毕业项目推荐:27-基于yolov8/yolov5/yolo11的电塔缺陷检测识别系统(Python+卷积神经网络)
文章目录
- 项目介绍大全(可点击查看,不定时更新中)
- 概要
- 一、整体资源介绍
- 技术要点
- 功能展示:
- 功能1 支持单张图片识别
- 功能2 支持遍历文件夹识别
- 功能3 支持识别视频文件
- 功能4 支持摄像头识别
- 功能5 支持结果文件导出(xls格式)
- 功能6 支持切换检测到的目标查看
- 二、系统环境与依赖配置说明
- 三、数据集
- 四、算法介绍
- 1. YOLOv8 概述
- 简介
- 2. YOLOv5 概述
- 简介
- 3. YOLO11 概述
- YOLOv11:Ultralytics 最新目标检测模型
- 🌟 五、模型训练步骤
- 🌟 六、模型评估步骤
- 🌟 七、训练结果
- 🌟八、完整代码
往期经典回顾
| 项目 | 项目 |
|---|---|
| 基于yolov8的车牌检测识别系统 | 基于yolov8/yolov5/yolo11的动物检测识别系统 |
| 基于yolov8的人脸表情检测识别系统 | 基于深度学习的PCB板缺陷检测系统 |
| 基于yolov8/yolov5的茶叶等级检测系统 | 基于yolov8/yolov5的农作物病虫害检测识别系统 |
| 基于yolov8/yolov5的交通标志检测识别系统 | 基于yolov8/yolov5的课堂行为检测识别系统 |
| 基于yolov8/yolov5的海洋垃圾检测识别系统 | 基于yolov8/yolov5的垃圾检测与分类系统 |
| 基于yolov8/yolov5的行人摔倒检测识别系统 | 基于yolov8/yolov5的草莓病害检测识别系统 |
具体项目资料请看项目介绍大全
项目介绍大全(可点击查看,不定时更新中)
概要
电塔缺陷检测在电力设备巡检、运行维护和故障预防中起着至关重要的作用,不仅能帮助相关部门实时监测电塔运行状态,还为智能化检测系统提供了可靠的数据支撑。本文介绍了一款基于深度学习框架的电塔缺陷检测模型,该模型使用了大量不同类型和状态的电塔图像进行训练,能够准确识别各种环境中的电塔缺陷。系统可在不同场景下进行检测,包括多种光照条件、复杂背景、电塔遮挡等。
此外,我们开发了一款带有UI界面的电塔缺陷检测识别系统,支持实时检测电塔缺陷,并能够直观地展示检测结果。系统采用Python与PyQt5开发,可以对图片、视频及摄像头输入进行目标检测,同时支持检测结果的保存。本文还提供了完整的Python代码和详细的使用指南,供有兴趣的读者学习参考。获取完整代码资源,请参见文章末尾。
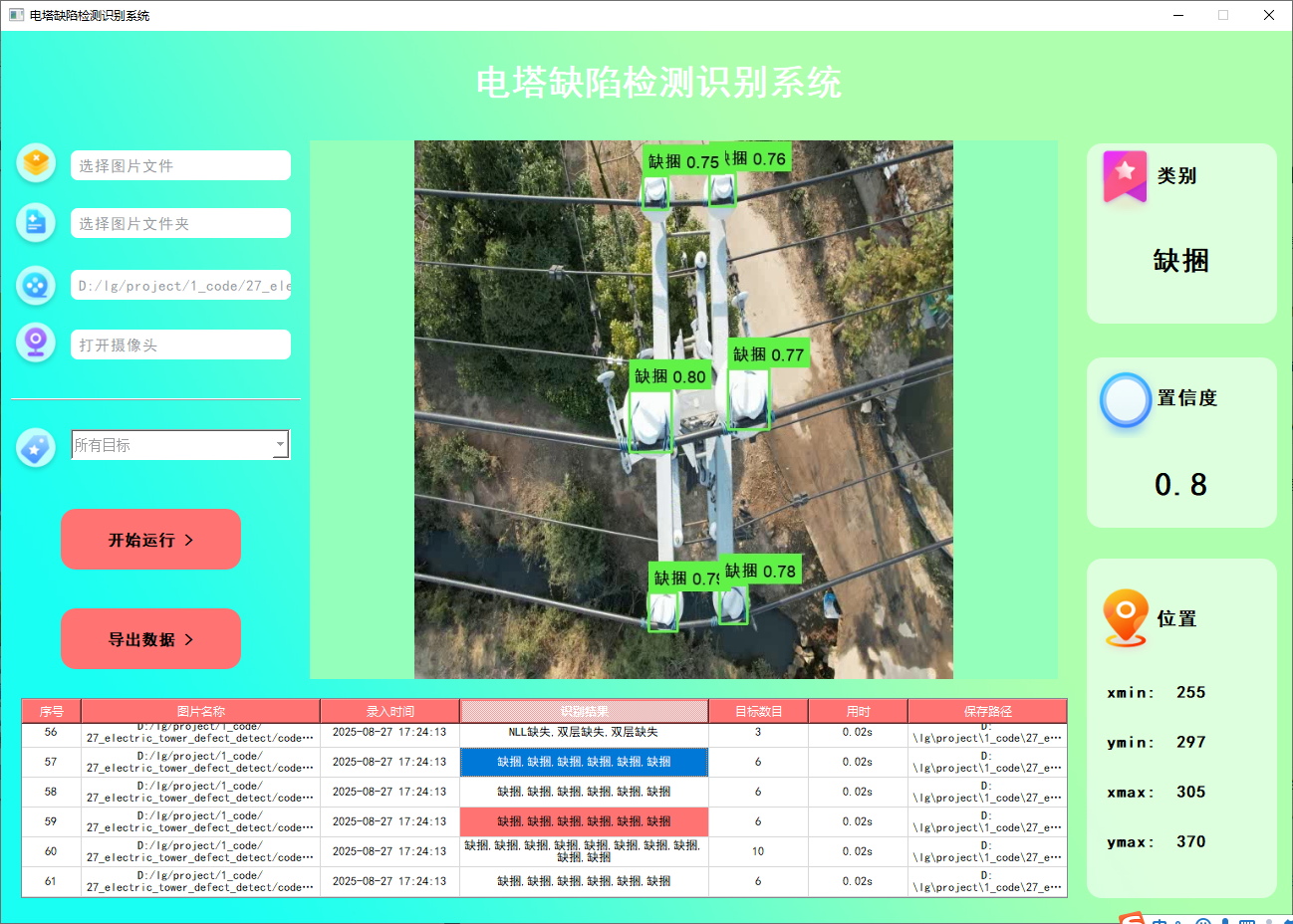
yolov8/yolov5界面如下
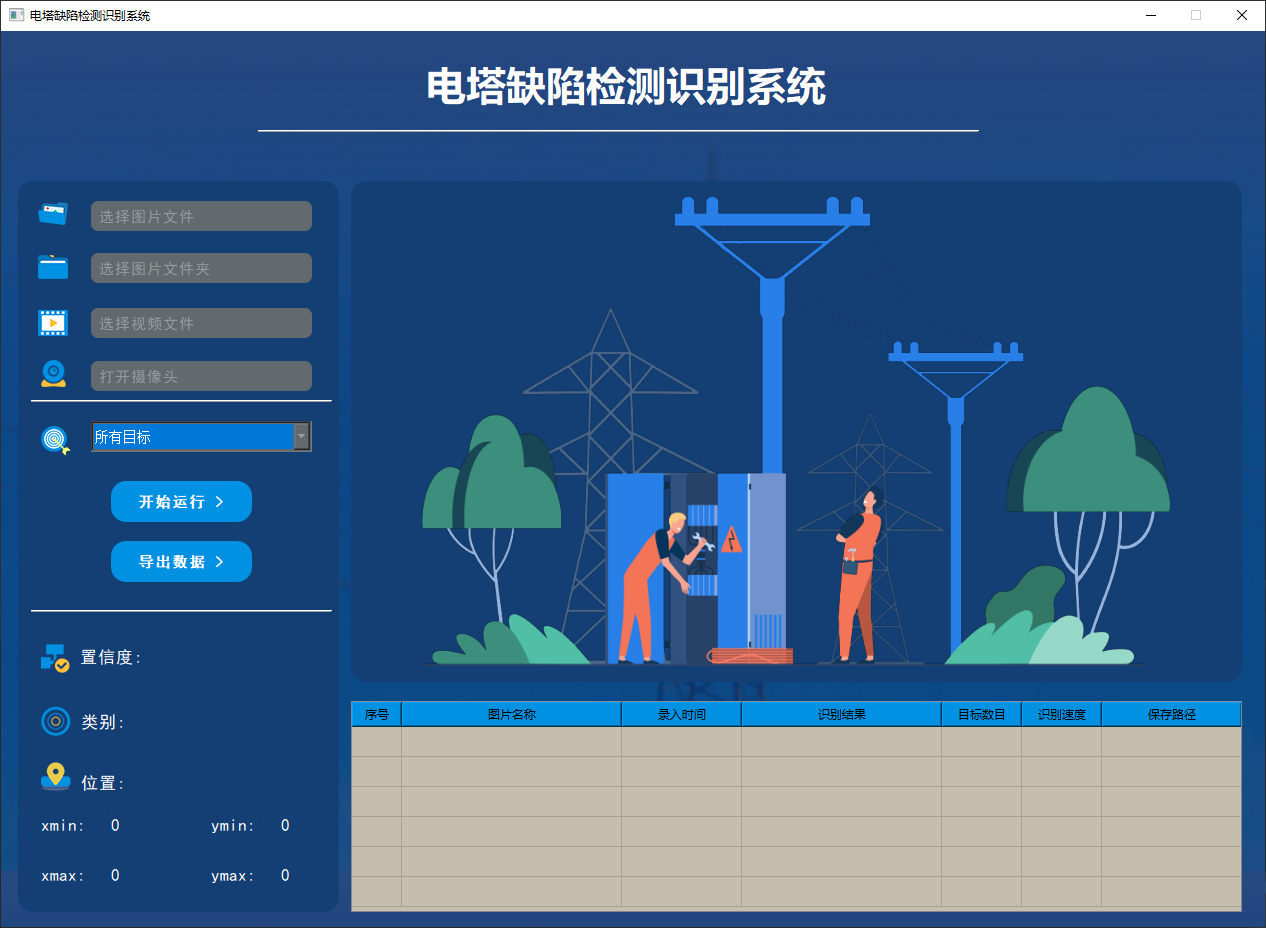
yolo11界面如下

