Ascend的aclgraph(七)AclConcreteGraph:capture_begin
1 回顾
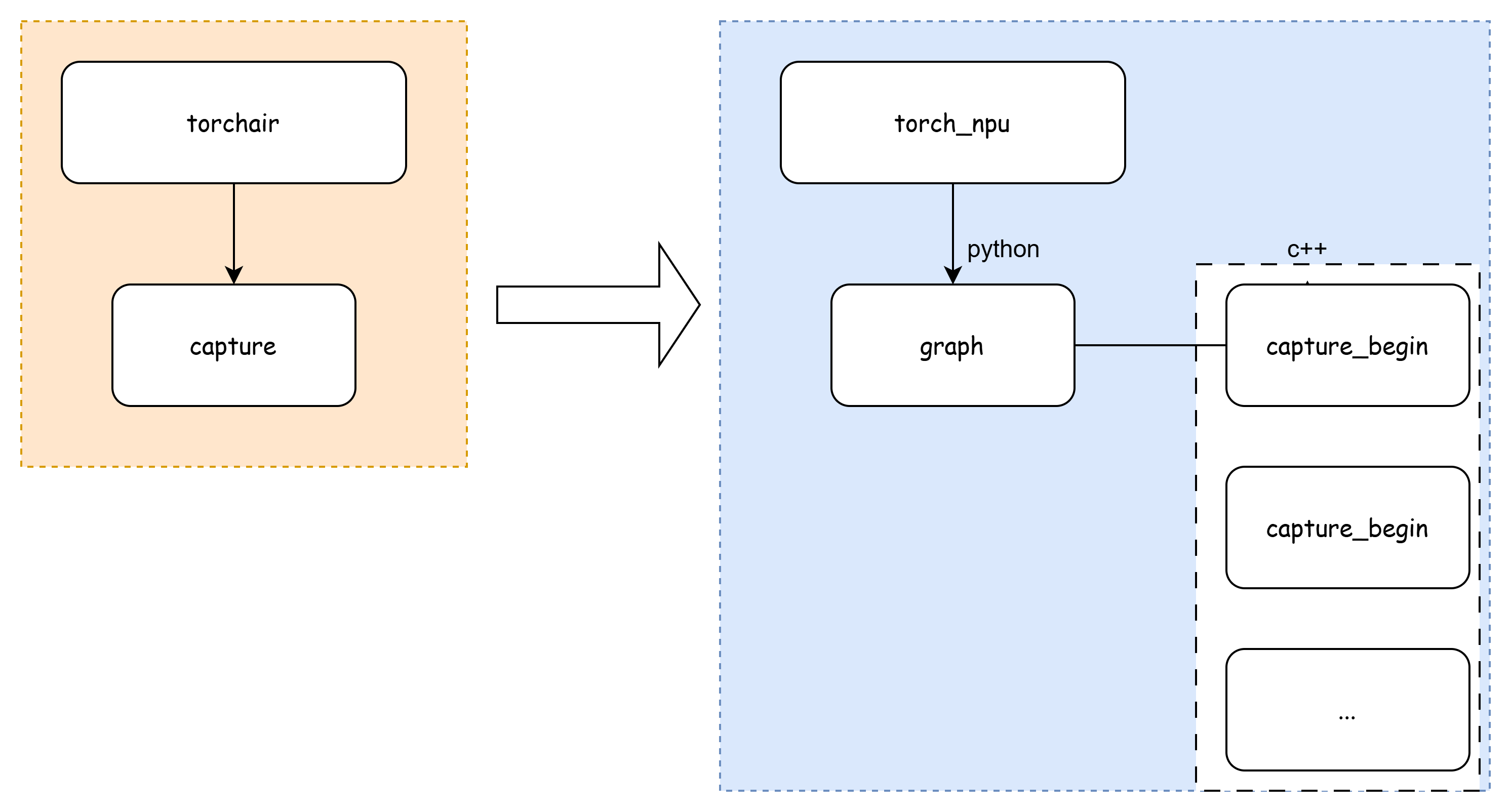
在上一章Ascend的aclgraph(六)AclConcreteGraph中提到了capture_begin和capture_end两个函数,这2个函数是pybind形式,调用到torch_npu中去执行。
大概流程图如下:
def __enter__(self):# Free as much memory as we can for the graphtorch.npu.synchronize()gc.collect()torch.npu.empty_cache()# Stackoverflow seems comfortable with this patternself.stream_ctx.__enter__()self.npu_graph.capture_begin(*self.pool, capture_error_mode=self.capture_error_mode)def __exit__(self, exc_type, exc_value, traceback):self.npu_graph.capture_end()self.stream_ctx.__exit__(exc_type, exc_value, traceback)
2 capture_begin
在torchair进入torch_npu之前,首先进行了算子同步、python的垃圾回收、缓存清理等操作,
然后调用进入到torch_npu的c++侧,
def("capture_begin",[](c10_npu::NPUGraph& self,std::optional<c10_npu::MempoolId_t> pool_opt,std::string capture_error_mode) {aclmdlRICaptureMode capture_mode;c10_npu::MempoolId_t pool = pool_opt.has_value()? pool_opt.value() : c10_npu::MempoolId_t{0, 0};if (capture_error_mode == "global") {capture_mode = aclmdlRICaptureMode::ACL_MODEL_RI_CAPTURE_MODE_GLOBAL;} else if (capture_error_mode == "thread_local") {capture_mode = aclmdlRICaptureMode::ACL_MODEL_RI_CAPTURE_MODE_THREAD_LOCAL;} else if (capture_error_mode == "relaxed") {capture_mode = aclmdlRICaptureMode::ACL_MODEL_RI_CAPTURE_MODE_RELAXED;} else {TORCH_CHECK(false,"Unknown capture error mode. Expected `global`, `thread_local`, or `relaxed`, got ",capture_error_mode);}return self.capture_begin(pool, capture_mode);},py::arg("pool"),py::arg("capture_error_mode"),py::call_guard<py::gil_scoped_release>())
capture_begin首先执行的是上述的lamda表达式中的内容,主要是对capture_mode进行了判断,还记得这几个mode模式之间的区别不?
该参数用于指定图形捕获流中的aclmdlRICaptureMode。可以是“全局”、“线程本地”或“宽松”。在NPU图形捕获期间,某些操作(如npuMalloc)可能会不安全。
- “全局”将在其他线程中执行的操作上引发错误,
- “线程本地”仅会在当前线程中执行的操作上引发错误,
- “宽松”不会在操作上引发错误。
除非您熟悉aclmdlRICaptureMode_,否则请勿更改此设置。
然后就正式进入到c++侧capture_begin函数,首先结合代码
void NPUGraph::capture_begin(MempoolId_t pool, aclmdlRICaptureMode capture_mode)
