Qwen3模型架构、训练方法梳理
qwen3炼丹真是全是技巧,下面来看看,仅供参考。
https://huggingface.co/Qwen
https://modelscope.cn/organization/qwen
https://github.com/QwenLM/Qwen3
模型架构
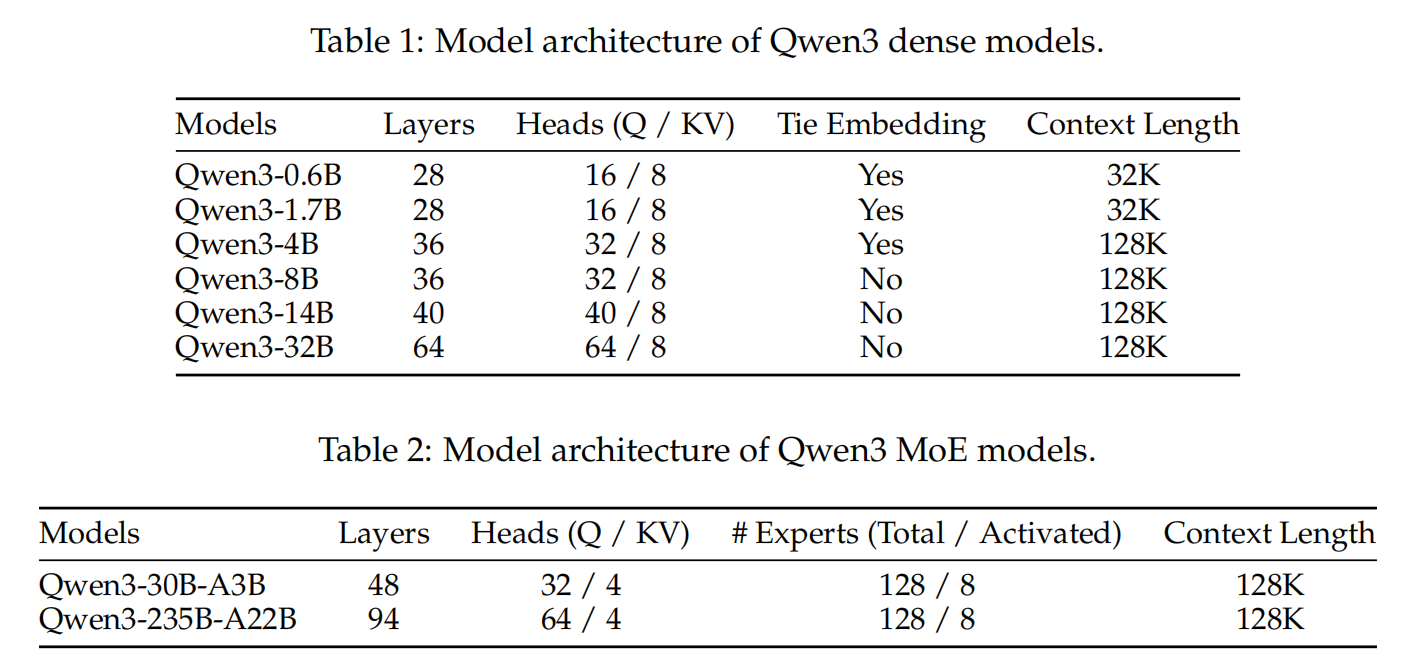
Dense 模型结构改进:
- GQA、SwiGLU、RoPE、RMSNorm with pre-normalization与Qwen2.5 相似。
- 移除了 Qwen2 中的 移除QKV偏置,减少模型复杂性,在注意力机制中引入 QK-Norm 来确保稳定训练。
MoE 模型结构改进:
| 改进点 | 描述 |
|---|---|
| 细粒度专家分割 | 增强模型的表达能力和效率。 |
| 全局批次负载均衡损失 | 鼓励专家专业化,提高模型整体性能。 |
| 移除共享专家 | 与Qwen2.5-MoE不同,Qwen3-MoE设计中排除了共享专家。 |
| 128个总专家,每个token激活8个专家 | 增加专家数量以提高模型的多样性和表现力。 |
Qwen3 模型使用 Qwen 的 tokenizer,byte-level BPE,词表大小 151669
预训练
预训练数据
预训练数据情况:
- 36万亿个标记,是Qwen2.5的两倍
- 包括多种语言和方言,总共支持119种语言,而Qwen2.5仅支持29种
- 包括高质量的文本,涵盖编程、STEM(科学、技术、工程和数学)、推理任务、书籍、多语言文本和合成数据等领域
数据收集方法:
