异步爬虫---
代码结构分析
这是一个同步新闻爬虫程序,主要包含以下几个部分:
们把爬虫设计为一个类,类在初始化时,连接数据库,初始化logger,创建网址池,加载hubs并设置到网址池。
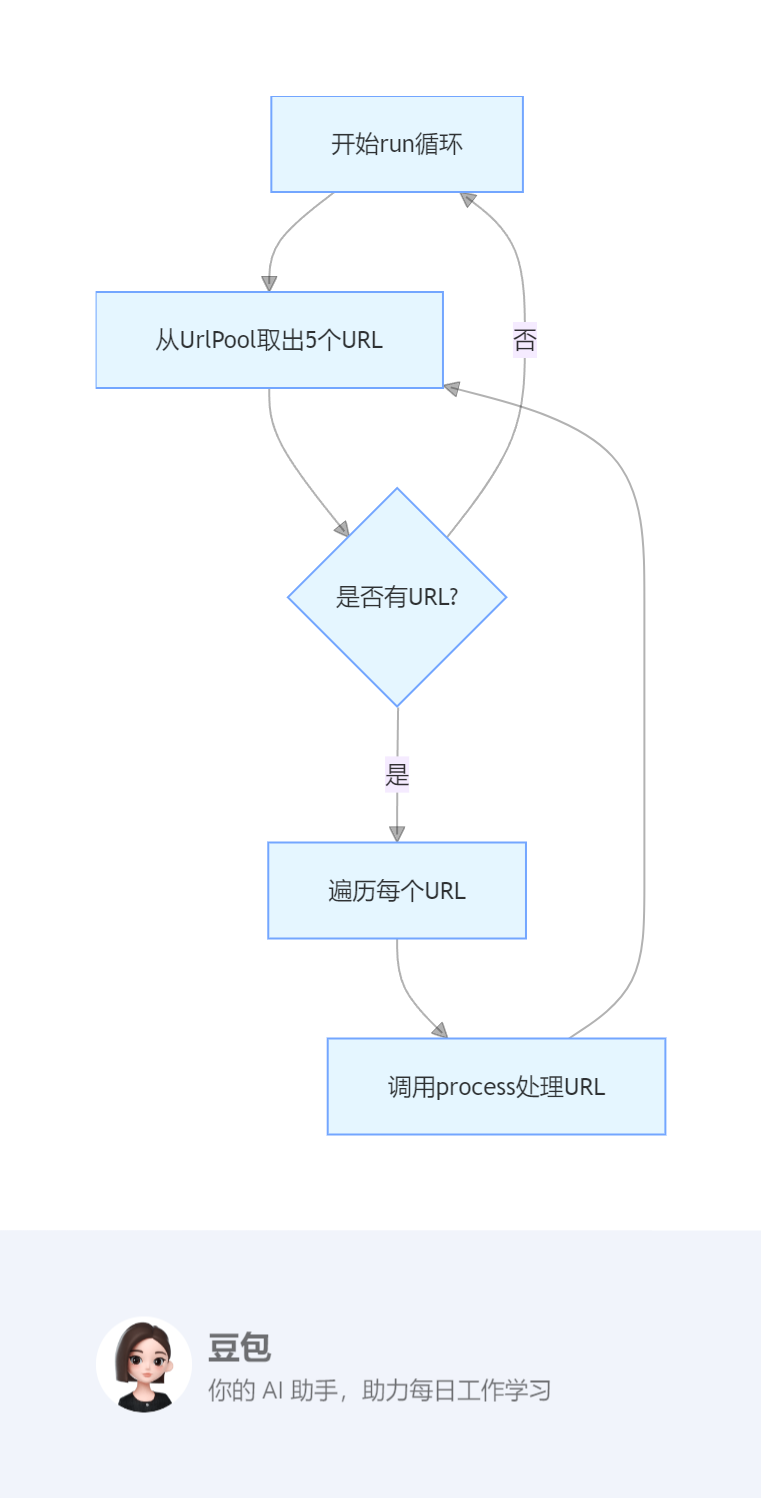
爬虫开始运行的入口就是run(),它是一个while循环,设计为永不停息的爬。先从网址池获取一定数量的url,然后对每个url进行处理,
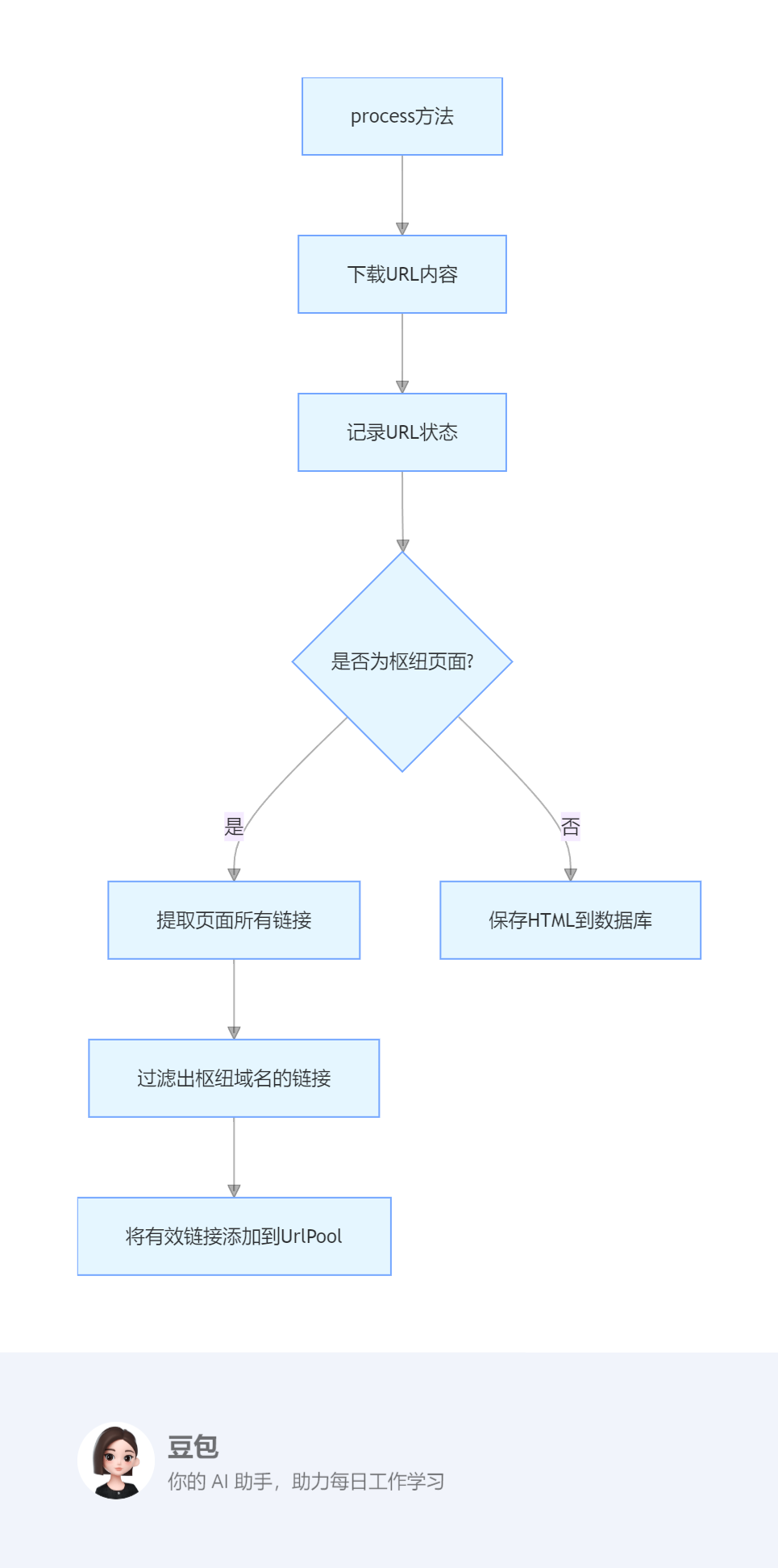
处理url也就是实施抓取任务的是process(),它先通过downloader下载网页,然后在网址池中设置该url的状态。接着,从下载得到的html提取网址,并对得到的网址进行过滤(filter_good()),过滤的原则是,它们的host必须是hubs的host。最后把下载得到的html存储到数据。
运行这个新闻爬虫很简单,生成一个NewsCrawlerSync的对象,然后调用run()即可。当然,在运行之前,要先在config.py里面配置MySQL的用户名和密码,也要在crawler_hub表里面添加几个hub网址才行。
##思考题: 如何收集大量hub列表
比如,我想要抓新浪新闻 news.sina.com.cn , 其首页是一个hub页面,但是,如何通过它获得新浪新闻更多的hub页面呢?小猿们不妨思考一下这个问题,并用代码来实现一下。
这个时候已经抓取到很多网页了,但是怎么抽取网页里的文字呢?
