K-Means算法详细解析:从原理到实践
前言
K-Means 是一种非常经典、常用的 聚类算法。它属于无监督学习范畴,广泛应用于图像压缩、市场细分、社交网络分析、用户画像等场景。本文将由浅入深逐带你逐步全面了解 K-Means这个算法的原理到底是什么。
聚类介绍
**聚类(Clustering)**是将数据按“相似性”划分为若干组的过程,每组称为一个“簇(Cluster)”。
- 输入:一堆没有标签的数据点。
- 输出:这些点被划分为 K 组,每组内点相似、组与组之间差异大。
可以这么理解:老师把学生按身高或成绩分成不同的小组。
K-Means 介绍
K-Means 是一种“划分式聚类算法”。它的目标是:将数据划分成 K 个簇,使得同簇样本尽可能相似,不同簇样本尽可能不同。
每个簇用一个“质心(Centroid)”表示,质心就是这组数据的平均点。
K-Means 算法流程
K-Means 的算法流程很简单,说白了就是搞一个分组游戏,比如下数据划分。
输入:
- 数据集 X = { x 1 , x 2 , … , x n } X = \{x_1, x_2, \ldots, x_n\} X={x1,x2,…,xn}
- 要分成的簇数 K
步骤:
- 初始化 K 个中心点(质心):随机选 K 个样本点作为初始质心。
- 分配步骤(Assignment step):将每个样本分配给最近的质心。
- 更新步骤(Update step):对每个簇,计算其所有成员的平均值作为新的质心。
- 迭代执行步骤 2 和 3,直到质心不再变化或达到最大迭代次数。
目标函数:
K-Means 实际上在最小化所有点到其所属簇中心的欧几里得距离平方之和,即:
J = ∑ i = 1 K ∑ x ∈ C i ∥ x − μ i ∥ 2 J = \sum_{i=1}^{K} \sum_{x \in C_i} \| x - \mu_i \|^2 J=i=1∑Kx∈Ci∑∥x−μi∥2
其中 C i C_i Ci 是第 i 个簇, μ i \mu_i μi 是该簇的质心。
数学原理理解
选“质心”
因为根据数学推导,一组点到某个点的欧几里得平方距离和最小值,就是所有点的平均值。这也解释了为什么质心更新为“平均值”。
能收敛
K-Means 迭代过程中,每一步都在减少目标函数 J J J 的值,且 K 种分法有限,所以必定收敛(虽然可能收敛到局部最优)。
K 的选取问题
K 是一个超参数,用户需要手动指定。
常见选法:
肘部法(Elbow Method):
- 计算不同 K 值下的总误差平方和 SSE(Sum of Squared Errors)。
- 绘制 K vs SSE 曲线,找到“SSE下降明显变缓”的“肘部”,这个点对应的 K 就是最优值。
这么做,画一张图,横轴是 K 值,纵轴是聚类误差(SSE)。
-
K 小的时候,增加 K 会显著降低误差;
-
当 K 增大到一定值时,误差下降幅度变小;
-
那个“下降开始变缓的转折点”就像人的“手肘”——就是最优 K!
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobsX, _ = make_blobs(n_samples=500, centers=5, random_state=42)sse = []
K_range = range(1, 10)
for k in K_range:kmeans = KMeans(n_clusters=k, random_state=42)kmeans.fit(X)sse.append(kmeans.inertia_) # inertia_ 就是 SSEplt.plot(K_range, sse, marker='o')
plt.xlabel("K")