- 使用Qwen2.5-VL模型对大量PDF文档进行文本识别,并通过Qwen2.5模型进行质量提升。
- 利用Qwen2.5、Qwen2.5-Math和Qwen2.5-Coder模型生成合成的文本数据,涵盖教科书、问答、指令和代码片段等格式。
此外,开发了一个多语言数据注释系统,标注超过30万亿个标记,涵盖教育价值、领域、安全和多语言等方面。通过详细的注释支持更有效的数据过滤和组合。
不同于之前在数据源或 domain 层面的优化数据组合的工作,通过带有细粒度标签的小模型上广泛的消融实验,在 instance-level 上对数据组合进行优化。
预训练阶段
qwen3经过 3 个阶段的预训练:
Qwen3的预训练分为三个阶段,每个阶段都有其特定的目标和策略:
-
通用阶段(General Stage, S1):建立广泛的语言知识和一般世界知识。使用超过30万亿个标记,覆盖119种语言和方言。序列长度:4096。模型在语言熟练度和一般知识方面得到充分预训练。
-
推理阶段(Reasoning Stage, S2):提高在科学、技术、工程、数学(STEM)和编码等领域的推理能力。增加STEM、编码、推理和合成数据的比例。序列长度:4096。加速学习率衰减,优化预训练语料库以提高推理能力。
-
长上下文阶段(Long Context Stage):扩展模型的最大上下文长度。收集高质量的上下文数据,将上下文长度从4,096扩展到32,768个标记。序列长度:32768。使用ABF技术增加RoPE的基础频率,引入YARN和Dual Chunk Attention以实现更长的上下文处理能力。
后训练
后训练的两个核心目标:
- 思考控制(Thinking Control)):整合“非思考”和“思考”两种模式,允许用户选择是否让模型进行推理。用户可以通过指定思考token的预算来控制思考过程的深度。
