【Elasticsearch】数据预处理(含实战案例)
数据预处理
- 1.定义
- 2.主要作用
- 3.实现方式
- 4.常见预处理器
- 4.1 基础数据处理
- 4.2 文本处理
- 4.3 结构化数据提取
- 4.4 日期与数值处理
- 4.5 数据增强
- 4.6 数组与对象操作
- 4.7 条件处理
- 4.8 网络与编码
- 5.实战案例
- 案例 1:日志解析(Nginx 访问日志)
- 案例 2:数据清洗(电商商品数据)
- 案例 3:字段增强(根据 IP 添加地理位置)
- 案例 4:条件处理(动态设置折扣)
- 案例 5:多级嵌套 JSON 解析
- 总结
1.定义
在 Elasticsearch 中,预处理(Pre-processing)是指在文档被索引(存入数据库)之前,通过一系列预定义的规则或管道对原始数据进行处理的机制。它的核心目的是在数据正式进入搜索系统前,对其进行标准化、清洗或增强,以提高后续搜索和分析的效果。
🚀 预处理是轻量级的实时数据处理(在写入时触发),而传统 ETL(如 Logstash)通常用于离线的大批量数据转换。对于复杂场景,两者可以结合使用。
2.主要作用
- 数据标准化
- 例如:将文本转为小写、去除多余空格、统一日期格式等,确保数据的一致性。
- 字段提取与结构化
- 从原始数据(如日志、JSON 字符串)中提取特定字段(如从日志行中提取时间戳、IP 地址)。
- 丰富数据
- 添加新字段(如根据 IP 添加地理位置信息)、合并字段或计算衍生字段。
- 数据清洗
- 去除敏感信息(如脱敏信用卡号)、修正格式错误的数据。
- 分词与文本处理
- 提前对文本进行分词(如中文分词)、去除停用词(如 “
的”、“和”)等,优化全文搜索。
- 提前对文本进行分词(如中文分词)、去除停用词(如 “
3.实现方式
Elasticsearch 通过 摄取管道(Ingest Pipeline)实现预处理,管道由一系列 处理器(Processors)组成,每个处理器完成一个具体任务。例如:
PUT _ingest/pipeline/my_pipeline
{"description": "预处理示例","processors": [{"lowercase": { "field": "message" } // 将字段转为小写},{"remove": { "field": "temp_field" } // 删除临时字段}]
