深度学习打卡1
神经网络原理
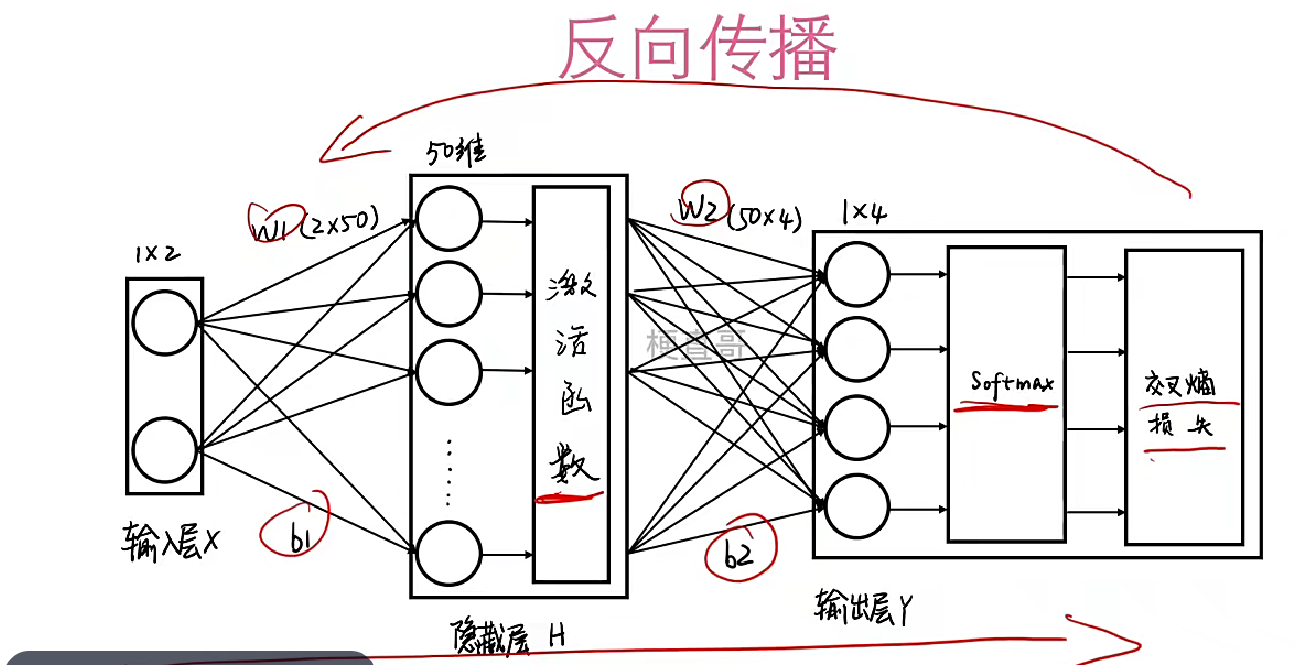
激活函数
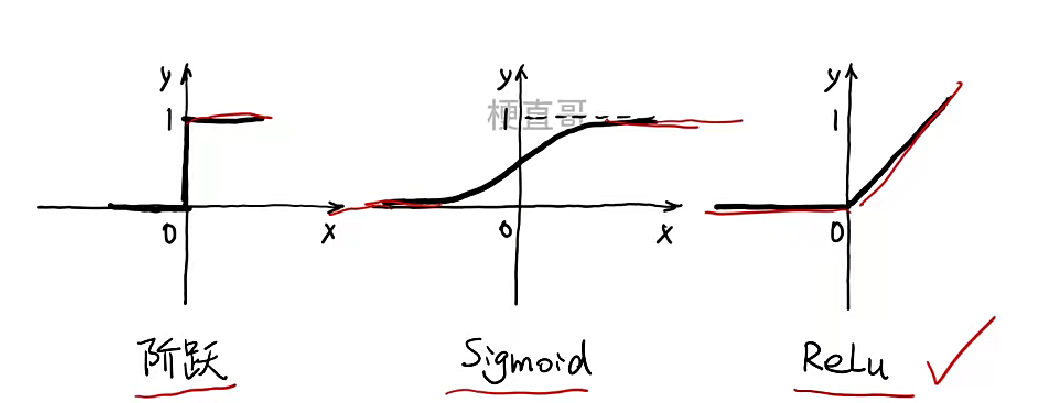
引入非线性: 这是最核心、最重要的作用! 如果没有激活函数(或者使用线性激活函数f(x) = x),无论神经网络有多少层,其整体计算仍然等价于一个单层的线性变换 (y = Wx + b)。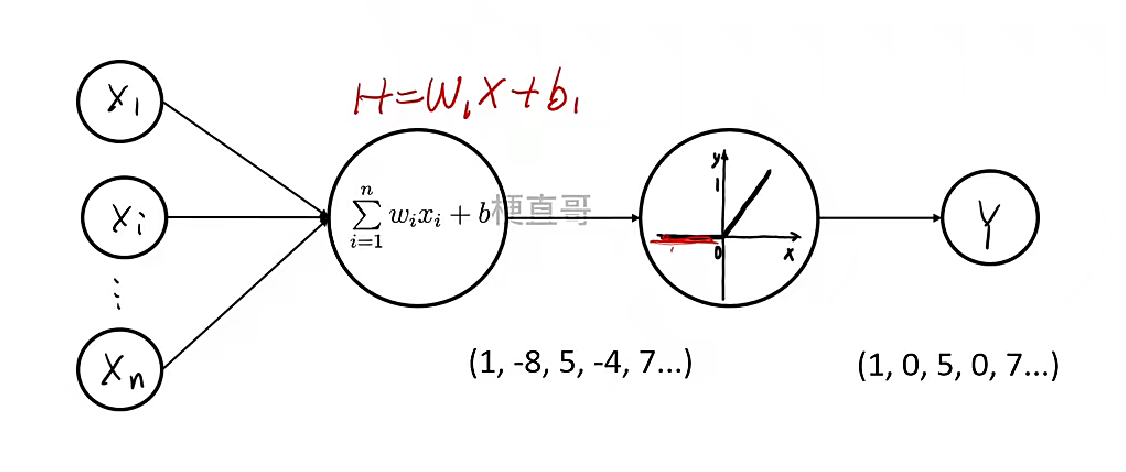
梯度下降
找到能使损失函数值最小化的模型参数
-
-
初始化: 随机选择一个起点(给模型参数赋初值)。
-
计算梯度: 在当前参数位置,计算损失函数关于所有参数的梯度。这个梯度告诉你“哪个方向是当前最陡的上坡”。
-
沿负梯度方向更新: 向负梯度方向迈出一小步(更新参数)。迈出的步长由学习率控制。
-
新参数 = 旧参数 - 学习率 * 梯度
-
-
重复: 不断重复步骤 2 和 3,计算新位置的梯度,再次沿负梯度方向更新参数。
核心思想: 通过迭代地计算梯度并沿着最陡下降方向(负梯度方向)调整参数,逐步逼近损失函数的最小值点。
-
学习率的重要性:
太大:步长过大,可能会“跨过”谷底,甚至导致损失值震荡或发散(在山谷两边来回跳)。
太小:步长过小,收敛速度极慢,可能需要非常多的步骤才能到达谷底,甚至卡在不是最低点的平坦区域(局部极小点或鞍点)。
损失函数
-
均方误差 (MSE):
L = 1/N * Σ(ŷ_i - y_i)²。最常用于回归问题(预测连续值)。惩罚大的误差很重。 -
平均绝对误差 (MAE):
L = 1/N * Σ|ŷ_i - y_i|。也用于回归。对异常值比MSE更鲁棒(不那么敏感)。 -
交叉熵损失 (Cross-Entropy Loss): 这是分类问题(尤其是多分类)的标准损失函数。
-
二分类交叉熵:
L = -[y * log(ŷ) + (1 - y) * log(1 - ŷ)](y是0或1的真实标签,ŷ是预测为1的概率)。 -
多分类交叉熵:
L = -Σ y_i * log(ŷ_i)(y_i是真实标签的one-hot编码,ŷ_i是模型预测的对应类别的概率)。它衡量预测概率分布与真实概率分布(one-hot)之间的差异。
-
-
Hinge Loss (合页损失): 常用于支持向量机(SVM)和某些神经网络分类任务,尤其是最大间隔分类。
优化器
它利用损失函数关于模型参数的梯度信息,决定如何调整参数以最小化损失函数
-
你构建一个神经网络结构(输入层、隐藏层、输出层,定义神经元和连接)。
-
选择一个合适的损失函数来衡量预测的好坏。
-
选择一个优化器(如Adam)来指导参数更新的策略。
-
将一批数据输入网络,进行前向传播得到预测。
-
计算损失。
-
使用反向传播计算损失函数关于所有权重/偏置(参数)的梯度。
-
优化器利用这些梯度,按照其特定的更新规则(如Adam的动量+自适应学习率)更新网络参数。
-
重复步骤4-7。在这个过程中,参数沿着损失函数的负梯度方向逐步调整(梯度下降思想),使得损失不断减小,预测越来越准。激活函数则在每一层的神经元内部施加非线性变换,赋予网络强大的拟合能力。
from gettext import npgettext
from socket import NI_NAMEREQD
import torch
torch.cuda
