Redis实现-优惠卷秒杀(基础版本)

(一)全局唯一ID
一、全局ID生成器
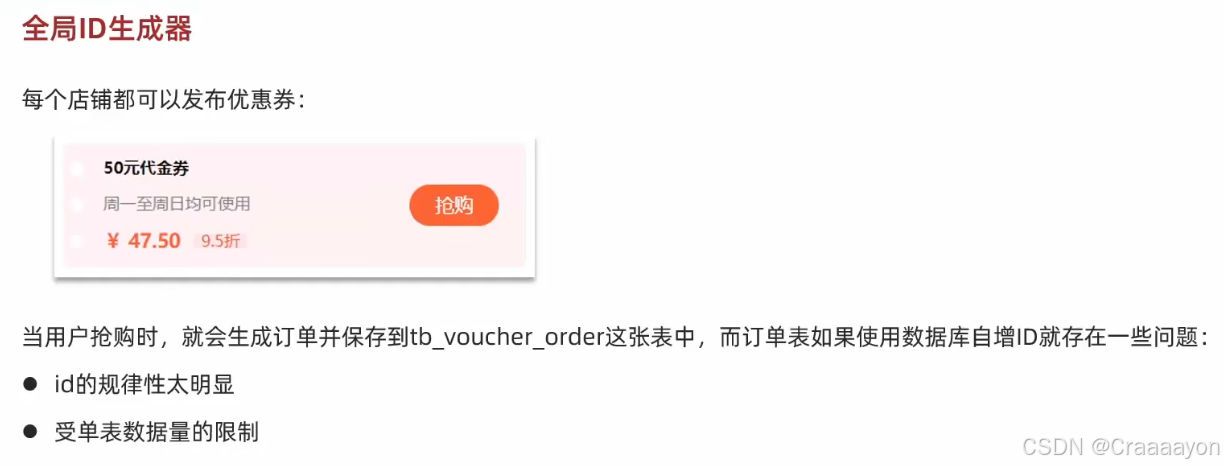
可以看到在优惠卷订单表中的主键id并没有设置Auto increment自增长
假如未来订单量达到数亿单,单表无法保存如此多数据,就需要对其进行分表存储(分布式)。假如每张表都采用自增长,各自从1开始自增,那么这个id就一定会出现重复,而从业务角度考虑,订单id都应当是独立且唯一的,那么也就会出现危险。也就需要去用到全局ID生成器。
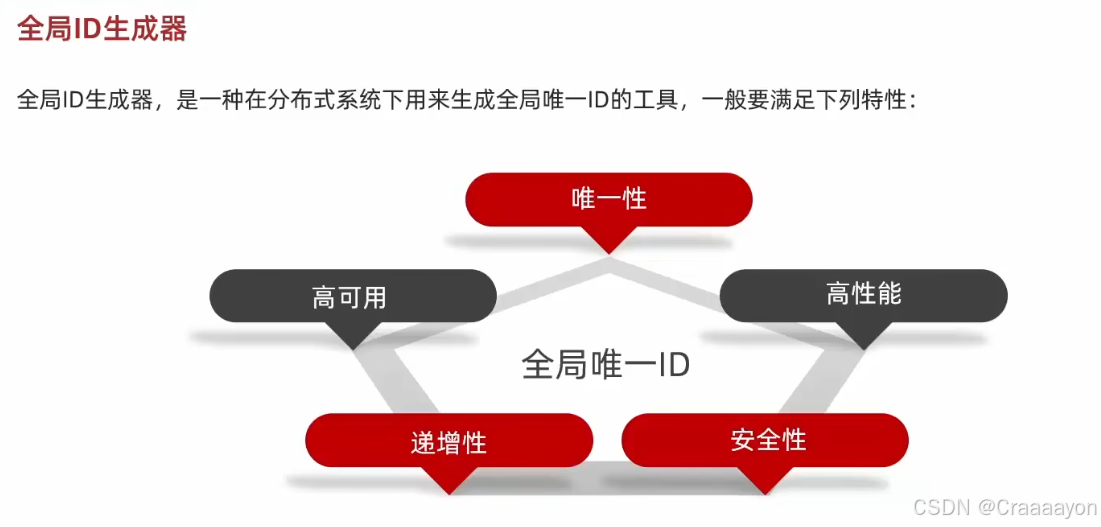
- 唯一性
Redis当中的String数据结构有一种自增且唯一特性的命令increm。因为Redis是独立于MySQL数据库之外的,无论有几个不同数据库几张不同的表,Redis都只有一个,这时当所有人来访问Redis时,它的自增ID一定是唯一的。 - 高可用
将来讲解Redis的集群方案、主从方案、哨兵方案都可以确保Redis的高可用性。 - 高性能
Redis的数据就是存储在内存当中,是以高性能著称的。 - 递增性
Redis的自增方案就能保证数据的递增性、连续性。 - 安全性
