CacheBlend:结合缓存知识融合的快速RAG大语言模型推理服务
温馨提示:
本篇文章已同步至"AI专题精讲" CacheBlend:结合缓存知识融合的快速RAG大语言模型推理服务
摘要
大语言模型(LLMs)通常在输入中包含多个文本片段,以提供必要的上下文。为了加速对较长LLM输入的预填充(prefill),可以预先计算文本的KV缓存,并在该上下文作为另一个LLM输入前缀时复用KV缓存。然而,被复用的文本片段并不总是作为输入前缀,这导致预计算的KV缓存无法直接使用,因为它们忽略了该文本与前置文本之间的交叉注意力。因此,KV缓存复用的优势在很大程度上尚未被实现。
本文聚焦于一个核心挑战:当LLM输入包含多个文本片段时,如何快速组合它们的预计算KV缓存,以实现与昂贵的完整预填充(即不复用KV缓存)相同的生成质量?该挑战在检索增强生成(RAG)中尤为常见,其中输入通常包含多个作为上下文的检索文本。我们提出了CacheBlend,这是一种可以复用预计算KV缓存的方案,无论其是否为前缀,并通过选择性地重新计算一小部分token的KV值来对每个复用的KV缓存进行部分更新。同时,重新计算部分token所需的轻微延迟可以与KV缓存的检索过程在同一任务中进行流水线化,从而使CacheBlend能够将KV缓存存储在更慢但容量更大的设备上,并在不增加推理延迟的前提下完成检索。
我们在三个不同规模的开源LLM和四个主流基准任务上,将CacheBlend与当前最先进的KV缓存复用方案进行比较。结果表明,CacheBlend在不降低生成质量的情况下,将首token生成时间(TTFT)减少了2.2–3.3倍,推理吞吐量提高了2.8–5倍。代码开源地址:https://github.com/LMCache/LMCache
CCS 分类概念 • 计算方法 → 自然语言处理;• 网络 → 云计算;• 信息系统 → 数据管理系统。
关键词 大语言模型,KV缓存,检索增强生成(RAG)
1 引言
由于其卓越的能力,大语言模型(LLMs)被广泛应用于个人助理、人工智能医疗和问答系统中 [1, 3, 4, 9]。为了确保高质量和一致性的响应,应用程序通常会在用户查询中添加额外文本,以提供必要的领域知识或用户特定信息。一个典型的例子是检索增强生成(RAG),其中用户查询前会添加多个从数据库中检索的文本片段,以构成LLM输入。
然而,这些上下文文本片段会显著降低LLM的推理速度。这是因为,在生成任何token之前,LLM首先需要通过预填充处理整个输入,以生成KV缓存——这是一个与每个输入token相关的张量的拼接,表示该token与其前序token之间的“注意力”关系。因此,预填充的延迟决定了首token生成时间(TTFT)。我们将其称为完整KV重计算(如图1(a)所示)。尽管已有许多优化手段,预填充的延迟和计算成本仍随着输入长度的增加呈超线性增长,在处理较长的LLM输入(例如RAG场景)时,这种开销很容易成为性能瓶颈 [11, 53, 60]。
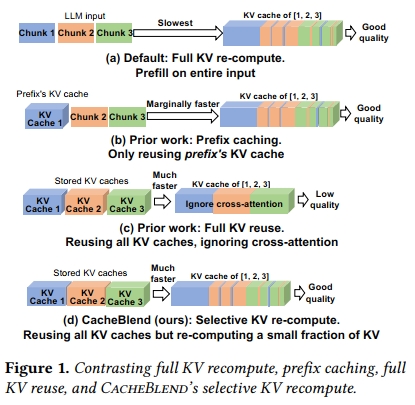
那么,我们该如何加速LLM输入的预填充过程呢?近期的优化方法利用了一个事实:相同的上下文文本通常会被多个LLM输入重复使用。因此,可以预先计算这些文本的KV缓存,并在之后复用这些已存储的KV缓存,以避免在这些复用文本上重复进行预填充操作。
现有方法的局限性: 目前关于KV缓存复用的方案主要有两类,但它们都存在一定的限制。
