JAVA中的Map集合
文章目录
- 前言
- 一、Map集合常用方法
- 二、方法详细介绍
- 1. put(K key, V value)
- 2.size()
- 3. clear()
- 4. isEmpty()
- 5. get(Object key)
- 6. remove(Object key)
- 7. containsKey(Object key)
- 8. containsValue(Object value)
- 9. keySet()
- 10. values()
- (拓展)11. putAll(Map<? extends K, ? extends V> m)
- 三、实现类解释
- 1 .HashMap
- 2 LinkedHashMap
- 3. TreeMap
- 总结
前言
Map 是 Java 中一种非常重要的集合类型,用于存储键值对(key-value pairs)。它的常见实现类包括 HashMap、TreeMap、LinkedHashMap 等,主要区别在于它们对键值对的存储和顺序管理方式。
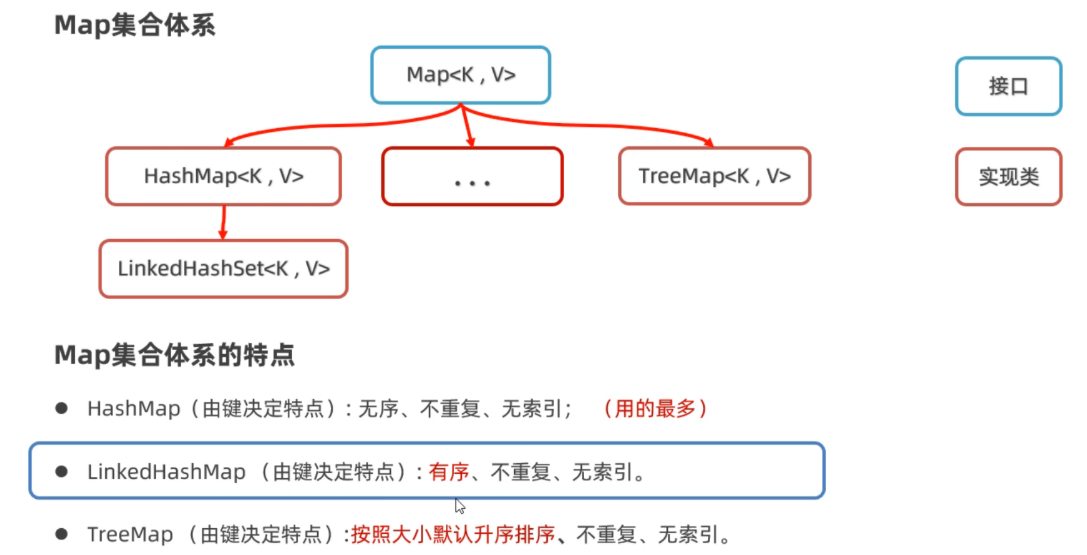
一、Map集合常用方法
由于Map是所有双列集合的父接口,所以我们只需要学习Map接口中每一个方法是什么含义,那么所有的Map集合方法你就都会用了。
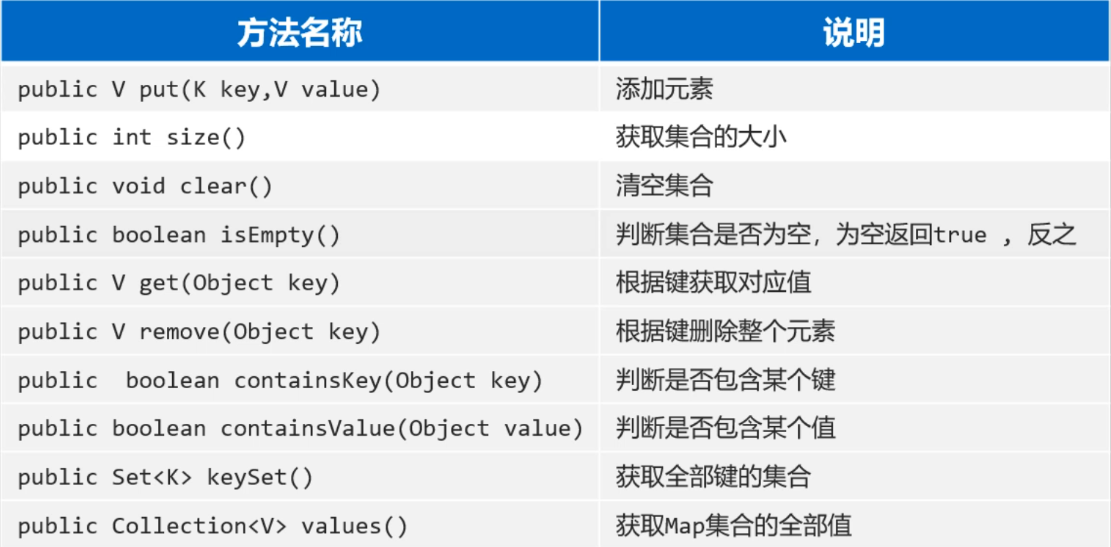
二、方法详细介绍
1. put(K key, V value)
添加一个键值对到 Map 中,键已存在则更新对应的值。
Map<String, Integer> map = new HashMap<>();
map.put("手表", 100);
map.put("手表", 220); // 更新"手表"的值
map.put("手机", 2);
System.out.println(map); // 输出: {手表=220, 手机=2}2.size()
获取集合的大小
System.out.println(map.size()); // 输出: 23. clear()
清空集合
map.clear(); // 清空集合
System.out.println(map); // 输出: {}4. isEmpty()
判断集合是否为空
System.out.println(map.isEmpty()); // 输出: true5. get(Object key)
根据键获取对应的值
int v1 = map.get("手表"); // 获取"手表"的值
System.out.println(v1); // 输出: 220
System.out.println(map.get("手机")); // 输出: 2
System.out.println(map.get("张三")); // 输出: null6. remove(Object key)
根据键删除键值对,并返回该键的值
System.out.println(map.remove("手表")); // 输出: 220
System.out.println(map); // 输出: {手机=2}7. containsKey(Object key)
判断Map是否包含某个键
System.out.println(map.containsKey("手表")); // 输出: false
System.out.println(map.containsKey("手机")); // 输出: true
System.out.println(map.containsKey("java")); // 输出: false
System.out.println(map.containsKey("Java")); // 输出: false8. containsValue(Object value)