假如Redis直接采用这种低端自增方案,那么就会与MySQL数据库一样不存在安全性(因为太容易被猜测出规律),所以在使用increm全局自增ID时不能直接把这个数值用来当作ID,而是拼接其他信息来减弱规律性。
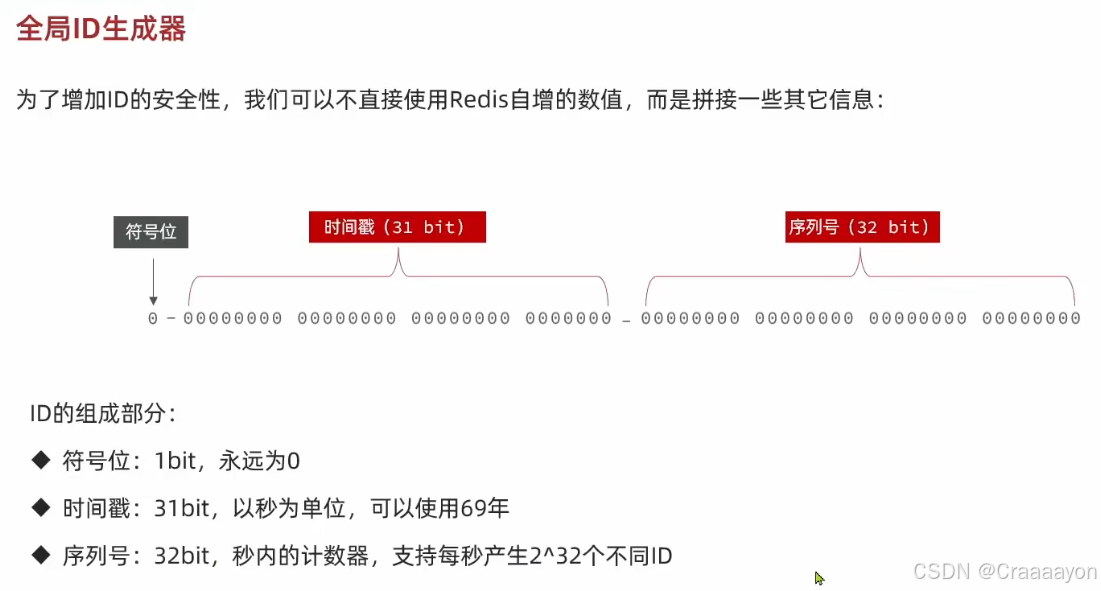
为了提高数据库性能,id会采用数值类型(也就是java中的Long型)。时间戳用于增加ID复杂性,长度为31位是因为将来要以秒为单位,定义一个初始时间至当下时间的时间差,31位能够存储21亿个单位,也就是接近69年,已经足够我们使用了。假如在一秒内生成多个订单需要生成多个ID,那么就会去自增后面的32位序列号,也就是Redis自增的值。
- Redis并不是全局唯一ID的唯一实现方案,还会有很多其他的方案。
二、Redis实现全局唯一ID
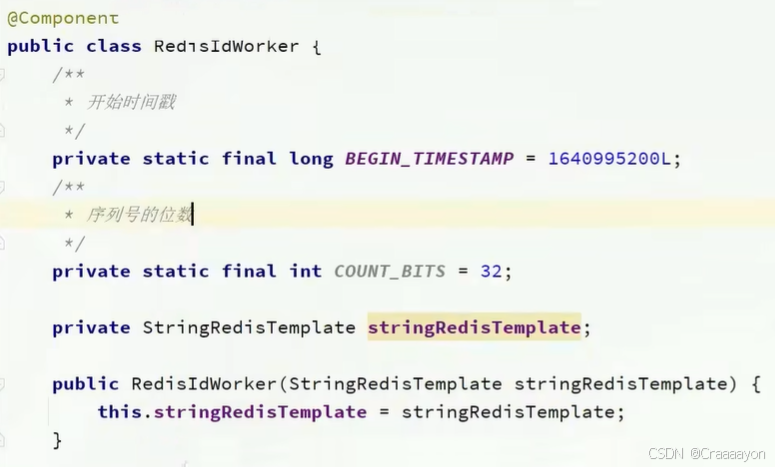
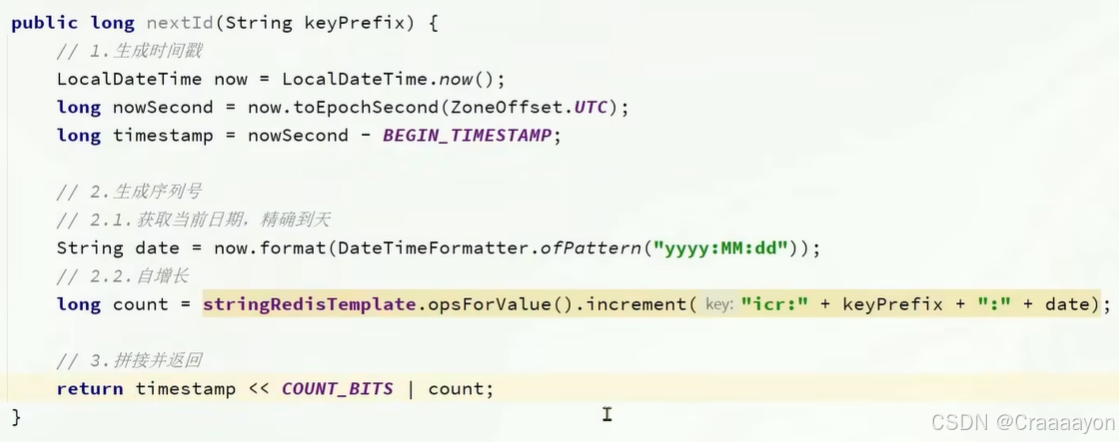
- 为什么需要引入一个keyPrefix参数:
该ID的生成策略是基于Redis自增长的,而我们也需要有一个key来对应该值,不同业务会有不同的key也就不能都去使用同一个自增长ID,也就是需要有一个前缀来区分不同业务。 - id生成策略也就是我们的核心业务-生成时间戳与序列号

- 为什么需要在key中拼接动态日期字符串:
若将key值写死,那么就代表整个业务永远采用同一个key来做自增长,也就是说无论该业务是经历了多少年,使用的永远是同一个key值,随着业务逐渐发展,值会越来越大。而我们知道,Redis中该自增值的上限是2的64次方,虽然该值看似足够大永远不会触及,但是它也是永远存在这个上限的,而且在key的生成策略当中用于记录序列号的值只有32个bit,这个值是很有可能被超过的。所以说我们不能永远使用同一个key,可以考虑在key值中拼接上当天的日期值,这样可以实现每天刷新value值上限,同时也更方便统计每天的记录数量。 - 为什么要将timestamp左移并且与count值进行或运算
因为我们要想生成的全局id的最后32位都应当为从Redis当中得到的自增值,而当前仅有的是时间戳值,所以我们需要将时间戳值左移32位来空出摆放自增值的空间。并且因为或运算的效果是只要当前位置上的数字不为0即可直接赋值,所以这里与count值进行或运算就是相当于将count值直接赋值到序列号位的数字上,就能实现一个拼接的效果。
