庙算兵棋推演AI开发初探(8-神经网络模型接智能体进行游戏)
前言の碎碎念
由于我做的模仿学习,可能由于没有完全模仿,可以说效果很烂……后来用强化学习优化,这个倒是不用自己做数据集了,为方便大家只搞代码,这里只说这部分的经历和方法。
实践基础介绍
1-动作
先介绍一个强化学习中的“行为空间”的概念。

玩过游戏机的都知道,游戏按键就那几个,顶多加上组合,所以你玩游戏可以操作的空间组合就那么大,你与游戏世界连接的输入方式只有这几个按钮。
比如坦克大战,你操纵的坦克只能上下左右和攻击,那你只能在这几个里进行操作,就好比你的手柄,你不能做出手柄按钮以外的操作来作为游戏的输入。
很自然的,智能体能做的只有行为空间中的行为,如果根据概率来选择行为来行动,是很自然的一种方式。
2-状态
我们玩游戏还得看游戏画面才能采取下一个决策,这就是反馈给智能体的状态。在实际工程中,需要将状态中的各种要素摘取出来(比如坦克大战,需要知道敌人的位置,自己的位置,哪里有墙,其他的信息就无所谓了)。
3-奖惩
我们打游戏,如果失误掉血了,肯定以后就会尽量避免这个操作;如果试出来的组合绝招管用,那以后肯定要记下来好好利用。这就是奖励和惩罚。衡量该奖还是惩罚的函数就叫奖励函数。
4-智能体
就类比成玩游戏的人,不同人玩游戏的技术进步也不一样,这就涉及到神经网络设计,或者简单的函数套路策略。
5-环境
游戏本身,毕竟玩坦克大战的经验在玩宝可梦的时候用不上,所以环境是根本。
范式
环境初始化:定义游戏规则和状态表示。
智能体设计:选择合适的算法(如 DQN),设计要被优化的目标神经网络。
训练循环:
初始化环境,获取初始状态。
选择动作(epsilon-greedy策略)。
执行动作,获取新的状态、奖励和是否终止。
存储经验到回放缓存。
从回放缓存中采样一批数据,更新目标网络参数。
更新目标网络(每隔一定频率步)。
保存模型(每隔一定局数,因为一局的奖励不平均,所以以几局为单位)。
评估:定期评估智能体的性能,记录关键指标。(每隔一定轮数评估智能体,评估时禁止对目标网络的改动,输出模型得到的动作,然后评估)
原理的简要介绍
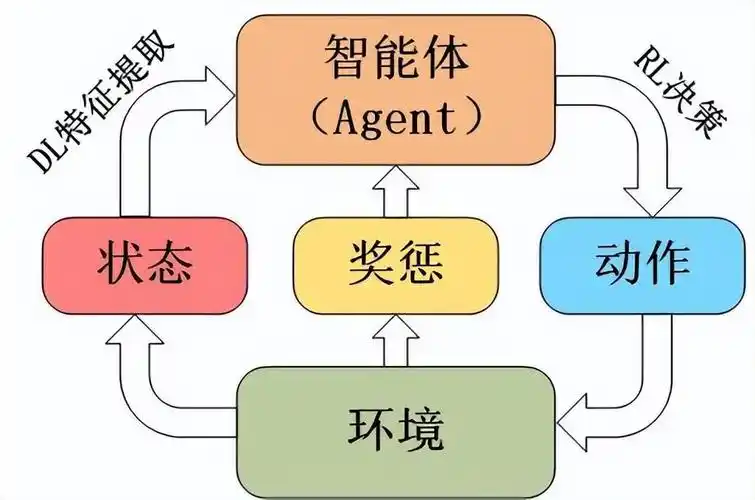
1. 强化学习的基本概念
智能体(Agent):学习者和决策者,负责根据当前状态选择动作。
环境(Environment):智能体所处的外部世界,接收智能体的动作并返回新的状态和奖励。
状态(State):环境的当前状况,描述了智能体所处的环境信息。
动作(Action):智能体在某个状态下可以采取的行为。
奖励(Reward):环境对智能体动作的反馈,通常是一个标量值,用于衡量动作的好坏。
策略(Policy):智能体的行为规则,决定了在给定状态下选择哪个动作。
价值函数(Value Function):衡量某个状态或动作的价值,通常用 V(s) 或 Q(s,a) 表示。
回报(Return):从某个时间步开始到结束的所有奖励的累积和,通常用 Gt 表示。
2. 马尔科夫决策过程(Markov Decision Process, MDP)
强化学习的核心是马尔科夫决策过程,它是一个数学框架,用于描述智能体与环境的交互过程。
马尔科夫性(Markov Property):当前状态包含了所有历史信息,即未来的状态只依赖于当前状态,而与之前的状态无关。
P(st+1∣st)=P(st+1∣st,st−1,…,s1)MDP 的组成:
状态集合 S
动作集合 A
转移概率 P(s′∣s,a):在状态 s 下采取动作 a 转移到状态 s′ 的概率。
奖励函数 R(s,a,s′):在状态 s 下采取动作 a 转移到状态 s′ 时获得的奖励。
3. 贝尔曼方程(Bellman Equation)
贝尔曼方程是强化学习中的核心方程,用于递归地定义价值函数。
贝尔曼期望方程(Bellman Expectation Equation):
V(s)=a∈A∑π(a∣s)[R(s,a)+γs′∈S∑P(s′∣s,a)V(s′)]Q(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)a′∈A∑π(a′∣s′)Q(s′,a′)其中,π(a∣s) 是策略,γ 是折扣因子(0≤γ<1)。
贝尔曼最优方程(Bellman Optimality Equation):
V∗(s)=a∈Amax[R(s,a)+γs′∈S∑P(s′∣s,a)V∗(s′)]Q∗(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)a′∈AmaxQ∗(s′,a′)这些方程用于定义最优价值函数和最优策略。
4. 价值函数与策略
价值函数(Value Function):
状态价值函数 V(s):在策略 π 下,从状态 s 开始的期望回报。
动作价值函数 Q(s,a):在策略 π 下,从状态 s 开始并采取动作 a 的期望回报。
策略(Policy):
确定性策略:在每个状态下选择一个固定的动作。
随机性策略:在每个状态下根据概率分布选择动作。
5. 策略迭代与价值迭代
策略迭代(Policy Iteration):
策略评估(Policy Evaluation):计算当前策略的价值函数。
策略改进(Policy Improvement):根据价值函数更新策略。
交替进行策略评估和策略改进,直到策略收敛。
价值迭代(Value Iteration):
直接求解贝尔曼最优方程,更新价值函数,直到收敛。
从初始价值函数开始,逐步逼近最优价值函数。
6. 探索与利用(Exploration vs. Exploitation)
探索(Exploration):尝试新的动作以获取更多信息。
利用(Exploitation):使用当前已知的最佳动作以获取最大回报。
平衡方法:
ϵ-贪心策略:以概率 ϵ 随机选择动作,以概率 1−ϵ 选择当前最优动作。
软最大化策略(Softmax Policy):根据动作的价值以概率分布选择动作。
7. 深度强化学习(Deep Reinforcement Learning)
将深度学习与强化学习结合,使用神经网络来近似价值函数或策略函数。
DQN(Deep Q-Network):
使用神经网络近似 Q(s,a)。
引入经验回放缓存(Experience Replay)和目标网络(Target Network)以提高训练稳定性。
PPO(Proximal Policy Optimization):
基于策略梯度的方法,通过截断概率比来限制策略更新的幅度,提高训练的稳定性和效率。
