超越基于角色的手术领域建模:手术室中的可泛化再识别|文献速递-医学影像算法文献分享
Title
题目
Beyond role-based surgical domain modeling: Generalizable re-identificationin the operating room
超越基于角色的手术领域建模:手术室中的可泛化再识别
01
文献速递介绍
在动态且高风险的手术室(OR)中,细微的决策都可能对患者结局产生深远影响。手术数据科学(SDS)已成为医学研究中的一个开创性领域,它赋能手术团队提升协作效率、减少流程冗余,并最终提高患者护理标准(Maier Hein 等,2022)。SDS的主要目标之一是手术室工作流分析:研究临床医生在手术室内外的移动、角色和互动。这包括手术阶段与动作识别(Sharghi 等,2020;Czempiel 等,2022;Garrow 等,2021;Bastian 等,2023a)、人员匿名化(Flouty 等,2018;Bastian 等,2023c)、人体姿态识别(Belagiannis 等,2016;Srivastav 等,2018;Gerats 等,2023;Liu 等,2024)、物体与实例分割(Li 等,2020;Bastian 等,2023b)以及角色预测(Özsoy 等,2022)等任务。这些方法上的进展为智能系统奠定了基础,这些系统在特定任务中已能辅助甚至超越人类表现(Varghese 等,2024),从提供实时手术团队支持(Varghese 等,2024;Moulla 等,2020)到可穿戴护士辅助设备(Cramer 等,2024)、个性化反馈(Laca 等,2022)以及自动报告生成(Lin 等,2022;Xu 等,2021a)。 手术室中的每个角色都有独特职责,这些职责主要由外科医生统筹协调——外科医生除了执行手术操作外,还负责协调团队活动并在整个手术流程中保持情境感知。研究表明,这种协同工作会增加认知负荷;智能系统有望引导每个角色在手术室中实现协调互动,减轻影响错误率和表现的认知负担(Avrunin 等,2018;Unknown,2021)。 现有文献广泛关注外科医生的技能(Zia 和 Essa,2018;Levin 等,2019;Liu 等,2021),却较少关注手术团队成员之间的动态互动和协作过程。此外,当前基于学习的手术室分析与优化方法往往将手术人员视为其指定角色内可互换的组成部分。这种视角虽然对粗略的工作流分析有用,但未能考虑到外科医生、助手、护士和其他团队成员之间的细微差异。团队熟悉度不足和协作协调不佳与手术时间延长、并发症发生率升高以及成本增加相关(Mazzocco 等,2009;Al Zoubi 等,2023;Pasquer 等,2024)。相反,稳定且高度同步的团队在多个指标上表现更优,包括手术持续时间更短、发病率更低以及住院时间更短(Pasquer 等,2024)。因此,手术室中的智能系统应了解每个个体在手术协同工作中的角色,并对不同团队组合下工作流的变化保持细致理解。 ### 1.1 以人员为中心的方法 一个凸显“以人员为中心”方法必要性的具体例子是手术人员的技能水平差异。基于角色的建模在提供工作流指导或建议时,无法区分新手住院医师和经验丰富的主治医师。然而,个体之间的需求、行为以及对手术结局的影响可能存在显著差异,并且在团队动态中发挥重要作用(Parker 等,2020;Laca 等,2022;Petrosoniak 等,2018)。其他方面,例如多推车机器人系统等新设备带来的复杂性(Verma 和 Ranga,2021),也会导致团队互动以不可预见的方式发生变化,这进一步强调了超越基于角色建模的必要性。 尽管手术数据科学文献此前已涉及手术室人员跟踪(Belagiannis 等,2016;Hu 等,2022)和角色预测(Özsoy 等,2022),但长期跟踪和再识别仍未得到探索。当前方法无法在较长时间尺度(数天、数周甚至数年)上建立对应关系,而这对于理解团队动态和技能发展至关重要。与基于人体姿态的跟踪方法不同,再识别可以在无需人工干预或使用干扰性物理跟踪设备的情况下,实现跨多个手术的细粒度工作流分析。为应对这些挑战,我们提出通过人员再识别的视角对手术室人员进行建模。这种范式不仅支持纵向手术分析,还可作为提高人体姿态跟踪器对跟踪交换和漏检鲁棒性的手段——这是拥挤手术室环境中存在的问题(见 4.3 节)。迄今为止,尚无无标记方法能够建立手术室人员的长期关联。 ### 1.2 手术室中的挑战 手术室面临着与一般计算机视觉领域不同的独特挑战,需要专门建模。传统的基于RGB的再识别方法通常关注头部、肩部和脚部(Li 等,2023-06)。在手术室中,手术服、口罩和手术帽等标准化着装遮挡了这些关键识别特征,导致传统方法失效(见图1)。此外,深度神经网络表现出对纹理而非形状的偏向(Geirhos 等,2019),这带来了挑战,因为同一诊所内的着装具有同质性,而不同诊所间的着装差异显著(见图2)(Liu 等,2024)。我们假设,可以通过强调个体独特的形状和动作而非特定诊所或手术团队角色的纹理特征来克服这种偏向。 ### 1.3 手术室的可泛化再识别 基于这些观察,我们提出了一种通过分析生物特征(如身体形状和关节运动模式)来跟踪和识别手术室人员的新方法——即使着装相同,这些特征在个体间仍具有可区分性。我们的方法对每个个体的3D点云序列进行编码,这些序列是从手术室的全局4D表示中分割出来的。这种方法减少了对外观或基于角色互动的依赖,强调了区分个体的形状和运动线索。我们的方法在不同场景下的泛化能力显著提升,为手术环境中更具适应性和个性化的智能系统铺平了道路。 我们的主要贡献总结如下: - 引入以人员为中心的手术领域建模概念,强调个体特征和团队动态在手术环境中的重要性。这种方法能够在较长时间内关联人员,为团队动态分析提供便利。 - 全面分析了手术室人员建模中的挑战,突出了现有跟踪方法的局限性,并说明了传统基于纹理的再识别技术在手术室中表现不佳或存在偏向的原因。 - 提出了一种通过从3D点云序列中隐式提取形状和关节运动线索来建模手术室人员的新方法。该方法解决了手术室特有的挑战,并在不同手术室环境中表现出优异的泛化能力,能够区分个体而非仅仅是手术角色。 - 通过在特定手术室数据集和更通用的室外人员再识别场景上的交叉评估验证了我们的方法,证明了其在各种环境中的鲁棒性和通用性。 - 通过生成特定角色的“3D活动印记”展示了我们方法的实际应用,为手术室团队动态和个体运动模式提供了见解。这种可视化技术为基于数据的手术流程优化奠定了基础,有望提高效率、改进培训并改善患者护理。