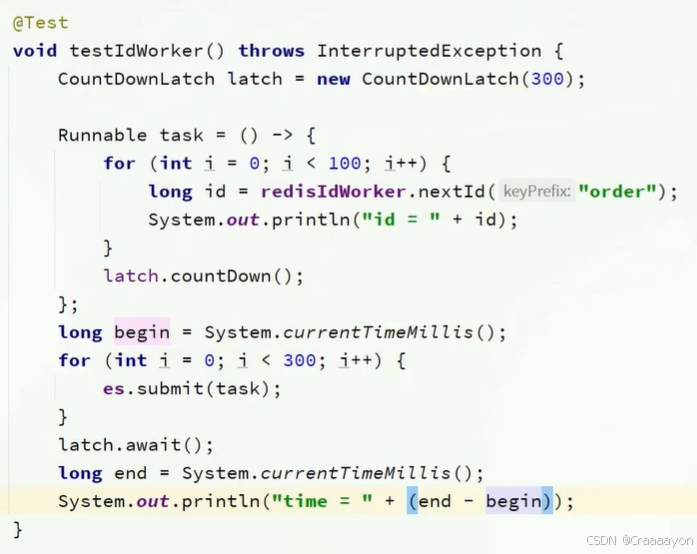
三、单元测试
测试在并发情况下生成id的性能以及值的情况,并且记录运行时间,因为使用的线程池是异步的,需要用CountDownLatch来记录每一条线程的执行时间并打印总耗费时间。

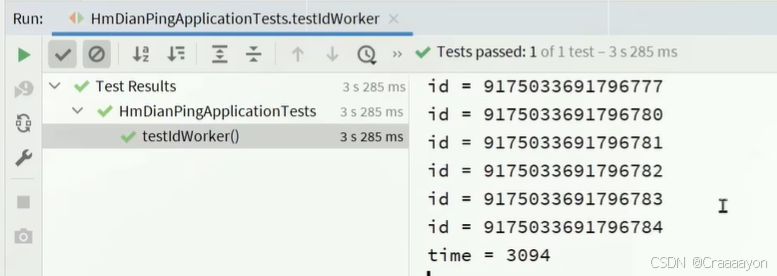
最终得到生成的全局ID以及总耗费时间,并且可以在Redis中查看到生成的id个数达30000个:
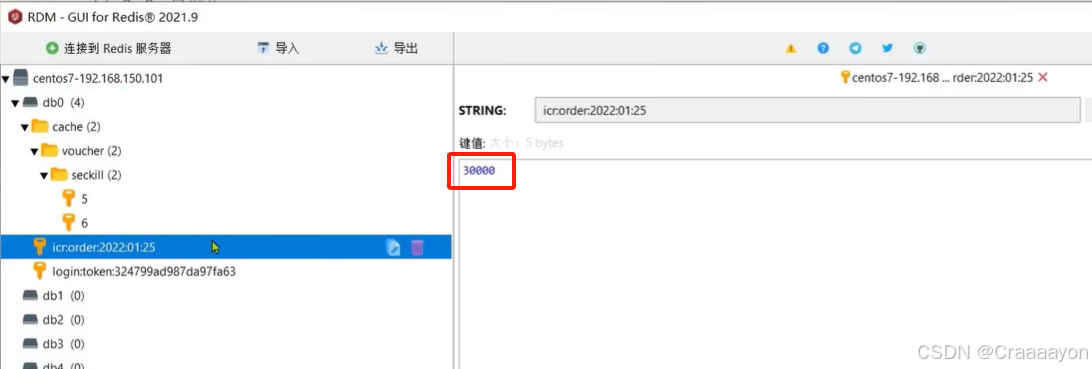
四、总结

(二)实现优惠卷秒杀下单
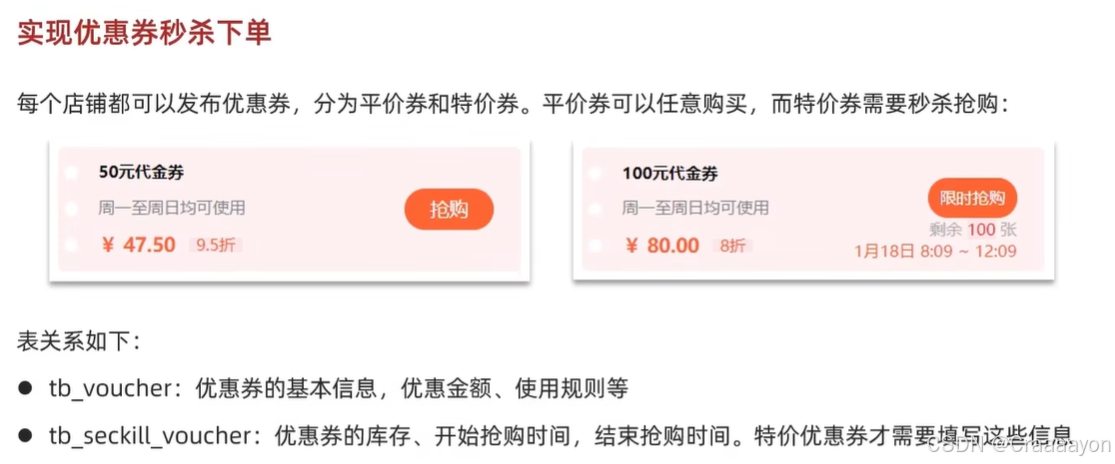
一、添加优惠卷




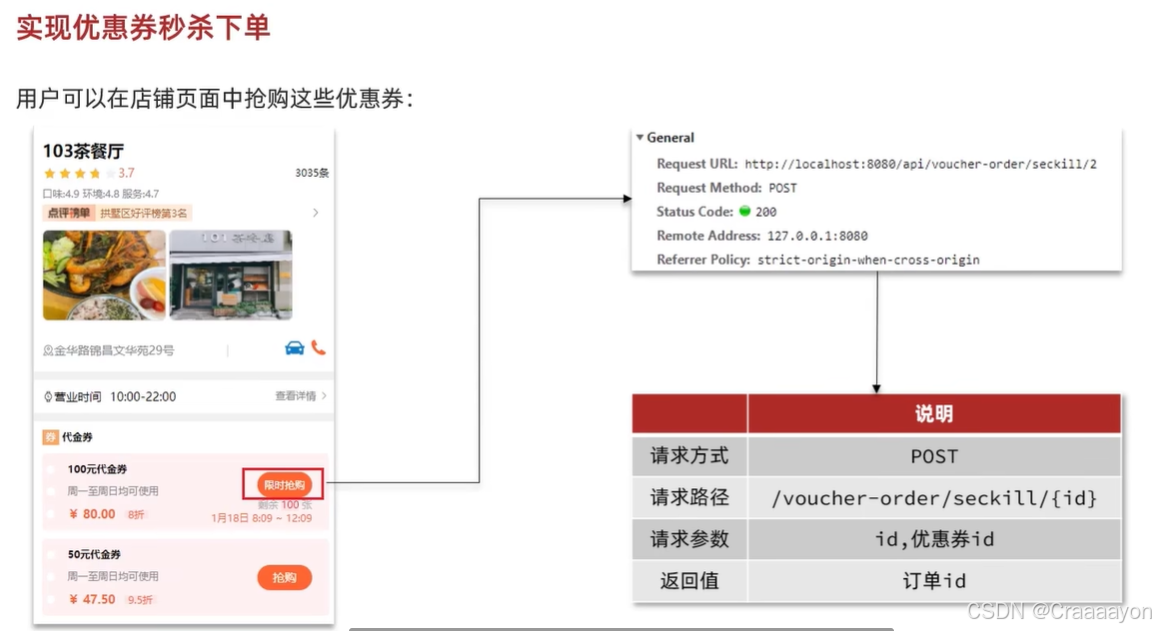
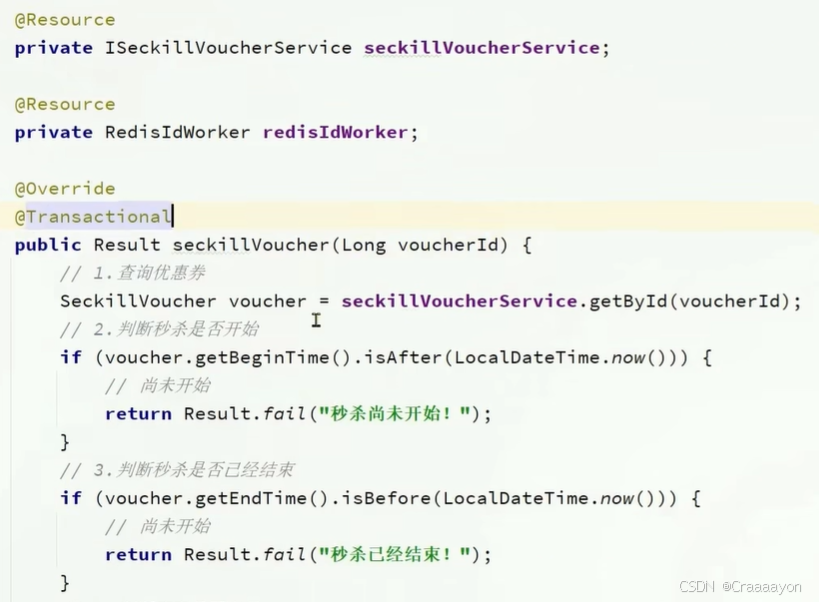
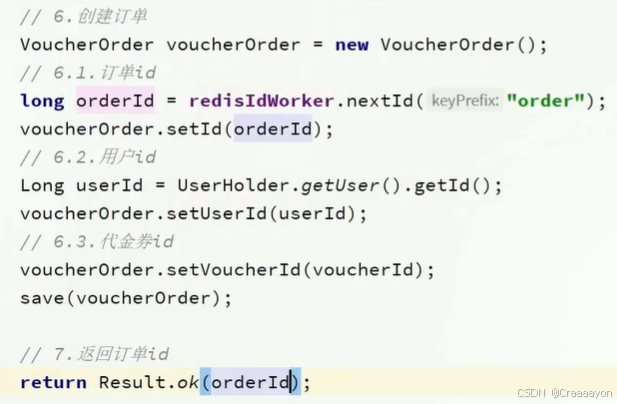
二、实现秒杀下单

优惠卷订单表:


(三)超卖问题
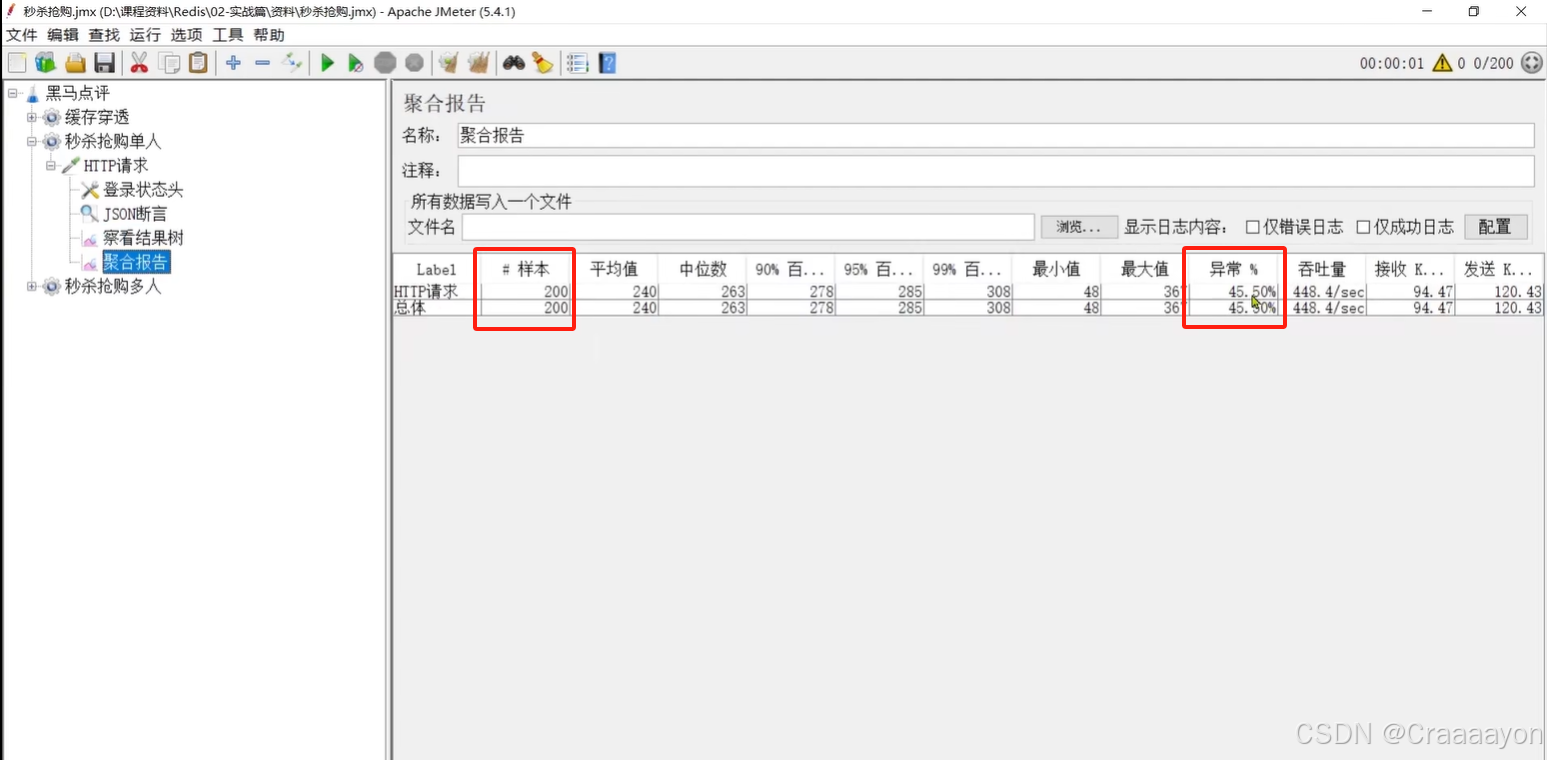