1. 异步的downloader
还记得我们之前使用requests实现的那个downloader吗?同步情况下,它很好用,但不适合异步,所以我们要先改造它。幸运的是,已经有aiohttp模块来支持异步http请求了,那么我们就用aiohttp来实现异步downloader。
async def fetch(session, url, headers=None, timeout=9):_headers = {'User-Agent': ('Mozilla/5.0 (compatible; MSIE 9.0; ''Windows NT 6.1; Win64; x64; Trident/5.0)'),}if headers:_headers = headerstry:async with session.get(url, headers=_headers, timeout=timeout) as response:status = response.statushtml = await response.read()encoding = response.get_encoding()if encoding == 'gb2312':encoding = 'gbk'html = html.decode(encoding, errors='ignore')redirected_url = str(response.url)except Exception as e:msg = 'Failed download: {} | exception: {}, {}'.format(url, str(type(e)), str(e))print(msg)html = ''status = 0redirected_url = urlreturn status, html, redirected_url
这个异步的downloader,我们称之为fetch(),它有两个必须参数:
- seesion: 这是一个aiohttp.ClientSession的对象,这个对象的初始化在crawler里面完成,每次调用fetch()时,作为参数传递。
- url:这是需要下载的网址。
实现中使用了异步上下文管理器(async with),编码的判断我们还是用cchardet来实现。
有了异步下载器,我们的异步爬虫就可以写起来啦~
- 导入部分:引入必要的库和模块
- 主类定义:
NewsCrawlerSync类,包含爬虫的主要功能 - 初始化方法:
__init__方法,初始化数据库连接、日志和 URL 池 - 辅助方法:如加载枢纽 URL、保存数据到数据库、过滤 URL 等
- 核心处理方法:
process方法处理 URL 下载和内容提取 - 运行方法:
run方法实现爬虫的主循环
涉及的知识点
- 网络爬虫基础:URL 处理、HTML 下载和解析
- 数据库操作:使用 MySQL 存储爬取的 URL 和 HTML 内容
- 数据压缩:使用 LZMA 算法压缩 HTML 内容
- 哈希算法:使用 farmhash 生成 URL 的哈希值
- 日志记录:使用自定义日志函数记录操作