第一种,前缀缓存(prefix caching),只存储并复用LLM输入前缀的KV缓存 [33, 36, 41, 42, 59](见图1(b))。由于前缀的KV缓存不依赖后续文本,因此这种方法不会影响生成质量。然而,许多应用(如RAG)在LLM输入中包含多个文本片段,而不仅仅是一个,以提供所有必要的上下文信息,确保良好的响应质量。因此,只有第一个文本片段是前缀,其他被复用的文本的KV缓存则无法复用。结果是,当输入中包含许多复用文本片段时,前缀缓存的推理速度几乎与完整KV重计算一样慢。
第二种,完整KV复用(full KV reuse),试图解决上述问题(见图1©)。当一个复用文本不是输入前缀时,它仍然可以通过调整其位置嵌入(positional embedding)来复用KV缓存,以使LLM生成出有意义的输出 [24]。然而,这种方法忽略了一个重要的因素——跨注意力(cross-attention),即一个片段中的token与其前序片段中的token之间的注意力关系。由于前置片段在预计算阶段并不确定,跨注意力信息无法预计算。但这种注意力对于某些需要综合多个片段信息的问题(例如关于地缘政治的问题,其中包含地理和政治内容的片段)是至关重要的。§3.3部分提供了具体示例,说明为何前缀缓存和模块化缓存在某些场景下不足以满足需求。
我们的方法: 本文聚焦于一个问题:当LLM输入包含多个文本片段时,如何快速组合它们各自的预计算KV缓存,以达到与完整预填充相同的生成质量?换句话说,我们希望兼具完整KV复用的速度和完整KV重计算的生成质量。
我们提出CacheBlend,这是一个系统,能够融合多个已预计算的KV缓存,无论这些缓存是否来自前缀。具体而言,CacheBlend会根据当前LLM输入中的前序文本,选择性地重新计算一小部分token的KV缓存,我们称之为选择性KV重计算(selective KV recompute)(见图1(d))。从高层次来看,选择性KV重计算在每一层中以传统的方式对输入文本进行预填充;但在每一层内,它只更新一小部分token的KV,而复用其余token的KV。
与完整KV重计算相比,更新比例小于15%通常就足以生成相同质量的输出,这是基于我们的实证经验。之所以只需更新少量KV就能维持生成质量,其根本原因在于注意力矩阵的稀疏性(详见§4.3)。
与完整KV复用相比,CacheBlend在仅增加少量KV更新计算的情况下获得了更高的生成质量。而且,这些额外的计算并不会增加推理延迟,因为CacheBlend会将一层中的部分KV更新与下一层KV缓存从磁盘加载到GPU内存的过程并行化。这种流水线处理使得CacheBlend可以将KV缓存存储在速度较慢但容量更大的非易失性设备(如磁盘)上,而不会带来额外延迟,从而实现更多KV缓存的存储与复用。
从整体贡献来看,CacheBlend实现了在单个LLM输入中复用多个文本片段KV缓存的能力,而不牺牲生成质量。这一方法补充了近期在减少KV缓存存储大小 [28, 35, 42, 43, 45, 58] 和优化KV缓存访问模式 [33, 59] 方面的研究。
我们在vLLM之上实现了CacheBlend,并在三个不同规模的开源LLM和三个主流基准数据集上的两个任务(RAG和问答)上,对CacheBlend与当前最先进的KV缓存复用方案进行了比较。结果表明,与前缀缓存相比,CacheBlend将首token生成时间(TTFT)降低了2.2–3.3倍,推理吞吐量提高了2.8–5倍,同时不降低生成质量,也不增加存储开销。与完整KV复用相比,CacheBlend在保持几乎相同TTFT的同时,在问答任务上提升了0.1–0.2的F1绝对分数,在摘要任务中提升了0.03–0.25的Rouge-L绝对分数。
2 背景
目前大多数LLM服务使用的是transformer架构 [13, 16, 52]。在接收到输入token后,LLM首先通过预填充阶段(prefill phase,稍后解释)将这些token转换为key(K)和value(V)向量,即KV缓存。完成预填充后,LLM再使用当前的KV缓存迭代式地解码(生成)下一个token,并将新生成token的K和V向量追加进KV缓存,以供下一轮生成使用。
