《编译原理》课程作业
文章目录
- 1. 说明文法G(S):S->aSb S->ab能够产生怎样的语言?
- 2. 写出能够产生语言 {ambn|1<=n<=m<=2n}的文法。
- 3. 写出文法G(E):E->i|E+E|E*E|(E)的最左推导和最右推导,画出对应的语法树并说明该文法是否具有二义性。
- 4. 对于DFA M = ({0, 1, 2, 3}, {a, b}, f, 0, {3}), 其中,f定义为:f(0, a)=1; f(0, b)=2; f(1, a)=3; f(1, b)=2; f(2, a)=1; f(2, b)=3; f(3, a)=3; f(3, b)=3. 请画出其状态转换矩阵和状态转换图。
- 5. 请指出下列的错误可在编译的那个阶段发现(18分)。
- 6. 请阐述编译原理在工业界或学术界的一项应用并给出代码(30分)。
1. 说明文法G(S):S->aSb S->ab能够产生怎样的语言?
起始符号是 SS。
产生规则:
第一条规则:S→aSbS→aSb,在字符串中添加一个aa,然后是任意数量的SS,最后是一个bb。这可以生成形式为anSbnanSbn的字符串,其中n≥1n≥1。
第二条规则:S→abS→ab允许直接生成字符串abab。使用第二条规则,生成字符串abab。使用第一条规则,生成更长的字符串。例如:
应用S→aSbS→aSb一次,得到aSbaSb。然后,将SS替换为abab(使用第二条规则),得到aabaab。再次应用S→aSbS→aSb,得到aaSbbaaSbb。将SS替换为abab,得到aabbaabb。可以生成形式为anbnanbn的字符串,其中n≥1n≥1。
文法 G(S)G(S) 可以生成所有形式为 anbnanbn 的字符串,其中n≥1n≥1。这意味着字符串必须有相同数量的 aa 和 bb,并且它们必须成对出现。
最终答案为:
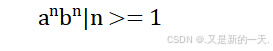
2. 写出能够产生语言 {ambn|1<=n<=m<=2n}的文法。
定义一个文法,其中起始符号SS可以生成一个aa,然后是一个bb,并且可以递归地生成更多的aa和bb,同时确保aa的数量至少与 bb 一样多,最多是 bb 的两倍。
文法如下: S→aSbS→aSb S→aSBS→aSB S→abS→ab B→bBB→bB B→ϵB→ϵ
规则S→aSbS→aSb:这条规则生成一个aa,然后是更多的aa和bb,确保 aa 和 bb 的数量保持平衡。
规则S→aSBS→aSB:这条规则生成一个aa,然后是更多的aa,最后是bb的序列,确保aa的数量可以是bb的两倍。
规则S→abS→ab:这条规则生成基本情况,即aa和bb的数量相等。
规则B→bBB→bB:这条规则生成更多的bb,直到aa的数量是bb的两倍。
规则B→ϵB→ϵ:这条规则停止生成bb,确保aa的数量不会超过bb的两倍。
最终答案:
S→aSb∣aSB∣ab∣B→bB∣B→ϵS→aSb∣aSB∣ab∣B→bB∣B→ϵ
3. 写出文法G(E):E->i|E+E|E*E|(E)的最左推导和最右推导,画出对应的语法树并说明该文法是否具有二义性。
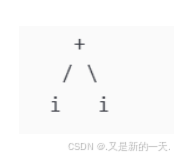
最左推导:E→E+E→i+E→i+iE→E+E→i+E→i+i
E
E+E
i+E
i+i
最左推导语法树:
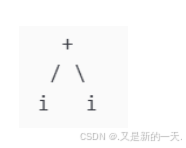
最右推导:E→E+E→E+i→i+iE→E+E→E+i→i+i
E
E+E
E+i
i+i
最右推导语法树:
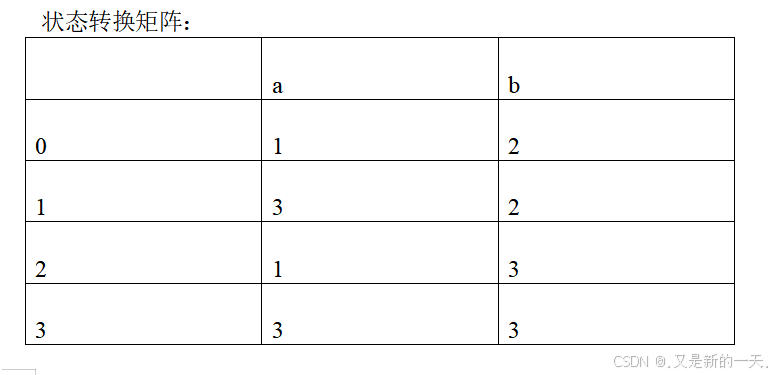
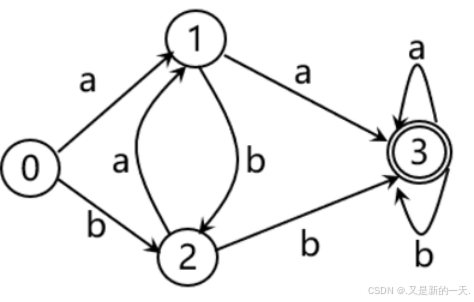
4. 对于DFA M = ({0, 1, 2, 3}, {a, b}, f, 0, {3}), 其中,f定义为:f(0, a)=1; f(0, b)=2; f(1, a)=3; f(1, b)=2; f(2, a)=1; f(2, b)=3; f(3, a)=3; f(3, b)=3. 请画出其状态转换矩阵和状态转换图。
状态转换矩阵:
状态转换图:
5. 请指出下列的错误可在编译的那个阶段发现(18分)。
关键字拼写错误:词法分析阶段
缺少运算对象:语法分析阶段
实参与形参的类型不一致:语义分析阶段
引用的变量没有定义:语义分析阶段
数组下标越界:语义分析阶段
