python 数据类型【python进阶一】
1. 数据类型:不可变与可变的本质区别
Python 数据类型按 “能否修改内存中的值” 分为 不可变类型 和 可变类型,这是基础中的基础,直接影响变量赋值、函数传参、拷贝等操作的行为。
1.1 不可变类型(Immutable Types)
定义
不可变类型指:创建后,内存地址(id)对应的内容无法修改,若要 “修改”,本质是创建新对象并指向新内存地址。
包含类型及特性
| 类型 | 核心特性 | 常见场景 |
|---|---|---|
int | 整数,Python 中整数无大小限制(区别于 C/C++ 的 int) | 计数、索引、ID 标识 |
str | 字符串,由 Unicode 字符组成,支持切片但不可修改单个字符 | 文本处理、接口返回值 |
tuple | 元组,可存储不同类型元素,不可修改元素(但嵌套的可变元素可修改,见陷阱) | 函数返回多值、不可变配置 |
float | 浮点数,遵循 IEEE 754 标准,存在精度问题(如 0.1 + 0.2 ≠ 0.3) | 小数计算(需精度用 decimal) |
bool | 布尔值,仅 True(本质是 1)和 False(本质是 0)两个值 | 条件判断、状态标记 |
代码示例:不可变类型的 “修改” 本质
# 1. int 类型:修改后内存地址变化
a = 10
print(f"修改前 a 的值:{a},内存地址:{id(a)}") # 输出:修改前 a 的值:10,内存地址:140708250000000
a += 5 # 看似“修改”,实则创建新对象
print(f"修改后 a 的值:{a},内存地址:{id(a)}") # 输出:修改后 a 的值:15,内存地址:140708250000160(新地址)# 2. str 类型:无法修改单个字符
s = "hello"
# s[0] = "H" # 报错:TypeError: 'str' object does not support item assignment
s_new = s.replace("h", "H") # 创建新字符串
print(f"原字符串:{s}(地址:{id(s)}),新字符串:{s_new}(地址:{id(s_new)})") # 地址不同# 3. tuple 类型:不可修改元素,但嵌套的可变元素可修改(面试陷阱)
t = (1, 2, [3, 4])
# t[0] = 10 # 报错:TypeError: 'tuple' object does not support item assignment
t[2][0] = 30 # 嵌套的 list 是可变类型,可修改内部元素
print(t) # 输出:(1, 2, [30, 4])
问题:为什么 tuple 是不可变类型,却能修改嵌套的 list?
- 本质:tuple 存储的是 元素的内存地址,不可变的是 “地址本身”,而非 “地址指向的内容”。
- 嵌套的 list 是可变类型,其内存地址被存在 tuple 中,修改 list 内部元素不会改变 list 自身的内存地址,因此 tuple 允许这种操作。
1.2 可变类型(Mutable Types)
定义
可变类型指:创建后,内存地址(id)不变,可直接修改内部元素的内容,无需创建新对象。
包含类型及特性
| 类型 | 核心特性 | 常见场景 |
|---|---|---|
list | 动态数组,支持增删改查(append/pop/insert),元素可重复 | 存储有序数据(如列表、队列) |
dict | 哈希表,Python 3.7+ 后保留插入顺序,key 必须是不可变类型 | 存储键值对(如配置、用户信息) |
set | 无序不重复集合,支持交集、并集、差集等运算,元素必须是不可变类型 | 去重、关系判断(如用户标签) |
bytearray | 可变字节序列,可修改单个字节(区别于不可变的 bytes) | 二进制数据处理(如文件读写) |
代码示例:可变类型的修改特性
# 1. list 类型:修改内部元素,地址不变
lst = [1, 2, 3]
print(f"修改前 lst:{lst},地址:{id(lst)}") # 输出:修改前 lst:[1,2,3],地址:140708250012000
lst.append(4) # 直接修改内部元素
lst[0] = 10 # 直接修改指定索引元素
print(f"修改后 lst:{lst},地址:{id(lst)}") # 输出:修改后 lst:[10,2,3,4],地址不变# 2. dict 类型:新增/修改 key-value,地址不变
d = {"name": "Alice", "age": 20}
print(f"修改前 dict:{d},地址:{id(d)}") # 输出:修改前 dict:{'name':'Alice','age':20},地址:140708250013000
d["age"] = 21 # 修改已有 key
d["gender"] = "female" # 新增 key
print(f"修改后 dict:{d},地址:{id(d)}") # 输出:修改后 dict:{'name':'Alice','age':21,'gender':'female'},地址不变# 3. set 类型:新增/删除元素,地址不变
s = {1, 2, 3}
print(f"修改前 set:{s},地址:{id(s)}") # 输出:修改前 set:{1,2,3},地址:140708250014000
s.add(4) # 新增元素
s.remove(2) # 删除元素
print(f"修改后 set:{s},地址:{id(s)}") # 输出:修改后 set:{1,3,4},地址不变
问题:为什么 dict 的 key 必须是不可变类型?
