进行软件步骤来确保核心在一致性上。
以下是关闭 Cortex®-A715 核心的步骤:
1. 如果需要,将核心状态保存到系统内存中,以便在核心上电时可以恢复核心状态。
2. 禁用核心的中断:
a. 在 ICC_IGRPEN0_EL1 和 ICC_IGRPEN1_EL1 寄存器中禁用中断使能位。
b. 使用 GICR_WAKER 寄存器设置 GIC 分发器的唤醒请求。
c. 读取 GICR_WAKER 寄存器,确认 ChildrenAsleep 位指示接口处于静止状态。
3. 禁用 RAS 寄存器的中断输出,或者将核心的 RAS 故障和错误中断输出重定向到系统错误管理器。有关更多信息,请参阅第49页的“在核心关机期间管理 RAS 故障和错误中断”的5.6.1节。
4. 将 IMP_CPUPWRCTLR_EL1.CORE_PWRDN_EN 位设置为1,表示请求关机。
5. 执行 ISB 指令。
6. 执行 WFI 指令。一旦执行了 WFI 指令,关机序列就不可中断。
在执行 WFI 指令后,如果从电源控制器收到关机请求,硬件将执行以下操作:
- 禁用和清理核心缓存
- 从系统一致性中移除核心
当设置了 IMP_CPUPWRCTLR_EL1.CORE_PWRDN_EN 位时,执行 WFI 指令会自动屏蔽核心中的所有中断和唤醒事件。因此,应用复位是唯一唤醒核心从等待中断(WFI)状态的方法。
5.6.1 Managing RAS fault and error interrupts during the core powerdown
//在核心关机期间管理 RAS(Reliability, Availability, and Serviceability)故障和错误中断。
在执行 WFI 指令后,电源管理架构不允许中断核心软件的执行。
因此,在以下情况下,无法通过中断来管理任何 RAS 故障或错误:
- 在核心关机程序执行 WFI 指令之前检测到 RAS 故障或错误,并且错误尚未清除。
- 在核心关机程序执行 WFI 指令后检测到 RAS 故障或错误。
您必须管理 RAS 故障和错误中断的状态,以完成核心关机序列。如果核心中存在活动的 RAS 故障或错误中断,则阻止核心关机,因此:
- 核心保持通电状态,但软件处于非活动状态。
- 核心处理器功率管理单元(PPU)发出的所有关机请求将被拒绝。
- 重新启动核心软件的唯一机制是进行完整的集群复位。
如果在核心关机过程之前禁用了 RAS 故障和错误中断输出,并且启用了错误检测和纠正响应,那么以下情况成立:
- 可纠正的错误将会被纠正。
- 可延迟处理的错误将会作为自动缓存清理和失效过程的一部分进行延迟处理。
- 当核心关闭电源时,可纠正和可延迟处理的错误记录将会丢失。
- 如果在核心关闭电源时存在不可纠正的错误,则不会向系统发出错误信号,并且可能会破坏系统行为。
如果方便的话,您可以禁用对可纠正和可延迟处理错误的 RAS 故障和错误中断生成,同时启用对不可纠正错误的中断。然而,在执行核心关机程序中的 WFI 指令之前,必须重新路由核心的错误中断输出到系统错误管理器。为此,可以按照以下方式配置 ERxCTLR_EL1 寄存器:
- ERxCTLR_EL1.CFI = 0
- ERxCTLR_EL1.FI = 0
- ERxCTLR_EL1.UI = 1
如果在关机过程中发生不可纠正的错误,核心将保持通电状态,软件将处于非活动状态。此时,系统错误管理器负责重置整个集群以及与核心和集群交互的更广泛系统。要使用这种方法,系统必须设计成允许核心的 RAS 错误中断重新路由到系统错误管理器。由于核心的 RAS 寄存器仅对在核心上运行的软件可访问,系统错误管理器无法确定不可纠正的错误发生在核心的哪个位置。
5.7 Debug over powerdown
Cortex®-A715核心支持调试关机功能,允许调试器在核心关机时保持与核心的连接。这种行为使得调试可以在关机情况下继续进行,而不需要每次重新建立连接。
调试关机逻辑是DynamIQ™ Shared Unit-110(DSU-110)中的DebugBlock的一部分。DebugBlock位于DSU-110 DynamIQ™集群之外,并且在调试关机过程中必须保持通电状态。
详细信息请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的调试章节。
6. Memory management
内存管理单元(MMU)将输入地址转换为输出地址。这种转换基于在Cortex®-A715核心内部寄存器和转换表中可用的地址映射和内存属性信息。MMU还控制每个内存区域的内存访问权限、内存属性和缓存策略。
从输入地址到输出地址的地址转换被描述为地址转换的一个阶段。Cortex®-A715核心可以执行以下操作:
- 第1阶段转换,将输入虚拟地址(VA)转换为输出物理地址(PA)或中间物理地址(IPA)。
- 第2阶段转换,将输入IPA转换为输出PA。
- 组合的第1阶段和第2阶段转换,将输入VA转换为IPA,然后将该IPA转换为输出PA。Cortex®-A715核心对每个转换阶段执行转换表遍历。
除了将输入地址转换为输出地址,地址转换的一个阶段还定义了输出地址的内存属性。对于两个阶段的转换,第2阶段的转换可以修改第1阶段转换定义的属性。地址转换的一阶段可以被禁用或绕过,并且核心可以为禁用和绕过的转换阶段定义内存属性。
每个地址转换阶段使用存储在内存映射转换表中的地址转换和相关内存属性。转换表项可以缓存在TLB(Translation Lookaside Buffer)中。转换表项使得MMU能够提供细粒度的内存系统控制,并控制表遍历硬件。
有关虚拟内存系统体系结构(VMSA)的更多信息,请参阅Arm® Architecture Reference Manual for A-profile architecture。
6.1 Memory Management Unit components
Cortex®‑A715核心的内存管理单元(MMU)包括多个Translation Lookaside Buffers (TLBs)、一个L2 TLB和一个转换表预取器。 TLB是MMU内部存储最近执行的页转换的缓存。Cortex®‑A715核心采用了两级TLB结构。L2 TLB存储所有页面大小,并在L1数据TLB或L1指令TLB需要时将这些页面分割成较小的页面。 下表描述了MMU的组件。

TLB条目包含以下内容:
• 全局指示器和地址空间标识符(ASID),允许在上下文切换时无需使TLB失效
• 虚拟机标识符(VMID),允许虚拟化管理程序(hypervisor)进行虚拟机切换,而无需使TLB失效
L1指令TLB的命中可以在一个时钟周期内访问转换,并将物理地址(PA)返回给指令缓存进行比较。它还检查访问权限,以发出指令异常信号。
L1数据TLB的命中可以在一个时钟周期内访问转换,并将物理地址(PA)返回给数据缓存进行比较。它也检查访问权限,以发出数据异常信号。
在L1数据TLB中未命中但在L2 TLB中命中的情况下,与L1数据TLB中的命中相比,会有5个时钟周期的延迟。根据待处理请求的仲裁,这个延迟可能会增加。
6.2 TLB entry content //TLB条目的内容
转换查找缓冲区(TLB)条目存储所需的上下文信息,以便进行匹配并避免在上下文或虚拟机切换时需要进行TLB清理。
每个TLB条目包含以下内容:
• 虚拟地址(VA)
• 物理地址(PA)
• 一组内存属性,包括类型和访问权限
每个TLB条目与以下之一相关联:
• 特定的地址空间标识符(ASID)
• 全局指示器
每个TLB条目还包含一个字段,用于存储适用于从EL0和EL1进行访问的虚拟机标识符(VMID)。VMID允许hypervisor进行虚拟机切换,而无需使TLB失效。
相关信息
第54页的6.4节“转换表遍历”
6.3 TLB match process //TLB匹配过程
Armv8-A架构支持多个以不同方式进行转换的虚拟地址(VA)空间。
每个转译查找缓冲区(TLB)条目与特定的转换方案相关联:
• 安全EL3
• 安全EL2
• 安全EL2和EL0
• 非安全EL2
• 非安全EL2和EL0
• 安全EL1和EL0
• 非安全EL1和EL0
当满足以下条件时,将发生TLB匹配条目:
• 其VA[48:N],其中N是存储在TLB条目中的该转换的块大小的log2,与请求的地址匹配。
• 条目的转换方案与当前的转换方案匹配。
• 地址空间标识符(ASID)与与目标转换方案相关联的TTBR0_ELx或TTBR1_ELx寄存器中保存的当前ASID匹配,或者该条目被标记为全局。
• 虚拟机标识符(VMID)与VTTBR_EL2寄存器中保存的当前VMID匹配。
ASID信息用于以下条目的TLB匹配:
• 使用安全EL1&0和非安全EL1&0的转换方案
• 使用安全EL2&0和非安全EL2&0的转换方案
VMID信息用于以下条目的TLB匹配:
• 当启用EL2时,使用安全EL1&0和非安全EL1&0的转换方案。
6.4 Translation table walks //转换表遍历
当Cortex®-A715核心生成内存访问时,内存管理单元(MMU)会在转译查找缓冲区(TLB)中搜索所请求的虚拟地址(VA)。如果不存在,则会发生缺失,此时MMU会继续在转译表遍历过程中查找。
当Cortex®-A715核心生成内存访问时,MMU会执行以下操作:
1. 在相关的指令或数据L1 TLB中对请求的VA、当前地址空间标识符(ASID)、当前虚拟机标识符(VMID)和当前转换方案进行查找。
2. 如果相关的L1 TLB中没有命中,那么MMU会在L2 TLB中对请求的VA、当前ASID、当前VMID和转换方案进行查找。
3. 如果L2 TLB中也没有命中,那么MMU会进行硬件转换表遍历。
只有在启用MMU时才执行地址转换。可以针对特定的转换基址寄存器禁用MMU,这种情况下MMU会返回一个转换错误。
您可以编程设置MMU使转换表遍历生成的访问可缓存。这意味着转换表条目可以缓存在L2缓存、L3缓存和外部缓存中。
在查找或转换表行走过程中,匹配的转换表条目中的访问权限位确定访问是否被允许。如果权限检查违反了规定,那么MMU会返回一个权限错误。有关更多信息,请参阅Arm®架构参考手册Armv8-A架构配置文件。
下图显示了TLB查找过程。

在转换表遍历过程中,描述符从L2缓存或外部存储系统中获取。
6.5 Hardware management of the Access flag and dirty state //访问标志(Access Flag)和脏位(Dirty State)的硬件管理
该核心包括执行对转换表进行硬件更新的选项。
这个功能在TCR_ELx(其中x为1-3)和VTCR_EL2中启用。为了支持脏位的硬件管理,转换表描述符中包含了Dirty Bit Modifier (DBM)字段。
Cortex®-A715核心仅在转换表存储在Inner Write-Back和Outer Write-Back Normal内存区域时支持对访问标志和脏位的硬件更新。
如果软件在非Inner Write-Back或Outer Write-Back Normal内存区域请求进行硬件更新,则Cortex®-A715核心返回以下编码的中止信息:
• 对于数据中止,ESR_ELx.DFSC = 0b110001
• 对于指令中止,ESR_ELx.IFSC = 0b110001
6.6 Responses
在某些故障和中止情况下,由于内存访问,可能会触发异常。
MMU响应
当完成以下操作之一时,内存管理单元(MMU)会向请求方生成一个转换响应:
• L1指令或数据转译查找缓冲器(TLB)命中
• L2 TLB命中
• 转换表遍历
从MMU返回的响应包含以下信息:
• 对应于转换的物理地址(PA)
• 一组权限
• 安全状态或非安全状态信息
• 报告中止所需的所有信息
MMU中止
MMU可以检测与地址转换相关的故障,并可能导致异常传递到核心。这些故障可能包括地址大小故障、翻译故障、访问标志故障和权限故障。
外部中止
外部中止发生在内存系统中,与MMU检测到的中止不同。
通常情况下,外部内存中止很少发生。外部中止由外部内存接口标记的错误或L1数据缓存或L2缓存数组中未纠正的纠错码(ECC)错误引起。
当发生以下情况时,同步地报告外部中止:
• 用于指令获取、加载和存储的转换表行走
• 将操作加载到内部写回、外部写回正常可缓存内存
在Fault Address Register(FAR)中捕获的地址是生成同步外部中止的指令的目标地址。
异步地报告外部中止发生在以下情况下:
• 在不是由转换表行走引起的情况下,将加载操作应用于除内部写回、外部写回正常内存之外的所有内存位置
• 对任何内存类型进行存储操作
• 缓存维护、TLB使失效和指令缓存使失效操作
• 包括AtomicLd、AtomicSt、AtomicCAS和AtomicSwap在内的原子操作
错误编程的连续提示
在出现错误编程的连续提示情况下,当存在一个包含置位CH位的描述符时,输入的虚拟地址(VA)地址空间必须包括此块中的所有连续VA。
VA地址空间由以下因素定义:
• 阶段1翻译:TCR_ELx.TxSZ
• 阶段2翻译:VTCR_EL2.T0SX
Cortex®‑A715核心将此类块视为不会引起翻译错误,并忽略连续位的值。
冲突中止
Cortex®‑A715核心不会生成冲突中止异常。
当在L1 TLB或L2 TLB中检测到TLB冲突时,硬件会自动处理冲突,通过使冲突条目无效来解决冲突。
6.7 Memory behavior and supported memory types
Cortex®‑A715核心支持Armv8-A架构中定义的内存类型。 设备内存类型具有以下属性:
G – Gathering(聚合)
将多个请求聚合并合并为单个事务的能力
R – Reordering(重排序)
对事务进行重排序的能力
E – Early Write Acknowledgement(提前写入确认)
接受来自互联的写入事务的提前确认的能力
在下表中,前缀n表示不允许该能力。
以下表格显示了Cortex®‑A715核心中支持的内存类型。