一、库存超卖问题分析
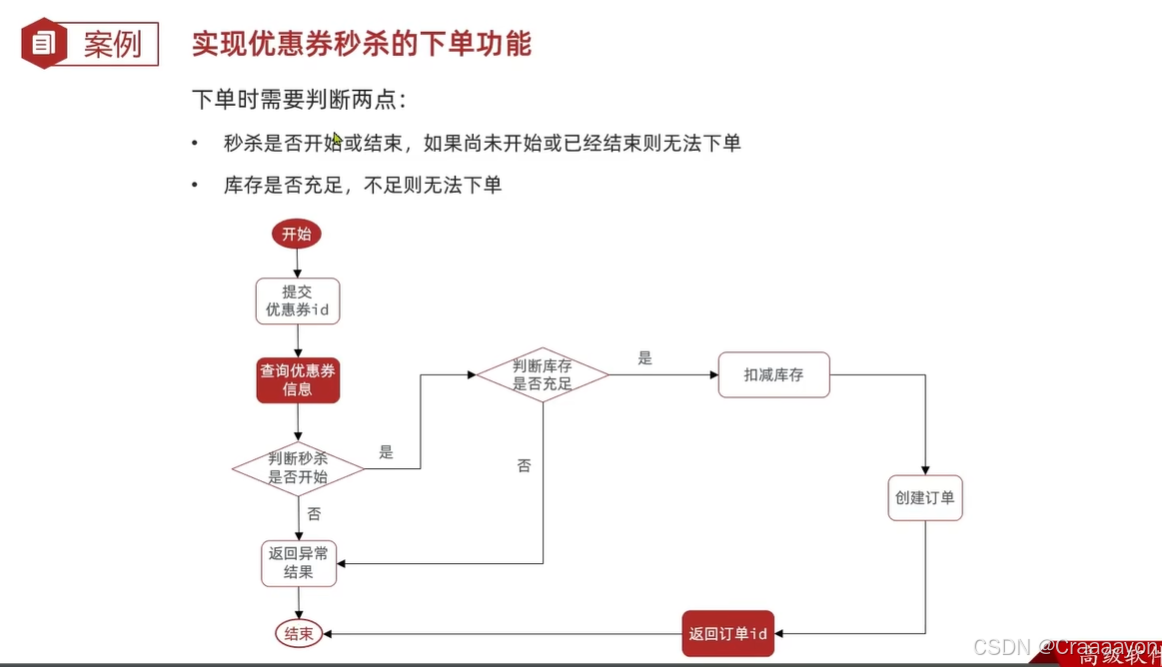
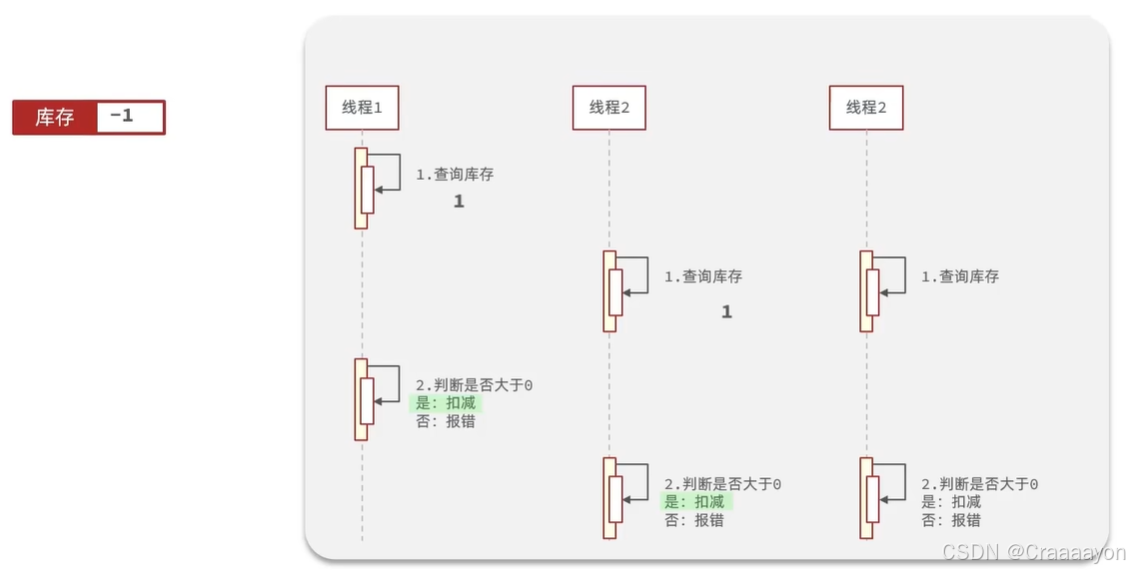
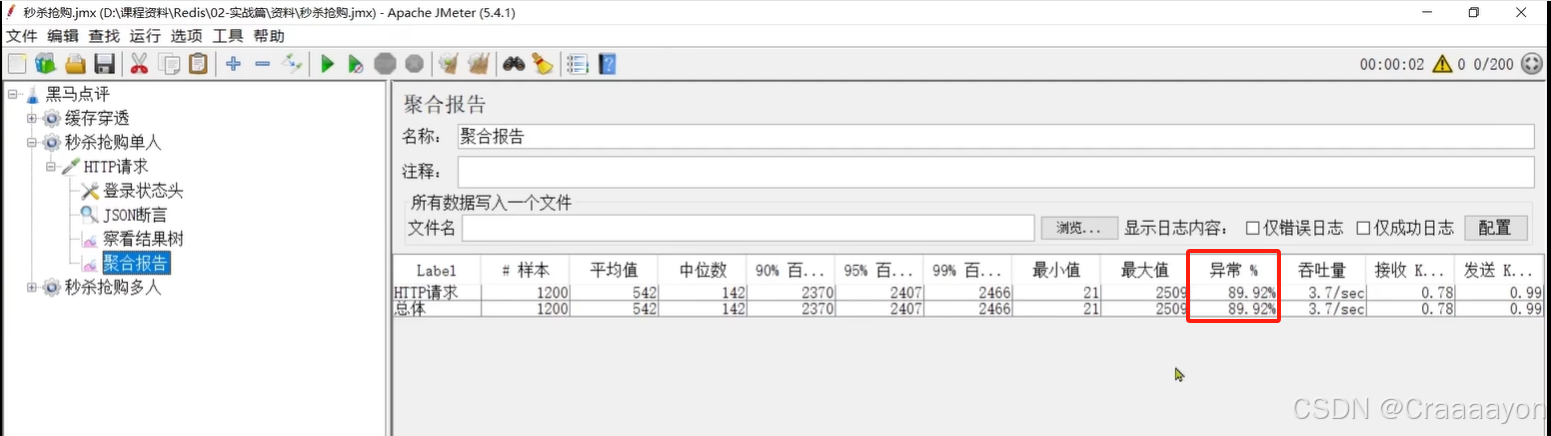
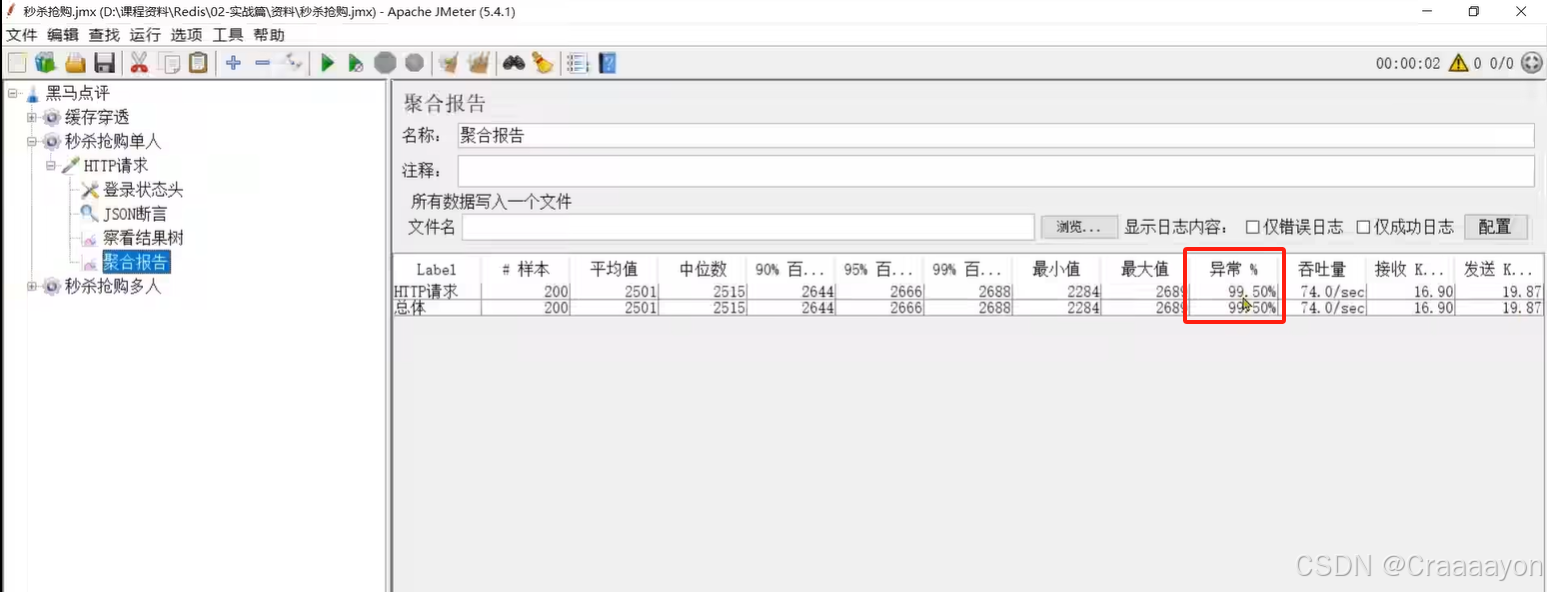
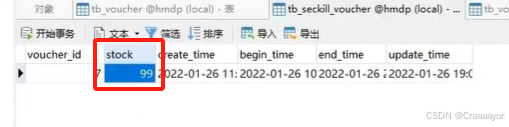
假设数据库中某优惠券的库存为100张,当我们使用jmeter调用200个线程来进行并发购买优惠券时会发现执行异常率为45%,也就是说有超过100条线程执行成功了,数据库中优惠券库存也变为负数,说明此时出现了超卖问题。
(1)执行流程分析
- 正常逻辑
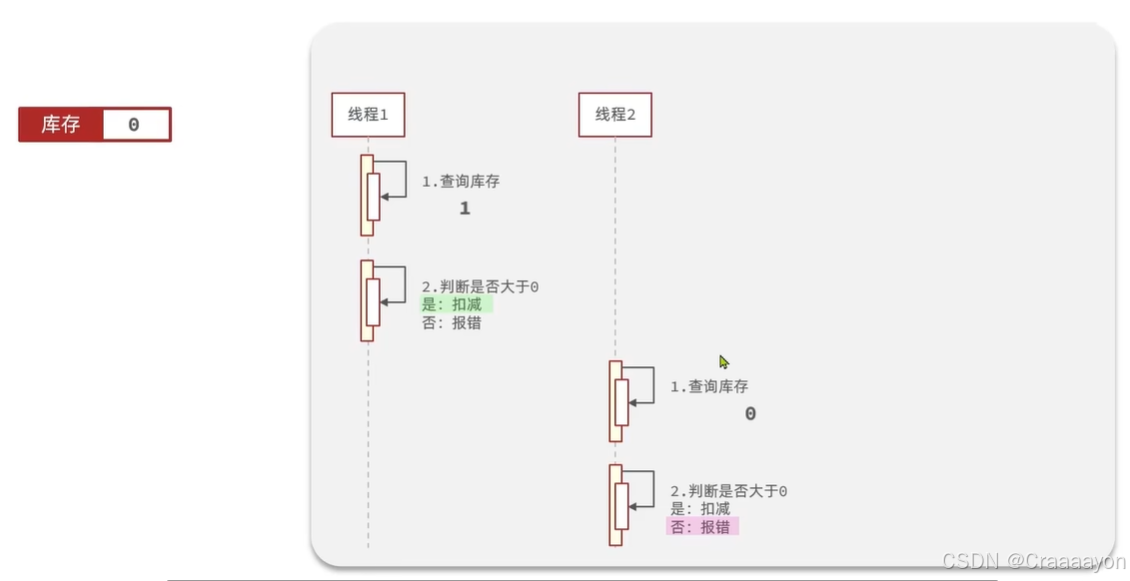
- 交叉执行
(2)解决方案
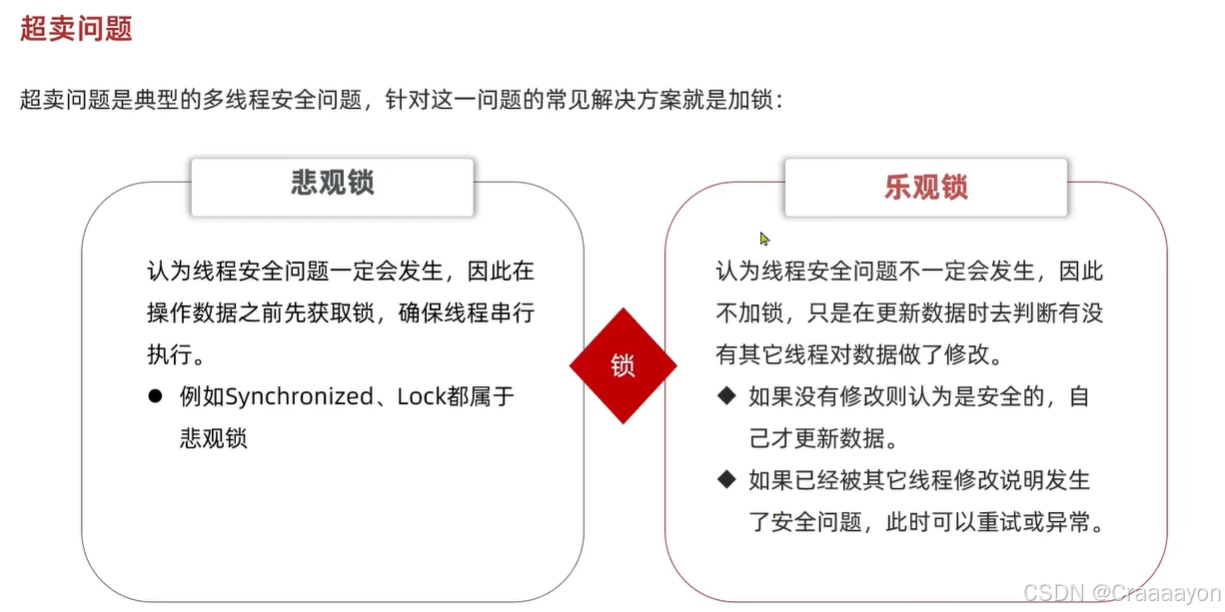
悲观锁与乐观锁并不是一种真正的锁,而是一种锁的设计理念
- 悲观锁