- URL 管理:使用自定义的 UrlPool 类管理 URL 队列
- 网页解析:使用正则表达式提取链接
执行流程
- 初始化爬虫对象,建立数据库连接,初始化日志和 URL 池
- 从数据库加载枢纽 URL,并将它们添加到 URL 池
- 进入主循环,每次从 URL 池取出 5 个 URL
- 对每个 URL,下载其内容并处理
- 如果是枢纽页面,提取其中的链接并过滤,将有效链接添加到 URL 池
- 如果是普通新闻页面,将其内容保存到数据库
- 重复步骤 3-6,直到程序停止
现在我将按照这个思路来详细分析代码的结构、知识点和流程。
新闻爬虫代码分析
一、整体结构
这是一个同步新闻爬虫程序,采用面向对象设计,核心类为 NewsCrawlerSync,主要包含以下模块:
- 数据存储模块:通过
ezpymysql.Connection连接 MySQL 数据库,存储 URL 和 HTML 内容 - URL 管理模块:使用
UrlPool类管理待爬取 URL 队列 - 下载处理模块:通过
fn.downloader下载网页内容 - 链接提取模块:通过
fn.extract_links_re从 HTML 中提取链接 - 日志记录模块:使用
fn.init_file_logger记录操作日志
二、核心知识点
1. 数据库操作
- 数据去重:通过
farmhash.hash64(url)生成 URL 哈希值,避免重复存储相同内容 - SQL 执行:使用参数化查询防止 SQL 注入(如
db.execute(sql, urlhash, url, html_lzma)) - 异常处理:捕获 1062 错误(唯一键冲突),处理数据重复情况
2. 网页处理
- URL 解析:使用
urllib.parse.urlparse解析 URL 的 host 部分 - 内容压缩:通过
lzma.compress压缩 HTML 内容,减少存储体积 - 链接提取:通过正则表达式从 HTML 中提取链接(
fn.extract_links_re)
3. 爬虫架构
- 枢纽页面机制:从
crawler_hub表加载枢纽 URL,作为爬虫入口 - URL 过滤:只爬取枢纽页面关联的域名(
self.hub_hosts集合) - 状态管理:通过
UrlPool.set_status记录 URL 爬取状态
三、执行流程详解
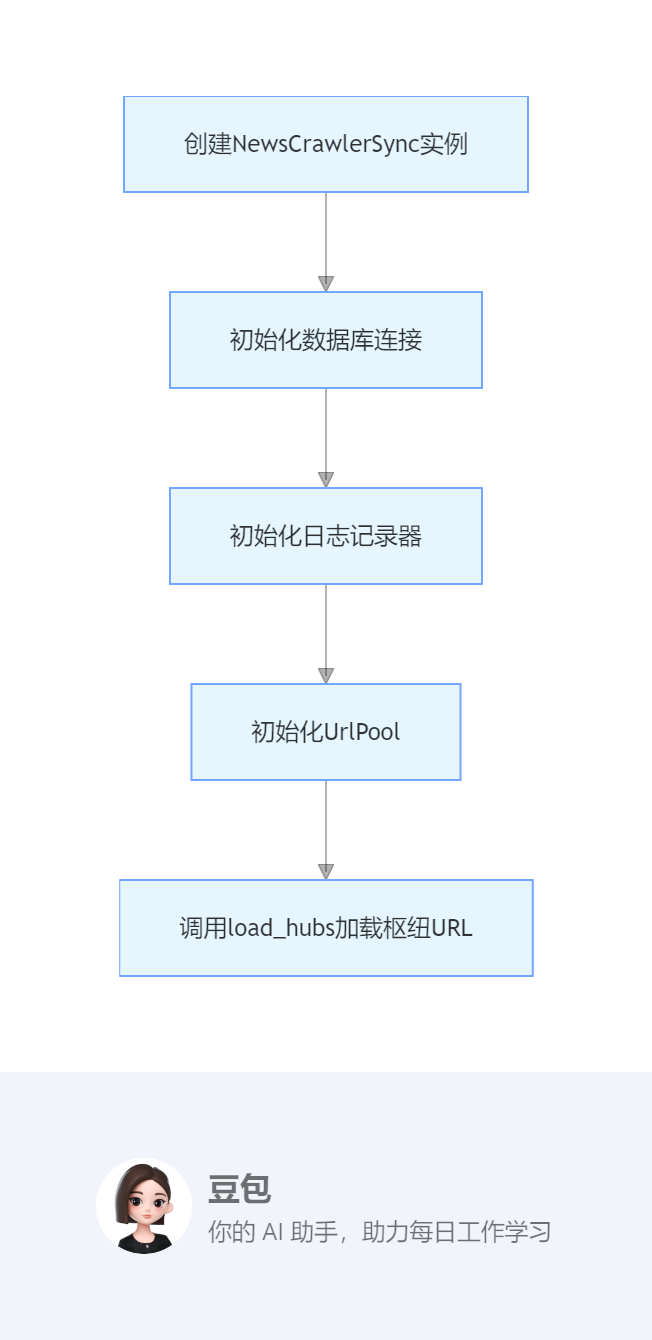
1. 初始化阶段
图片
代码
创建NewsCrawlerSync实例
初始化数据库连接
初始化日志记录器
初始化UrlPool
调用load_hubs加载枢纽URL
创建NewsCrawlerSync实例
初始化数据库连接
初始化日志记录器
初始化UrlPool
调用load_hubs加载枢纽URL

豆包
你的 AI 助手,助力每日工作学习
- 从
crawler_hub表读取枢纽 URL,提取域名存入hub_hosts集合 - 将枢纽 URL 添加到 UrlPool,设置 300 秒的重复爬取间隔
2. 主爬取循环
图片
代码
是
否
开始run循环
从UrlPool取出5个URL
是否有URL?