}
使用时,在索引文档时指定管道:
POST my_index/_doc?pipeline=my_pipeline
{"message": "Hello WORLD","temp_field": "unused"
}
最终存入的文档会是:
{"message": "hello world"
}
4.常见预处理器
4.1 基础数据处理
-
set:设置字段值(常量、变量或脚本计算结果)。{ "set": { "field": "status", "value": "active" } } -
remove:删除指定字段。{ "remove": { "field": "debug_info" } } -
rename:重命名字段。{ "rename": { "field": "old_name", "target_field": "new_name" } } -
copy:复制字段值到新字段。{ "copy": { "field": "source_field", "target_field": "target_field" } }
4.2 文本处理
-
lowercase/uppercase:转换文本为全小写或全大写。{ "lowercase": { "field": "message" } } -
trim:去除字段值首尾空格。{ "trim": { "field": "username" } } -
split:按分隔符拆分字符串为数组。{ "split": { "field": "tags", "separator": "," } } -
join:将数组字段合并为字符串(需指定分隔符)。{ "join": { "field": "words", "separator": " " } } -
gsub:正则替换文本内容。{ "gsub": { "field": "text", "pattern": "\\d+", "replacement": "[REDACTED]" } }
4.3 结构化数据提取
-
grok:从非结构化文本(如日志)中提取结构化字段(基于正则模式)。{"grok": {"field": "message","patterns": ["%{IP:client} %{WORD:method} %{URIPATHPARAM:request}"]} } -