判断Map是否包含某个值
System.out.println(map.containsValue(2)); // 输出: true
System.out.println(map.containsValue("2")); // 输出: false9. keySet()
获取Map中所有键的集合
Set<String> keys = map.keySet();
System.out.println(keys); // 输出: [手机]10. values()
获取Map中所有值的集合
Collection<Integer> values = map.values();
System.out.println(values); // 输出: [2](拓展)11. putAll(Map<? extends K, ? extends V> m)
将另一个Map的所有元素添加到当前Map
Map<String, Integer> map1 = new HashMap<>();
map1.put("java1", 10);
map1.put("java2", 20);Map<String, Integer> map2 = new HashMap<>();
map2.put("java3", 10);
map2.put("java2", 222);map1.putAll(map2); // 把map2的元素添加到map1中
System.out.println(map1); // 输出: {java1=10, java2=222, java3=10}
System.out.println(map2); // 输出: {java3=10, java2=222}三、实现类解释
1 .HashMap
HashMap底层数据结构: 哈希表结构
JDK8之前的哈希表 = 数组+链表
JDK8之后的哈希表 = 数组+链表+红黑树
哈希表是一种增删改查数据,性能相对都较好的数据结构
往HashMap集合中键值对数据时,底层步骤如下
第1步:当你第一次往HashMap集合中存储键值对时,底层会创建一个长度为16的数组
第2步:把键然后将键和值封装成一个对象,叫做Entry对象
第3步:再根据Entry对象的键计算hashCode值(和值无关)
第4步:利用hashCode值和数组的长度做一个类似求余数的算法,会得到一个索引位置
第5步:判断这个索引的位置是否为null,如果为null,就直接将这个Entry对象存储到这个索引位置
如果不为null,则还需要进行第6步的判断
第6步:继续调用equals方法判断两个对象键是否相同
如果equals返回false,则以链表的形式往下挂
如果equals方法true,则认为键重复,此时新的键值对会替换就的键值对。
HashMap底层需要注意这几点:
1.底层数组默认长度为16,如果数组中有超过12个位置已经存储了元素,则会对数组进行扩容2倍
数组扩容的加载因子是0.75,意思是:16*0.75=12
2.数组的同一个索引位置有多个元素、并且在8个元素以内(包括8),则以链表的形式存储
JDK7版本:链表采用头插法(新元素往链表的头部添加)
JDK8版本:链表采用尾插法(新元素我那个链表的尾部添加)
3.数组的同一个索引位置有多个元素、并且超过了8个,则以红黑树形式存储
2 LinkedHashMap
LinkedHashMap的底层原理,和LinkedHashSet底层原理是一样的。底层多个一个双向链表来维护键的存储顺序。