关键词:电塔缺陷检测;深度学习;特征融合;注意力机制;卷积神经网络

一、整体资源介绍
项目中所用到的算法模型和数据集等信息如下:
算法模型:
yolov8、yolov8 + SE注意力机制 或 yolov5、yolov5 + SE注意力机制 或 yolo11、yolo11 + SE注意力机制
数据集:
网上下载的数据集,格式都已转好,可直接使用。
以上是本套代码算法的简单说明,添加注意力机制是本套系统的创新点 。
技术要点
- OpenCV:主要用于实现各种图像处理和计算机视觉相关任务。
- Python:采用这种编程语言,因其简洁易学且拥有大量丰富的资源和库支持。
- 数据增强技术: 翻转、噪点、色域变换,mosaic等方式,提高模型的鲁棒性。
功能展示:
部分核心功能如下:
- 功能1: 支持单张图片识别
- 功能2: 支持遍历文件夹识别
- 功能3: 支持识别视频文件
- 功能4: 支持摄像头识别
- 功能5: 支持结果文件导出(xls格式)
- 功能6: 支持切换检测到的目标查看
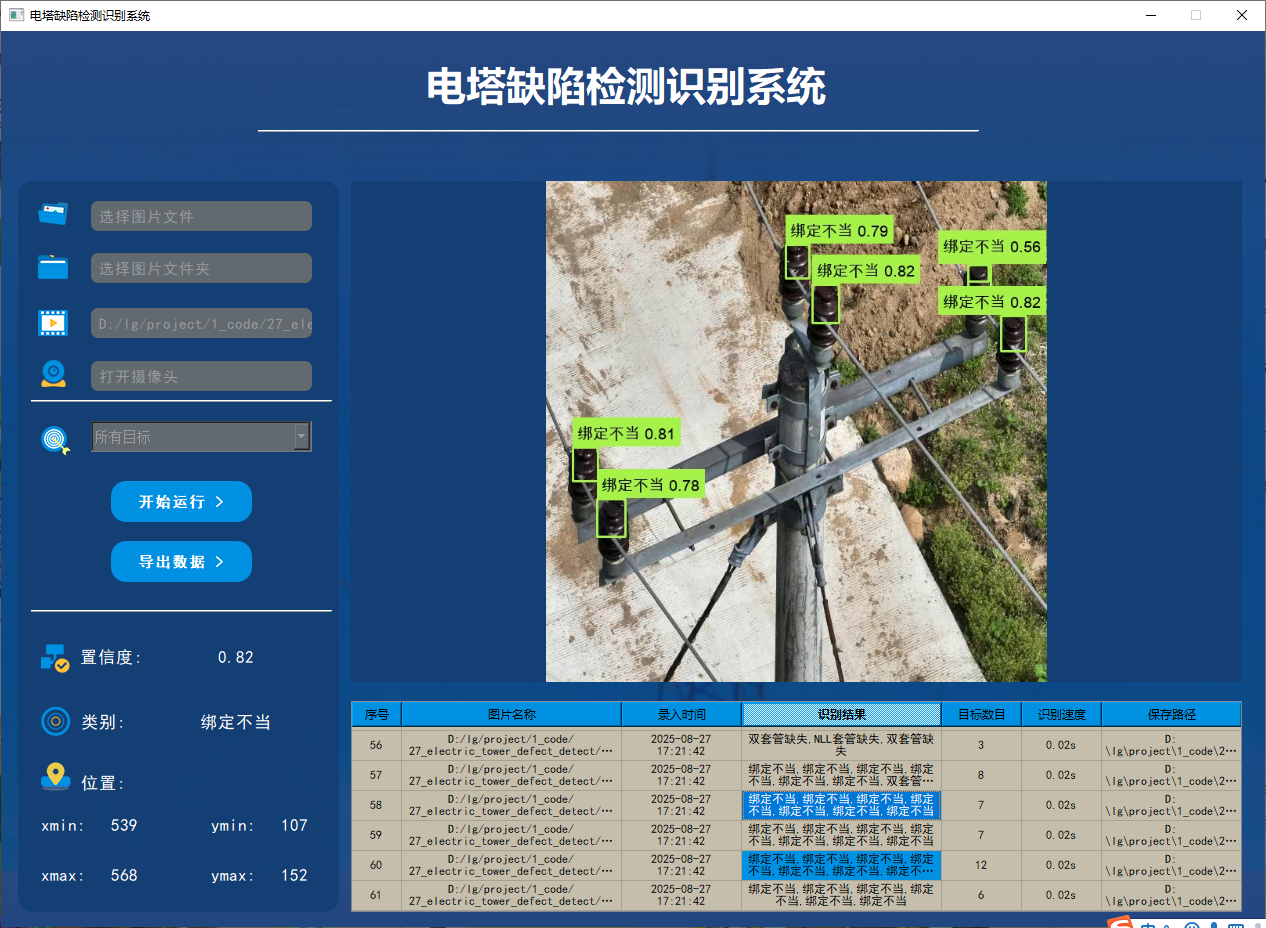
功能1 支持单张图片识别
系统支持用户选择图片文件进行识别。通过点击图片选择按钮,用户可以选择需要检测的图片,并在界面上查看所有识别结果。该功能的界面展示如下图所示:
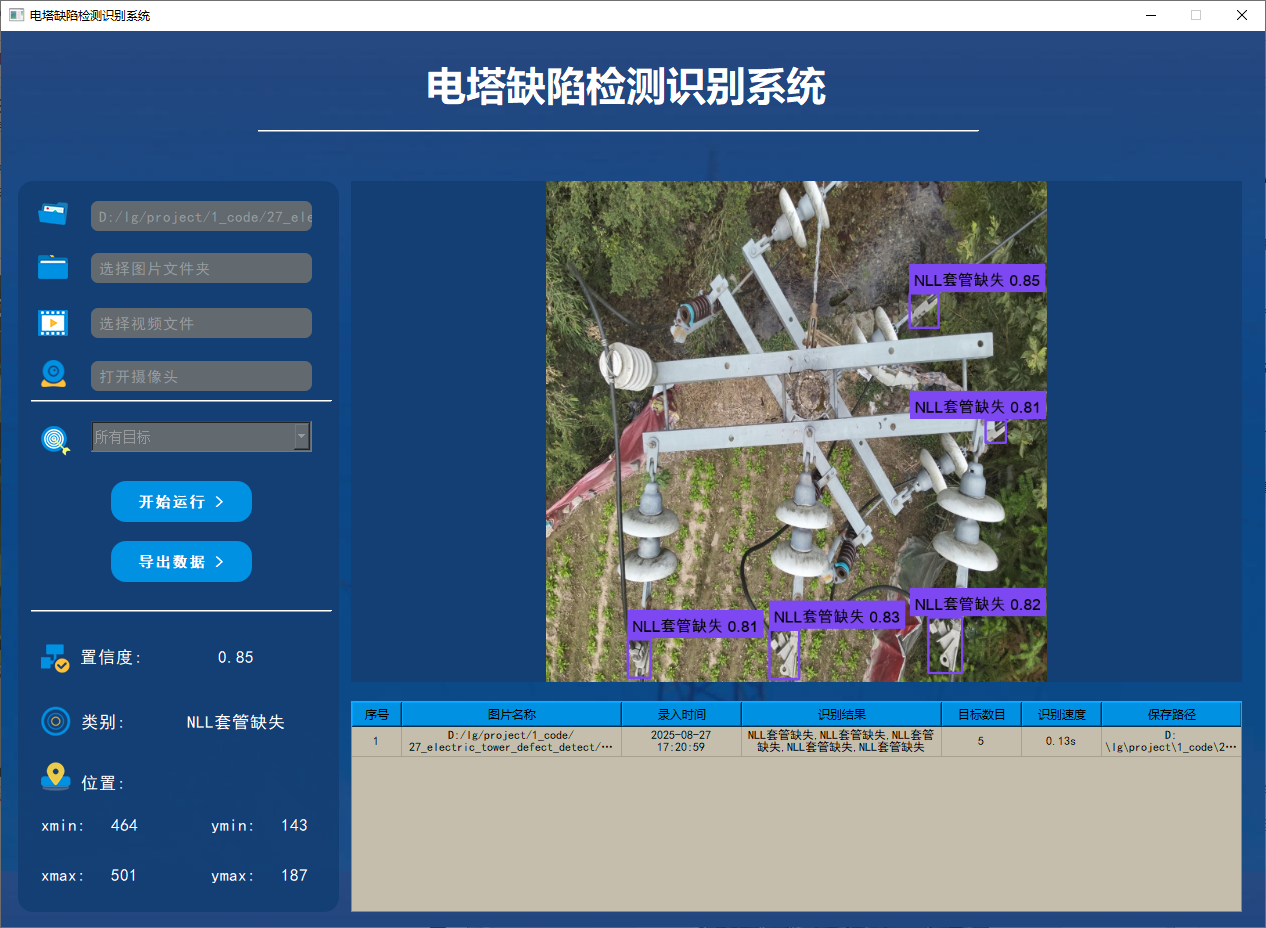
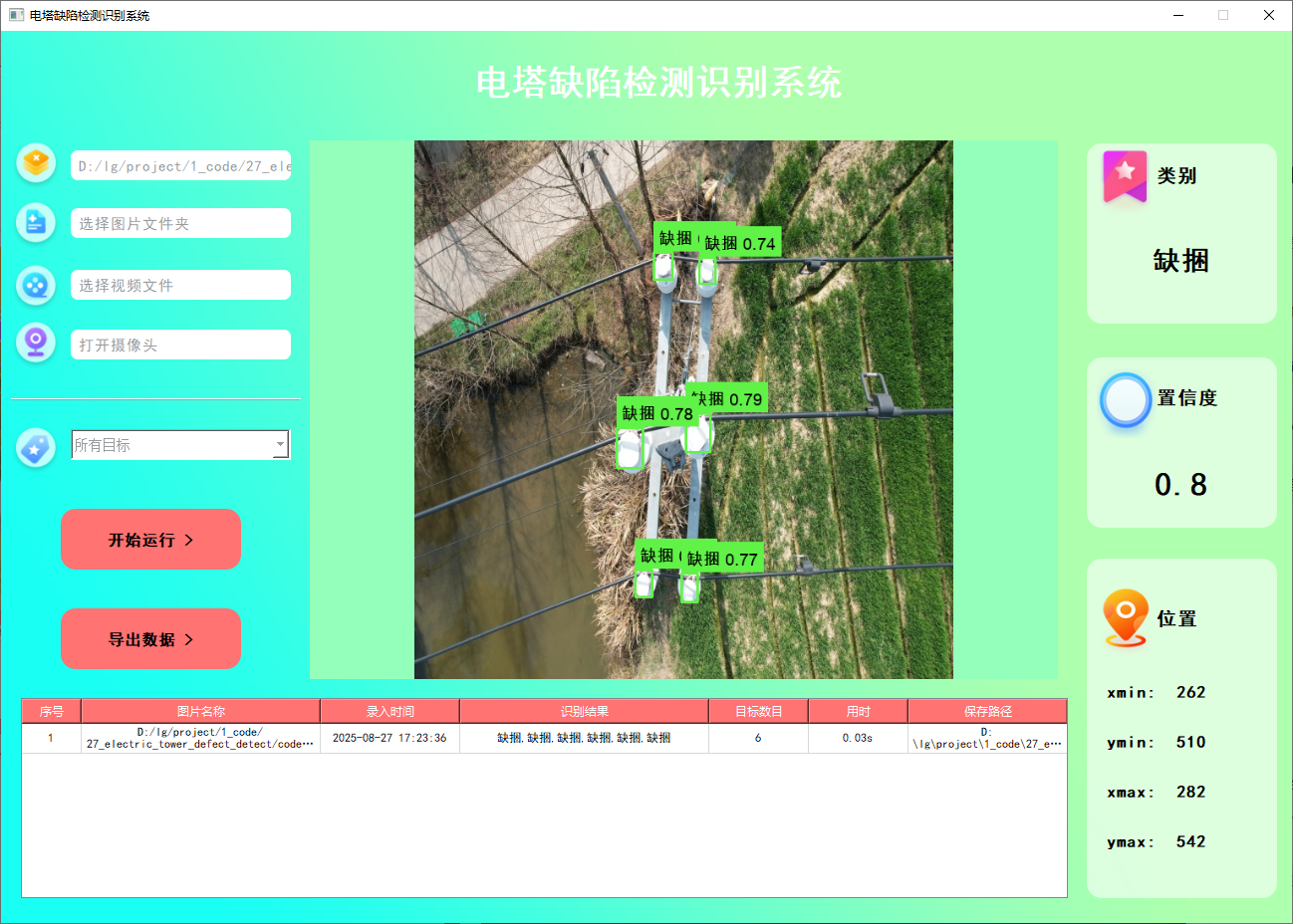
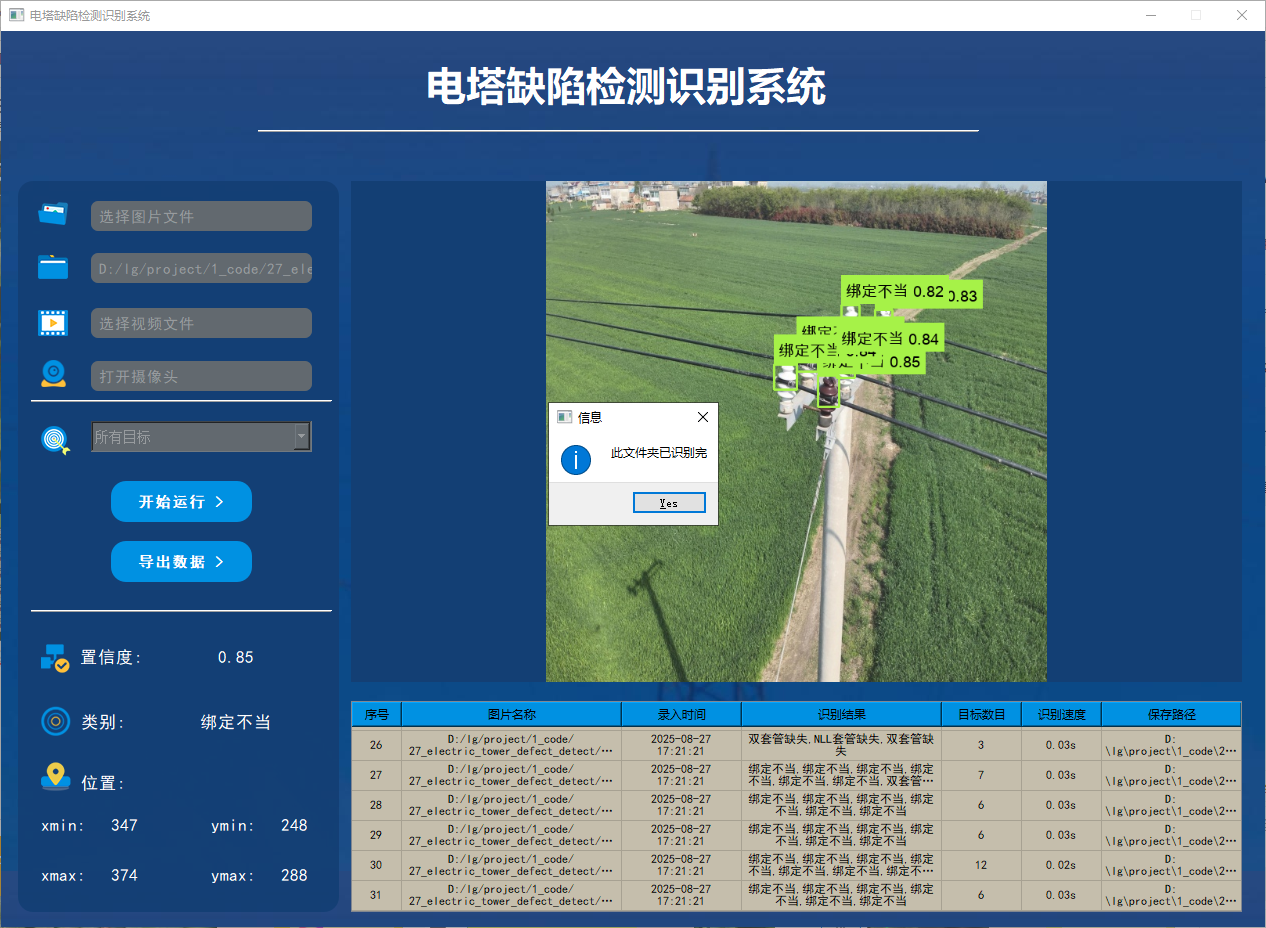
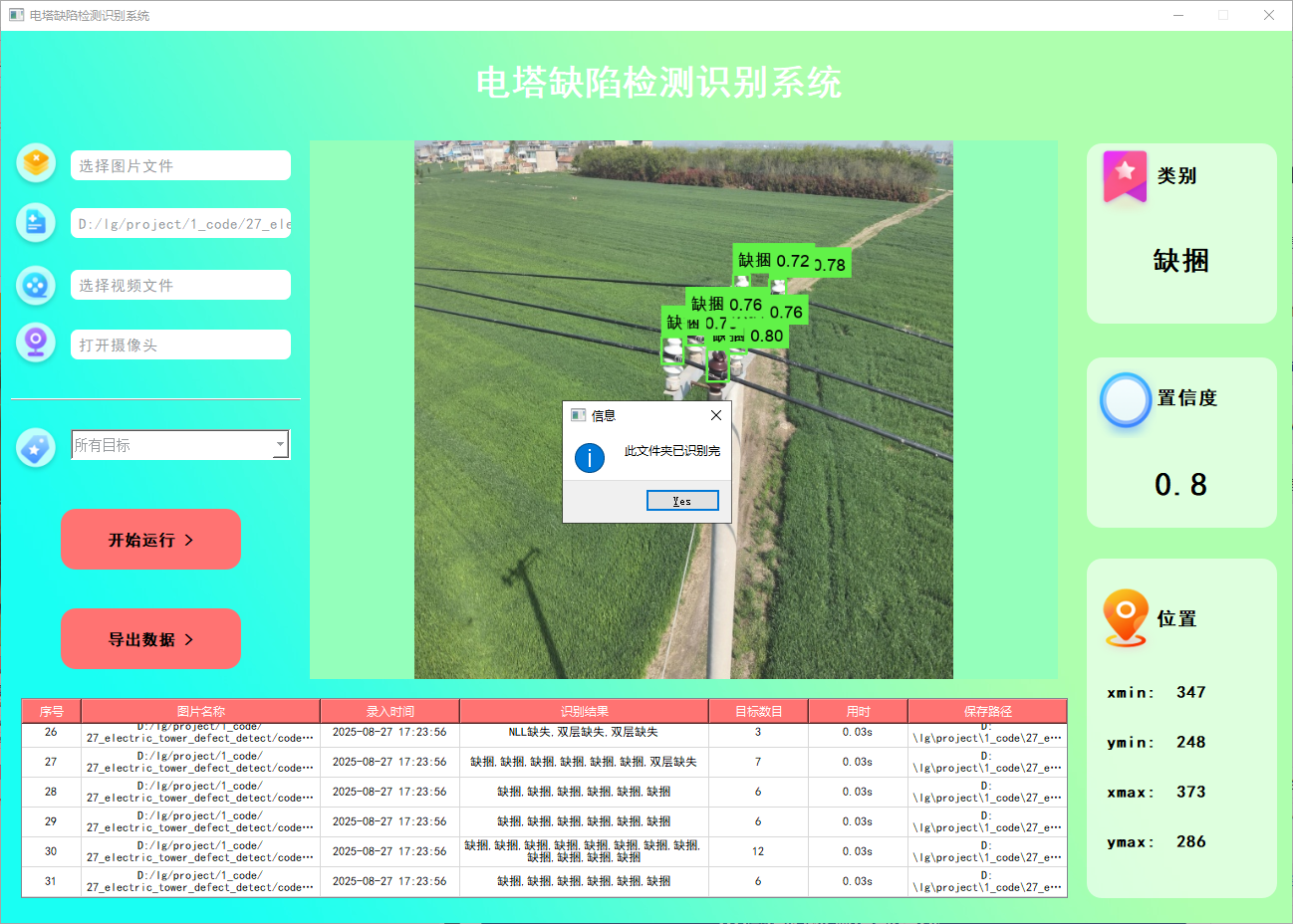
功能2 支持遍历文件夹识别
系统支持选择整个文件夹进行批量识别。用户选择文件夹后,系统会自动遍历其中的所有图片文件,并将识别结果实时更新显示在右下角的表格中。该功能的展示效果如下图所示:
功能3 支持识别视频文件
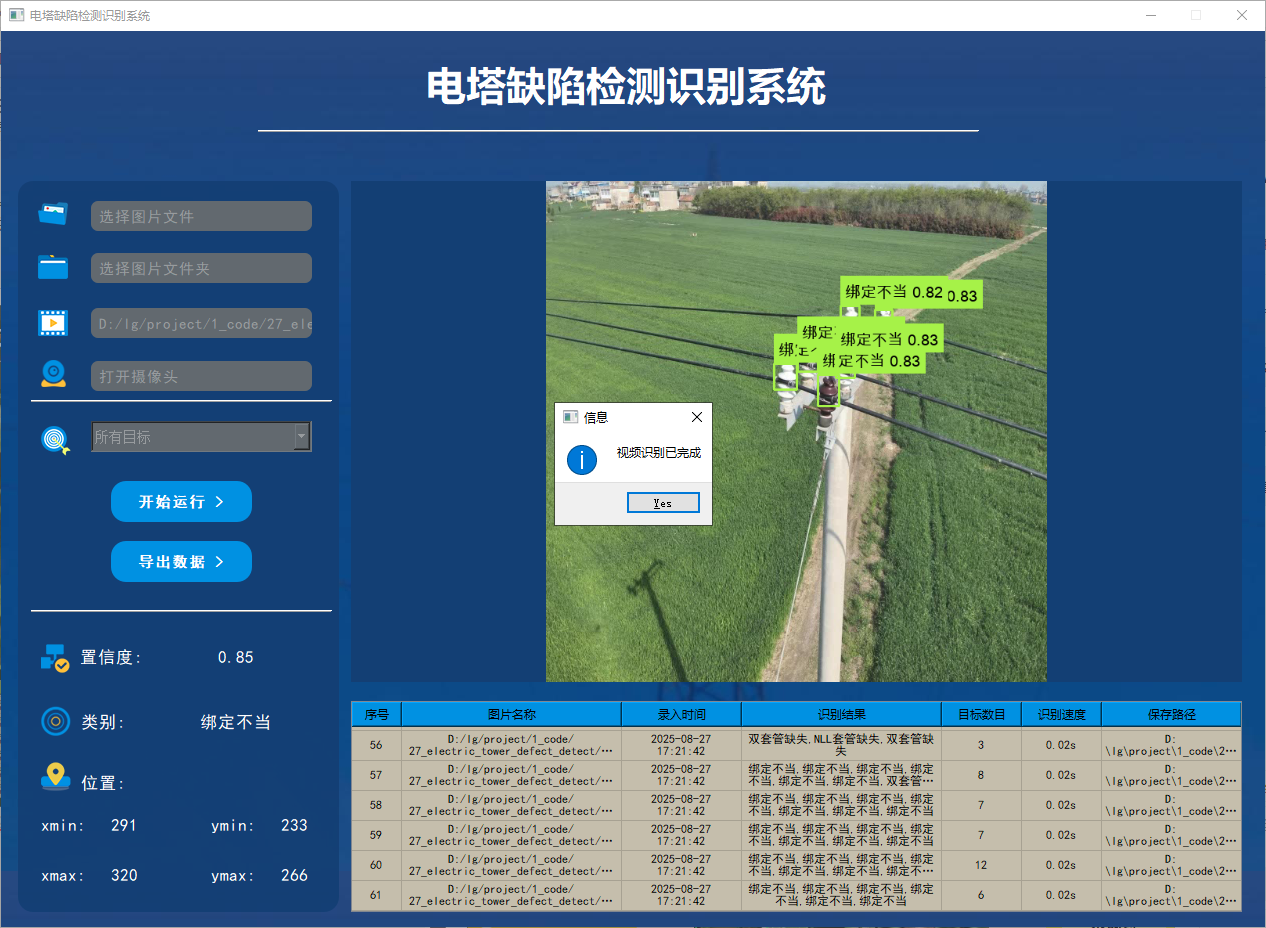