- 强到弱蒸馏(Strong-to-Weak Distillation):优化轻量级模型,通过从大型模型中提取知识来减少计算成本和开发工作量。包括离线蒸馏和在线蒸馏两个阶段,赋予轻量级模型基本的推理技能和模式切换能力。
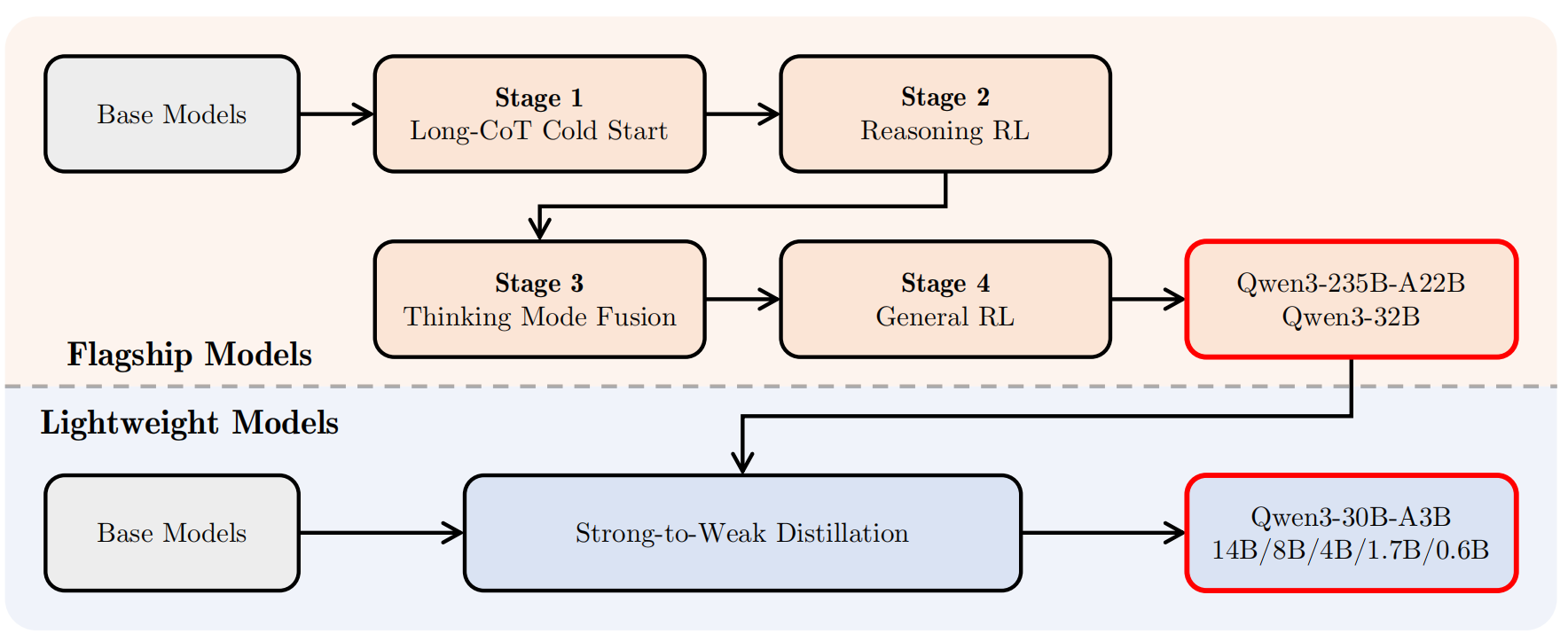
后训练pipline:
1. 长CoT冷启动
Long-CoT Cold Start目的是通过高质量数据集和精简训练流程,让模型初步掌握CoT推理能力。
数据集构建:
(1) Query 过滤(筛选高质量问题)
• 移除低质量 query:使用 Qwen2.5-72B-Instruct 识别并剔除:不易验证的 query(如含多个子问题、普通文本生成类问题)。 Qwen2.5-72B-Instruct 可直接回答的 query(无需 CoT 推理)。领域平衡:对 query 进行标注,确保数据集覆盖多个领域,避免偏差。
(2) Response 过滤(筛选高质量答案)
-
初步筛选:保留一个验证 query 集,用 QwQ-32B 生成 N 个候选 response。
-
人工评估:当 QwQ-32B 无法正确回答时,人工检查 response 的准确性,并过滤掉:
- 错误答案(最终结果错误)。
- 大量重复内容。
- 无充分推理的猜测。
- 思考内容与总结内容表现不一致(逻辑矛盾)。
- 不适当语言混合/风格变化。
- 疑似与验证集相似(防止数据泄露)。
-
严格筛选 positive Pass@N 的 query:进一步提高数据质量。
(3) 数据精选与训练
-