{static const auto _task_queue_enable = c10_npu::option::OptionsManager::GetTaskQueueEnable();TORCH_CHECK(_task_queue_enable != 2,"Do not support TASK_QUEUE_ENABLE = 2 during NPU graph capture, please ""export TASK_QUEUE_ENABLE=1/0.",PTA_ERROR(ErrCode::NOT_SUPPORT));TORCH_CHECK(!has_graph_exec_,"This NPUGraph instance already owns a captured graph. ""To capture a new graph, create a new instance.");auto stream = c10_npu::getCurrentNPUStream();TORCH_CHECK(stream != c10_npu::getDefaultNPUStream(),"NPU graphs must be captured on a non-default stream. ""(However, after capture, it's ok to replay them on the ""default stream.)");capture_stream_ = stream;capture_dev_ = c10_npu::current_device();if (pool.first != 0 || pool.second != 0) {// Either value being nonzero means the user supplied a pool to share.// But only one should be nonzero.// If pool was created by another graph's capture_begin, first should be nonzero.// If pool was created by graph_pool_handle, second should be nonzero.TORCH_INTERNAL_ASSERT(!(pool.first && pool.second));mempool_id_ = pool;} else {// User did not ask us to share a mempool. Create graph pool handle using is_user_created=false.// Sets just the first value, to distinguish it from MempoolId_ts created by graph_pool_handle().auto mempool = c10_npu::MemPool({}, false);mempool_id_ = mempool.id();TORCH_INTERNAL_ASSERT(mempool_id_.first > 0);}// Addendum: beginAllocateStreamToPool is now called before cudaStreamBeginCapture to prevent an// autograd thread's free() call triggering an invalid cudaEventRecord in the caching allocator// due to the capture status being updated _after_ a capture had already started.c10_npu::NPUCachingAllocator::beginAllocateToPool(capture_dev_, mempool_id_, [this](aclrtStream stream) {aclmdlRICaptureStatus status;aclmdlRI model_ri;NPU_CHECK_ERROR(c10_npu::acl::AclmdlRICaptureGetInfo(stream, &status, &model_ri));return status == aclmdlRICaptureStatus::ACL_MODEL_RI_CAPTURE_STATUS_ACTIVE && model_ri == model_ri_;});// At this point, any NCCL watchdogs should be aware that we are in capture mode// and therefore should not enqueue any additional work that could be event-queried.// We still must wait on any existing work that has not been cleaned up.while (num_pending_event_queries()) {TORCH_WARN_ONCE("Waiting for pending NCCL work to finish before starting graph capture.");std::this_thread::sleep_for(std::chrono::milliseconds(kSynchronizeBusyWaitMillis));}// cudaStreamCaptureModeGlobal is the most conservative option to// prevent potentially unsafe CUDA API calls during capture.NPU_CHECK_ERROR(c10_npu::acl::AclmdlRICaptureBegin(capture_stream_, capture_mode));aclmdlRICaptureStatus status;NPU_CHECK_ERROR(c10_npu::acl::AclmdlRICaptureGetInfo(stream, &status, &model_ri_));TORCH_INTERNAL_ASSERT(status == aclmdlRICaptureStatus::ACL_MODEL_RI_CAPTURE_STATUS_ACTIVE);