悲观锁认为一定会出现线程安全问题,因此会在操作数据之前先去获取锁,来确保所有线程串行执行,减少并发情况。但是这也代表它的性能并不是很好,因为所有线程都是一个一个去执行的,不适合高并发场景。 - 乐观锁
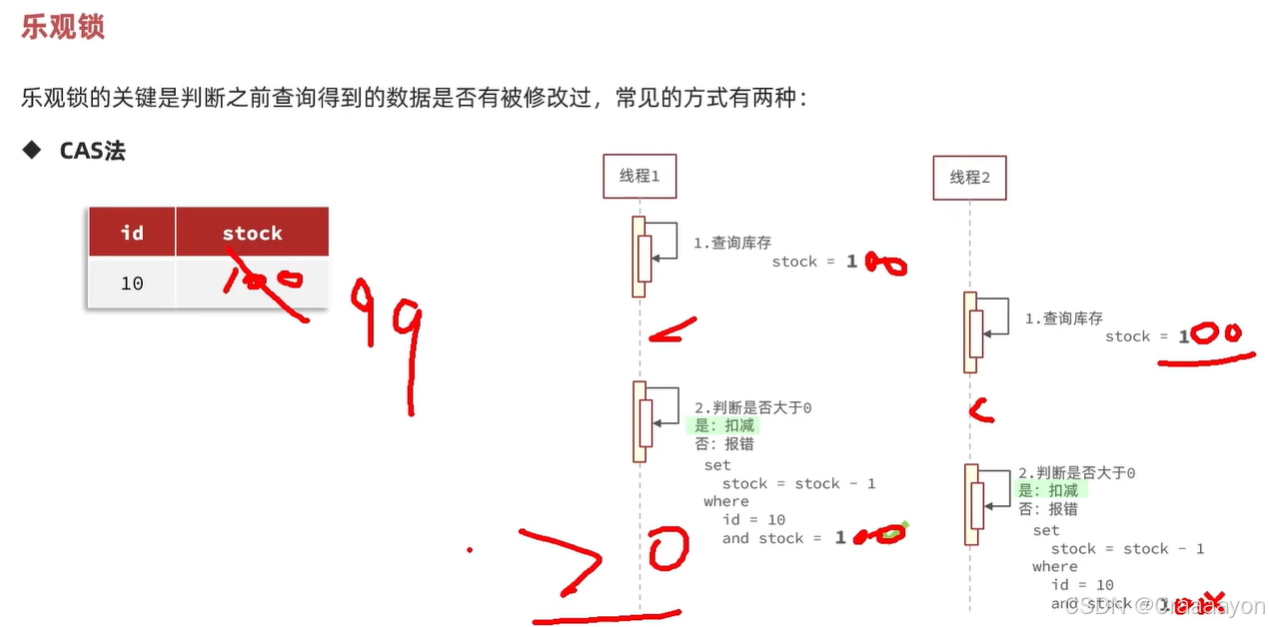
乐观锁认为不一定会出现线程安全问题(认为出现问题的概率比较低),因此不会直接加锁,而是会在线程对数据做修改时去判断在这之前是否有别的线程已经对数据进行修改。也就是当我们查询到数据库中数据且将要对其做修改之前,会去检查当前被修改的数据是否与一开始查询到的数据相同,若不同则说明有别人已经对该数据进行修改了,会有线程安全问题,此时可以去重试或抛异常。它的性能会比悲观锁强很多,核心就是要去判断数据是否被修改。
(3)乐观锁
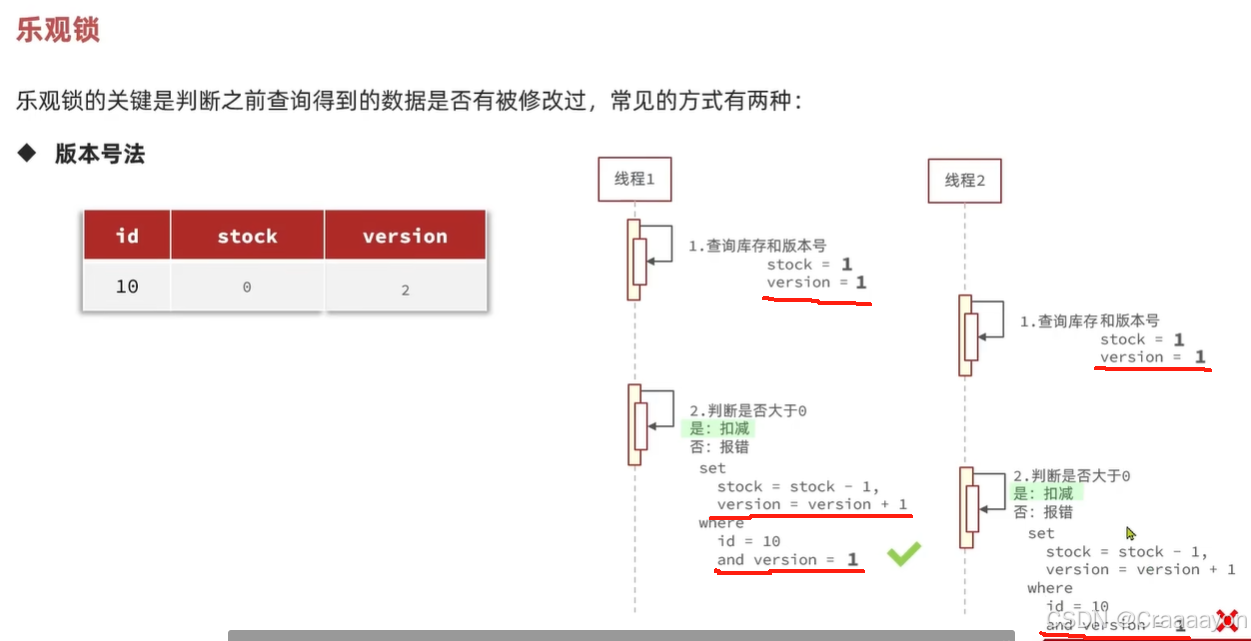
- 版本号法
版本号法也就是给数据加上一个版本,在多线程并发时基于版本号来判断是否被修改过,每当数据做一次修改,版本号就会加一。要想判断一个数据是否被修改过,就是要判断它的版本号是否有变化。
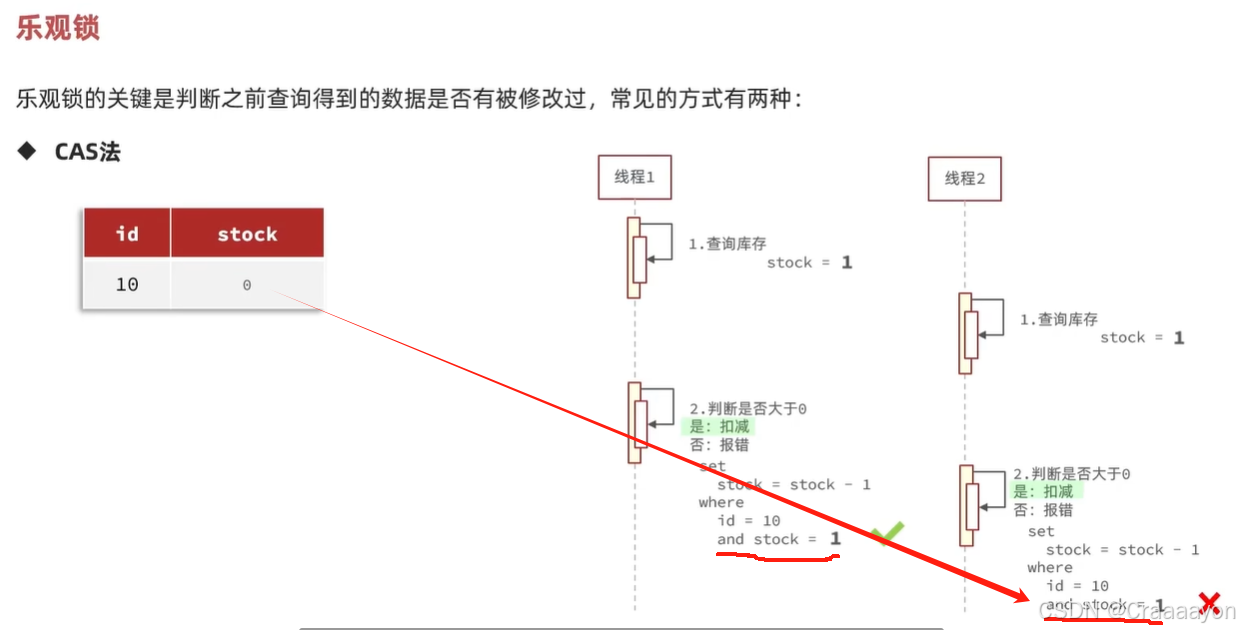
- CAS法
直接将目标修改的数据值作为比较值,替代版本号的作用