Abatract
摘要
Surgical domain models seek to optimize the surgical workflow through the incorporation of each staffmember’s role. However, mounting evidence indicates that team familiarity and individuality impact surgicaloutcomes. We present a novel staff-centric modeling approach that characterizes individual team membersthrough their distinctive movement patterns and physical characteristics, enabling long-term tracking andanalysis of surgical personnel across multiple procedures. To address the challenge of inter-clinic variability,we develop a generalizable re-identification framework that encodes sequences of 3D point clouds to captureshape and articulated motion patterns unique to each individual. Our method achieves 86.19% accuracy onrealistic clinical data while maintaining 75.27% accuracy when transferring between different environments– a 12% improvement over existing methods. When used to augment markerless personnel tracking, ourapproach improves accuracy by over 50%, addressing failure modes including occlusions and personnel reentering the operating room. Through extensive validation across three datasets and the introduction of anovel workflow visualization technique, we demonstrate how our framework can reveal novel insights intosurgical team dynamics and space utilization patterns, advancing methods to analyze surgical workflows andteam coordination.
手术领域模型旨在通过整合每位工作人员的角色来优化手术流程。然而,越来越多的证据表明,团队熟悉度和个体特质会对手术结果产生影响。我们提出了一种新颖的以工作人员为中心的建模方法,该方法通过团队成员独特的运动模式和身体特征来对其进行刻画,从而能够在多个手术过程中对手术人员进行长期跟踪和分析。 为应对诊所间存在差异这一挑战,我们开发了一个可泛化的再识别框架,该框架对三维点云序列进行编码,以捕捉每个人独特的形态和关节运动模式。我们的方法在真实临床数据上的准确率达到86.19%,而在不同环境间迁移时仍能保持75.27%的准确率——相比现有方法提升了12%。当用于增强无标记人员跟踪时,我们的方法将准确率提高了50%以上,解决了包括遮挡和人员重新进入手术室等失效模式。 通过在三个数据集上的广泛验证以及引入一种新颖的工作流可视化技术,我们展示了该框架如何揭示有关手术团队动态和空间利用模式的新见解,推动了手术流程和团队协作的分析方法的发展。
Method
方法
3.1. Generalizable operating room re-identification
We proceed with our problem statement of how we model shortand long-term personnel tracking through contrastive metric learningin Section 3.1.1. Next, we explain our method, which encodes 3D pointcloud sequences of OR personnel by capturing the shape and articulatedmotion while mitigating biases caused by varying textures in the ORenvironment. Finally, motivated by the hypothesis that changes in theattire of OR personnel impact the generalizability of commonly studiedre-id methods, we outline our framework for re-identifying personnelfrom RGB- and point cloud-based modalities (Section 3.1.2), detailingour inference process study in Section 3.1.4.
