电商双 11 美妆数据分析:从数据清洗到市场洞察
在电商行业中,双 11 作为年度重要促销节点,美妆品类的销售数据蕴含着丰富的市场规律。本文基于淘宝双 11 美妆商品数据(27598 条记录),通过数据清洗、特征工程与可视化分析,挖掘消费者行为与品牌表现的关键 insights,为电商运营提供决策参考。
数据包含 7 个核心字段:
update_time:数据更新时间id:商品唯一标识title:商品标题price:商品价格(元)sale_count:销量comment_count:评论数店名:销售店铺名称
重复值处理
原始数据存在 86 条重复记录,通过drop_duplicates方法去重后保留 27512 条有效数据:
data = df.drop_duplicates(inplace=False) # 去重
data.reset_index(inplace=True, drop=True) # 重置索引
分析发现sale_count(销量)和comment_count(评论数)存在缺失,结合业务逻辑判断缺失值代表 “未销售”,故用 0 填充:
data = data.fillna(0) # 填充缺失值
商品标题分词
使用jieba库对商品标题进行分词,提取关键特征用于后续分类:
import jieba
subtitle = [ ]
for each in data['title']:
k = jieba.lcut_for_search(each) # 搜索引擎模式分词
subtitle.append(k)
data['subtitle'] = subtitle
商品分类体系构建
基于行业知识定义三级分类规则(大类 - 小类 - 关键词),通过字典映射实现自动分类:
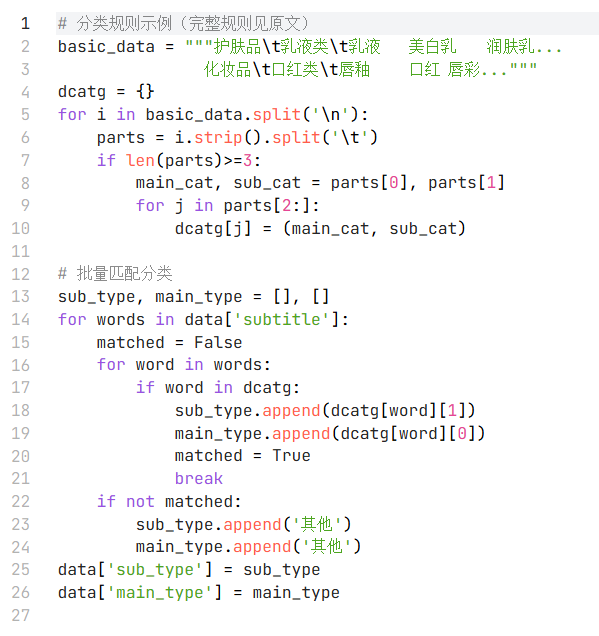
(3)新增业务特征
- 是否男士专用:基于标题关键词识别(如 “男士”“男用”)
- 销售额:通过
price * sale_count计算 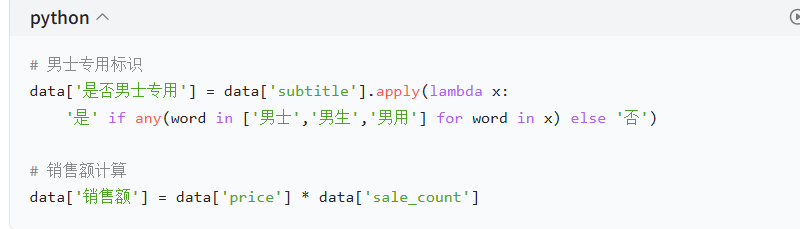
核心分析与可视化
品牌表现分析
通过对比各品牌的商品数量、销量、销售额及客单价,发现:
- 悦诗风吟商品数量最多(3021 款),但销量仅排第三,客单价偏低
- 相宜本草销量和销售额均居首位,客单价不足 200 元,性价比策略显著
- 高端品牌(如雅诗兰黛)客单价超 500 元,销售额依赖品牌溢价
价格区间影响
将品牌按客单价分为 4 类(0-100 元、100-200 元、200-300 元、300 + 元),分析发现:
- 低价区间(0-100 元)品牌销售额占比最高,消费者对美妆产品价格敏感度高
- 高价区间品牌中,雅诗兰黛贡献超 50% 销售额,品牌忠诚度显著
3.3 品类销售结构
- 大类:护肤品销量占比超 60%,远高于化妆品(30%)及其他品类
- 小类:清洁类(洗面奶、卸妆产品)和补水类(面膜、爽肤水)为销量前二,合计占比超 50%
3.4 性别差异分析
- 男士专用商品销量仅占总销量的 8%,但清洁类(如男士洗面奶)占男士消费的 70%
- 妮维雅、欧莱雅占据男士市场主要份额,相宜本草潜力较大
3.5 时间趋势洞察
- 双 11 当天销量反而下滑,9 日达到峰值(预热活动效果显著)
- 消费者存在 “错峰下单” 心理,避免当天平台卡顿
四、结论与建议
- 定价策略:中低端品牌(客单价 < 200 元)可通过规模化提升销售额;高端品牌需强化品牌价值
- 品类布局:重点拓展清洁类、补水类护肤品,同时关注男士专用产品线的空白市场
- 营销节奏:双 11 预热期(11 月 1-10 日)为核心转化窗口,可加大优惠券发放力度;活动后通过返券刺激二次消费
- 数据监控:对评论数与销量比例异常的品牌(如相宜本草)需排查刷单风险
-
通过本次分析可见,美妆电商的竞争已从单一价格战转向 “性价比 + 精准营销 + 品类创新” 的综合较量,数据驱动的精细化运营将成为核心竞争力。