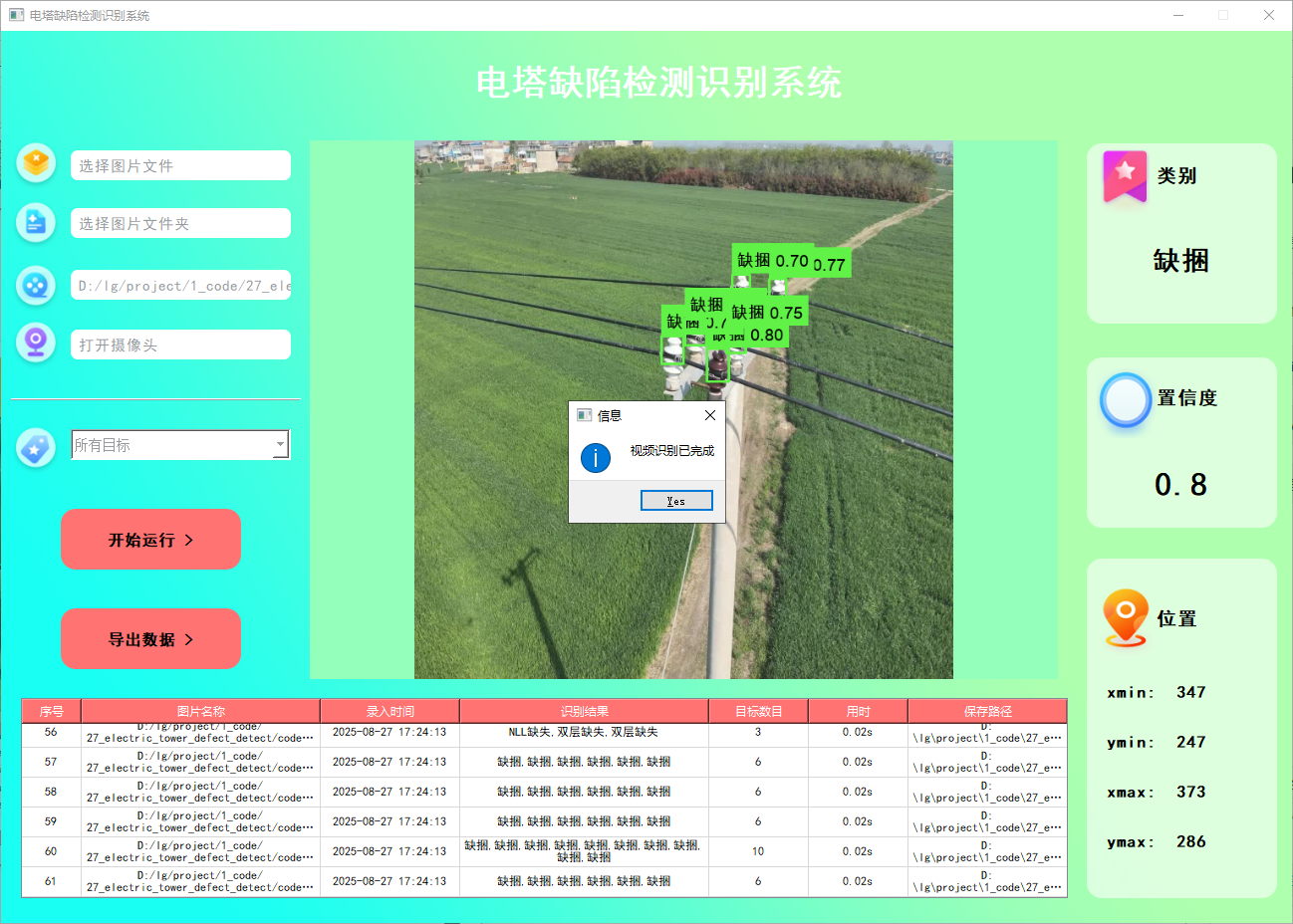
在许多情况下,我们需要识别视频中的目标。因此,系统设计了视频选择功能。用户点击视频按钮即可选择待检测的视频,系统将自动解析视频并逐帧识别多个车牌,同时将识别结果记录在右下角的表格中。以下是该功能的展示效果:
功能4 支持摄像头识别
在许多场景下,我们需要通过摄像头实时识别目标。为此,系统提供了摄像头选择功能。用户点击摄像头按钮后,系统将自动调用摄像头并进行实时车牌识别,识别结果会即时记录在右下角的表格中。
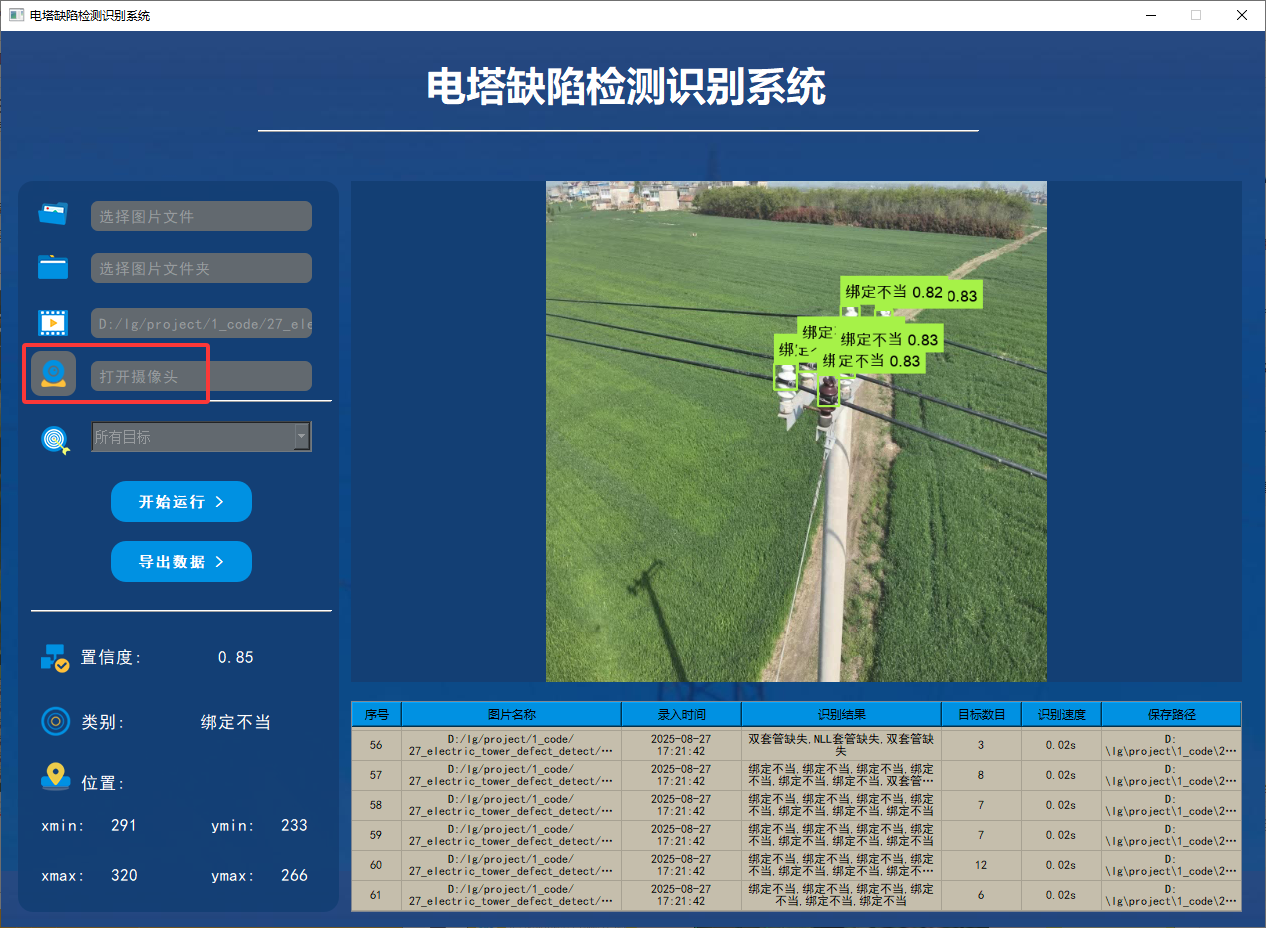
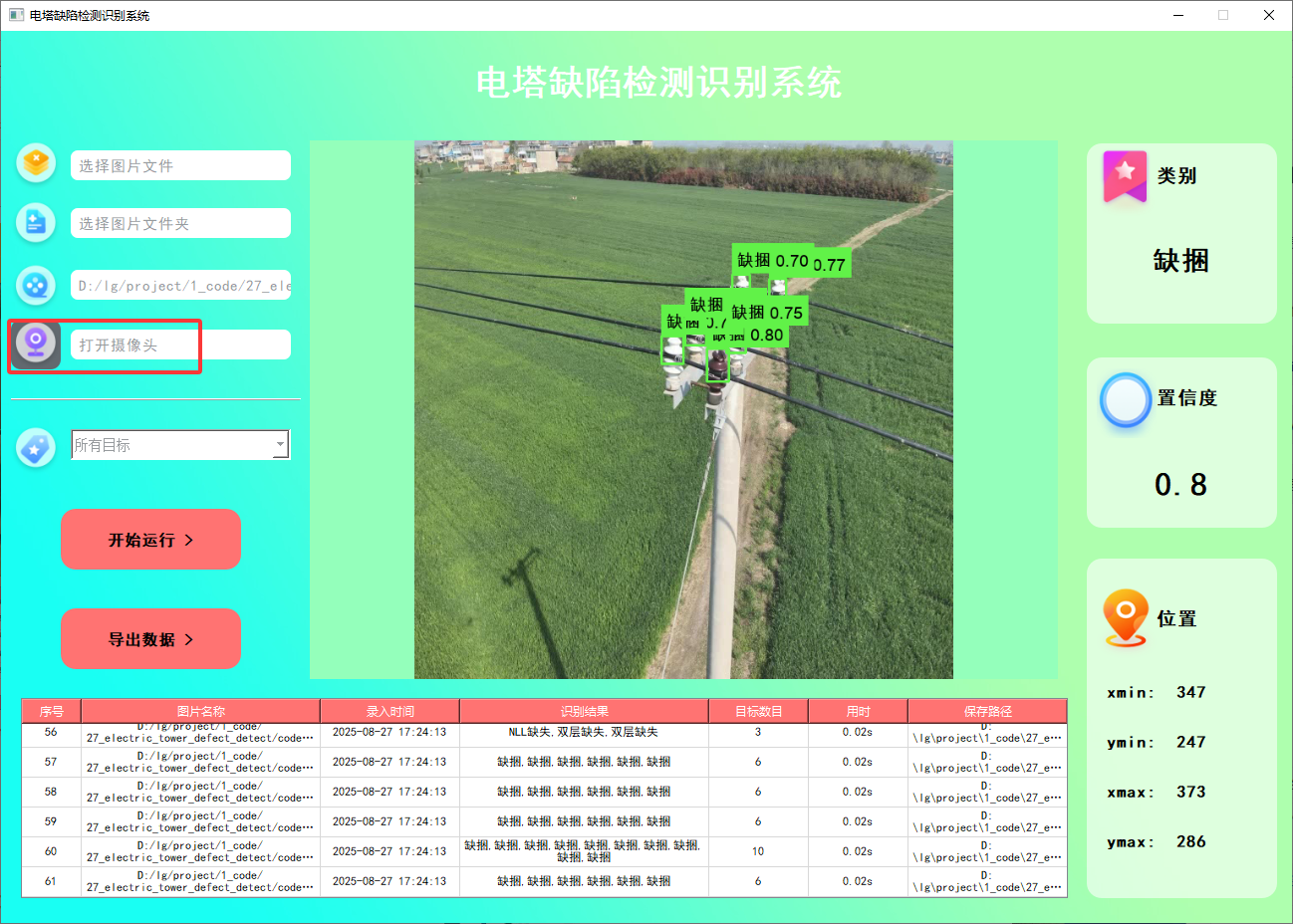
功能5 支持结果文件导出(xls格式)
本系统还添加了对识别结果的导出功能,方便后续查看,目前支持导出cvs和xls两种数据格式,功能展示如下:
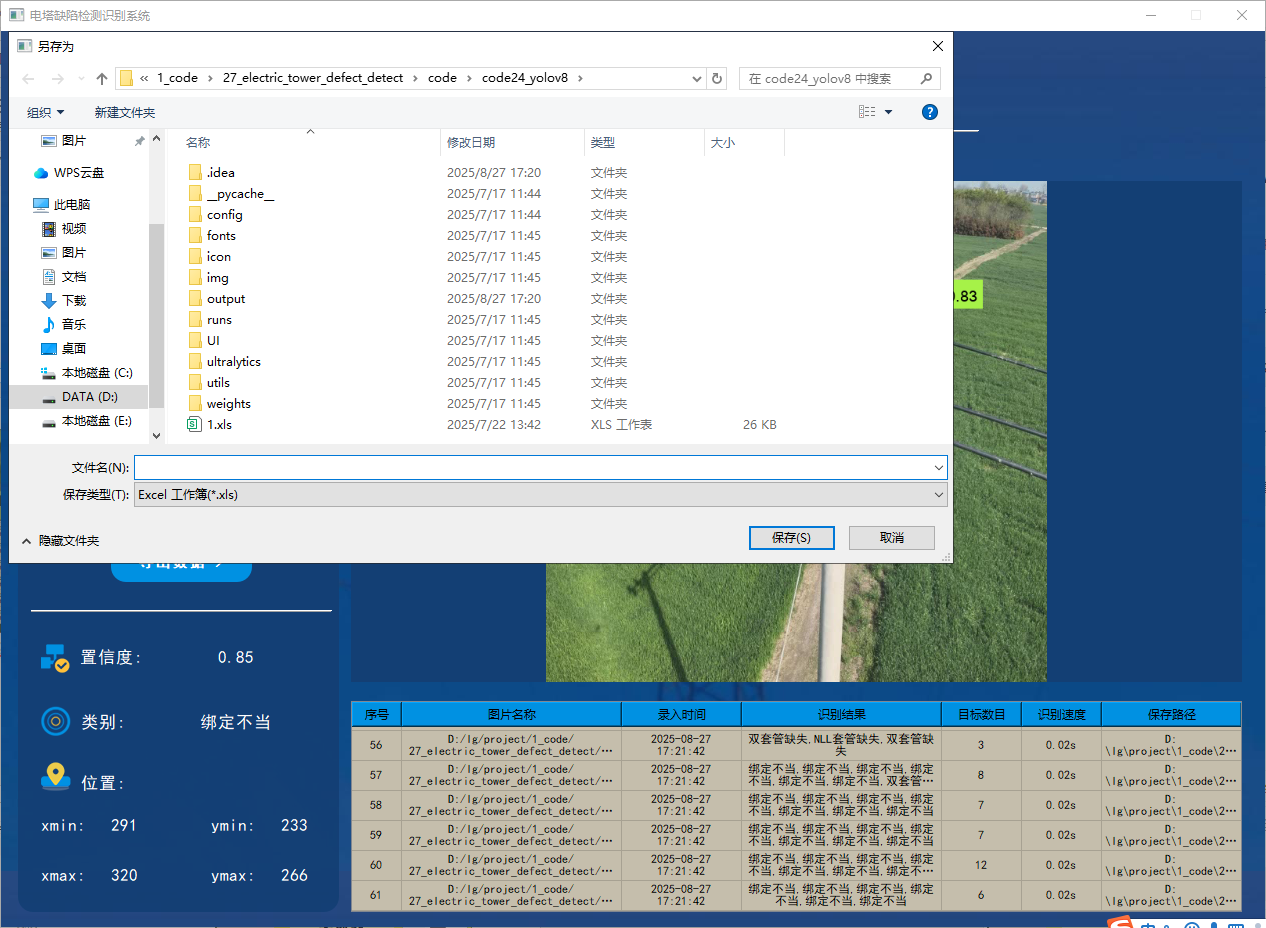
