【程序地址空间】虚拟地址与页表转化
前言
在我们学习内存空间划分的时候,我们知道内存空间会被划分为堆区、栈区、初始化区、代码区等,我们此时思考一下,这个空间是真实存在的吗?如果是真实存在的,那么为什么要这么划分地址空间呢?如果不是真实存在的,那么为什么要用虚拟内存空间呢?根据上面的问题,我将带着大家来了解本篇博客所要介绍的内容——程序地址空间。如果本篇博客对您有所帮助的话,希望留下点赞、关注加收藏,您的支持就是我创作的最大动力
程序地址空间
我们都知道,我们的内存空间是被划分了许多不同的区域的,每个区域保存了相应的数据,如果我们不对内存空间进行划分,就会导致数据在读写的时候发生混乱,不方便我们进行读取数据,那么C语言的内存空间是如何划分的呢?我们先来看一下C语言的内存空间布局
内存空间布局
我们在学习C语言的时候,都学习过内存空间的划分,我们会看到这样一张内存空间划分的图片:
我们可以看到内存空间从低到高分别分为:代码区、初始化数据区、未初始化数据区、堆区、栈区等空间
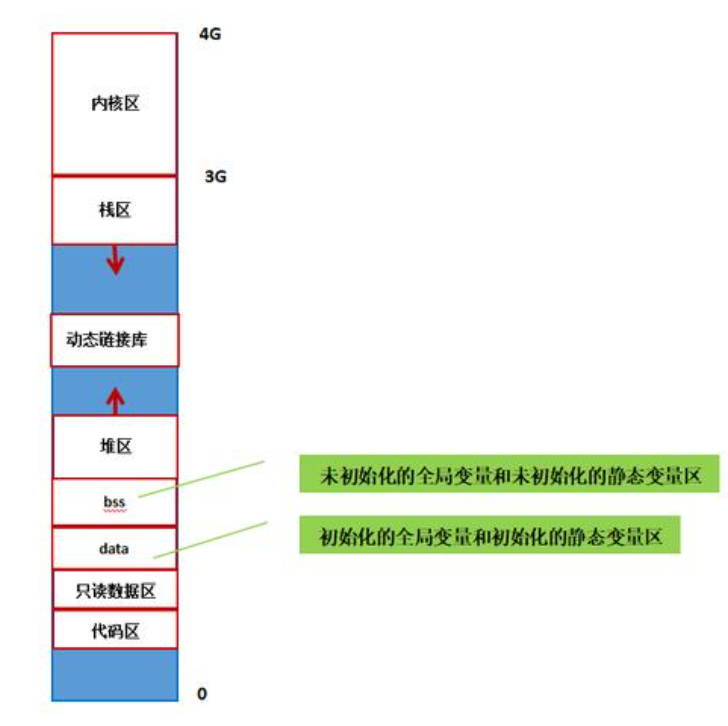
但是实际上我们对这个空间布局图并不是很理解,我们结合下面的代码:
1 #include<stdio.h>2 #include<unistd.h>3 #include<stdlib.h>4 5 int g_unval;6 int g_val=100;7 8 int main(int argc,char*argv[],char*env[])9 {10 const char*str="hello world";11 printf("code addr:%p\n",main);12 printf("init global addr:%p\n",&g_val);13 printf("uninit global addr:%p\n",&g_unval);14 15 static int test=10;16 char*heap_mem=(char*)malloc(10);17 char*heap_mem1=(char*)malloc(10);18 char*heap_mem2=(char*)malloc(10);19 char*heap_mem3=(char*)malloc(10);20 printf("heap addr:%p\n",heap_mem);21 printf("heap addr:%p\n",heap_mem1);22 printf("heap addr:%p\n",heap_mem2);23 printf("heap addr:%p\n",heap_mem3);24 25 26 printf("test static addr:%p\n",&test);27 printf("stack addr:%p\n",&heap_mem);28 printf("stack addr:%p\n",&heap_mem1);29 printf("stack addr:%p\n",&heap_mem2);30 printf("stack addr:%p\n",&heap_mem3);31 32 printf("read only string addr:%p\n",str);33 for(int i=0;i<argc;i++)34 {35 printf("argv[%d]:%p\n",i,argv[i]); 36 }37 for(int i=0;env[i];i++)38 {39 printf("env[%d]:%p\n",i,env[i]);40 }41 return 0;43 } 运行结果如下所示:
从上面的代码运行结果的地址来看,各个代码块的内存空间存在明显的分层现象,这个空间划分不会因为变量定义的顺序不同而发生改变。
我们在这些地址空间当中发现,堆区空间是从小到大增长,栈区空间是从大到小变化
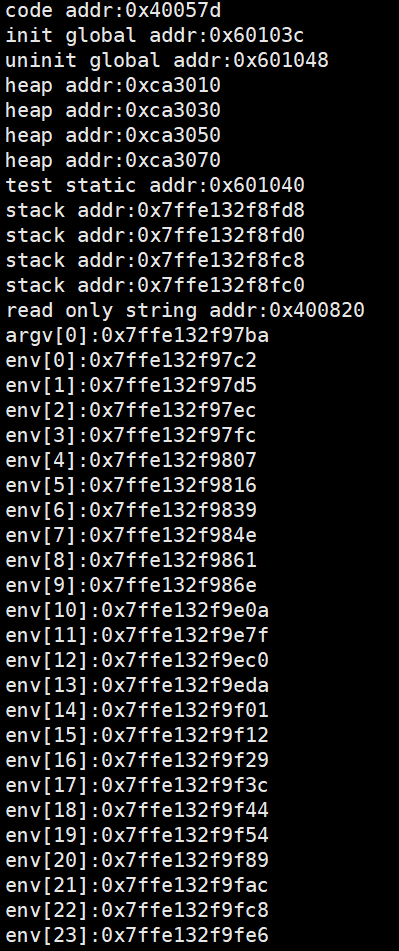
那么此时我想问大家一个问题,这里的地址空间是真实存在的地址空间吗?即:我们通过这个地址空间可以在内存中直接找到当前定义的变量吗?
虚拟地址
我们带着上面的疑问,来看下面这段代码:
1 #include<stdio.h>2 #include<unistd.h>3 4 int g_val=100;5 6 int main()7 {8 pid_t id=fork();9 if(id==0)10 {11 //子进程12 printf("子进程pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);13 }14 else{15 printf("父进程pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val); 16 }17 return 0;18 }运行结果如下所示:

我们可以看到,父子进程对g_val取地址得到的地址是相同的,我们应该怎么理解这个现象呢?
首先,对于父进程来说,这块空间是由父进程开辟的,而子进程在创建的时候,默认是对父进程代码和数据的一个拷贝,因此子进程和父进程指向的地址空间是同一块地址空间。
但是,如果我们对子进程的变量的值进行修改呢?按照我们之前所学,当我们对子进程的变量进行修改时,子进程会重新开辟一块空间,然后将变量的值做修改,因此父子进程指向的空间是不相同的,那么真实的情况与我们分析的是一样的吗?我们将上述代码进行修改:
1 #include<stdio.h>2 #include<unistd.h>3 4 int g_val=100;5 6 int main()7 {8 pid_t id=fork();9 if(id==0)10 {11 //子进程12 g_val=0; 13 printf("子进程pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);14 }15 else{16 printf("父进程pid:%d,ppid:%d,g_val:%d,&g_val:%p\n",getpid(),getppid(),g_val,&g_val);17 }18 return 0;19 }结果如下所示:
我们可以看到,即使我们对变量进行了修改,但是它们两个的地址还是指向同一块地址空间,那么是我们之前所学的知识出现了问题吗?下面我们仔细分析。

如果说我们在没对代码进行修改时,父子进程的变量地址指向同一个值的原因是:子进程对父进程的代码和数据进行拷贝,从而使它们两个变量的值指向同一片空间;后面我们将变量的值进行修改之后,它们两个变量的值为什么还会指向同一块空间呢?