下表显示了对于特定的Normal内存,如何处理共享性(shareability)。

6.8 Page-based hardware attributes
Page-Based Hardware Attributes (PBHA)是一个可选的、实现定义的特性。它允许软件在转换表中设置最多四个位,然后通过内存系统传播这些位,并可用于控制系统组件。这些位的含义特定于系统设计。
要了解如何在转换表中设置和启用PBHA位,请参阅Arm® A型架构参考手册。当禁用时,总线上传播的PBHA值为0。
对于由转换表遍历引起的内存访问,ATCR和AVTCR寄存器控制PBHA值。
在内存访问中,stage 1和stage 2之间的PBHA组合
PBHA应始终被视为物理地址的属性。
当同时启用stage 1和stage 2时:
- 如果stage 1 PBHA和stage 2 PBHA都启用,则最终的PBHA是stage 2 PBHA。
- 如果stage 1 PBHA启用且stage 2 PBHA禁用,则最终的PBHA是stage 1 PBHA。
- 如果stage 1 PBHA禁用且stage 2 PBHA启用,则最终的PBHA是stage 2 PBHA。
- 如果stage 1 PBHA和stage 2 PBHA都禁用,则最终的PBHA被定义为0。
启用PBHA的粒度是一位,因此该属性独立地应用于每个PBHA位。
不匹配的别名
如果通过多个虚拟地址映射访问相同的物理地址,并且这些映射中的PBHA位不同,则结果是不可预测的。总线上传播的PBHA值可以是任一映射的值。
7. L1 instruction memory system
The Cortex®-A715核心的L1指令存储器系统用于获取指令并预测分支。它包括L1指令缓存、L1指令转换查找缓冲器(TLB)和分支预测单元。
L1指令存储器系统为解码器提供指令流。为了提高整体性能并降低功耗,L1指令存储器系统使用动态分支预测和指令缓存。
以下表格显示了L1指令存储器系统的特性:
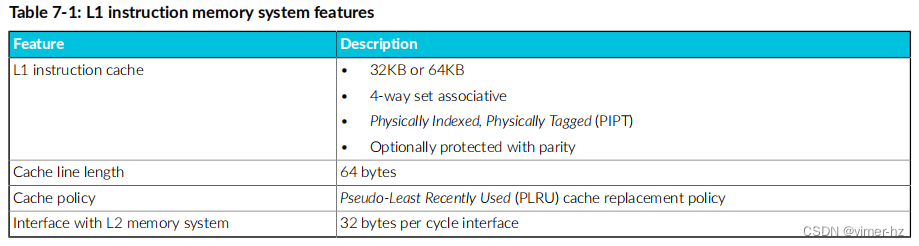
L1指令TLB也位于L1指令存储器系统中。然而,它是内存管理单元(MMU)的一部分,并在第51页的“内存管理”部分进行了描述。
7.1 L1 instruction cache behavior
L1指令缓存在复位时会自动失效,除非将核心功耗模式初始化为“调试恢复”模式。
在调试恢复模式下,L1指令缓存无法正常工作。
禁用L1指令缓存
不会对L1指令缓存的操作产生影响。即使在禁用状态下,指令仍然可以被缓存到L1指令缓存中,并从中获取。软件必须考虑到非缓存访问,以确保正确的行为。更多详情请参阅Arm® A-profile架构参考手册。
如果禁用了L1指令缓存,则由于指令获取引起的所有内存访问都将使用非缓存内存属性进行。这意味着指令获取可能与同一核心或其他核心中的缓存不一致。软件必须通过执行适当的缓存维护操作来考虑这一点。
L1指令缓存的维护
操作可以在任何时间发生,不受L1I$(禁用或启用)的状态限制。
相关信息
请参考第45页的"5.4.5 调试恢复模式"。
7.2 L1 instruction cache Speculative memory accesses //L1指令缓存的推测性内存访问
指令获取是有推测性质的,流水线中可能存在多个未解决的分支。代码流中的分支指令或异常可能导致流水线刷新,丢弃当前已获取的指令。在指令获取中,具有设备内存类型属性的页面被视为非缓存正常内存。
设备内存页面必须使用翻译表描述符属性位eXecute Never (XN)进行标记。设备和代码地址空间必须在物理内存映射中分离。这种分离可以防止在地址转换被禁用时进行推测性获取敏感设备的操作。
如果启用了L1指令缓存,并且指令获取在L1指令缓存中未命中,它们仍然可以在L1数据缓存中查找。然而,无论数据缓存是否启用,该查找都不会导致L1数据缓存重新填充。只有在启用L1指令缓存的情况下,才会在L2缓存中分配该行。
7.3 Program flow prediction
Cortex®-A715核心包含程序流预测硬件,也称为分支预测。分支预测可以提高整体性能并增强功耗效率。除非当前异常级别下的内存管理单元(MMU)被禁用,否则程序流预测始终处于启用状态。如果禁用了程序流预测,则所有taken(被执行)的分支都会产生与清理流水线相关的惩罚。如果启用了程序流预测,则会预测条件分支或无条件分支是否被执行,具体如下:
- 对于条件分支,它会预测该分支是否被执行以及分支转到的地址,即分支目标地址。
- 对于无条件分支,它只会预测分支的目标地址。
程序流预测硬件包含以下功能:
- 分支目标缓冲区(BTB),保存先前执行的分支的目标地址。
- 分支预测器(BP),使用先前的分支历史进行预测。
- 返回栈,包括嵌套子程序的返回地址。
- 静态分支预测器。
- 间接分支预测器。
预测和非预测指令
程序流预测硬件会预测所有的分支指令,包括:
- 条件分支
- 无条件分支
- 与过程调用和返回指令相关的间接分支
异常返回分支指令不会进行预测。
返回栈
返回栈(return stack)存储地址和指令集状态。这个地址等于AArch64中X30寄存器(链接寄存器)的值。
下列指令会导致返回栈的压栈操作:
- BL
- BLR
- BLRAA
- BLRAAX
- BLRAB
- BLRABZ
下列指令会导致返回栈的出栈操作:
- RET
- RETAA
- RETAB
以下指令不会进行预测,因为它们可以改变核心的特权模式和安全状态:
- ERET
- ERETAA
- ERETAB
8. L1 data memory system
Cortex®-A715核心的L1数据存储系统执行加载和存储指令。它处理内存一致性请求以及特定的指令,例如原子操作、缓存维护操作和内存标记指令。L1数据存储系统包括L1数据缓存和L1数据转换后备缓冲器(TLB)。
以下表格展示了L1数据存储系统的特性。

L1数据TLB也驻留在L1数据存储系统中。然而,它是内存管理单元(MMU)的一部分,并在第51页的「6. 内存管理」中描述。
8.1 L1 data cache behavior
L1数据缓存在复位时会自动失效,除非将核心电源模式初始化为调试恢复模式。
在调试恢复模式下,L1数据缓存不可用。
没有针对整个数据缓存进行失效的操作。如果软件需要此功能,那么必须通过迭代缓存几何结构并执行一系列单独的按集/路指令来构建它。DC CISW操作同时对目标集/路进行清除和失效。HCR_EL2.SWIO的值不起作用。有关DC CISW和HCR_EL2的更多信息,请参阅Arm® A-profile架构参考手册。
当L1数据缓存禁用时的行为:
• 加载指令不会在L2或L3缓存中分配新的行。
• 对可缓存内存的所有加载和存储指令均视为非可缓存。
• 数据缓存维护操作继续正常执行。
L1数据缓存和L2缓存不能独立禁用。当一个核心禁用了L1数据缓存后,由该核心发出的可缓存内存访问不再缓存到L1或L2缓存中。但是,共享L2缓存的另一个核心仍然可以将数据缓存在其L1缓存和共享的L2缓存中。
为了保持多个核心之间的数据一致性,Cortex®-A715核心使用修改、排他、共享、失效(MESI)协议。
缓存索引的确定方式意味着物理地址(PA)和组号之间没有直接关系。您不能使用假定PA和组号之间存在关系的目标化操作。
要刷新整个缓存,必须按照CCSIDR_EL1中描述的缓存的组数和路数执行集和路维护操作。该操作符合Armv8-A架构。
相关信息:
5.4.5 调试恢复模式 (第45页)
8.2 Write streaming mode
Cortex®-A715核心支持写流模式,有时也称为读分配模式,适用于L1和L2缓存。
在读缺失或写缺失时,缓存行会分配给L1或L2缓存。然而,写入大块数据可能会使缓存中充满不必要的数据。当执行的线填充只是为了丢弃线填充数据时,这会浪费功耗和性能,因为整个缓存行会被后续的写操作覆盖(例如使用memset()或memcpy())。在某些情况下,写操作不需要分配缓存行,比如执行C标准库的memset()函数来将大块内存清零。
为了防止不必要的缓存行分配,合并写缓冲器(MWB)会检测核心在线填充完成之前是否已经写入了完整的缓存行。如果在可配置数量的连续线填充中检测到这种情况,则MWB切换到写流模式。进入写流模式后,加载操作的行为正常,仍可能导致线填充。在写流模式下,写操作仍会查找缓存,但如果未命中,则会写入L2或L3缓存,而不是开始线填充。
在MWB切换到写流模式之前,可能会观察到超过指定数量的线填充。
写流模式将保持启用,直到以下情况发生之一:
• 检测到一个不完整的缓存行可缓存写入突发。
• 有一个后续的加载操作与尚未完成的写流目标相同。
当Cortex®-A715核心切换到写流模式时,MWB会继续监视总线流量。当它观察到进一步数量的完整缓存行写入时,它会向L2或L3缓存发出信号进入写流模式。
写流阈值定义了在存储操作停止引起缓存分配之前,连续多少个缓存行将被完全写入而没有被读取。您可以通过写入寄存器A.1.15 IMP_CPUECTLR_EL1,即CPU扩展控制寄存器,来配置每个缓存(L1、L2和L3)的写流阈值。
8.3 Instruction implementation in the L1 data memory system
Cortex®-A715核心支持Arm®v8.1-A架构中添加的原子指令。
对可缓存内存的原子指令可以作为近原子操作或远原子操作执行,默认情况下,Cortex®-A715核心将这些指令作为近原子操作执行。
另外,可以对CPUECTLR进行编程,以根据系统行为,某些原子指令尝试作为远原子操作执行。
当作为远原子操作执行时,原子操作传递给互连模块执行。如果操作在集群内任何位置命中,或者互连模块不支持原子操作,则L3内存系统执行原子操作。如果缓存行不存在,则将其分配到L3缓存中。
当启用了精确检查的内存标记扩展(MTE)时,所有经过检查的原子操作都会在近处执行。
Cortex®-A715核心支持对设备或非缓存内存的原子操作,但这也取决于互连模块是否支持原子操作。如果在互连模块不支持原子操作的情况下执行此类原子指令,则会导致异常中止。
8.4 Internal exclusive monitor //内部独占监视器
Cortex®-A715核心包含一个内部独占监视器,具有2状态(开放状态和独占状态)的状态机,用于管理Load-Exclusive和Store-Exclusive访问以及Clear-Exclusive (CLREX)指令。
您可以使用这些指令构建信号量,确保在核心上运行的不同进程之间以及使用相同一致性内存位置的不同核心之间的同步。Load-Exclusive指令会为一小块内存标记独占访问权。CTR_EL0将标记块的大小定义为16个字,即一个缓存行。
Load-Exclusive或Store-Exclusive指令是以LDX、LDAX、STX或STLX开头的指令助记符。
有关这些指令的更多信息,请参阅A-Profile架构的Arm® Architecture Reference Manual。
有关更多技术参考和寄存器信息,请参阅第312页的A.4.23 CTR_EL0,缓存类型寄存器。
8.5 Data prefetching
数据预取在执行性能提升之前获取数据。对于无法有效处理的情况,Cortex®-A715核心支持AArch64预取存储器指令PRFM。
这些指令向内存系统发出信号,指示指定地址的内存访问可能很快发生。内存系统采取措施以减少内存访问的延迟。
PRFM指令在缓存中进行查找。如果缓存未命中且是可缓存地址,则开始进行线填充(linefill)。然而,当线填充开始时,PRFM指令已经完成,并且不会等待线填充完成。
有关预取内存和预加载缓存的更多信息,请参阅A-Profile架构的Arm® Architecture Reference Manual。
硬件数据预取器
加载/存储单元包括负责生成针对L1、L2和L3缓存的预取的硬件预取引擎。具体而言,L1内存子系统中的预取引擎针对L1和L2缓存。L2内存子系统中的预取引擎针对L2和L3缓存。加载端的预取器使用虚拟地址(VA)和程序计数器(PC)。存储端的预取器仅使用虚拟地址(VA)。
CPUECTLR寄存器允许对预取器行为的某些方面进行控制。有关更多信息,请参阅以下内容:
• 第159页的A.1.15 IMP_CPUECTLR_EL1,CPU扩展控制寄存器
• 第167页的A.1.16 IMP_CPUECTLR2_EL1,CPU扩展控制寄存器
数据缓存清零
在Cortex®-A715核心中,通过虚拟地址执行数据缓存清零(DC ZVA)指令可将内存中的一块64字节区域(对齐到64字节)设置为零。
有关更多信息,请参阅A-Profile架构的Arm® Architecture Reference Manual。
9. L2 memory system
Cortex®‑A715核心的L2内存系统通过CPU桥将核心与DynamIQ™共享单元-110(DSU-110)连接在一起。它包括私有的L2缓存。
L2缓存是统一的,并且对于集群中的每个Cortex®‑A715核心都是私有的。 //L2是core私有的!!!
L2内存系统包括使用虚拟地址(VA)和程序计数器(PC)的数据预取引擎。不同的引擎能够预取L2缓存和L3缓存中的数据。
以下表格显示了L2内存系统的特性。