public class Test2LinkedHashMap {public static void main(String[] args) {// Map<String, Integer> map = new HashMap<>(); // 按照键 无序,不重复,无索引。LinkedHashMap<String, Integer> map = new LinkedHashMap<>(); // 按照键 有序,不重复,无索引。map.put("手表", 100);map.put("手表", 220);map.put("手机", 2);map.put("Java", 2);map.put(null, null);System.out.println(map);}
}

3. TreeMap
-
TreeMap集合的特点也是由键决定的,默认按照键的升序排列,键不重复,也是无索引的
-
TreeMap集合的底层原理和TreeSet也是一样的,底层都是红黑树实现的。所以可以对键进行排序。
排序方式1:写一个Student类,让Student类实现Comparable接口
//第一步:先让Student类,实现Comparable接口
public class Student implements Comparable<Student>{private String name;private int age;private double height;//无参数构造方法public Student(){}//全参数构造方法public Student(String name, int age, double height){this.name=name;this.age=age;this.height=height;}//...get、set、toString()方法自己补上..//按照年龄进行比较,只需要在方法中让this.age和o.age相减就可以。/*原理:在往TreeSet集合中添加元素时,add方法底层会调用compareTo方法,根据该方法的结果是正数、负数、还是零,决定元素放在后面、前面还是不存。*/@Overridepublic int compareTo(Student o) {//this:表示将要添加进去的Student对象//o: 表示集合中已有的Student对象return this.age-o.age;}
}
排序方式2:在创建TreeMap集合时,直接传递Comparator比较器对象。
/*** 目标:掌握TreeMap集合的使用。*/
public class Test3TreeMap {public static void main(String[] args) {Map<Student, String> map = new TreeMap<>(new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return Double.compare(o1.getHeight(), o2.getHeight());}});
// Map<Student, String> map = new TreeMap<>(( o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()));map.put(new Student("蜘蛛精", 25, 168.5), "盘丝洞");map.put(new Student("蜘蛛精", 25, 168.5), "水帘洞");map.put(new Student("至尊宝", 23, 163.5), "水帘洞");map.put(new Student("牛魔王", 28, 183.5), "牛头山");System.out.println(map);}
}
这种方式都可以对TreeMap集合中的键排序。注意:只有TreeMap的键才能排序,HashMap键不能排序。
总结
Map提供了丰富的功能来管理键值对。常见操作包括添加、查找、删除、检查、遍历等。不同的实现类(如HashMap、TreeMap、LinkedHashMap)在特性上有所不同,选择合适的实现类有助于提升程序的性能和可维护性。