- 底层原理:dict 基于 哈希表(Hash Table) 实现,查询 key 的速度依赖
hash(key)计算哈希值,再通过哈希值定位存储位置。 - 关键限制:若 key 是可变类型(如 list),修改后
hash(key)会变化,导致 dict 无法定位到原 key,破坏哈希表的一致性。 - 反例:
d = {[1,2]: "value"}会直接报错TypeError: unhashable type: 'list',因为 list 不可哈希。
1.3 类型判断与转换
1. 类型判断:type() vs isinstance()
| 函数 | 作用 | 特点 | 适用场景 |
|---|---|---|---|
type(obj) | 返回对象的直接类型(不考虑继承关系) | 只能判断 “直接类型”,无法识别子类 | 简单类型判断(如 int/str) |
isinstance(obj, cls) | 判断对象是否是指定类或其子类的实例 | 考虑继承关系,支持多类型判断(传元组) | 面向对象场景(如判断子类实例) |
代码示例:两者区别
# 1. 基础类型判断
a = 10
print(type(a) is int) # 输出:True
print(isinstance(a, int)) # 输出:True# 2. 继承场景的区别(核心)
class Parent:pass
class Child(Parent): # Child 继承 Parentpassc = Child()
print(type(c) is Parent) # 输出:False(type 只看直接类型)
print(isinstance(c, Parent)) # 输出:True(isinstance 考虑继承)# 3. 多类型判断(isinstance 专属)
b = "hello"
print(isinstance(b, (int, str, list))) # 输出:True(b 是 str,在元组中)
面试结论:优先用 isinstance(),除非明确需要排除子类。
2. 类型转换:常见转换函数
- 转为整数:
int(x)(如int("10") → 10,int(3.9) → 3,注意小数转整数会截断小数部分,而非四舍五入) - 转为字符串:
str(x)(如str(10) → "10",str([1,2]) → "[1,2]") - 转为列表:
list(x)(如list("hello") → ["h","e","l","l","o"],list((1,2)) → [1,2]) - 转为字典:
dict(x)(如dict([("name","Alice"), ("age",20)]) → {"name":"Alice","age":20}) - 转为集合:
set(x)(如set([1,2,2,3]) → {1,2,3},自动去重)
1.4 类型之间的区别
Python 容器类型对比表
| 特性 | 列表 (List) | 元组 (Tuple) | 字典 (Dict) | 集合 (Set) | 字符串 (String) | 字节 (Bytes) |
|---|---|---|---|---|---|---|
| 可变性 | ✅ 可变 | ❌ 不可变 | ✅ 可变 | ✅ 可变 | ❌ 不可变 | ❌ 不可变 |
| 有序性 | ✅ 有序 | ✅ 有序 | ❌ 无序 (Py≥3.7 保序) | ❌ 无序 | ✅ 有序 | ✅ 有序 |
| 语法标识 | [ ] | ( )(单元素需加逗号:(1,)) | {key: value} | { }(空集合用 set()) | " " 或 ' ' | b" " |
| 元素要求 | 无限制 | 无限制 | 键必须可哈希(不可变类型) | 元素必须可哈希(不可变类型) | 字符序列 | 字节值(0-255) |
| 重复元素 | ✅ 允许 | ✅ 允许 | 键❌不允许,值✅允许 | ❌ 不允许(自动去重) | ✅ 允许 | ✅ 允许 |
| 索引支持 | ✅ (如 lst[0]) | ✅ (如 tup[0]) | ✅ 键索引(如 dict["key"]) | ❌ 无索引 | ✅ (如 str[0]) | ✅ (如 bytes[0]) |