从精炼后的数据集中挑选 子集 进行 初始冷启动训练,植入基础推理模式。
-
控制数据量 & 训练步数,避免过度拟合,为后续 RL 阶段留出优化空间。
核心创新点 :数据集设计时已考虑 /think 和 /no_think 模式,使模型能灵活切换推理方式。在训练时,允许模型基于思考预算动态调整计算资源分配。
冷启动后,模型进入 Reasoning RL 阶段,利用 3995 个高质量 query-verifier 对 进行强化学习,进一步提升推理能力。
2.Reasoning RL
Reasoning RL 阶段,Qwen3 通过 高质量 query-verifier 对 和 RL优化,进一步提升模型的推理能力,使其在数学、代码、STEM 等复杂任务上表现更优。
Query-Verifier 设计标准
| 标准 | 说明 |
|---|---|
| 未在冷启动阶段使用过 | 避免数据重复,确保 RL 训练的数据多样性。 |
| 对冷启动模型是可学习的 | 确保模型在 RL 阶段仍有提升空间,避免过难或过易的问题。 |
| 尽可能具有挑战性 | 提高模型的推理能力,使其能处理更复杂的逻辑和计算任务。 |
| 涵盖广泛的子领域 | 确保模型在不同任务(如数学、代码、逻辑推理)上都能提升。 |
最终收集了 3995 个高质量的 query-verifier 对,用于 RL 训练。
RL 训练方法
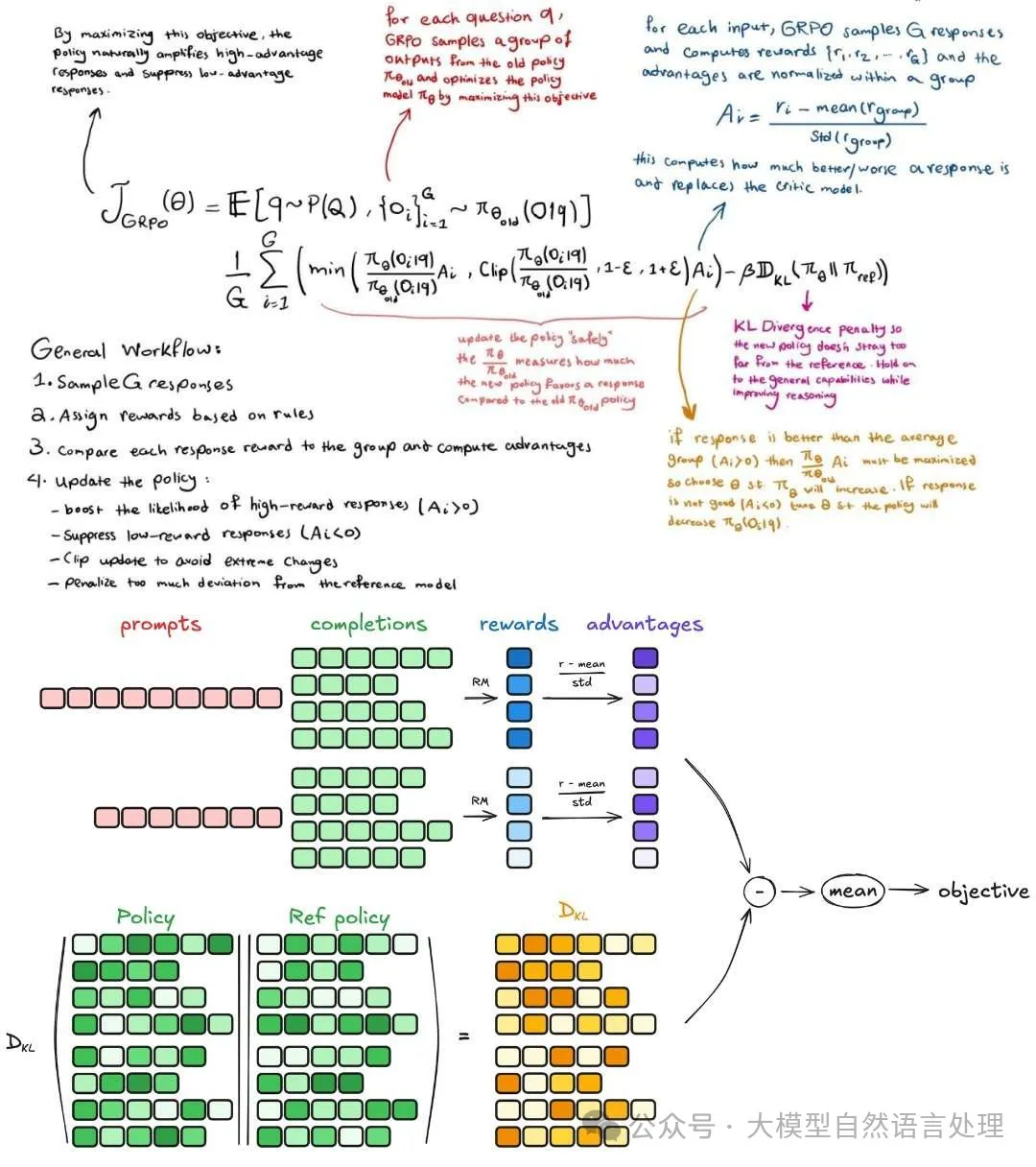
采用 GRPO 更新模型参数,并采用以下优化策略:
| 策略 | 说明 |
|---|---|
| 大 batchsize | 提高训练稳定性,减少训练波动。 |
| 大 rollout | 增加样本多样性,提升泛化能力。 |