3.1 可泛化的手术室人员再识别 我们在3.1.1节中通过对比度量学习,阐述了如何对人员的短期和长期跟踪进行建模的问题。接下来,我们将说明我们的方法——该方法通过捕捉手术室人员的3D点云序列的形状和关节运动特征,同时减轻手术室环境中不同纹理带来的偏差,对这些序列进行编码。最后,基于“手术室人员着装变化会影响常见再识别方法泛化能力”这一假设,我们概述了从基于RGB和点云的模态中实现人员再识别的框架(3.1.2节),并在3.1.4节中详细介绍了我们的推理过程研究。
Conclusion
结论
Our work addresses an existing gap in surgical domain modeling,namely that OR personnel are only modeled by their role while morenuanced individual characteristics are ignored. We propose a methodfor personnel re-identification in operating rooms (ORs) that is robustto different environments and large domain changes which addressesboth short- and long-term tracking and identification challenges. Ourmethodological design is motivated by insights into the challenges ofmodeling personnel movement and identities in ORs. Due to largedomain shifts between different clinics, RGB-based models tend tooverfit to distinct visual cues, leading to performance degradation.To address these shortcomings, we demonstrate the superior performance and generalizability of our proposed 3D point cloud sequencebased tracking model that effectively captures body shape and articulated motion patterns over potentially misleading visual appearance.Finally, we showcase the practical applications of our approach forworkflow analysis and optimization through 3D activity imprint generation to aid in the analysis of OR teams. By introducing a non-invasiveand robust method for identifying surgical personnel, our approachshifts the analysis of surgical procedures to a more individualizedlevel. This lays the foundation for more adaptive and tailored AIdriven systems in surgical settings, facilitating individualized feedback,optimizing team coordination, reducing inefficiencies, and ultimatelyenhancing patient safety and care.
我们的研究填补了手术领域建模中存在的一个空白,即手术室人员仅按其角色进行建模,而更细微的个体特征却被忽略。我们提出了一种适用于手术室人员再识别的方法,该方法对不同环境和较大领域变化具有鲁棒性,能够解决短期和长期跟踪与识别的挑战。 我们的方法设计源于对手术室人员运动和身份建模挑战的深刻理解。由于不同诊所之间存在较大的领域差异,基于RGB的模型往往会过度拟合特定的视觉线索,导致性能下降。为解决这些不足,我们证明了所提出的基于3D点云序列的跟踪模型具有更优异的性能和泛化能力——该模型能够有效捕捉身体形状和关节运动模式,而非易产生误导的视觉外观。 最后,我们通过生成3D活动印记展示了该方法在工作流分析和优化中的实际应用,为手术室团队分析提供支持。通过引入一种非侵入性且稳健的手术人员识别方法,我们的研究将手术流程分析提升到了更个性化的层面。这为手术环境中更具适应性和针对性的人工智能驱动系统奠定了基础,有助于实现个性化反馈、优化团队协作、减少低效环节,并最终提升患者安全与护理质量。
Figure
图
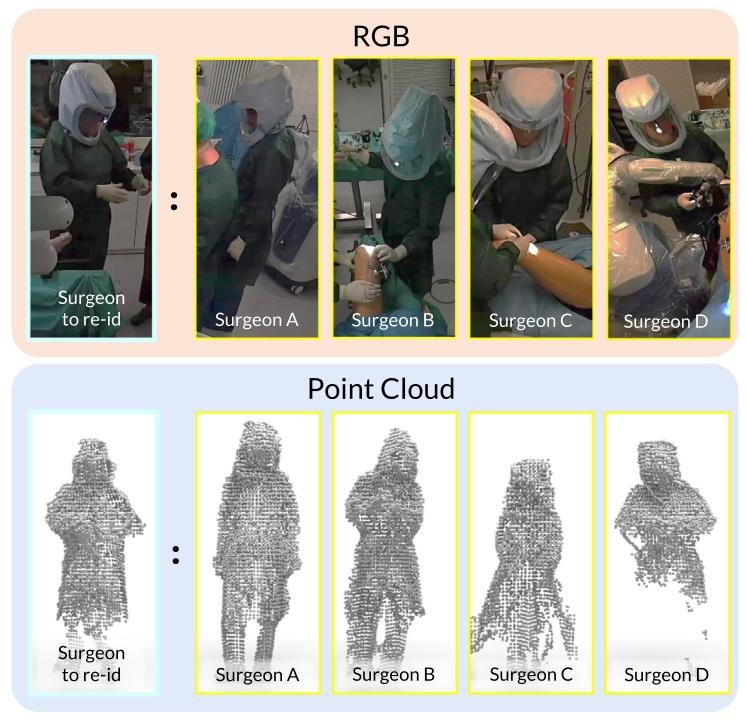
Fig. 1. Who is the surgeon to re-identify? A depiction of four surgeons (persons A, B,C, and D), which are challenging to visually differentiate. Existing re-identificationmethods relying on RGB (top) images often depend on facial features, attire,complexion, or physique. These distinctive features are obscured in ORs, providing anobstacle to such methods; we observe that encoding 3D point clouds (bottom) provesmore effective. By encapsulating characteristics such as an individual’s stature, bodyshape, proportions, and volume, methods can more easily differentiate individuals thantheir clinical role. For example, these four surgeons can be more easily distinguishedbased on their height differences, which is ambiguous in RGB images due to the lossof absolute scale. The surgeon to re-identify is Person D.