kv(Key-Value):从键值对字符串(如"name=John&age=30")中提取字段。{ "kv": { "field": "query_string", "field_split": "&", "value_split": "=" } } -
json:解析 JSON 字符串为结构化字段。{ "json": { "field": "user_json", "target_field": "user" } }
4.4 日期与数值处理
-
date:解析日期字符串并转为 Elasticsearch 标准格式。{"date": {"field": "log_date","formats": ["yyyy-MM-dd HH:mm:ss", "ISO8601"],"target_field": "@timestamp"} } -
convert:转换字段数据类型(如字符串转整数)。{ "convert": { "field": "price", "type": "float" } }
4.5 数据增强
-
geoip:根据 IP 地址添加地理位置信息(如国家、城市、经纬度)。{ "geoip": { "field": "ip", "target_field": "geo" } } -
user_agent:解析 User-Agent 字符串,提取浏览器、设备等信息。{ "user_agent": { "field": "ua", "target_field": "user_agent_info" } } -
script:使用 Painless 脚本自定义处理逻辑(如条件判断、复杂计算)。{"script": {"source": """if (ctx['price'] > 100) {ctx['discount'] = ctx['price'] * 0.9;}"""} }
4.6 数组与对象操作
-
append:向数组字段追加值。{ "append": { "field": "tags", "value": ["new_tag"] } } -
sort:对数组字段排序。{ "sort": { "field": "scores", "order": "desc" } } -