if torch.cuda.is_available():print("CUDA可用")device_count = torch.cuda.device_count()print(f"CUDA设备数量: {device_count}")curent_device=torch.cuda.current_device()print(f"当前使用的CUDA设备: {curent_device}")device_name = torch.cuda.get_device_name(curent_device)print(f"当前CUDA设备名称: {device_name}" )
else:print("CUDA不可用")from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
iris = load_iris()
X= iris.data
y= iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)from sklearn.preprocessing import MinMaxScaler
scaler= MinMaxScaler()
X_train = scaler,fit_transform(X_train)
X_test = scaler.transform(X_test)X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)import torch
import torch.nn as nn
import torch.optim as optimclass MLP(nn.Module):def __init__(self):super(MLP,self).__init__()self.fc1 = nn.Linear(4,10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10,3)def forward(self,x):out= self.fc1(x)out = self.relu(out)out = self.fc2(out)return out
model = MLP()criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01)num_epochs = 20000
losses = []
for epoch in range(num_epochs):outputs = model.forward(X_train)loss= criterion(outputs,y_train)optimizer.zero_grad()loss.backward()optimizer.step()losses.append(loss.item())if (epoch+1) % 100 ==0:print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")import matplotlib.pyplot as plt
plt.plot (range{num_epochs},losses)
plt.xlabel('Epoch')
plt.ylable('Loss')
plt.title('Training Loss overe Epochs')
plt.show()@浙大疏锦行