| off-policy 训练 | 提高样本效率,减少计算资源消耗。 |
此外,Qwen3 还解决了探索(exploration)与利用(exploitation) 的平衡问题: 控制模型熵的稳定增长或保持稳定,确保训练过程不会过早收敛或陷入局部最优。
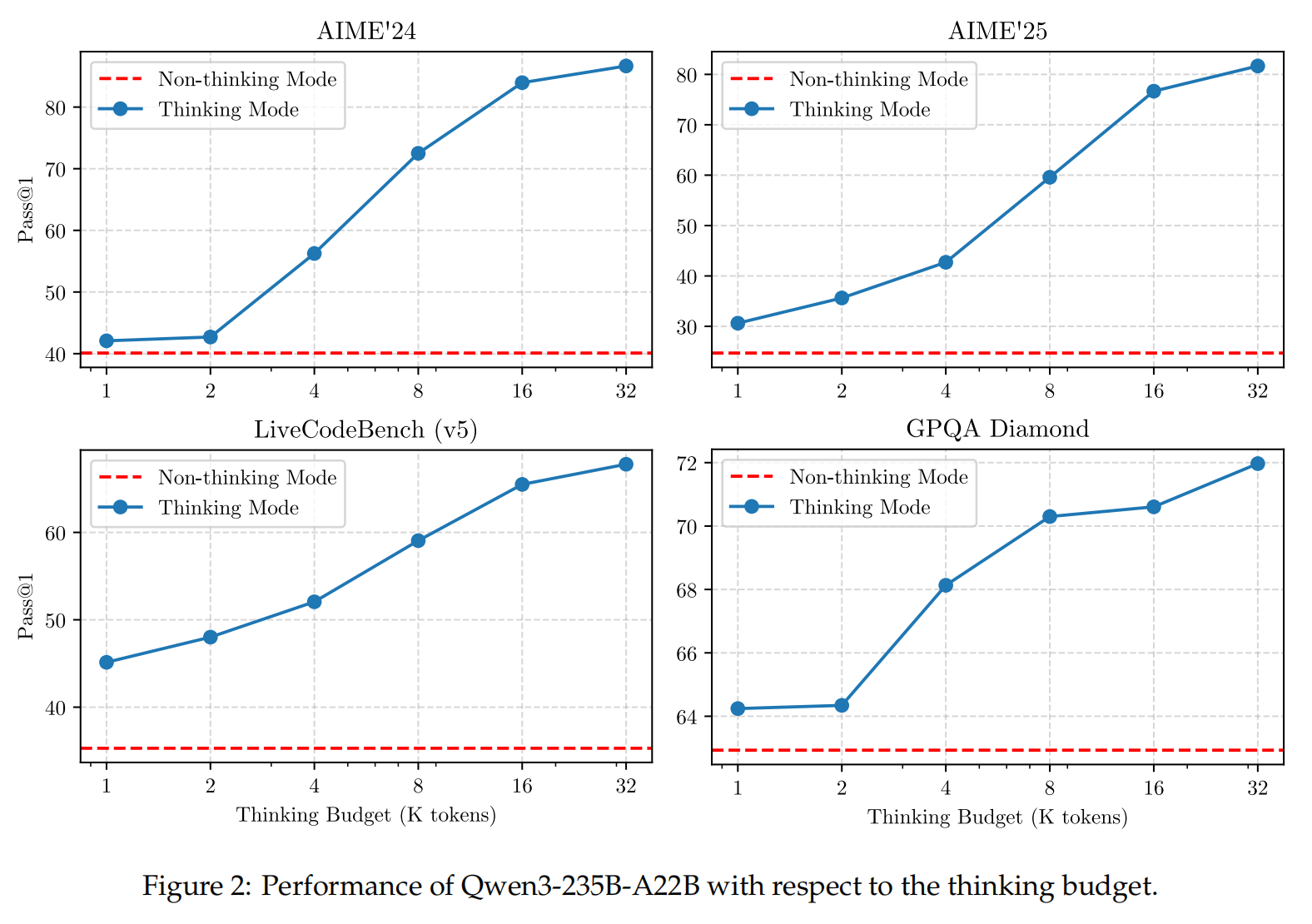
效果: 无需手动调整超参数,训练过程中 reward 和验证集表现持续提升。 Qwen3-235B-A22B 在 AIME’24 的得分从 70.1 提升至 85.1,仅用了 170 步 RL 训练。
3.Thinking Mode Fusion(思考模式融合)
核心目标 :将 non-thinking(快速响应)能力整合到 thinking(复杂推理)模型中,使开发者能够动态控制模型的推理行为,从而在不同任务需求下灵活切换模式,并保持高性能。
方法
(1) 继续 SFT(监督微调)
-
基于 Reasoning RL 模型进行 SFT,进一步优化模型的推理和响应能力。
-
数据构造方式:
-
Thinking 数据:由第一阶段的 query 拒绝采样得到(确保高质量)。
-
Non-thinking 数据:涵盖多样化任务(代码、数学、指令遵循、多语言、创意写作、问答、角色扮演等),并增加 翻译任务比例(提升低资源语言性能)。
-
数据质量评估:采用自动化生成的 checklists 确保数据质量。
-
(2) Chat Template 设计
-
引入
/think和/no_think标志,使用户能动态控制模型的推理模式: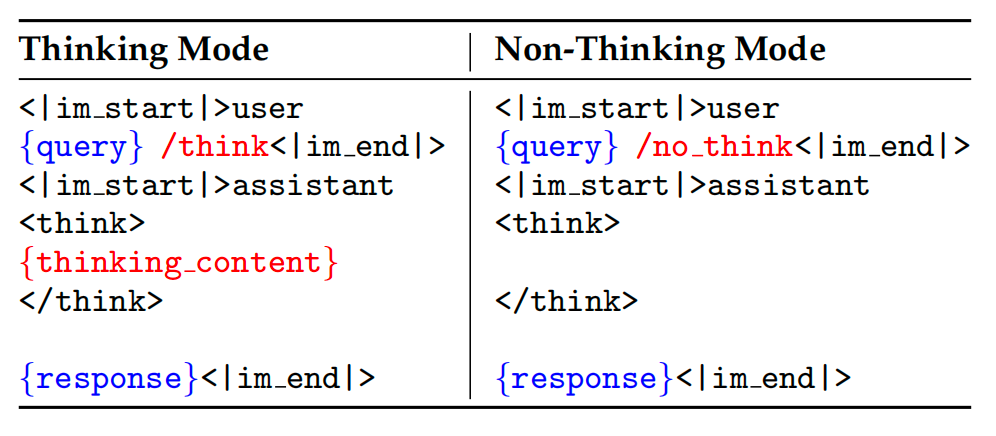