8. 必须补充的基础
概率论与数理统计:理解随机过程、概率分布、期望值等概念。
线性代数:掌握向量、矩阵运算,用于表示状态和动作。
动态规划:理解贝尔曼方程和策略迭代、价值迭代等概念。
神经网络:了解神经网络的基本结构和训练方法,用于近似价值函数或策略函数。
优化算法:掌握梯度下降、Adam 等优化算法,用于更新网络参数。
总结
强化学习通过智能体与环境的交互来学习最优策略。其核心包括马尔科夫决策过程、贝尔曼方程、价值函数、策略迭代和价值迭代等。深度强化学习结合了深度学习技术,进一步提升了强化学习的性能。理解这些基础知识是掌握强化学习的关键。
最后,代码。
由于大家没有数据集和模仿学习的部分的神经网络,这里放一个基本的梯度下降来优化目标网络的强化学习的样例代码,需要装一些包。
这部分由于设计的依赖比较多,都放出来放不下,这部分只做参考
1-环境准备
def init_wargame(redAgent , blueAgent):"""run demo in single agent mode"""print("running in single agent mode...")# instantiate agents and envred1 = redAgent #MyAgent1()#自己的agent,因为样本数据都来自红方blue1 = blueAgentenv1 = TrainEnv()begin = time.time()# get data ready, data can from files, web, or any other sourceswith open(gopt.scenpath+"201033029601.json", encoding='utf8') as f:scenario_data = json.load(f)with open(gopt.mappath+"basic.json", encoding='utf8') as f:basic_data = json.load(f)with open(gopt.mappath+"cost.pickle", 'rb') as file:cost_data = pickle.load(file)see_data = numpy.load(gopt.mappath+"see.npz")['data']# varialbe to build replayall_states = []# player setup infoplayer_info = [{"seat": 1,"faction": 0,"role": 1,"user_name": myAgentname,"user_id": 0},{"seat": 11,"faction": 1,"role": 1,"user_name": "demo","user_id": 0}]# env setup infoenv_step_info = {"scenario_data": scenario_data,"basic_data": basic_data,"cost_data": cost_data,"see_data": see_data,"player_info": player_info}# setup env - 初始化环境并获取指针state = env1.setup(env_step_info)import copyall_states.append(copy.deepcopy(state[GREEN]))#初始帧print("Environment is ready.")# setup AIs - 注册AI信息red1.setup({"scenario": scenario_data,"basic_data": basic_data,"cost_data": cost_data,"see_data": see_data,"seat": 1,"faction": 0,"role": 0,"user_name": myAgentname,"user_id": 0,"state": state,})blue1.setup({"scenario": scenario_data,"basic_data": basic_data,"cost_data": cost_data,"see_data": see_data,"seat": 11,"faction": 1,"role": 0,"user_name": "demo","user_id": 0,"state": state,})print("agents are ready.")return red1, blue1, env1, state, all_states, begin2-训练脚本
def train():"""智能体-主训练函数"""# 初始化环境和智能体# 日志记录writer = create_writer(LOG_DIR)# TensorBoardbest_reward = -float('inf')for episode in tqdm(range(EPOCH), desc="Training Episodes"):print(f"Episode {episode + 1}/{EPOCH} started...")red1, blue1, env1, state, all_states, begin = init_wargame(MyAgent56(), Agent())rewards = []losses = []# ====训练阶段episode_reward = 0episode_loss = 0step = 0# loop until the end of gameprint("steping")done = False#传入actions-处理step-记录all_states循环while not done :actions = []actions += red1.step(state[RED])actions += blue1.step(state[BLUE])state, done = env1.step(actions) #更新环境状态print("step_", state[-1]["time"]["cur_step"])print("stage", state[-1]["time"]["stage"])all_states.append(copy.deepcopy(state[GREEN]))#原因可能是 state 和 all_states 中的元素共享相同的引用# # 方便验证-cq20250421# if state[-1]["time"]["cur_step"] >= 29:# breakepisode_reward += red1.trainer.outrewardepisode_loss += red1.trainer.outlossstep += 1if done:break# 一局结束了,如果你的任务是分局进行的(例如,一局有1800帧step记录了),并且每局的奖励是独立计算的,那么每局结束后保存一次模型是一个合理的选择。