预填充阶段按层计算KV缓存。每一层中,输入token的embedding会先被转换为query(Q)、key(K)和value(V)向量,其中K和V向量构成当前层的KV缓存。然后,LLM会将Q和K向量进行乘法运算,得到注意力矩阵,即每个token与其前序token之间的注意力关系;随后再对该注意力矩阵(经归一化和掩码处理)与V向量进行点积,得到的结果将通过多个神经网络层,最终用于生成下一层的token embedding。
当某段前缀的KV缓存已存在时,预填充阶段只需要在每一层计算后缀token与前缀token之间的前向注意力矩阵(forward attention),这些注意力会直接影响生成token的输出。
预填充阶段在输入很长时会变得很慢。例如,在包含4000个token的输入上(这在RAG场景中很常见 [33]),Llama-34B(或Llama-70B)在一张A40 GPU上运行预填充可能需要3秒(或6秒)。这将导致用户在看到第一个生成词之前不得不等待较长时间。近期的研究还显示,预填充阶段可能成为推理吞吐量的瓶颈——研究表明移除预填充阶段可以使LLM推理系统的吞吐量翻倍 [60]。
3 动机
3.1 复用KV缓存的机会
近期的系统尝试通过观察许多LLM使用场景中相同文本在不同输入中被反复使用的现象,以此缓解预填充阶段的开销。这使得我们可以复用这些重复文本的KV缓存(下面会具体解释)。
文本复用在许多LLM应用中十分常见,因为同样的文本通常被包含在LLM输入中,作为提供必要上下文的手段,以确保回答质量高且一致。为了更具体地说明,我们来看两个场景:
-
在一个利用LLM管理内部记录的公司中,有两个查询可能分别是:“谁在最近的全员大会上提议使用RAG来优化客户服务X?”以及“IT部门中有哪些人毕业于Y大学?”这两个问题看似不同,但都涉及“IT部门员工列表”这一上下文,只有提供这一信息,LLM才能给出正确答案。
-
同样地,在一个基于LLM的Arxiv论文摘要应用中,有两个问题可能是:“当前在Arxiv上流行的RAG技术有哪些?”以及“最近有哪些数据集被用于评估RAG相关论文?”这两个问题都需要LLM读入关于RAG的Arxiv论文作为上下文,才能生成准确答案。
由于被复用的上下文通常比用户的查询更长、更复杂,因此在输入中的“上下文”部分会占据预填充计算的绝大部分开销 [22, 33]。因此,理想的做法是存储并复用这些上下文的KV缓存,以避免在它们被再次用于不同LLM输入时重复进行预填充计算。
3.2 为什么前缀缓存不够用?
确实,已有一些系统被设计出来以通过复用KV缓存来减少预填充延迟。例如,在**前缀缓存(prefix caching)**中,可复用的文本片段的KV缓存会预先计算好;如果该片段出现在LLM输入的前缀位置,那么这段KV缓存就可以直接复用,省去该部分的预填充。前缀缓存的好处是,这段KV缓存不受后续文本的影响,因此其生成结果与完全不使用KV缓存、重新计算得到的结果是一致的。多个系统采用了这种方式,如vLLM [36]、SGLang [59] 和 RAGCache [33]。
然而,前缀缓存也有明显的局限性。在回答某个查询时,诸如RAG等应用往往会在LLM输入中前置多个文本片段,以提供回答问题所需的多重上下文。结果是,除了第一个片段外,其他片段都不是输入的前缀,它们的KV缓存便无法被复用。