-
/think:启用推理模式(适合复杂任务)。 -
/no_think:启用快速响应模式(适合简单任务)。
-
-
默认模式:默认使用 thinking 模式,但允许灵活调整。
-
多轮对话支持:在复杂对话中,可随机插入多个
/think和/no_think标志,模型按 最后遇到的标志 决定当前模式。
(3) Thinking Budget 机制
Thinking Mode Fusion 的一个额外优势是,一旦模型学会了以 non-thinking 和 thinking 两种模式进行回应,就自然发展出处理中间情况的能力——基于不完整的思考生成 response。为实现对模型思考过程的预算控制提供基础。当模型思考长度达到用户定义的阈值时,手动停止思考过程,并插入停止思考指令:“Considering the limited time by the user, I have to give the solution based on the thinking directly now.\n.\n\n“。模型会基于此时积累的推理生成最终 response。这一能力没有经过明确训练,而是应用 thinking mode fusion 后自然出现的。
4.General RL(通用强化学习)阶段
核心目标:全面提升Qwen3模型在不同场景下的能力与稳定性,使其能够适应各种复杂任务需求,提供更优质的用户体验。
复杂的Reward System设计:
构建了一个涵盖超过20个不同任务的复杂奖励系统,每个任务都有定制化的评分标准,主要针对以下核心能力进行提升:
(1) 指令遵循:确保模型能准确解读并遵循用户指令。包括对内容、格式、长度以及结构化输出使用等方面的要求。目标是提供符合用户预期的回应。