图1. 需要再识别的外科医生是谁? 图示为四位外科医生(人员A、B、C和D),从视觉上难以区分他们。现有的依赖RGB图像(上方)的再识别方法通常依靠面部特征、着装、肤色或体型。但在手术室中,这些独特特征被遮挡,给这类方法带来了障碍;我们发现对3D点云(下方)进行编码更为有效。通过捕捉个体的身高、体型、比例和体积等特征,相比依据临床角色,该方法能更轻松地区分不同个体。例如,这四位外科医生可通过身高差异更易区分,而由于绝对尺度的缺失,这种差异在RGB图像中并不明显。需要再识别的外科医生是人员D。

Fig. 2. RGB image excerpts and overlayed saliency maps generated with GradCAM (Selvaraju et al., 2017) on the simulated datasets 4D-OR (Özsoy et al., 2022) and OR_ReID_13.4D-OR’s limited realism and variety allow CNNs to identify individuals solely by their heads and shoes. In more realistic OR settings like OR_ReID_13, these features become lessuseful due to more homogeneous attire. These discrepancies between different clinical environments can impede generalization
图2. RGB图像节选以及在模拟数据集4D-OR(Özsoy等人,2022)和OR_ReID_13上通过GradCAM(Selvaraju等人,2017)生成的叠加显著性图。4D-OR的真实感和多样性有限,使得卷积神经网络(CNNs)仅通过头部和鞋子就能识别个体。而在像OR_ReID_13这样更真实的手术室环境中,由于着装更具同质性,这些特征的作用变得更小。不同临床环境之间的这些差异可能会阻碍模型的泛化能力。
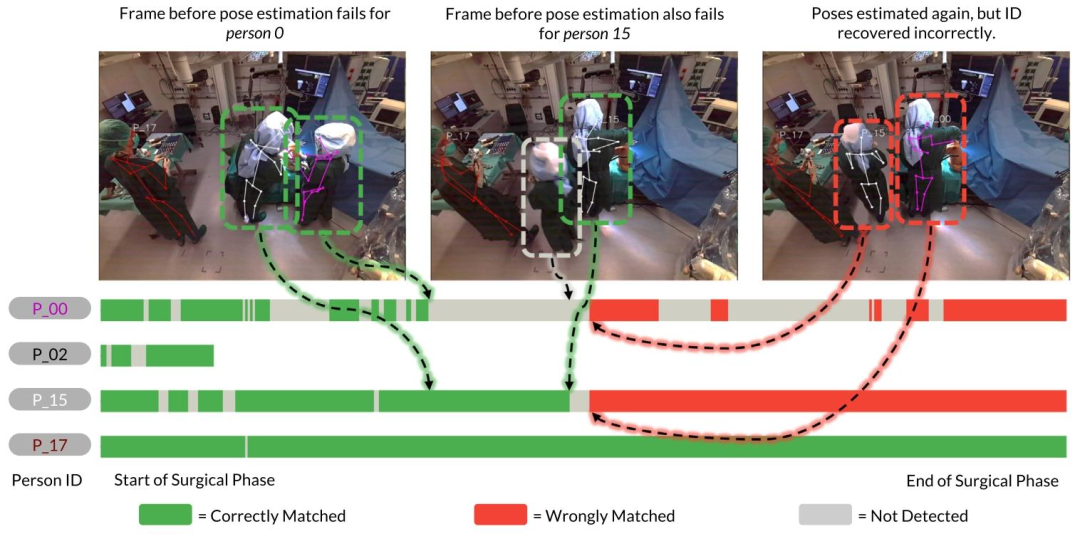
Fig. 3. Person tracking using a heuristic-based approach by associating 3D human key points over time. Each bar represents the timeline of an individual during the surgicalphase. Human pose estimation (Srivastav et al., 2024) fails for person 0 just as they move to the left (from the depicted camera angle) of person 15, and after some frames alsofor person 15. When the 3D human pose estimator resumes detection in the subsequent frames, a heuristic-based tracking method (Özsoy et al., 2022) incorrectly associates theposes of persons 0 and 15, due to a missed detection. After a wrong association, tracks can be irreversibly mismatched for the remainder of a surgery
