双向长短期记忆网络-BiLSTM
5月14日复盘
二、BiLSTM
1. 概述
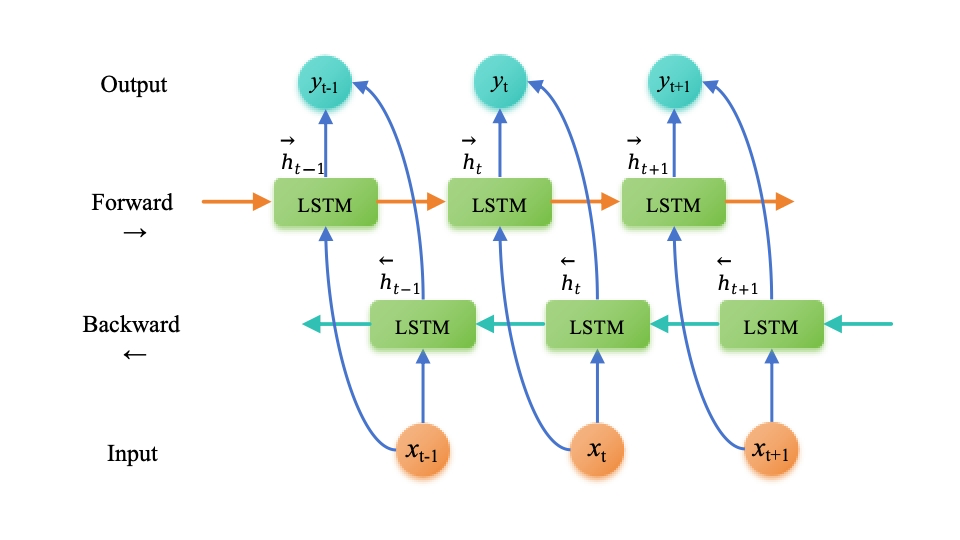
双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)是一种扩展自长短期记忆网络(LSTM)的结构,旨在解决传统 LSTM 模型只能考虑到过去信息的问题。BiLSTM 在每个时间步同时考虑了过去和未来的信息,从而更好地捕捉了序列数据中的双向上下文关系。
BiLSTM 的创新点在于引入了两个独立的 LSTM 层,一个按正向顺序处理输入序列,另一个按逆向顺序处理输入序列。这样,每个时间步的输出就包含了当前时间步之前和之后的信息,进而使得模型能够更好地理解序列数据中的语义和上下文关系。
-
正向传递: 输入序列按照时间顺序被输入到第一个LSTM层。每个时间步的输出都会被计算并保留下来。
-
反向传递: 输入序列按照时间的逆序(即先输入最后一个元素)被输入到第二个LSTM层。与正向传递类似,每个时间步的输出都会被计算并保留下来。
-
合并输出: 在每个时间步,将两个LSTM层的输出通过某种方式合并(如拼接或加和)以得到最终的输出。
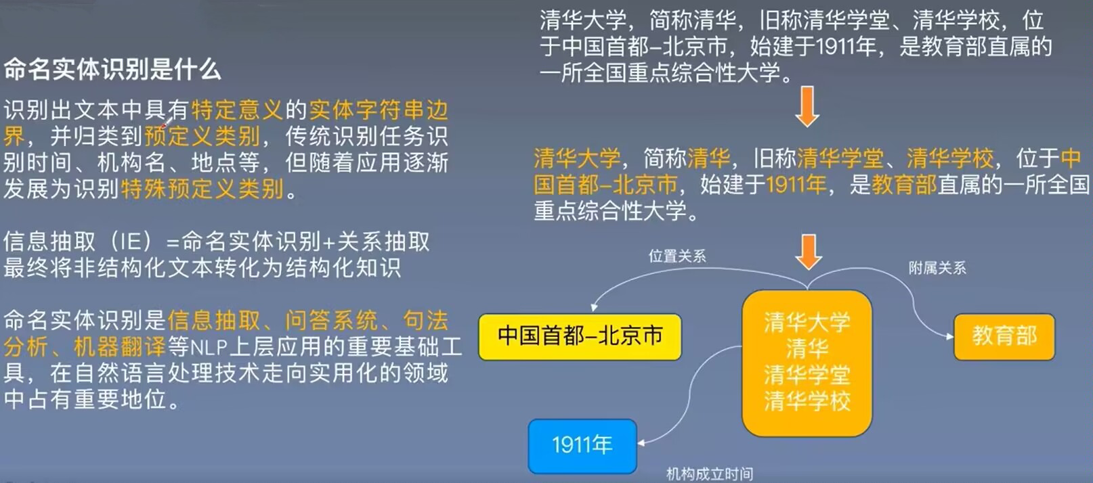
2. BILSTM模型应用背景
命名体识别
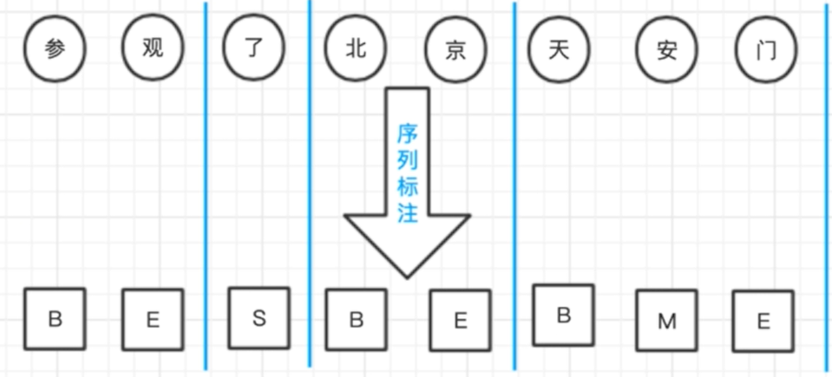
标注集
BMES标注集
分词的标注集并非只有一种,举例中文分词的情况,汉子作为词语开始Begin,结束End,中间Middle,单字Single,这四种情况就可以囊括所有的分词情况。于是就有了BMES标注集,这样的标注集在命名实体识别任务中也非常常见。
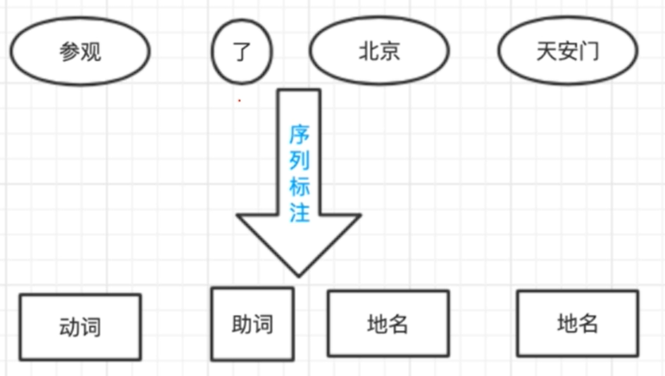
词性标注
在序列标注问题中单词序列就是x,词性序列就是y,当前词词性的判定需要综合考虑前后单词的词性。而标注集最著名的就是863标注集和北大标注集。
3. 代码实现
原生代码
import numpy as npdef sigmoid(x):return 1 / (1 + np.exp(-x))def tanh(x):return np.tanh(x)class GRU:def __init__(self, input_size, hidden_size, output_size):self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size#权重矩阵和偏置self.W_z = np.random.randn(hidden_size + input_size, hidden_size)self.b_z = np.zeros((hidden_size,))self.W_r = np.random.randn(hidden_size + input_size, hidden_size)self.b_r = np.zeros((hidden_size,))# ht候选self.W = np.random.randn(hidden_size + input_size, hidden_size)self.b = np.zeros((hidden_size,))def forward(self, x, h_last):""":param x: [s,dim]:param h_last::return:"""# 初始化状态h_prev = np.zeros((self.hidden_size,))h_all = []for i in range(x.shape[0]):x_t = x[i]x_t_h_prev = np.concatenate((x_t, h_prev), axis=0)r_t = sigmoid(np.dot(x_t_h_prev, self.W_r) + self.b_r)z_t = sigmoid(np.dot(x_t_h_prev, self.W_z) + self.b_z)# h_prev = r_t * h_prevh_t_input = np.concatenate((x_t, h_prev * r_t), axis=0)h_t_candidate = tanh(np.dot(h_t_input, self.W) + self.b)h_t = (1 - z_t) * h_prev + z_t * h_t_candidateh_all.append(h_t)return h_allif __name__ == '__main__':gru = GRU(input_size=2, hidden_size=5, output_size=1)x = np.random.randn(3 , 2)h_last = np.zeros((3,))h_all = gru.forward(x, h_last)print(h_all)# ---------------------------------------------------------------------------
import numpy as np# 创建一个包含两个二维数组的列表
inputs = [np.array([[0.1], [0.2], [0.3]]), np.array([[0.4], [0.5], [0.6]])]# 使用 numpy 库中的 np.stack 函数。这会将输入的二维数组堆叠在一起,从而形成一个新的三维数组
inputs_3d = np.stack(inputs)# 将三维数组转换为列表
list_from_3d_array = inputs_3d.tolist()print(list_from_3d_array)
Pytorch
import torch
import torch.nn as nn# 模型参数设置
batch_size = 10
sen_len = 6
hidden_size = 8input_size = 3
output_size = hidden_size * 2 # 类别是隐藏层大小的两倍# 初始化隐藏层状态
h_prev = torch.zeros(1, batch_size, hidden_size)# RNN调用
model = nn.GRU(input_size, hidden_size, batch_first=True)
fc = nn.Linear(hidden_size, output_size) # 全连接层用于分类# 初始化数据
x = torch.randn(10, 6, 3)out, h_next = model(x, h_prev)
# 对每个时间步的输出进行分类
out = out.contiguous().view(-1, hidden_size) # 调整形状为 (batch_size * sen_len, hidden_size)
out = fc(out)
out = out.view(batch_size, sen_len, output_size) # 调整回 (batch_size, sen_len, output_size)print("多对多输出:")
print(out.shape)
print(out)
print(h_next.shape)
print(h_next)out, h_next = model(x, h_prev)
# 只对最后一个时间步的输出进行分类
final_out = h_next.squeeze(0) # 移除多余的维度,得到 (batch_size, hidden_size)
final_out = fc(final_out)print("\n多对一输出:")
print(final_out.shape)
print(final_out)
print(h_next.shape)
print(h_next)