(2) 格式遵循:期望模型遵守特定的格式规范。例如,根据/think和/no-think标志在思考与非思考模式之间切换。一致使用指定的标记来分离最终输出中的思考和响应部分。
(3) 偏好对齐:关注提高模型的有用性、参与度和风格。最终目标是提供更加自然和令人满意的用户体验。
(4) Agent能力:涉及训练模型通过指定的接口正确调用工具。在RL rollout期间,模型被允许执行完整的多轮互动周期,并获得真实环境执行的反馈。提高其在长期决策任务中的表现和稳定性。
(5) 特定场景能力:在更专业的场景中设计针对具体情境的任务。例如,在RAG(检索增强生成)任务中,结合奖励信号来指导模型生成准确且符合上下文的response。最小化产生幻觉的风险。
3. 多样化的奖励类型
为上述任务提供反馈,使用了三种不同类型的奖励:
(1) Rule-based Reward:基于规则的奖励机制。可以高准确性地评估模型输出的正确性。 防止reward hacking等问题。
(2) Model-based Reward with Reference Answer:给每个query提供一个参考答案。使用Qwen2.5-72B-Instruct基于参考答案给模型的response打分。允许更灵活地处理多样化任务,无需严格的格式命令。避免了rule-based reward的假阴性问题。
(3) Model-based Reward without Reference Answer:利用人类偏好数据,训练一个Reward Model。为每个response提供标量分数。更加灵活地适应不同任务和场景的需求。
5.Strong-to-Weak Distillation(强到弱蒸馏)