图3. 基于启发式的人员跟踪方法:通过关联随时间变化的3D人体关键点实现。每个条形代表手术阶段中某一个体的时间线。当人员0(从所示相机角度看)移动到人员15左侧时,人体姿态估计(Srivastav等人,2024)对人员0的检测失效,随后几帧对人员15的检测也出现失效。当3D人体姿态估计器在后续帧中恢复检测时,由于存在漏检,基于启发式的跟踪方法(Özsoy等人,2022)错误地将人员0和人员15的姿态关联起来。一旦出现错误关联,在剩余的手术过程中,跟踪结果可能会出现不可逆的匹配错误。
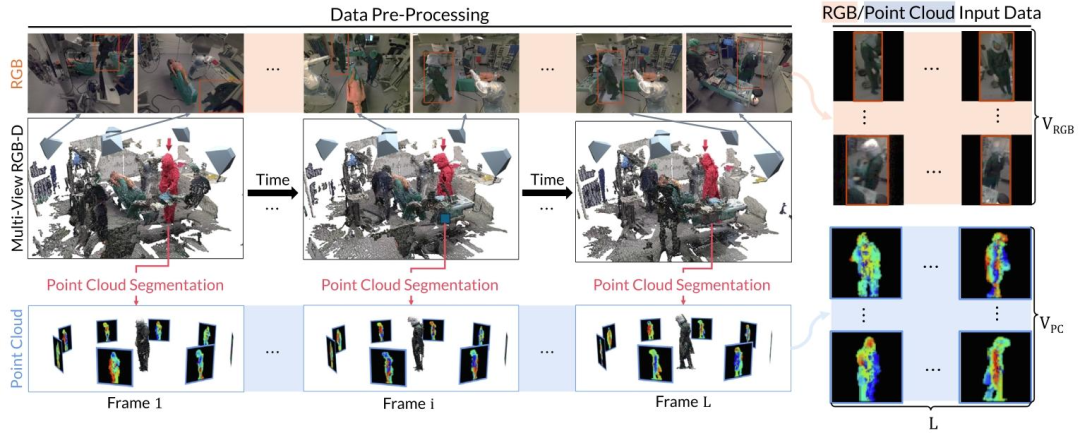
Fig. 4. An overview of the data pre-processing to acquire RGB and point cloud input frames. From the raw multi-view RGB-D recordings, we first segment each individual fromthe fused 3D point cloud sequence using weakly-supervised 3D point cloud segmentation (Bastian et al., 2023b). The resulting person point cloud is then used to render 2D depthmaps using virtual rendering and to acquire the person bounding boxes to extract the 2D bounding boxes from the RGB images. Note that this example depicts the process for asingle person. In practice, we repeat the same process for each person in the scene.
图4. 获取RGB和点云输入帧的数据预处理概述。从原始的多视角RGB-D记录中,我们首先使用弱监督3D点云分割(Bastian等人,2023b)从融合的3D点云序列中分割出每个个体。然后,得到的人体点云通过虚拟渲染生成2D深度图,并用于获取人体边界框,以便从RGB图像中提取2D边界框。请注意,此示例展示的是单个个体的处理过程。在实际操作中,我们会对场景中的每个个体重复相同的处理步骤。
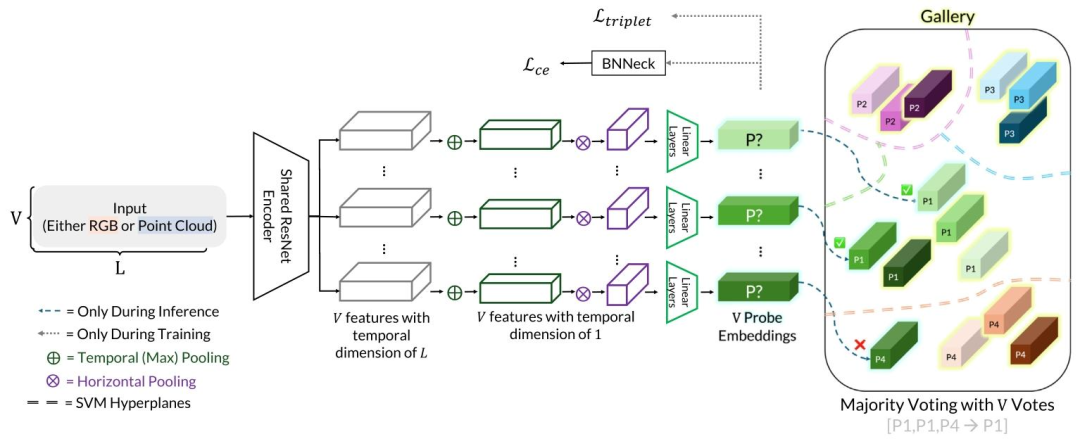
Fig. 5. Our model can take a sequence of multi-view 2D images as input. These sequences can be RGB images or rendered point cloud images. Each image is individually encodedusing a shared lightweight ResNet-9 encoder. Subsequently, each view is processed independently and trained with a combination of contrastive loss and cross-entropy loss. Duringinference, we use the gallery features to train an SVM, which separates the latent space into hyperplanes. Each probe embedding is then assigned to a cluster, and we applymajority voting across the views to obtain our final prediction