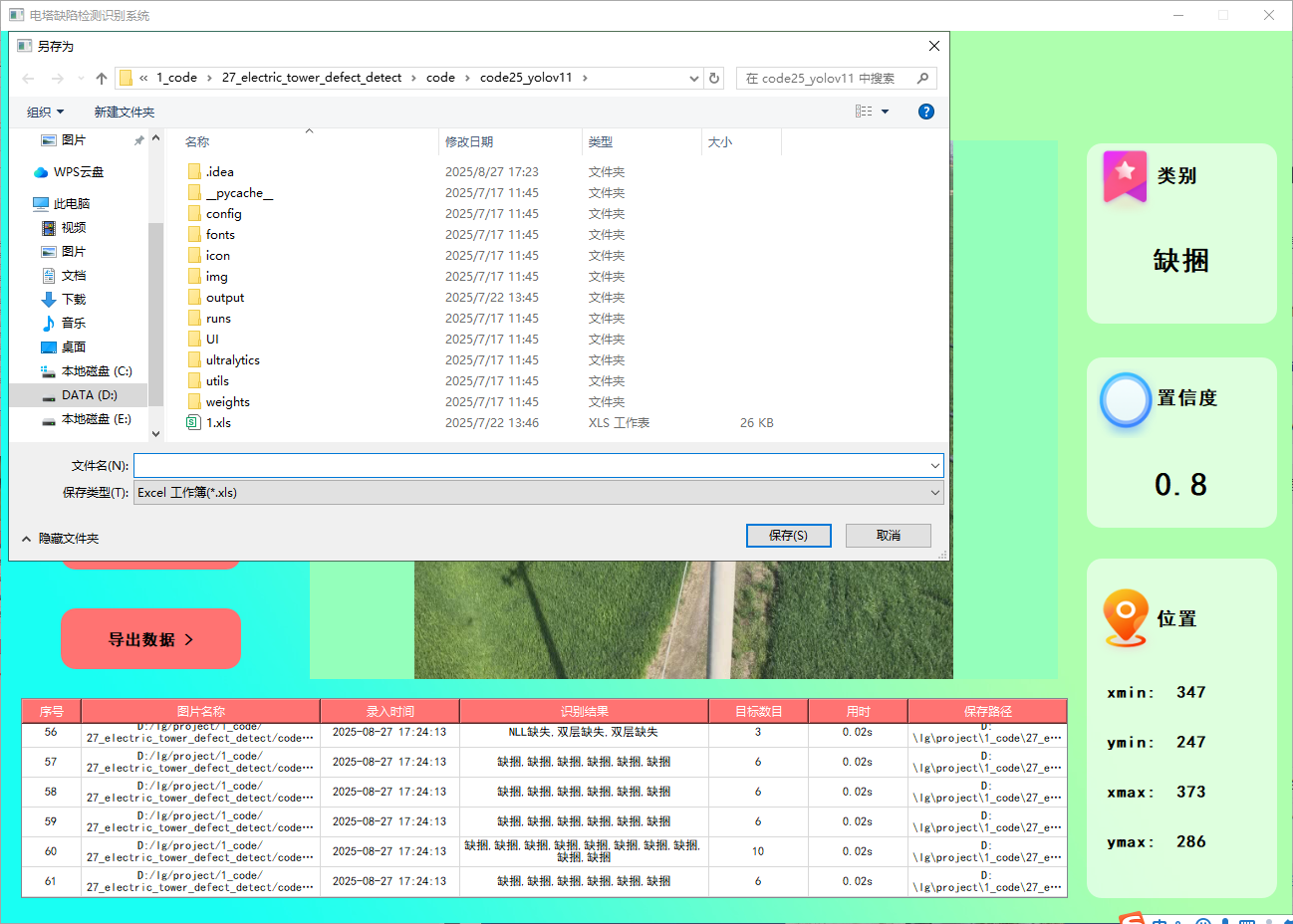
功能6 支持切换检测到的目标查看
二、系统环境与依赖配置说明
本项目采用 Python 3.8.10 作为开发语言,整个后台逻辑均由 Python 编写,主要依赖环境如下:
图形界面框架:
- PyQt5 5.15.9:用于搭建系统图形用户界面,实现窗口交互与组件布局。 深度学习框架:
- torch 1.9.0+cu111: PyTorch 深度学习框架,支持 CUDA 11.1 加速,用于模型构建与推理。
- torchvision 0.10.0+cu111:用于图像处理、数据增强及模型组件辅助。 CUDA与 cuDNN(GPU 加速支持):
- CUDA 11.1.1(版本号:cuda_11.1.1_456.81):用于 GPU 加速深度学习运算。
- cuDNN 8.0.5.39(适用于 CUDA 11.1):NVIDIA 深度神经网络库,用于加速模型训练与推理过程。 图像处理与科学计算:
- opencv-python 4.7.0.72:实现图像读取、显示、处理等功能。
- numpy 1.24.4:用于高效数组计算及矩阵操作。
- PIL (pillow) 9.5.0:图像文件读写与基本图像处理库。
- matplotlib 3.7.1(可选):用于结果图形化展示与可视化调试。
三、数据集
本数据集共包含 8983 张图像,涵盖5种输电塔及相关设备的典型缺陷类型,适用于输电线路巡检、智能识别与故障分类研究等场景。
具体类别说明如下:
- 绑定不当(improper_binding)
该类别表示输电塔导线或拉线固定方式不规范,如钢丝松动、捆绑松弛等问题,可能导致线路不稳定或安全隐患。 - 双套管缺失(double_case_miss)
指本应设置双层绝缘或保护套的部分仅安装一层或完全缺失,存在较大的电气安全风险。 - NLL套管缺失(nll_case_miss)
专指某型号(如NLL系列)紧固装置或护套缺失,通常影响接线可靠性和绝缘防护。 - 横杆腐蚀(bar_corrosion)
表示输电塔横向支撑杆出现明显锈蚀、掉漆或金属疲劳的情况,需尽快维护处理,以防结构受损。 - 塔头损坏(tower_head_damage)
包括塔顶的金属构件破裂、弯曲、缺失等多种物理损伤,属高危故障,影响整个输电系统的稳定性。
四、算法介绍
1. YOLOv8 概述
简介
YOLOv8算法的核心特性和改进如下:
- 全新SOTA模型
YOLOv8 提供了全新的最先进(SOTA)的模型,包括P5 640 和 P6 1280分辨率的目标检测网络,同时还推出了基于YOLACT的实例分割模型。与YOLOv5类似,它提供了N/S/M/L/X五种尺度的模型,以满足不同场景的需求。 - Backbone
骨干网络和Neck部分参考了YOLOv7 ELAN的设计思想。
将YOLOv5的C3结构替换为梯度流更丰富的C2f结构。
针对不同尺度的模型,调整了通道数,使其更适配各种任务需求。