dot_expander:将嵌套字段的路径展开(如{"a.b": 1}→{"a": {"b": 1}})。{ "dot_expander": { "field": "a.b" } }
4.7 条件处理
-
fail:主动抛出错误(用于数据校验)。{ "fail": { "message": "Invalid data: price is negative!", "if": "ctx.price < 0" } } -
foreach:对数组中的每个元素应用处理器。{"foreach": {"field": "items","processor": { "uppercase": { "field": "_ingest._value.name" } }} }
4.8 网络与编码
-
urldecode:解码 URL 编码的字符串(如%20→ 空格)。{ "urldecode": { "field": "encoded_url" } } -
bytes:转换人类可读的字节单位(如1KB)为数字(1024)。{ "bytes": { "field": "file_size" } }
通过组合这些处理器,可以构建强大的数据预处理管道,满足从简单格式化到复杂日志解析的各种需求。
5.实战案例
案例 1:日志解析(Nginx 访问日志)
需求:将原始的 Nginx 日志行解析为结构化字段(如 IP、时间戳、请求方法等)。
原始日志:
192.168.1.1 - - [10/Oct/2023:13:55:36 +0800] "GET /api/user?id=123 HTTP/1.1" 200 1024
- 创建 Pipeline
PUT _ingest/pipeline/nginx_log_parser
{"description": "Parse Nginx access logs","processors": [{"grok": {"field": "message","patterns": ["%{IP:client_ip} %{USER:ident} %{USER:auth} \\[%{HTTPDATE:timestamp}\\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:http_version}\" %{NUMBER:status} %{NUMBER:bytes}"]}},{"date": {"field": "timestamp","formats": ["dd/MMM/yyyy:HH:mm:ss