9.1 L2 cache
集成的L2缓存处理来自指令和数据方面的指令和数据请求,以及转换表遍历请求。
L1指令缓存和L2缓存是弱包容性(weakly inclusive)的。在L1指令缓存和L2缓存中未命中的指令获取会分配两个缓存,但是L2缓存的失效不会导致L1指令缓存的回写无效(back-invalidate)。
L1数据缓存和L2缓存是严格排他的(strictly exclusive)。L1数据缓存中的任何数据都不会存在于L2缓存中。
除非核心电源模式初始化为调试恢复模式(Debug recovery mode),否则L2缓存会在复位时自动失效。
缓存索引的确定方式意味着物理地址(PA)与组号之间没有直接关系。您不能使用假设PA和组号之间存在关系的目标操作。
要刷新整个缓存,您必须根据该缓存的CCSIDR_EL1描述执行组和路维护操作,操作数量等于集合数和路数。此操作符合Armv8-A架构规范。
相关信息
5.4.5 第45页的调试恢复模式(Debug recovery mode)
9.2 Support for memory types
Cortex®-A715核心通过降级某些内存类型简化一致性逻辑。
被标记为内部写回高速缓存和外部写回高速缓存的内存将被缓存在L1数据缓存和L2缓存中。
被标记为内部写透模式的内存会被降级为不可缓存。
被标记为外部写透模式或外部非缓存模式的内存会被降级为不可缓存,即使内部属性为写回高速缓存。
额外的属性提示如下使用:
分配提示(Allocation hint)
分配提示有助于确定系统中新获取行的分配规则。
瞬态提示(Transient hint)
所有设置了瞬态位的可缓存读取和写入会在L2缓存中进行分配。
对L1数据缓存进行的具有瞬态位设置的读取会在L1缓存中进行分配。从L1缓存逐出的瞬态行不会在下游缓存中进行分配。
9.3 Transaction capabilities //事务能力
The CHI Issue E接口连接了Cortex®-A715核心的L2内存系统和DynamIQ™共享单元-110 (DSU-110),为核心提供了事务能力。
以下表格显示了Cortex®-A715核心L2缓存的读取、写入、分布式虚拟内存(DVM)发出和嗅探能力的最大可能值。


请参考Arm®架构参考手册中的A-profile架构部分,了解不同内存类型的信息。
10. Direct access to internal memory
Cortex®-A715核心通过IMPLEMENTATION DEFINED系统寄存器提供了一种读取L1缓存、L2缓存和TLB结构所使用的内部内存的机制。当缓存数据与系统内存数据之间的一致性被破坏时,您可以使用这种机制来调查任何问题。
无法更新缓存或TLB结构的内容。
只有在EL3中才能直接访问内部内存。在其他所有异常级别中,执行这些指令会导致未定义指令异常。
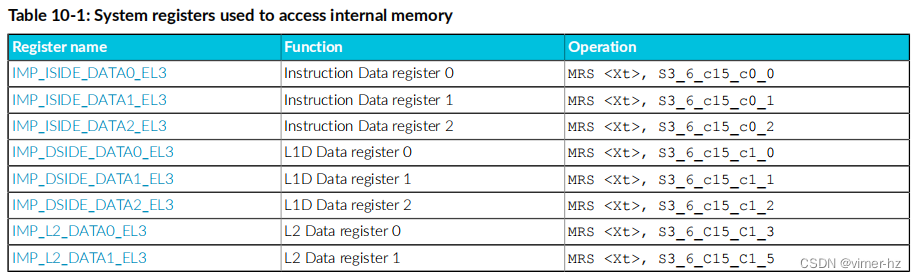
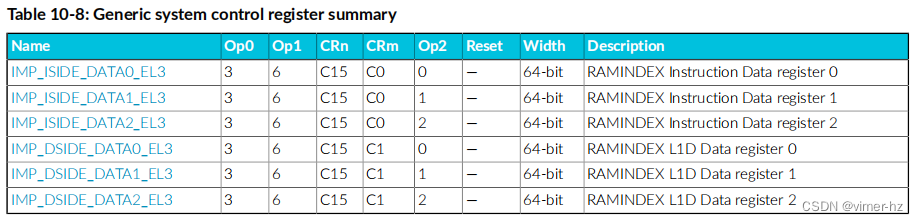
您可以使用表10-1中的十二个只读(RO)系统寄存器来访问内部内存的内容。通过使用以下SYS指令将内部内存选定为IMPLEMENTATION DEFINED RAMINDEX寄存器进行编程:
SYS #6, C15, C0, #0, <Xt>
有关RAMINDEX寄存器的更多信息,请参见第255页的附录A.3.1 RAMINDEX, RAMINDEX system instruction。数据从只读系统寄存器中读取,如下表所示。
- 所有系统寄存器均为只读(RO)且宽度为64位。
- 有关寄存器复位值,请参阅各个位复位。
- 对数据寄存器的任何访问都会返回数据。
- 单击寄存器名称以获取返回数据格式的详细信息。

10.1 L1 cache encodings
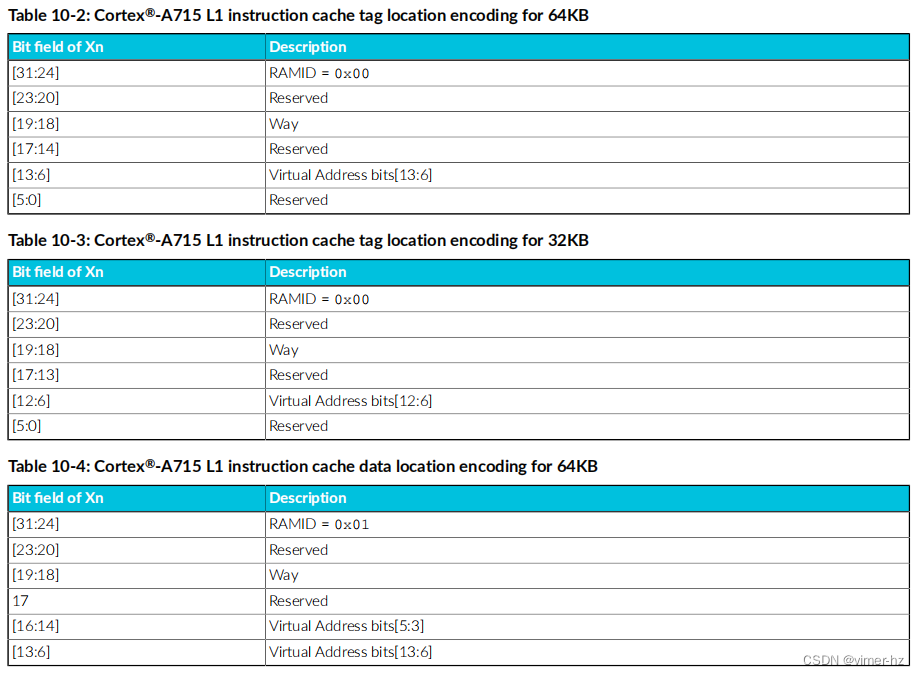
L1数据缓存和指令缓存都是4路组相联的。
配置的缓存大小确定了每个组相联方式中的组数。用于定位标签和数据内存的缓存数据条目的编码在适当的SYS指令中的Xn中设置。对于标签和数据RAM访问,它们的编码是相似的。
//L1数据缓存和指令缓存都是4路组相联的。具体解释下:
L1数据缓存和指令缓存是处理器中的两个关键组件,用于提高数据和指令的访问速度。它们都采用了4路组相联的设计。
"组相联"指的是缓存中数据和指令条目的存储方式。每个缓存被划分为多个组,而每个组中又有多个条目。在4路组相联的设计中,每个组内有4个条目。
当需要访问缓存中的数据或指令时,处理器会使用特定的算法根据内存地址来确定数据所在的组。然后,它会在该组的4个条目中查找匹配的数据。
使用4路组相联的设计可以提高缓存的命中率。当处理器需要读取或写入数据时,它首先会检查该数据是否已经存在于缓存中。如果数据在缓存中被找到(即命中),处理器就可以更快地访问数据,从而提高了系统性能。如果数据未命中,则需要从主存储器中读取或写入数据,这需要更多的时间。
总之,L1数据缓存和指令缓存都采用了4路组相联的设计,以提高数据和指令的访问速度和系统性能。
以下表格显示了定位和选择给定缓存行所需的编码:
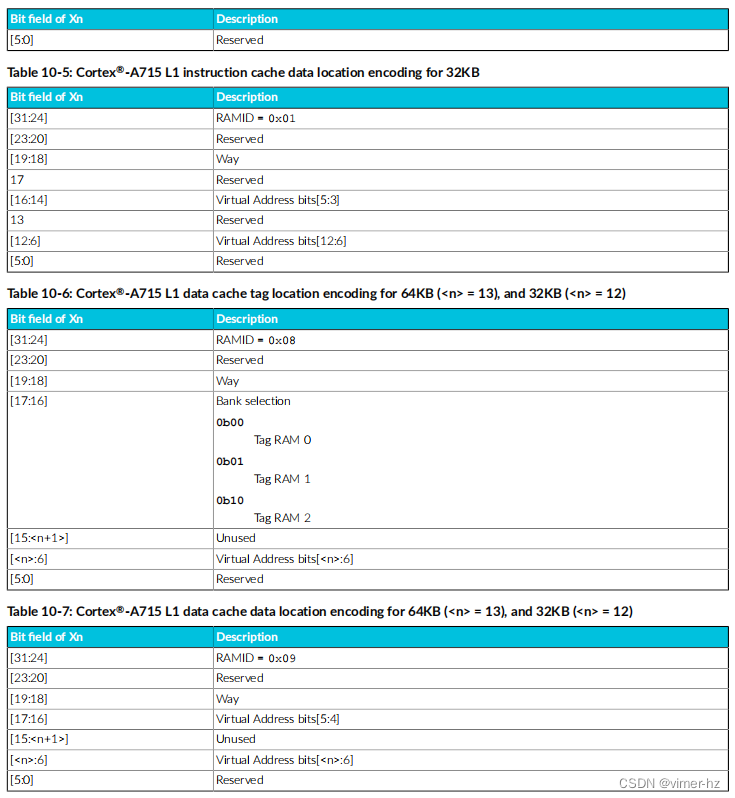
10.1.1 L1 RAM returned data
对于每个寄存器,对L1 RAM的任何访问都会返回数据。
点击下表中的寄存器名称以获取返回数据格式的详细信息。
10.2 L2 cache encodings
L2缓存是8路组相联的。
配置的缓存大小确定了每个组相联方式中的组数。用于定位标签和数据内存的缓存数据条目的编码在适当的SYS指令中的Xn中设置。对于标签和数据RAM访问,它们的编码是相似的。
以下表格显示了定位和选择给定缓存行所需的编码:
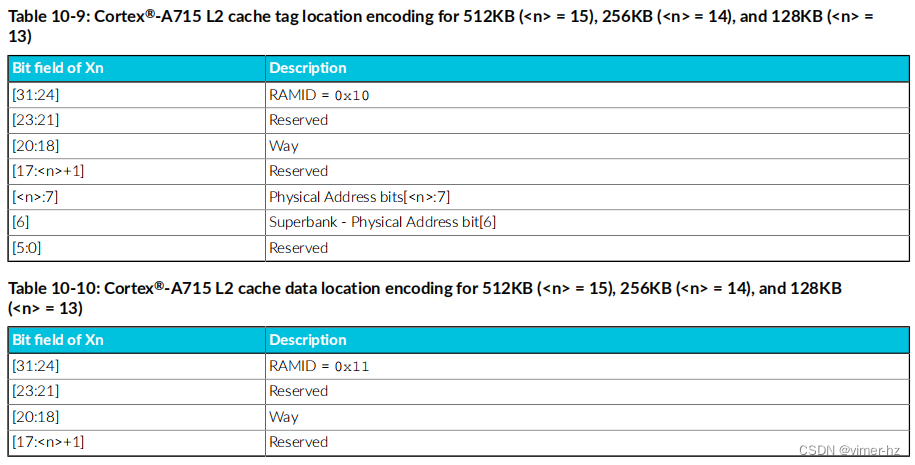

10.2.1 L2 RAM returned data
对于每个寄存器,对L2 RAM的任何访问都会返回数据。
点击下表中的寄存器名称以获取返回数据格式的详细信息。

10.3 L2 TLB encodings
L2 TLB RAM中的小页面(TCSP)采用6路组相联方式,中等页面(TCMP)采用4路组相联方式。
以下表格显示了定位和选择给定缓存行所需的编码:

10.3.1 L2 TLB RAM returned data
对于每个寄存器,对L2 TLB RAM的任何访问都会返回数据。
点击下表中的寄存器名称以获取返回数据格式的详细信息。

11. RAS Extension support
Cortex®‑A715核心支持可靠性、可用性和可服务性(RAS)v1.1扩展,但不支持可选的RAS时间戳扩展。
具体而言,Cortex®‑A715核心支持以下RAS扩展功能:
• 对包含脏数据的功能性RAM进行单错误纠正、双错误检测(SECDED)和错误纠正码(ECC)的缓存保护。包括L1数据标签和数据、L2标签和数据以及L2事务队列(TQ)RAM。
• 对只包含干净数据的功能性RAM进行单错误检测(SED)奇偶校验的缓存保护。包括L1指令标签和数据缓存以及内存管理单元(MMU)RAM。
• 错误同步屏障(ESB)指令。当执行ESB指令时,核心确保在ESB之前生成的所有SError中断要么由核心接收,要么挂起在DISR_EL1中。
• 总线传输中的毒属性。
• 错误数据记录寄存器。
• 错误处理中断(FHI)。
• 错误恢复中断(ERI)。
• 错误注入。
Cortex®‑A715核心具有以下节点:
• 节点0,包括DynamIQ™ Shared Unit-110(DSU-110)中的共享L3内存系统。
• 节点1,包括核心中的私有L1和L2内存系统。
有关架构RAS扩展和节点定义的更多信息,请参阅Arm® Reliability, Availability, and Serviceability (RAS) Specification Armv8,针对Armv8-A架构配置文件。
有关包含共享L3内存系统的节点的信息,请参阅Arm® DynamIQ™ Shared Unit-110 Technical Reference Manual中的RAS扩展支持部分。
11.1 Cache protection behavior
在Cortex®‑A715核心中,可靠性、可用性和可服务性(RAS)扩展的配置包括缓存保护。在这种情况下,Cortex®‑A715核心可以防止RAM位单元保存错误值而导致的错误。
Cortex®‑A715核心中的RAM具有以下功能:
SED奇偶校验
单错误检测(SED)。一个奇偶校验位适用于整个字。字的大小对于每个RAM都是特定的,并且取决于保护颗粒。
SECDED纠错码
单错误纠正、双错误检测(SECDED),错误纠正码(ECC)。字的大小对于每个RAM都是特定的,并且取决于保护颗粒。
以下表格显示了每个RAM应用的保护类型。当任何RAM中有单个位错误时,核心可以继续进行并保持功能上的正确性。