我们回顾一下§3.1中的例子:要回答“谁在最近的全员大会上提议使用RAG来优化客户服务X?”,LLM需要来自多个信息源的上下文,包括IT部门员工的信息、客户服务X的相关内容、全员大会的会议纪要等。同样地,在Arxiv摘要应用中,要回答示例问题也需要LLM读取几篇RAG相关的Arxiv论文作为上下文。由于这些上下文涉及的主题不同,它们不太可能出现在同一个文本片段中,而是在回答具体查询时才被临时组合使用。
为了实证LLM输入中包含多个文本片段的需求,我们使用了两个流行的多跳问答数据集:Musique和2WikiMQA。这些数据集中包含了多个查询以及对应多个必要上下文文本。我们遵循RAG的常见做法,首先将上下文分割为长度为128 token的片段(这个长度很常见 [29]),使用Langchain中的文本切片机制 [5]。对每个查询,我们使用SentenceTransformers [49]对其进行embedding,然后基于查询embedding与每个chunk embedding的L2距离,从向量数据库中选取前k个最相关的chunk。图2展示了随着选择的文本片段数量增加,生成质量(以标准F1分数衡量)如何变化。可以看到,当检索到更多文本片段补充LLM输入时,质量显著提升,但当片段过多时,质量反而下降,这源于广为人知的“middle token被忽视(lost-in-the-middle)”问题 [40, 54]。
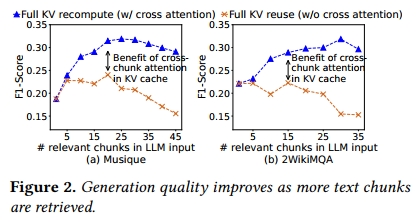
简而言之,前缀缓存只能节省第一个文本片段的预填充开销,因此当LLM输入包含多个文本片段时,即使这些片段被重复使用,节省的计算量也只是微不足道的。
3.3 为什么 full KV reuse 不足?
Full KV reuse 被提出是为了应对这个问题。该方法最近由 PromptCache [24] 首创。它通过缓冲区来维护每个文本块的位置准确性,从而将独立预计算的重复文本块的 KV 缓存进行拼接。例如,为了拼接文本块 𝐶₁ 和 𝐶₂ 的 KV 缓存,PromptCache 首先需要通过在一个假设输入上运行 prefill 来预计算 𝐶₂ 的 KV 缓存,该输入在 𝐶₂ 前添加了一个长度大于等于 𝐶₁ 的虚拟前缀。通过这种方式,即使 𝐶₂ 不是输入的 prefix,我们仍然可以正确保留 𝐶₂ 的 KV 缓存中的位置信息,尽管每个块的 KV 缓存可能不得不被多次预计算。
然而,即便位置信息被保留,一个更根本的问题是,非 prefix 的文本块(如 𝐶₂)在其 KV 缓存中会忽略该块与其前面文本块(如 𝐶₁)之间的重要 cross-attention。这是因为在预计算 KV 缓存时,前面的文本块是未知的。
忽略 cross-attention 会导致错误的响应。图3 展示了一个说明性示例,其中一个用户查询 “How many goals did Messi score more than Cristiano Ronaldo at FIFA World Cups?” 被两个关于球员职业统计数据的文本块所预置。使用 full prefill 或 prefix caching 时,结果是明确且正确的。而在使用 full KV reuse 的情况下,这两个文本块的 KV 缓存已被预计算,每个文本块具有正确的 positional embedding,然后被拼接形成最终 KV 缓存。然而,如果 LLM 使用这个 KV 缓存来生成答案,它将开始胡言乱语,且无法得出正确答案。
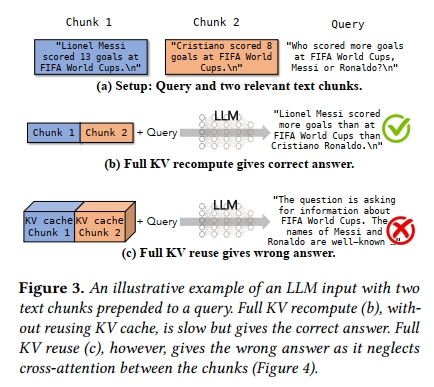
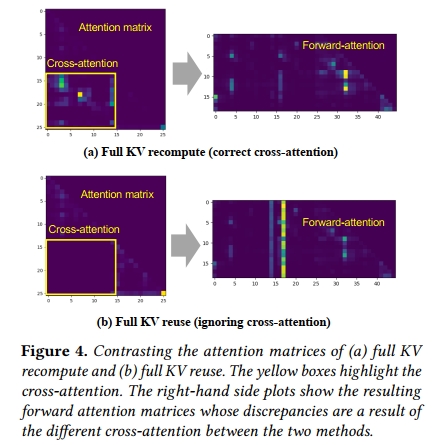