图5. 我们的模型可接收多视角2D图像序列作为输入,这些序列可以是RGB图像或渲染的点云图像。每张图像通过共享的轻量级ResNet-9编码器进行单独编码。随后,每个视角被独立处理,并结合对比损失和交叉熵损失进行训练。在推理阶段,我们利用图库特征训练支持向量机(SVM),将潜在空间划分为超平面。之后,每个探针嵌入被分配到一个聚类中,我们通过对各视角的结果进行多数投票,得到最终预测结果。
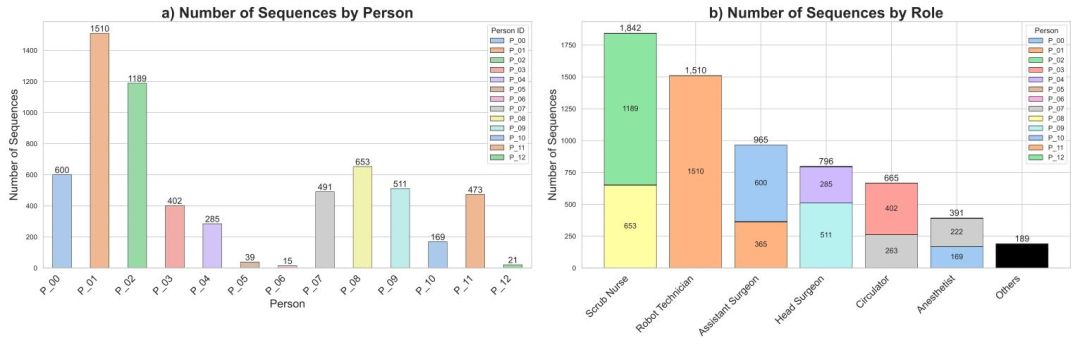
Fig. 6. A statistical overview depicting the distribution of roles and persons in OR_ReID_13. (a) shows the distribution of sequences per person. (b) shows the distribution ofsequences and individuals per role. ‘‘Others’’ denotes individuals in recordings that do not correspond to any of the six roles
图6. 展示OR_ReID_13数据集中角色和人员分布的统计概览。(a)显示每个人员的序列分布。(b)显示每个角色的序列和个体分布。“Others(其他)”表示记录中不属于六个角色中任何一个的人员。
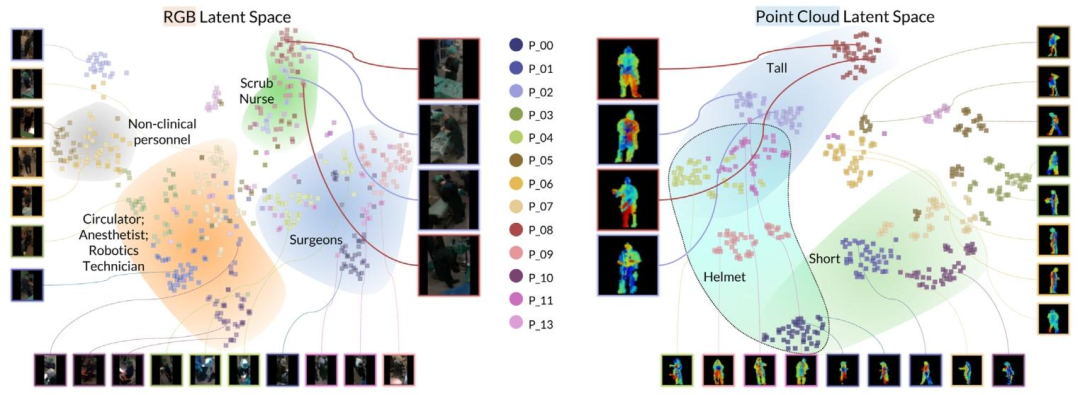
Fig. 7. Visualization of the RGB and point cloud latent spaces on OR_ReID_13, visualized by a t-SNE projection. Regions are manually highlighted based on the commonattributes within clusters in the latent spaces.
图7. OR_ReID_13数据集上RGB和点云潜在空间的可视化(通过t-SNE投影实现)。根据潜在空间中聚类内的共同属性,对各区域进行了手动标记。

Fig. 8. 3D OR activity imprints generated via automated personnel tracking during the intra-operative phase. Each role is represented by a maximum of two individuals, distinguishedby borders of different colors ( green and pink ). The patient table is highlighted in blue , the tool table in green , and the robot maintenance station in gold . The data isgenerated from OR_ReID_13.