如果不同的RAM或同一RAM内的不同保护颗粒存在多个单位错误,核心也可以保持功能上的正确性。
如果在同一保护颗粒内的单个RAM中存在双位错误,则行为取决于RAM:
• 对于具有SECDED功能的RAM,核心会检测并报告或推迟错误。如果错误出现在包含脏数据的缓存行中,则可能丢失该数据。
• 对于仅具有SED的RAM,核心无法检测到双位错误。这可能导致数据损坏。
如果在同一保护颗粒内有三个或更多位错误,核心可能会或可能不会检测到这些错误。它是否检测到错误取决于RAM和错误在RAM内的位置。当没有错误时,核心的缓存保护功能对性能的影响很小。
11.2 Error containment //错误隔离
Cortex®-A715核心支持数据错误的错误隔离。这意味着检测到的数据错误不会静默传播。使用数据污染来延迟数据错误,确保使用者知道错误的存在。无法纠正的L1数据缓存标签错误和L2缓存标签错误无法被隔离。
错误隔离还意味着在替换时,如果存在双重错误,支持对所关联数据进行污染,以确保在使用时报告相关数据的错误。
该核心还支持错误同步屏障(Error Synchronization Barrier,ESB)指令,进一步隔离在使用污染数据时报告的不精确异常。
11.3 Fault detection and reporting
当Cortex®-A715核心检测到故障时,通过故障或错误信号引发Fault Handling Interrupt (FHI)异常或Error Recovery Interrupt (ERI)异常。FHIs和ERIs会在可靠性、可用性和可维护性(RAS)寄存器中反映,这些寄存器会在检测到错误的节点中更新。核心节点错误使用nCOREFAULTIRQ进行报告。
未纠正的故障
当ERR1CTLR.FI被设置时,所有由核心n检测到的延迟错误和未纠正错误都会通过nFAULTIRQ[n+1]信号生成一个FHI。
当ERR1CTLR.CFI或任何其他CE计数器溢出位被设置时,所有检测到的已纠正错误也会导致生成一个FHI。
未纠正的中断
当ERR1CTLR.UI被设置时,核心n检测到的所有未推迟的未纠正错误都会在nCOREERRIQ信号上生成一个错误恢复中断。
清除报告的故障
nFAULTIRQ [n+1]和nERRIRQ [n+1]信号必须保持激活状态,直到软件通过写入ERR1STATUS寄存器来清除它们。
11.4 Error detection and reporting
当Cortex®-A715核心发生错误时,根据错误类型会引发不同的异常。
Cortex®-A715核心可能引发以下异常:
- 同步外部中止(Synchronous External Abort,SEA)
- 异步外部中止(Asynchronous External Abort,AEA)
- 错误恢复中断(Error Recovery Interrupt,ERI)
错误检测和报告寄存器:
以下寄存器用于错误处理和报告:
- 错误记录特征寄存器(Error Record Feature Registers,ERR1FR)。这些只读寄存器指定各种错误记录设置。
- 错误记录控制寄存器(Error Record Control Registers,ERR1CTLR)。这些寄存器用于启用错误报告,并启用与错误和故障相关的各种中断。
- 错误记录杂项寄存器(Error Record Miscellaneous Registers,ERR1MISC0-3)。这些寄存器记录错误位置和计数的详细信息。
- 伪故障生成特征寄存器(Pseudo-fault Generation Feature register,ERR1PFGF)。这个只读寄存器指定各种错误设置。
11.4.1 Error reporting and performance monitoring
所有检测到的内存错误,包括纠错码(ECC)错误或奇偶校验错误,都会触发"MEMORY_ERROR"事件。
如果选择了"MEMORY_ERROR"事件并且计数器已启用,则性能监视单元(Performance Monitoring Unit,PMU)计数该事件。
在安全状态下,只有当MDCR_EL3.SPME被断言时,才会计数该事件。关于MDCR_EL3的详细信息,请参阅Arm® A-profile架构参考手册。
相关信息
可以在《Arm® Architecture Reference Manual for A-profile architecture》的第98页中找到,其中描述了性能监视器事件。
11.5 Error injection //错误注入
错误注入(Error injection)是指在错误检测逻辑中插入错误,以验证错误处理软件的功能。
错误注入使用错误检测和报告寄存器来插入错误。Cortex®-A715核心可以注入以下类型的错误:
修正的错误
单个纠错码(ECC)错误在L1数据缓存访问时会生成一个修正错误(CE)。
延迟的错误
当从L1缓存驱逐一个缓存行到L2缓存时发生双重ECC错误,或者在对L1缓存进行探测时产生延迟错误(DE)。
无法控制的错误
当L1标签RAM或随后发生驱逐的L2标签RAM出现双重ECC错误时,会生成无法控制的错误(UC)。
错误可以立即注入,也可以在一个32位计数器达到零时注入。您可以通过错误伪故障生成倒计时寄存器(ERR1PFGCDN)控制计数器的值。计数器的值按每个时钟周期递减。有关ERR1PFGCDN的更多信息,请参阅《Arm®可靠性、可用性和可维护性(RAS)规范Armv8》,了解Armv8-A架构配置文件的更多信息。
错误注入是系统中的一个独立的错误源,不会创建硬件故障。
11.6 AArch64 RAS registers
摘要表提供了核心中实现定义的RAS寄存器的概览。要了解有关寄存器的更多信息,请在表格中单击寄存器名称。
对于没有列出复位值的寄存器,请参考注册表描述页面或Arm ARM中记录的各个字段复位信息。

12. Utility bus
实用总线(utility bus)提供对DynamIQ™ 共享单元-110(DSU-110)中各个系统组件的控制寄存器的访问,以及DSU-110 DynamIQ™ 集群内核心的控制寄存器。实用总线被实现为一个64位的AMBA AXI5从设备端口,并且控制寄存器被内存映射到实用总线上。
在Cortex®-A715核心中,实用总线提供对以下系统功能的访问:
• 核心中的活动监视器单元(AMU)寄存器
• 核心中的最大功率缓解机制(MPMM)寄存器
有关集群中核心的PPU寄存器的信息,请参阅Arm® DynamIQ™ 共享单元-110 技术参考手册。对于实用总线访问的所有其他寄存器,请参阅Arm® DynamIQ™ 共享单元-110 技术参考手册中的实用总线章节。
12.1 Base addresses for system components
系统寄存器的每组都在单独的64KB页面边界上进行分组,以便通过内存管理单元(MMU)强制执行访问。
以下表格显示了每组系统组件寄存器的基地址及其应该从何种安全状态进行访问:
• 核心AMU和MPMM寄存器的每组寄存器的基地址取决于核心实例编号 <n>,从 0 到总核心数减一。
• 在下表中,任何未记录的地址空间视为RAZ/WI(保留为零/写入无效)。
• 下表中的基地址是通过实用总线接口访问的地址。系统互连通常将这些地址映射到特定的地址范围上,根据系统地址映射来确定。因此,软件必须将此处列出的基地址加上系统地址范围基址,以获得寄存器的绝对物理地址。