}
给出流程图

mempool是图capture用来做显存复用的,每次cupture都有一个PrivatePool对象。PrivatePool对象可以被多个capture graph共用,使用mempool_id来管理。
// Called by NPUGraph::capture_begin
void beginAllocateToPool(MempoolId_t mempool_id, std::function<bool(aclrtStream)> filter)
{std::lock_guard<std::recursive_mutex> lock(mutex);auto it = graph_pools.find(mempool_id);if (it == graph_pools.end()) {// mempool_id does not reference an existing pool. Make a new pool for// this capture.graph_pools.emplace(mempool_id, std::make_unique<PrivatePool>());} else {// mempool_id references an existing pool, which the current capture will// share. Check this pool is live (at least one other capture already// references it).TORCH_INTERNAL_ASSERT(it->second->use_count > 0);it->second->use_count++;}for (auto it2 = captures_underway.begin(); it2 != captures_underway.end(); ++it2) {TORCH_CHECK(it2->first != mempool_id, "beginAllocateToPool: already recording to mempool_id");}captures_underway.emplace_back(mempool_id, std::move(filter));
}
captures_underway用来继续当前正在图capture中使用到的mempool_id。
captures_underway 用于跟踪我们是否将某些分配重定向到特定池。
// 大多数情况下它是空的,在这种情况下,malloc 可以避免在热路径上调用 aclrtStreamGetCaptureInfo。
num_pending_event_queries是在图开始capture之前,等待所有nccl的任务完成。
AclmdlRICaptureBegin函数核心的cupture函数
aclError AclmdlRICaptureBegin(aclrtStream stream, aclmdlRICaptureMode mode)
{typedef aclError (*AclmdlRICaptureBegin)(aclrtStream, aclmdlRICaptureMode);static AclmdlRICaptureBegin func = nullptr;if (func == nullptr) {func = (AclmdlRICaptureBegin) GET_FUNC(aclmdlRICaptureBegin);}TORCH_CHECK(func, "Failed to find function aclmdlRICaptureBegin", PTA_ERROR(ErrCode::NOT_FOUND));return func(stream, mode);
}
GET_FUNC的宏定义如下:
#define GET_FUNC(funcName) \GET_FUNCTION(libascendcl, funcName)
整个代码的逻辑就是:
- 先定义了一个函数指针类型 AclmdlRICaptureBegin,它指向一个接受两个参数(一个 aclrtStream 和一个 aclmdlRICaptureMode)并返回一个 aclError 值的函数。
- 然后定义了一个函数级的静态成员变量AclmdlRICaptureBegin
- 尝试通过
GET_FUNC(aclmdlRICaptureBegin) 动态加载 aclmdlRICaptureBegin 函数,并将其地址赋值给 func。也就是从libascendcl.so中查找aclmdlRICaptureBegin的函数 - 然后调用func执行具体的函数。
说白了,关键函数还是藏在libascendcl.so里面。
先弄明白aclmdlRICaptureBegin是什么时候注册进去的?