图8. 术中阶段通过自动化人员跟踪生成的3D手术室活动印记。每个角色最多由两名人员代表,通过不同颜色的边框(绿色和粉色)加以区分。患者手术台以蓝色突出显示,器械台以绿色突出显示,机器人维护站以金色突出显示。数据来源于OR_ReID_13数据集。
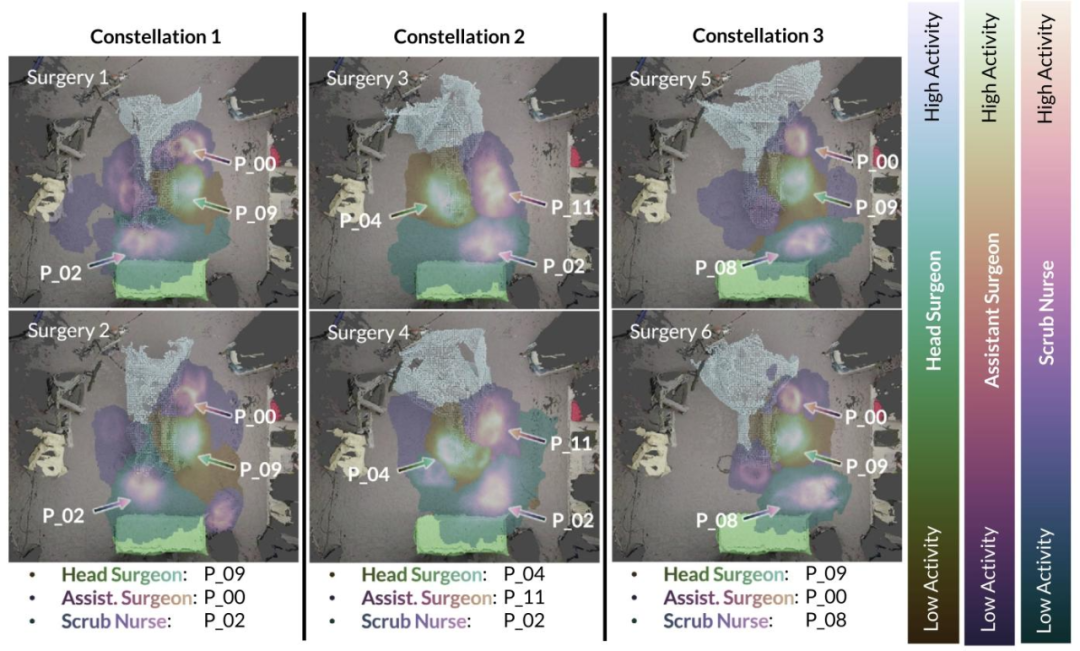
Fig. 9. Different personnel constellations and their respective 3D activity imprints. Our proposed re-ID-based tracking approach yields insight into the coordination of surgicalteams, providing insight into group workflow patterns and usage of the OR for a given surgery. The patient table is visualized in blue ; the tool-table in green ; the robotmaintenance station in gold . The data is generated fromOR_ReID_13.
图9. 不同的人员组合及其相应的3D活动印记。我们提出的基于再识别(re-ID)的跟踪方法,能够深入了解手术团队的协作情况,为特定手术的团队工作流模式和手术室使用情况提供见解。患者手术台以蓝色显示;器械台以绿色显示;机器人维护站以金色显示。数据来源于OR_ReID_13数据集。
Table
表

Table 1Overview of datasets used in the study. IDs denotes the number of unique identitiespresent, and the number of annotated Sequences in each dataset.
表1 本研究中使用的数据集概述。IDs表示存在的唯一身份数量,以及每个数据集中带注释的序列数量。
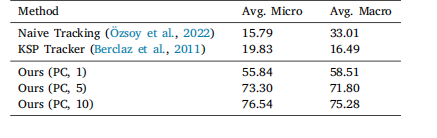
Table 2Rank-1 micro and macro accuracy (in percentage) when tracking individuals over an entire surgery of OR_ReID_13 based on associating 3Dhuman poses between frames (Naive Tracking, KSP Tracker) comparedto re-identification based tracking [Ours (PC, 𝑛)], where 𝑛 denotes thenumber of sequences per person in the gallery.