13. GIC CPU interface
通用中断控制器(GIC)支持和控制中断。GIC Distributor 通过 GIC CPU 接口与 Cortex®-A715 核心连接。GIC CPU 接口包括用于屏蔽、识别和控制转发到核心的中断状态的寄存器。
DSU-110 DynamIQ™ 集群中的每个核心都有一个 GIC CPU 接口,它连接到一个共同的外部分发器组件。
在 Cortex®-A715 核心中实现的 GICv4.1 架构支持:
• 两个安全状态
• 安全虚拟化
• 软件生成的中断(SGI)
• 基于消息的中断
• CPU 接口的系统寄存器访问
• 中断屏蔽和优先级设置
• 集群环境,包括包含超过八个核心的系统
• 电源管理环境中的唤醒事件
GIC 包括中断分组功能,支持:
• 将每个中断配置为属于 Group 0 或 Group 1,其中 Group 0 中断始终为安全中断
• 使用 IRQ 或 FIQ 异常请求将 Group 1 中断传递给目标核心。Group 1 中断可以是安全或非安全中断
• 只使用 FIQ 异常请求将 Group 0 中断传递给目标核心
• 统一的方案处理 Group 0 和 Group 1 中断的优先级
有关中断组的更多信息,请参阅 Arm® Generic Interrupt Controller Architecture Specification,GIC 架构版本 3 和版本 4。
13.1 Disable the GIC CPU interface
Cortex®-A715 核心始终包含通用中断控制器(GIC)CPU接口。但是,您可以禁用它以满足您的需求。
要禁用 GIC CPU 接口,在复位时将 GICCDISABLE 信号置为高电平。如果以这种方式禁用它,则可以使用外部的 GIC IP 驱动中断信号(nFIQ、nIRQ)。如果在系统中未将 Cortex®-A715 核心集成到外部 GIC 中断分发器组件(最小 GICv3 架构),则必须禁用 GIC CPU 接口。
如果禁用了 GIC CPU 接口,则:
• 虚拟输入信号 nVIRQ 和 nVFIQ 以及输入信号 nIRQ 和 nFIQ 可以由 SoC 中的外部 GIC 驱动。
• GIC 系统寄存器访问会生成 UNDEFINED 指令异常。
如果启用了 GIC CPU 接口,则必须将 nVIRQ 和 nVFIQ 绑定为高电平。这是因为 GIC CPU 接口会向核心生成虚拟中断信号。而 nIRQ 和 nFIQ 信号由软件控制,因此不需要将它们绑定为高电平。
有关这些信号的更多信息,请参阅 Arm® DynamIQ™ Shared Unit-110 Configuration and Integration Manual 中的功能集成部分。
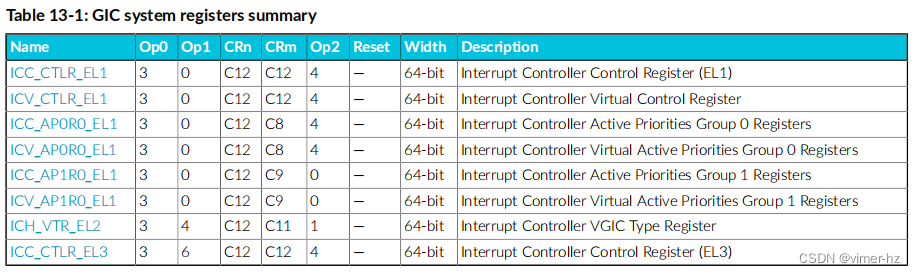
13.2 AArch64 GIC system registers
总结表格提供了核心中实现定义的 GIC 系统寄存器的概述。要获取有关寄存器的更多信息,请在表格中单击寄存器名称。对于未列出复位值的寄存器,请参考寄存器描述页面或 Arm ARM(架构参考手册)中记录的各个字段复位。
14. Advanced SIMD and floating-point support
Cortex®-A715核心支持A64指令集中的高级SIMD和标量浮点指令,而无需进行浮点异常捕获。
Cortex®-A715核心浮点实现包括Arm®v8.5-A的功能。BFloat16浮点和Int8矩阵乘法是这些支持的功能之一。
Cortex®-A715核心在硬件中实现了所有操作,支持以下各种组合:
• 舍入模式
• 清零模式
• 默认非数字(NaN)模式
15. Scalable Vector Extensions support
Cortex®-A715核心支持可扩展向量扩展(SVE)和可扩展向量扩展2(SVE2)。SVE和SVE2是对AArch64高级SIMD和浮点功能的补充,而不是替代品。
SVE是由Armv8.2架构引入的可选扩展。SVE提供的向量指令主要支持比Arm Advanced SIMD指令集更宽的向量。Cortex®-A715核心实现了128位的可扩展向量长度。
SVE引入的所有功能和附加内容都在《Arm®体系结构参考手册增补》中进行了描述,即《可扩展向量扩展》一书中。
16. System control
系统寄存器控制和提供核心实现的功能的状态信息。
系统寄存器的主要功能包括:
• 系统性能监控
• 缓存配置和管理
• 整体系统控制和配置
• 内存管理单元(MMU)的配置和管理
• 通用中断控制器(GIC)的配置和管理
系统寄存器可以在AArch64执行状态的EL0到EL3中访问。其中一些系统寄存器可以通过外部调试接口或实用总线接口进行访问。
17. Debug
DSU-110 DynamIQ™集群提供了一种支持自托管和外部调试的调试系统。它具有一个外部的DebugBlock组件,并集成了各种CoreSight调试相关组件。
CoreSight调试相关组件分为两组,其中一些组件位于DynamIQ™集群中,另一些组件位于单独的DebugBlock中。
DebugBlock是DSU-110中的专用调试组件,与集群分离。DebugBlock在单独的电源域内运行,可以在核心和DynamIQ™集群同时关闭电源时保持与调试器的连接。
集群和DebugBlock之间的连接由一对高级外设总线APB接口组成,各自向一个方向进行数据传输。除了认证接口外,所有调试流量都通过该接口进行读取或写入APB事务。这些调试流量包括寄存器读取、寄存器写入和交叉触发接口(CTI)触发。
调试系统实现了以下CoreSight调试组件:
• 集成到CoreSight子系统中的每个核心跟踪单元。
• 包含在DebugBlock中的每个核心CTI。
• 交叉触发矩阵(CTM)
• 由AMBA® APB接口提供的DebugBlock的调试控制
下图展示了如何在DynamIQ™集群中实现调试系统。
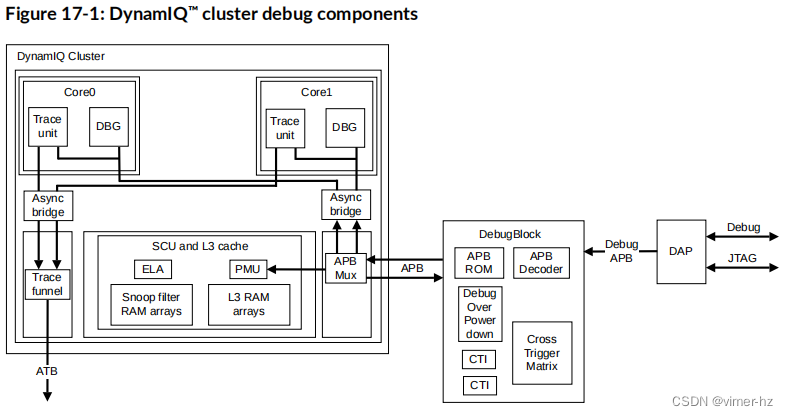
DebugBlock上的主要调试APB接口控制调试组件。在将请求发送到DebugBlock或DynamIQ™集群中的适当组件之前,APB解码器会对该总线上的请求进行解码。每个核心的CTI都连接到CTM。
每个核心都包含一个调试组件,调试APB总线可以访问这些组件。这些核心支持通过DebugBlock中的模块进行断电调试,这些模块反映了关键核心信息。这些模块允许在核心断电时访问断电调试的CoreSight™寄存器。
每个核心中的跟踪单元输出跟踪数据,这些数据在DynamIQ™集群中汇聚到一个单独的AMBA® 4 ATBv1.1接口。
关于DynamIQ™集群调试组件的更多信息,请参阅《Arm® DynamIQ™ Shared Unit-110 Technical Reference Manual》中的“调试(Debug)”部分。
Cortex®-A715核心还支持对内部存储器的直接访问,即缓存调试。直接访问内部存储器允许软件读取L1和L2缓存以及转译查找缓冲器(TLB)结构使用的内部存储器。有关更多信息,请参阅第71页上的"10. Direct access to internal memory"。
17.1 Supported debug methods
DSU-110 DynamIQ™集群及其相关核心是支持自托管和外部调试的调试系统的一部分。
下图展示了一个典型的外部调试系统。
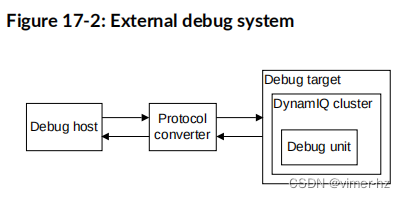
调试主机
一台计算机,例如个人电脑,上运行着诸如Arm®调试器之类的软件调试器。您可以使用调试主机发出高级命令。例如,您可以在特定位置设置断点或检查内存地址的内容。
协议转换器
调试主机使用诸如以太网之类的接口向调试目标发送消息。然而,调试目标通常实现了不同的接口协议。需要一个设备(例如DSTREAM)来在两个协议之间进行转换。
调试目标
系统的最底层实现了协议转换器通过调试单元访问的系统支持。对于基于DSU-110的设备,用于访问调试单元的机制是基于CoreSight架构实现的。通过APB接口访问DSU-110 DebugBlock,然后将调试访问定向到DynamIQ™集群内的选定A715核心。调试目标的一个示例是具有测试芯片或带有A715核心的硅芯片的开发系统。
调试单元
用于帮助调试运行在核心上的软件:
• 基于核心的DSU-110和外部硬件。
• 操作系统。
• 应用软件。
使用调试单元,您可以:
• 停止程序执行。
• 检查和更改进程和协处理器状态。
• 检查和更改内存以及输入或输出外设的状态。
• 重新启动处理单元(PE)。
对于自托管调试,调试目标运行在DynamIQ™集群中的核心上运行的调试监视器软件。这样,它不需要昂贵的接口硬件来连接第二个主机计算机。
17.2 Debug register interfaces
Cortex®-A715核心实现了Arm®v9.0-A调试架构。它还支持Arm®v8.4-A调试架构和Arm®v8.3-A的断电调试。
调试架构定义了一组调试寄存器。调试寄存器接口可以从在核心上运行的软件或外部调试器中访问这些寄存器。有关详细信息,请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的调试章节。
相关信息
第50页的5.7节中的断电调试(Debug over powerdown)
17.2.1 Core interfaces
系统寄存器访问允许Cortex®-A715核心直接访问特定的调试寄存器。调试寄存器接口可以从在核心上运行的软件或外部调试器中访问这些寄存器。
对调试寄存器的访问按如下方式进行划分:
调试
此功能既基于系统寄存器又基于内存映射。您可以使用连接到DynamIQ™共享单元-110(DSU-110)的APB从属端口访问调试寄存器映射。
性能监测
此功能基于系统寄存器并进行内存映射。您可以使用连接到DSU的DebugBlock的APB从属端口访问性能监测寄存器。
跟踪
此功能基于系统寄存器并进行内存映射。您可以使用连接到DSU的DebugBlock的APB从属端口访问跟踪单元寄存器。
统计分析
此功能基于系统寄存器。
ELA寄存器
此功能进行内存映射。您可以使用连接到DSU的DebugBlock的APB从属端口访问嵌入式逻辑分析器(ELA)寄存器。
有关APB从属端口接口的信息,请参阅Arm® DynamIQ™ Shared Unit-110技术参考手册中的接口部分。
17.2.2 Effects of resets on debug registers
core的complexporeset_n信号和complexreset_n信号会影响调试寄存器。
complexporeset_n信号对应一个冷复位,涵盖了核心逻辑和集成调试功能的复位。这个信号会初始化核心逻辑,包括跟踪单元、断点、监视点逻辑、性能监测器和调试逻辑。
complexreset_n信号对应一个热复位,涵盖了核心逻辑的复位。这个信号会复位部分调试和性能监测器逻辑。
17.2.3 External access permissions to Debug registers
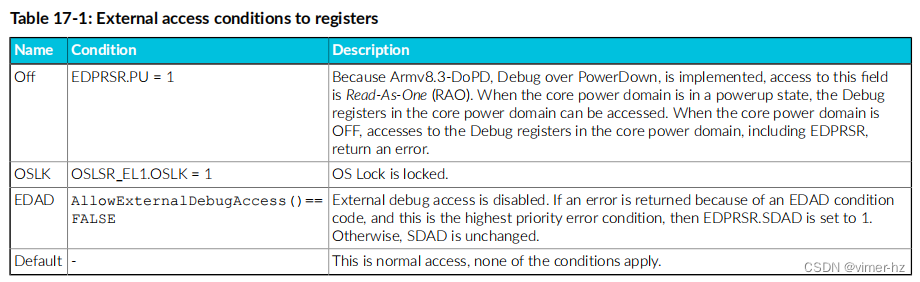
对Debug寄存器的外部访问权限取决于访问时的条件。
下表显示了通过外部调试接口进行访问时核心的响应:
17.2.4 Breakpoints and watchpoints
Cortex®-A715核心支持六个断点(breakpoint)、四个监视点(watchpoint)和一个标准的调试通信通道(Debug Communications Channel,DCC)。
一个断点由一个断点控制寄存器和一个断点值寄存器组成。这两个寄存器被称为断点寄存器对(Breakpoint Register Pair,BRP)。其中四个断点(BRP 0-3)仅匹配虚拟地址(Virtual Address,VA),另外两个断点(BRP 4和5)可以匹配虚拟地址(VA)、上下文ID(context ID)或虚拟机ID(Virtual Machine ID,VMID)。
你可以使用监视点来在程序访问特定内存地址时停止目标执行。所有的监视点都可以连接到两个断点(BRP 4和5),以便在给定的进程上下文中捕获内存请求。
17.3 Debug events
调试事件可以是软件调试事件或停机调试事件。
Cortex®-A715核心对调试事件的响应有以下几种方式:
- 忽略调试事件
- 抛出调试异常
- 进入调试状态
在Cortex®-A715核心中,监视点调试事件始终是同步的。内存提示指令和缓存清除操作(除了DC ZVA和DC IVAC)不会生成监视点调试事件。存储互斥指令即使在对互斥监视器控制检查失败时也会生成监视点调试事件。原子比较交换(CAS)指令即使在比较操作失败时也会生成监视点调试事件。
冷复位(Cold reset)将设置调试操作系统锁(Debug OS Lock)。为了使调试事件和调试寄存器访问正常运行,必须清除调试操作系统锁。
17.4 Debug memory map and debug signals
调试内存映射和调试信号在DSU-110 DynamIQ™集群级别进行处理。你可以参考《Arm® DynamIQ™ Shared Unit-110 Technical Reference Manual》中的调试表和ROM表来了解更多信息。该手册将提供关于如何处理调试内存映射和调试信号的详细技术参考。
17.5 ROM table
在Cortex®‑A715核心中,包含一个ROM表,其中列出了系统中的组件列表。调试器必须使用ROM表来确定实现了哪些CoreSight组件。ROM表是与CoreSight SoC一起用于系统调试的CoreSight调试相关组件,专为Cortex®‑A715核心设计。每个核心都有一个ROM表,并且ROM表符合Arm® CoreSight™ Architecture Specification v3.0。
DynamIQ™ Shared Unit-110 (DSU-110)具有自己的ROM表,一个用于集群(cluster),一个用于DebugBlock,并在集群ROM表中具有属于每个核心的ROM表的入口点。详细信息请参阅《Arm® DynamIQ™ Shared Unit-110 Technical Reference Manual》中的ROM表部分。
Cortex®‑A715核心的ROM表包括以下条目:

Related information
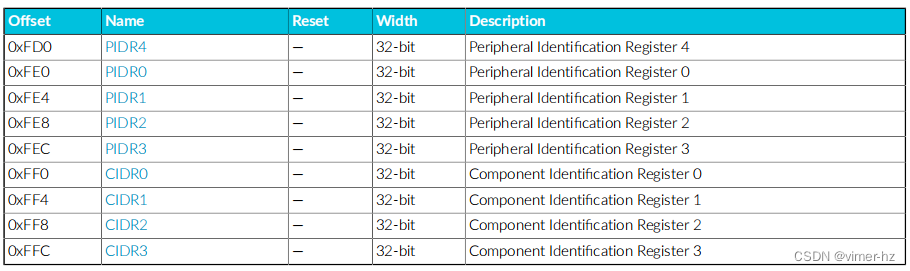
17.9 External ROM table registers on page 96
17.6 CoreSight™ component identifification
与Cortex®‑A715核心相关的每个组件都有一组唯一的CoreSight™ ID值。下表显示了这些值。