| 核心操作 | 增删改(append, pop, insert) | 仅查询(count, index) | 键值对操作(get, keys, update) | 集合运算(union, intersection) | 切片、替换(replace, split) | 解码/编码(decode, hex) |
| 内存占用 | 较高(预留扩容空间) | ✅ 较低(静态分配) | 中等(哈希表开销) | 中等(哈希表开销) | 中等 | 低 |
| 迭代速度 | 较慢 | ✅ 最快(可缓存复用) | 中等 | 快(基于哈希) | 快 | 快 |
| 哈希支持 | ❌ 不可哈希 | ✅ 可哈希(若元素可哈希) | ❌ 不可哈希 | ❌ 不可哈希(但 frozenset 可哈希) | ✅ 可哈希 | ✅ 可哈希 |
| 典型应用场景 | 动态数据集(日志、队列) | 固定结构(坐标、配置项、字典键) | 键值映射(JSON、缓存) | 去重、关系运算(并集/交集) | 文本处理、正则匹配 | 二进制数据(图片/文件) |
扩展说明与常见误区
元组 (Tuple) 的不可变陷阱
- 若元组包含可变元素(如列表),则嵌套元素仍可修改:
t = (1, 2, [3, 4])t[2].append(5) # ✅ 合法 → (1, 2, [3, 4, 5]) 设计语义:Tuple 强调 异构性(各位置类型/含义不同),而 List 为同构集合。
例:person = ("Alice", 25) vs scores = [85, 90, 78]
集合 (Set) 的独特价值
数学运算:快速完成交集(&)、并集(\|)、差集(-)、对称差(^)
例:active_users = registered_users & logged_in_users
去重效率:比手动遍历列表高 O(n) 倍。
字典 (Dict) 与哈希性
键必须是不可变类型(如 Tuple、String、int),因哈希依赖对象内存地址稳定性。
Py≥3.7 版本后保留插入顺序,但逻辑设计仍应避免依赖顺序。
字符串/字节的不可变性
修改操作(如 replace())实际生成新对象,原对象不变。
字节数组(bytearray)为可变替代方案。
关键差异总结:
可变 vs 不可变
不可变类型(Tuple, String, Bytes, FrozenSet):创建后无法修改,线程安全,可哈希。
可变类型(List, Set, Dict, ByteArray):支持原位修改,但需注意并发安全问题 。
有序 vs 无序
- List/Tuple/String 保持插入顺序,Set/Dict 在 Python 3.7+ 后虽保序但不依赖顺序逻辑。
哈希性要求
- 字典键或集合元素必须可哈希(即不可变类型),List/Set 不可作为字典键 。
快速匹配法则:
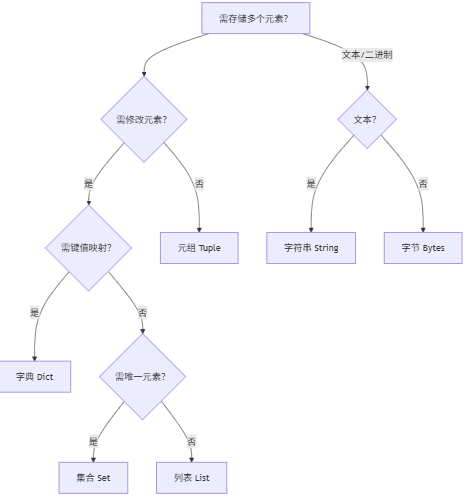
高频误区与避坑指南
1.默认参数慎用可变容器
# 错误:默认列表会持久化,多次调用共享同一对象def add_item(item, items=[]):items.append(item)return items# 正确:用 None 替代def add_item(item, items=None):items = items or [] # 每次调用新建列表2.元组 vs 列表的性能差异
遍历:Tuple 因内存连续且无扩容检查,比 List 快 20%~30% 。
哈希缓存:Tuple 可作字典键,List 不可。
3.集合初始化陷阱
s = {} 实际创建字典而非集合 → 空集合用 s = set()。
总结:
| 需求 | 推荐容器 | 示例场景 |
|---|---|---|
| 频繁增删改动态数据集 | List | 用户行为日志、实时队列 |
| 固定结构且需哈希 | Tuple | 数据库记录 (id, name, age) |
| 键值查询与快速映射 | Dict | 缓存 {"user_123": profile_data} |
| 去重或关系运算 | Set | 共同好友 friends_a & friends_b |
| 只读文本/二进制数据 | String/Bytes | 配置文件解析、网络数据传输 |