网络结构如下:

相比之前版本,YOLOv8对模型结构进行了精心微调,不再是“无脑”地将同一套参数应用于所有模型,从而大幅提升了模型性能。这种优化使得不同尺度的模型在面对多种场景时都能更好地适应。
然而,新引入的C2f模块虽然增强了梯度流,但其内部的Split等操作对特定硬件的部署可能不如之前的版本友好。在某些场景中,C2f模块的这些特性可能会影响模型的部署效率。
2. YOLOv5 概述
简介
YOLOV5有YOLOv5n,YOLOv5s,YOLOv5m,YOLOV5l、YOLO5x五个版本。这个模型的结构基本一样,不同的是deth_multiole模型深度和width_multiole模型宽度这两个参数。就和我们买衣服的尺码大小排序一样,YOLOV5n网络是YOLOV5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。不过最常用的一般都是yolov5s模型。

本系统采用了基于深度学习的目标检测算法——YOLOv5。作为YOLO系列算法中的较新版本,YOLOv5在检测的精度和速度上相较于YOLOv3和YOLOv4都有显著提升。它的核心理念是将目标检测问题转化为回归问题,简化了检测过程并提高了性能。
YOLOv5引入了一种名为SPP (Spatial Pyramid Pooling)的特征提取方法。SPP能够在不增加计算量的情况下,提取多尺度特征,从而显著提升检测效果。
在检测流程中,YOLOv5首先通过骨干网络对输入图像进行特征提取,生成一系列特征图。然后,对这些特征图进行处理,生成检测框和对应的类别概率分数,即每个检测框内物体的类别和其置信度。
YOLOv5的特征提取网络采用了CSPNet (Cross Stage Partial Network)结构。它将输入特征图分成两部分,一部分通过多层卷积处理,另一部分进行直接下采样,最后再将两部分特征图进行融合。这种设计增强了网络的非线性表达能力,使其更擅长处理复杂背景和多样化物体的检测任务。

3. YOLO11 概述
YOLOv11:Ultralytics 最新目标检测模型
YOLOv11 是 Ultralytics 公司在 2024 年推出的 YOLO 系列目标检测模型的最新版本。以下是对 YOLOv11 的具体介绍:
主要特点
-
增强的特征提取:
- 采用改进的骨干和颈部架构,如在主干网络中引入了 c2psa 组件,并将 c2f 升级为 c3k2。
- c3k 允许用户自定义卷积模块的尺寸,提升了灵活性。
- c2psa 通过整合 psa(位置敏感注意力机制)来增强模型的特征提取效能。
- 颈部网络采用了 pan 架构,并集成了 c3k2 单元,有助于从多个尺度整合特征,并优化特征传递的效率。
-
针对效率和速度优化:
- 精细的架构设计和优化的训练流程,在保持准确性和性能最佳平衡的同时,提供更快的处理速度。
- 相比 YOLOv10,YOLOv11 的延迟降低了 25%-40%,能够达到每秒处理 60 帧 的速度,是目前最快的目标检测模型之一。
-
更少的参数,更高的准确度:
- YOLOv11m 在 COCO 数据集上实现了比 YOLOv8m 更高的 mAP,参数减少了 22%,提高了计算效率,同时不牺牲准确度。
-
跨环境的适应性:
- 可无缝部署在 边缘设备、云平台 和配备 NVIDIA GPU 的系统上,确保最大的灵活性。
-
支持广泛的任务范围:
- 支持多种计算机视觉任务,包括 目标检测、实例分割、图像分类、姿态估计 和 定向目标检测(OBB)。
架构改进
-
主干网络:
- 引入了 c2psa 组件,并将 c2f 升级为 c3k2。
- c3k 支持用户自定义卷积模块尺寸,增强灵活性。
- c2psa 整合了 psa(位置敏感注意力机制),提升特征提取效能。
-
颈部网络:
- 采用 pan 架构,并集成了 c3k2 单元,帮助从多个尺度整合特征并优化特征传递效率。
-
头部网络:
- YOLOv11 的检测头设计与 YOLOv8 大致相似。
- 在分类(cls)分支中,采用了 深度可分离卷积 来增强性能。
性能优势
-
精度提升:
- 在 COCO 数据集上取得了显著的精度提升:
- YOLOv11x 模型的 mAP 得分高达 54.7%。
- 最小的 YOLOv11n 模型也能达到 39.5% 的 mAP 得分。
- 与前代模型相比,精度有明显进步。
- 在 COCO 数据集上取得了显著的精度提升:
-
速度更快:
- 能够满足实时目标检测需求
🌟 五、模型训练步骤
提供封装好的训练脚本,如下图,更加详细的的操作步骤可以参考我的飞书在线文档:https://aax3oiawuo.feishu.cn/wiki/HLpVwQ4QWiTd4Ckdeifcvvdtnve , 强烈建议直接看文档去训练模型,文档是实时更新的,有任何的新问题,我都会实时的更新上去。另外B站也会提供视频。
-
使用pycharm打开代码,找到
train.py打开,示例截图如下:

-
修改
model_yaml的值,根据自己的实际情况修改,想要训练yolov8s模型 就 修改为model_yaml = yaml_yolov8s, 训练 添加SE注意力机制的模型就修改为model_yaml = yaml_yolov8_SE -
修改
data_path数据集路径,我这里默认指定的是traindata.yaml文件,如果训练我提供的数据,可以不用改 -
修改
model.train()中的参数,按照自己的需求和电脑硬件的情况更改# 文档中对参数有详细的说明 model.train(data=data_path, # 数据集imgsz=640, # 训练图片大小epochs=200, # 训练的轮次batch=2, # 训练batchworkers=0, # 加载数据线程数device='0', # 使用显卡optimizer='SGD', # 优化器project='runs/train', # 模型保存路径name=name, # 模型保存命名) -
修改
traindata.yaml文件, 打开traindata.yaml文件,如下所示:

在这里,只需修改 path 的值,其他的都不用改动(仔细看上面的黄色字体),我提供的数据集默认都是到yolo文件夹,设置到 yolo 这一级即可,修改完后,返回train.py中,执行train.py。 -
打开
train.py,右键执行。

-
出现如下类似的界面代表开始训练了

-
训练完后的模型保存在runs/train文件夹下

🌟 六、模型评估步骤
-
打开
val.py文件,如下图所示:

-
修改
model_pt的值,是自己想要评估的模型路径 -
修改
data_path,根据自己的实际情况修改,具体如何修改,查看上方模型训练中的修改步骤 -
修改
model.val()中的参数,按照自己的需求和电脑硬件的情况更改model.val(data=data_path, # 数据集路径imgsz=300, # 图片大小,要和训练时一样batch=4, # batchworkers=0, # 加载数据线程数conf=0.001, # 设置检测的最小置信度阈值。置信度低于此阈值的检测将被丢弃。iou=0.6, # 设置非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。有助于减少重复检测。device='0', # 使用显卡project='runs/val', # 保存路径name='exp', # 保存命名) -
修改完后,即可执行程序,出现如下截图,代表成功(下图是示例,具体以自己的实际项目为准。)

-
评估后的文件全部保存在在
runs/val/exp...文件夹下

🌟 七、训练结果
我们每次训练后,会在 run/train 文件夹下出现一系列的文件,如下图所示:
如果大家对于上面生成的这些内容(confusion_matrix.png、results.png等)不清楚是什么意思,可以在我的知识库里查看这些指标的具体含义,示例截图如下:

🌟八、完整代码
如果您希望获取博文中提到的所有实现相关的完整资源文件(包括测试图片、视频、Python脚本、UI文件、训练数据集、训练代码、界面代码等),这些文件已被全部打包。以下是完整资源包的截图:

您可以通过下方演示视频的视频简介部分进行获取
演示视频:
27-基于深度学习的电塔缺陷检测识别系统-yolov8/yolov5-经典版界面
27-基于深度学习的电塔缺陷检测识别系统-yolo11-彩色版界面