二、乐观锁解决超卖问题
- 乐观锁实现逻辑与业务逻辑的冲突问题
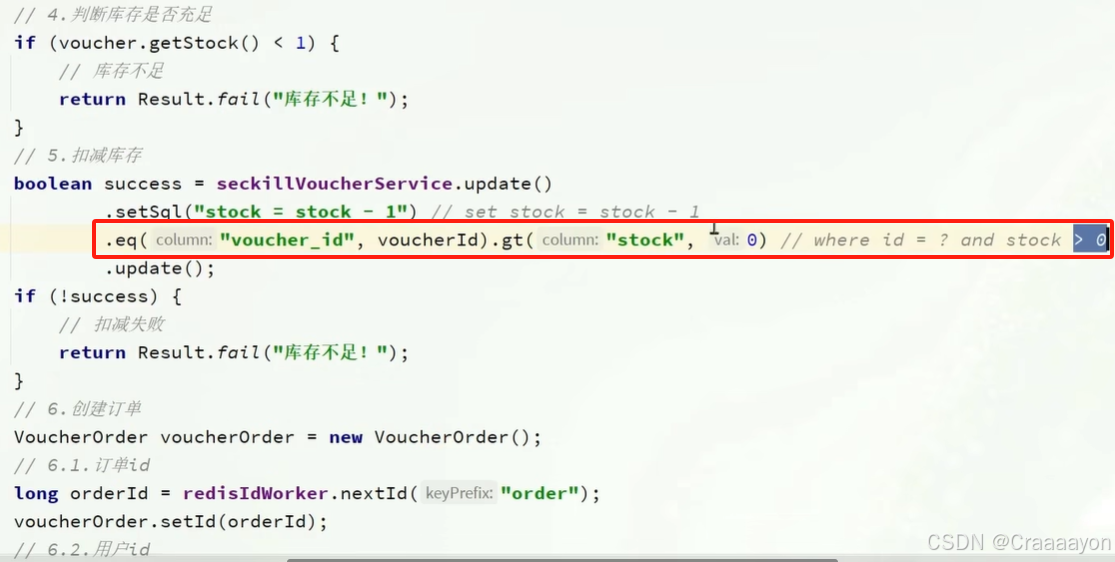
在乐观锁中要求对数据修改前原数据不能发生变化,而在当前业务中仅要求库存大于0即可,乐观锁与业务的逻辑差异会导致线程异常率增大,也就是实际扣减成功率太低了,所以要对其进行优化。
- 最终代码修改情况
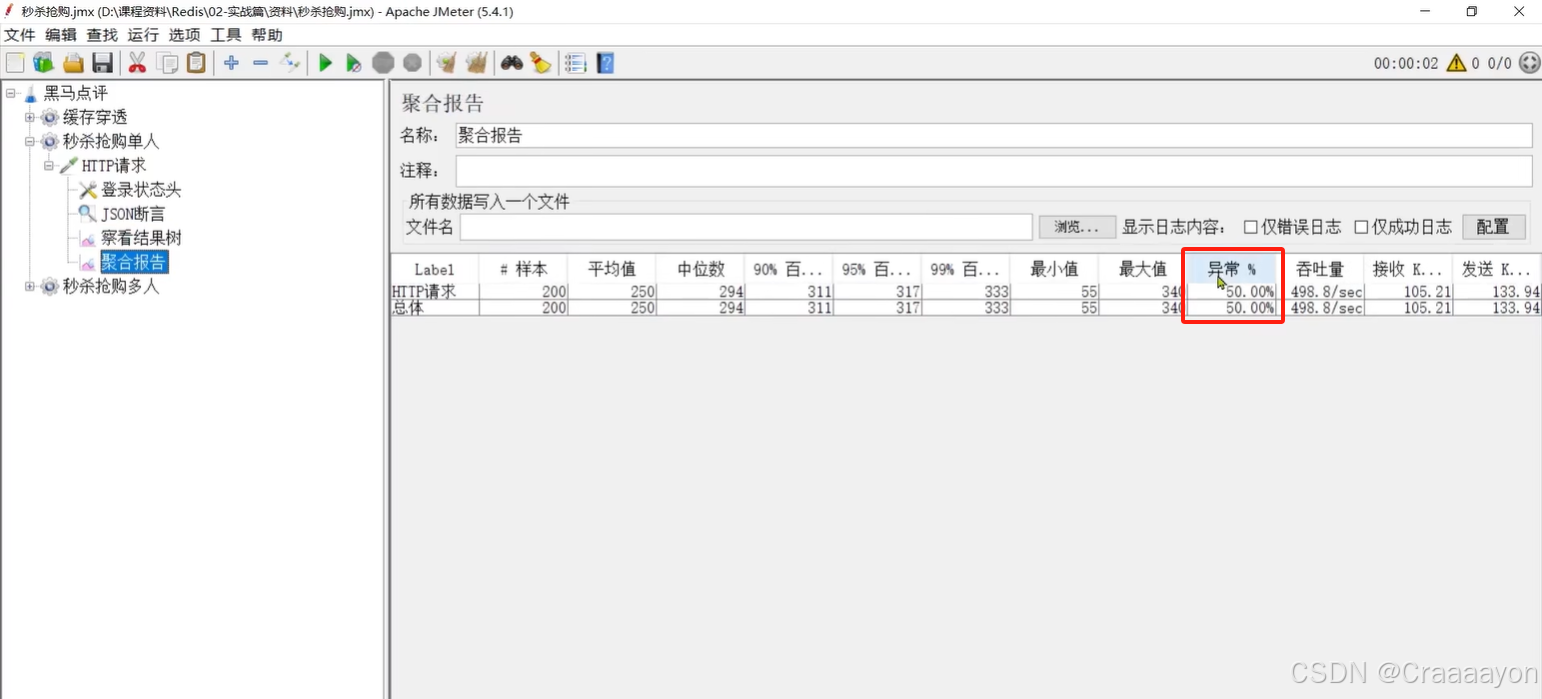
再次执行测试,发现线程异常率达50%,也就是正好卖空全部库存
- 总结

(四)一人一单
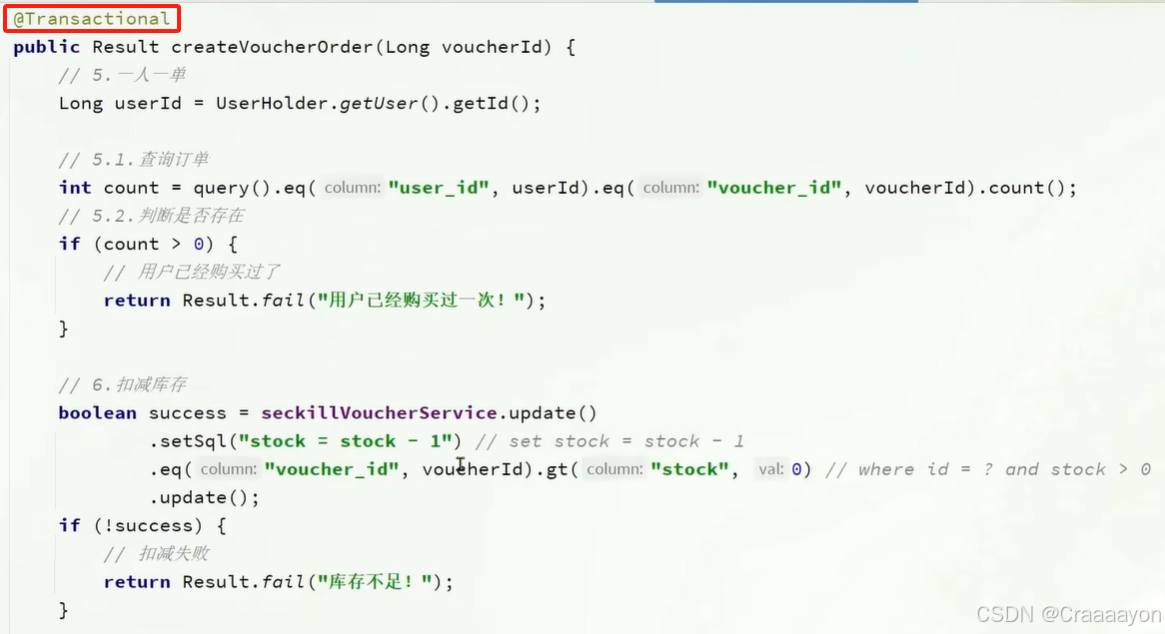
一、一人一单功能实现
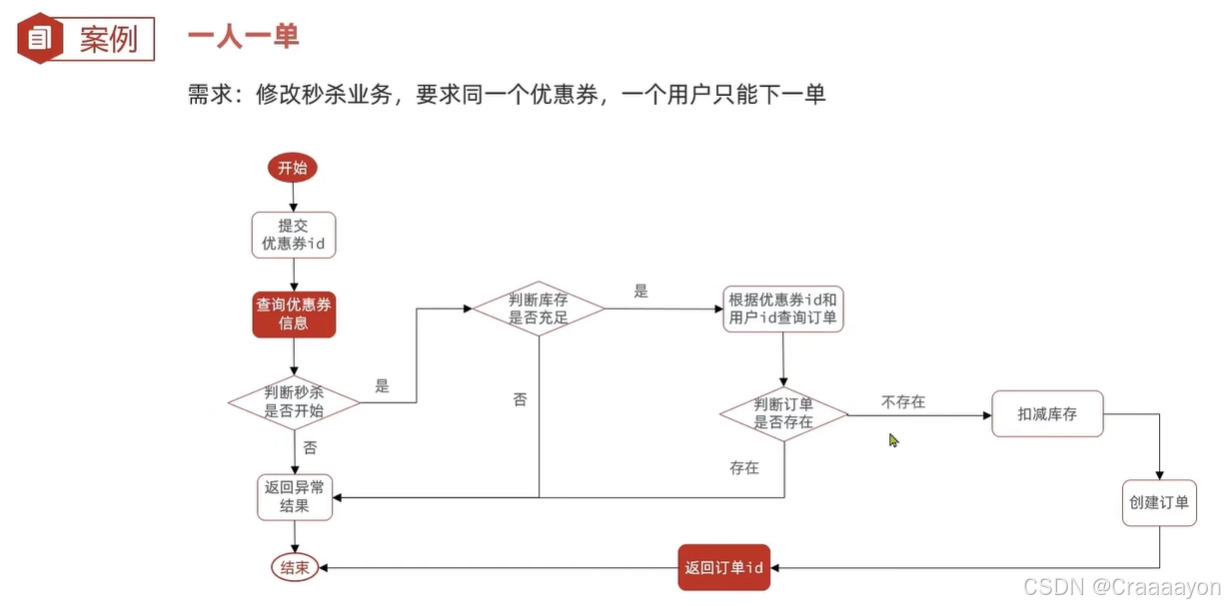

但是此时的业务逻辑并不完美,因为此时一人一单的逻辑与之前下单的逻辑相同,都是先查询再判断,这使得同样会出现多个线程穿插执行的情况,导致出现超卖,也就是并发安全问题。
之前提到的乐观锁是在更新数据时去使用的,这里是需要去插入数据,所以不能直接去判断数据是否有被修改过,而是要去判断数据是否存在,也就只能去使用悲观锁。
(1)具体改造流程
- 封装方法