Z"],"target_field": "@timestamp"}},{"remove": { "field": "message" } // 解析后删除原始日志}]
}
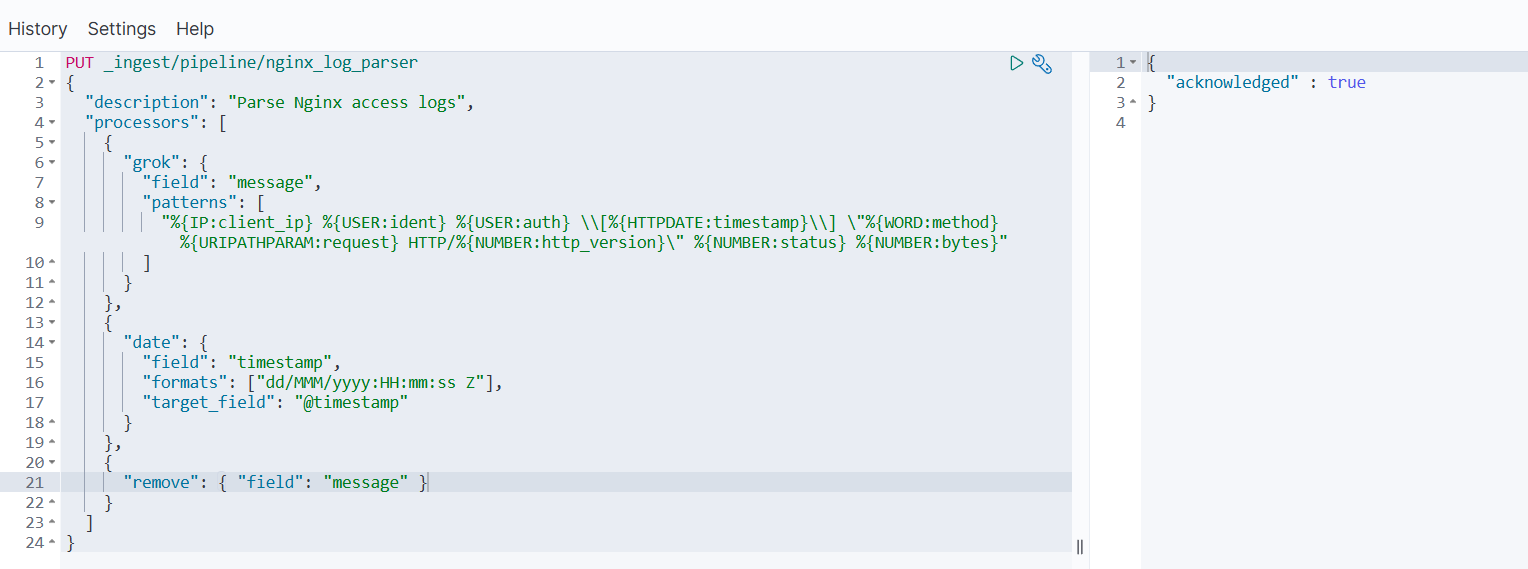
- 测试 Pipeline
POST _ingest/pipeline/nginx_log_parser/_simulate
{"docs": [{"_source": {"message": "192.168.1.1 - - [10/Oct/2023:13:55:36 +0800] \"GET /api/user?id=123 HTTP/1.1\" 200 1024"}}]
}
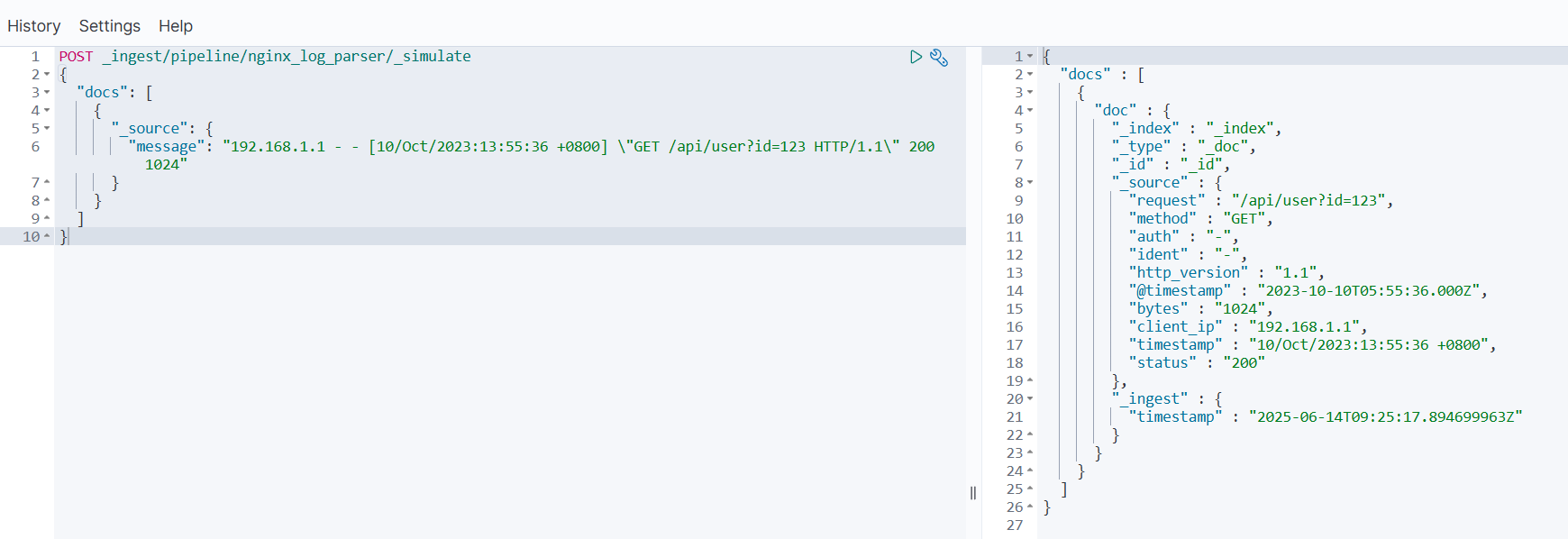
案例 2:数据清洗(电商商品数据)
需求:清洗商品数据,统一价格格式、去除无效字段、转换单位。
原始数据:
{"product_name": " Wireless Headphones ","price": "$99.99","weight": "0.5kg","temp_note": "discount_applied"
}
- 创建 Pipeline
PUT _ingest/pipeline/clean_product_data
{"processors": [{ "trim": { "field": "product_name" } },{ "gsub": { "field": "price", "pattern": "\\$", "replacement": "" } },{ "convert": { "field": "price", "type": "float" } },{ "gsub": { "field": "weight", "pattern": "kg", "replacement": "" } },{ "convert": { "field": "weight", "type": "float" } },{ "remove": { "field": "temp_note" } }]