遍历每个URL
调用process处理URL
是
否
开始run循环
从UrlPool取出5个URL
是否有URL?
遍历每个URL
调用process处理URL

豆包
你的 AI 助手,助力每日工作学习
3. 单 URL 处理流程
图片
代码
是
否
process方法
下载URL内容
记录URL状态
是否为枢纽页面?
提取页面所有链接
过滤出枢纽域名的链接
将有效链接添加到UrlPool
保存HTML到数据库
是
否
process方法
下载URL内容
记录URL状态
是否为枢纽页面?
提取页面所有链接
过滤出枢纽域名的链接
将有效链接添加到UrlPool
保存HTML到数据库

豆包
你的 AI 助手,助力每日工作学习
四、关键方法解析
1. save_to_db - 数据存储核心
python
运行
def save_to_db(self, url, html):# 生成URL哈希值urlhash = farmhash.hash64(url)# 检查是否已存在相同哈希的记录d = self.db.get('select url from crawler_html where urlhash=%s', urlhash)if d:# 处理哈希冲突if d['url'] != url:self.logger.error('farmhash collision')return True# 压缩HTML内容if isinstance(html, str):html = html.encode('utf8')html_lzma = lzma.compress(html)# 插入数据库,处理唯一键冲突try:self.db.execute('insert into crawler_html(urlhash, url, html_lzma) values(%s, %s, %s)',urlhash, url, html_lzma)return Trueexcept Exception as e:if e.args[0] == 1062: # 重复记录return Trueelse:traceback.print_exc()raise e
2. process - 爬虫核心逻辑
python
运行
def process(self, url, ishub):# 下载网页内容status, html, redirected_url = fn.downloader(url)# 更新URL状态self.urlpool.set_status(url, status)if redirected_url != url:self.urlpool.set_status(redirected_url, status)# 处理非200状态码if status != 200:return# 处理枢纽页面if ishub:newlinks = fn.extract_links_re(redirected_url, html) # 提取所有链接goodlinks = self.filter_good(newlinks) # 过滤枢纽域名链接self.urlpool.addmany(goodlinks) # 添加到URL池# 处理新闻页面else:self.save_to_db(redirected_url, html) # 保存到数据库
五、技术特点与注意事项
-
同步爬虫特性:
- 单线程执行,通过循环依次处理 URL
- 适合小规模爬取,大规模爬取需改造为异步模式
-
去重机制:
- 基于 farmhash 哈希值去重,可能存在哈希冲突(代码中已处理)
- 数据库中通过
urlhash建立唯一索引强化去重
-
可优化点:
- 改为异步爬虫(使用
asyncio)提升并发效率 - 添加 User-Agent 轮换和请求延迟,避免被封 IP
- 完善代理 IP 池机制,应对反爬措施
- 改为异步爬虫(使用
通过这个爬虫框架,可以实现对指定新闻网站的持续爬取,并将内容结构化存储到数据库中,适合作为入门级爬虫系统的参考