# 记录训练指标rewards.append(episode_reward)losses.append(episode_loss / (step + 1))writer.add_scalar("Train/Reward", episode_reward, episode)writer.add_scalar("Train/Loss", episode_loss / (step + 1), episode)mean_eval_reward = np.mean(rewards)writer.add_scalar("Eval/Reward", mean_eval_reward , episode)# 保存模型的策略if episode_reward > best_reward:best_reward = episode_rewardred1.trainer.save(gopt.modelpath+'best_rl_model.pth') # 保存最佳模型print(f"回合:{episode}/{EPOCH},奖励:{episode_reward:.2f}, \评估奖励:{mean_eval_reward:.2f},最佳评估奖励:{best_reward:.2f}")# if episode % save_interval == 0:# agent.save_model(f'model_episode_{episode}.pth') # 定期保存# 探索率衰减red1.trainer.epsilon = max(red1.trainer.epsilon * 0.995, red1.trainer.epsilon_min)# # ====评估阶段,每5局评估一次# if episode % 5 == 0:# # 在训练过程中定期冻结策略(暂停梯度更新),让智能体在固定环境中运行多个回合,计算平均奖励以衡量当前策略的优劣。# # 保存最佳模型# if mean_eval_reward > best_reward:# best_reward = mean_eval_reward# save_model_lite(red1.trainer.policy_net, f"{gopt.rlmodelsavepath}best_model.pth")# print(f"回合:{episode}/{1800},奖励:{episode_reward:.2f}, \# 评估奖励:{mean_eval_reward:.2f},最佳评估奖励:{best_reward:.2f}")print(f"Total time: {time.time() - begin:.3f}s")begin_formatted = time.strftime("%Y%m%d%H%M%S", time.localtime(begin)) #年月日时分秒的字符串# 旧的连续方式zip_name = gopt.logdir+"replays/"+f"replay_{begin_formatted}_old.zip"with zipfile.ZipFile(zip_name, 'w', zipfile.ZIP_DEFLATED, compresslevel=9) as z:z.writestr(f"replay_{begin_formatted}.json", json.dumps(all_states, ensure_ascii=False, indent=None, separators=(',', ':')).encode('gbk'))print(f"Replay saved to {zip_name}")# 添加资源释放# env1.reset()# red1.reset()# blue1.reset()del red1, blue1, env1, state, all_statesif torch.cuda.is_available():torch.cuda.empty_cache()# 训练结束writer.close()print(f"Training completed. Best eval reward: {best_reward:.2f}")3-强化学习部分(优化的目标网络是self.policy_net)
def get_pred(policy_net ,obs_tensor: torch.Tensor) -> List[int]:"""预测动作的函数"""# 这里可以直接调用模型进行预测# 假设模型输出的是一个概率分布with torch.no_grad():probs = policy_net(obs_tensor) # 输出概率分布[1, 3, 8]# 在最后一个维度上取【概率最大】的类别索引max_indices = torch.argmax(probs, dim=-1) # 结果形状为 [1, 3]# 如果需要去掉第一个维度(batch 维度),可以使用 squeezemax_indices = max_indices.squeeze(0) # 结果形状为 [3]# 将 max_indices 转换为整数列表actionLists = max_indices.tolist()return actionLists# ====可插拔强化学习类