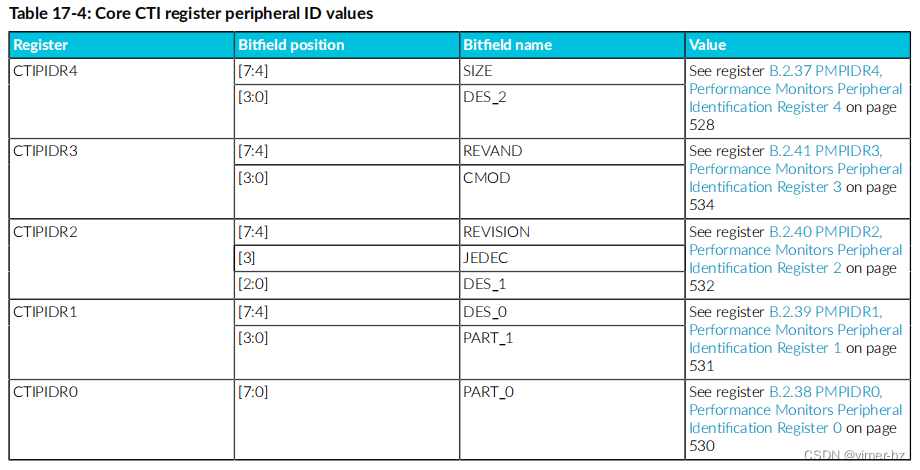
17.7 CTI register identifification values
Cortex®‑A715核心的Cross Trigger Interface (CTI)寄存器位于DSU-110的DebugBlock中。 有关集群和核心CTI寄存器的名称和描述,请参阅《Arm® DynamIQ™ Shared Unit-110 Configuration and Integration Manual》中的External CTI register summary。仅核心CTI寄存器的外设ID值与集群CTI寄存器的外设ID值不同。 下表显示了核心CTI寄存器的外设ID值。
17.8 External Debug registers
该摘要表提供了核心中实现定义的内存映射调试寄存器的概述。要获取有关寄存器的更多信息,请单击表中的寄存器名称。对于没有列出复位值的寄存器,请参考寄存器描述页中或Arm ARM中记录的各个字段复位。
17.9 External ROM table registers
该摘要表提供了核心中实现定义的内存映射ROM表寄存器的概述。要获取有关寄存器的更多信息,请单击表中的寄存器名称。对于没有列出复位值的寄存器,请参考寄存器描述页中或Arm ARM中记录的各个字段复位。
18. Performance Monitors Extension support
Cortex®‑A715核心实现了性能监视扩展,包括Arm®v8.4-A和Arm®v8.5-A的性能监测特性。
Cortex®‑A715核心的性能监视单元(PMU)具有以下功能:
- 通过事件接口从设计中的其他单元收集事件。这些事件被用作事件计数器的触发器。
- 通过性能监视控制寄存器支持周期计数器。
- 实现了PMU快照以进行上下文采样。
- 提供六个或20个64位PMU计数器,可以计算核心中提供的任何事件。记录的绝对计数可能因流水线效应而有所不同。除非计数器在很短的时间内启用,否则这种变化对性能影响微乎其微。
您可以使用系统寄存器或外部调试APB接口来对PMU进行编程。
18.1 Performance monitors events
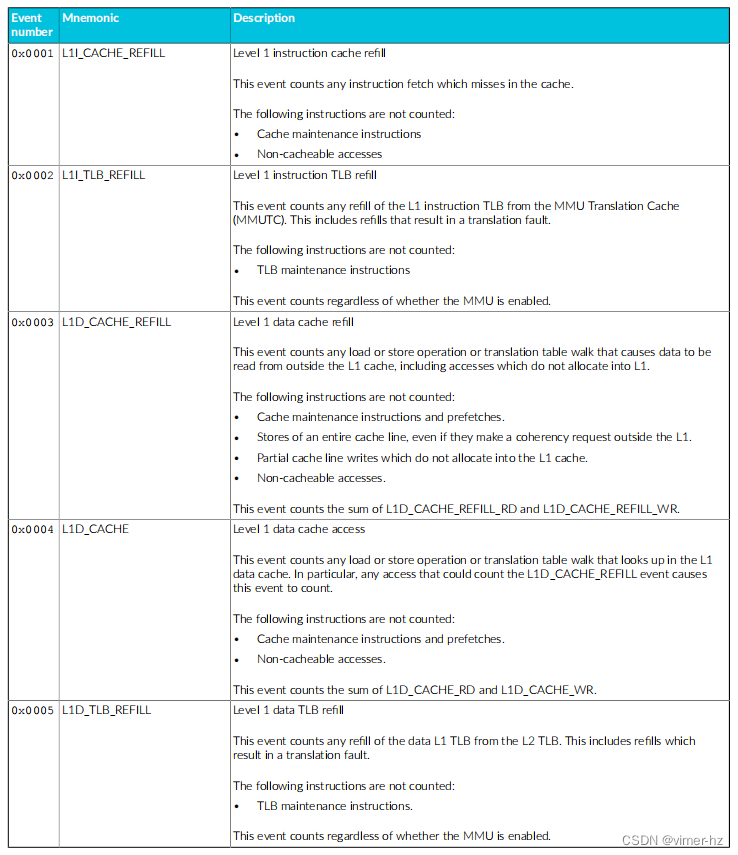
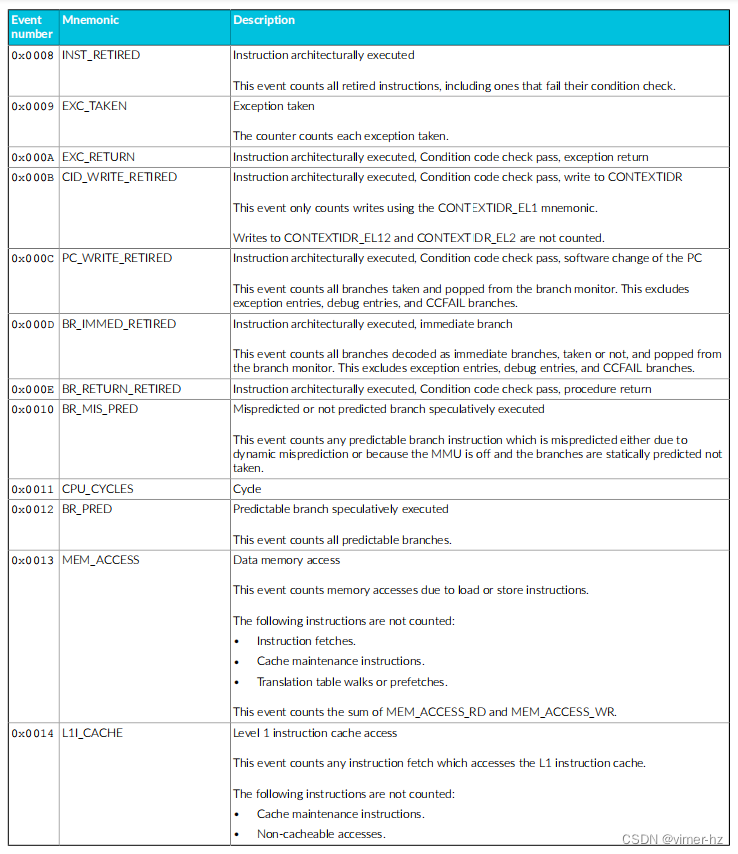
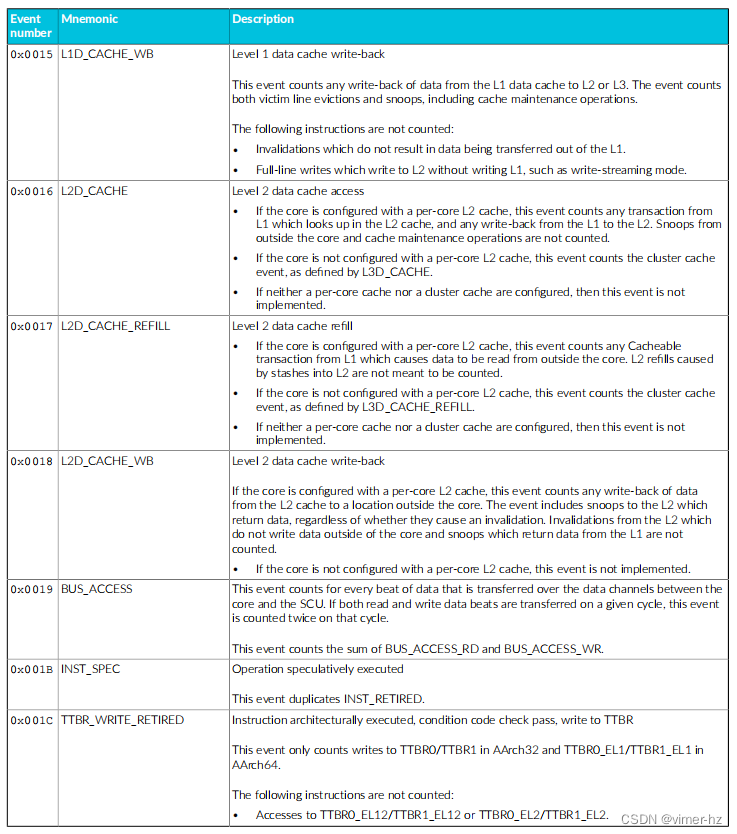
Cortex®‑A715核心的性能监视单元(PMU)从设计中的其他单元收集事件,并使用数字引用这些事件。
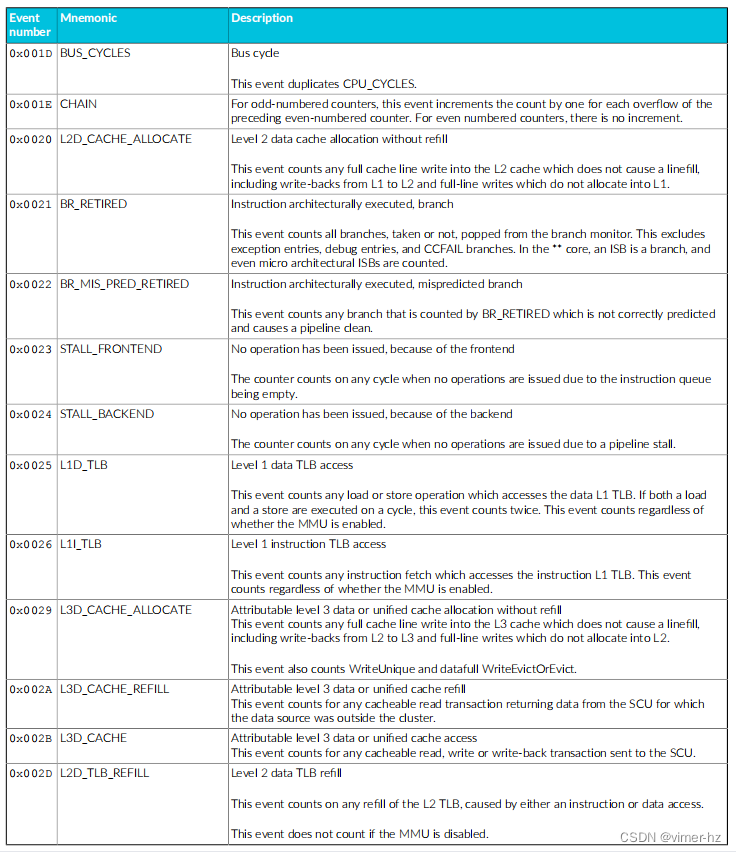
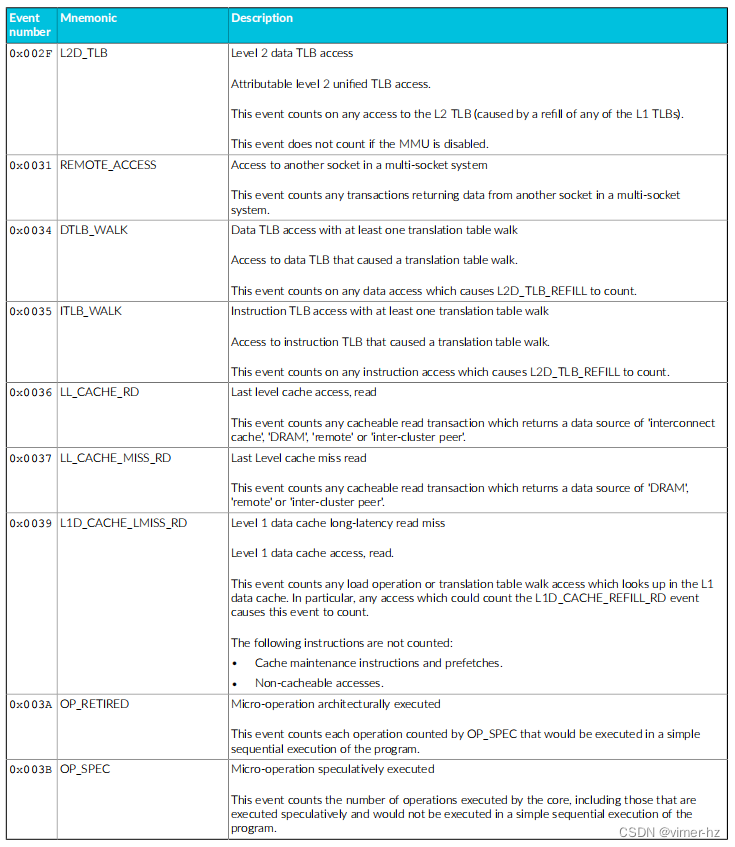
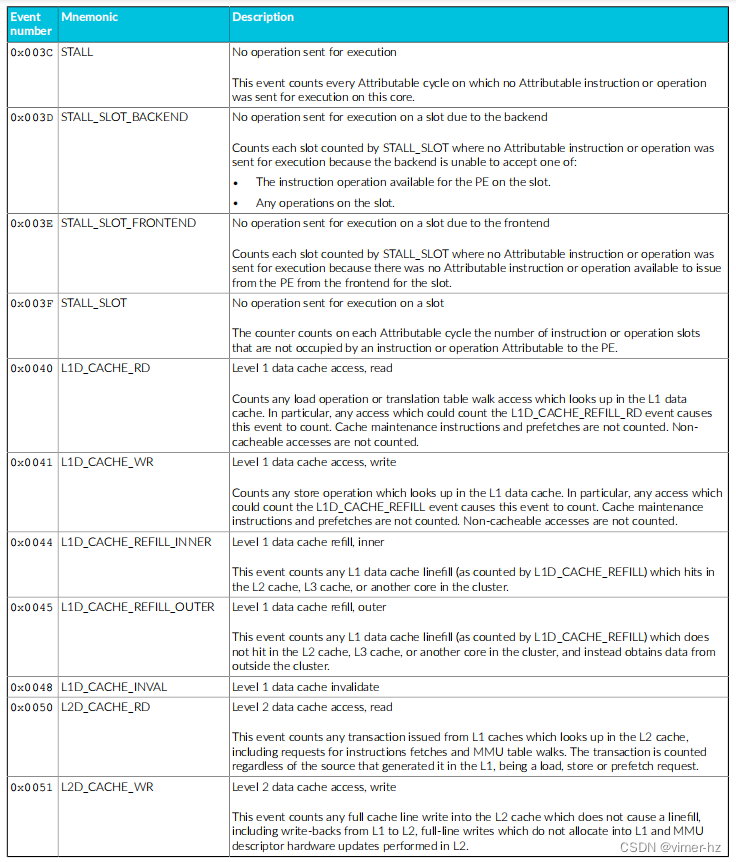
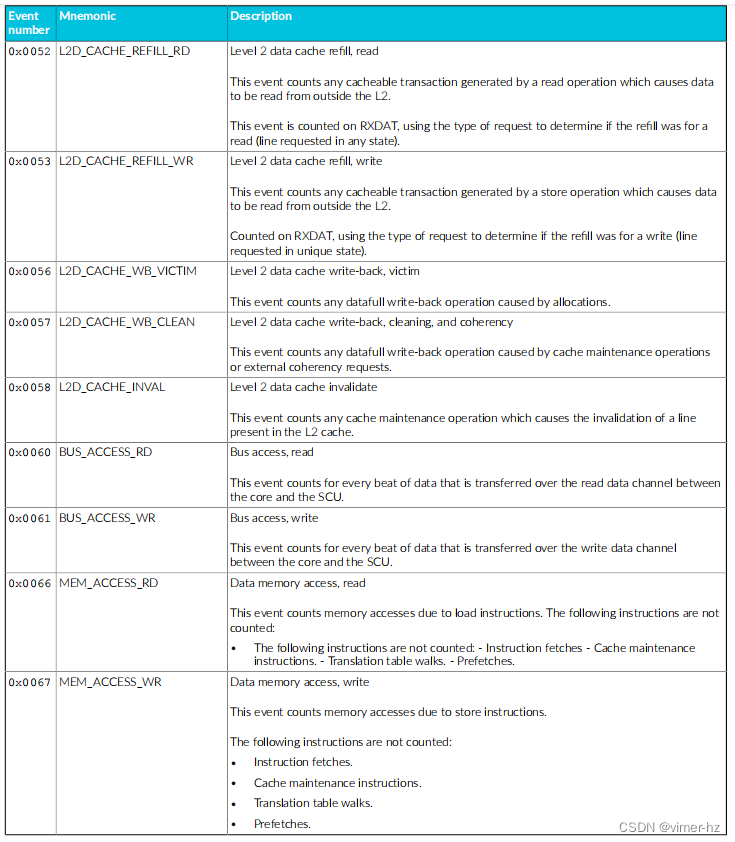
常见事件PMU事件 下表显示了Cortex®‑A715核心生成的性能监视器事件以及PMU用于引用这些事件的数字。表中还显示了每个事件在事件总线上的位位置。未列出的事件编号保留。 除非另有说明,否则这些事件中的每一个都可以导出到跟踪单元,并根据Arm®嵌入式跟踪扩展进行选择。