为了理解其中原因,我们进一步观察 attention matrix(在 §2 中解释),尤其是涉及两段关于球员数据的文本块之间的 cross-attention。图4 可视化了由原始(full)prefill 所产生的 attention matrix 以及由 full KV reuse 所产生的 attention matrix。由于 full KV reuse 是分别预计算每个文本块的,因此在预计算 KV 缓存时,这两个文本块之间的 cross-attention 完全被遗漏(从未被计算)。在本示例中,第一个文本块包含 Messi 的进球数,第二个文本块包含 Ronaldo 的。LLM 被查询以比较 Messi 和 Ronaldo 的进球数。如果忽略这两个文本块之间的交互(cross-attention),将会导致一个有缺陷的答案。
公平地说,在文本块之间的 cross-attention 较弱时,full KV reuse 确实可以发挥作用。这种情况通常出现在 prompt templates 中,而这正是 PromptCache [24] 的主要目标应用场景。
full KV reuse 中缺乏 cross-attention 会在 forward attention matrix(在 §2 中解释)中造成显著差异,该矩阵描述了上下文 tokens 与最后几个 tokens 之间的注意力关系,并会直接影响生成的 tokens。
为了展示在多文本块 LLM 输入中 cross-attention 的普遍性,图2 对比了 full KV recompute(包含 cross-attention)与 full KV reuse(不包含 cross-attention)在响应质量(F1 分数)上的表现。可以看到,随着相关文本块数量的增加,full prefill 与 modular caching 之间的差距愈发明显。这是因为随着文本块数量的增多,输入中不同部分之间的交叉引用和相互依赖关系(即 cross-attention)也随之增加。
4 快速 KV 缓存融合
鉴于 full KV recompute(即 full prefill 或 prefix caching)速度太慢,而 full KV reuse 生成质量较低,一个自然的问题是,如何既能拥有 full KV reuse 的速度,又能兼顾 full KV recompute 的质量。因此,我们的目标如下:
目标:当 LLM 输入包含多个被重复使用的文本块时,如何快速更新预先计算的 KV 缓存,使得生成的 forward attention matrix(以及随后生成的文本)与 full KV recompute 所产生的结果之间的差异最小。
为实现这一目标,我们提出 CacheBlend,它在每一层中仅对部分 token 的 KV 进行选择性地重新计算,同时复用其他 token 的 KV。本节将从三个方面介绍 CacheBlend 的方法。我们首先给出所用记号(§4.1),然后描述如何只重新计算一小部分 token 的 KV(§4.2),最后解释如何在每一层选择需要重新计算 KV 的 token(§4.3)。
4.1 术语说明
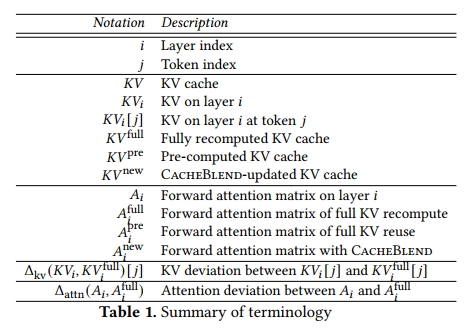
表1 总结了本节中使用的记号。对于一个包含 𝑁 个文本块的列表,我们使用 𝐾𝑉^full 表示 full KV recompute 所产生的 KV 缓存,𝐾𝑉^pre 表示预计算的 KV 缓存,𝐾𝑉new𝐾𝑉^{new}KVnew 表示经过 CacheBlend 更新后的 KV 缓存。在这里,这些 KV 缓存都是由不同文本块对应的 KV 缓存拼接而成的。每一层 𝑖 的 KV 缓存,记作 𝐾𝑉ᵢ,会生成该层的 forward attention matrix,记作 𝐴ᵢ。
温馨提示:
阅读全文请访问"AI深语解构" CacheBlend:结合缓存知识融合的快速RAG大语言模型推理服务