}
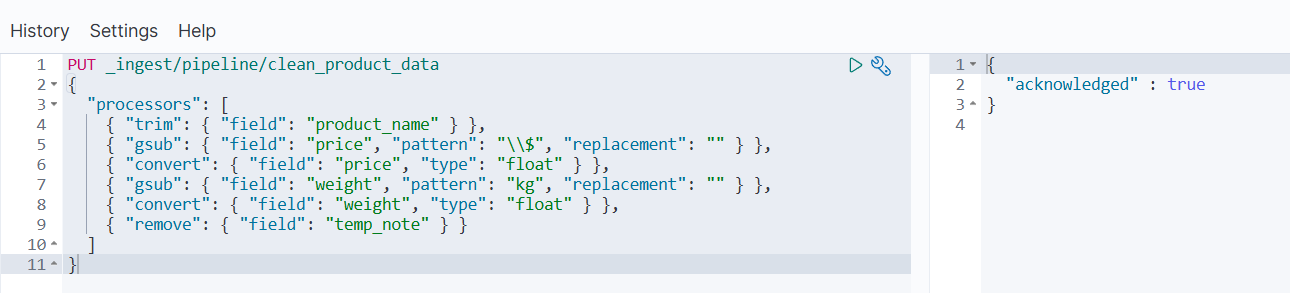
- 测试 Pipeline
POST _ingest/pipeline/clean_product_data/_simulate
{"docs": [{"_source": {"product_name": " Wireless Headphones ","price": "$99.99","weight": "0.5kg","temp_note": "discount_applied"}}]
}
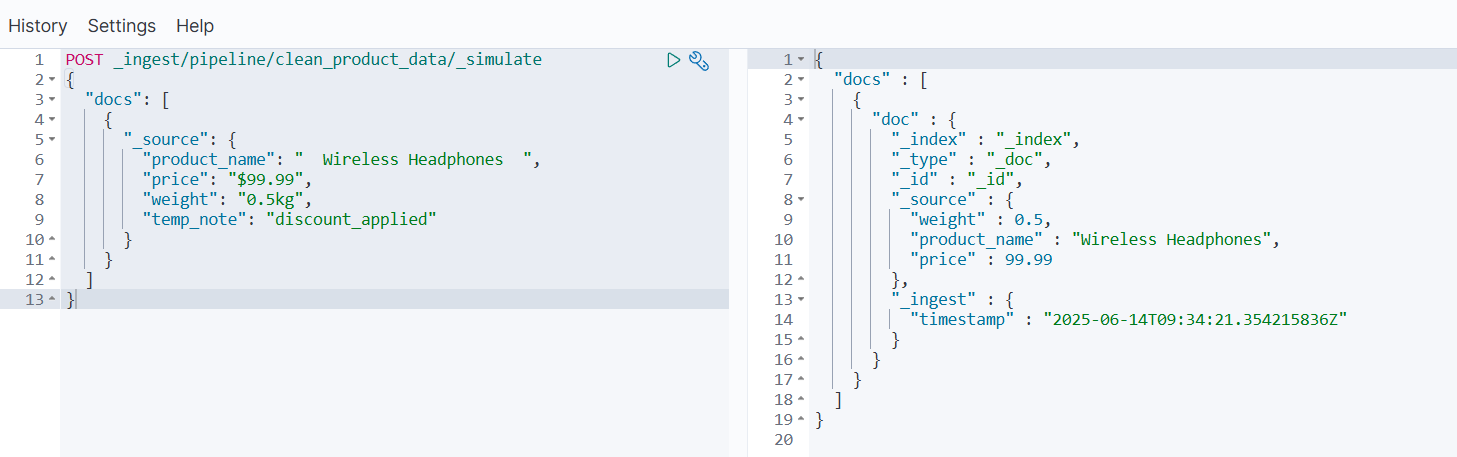
- 实际写入数据到索引
POST ecommerce_products/_doc?pipeline=clean_product_data
{"product_name": " Wireless Headphones ","price": "$99.99","weight": "0.5kg","temp_note": "discount_applied"
}
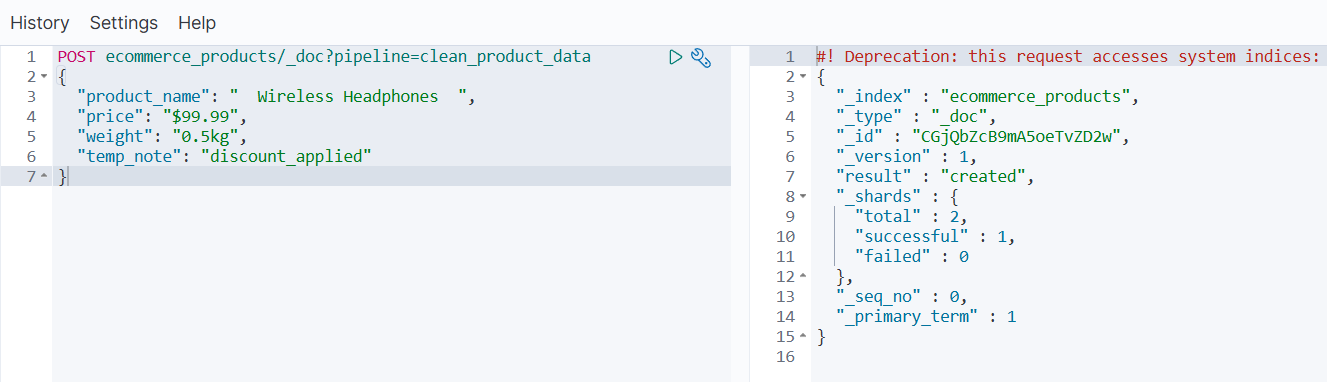
- 查询结果验证
GET ecommerce_products/_search
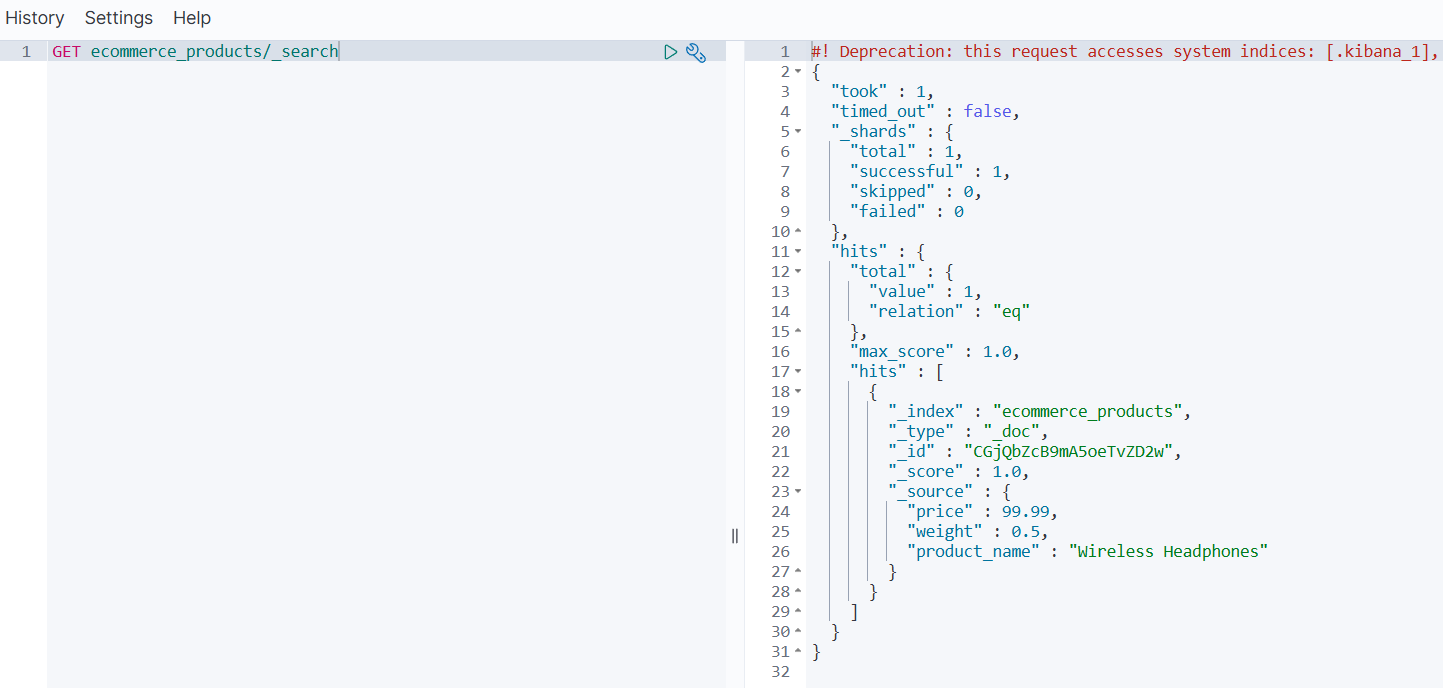
案例 3:字段增强(根据 IP 添加地理位置)
需求:根据用户的 IP 地址添加国家、城市等地理信息。
原始数据:
{ "ip": "8.8.8.8", "action": "login" }
- 创建 Pipeline
PUT _ingest/pipeline/enrich_geoip
{"processors": [{"geoip": {"field": "ip","target_field": "geo","properties": ["country_name", "city_name", "location"]}}]
}
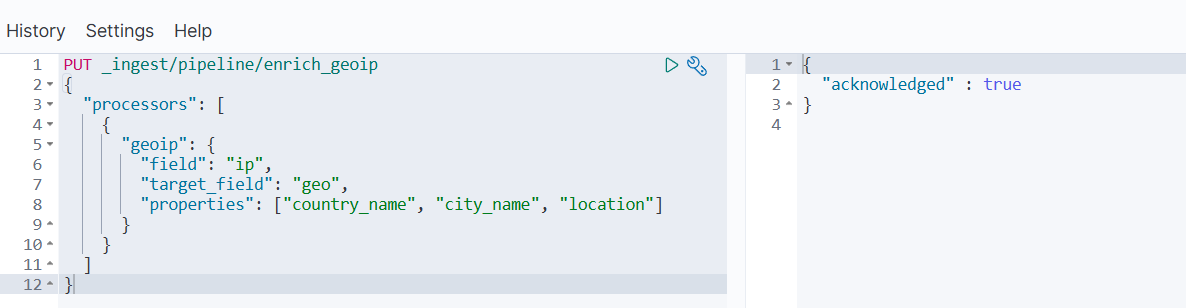
- 测试 Pipeline
POST _ingest/pipeline/enrich_geoip/_simulate