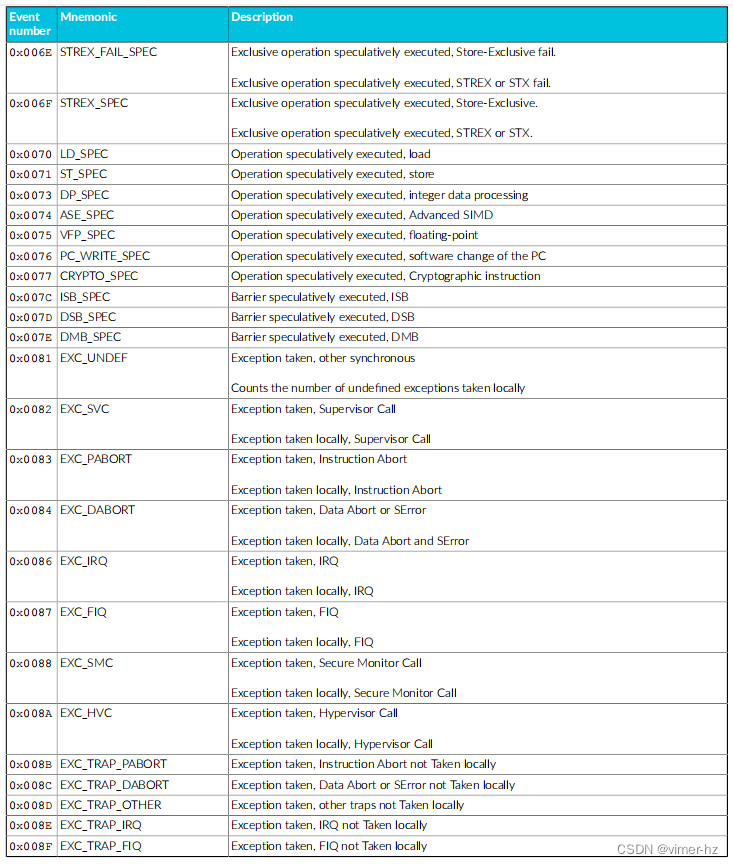
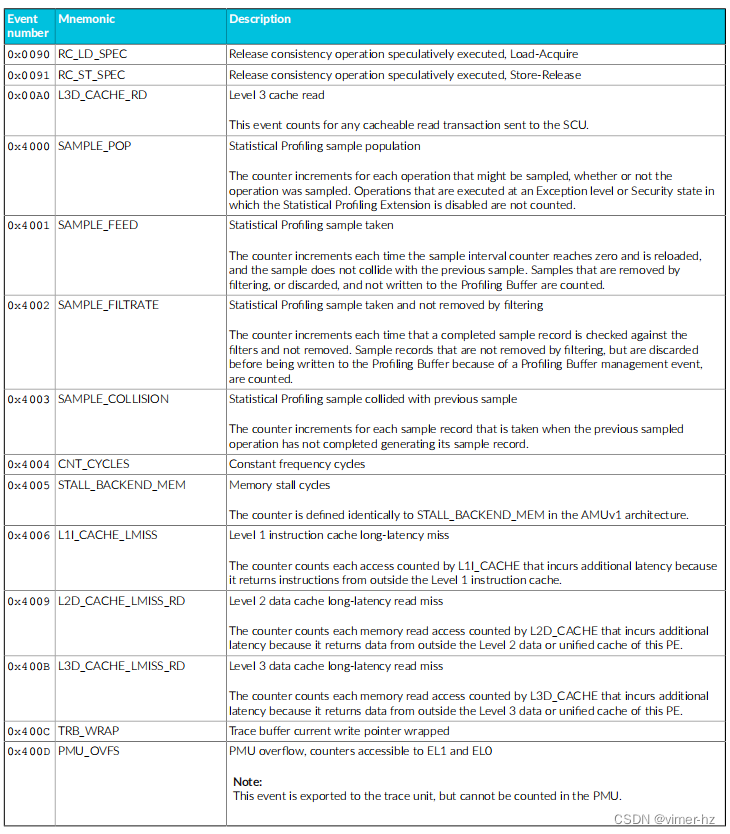
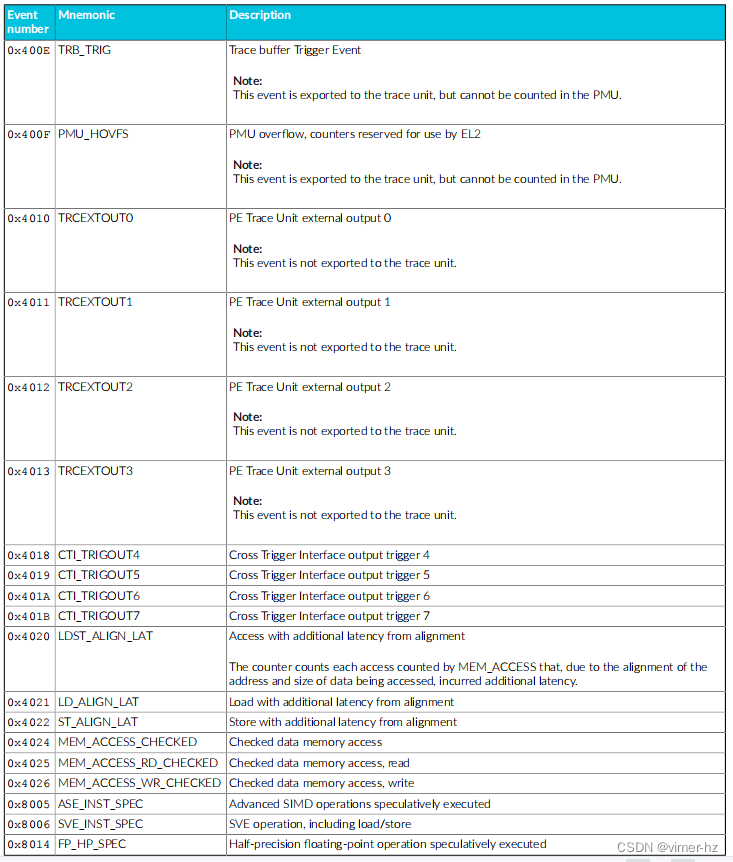
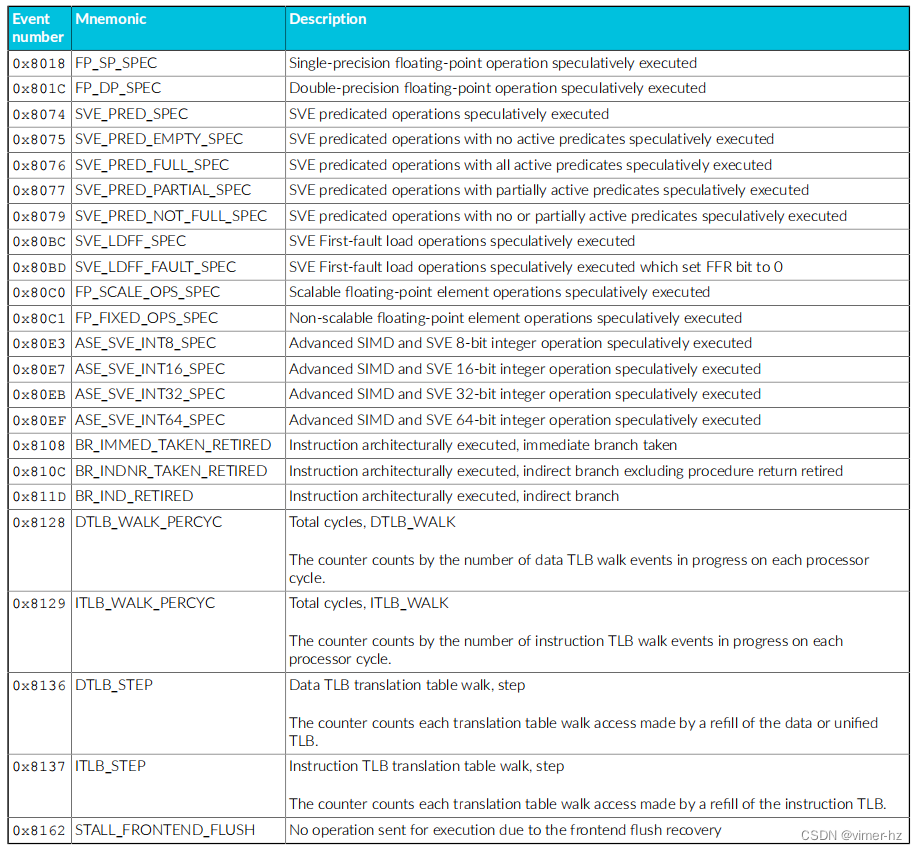
18.2 Performance monitors interrupts
性能监视单元(PMU)可以配置为在一个或多个计数器溢出时生成中断。
当PMU生成中断时,nPMUIRQ[n]输出将被拉低。
18.3 External register access permissions
Cortex®‑A715核心支持通过系统寄存器接口和内存映射接口访问性能监视单元(PMU)寄存器。
对寄存器的访问取决于:
- 核心是否已上电
- OS Lock的状态
- 外部性能监视器访问禁用的状态
对于每个寄存器,其行为是特定的,并且不在本手册中描述。有关这些特性及其对寄存器的影响的详细说明,请参阅Arm® A-profile架构的《Arm®体系结构参考手册》。本手册提供的寄存器描述中说明了每个寄存器是读/写还是只读。
18.4 AArch64 Performance Monitors registers
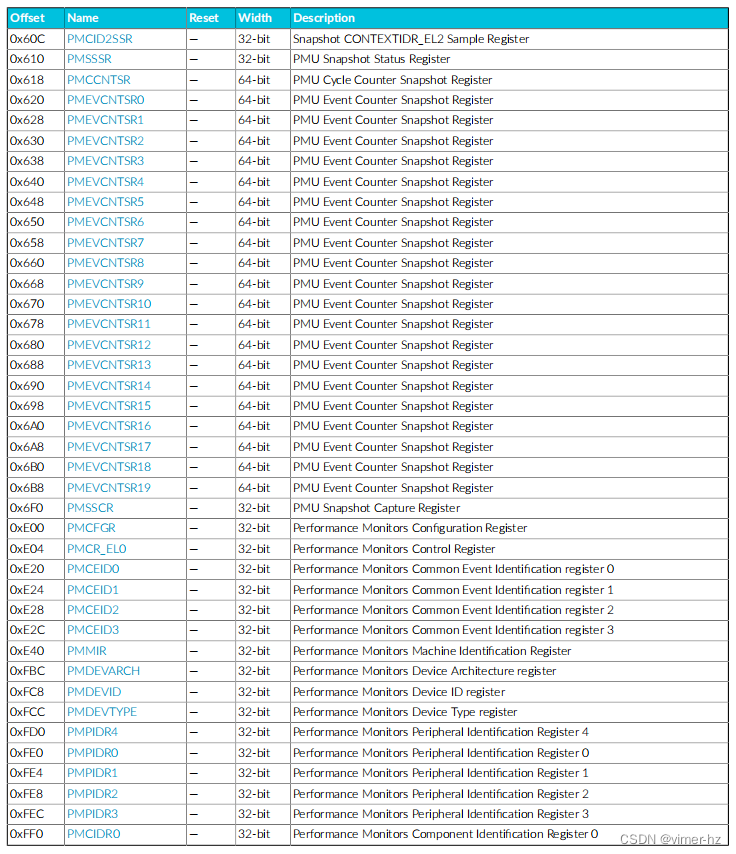
总结表提供了核心中IMPLEMENTATION DEFINED性能监视器寄存器的概述。有关寄存器的更多信息,请单击表中的寄存器名称。
对于没有列出重置值的寄存器,请参考寄存器描述页或《Arm ARM》中记录的各个字段重置值。

18.5 External PMU registers
总结表提供了核心中IMPLEMENTATION DEFINED的内存映射PMU寄存器的概述。有关寄存器的更多信息,请单击表中的寄存器名称。
对于没有列出重置值的寄存器,请参考寄存器描述页面或《Arm ARM》中记录的各个字段重置。


19. Embedded Trace Extension support
Cortex®‑A715核心实现了嵌入式跟踪扩展(ETE)。跟踪单元基于ETE执行实时指令流跟踪。跟踪单元是CoreSight组件的一部分,是Arm实时调试解决方案的重要组成部分。
下图显示了跟踪单元的主要组件:

核心接口
核心接口监视并生成P0元素,这些元素实质上是按程序顺序执行的分支和异常跟踪。
跟踪生成
跟踪生成逻辑根据P0元素生成各种跟踪数据包。
过滤和触发资源
您可以通过过滤来限制跟踪单元生成的跟踪数据量。例如,您可以将跟踪生成限制在某个地址范围内。跟踪单元支持其他逻辑分析器风格的过滤选项。跟踪单元还可以生成触发信号,用于指示跟踪捕获设备停止捕获跟踪数据。
FIFO(先进先出缓冲区)
跟踪单元以高度压缩的形式生成跟踪数据。先进先出(FIFO)缓冲区使得跟踪数据可以被平滑输出。当FIFO缓冲区已满时,会发出溢出信号。在FIFO缓冲区被清空之前,跟踪生成逻辑不会生成任何新的跟踪数据。这种行为在调试器中查看时会导致跟踪数据中的间断。
跟踪输出
跟踪数据从FIFO缓冲区输出到AMBA ATB接口或跟踪缓冲区。
有关更多信息,请参阅Arm® Architecture Reference Manual Supplement Armv9,适用于Armv9-A架构配置文件。
19.1 Trace unit resources
跟踪资源包括计数器、外部输入和输出信号以及比较器。
下表显示了跟踪单元的资源,并指示A715核心跟踪单元实现了哪些资源。

19.2 Trace unit generation options
Cortex®-A715核心跟踪单元实现了一组生成选项。
下表显示了跟踪生成选项,并指示Cortex®-A715核心跟踪单元实现了哪些选项。

19.3 Reset the trace unit
对于跟踪缓冲区的复位与核心的冷复位是相同的。当使用跟踪缓冲区扩展(TRBE)时,热复位会禁用跟踪缓冲区,因此无法使用跟踪缓冲区来捕获热复位的跟踪信息。
如果跟踪单元被复位,那么跟踪将停止直到重新编程和重新使能跟踪单元。
然而,如果使用热复位对核心进行复位,那么在复位之前由核心提供的最后几条指令可能无法被跟踪。
19.4 Program and read the trace unit registers
您可以使用Debug APB接口或系统寄存器接口来编程和读取跟踪单元寄存器。
在编程跟踪单元寄存器时,核心不必处于调试状态。当您编程跟踪单元寄存器时,必须同时启用所有更改。否则,如果您编程计数器,在正确设置触发条件之前,它可能开始基于不正确的事件计数。要禁用跟踪单元,请使用TRCPRGCTLR.EN位。有关以下寄存器的更多信息,请参阅Arm® Architecture Reference Manual Supplement Armv9,针对Armv9-A体系结构配置文件:
- Programming Control Register,TRCPRGCTLR
- Trace Status Register,TRCSTATR
以下图表显示了使用DebugBlock APB接口编程跟踪单元寄存器的流程:

以下图表显示了使用系统寄存器接口编程跟踪单元寄存器的流程:

19.5 Trace unit register interfaces
Cortex®‑A715核心支持一种APB内存映射接口和一种系统寄存器接口来访问跟踪单元寄存器。
根据跟踪单元的状态,寄存器访问方式有所不同。请参阅Arm® Architecture Reference Manual Supplement Armv9,关于Armv9-A体系结构配置文件中的行为和访问机制获取更多信息。
19.6 Interaction with the Performance Monitoring Unit and Debug
跟踪单元与性能监视单元(PMU)进行交互,并且可以访问PMU事件。
与PMU的交互:
Cortex®-A715核心包括一个PMU,可以在一段时间内计数缓存失效和执行指令等事件。
PMU和跟踪单元一起工作。
跟踪单元使用PMU事件:
通过扩展输入功能,PMU体系结构事件可供跟踪单元使用。
跟踪单元使用四个扩展外部输入选择器来访问PMU事件。每个选择器可以独立选择一个PMU事件,然后在相关事件发生的周期内激活。这些选定的事件可以由跟踪单元内的任何事件寄存器访问。
相关信息:
18. 第98页的性能监视器扩展支持
18.1. 第98页的性能监视器事件
19.7 ETE events
Cortex®‑A715核心的跟踪单元从设计中的其他单元收集事件,并使用数字来引用这些事件。
除了第98页上提到的性能监视器事件外,以下表格中列出的事件也被导出。由于我无法查看具体的表格内容,请您提供需要了解的事件列表,我将尽力提供相关信息。

19.8 AArch64 Trace unit registers
这个摘要表格提供了核心中的IMPLEMENTATION DEFINED跟踪寄存器的概述。
要获取有关寄存器的更多信息,请在表格中点击寄存器名称。
对于没有列出复位值的寄存器,请参考寄存器描述页面或Arm ARM中记录的各个字段复位值。


19.9 External ETE registers
这个摘要表格提供了核心中的IMPLEMENTATION DEFINED内存映射ETE寄存器的概述。
要获取有关寄存器的更多信息,请在表格中点击寄存器名称。
对于没有列出复位值的寄存器,请参考寄存器描述页面或Arm ARM中记录的各个字段复位值。


20. Trace Buffer Extension support
Cortex®‑A715核心实现了Trace Buffer Extension (TRBE)。TRBE将跟踪单元生成的程序流跟踪直接写入内存。TRBE通过系统寄存器进行编程。
当启用TRBE时,它可以:
• 接收跟踪单元的跟踪数据并将其写入L2内存。
• 丢弃来自跟踪单元的跟踪数据。在这种情况下,数据将会丢失。
• 拒绝来自跟踪单元的跟踪数据。在这种情况下,跟踪单元会保留数据,直到TRBE接受为止。
当禁用TRBE时,TRBE将忽略跟踪数据,跟踪单元将跟踪数据发送到AMBA® Trace Bus (ATB)接口。
20.1 Program and read the trace buffer registers
您可以使用系统寄存器接口来编程和读取Trace Buffer Extension (TRBE)寄存器。
在编程TRBE寄存器时,核心无需处于调试状态。当您编程TRBE寄存器时,必须同时启用所有更改。否则,如果您仅编程计数器,在正确设置触发条件之前,它可能根据错误的事件开始计数。要禁用TRBE,请使用TRBLIMITR_EL1.E位。
请参阅《Arm®架构参考手册补充Armv9,适用于Armv9-A架构配置文件》以获取有关TRBE寄存器行为和访问机制的信息。
20.2 Trace buffer register interface
Cortex®‑A715核心支持通过系统寄存器接口访问Trace Buffer Extension (TRBE)寄存器。
寄存器访问方式取决于TRBE的状态。请参阅《Arm®架构参考手册补充Armv9,适用于Armv9-A架构配置文件》以获取有关行为和访问机制的信息。
21. Activity Monitors Extension support
Cortex®‑A715核心在Arm®v8.4-A架构中实现了Activity Monitors扩展。活动监控具有类似于性能监控的功能,但用于系统管理,而性能监控则面向用户和调试应用程序。
活动监控提供了对系统功耗管理和持续监控的有用信息。活动监控在操作中为只读,并且其配置受限于已实现的最高异常级别。
Cortex®‑A715核心在两个组中实现了七个计数器,每个计数器都是一个64位计数器,用于计算固定事件。组0有四个计数器,编号为0-3,组1有三个计数器,编号为10-12。
21.1 Activity monitors access
Cortex®‑A715核心支持通过系统寄存器接口访问活动监控,并支持使用实用总线接口进行只读的内存映射访问。
要了解这些寄存器的内存映射信息,请参阅Arm® A-profile架构的《Arm®架构参考手册》。
访问使能位
访问使能位AMUSERENR_EL0.EN控制EL0对活动监控系统寄存器的访问。
CPTR_EL2.TAM位控制EL0和EL1对活动监控系统寄存器的访问。
CPTR_EL3.TAM位控制EL0、EL1和EL2对活动监控扩展系统寄存器的访问。AMUSERENR_EL0.EN位在EL1、EL2和EL3可配置。所有其他控制和计数器的值仅在最高实现的异常级别可配置。
有关寄存器访问控制的详细说明,请参阅Arm® A-profile架构的《Arm®架构参考手册》。
系统寄存器访问
可以使用MRS和MSR指令访问这些活动监控寄存器。
外部内存映射访问
可以从实用总线接口对活动监控进行内存映射访问。在这种情况下,活动监控寄存器仅对活动监控事件计数器寄存器提供读访问。
在DSU-110 DynamIQ™集群中,活动监控单元(AMU)寄存器在实用总线接口上的基地址为0x<n>90000,其中n是Cortex®‑A715核心实例号。
如果满足以下条件之一,则将这些寄存器视为RAZ/WI:
• 该寄存器标记为保留。
• 以错误的安全状态对寄存器进行访问。
21.2 Activity monitors counters
Cortex®‑A715核心实现了四个活动监控计数器,编号为0-3,以及三个辅助计数器,编号为10-12。
每个计数器具有以下特点:
• 所有事件都在64位的循环计数器中进行计数,在溢出时会重新计数。不支持溢出状态指示或中断。
• 任何时钟频率的变化,包括WFI和WFE指令停止时钟,都可能影响任何一个计数器。
• 事件0-3和辅助事件10-12是固定的,AMEVTYPER0<n>_EL0和AMEVTYPER1<n>_EL0的evtCount位是只读的。
• 在对核心的电源域进行冷复位时,活动监控计数器会被重置为零。当核心处于非复位状态时,可以进行活动监控。
21.3 Activity monitors events
Cortex®‑A715核心中的活动监控事件可以是固定的或可编程的,并且它们映射到活动监控计数器。 下表显示了计数器与固定事件的映射。


21.4 AArch64 Activity Monitors registers
摘要表格提供了核心中IMPLEMENTATION DEFINED的活动监控寄存器的概述。要获取有关寄存器的更多信息,请单击表格中的寄存器名称。
对于未列出复位值的寄存器,请参考寄存器描述页面或Arm ARM中记录的各个字段复位值的文档。
请注意,具体实现中的活动监控寄存器及其详细信息可能会有所不同。建议参考Arm提供的官方文档,以获取关于Cortex®-A715核心中活动监控寄存器的准确和最新信息。

21.5 External AMU registers
摘要表格提供了核心中IMPLEMENTATION DEFINED的内存映射AMU寄存器的概述。要获取有关寄存器的更多信息,请单击表格中的寄存器名称。
对于没有列出复位值的寄存器,请参考寄存器描述页面或Arm ARM中记录的各个字段复位值的文档。
请注意,具体实现中的内存映射AMU寄存器及其详细信息可能会有所不同。建议参考Arm提供的官方文档,以获取关于核心中内存映射AMU寄存器的准确和最新信息。

22. Statistical Profiling Extension Support
Cortex®-A715核心在Arm®v8.2-A架构中实现了可选的统计分析扩展(SPE)。SPE提供了对执行指令性能特征的统计视图,软件开发者可以利用这些信息来优化代码以获得更好的性能。
Cortex®-A715核心通过对微操作进行分析来最小化支持SPE所需的逻辑量。
下图展示了Cortex®-A715核心中SPE的行为特点。
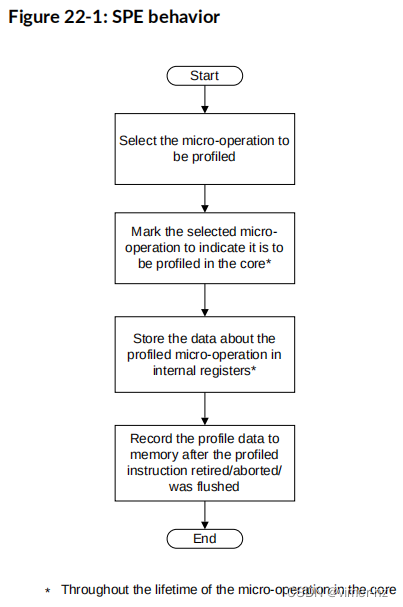
SPE收集性能分析数据是周期性进行的,一个倒计数器驱动着选择要进行分析的微操作。该倒计数器记录了派发的推测微操作的数量,并在每个微操作执行后递减一次。当倒计数器达到零时,就会将一个微操作标识为样本,并在其在核心中的整个生命周期中进行分析。
SPE的分析数据使用虚拟地址(VA)写入内存,这意味着进行分析数据的写入必须具备内存管理单元(MMU)来将虚拟地址转换为物理地址(PA),并且必须有一种方式来将数据写入内存。
预计进行性能分析对核心性能的影响较小。在进行性能分析时,核心的性能不会受到实质性的干扰。
发生频率取决于采样率。您可以指定一个对核心性能有实质性干扰的采样率。Arm建议最小采样间隔为每1024个微操作一次。这个值通过PMSIDR_EL1.Interval的位[11:8]向软件进行传递。
更多信息,请参考《Arm® Architecture Reference Manual for A-profile architecture》。
22.1 Statistical Profiling Extension events packet
事件数据包指示采样操作生成的实现定义事件。 下表显示了在Cortex®-A715核心中实现的32位事件数据包中定义的事件。

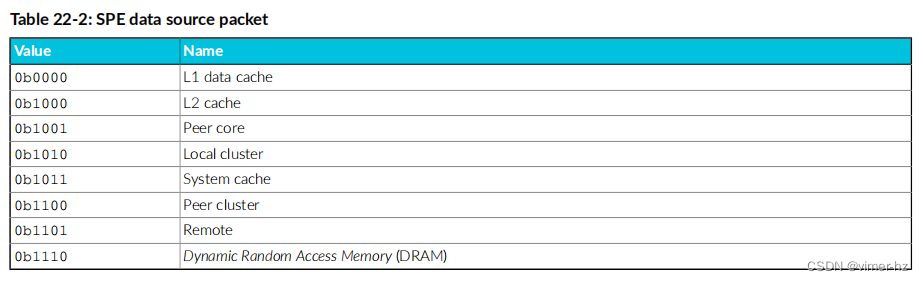
22.2 Statistical Profiling Extension data source packet
数据源数据包指示加载或存储操作返回的数据来自哪里。 下表显示了在Cortex®-A715核心中实现的8位数据源数据包中定义的数据源。