#define REGISTER_LIBRARY(soName) \auto library_##soName = \::std::unique_ptr<c10_npu::option::FunctionLoader>(new c10_npu::option::FunctionLoader(#soName)); \static c10_npu::option::register_function::FunctionRegisterBuilder \register_library_##soName(#soName, library_##soName);#define REGISTER_FUNCTION(soName, funcName) \static c10_npu::option::register_function::FunctionRegisterBuilder \register_function_##funcName(#soName, #funcName);#define GET_FUNCTION(soName, funcName) \c10_npu::option::register_function::FunctionRegister::GetInstance()->Get(#soName, #funcName);
这里看到了REGISTER_FUNCTION宏定义。根据小编的理解,先给出流程图:

这里关注FunctionLoader这个对象,弄明白为什么registry这个map里面存储的不是函数对象,而是需要一个类对象(智能指针形式)。
先给出FunctionLoader的定义:
class FunctionLoader {
public:/**ctr*/explicit FunctionLoader(const std::string& filename);/**dectr*/~FunctionLoader();/**set function name*/void Set(const std::string& name);/**get function address by function name.*/void* Get(const std::string& name);
private:mutable std::mutex mu_;std::string fileName;void* handle = nullptr;mutable std::unordered_map<std::string, void*> registry;
}; // class FunctionLoader
发现,真正存储函数指针的地方,应该是FunctionLoader 中的registry。Set函数
void FunctionLoader::Set(const std::string &name)
{this->registry[name] = nullptr;
}
Set函数执行的时候,在registry中存储了对应的key值,value设置为nullptr。
Get函数
void *FunctionLoader::Get(const std::string &name)
{// 缓存if (this->handle == nullptr) {auto handle = dlopen(this->fileName.c_str(), RTLD_LAZY | RTLD_GLOBAL);if (handle == nullptr) {AT_ERROR(dlerror());return nullptr;}this->handle = handle;}auto itr = registry.find(name);if (itr == registry.end()) {AT_ERROR("function(", name, ") is not registered.");return nullptr;}if (itr->second != nullptr) {return itr->second;}auto func = dlsym(this->handle, name.c_str());if (func == nullptr) {return nullptr;}this->registry[name] = func;return func;
}
先通过dlopen打开了对应的so,如上就是libascendcl.so,并缓存了对应的handle(在FunctionLoader析构的时候调用dlclose)
然后通过dlsym在so中去查找对应的函数名称。
读到这里,还没弄明白aclmdlRICaptureBegin到底做的是什么事情?
在昇腾官网上搜索到如下信息:
https://www.hiascend.com/document/detail/zh/canncommercial/81RC1/apiref/appdevgapi/aclcppdevg_03_1782.html
函数原型
aclError aclmdlRICaptureBegin(aclrtStream stream, aclmdlRICaptureMode mode)

接口解释
开始捕获Stream上下发的任务。
在aclmdlRICaptureBegin和aclmdlRICaptureEnd接口之间,所有在指定Stream上下发的任务不会立即执行,而是被暂存在系统内部模型运行实例中,只有在调用aclmdlRIExecuteAsync接口执行模型推理时,这些任务才会被真正执行,以此减少Host侧的任务下发开销。任务执行完毕后,若无需再使用内部模型,可调用aclmdlRIDestroy接口及时销毁该资源。
aclmdlRICaptureBegin和aclmdlRICaptureEnd接口要成对使用,且两个接口中的Stream应相同。在这两个接口之间,可以调用aclmdlRICaptureGetInfo接口获取捕获信息,调用aclmdlRICaptureThreadExchangeMode接口切换当前线程的捕获模式。此外,在调用aclmdlRICaptureEnd接口之后,还可以调用aclmdlRIDebugPrint接口打印模型信息,这在维护和测试场景下有助于问题定位。
在aclmdlRICaptureBegin和aclmdlRICaptureEnd接口之间捕获的任务,若要更新任务(包含任务本身以及任务的参数信息),则需在aclmdlRICaptureTaskGrpBegin、aclmdlRICaptureTaskGrpEnd接口之间下发后续可能更新的任务,给任务打上任务组的标记,然后在aclmdlRICaptureTaskUpdateBegin、aclmdlRICaptureTaskUpdateEnd接口之间更新任务的输入、输出信息。
说明
在aclmdlRICaptureBegin和aclmdlRICaptureEnd接口之间捕获到的任务会暂存在系统内部模型运行实例中,随着任务数量的增加,以及通过Event推导、内部任务的操作,导致更多的Stream进入捕获状态,Stream资源被不断消耗,最终可能会导致Stream资源不足(Stream数量限制请参见aclrtCreateStream),因此需提前规划好Stream的使用、关注捕获的任务数量。
这里也说明了stream管理,在mempool使用的重要性。
3 小结
最终device侧如何根据aclmdlRICaptureBegin和aclmdlRICaptureEnd捕捉,存储相关的节点,当前是没有对外代码说明的,无从看起。但是能知道,算子的执行信息都是在device侧的,并没有在host上留下信息,那么跟以前的FX graph又是什么关系呢?先记住这些疑问,后续继续探讨。下一篇章,看下capture_end又做了些什么事情。