表2 在OR_ReID_13数据集中,基于帧间3D人体姿态关联的跟踪方法(朴素跟踪、KSP跟踪器)与基于再识别的跟踪方法[我们的方法(点云,𝑛)]在整个手术过程中跟踪个体时的Rank-1微精度和宏精度(百分比)。其中,𝑛表示图库中每个人员的序列数量。
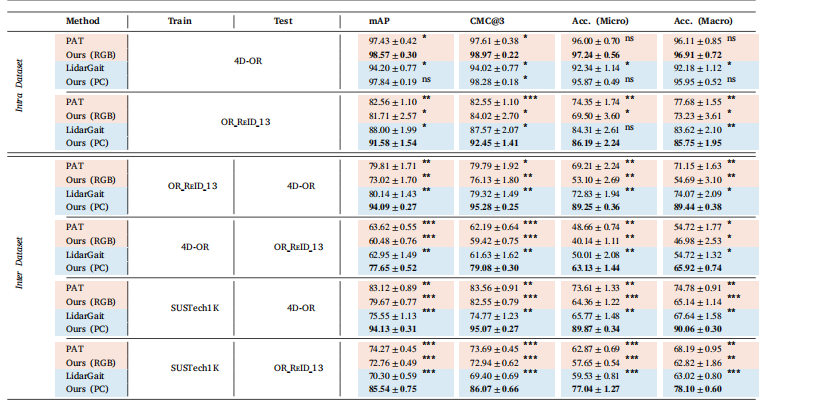
Table 3Comparison of inter- and intra-dataset performance between LidarGait (Shen et al., 2023), PAT (Ni et al., 2023a), and our method.Methods are color-coded based on the input modality: RGB for RGB input and point cloud (PC) for point cloud input. We evaluateperformance across three datasets: the two OR datasets, OR_ReID_13 and 4D-OR (Özsoy et al., 2022), and the general computer visiondataset, SUSTech1K (Shen et al., 2023). The metrics include mean average precision (mAP), rank-3 cumulative matching characteristics(CMC@3), rank-1 micro accuracy [Acc. (Micro)], and rank-1 macro accuracy [Acc. (Macro)]. Each metric reports the average and standarderror across the four-fold cross-validation in percentage. The best value for each metric is highlighted in bold. Statistical significancedetermined by repeated-measures ANOVA followed by paired t-tests with Bonferroni correction (‘‘*‘‘: 𝑝 < 0.001, ‘‘’’: 𝑝 < 0.01, ‘‘":𝑝 < 0.05, ‘‘ns’’: not significant).
表3 LidarGait(Shen等人,2023)、PAT(Ni等人,2023a)与我们的方法在数据集内部和数据集之间的性能比较。方法根据输入模态进行颜色编码:RGB表示RGB输入,点云(PC)表示点云输入。我们在三个数据集上评估性能:两个手术室数据集OR_ReID_13和4D-OR(Özsoy等人,2022),以及通用计算机视觉数据集SUSTech1K(Shen等人,2023)。评估指标包括平均精度均值(mAP)、Rank-3累积匹配特征(CMC@3)、Rank-1微精度[Acc.(Micro)]和Rank-1宏精度[Acc.(Macro)]。每个指标均以百分比形式报告四次交叉验证的平均值和标准误差。每个指标的最佳值以粗体突出显示。统计显著性通过重复测量方差分析(ANOVA)确定,随后进行配对t检验并采用Bonferroni校正(“”:p* < 0.001,“”:p < 0.01,“”:p* < 0.05,“ns”:不显著)。

Table 4Role prediction on 4D-OR (Özsoy et al., 2022). We compare our re-identification approach against scene graph-based role prediction(Özsoy et al., 2022). Numbers are reported in percentage of accuracy. ‘‘-’’ indicates the role is not present in that phase.
表4 在4D-OR数据集(Özsoy等人,2022)上的角色预测结果。我们将自己的再识别方法与基于场景图的角色预测方法(Özsoy等人,2022)进行了比较。数值以准确率百分比表示。“-”表示该角色在相应阶段中不存在。
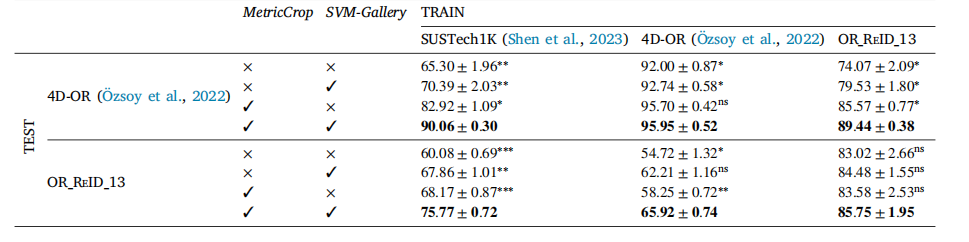
Table 5Inter- and intra-dataset performance (in percentage macro accuracy) of our proposed method in addition to two ablations, MetricCrop, and using anSVM-Gallery. Columns indicate the training dataset and rows the ablation configuration for a given test dataset. We use the same 4-fold cross-validationsplits as in previous experiments. Mean, standard error (using ± to separate values), and statistical significance with respect to the best performingmethod are reported for each other method (‘‘**‘‘: 𝑝 < 0.001, ‘‘**’’: 𝑝 < 0.01, ‘‘*": 𝑝 < 0.05, ‘‘ns’’: not significant)
表5 我们提出的方法以及两种消融实验(MetricCrop和使用SVM-Gallery)的数据集内和数据集间性能(以宏精度百分比表示)。列表示训练数据集,行表示特定测试数据集的消融配置。我们使用与先前实验相同的4折交叉验证划分。表格中报告了每种方法的平均值、标准误差(用±分隔数值)以及相对于性能最佳方法的统计显著性(“**”:p < 0.001,“*”:p* < 0.01,“”:p* < 0.05,“ns”:不显著)。