常数中出现了非数字字符:词法分析阶段
6. 请阐述编译原理在工业界或学术界的一项应用并给出代码(30分)。
编译原理在学术界的一个重要应用是代码优化,特别是在高性能计算和并行计算领域。一个具体的例子是循环优化,它涉及到循环展开、循环融合、循环分布等技术,以减少循环迭代之间的依赖,提高数据局部性和并行度。
下面是使用Python编写的简单循环展开的示例代码。循环展开是一种减少循环迭代次数,每次迭代执行多个操作的技术,这有助于减少循环开销和提高指令流水线的效率。
循环展开示例
假设有一个简单的循环,用于计算数组中所有元素的和。通过循环展开来优化这个循环。
代码如下:
def simple_sum(arr):total = 0for i in range(len(arr)):total += arr[i]return total
def loop_unrolling(arr):n = len(arr)total = 0# 循环展开因子为4unroll_factor = 4for i in range(0, n, unroll_factor):total += arr[i] + arr[i+1] + arr[i+2] + arr[i+3] if i+3 < n else (arr[i] + arr[i+1] + arr[i+2] + arr[i+3] - 3*(n-i))return total
import random
arr = [random.randint(1, 100) for _ in range(100)]
simple_result = simple_sum(arr)
print("Simple loop sum:", simple_result)
unrolled_result = loop_unrolling(arr)
print("Loop unrolling sum:", unrolled_result)
或者:
以下是C++代码,它使用DFA来识别一个简单的语言,该语言包含关键字if和else,以及标识符和数字。
#include <bits/stdc++.h>
using namespace std;enum State {START,IF,ELSE,IDENT,NUM,ERROR
};// DFA转换函数
State transition(State current, char input) {switch (current) {case START:if (input == 'i') return IF;if (input == 'e') return ELSE;if (isalpha(input)) return IDENT;if (isdigit(input)) return NUM;return ERROR;case IF:if (input == 'f') return IF + 1;return ERROR;case ELSE:if (input == 'l') return ELSE + 1;return ERROR;case IDENT:if (isalpha(input) || isdigit(input) || input == '_') return IDENT;return ERROR;case NUM:if (isdigit(input)) return NUM;return ERROR;default:return ERROR;}
}// 识别标记
string recognizeToken(string input) {State state = START;for (char c : input) {state = transition(state, c);if (state == ERROR) {return "Error";}}switch (state) {case IF + 1:return "if";case ELSE + 1:return "else";case IDENT:return "Identifier";case NUM:return "Number";default:return "Unknown";}
}int main() {string input;cout << "Enter a keyword or identifier: ";cin >> input;cout << "Token: " << recognizeToken(input) << endl;return 0;
}