class RLTrainer:def __init__(self, policy_net: nn.Module, lr: float = 1e-3):# 加载模仿学习的预训练模型self.policy_net = policy_netself.target_update_freq = 20 # 目标网络更新频率(TARGET_UPDATE)# self.batch_size = 32 # 训练批量大小(BATCH_SIZE)self.epsilon_min = 0.1 # 最小探索率self.epsilon = 0.1 # 探索率self.gamma=0.99 # 折扣因子self.step_counter = 0 # 全局步数计数器,用于调试和监控训练进度self.optimizer = optim.Adam(self.policy_net.parameters(), lr=lr)self.memory = [] # 简单 bufferself.outreward = 0 # 初始化输出奖励(对外可获取)self.outloss = 0 # 初始化输出损失(对外可获取)def select_action(self, obs_tensor: torch.Tensor) -> int:actions = get_pred(self.policy_net, obs_tensor)return actionsdef store_transition(self, obs, action, reward, next_obs): if len(self.memory) >= BUFFERSIZE:self.memory.pop(0) # 移除最旧的经验self.memory.append((obs, action, reward, next_obs))def loss_fn(self, obs_batch_dict, next_obs_batch_dict, action_batch, reward_batch):# 计算损失函数的示例# 这里可以使用 PPO 或其他算法的损失函数# 这里只是一个简单的示例# 将输入数据移动到模型所在的设备# device = next(self.policy_net.parameters()).device # 获取模型所在的设备action_batch.to(device) # 将 action_batch 移动到同一设备reward_batch = reward_batch.to(device) # 将 reward_batch 移动到同一设备i = 'PolicyGradient'if i == 'PolicyGradient':# 策略梯度 log_probs = torch.log(self.policy_net(obs_batch_dict))log_probs = log_probs.squeeze(0) # 去掉第 0 维,形状变为 (3, 8)action_batch = action_batch.squeeze(0) # 去掉第 0 维,形状变为 (3,)selected_log_probs = log_probs[range(len(action_batch)), action_batch]loss = -torch.mean(selected_log_probs * reward_batch) # 计算策略梯度损失elif i == "DQN":if next_obs_batch_dict is None:raise ValueError("next_obs_batch_dict must be provided for DQN loss calculation")# 假设有 Q 网络 q_net 和目标 Q 网络 target_q_net if not hasattr(self, 'q_net'): # 首次调用时初始化self.q_net = Noneq_values = self.q_net(obs_batch_dict)next_q_values = self.target_q_net(next_obs_batch_dict).max(dim=1)[0].detach()target_q_values = reward_batch + self.gamma * next_q_valuesloss = torch.mean((q_values[range(len(action_batch)), action_batch] - target_q_values) ** 2)else:raise ValueError("Unsupported loss function type")return lossdef train_step(self ):# 经验回放训练if not self.memory:return# 简单策略梯度损失示意(可替换成 PPO)obs_batch, action_batch, reward_batch, _ = zip(*self.memory) # `zip` 函数:将多个可迭代对象的对应元素打包成元组。` 操作符*:将列表解包为独立的参数(即拆开 `self.memory` 的外层列表)。# 将 obs_batch经过memory后会变成元组,tmd还得转回来 -cq20250522obs_batch_temp = obs_batch[-1]obs_batch_dict = {"game_stats": obs_batch_temp["game_stats"],"bop_features": obs_batch_temp["bop_features"],"spatial_features": obs_batch_temp["spatial_features"],"bop_embeddings": obs_batch_temp["bop_embeddings"]}if len(self.memory) >= 20: # 使用len()获取列表长度 obs_batch_temp = obs_batch[-20]else:obs_batch_temp = obs_batch[-1] # 如果只有一条记录,使用最后一条记录next_obs_batch_dict = {"game_stats": obs_batch_temp["game_stats"],"bop_features": obs_batch_temp["bop_features"],"spatial_features": obs_batch_temp["spatial_features"],"bop_embeddings": obs_batch_temp["bop_embeddings"]}action_batch = torch.tensor(action_batch)reward_batch = torch.tensor(reward_batch, dtype=torch.float32)# 构建loss --可替换的策略优化器(PPO, A2C, BCQ, DQN)loss = self.loss_fn(obs_batch_dict, next_obs_batch_dict, action_batch, reward_batch)# 