显然,通过分析,我们可以推测,它们所对应的地址空间一定不是真实的地址空间,因为如果是真实的地址空间,那么一个地址只能严格对应一个变量,那么这个地址是什么呢?我们称之为:虚拟地址,由此我们可以推测,我们在代码当中所申请的空间、变量都是虚拟地址,并不是物理地址
什么是虚拟地址
既然我们所申请的空间都是虚拟地址,那么为了将我们所定义的变量写入内存必然存在虚拟地址到物理地址之间的转换,我们将虚拟地址到物理地址的转换过程称之为页表映射。
那么页表映射是一个什么样的过程呢?我们通过一张图来简单理解:
通过这张图我们可以看到,虚拟地址空间实际上是PCB结构体当中定义的一个结构体指针,通过这个结构体指针,指向虚拟空间这个结构体,我们在C语言上面申请的内存空间实际上是在这个虚拟空间上面开辟,然后通过页表映射到物理内存,最后加载到磁盘当中
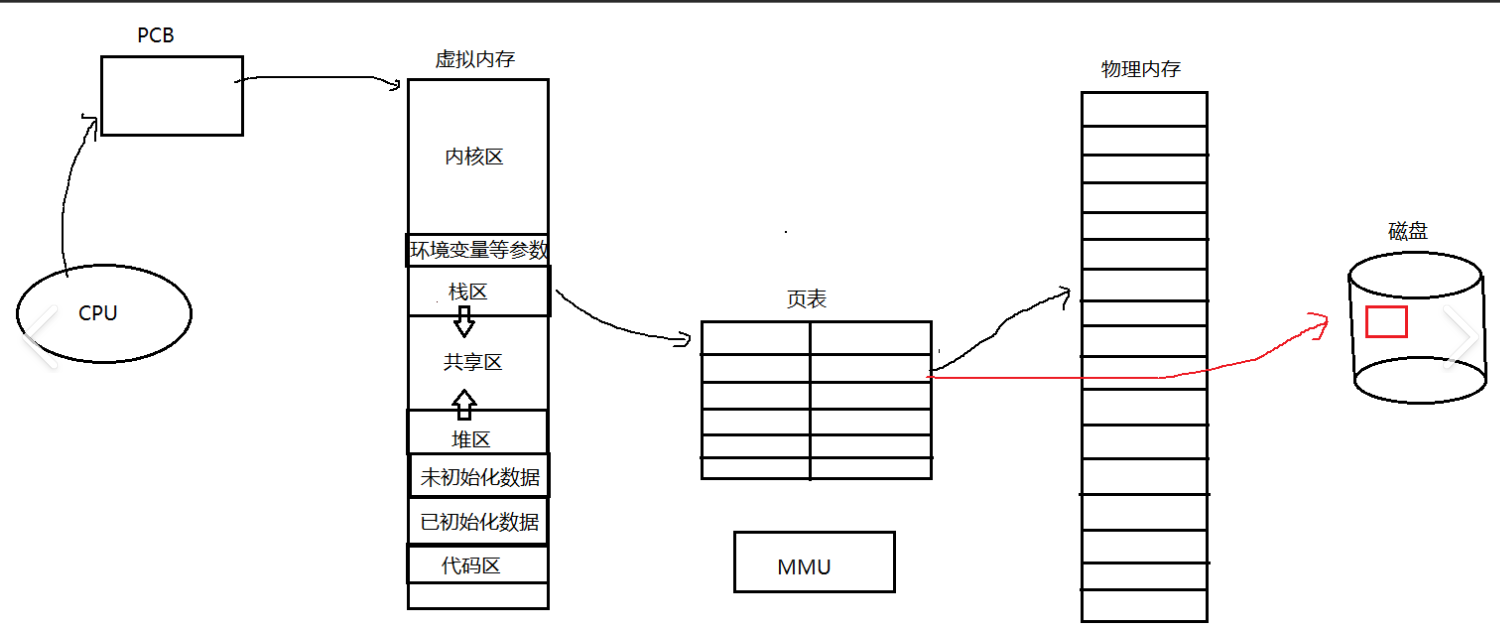
但是上图只是针对一个进程而言,如果是多进程,并且还是父子进程呢?那么此时页表映射是一个什么样的过程呢?
我们知道,进程之间是存在独立性的,即使是父子进程,由于子进程是对父进程代码和数据的一种继承关系,所以当子进程不对继承的数据进行修改时,它们默认通过页表映射指向的是同一块物理空间,但是一旦用户对子进程继承的代码和数据进行修改,为了保证进程之间的独立性,页表就会更改从虚拟地址到物理地址之间的映射关系,我们将这一过程成为写时拷贝。
换句话说就是,当我们对子进程代码和数据进行修改时,操作系统会更改页表的映射关系,使虚拟地址映射到一片新的物理地址中去。
那么写时拷贝是一个怎样的过程呢?
第一步:开辟空间,我们需要在物理内存当中开辟一片新的空间
第二步:拷贝内容,将旧空间当中的内容拷贝放入新开辟的一片空间当中
第三步:更改映射关系,更改从虚拟地址到物理地址的映射关系
此时我们就可以回答前面的问题,为什么父子进程中的变量所指向的空间是相同的呢?