- 根据用户id进行加锁并且通过获取代理对象来开启createVoucherOrder方法的事务
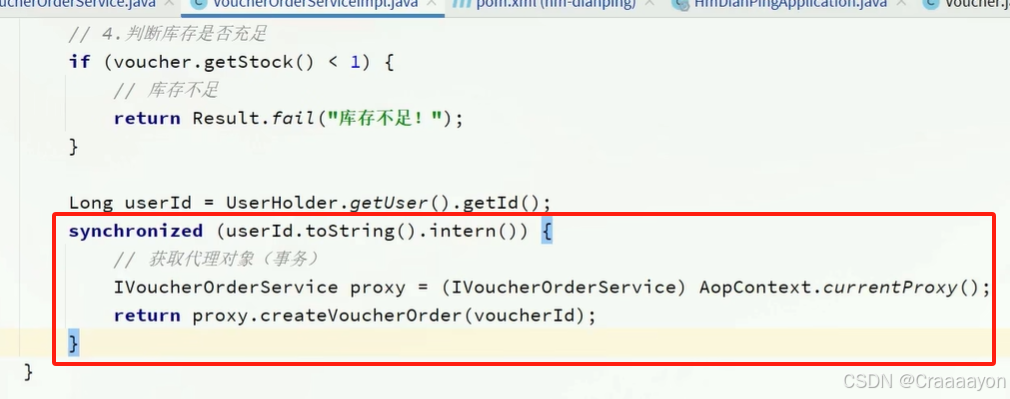
引入依赖并添加注解去暴露代理对象

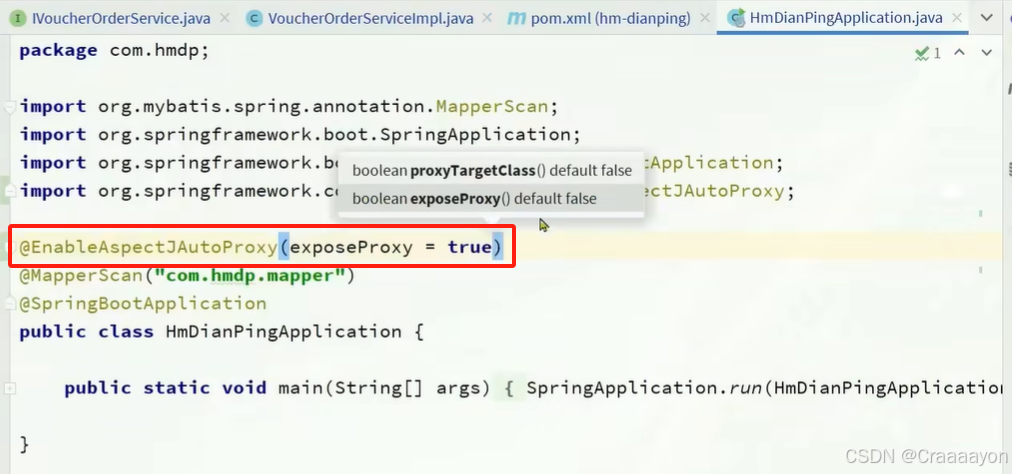
- 测试
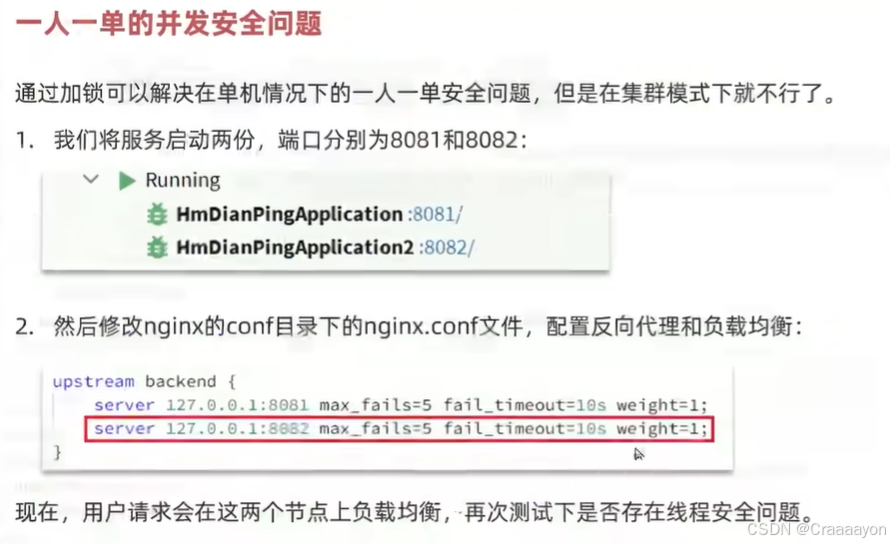
二、集群下的线程并发安全问题
- 正常执行情况
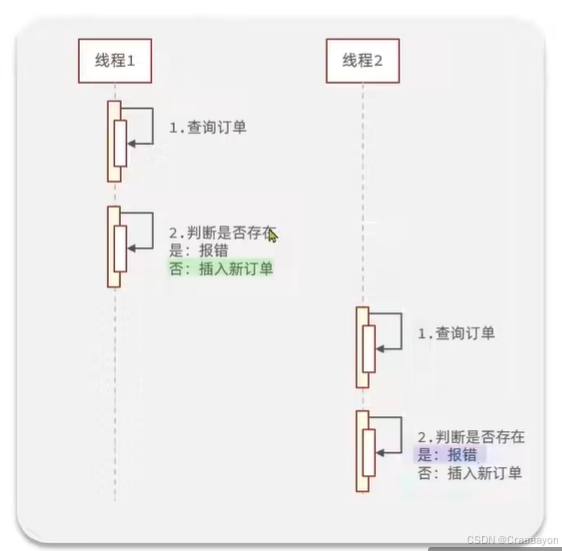
- 交叉执行情况(出现并发问题)
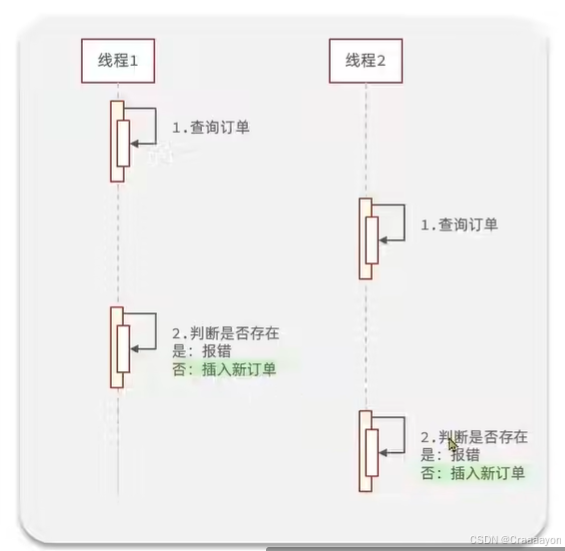
会导致插入了两次订单 - 加入互斥锁的执行情况
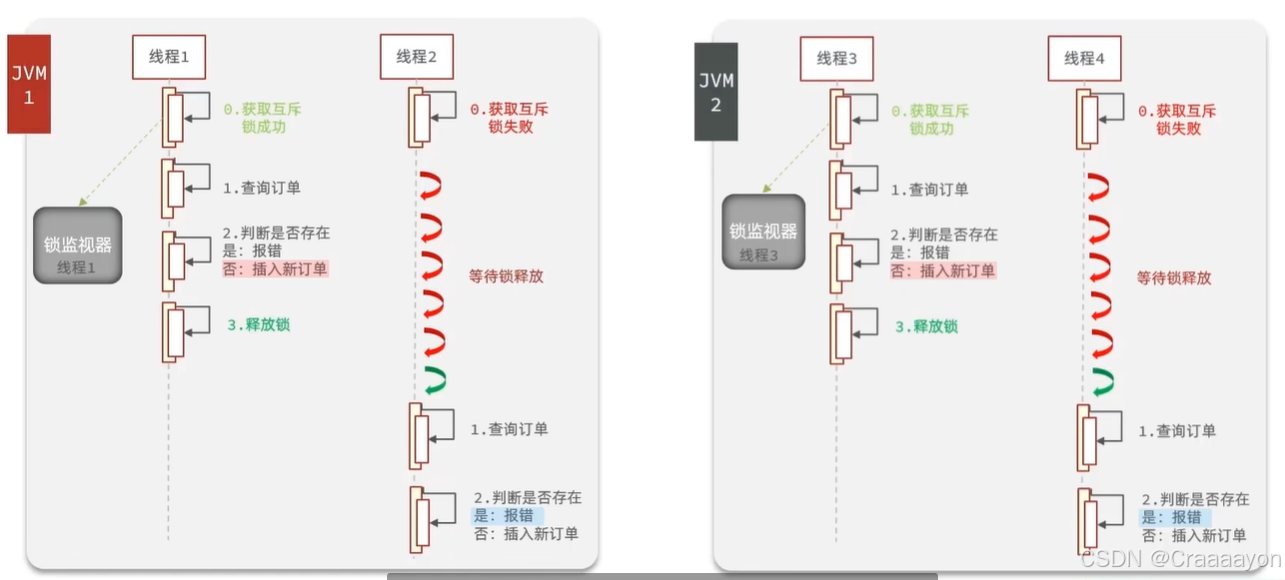
产生线程安全问题的原因:
在集群部署模式或分布式系统下,每一台服务都会有一个独立的JVM,而每个JVM当中都会存在独立的锁监视器去维护互斥锁,导致了每台服务中都有一个线程是能获取到互斥锁的,也就会发生并行运行,就可能出现线程安全问题。
解决办法:让多个JVM只能使用同一把锁,也就是实现跨进程的分布式锁。