更新参数self.optimizer.zero_grad()loss.backward()self.optimizer.step()self.memory.clear()# 监控训练进度self.step_counter += 1if self.step_counter % 100 == 0: # 每100步打印一次损失,保存一次网络模型print(f"Step: {self.step_counter}, Loss: {loss.item()}")# # 定期更新目标网络# if self.count % self.target_update_freq == 0:# self.policy_net.load_state_dict(self.policy_net.state_dict())# 监控与保存import ossvaepath = RL_MODEL_PATH + f"_{current_date}/"if not os.path.exists(svaepath):os.makedirs(svaepath)self.save(svaepath + f"trainer_step_{self.step_counter}.pth") # 保存模型4-智能体网络设计 (比较复杂,考虑了各种信息作为了向量输入)
这部分我没全放出来,需要大家自己设计
而且这部分要搭配数据向量化处理的代码,神经网络的形状也要考虑,十分繁琐……
class troopsNNv2(nn.Module):def __init__(self, game_stat_dim=12,bop_feat_dim=43,enemy_num=3,ally_num=3,spatial_channels=6, # 适配精简版空间通道数:enemy(3) + exposure(1) + see(1) + fire(1)output_dim=8,use_opponent_modeling=False):super(troopsNNv2, self).__init__()self.ally_num = ally_num# 游戏状态信息(全局统计)self.mlp_game = nn.Linear(game_stat_dim, 32)# 单位特征处理self.unit_fc = nn.Linear(bop_feat_dim, 128)self.unit_gru = nn.GRU(input_size=128, hidden_size=128, batch_first=True)......................................# 最终动作预测头(7方向 + 停止 = 8个动作)self.policy_head = nn.Sequential(nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, output_dim))def forward(self, inputs):# print(type(inputs)) # 打印类型# 将输入张量移动到设备device = torch.device(DEVICE)game_stats = inputs['game_stats'].to(device)bop_features = inputs['bop_features'].to(device)spatial_features = inputs['spatial_features'].to(device)bop_embeddings = inputs['bop_embeddings'].to(device)# 对敌的张量没有t步的事情,所以不用进入下面的循环enemy_strategy = inputs['enemy_strategy'].to(device) if self.is_using_opponent else torch.empty(0, dtype=torch.float32, device=device)bop_enemy_embeddings = inputs['bop_enemy_embeddings'].to(device) if self.is_using_opponent else torch.empty(0, dtype=torch.float32, device=device)batch_size, seq_len = game_stats.shape[:2]outputs = []for t in range(seq_len):# 当前帧特征提取g = game_stats[:, t].float()bop = bop_features[:, t].float()spatial = spatial_features[:, t].float() # shape (B, 6, 13, 23)embeddings = bop_embeddings[:, t].float() # shape (B, 3, 13, 23)f_game = self.mlp_game(g) # (B, 32)# 单位特征编码bop_embed = self.unit_fc(bop)_, bop_hidden = self.unit_gru(bop_embed)bop_hidden = bop_hidden.squeeze(0) # (B, 128)
......................................temporal_input = torch.stack(outputs, dim=1) # (B, T, D)_, final_hidden = self.temporal_gru(temporal_input) # final_hidden: (1, B, 512)final_feature = final_hidden.squeeze(0).unsqueeze(1).repeat(1, self.ally_num, 1) # (B, 3, 512)logits = self.policy_head(final_feature) # (B, 3, 8)# logits_all = []# logits_all.append(logits)return logits
在实际编码时我曾经把3-4-1都放到一个python中,但是调试起来自己都乱了,所以分成这么4大块挺好的,这是自己的经验。
参考:
深度强化学习之模仿学习(Imitation Learning)-腾讯云开发者社区-腾讯云