因为写时拷贝这个操作完全由操作系统来完成,这个过程对用户是透明的
当我们对虚拟地址空间有了一个大致的了解之后,我们应该如何理解虚拟地址空间呢?
如何理解虚拟地址空间
对于一个操作系统而言,在任何时刻,操作系统当中都同时存在多个进程,各个进程之间彼此独立,而每个进程都是需要访问内存空间的,假设我们不通过虚拟地址到物理地址的转化,直接让进程在物理地址上面进行操作我们来看一下会发生什么问题。
首先,如果我们运行进程直接对物理地址进行操作,由于进程之间彼此独立,它们并不知道当前物理地址是否被使用,如果当前进程A对内存做写入操作,它写入的内存空间已经被进程B占用,如果A成功写入那么B的数据就会发生丢失,那么就会导致数据丢失的情况发生,那么如果我们此时在进程到物理内存之间增加一层虚拟地址,每当我们想要对物理地址进行读写操作时,我们都需要先写入虚拟地址,然后操作系统通过页表映射的方式将虚拟地址映射到一片固定的物理地址处,后续我们如果想要找到这块空间只需要通过页表就可以找到当前变量所在的空间
通过上面的分析我们发现,页表映射的整个过程都有操作系统帮助我们完成,那么操作系统是如何完成这样的过程的呢?一句话:先描述再组织
我们可以猜测,操作系统当中一定存在虚拟地址空间这样一个数据结构,这个数据结构里面被划分出来了很多很多的内存空间,指向该段空间的开始和结束位置,在Linux系统里面,这个结构体称为mm_struct。
为了让进程对虚拟地址进行操作,在进程的PCB结构体当中一定包含了mm_struct结构体指针,指向该结构体,方便后续对虚拟内存空间的操作,那么事实是这样吗?我们来看Linux的源代码:
1 struct task_struct
2 {
3 /*...*/
4 struct mm_struct *mm; //对于普通的⽤⼾进程来说该字段指向他的//虚拟地址空间的⽤⼾空间部分,对于内核线程来说这部分为NULL。
5 struct mm_struct *active_mm; // 该字段是内核线程使⽤的。当该进程是内核线程时,它的mm字段为NULL,表⽰没有内存地址空间,可也并不是真正的没有,这是因为所
有进程关于内核的映射都是⼀样的,内核线程可以使⽤任意进程的地址空间。
6
7 /*...*/
8 }
1 struct mm_struct
2 {
3 /*...*/
4 struct vm_area_struct *mmap; /* 指向虚拟区间(VMA)链表 */
5 struct rb_root mm_rb; /* red_black树 */
6 unsigned long task_size; /*具有该结构体的进程的虚拟地址空间的⼤⼩*/
7 /*...*/
8 // 代码段、数据段、堆栈段、参数段及环境段的起始和结束地址。
9 unsigned long start_code, end_code, start_data, end_data;
10 unsigned long start_brk, brk, start_stack;
11 unsigned long arg_start, arg_end, env_start, env_end;
12 /*...*/
13 }
虚拟内存管理
在前面我们的讨论当中,我们知道操作系统中会同时存在多个进程,每个进程都有自己独立的虚拟地址空间mm_struct结构体,那么操作系统是如何对这些虚拟地址空间进行管理的呢?