核心目标:利用大模型(教师模型)的知识,优化小模型(学生模型)的性能,使其在计算资源有限的情况下,仍能保持较高的推理能力和多任务适应性。
-
5个Dense模型(0.6B、1.7B、4B、8B、14B)
-
1个MoE模型(Qwen3-30B-A3B)
蒸馏流程
(1) Off-policy Distillation(离线蒸馏) :利用大模型(教师模型)在 /think 和 /no_think 模式下的输出,初始化小模型的能力。
-
将教师模型在不同模式下的 response 作为“软标签”(soft labels)。
-
学生模型通过最小化与教师模型输出的 KL 散度(Kullback-Leibler Divergence),学习大模型的推理模式。
(2) On-policy Distillation(在线蒸馏) :进一步优化学生模型,使其更适应特定任务。
-
学生模型生成 on-policy 数据(即学生模型自己采样生成的数据)。
-
使用教师模型(Qwen3-32B 或 Qwen3-235B-A22B)的 logits 作为参考,调整学生模型的输出分布。
-
最小化 KL 散度,使小模型的预测更接近大模型。
结果
-
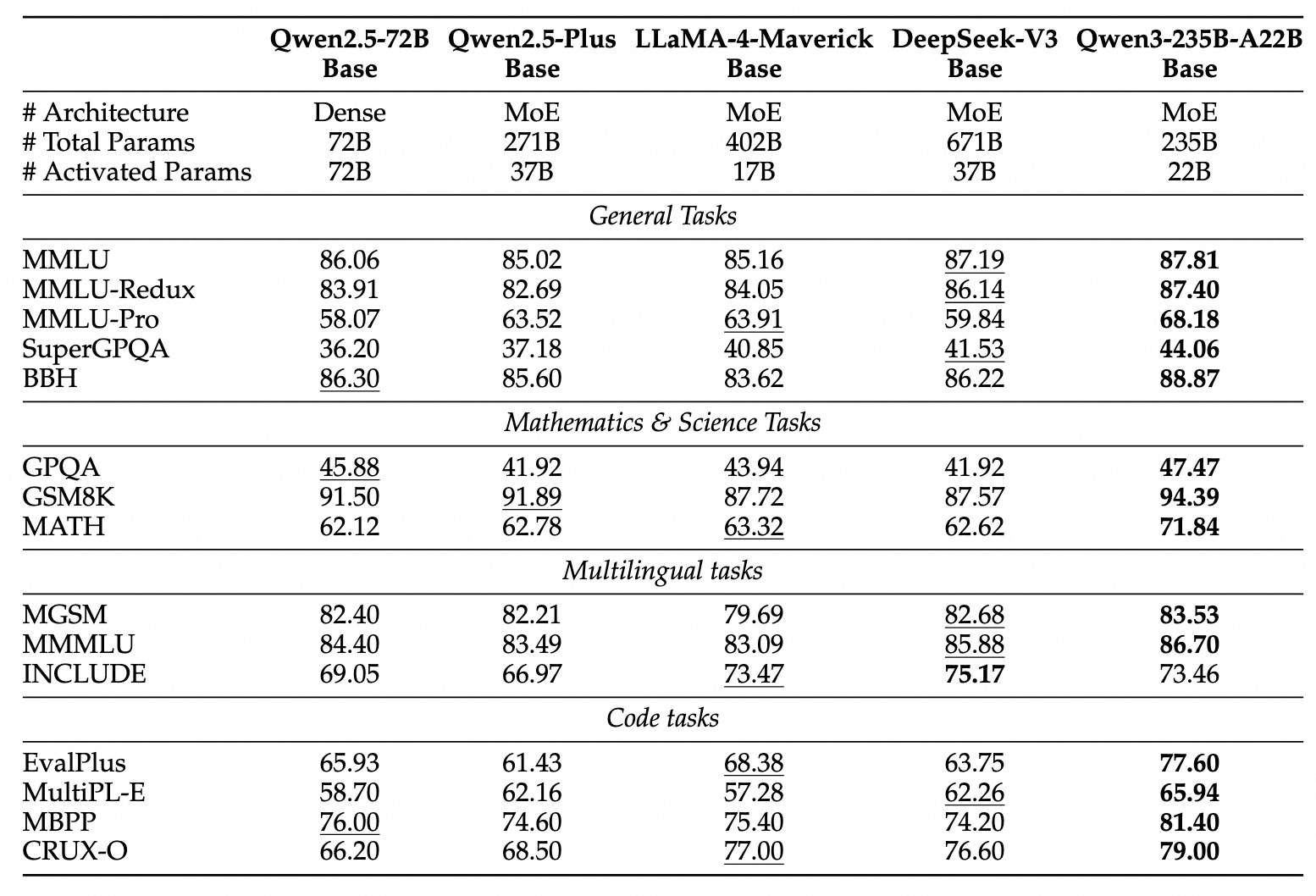
Qwen3 Dense Base 模型:在类似规模下,性能与 Qwen2.5 更大规模模型相当。
-
Qwen3 MoE Base 模型: 仅用 1/5 的激活参数 就能达到与 Dense 模型相似的性能。 即使只有 Qwen2.5 Dense 模型 1/10 的激活参数,仍能保持可比性能。
实验评测的一些表
表太多,看原文