plt.ylabel("SSE")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("肘部法选择最佳K")
plt.show()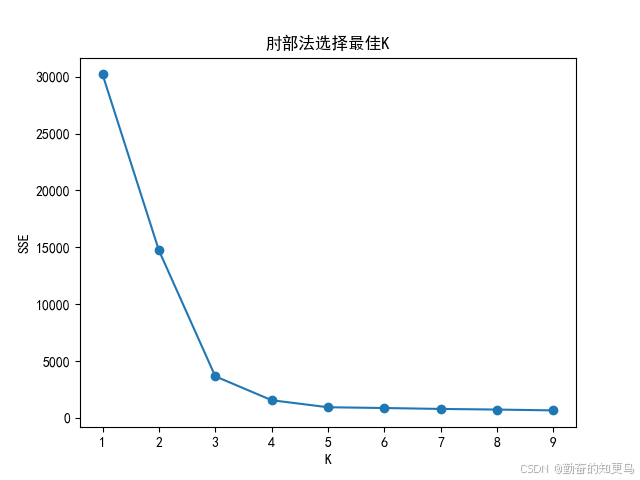
轮廓系数(Silhouette Coefficient):
衡量样本在簇内的紧密程度与簇间的分离度,值越高越好。

from sklearn.metrics import silhouette_scorescores = []
for k in range(2, 10):kmeans = KMeans(n_clusters=k, random_state=42)labels = kmeans.fit_predict(X)score = silhouette_score(X, labels)scores.append(score)plt.plot(range(2, 10), scores, marker='o')
plt.xlabel("K")
plt.ylabel("轮廓系数")
plt.title("用轮廓系数选最佳K")
plt.show()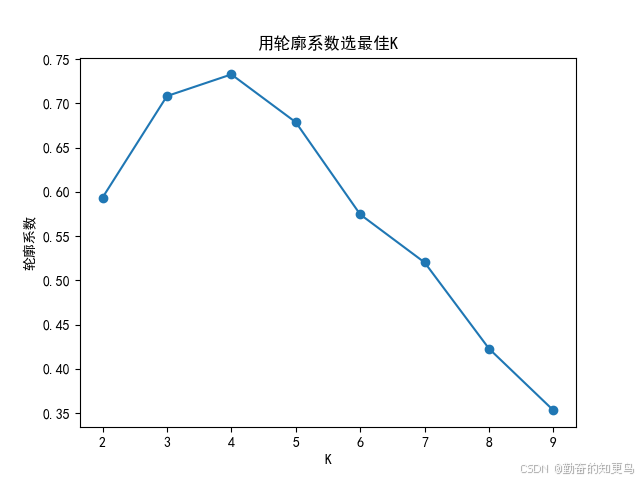
K-Means 的优缺点
优点:
- 算法简单高效,易实现
- 聚类结果容易理解
- 速度快,适合大规模数据
缺点:
- 必须预先指定 K
- 对初始质心敏感,可能陷入局部最优
- 不能处理非球形或不同大小密度的簇
- 对异常值敏感
K-Means示例代码
我们用 sklearn 快速实现 K-Means 聚类:
import matplotlib.pyplot as plt
from matplotlib import font_manager
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs# 生成模拟数据
X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=1, random_state=42)
font = font_manager.FontProperties(fname='C:/Windows/Fonts/simfang.ttf')
# 可视化数据
plt.scatter(X[:, 0], X[:, 1], s=30)
plt.title("原始数据分布", fontproperties=font)
plt.show()# KMeans 聚类
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
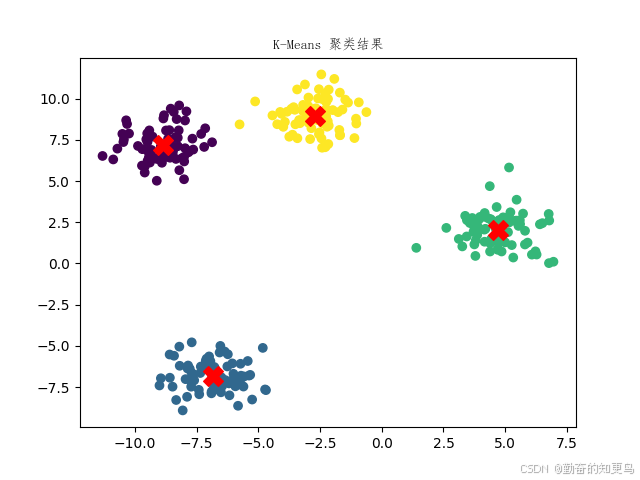
y_kmeans = kmeans.predict(X)# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],s=200, c='red', marker='X')
plt.title("K-Means 聚类结果", fontproperties=font)
plt.show()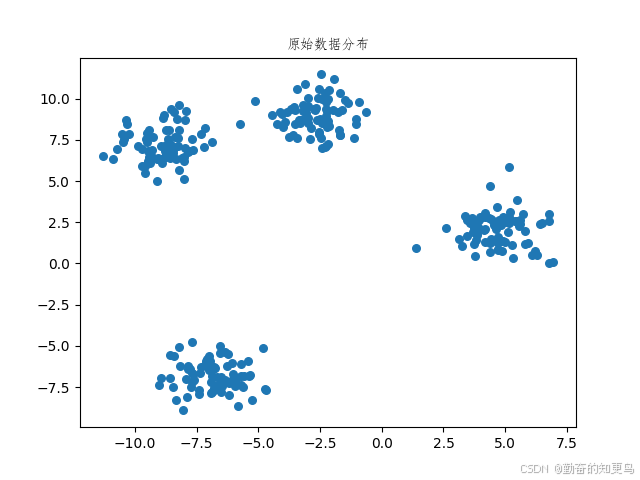
常见变体与扩展
- K-Means++:改进初始质心选择,避免陷入局部最优
- Mini-Batch K-Means:使用小批量数据进行迭代,适合大数据
- Bisecting K-Means:层次化地进行 KMeans 聚类
- Spectral Clustering:结合图论和 KMeans 的方法
总结
K-Means 是一把“快速有效”的聚类工具,理解了它的原理之后,可以灵活用于很多任务中。记得注意:
- K 的选择很关键;
- 适合球形簇、相似大小的簇;
- 可结合其他方法(如 PCA)进行降维预处理;
- 可与其他算法(如 DBSCAN、GMM)互补使用。