有两种方式:
1.当虚拟区较少时采用单链表,由mmap指针指向这个链表
2.当虚拟区间较多时采取红黑树来管理,由mm_rb指针指向这棵树
Linux内核使用vm_area_struct结构体来表示一个独立的虚拟内存区域,由于每个不同质的虚拟内存区域功能和内部机制不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。
vm_area_struct结构体代码如下所示:
struct vm_area_struct {unsigned long vm_start; //虚存区起始unsigned long vm_end; //虚存区结束struct vm_area_struct *vm_next, *vm_prev; //前后指针struct rb_node vm_rb; //红⿊树中的位置unsigned long rb_subtree_gap;struct mm_struct *vm_mm; //所属的 mm_structpgprot_t vm_page_prot;unsigned long vm_flags; //标志位struct {struct rb_node rb;unsigned long rb_subtree_last;} shared;struct list_head anon_vma_chain;struct anon_vma *anon_vma;const struct vm_operations_struct *vm_ops; //vma对应的实际操作unsigned long vm_pgoff; //⽂件映射偏移量struct file * vm_file; //映射的⽂件void * vm_private_data; //私有数据atomic_long_t swap_readahead_info;#ifndef CONFIG_MMUstruct vm_region *vm_region; /* NOMMU mapping region */#endif#ifdef CONFIG_NUMAstruct mempolicy *vm_policy; /* NUMA policy for the VMA */#endifstruct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;内存空间划分
在我们有了前面知识得基础上,我们再来看一下内存空间的划分示意图:
其中主要分为两大块,一块是内核空间,这一块空间只能使用系统调用;另一块是用户空间,这一块空间是我们用户能够直接操作的空间,在用户空间当中从下到上分为:正文代码、初始化数据区、未初始化数据区、堆、共享区、栈、命令行参数和环境变量
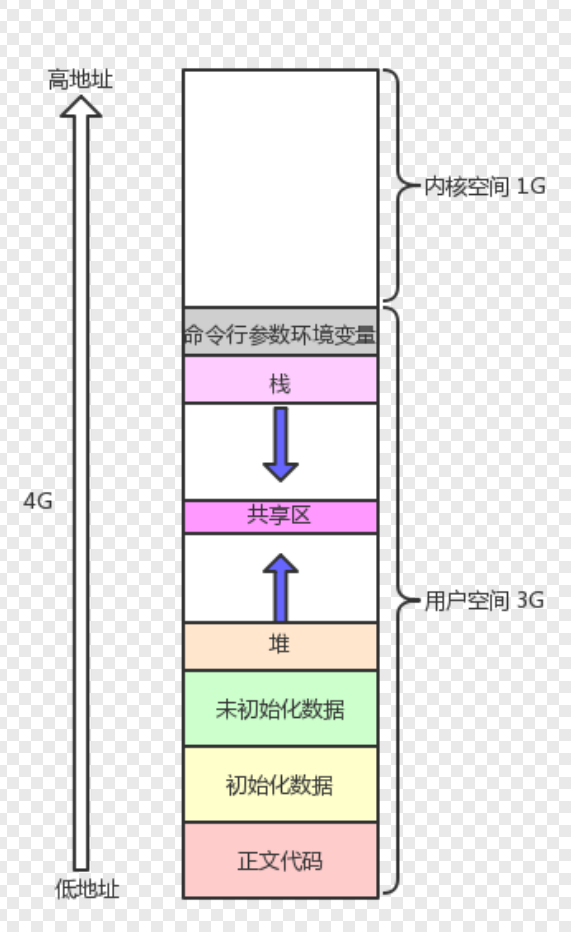
我们知道,正文代码是只读的;初始化数据区和未初始化数据区是可读可写的,全局变量就位于这里,换句话说,这些内存空间是存在访问权限的,那么这个权限是如何被操作系统知道的呢?
实际上,这个权限是通过页表转化得到的,操作系统通过页表将虚拟内存转化为物理内存的过程当中,页表中对所有区域的权限都设置为只读的,一旦发生了写时拷贝,那么就会把权限修改为读写,简单来说,是因为我们需要写时拷贝,所以我们才需要把权限改为可读可写的,由于所有进程都是通过bash创建的子进程,对于已初始化变量和未初始化变量而言,需要发生写时拷贝,所以该区域的权限就被更改为可读可写的了。
有了上面对内存空间划分和页表映射的认识,我们可以的到下面的结论:
1、只要虚拟地址空间存在,那么全局数据区就存在,因此全局变量就会一直存在
2、字符串常量实际上是和代码区编译在一起的,是只读的
3、命令行参数和环境变量属于父进程的地址空间内的数据资源,和代码数据区一样,子进程会继承父进程的地址空间,所以子进程可以看到命令行参数和环境变量
为什么要有虚拟地址空间
通过上面对虚拟地址和页表映射的认识,我们就可以来回答为什么要有虚拟地址空间这一问题。
1、因为有了虚拟地址,就必须转化为物理地址,要访问内存必须先转换,在虚拟到物理内存转换时进行安全审核,变相保证物理内存的安全维护进程的独立性
2、使无序的物理内存空间通过页表映射,在逻辑上转换成有序的地址空间
3、使进程管理和内存管理进行解耦,使它们两个可以分别进行管理
小结
以上就是本篇博客的全部内容,受限于博主的知识水平,可能一些方面还存在些许纰漏,欢迎大家指正,最后,如果本篇文章对您有所帮助的,希望点赞、关注加收藏,您的支持就是我创作的最大动力