{"docs": [{"_source": {"ip": "8.8.8.8","action": "login"}}]
}
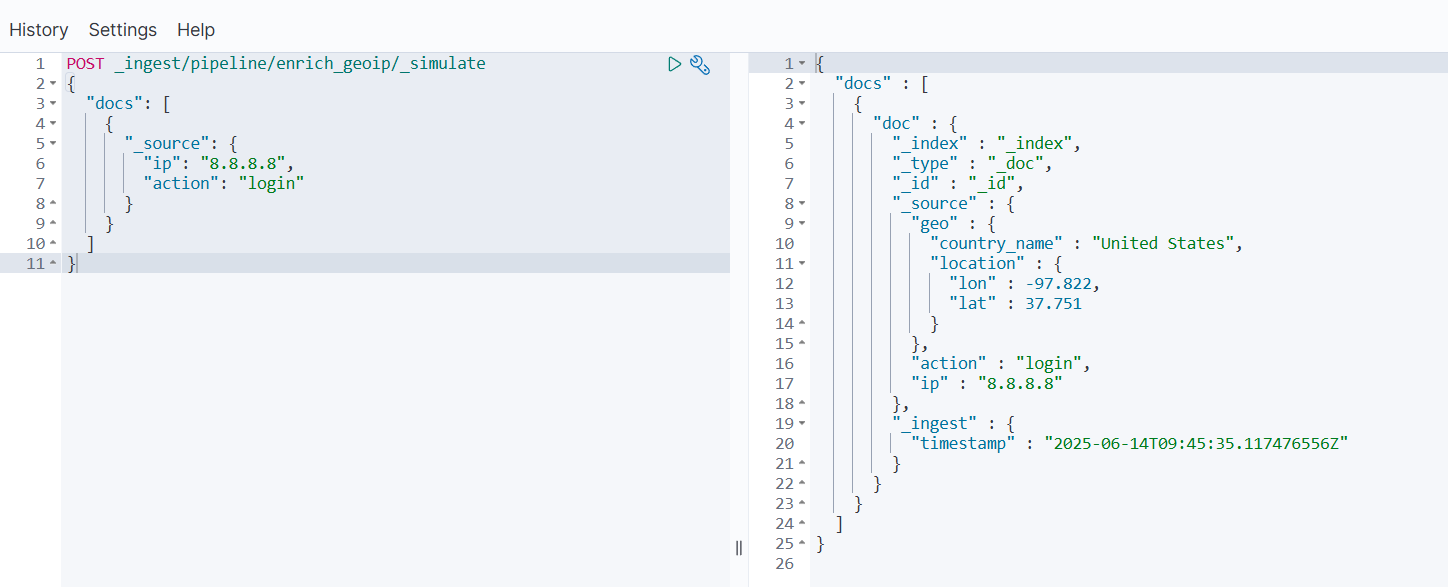
- 实际写入数据到索引
POST user_actions/_doc?pipeline=enrich_geoip
{"ip": "8.8.8.8","action": "login"
}
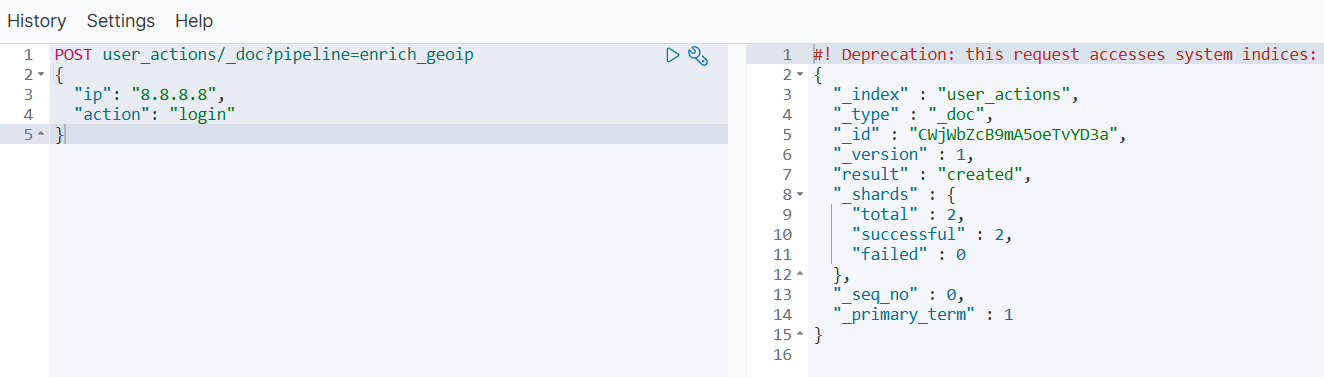
- 查询结果验证
GET user_actions/_search
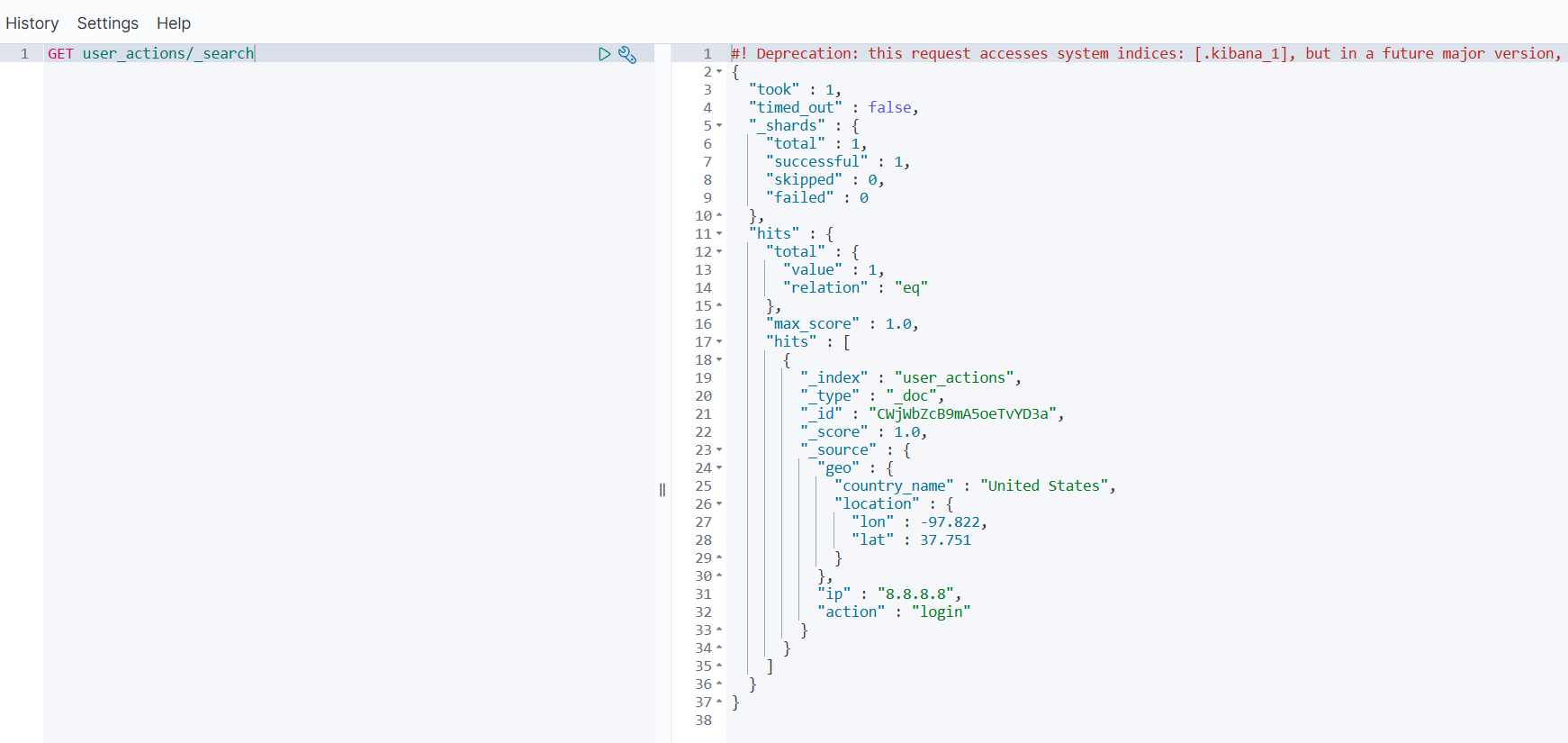
案例 4:条件处理(动态设置折扣)
需求:根据商品价格动态计算折扣(价格 >100 的打 9 折)。
原始数据:
{ "product": "Laptop", "price": 1200 }
- 创建 Pipeline
PUT _ingest/pipeline/apply_discount
{"processors": [{"script": {"source": """if (ctx.price > 100) {ctx.discounted_price = ctx.price * 0.9;}"""}}]
}

- 测试 Pipeline
POST _ingest/pipeline/apply_discount/_simulate
{"docs": [{"_source": {"product": "Laptop","price": 1200}}]
}
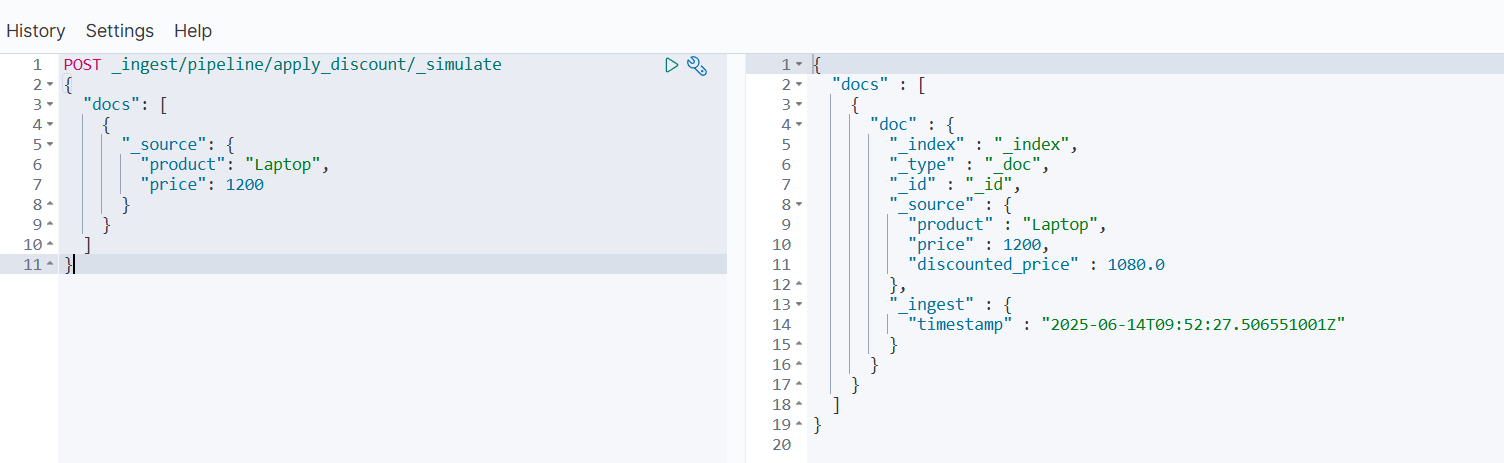
- 实际写入数据到索引
POST products/_doc?pipeline=apply_discount
{"product": "Laptop","price": 1200
}
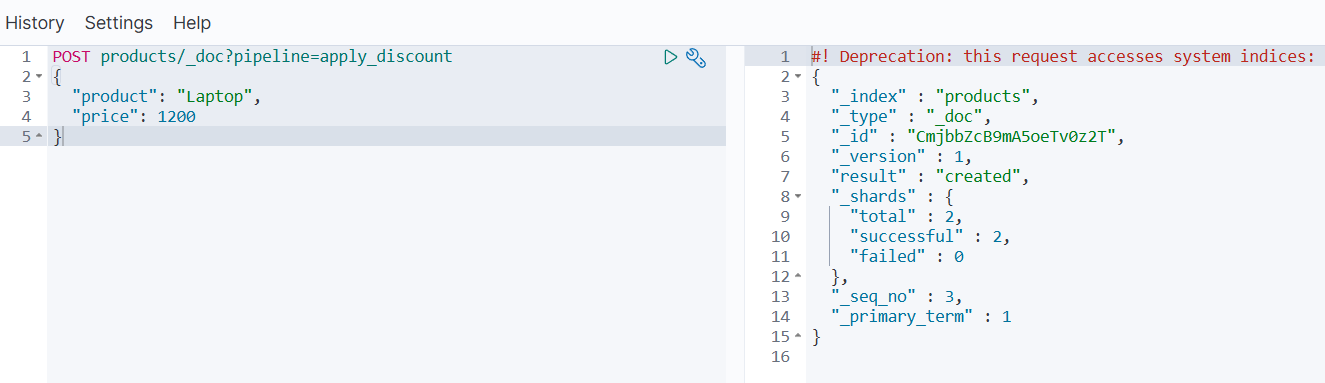
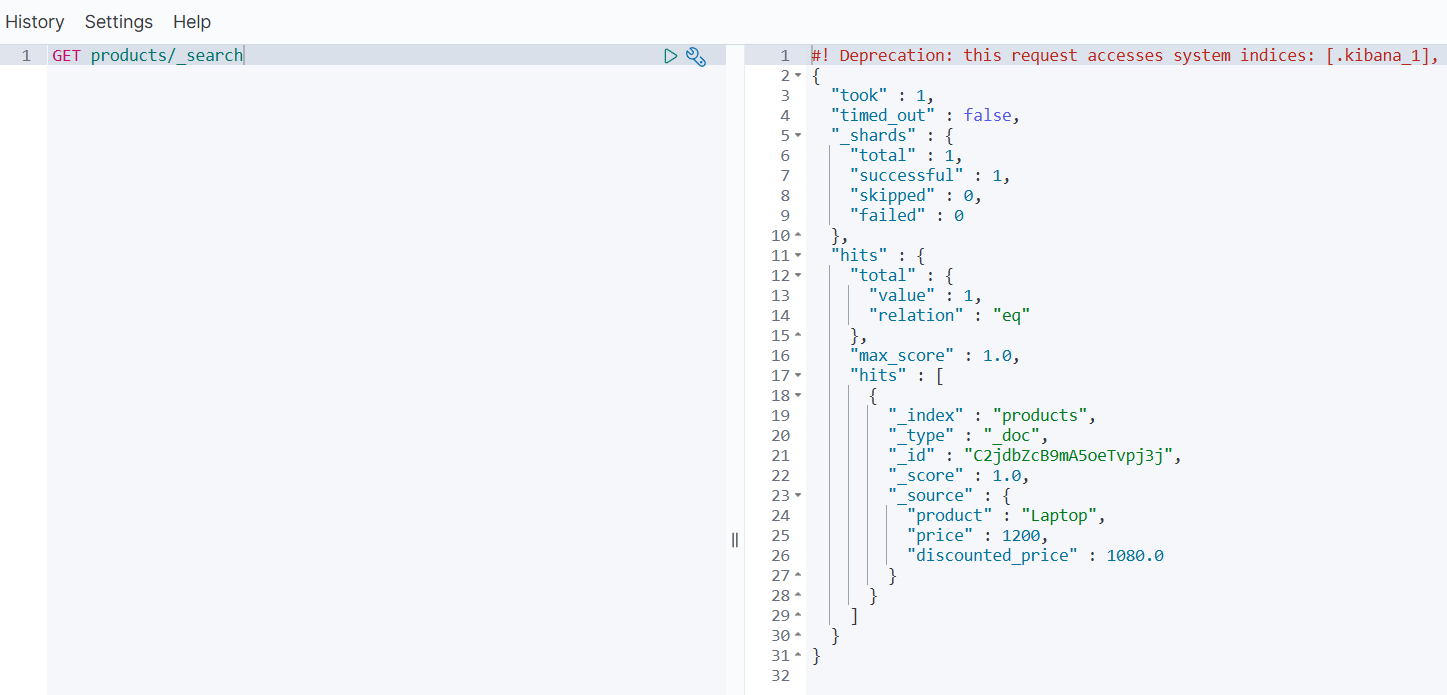
- 查询结果验证
GET products/_search
案例 5:多级嵌套 JSON 解析
需求:解析嵌套的 JSON 字符串并展开字段。
原始数据:
{"user": "{\"name\":\"John\", \"address\":{\"city\":\"Beijing\"}}"
}
- 创建 Pipeline
PUT _ingest/pipeline/parse_nested_json
{"processors": [{ "json": { "field": "user", "target_field": "user_obj" } },{ "dot_expander": { "field": "user_obj.address.city" } }]
}

- 测试 Pipeline
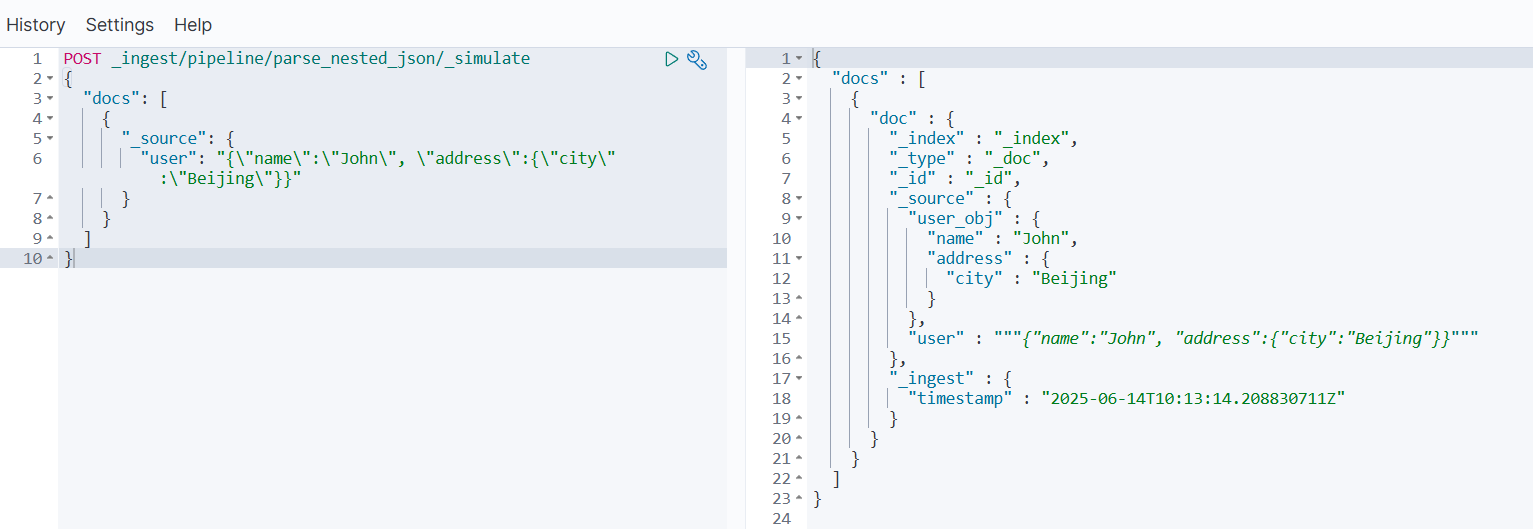
POST _ingest/pipeline/parse_nested_json/_simulate
{"docs": [{"_source": {"user": "{\"name\":\"John\", \"address\":{\"city\":\"Beijing\"}}"}}]
}
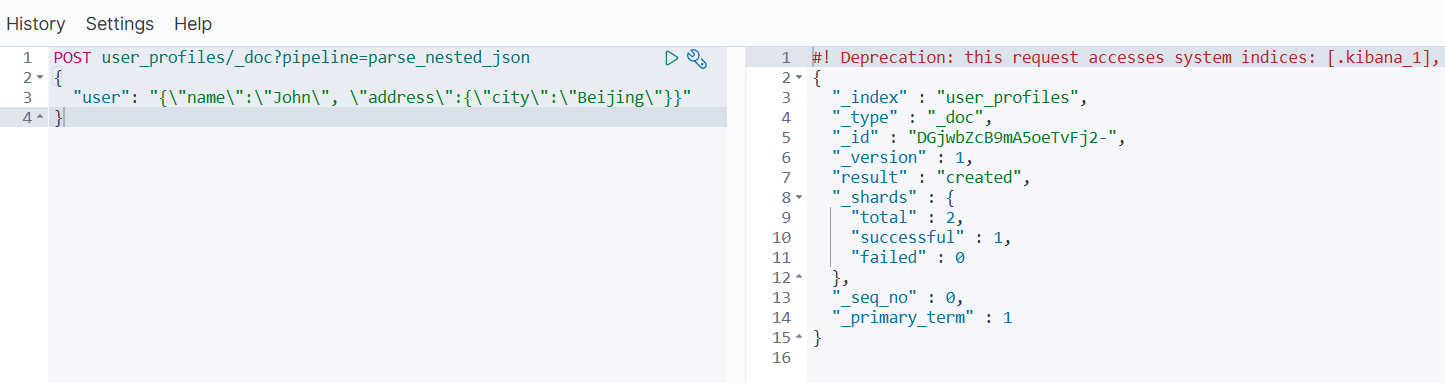
- 实际写入数据到索引
POST user_profiles/_doc?pipeline=parse_nested_json
{"user": "{\"name\":\"John\", \"address\":{\"city\":\"Beijing\"}}"
}
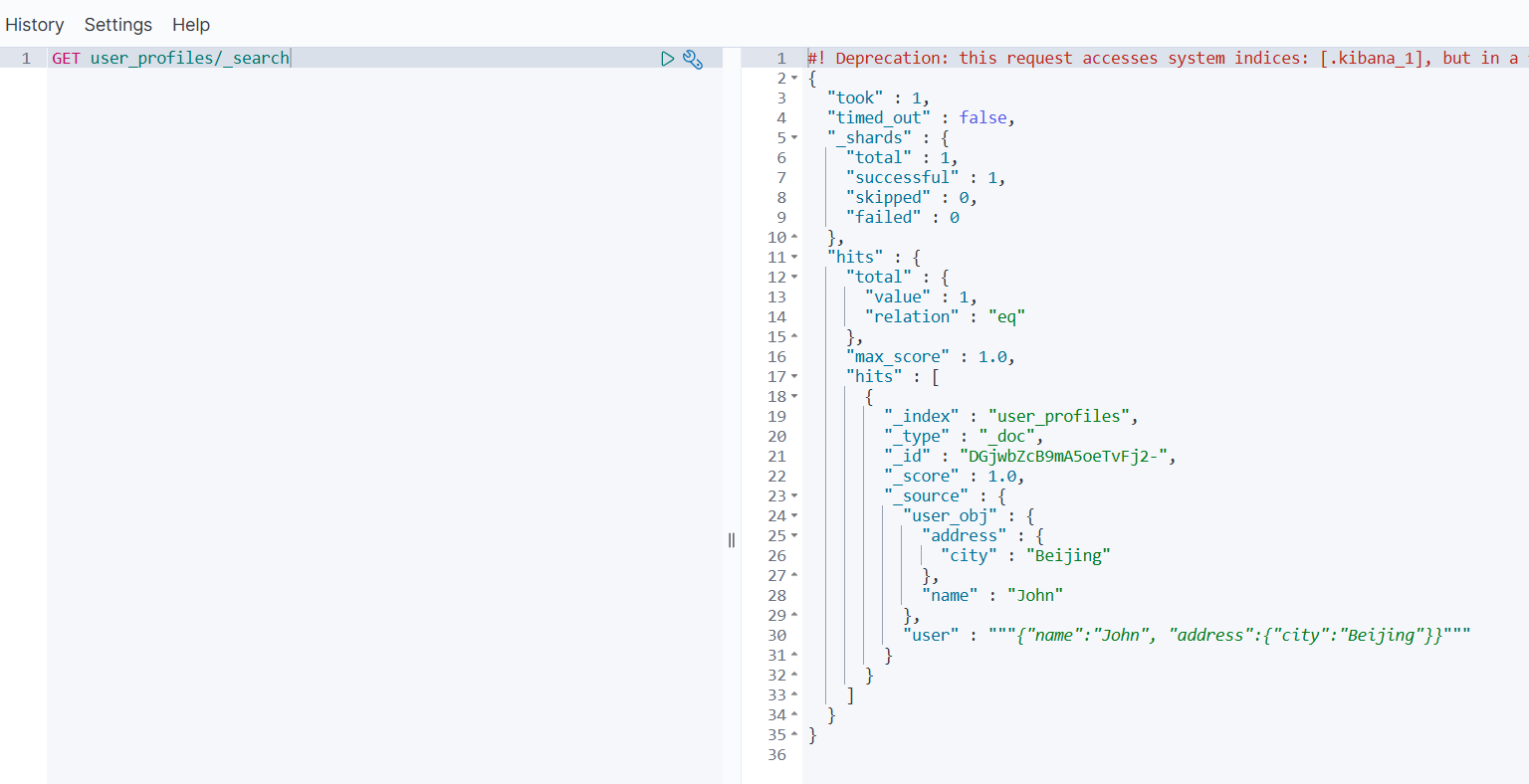
- 查询结果验证
GET user_profiles/_search
总结
| 场景 | 关键处理器 | 用途 |
|---|---|---|
| 日志解析 | grok + date | 从非结构化文本提取结构化字段 |
| 数据清洗 | gsub + convert + remove | 标准化字段格式,删除无用数据 |
| 字段增强 | geoip + user_agent | 添加地理位置或设备信息 |
| 条件逻辑 | script | 动态计算或分支处理 |
| 嵌套数据展开 | json + dot_expander | 处理复杂 JSON 结构 |
通过组合这些案例中的方法,可以灵活应对实际业务中的数据处理需求!